【2026计算机毕设设计必过选题】基于大数据的葡萄酒品质数据可视化分析系统 白酒洋酒数据可视化分析(Hadoop+Spark+Hive)
本文介绍了一个基于大数据的葡萄酒品质数据可视化分析系统。该系统整合Hadoop、Spark和Hive技术栈,实现从数据采集、清洗到分布式计算的全流程处理。后端采用Django框架搭建RESTful API,前端基于Vue.js结合Echarts实现十大可视化分析功能,包括酒精酸度品质分析、K-Means聚类等。系统通过直观的交互式图表揭示葡萄酒理化指标与品质的关系,为葡萄酒酿造工艺优化提供数据支持
🔥作者:雨晨源码🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💕💕文末获取源码
文章目录
本次文章主要是介绍基于大数据的葡萄酒品质数据可视化分析系统 白酒洋酒数据可视化分析(Hadoop+Spark+Hive)
1、葡萄酒品质数据可视化分析系统-前言介绍
1.1背景
随着全球葡萄酒市场的日益成熟与竞争加剧,以及消费者对产品品质与风味要求的不断提升,传统依赖于酿酒师经验和感官品评的葡萄酒品质控制模式正面临着前所未有的挑战。这种主观性强的评估方式不仅存在个体差异和不确定性,难以实现标准化,而且在处理海量生产数据时效率低下,无法深入挖掘影响葡萄酒品质的复杂理化规律。在现代酿酒工业中,从葡萄种植、采摘到发酵、陈酿的每一个环节,都会产生包含酒精含量、酸度、pH值、酚类物质等在内的大量高维数据。这些数据中蕴含着决定最终产品风味与品质的关键信息,然而,其数据量庞大、关系错综复杂的特点,使得传统的数据分析工具和方法难以有效处理。因此,如何利用先进的大数据技术,对这些海量数据进行深度挖掘与智能分析,并将复杂的分析结果以直观、易懂的可视化形式呈现出来,从而为葡萄酒的精准酿造、工艺优化和品质预测提供科学、客观的决策依据,已成为当前葡萄酒产业升级与智能化转型中亟待解决的核心问题,这也是开发本系统的根本动因。
1.2课题功能、技术
为应对上述挑战,本课题设计并实现了一个基于大数据的葡萄酒品质数据可视化分析系统。系统整体采用前后端分离的架构,后端以Python语言为核心,整合了强大的大数据技术栈与Web服务框架。首先,利用Hadoop分布式文件系统(HDFS)对海量葡萄酒原始数据进行可靠存储;接着,通过Apache Spark这一高性能的分布式计算引擎,执行包括数据清洗、转换、聚合在内的复杂ETL操作,并借助其机器学习库MLlib实现K-Means聚类分析、指标离群值检测等高级算法任务;同时,结合Hive构建数据仓库,为即席查询提供便利。分析产生的关键结果,如各项理化指标的统计值、指标间的相关性矩阵、聚类中心点坐标等,被持久化存储于MySQL数据库中,以优化前端访问性能。后端服务层采用Django框架,负责构建RESTful API接口,高效响应前端请求。前端则基于Vue.js框架构建用户界面,通过Axios与后端进行异步数据交互,并集成功能强大的Echarts可视化库,将数据动态渲染为散点图、热力图、饼图、箱形图等多种交互式图表,具体实现了酒精酸度品质分析、酒精品质关系分析、理化指标统计分析、指标相关性矩阵分析、固定酸度PH值分析、K-Means聚类分析、酒精浓度分布分析、指标离群值检测分析、PH值与品质关系分析以及品质等级分布分析等十大核心功能模块。
1.3 意义
本课题的研究与实现具有显著的理论价值与实践意义。在理论层面,它成功地将Hadoop、Spark等前沿大数据技术与Web可视化技术相结合,构建了一套完整的数据处理、分析与展示流程,为传统食品与农业领域的数字化转型提供了一个可复制、可扩展的技术范式和解决方案。在实践层面,该系统将复杂的葡萄酒品质数据转化为直观的视觉洞察,极大地降低了数据分析的门槛,使得酿酒师、品控专家乃至企业管理者都能快速理解数据背后的规律。通过系统揭示的酒精、酸度、pH值等关键指标与品质的量化关系,生产企业能够实现从“经验酿造”到“数据驱动酿造”的转变,精准优化发酵工艺参数,稳定并提升产品质量,减少生产成本。同时,K-Means聚类分析能够对葡萄酒进行科学的市场细分,而离群值检测则有助于及时发现生产过程中的异常批次。综上所述,本系统不仅为葡萄酒品质的科学化、精细化管理提供了强有力的技术工具,也为推动整个葡萄酒产业链的智能化升级和高质量发展贡献了重要力量。
2、葡萄酒品质数据可视化分析系统-研究内容
(1)数据采集与清洗:从UCI等公开数据集获取葡萄酒数据,使用Pandas处理缺失值与异常值,并进行标准化,为后续分析做准备。
(2)大数据处理与分析:将数据上传至HDFS,利用Spark进行分布式计算,执行K-Means聚类、相关性分析等任务,结果存入Hive或MySQL。
(3)数据可视化:前端Vue通过Axios调用后端API获取数据,利用Echarts将数据渲染为散点图、热力图等交互式图表,直观展示分析结果。
(4)Web框架搭建:基于Django框架搭建后端服务,设计RESTful API接口,配置路由与视图,利用ORM与MySQL数据库进行数据交互。
(5)系统测试:编写单元测试验证后端逻辑,使用Postman测试API接口,进行前端功能与兼容性测试,确保系统稳定可靠。
3、葡萄酒品质数据可视化分析系统-开发技术与环境
- 开发语言:Python
- 大数据:Hadoop+Spark+Hive
- 数据处理:pandas
- 后端框架:Django
- 前端:Vue
- 数据库:MySQL
- 算法:K-means算法
- 开发工具:Pycharm
4、葡萄酒品质数据可视化分析系统-功能介绍
1、数据管理:信息列表展示。
2、词云图:词云图。
3、可视化分析:酒精酸度品质分析、酒精品质关系分析、理化指标统计分析、指标相关性矩阵分析、因定酸度PH值分析、K-Means聚类分析、酒精浓度分布分析、指标离群值检测分析、PH值与品质关系分析、品质等级分布分析
4、系统管理:登录注册、个人信息修改。
5、葡萄酒品质数据可视化分析系统-论文参考
6、葡萄酒品质数据可视化分析系统-成果展示
6.1演示视频
【2026计算机毕设设计必过选题】基于大数据的葡萄酒品质数据可视化分析系统 白酒洋酒数据可视化分析(Hadoop+Spark+Hive)
6.2演示图片
☀️首页☀️
☀️登录☀️
☀️可视化分析☀️
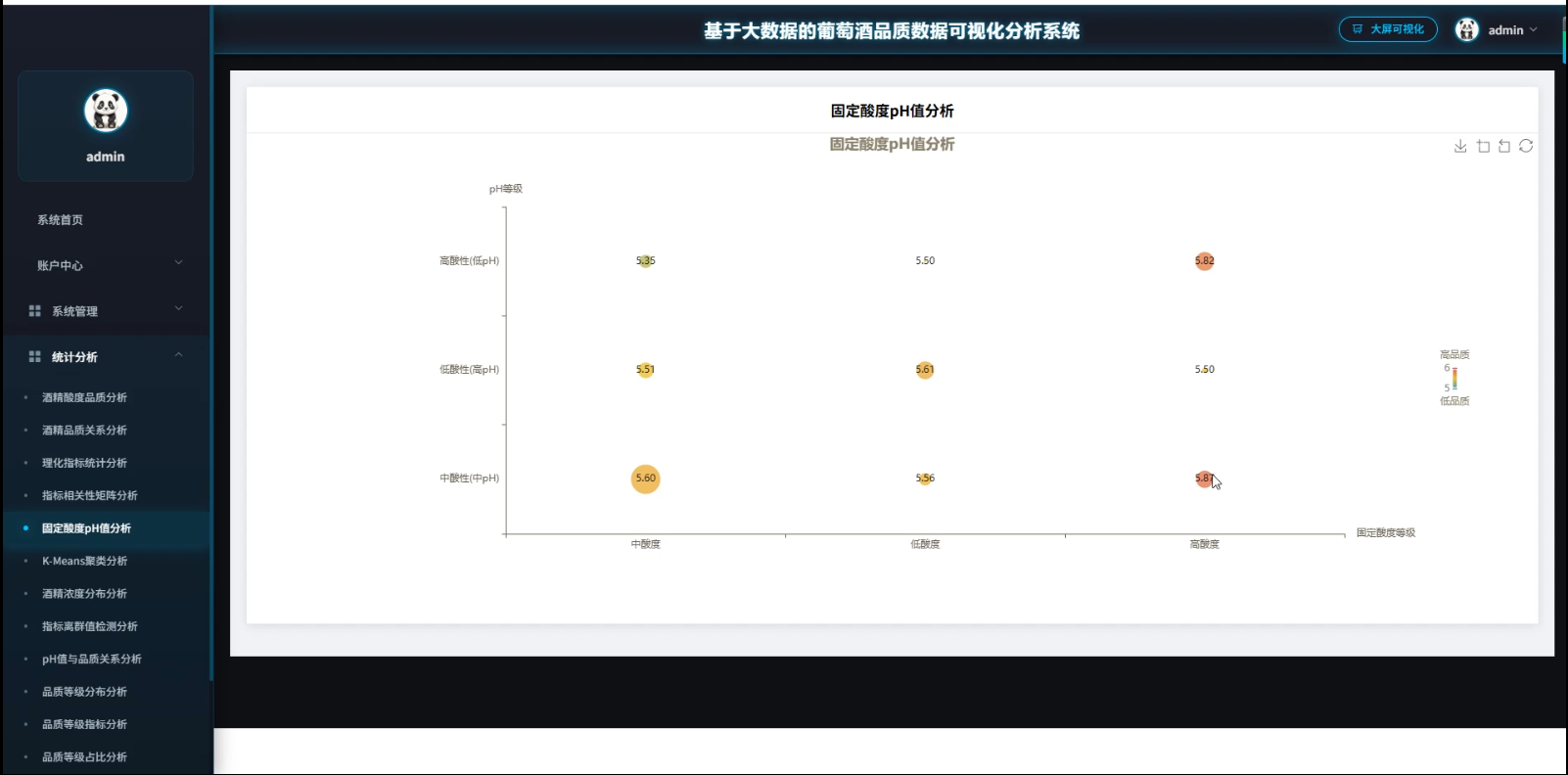
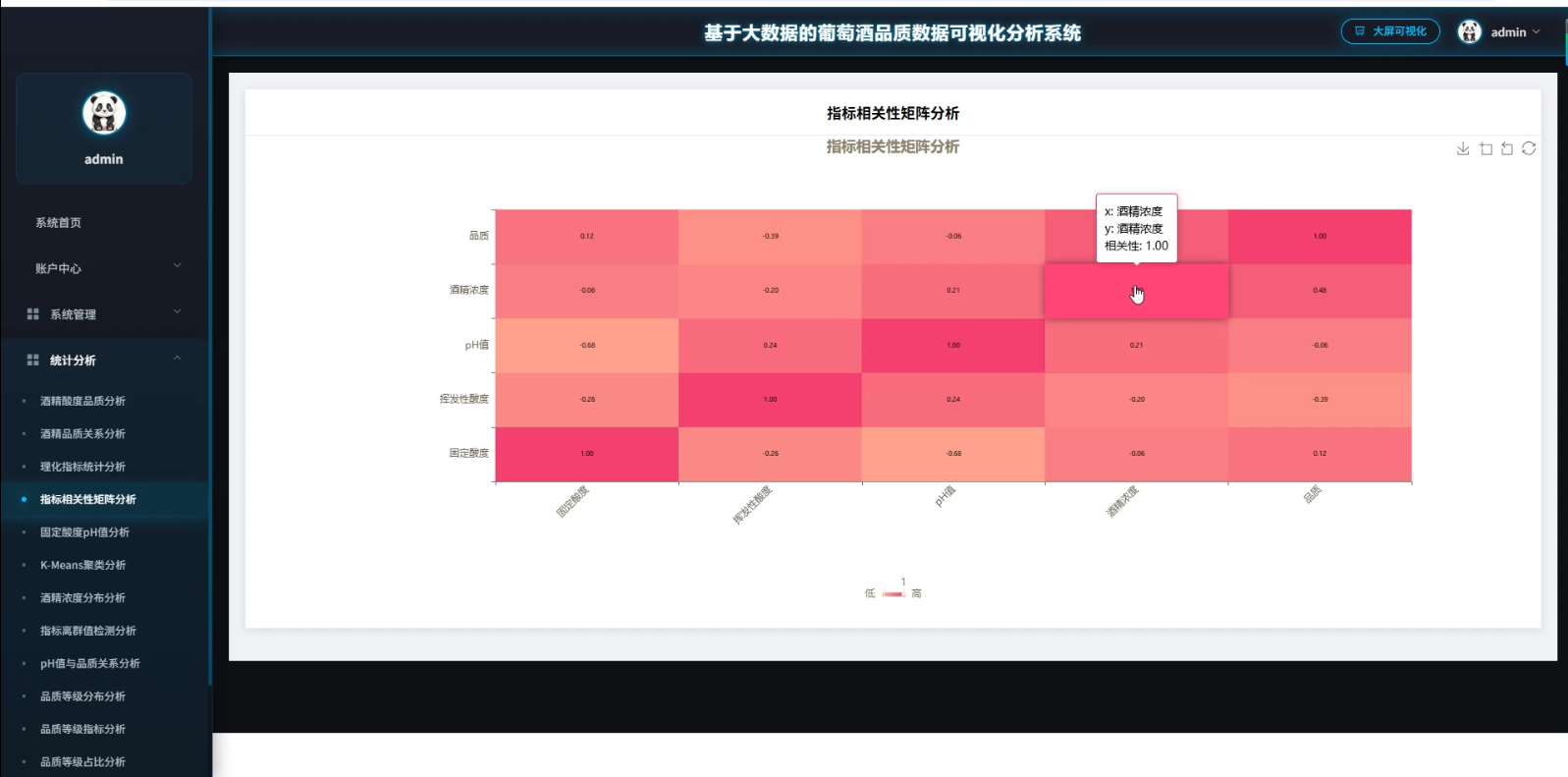
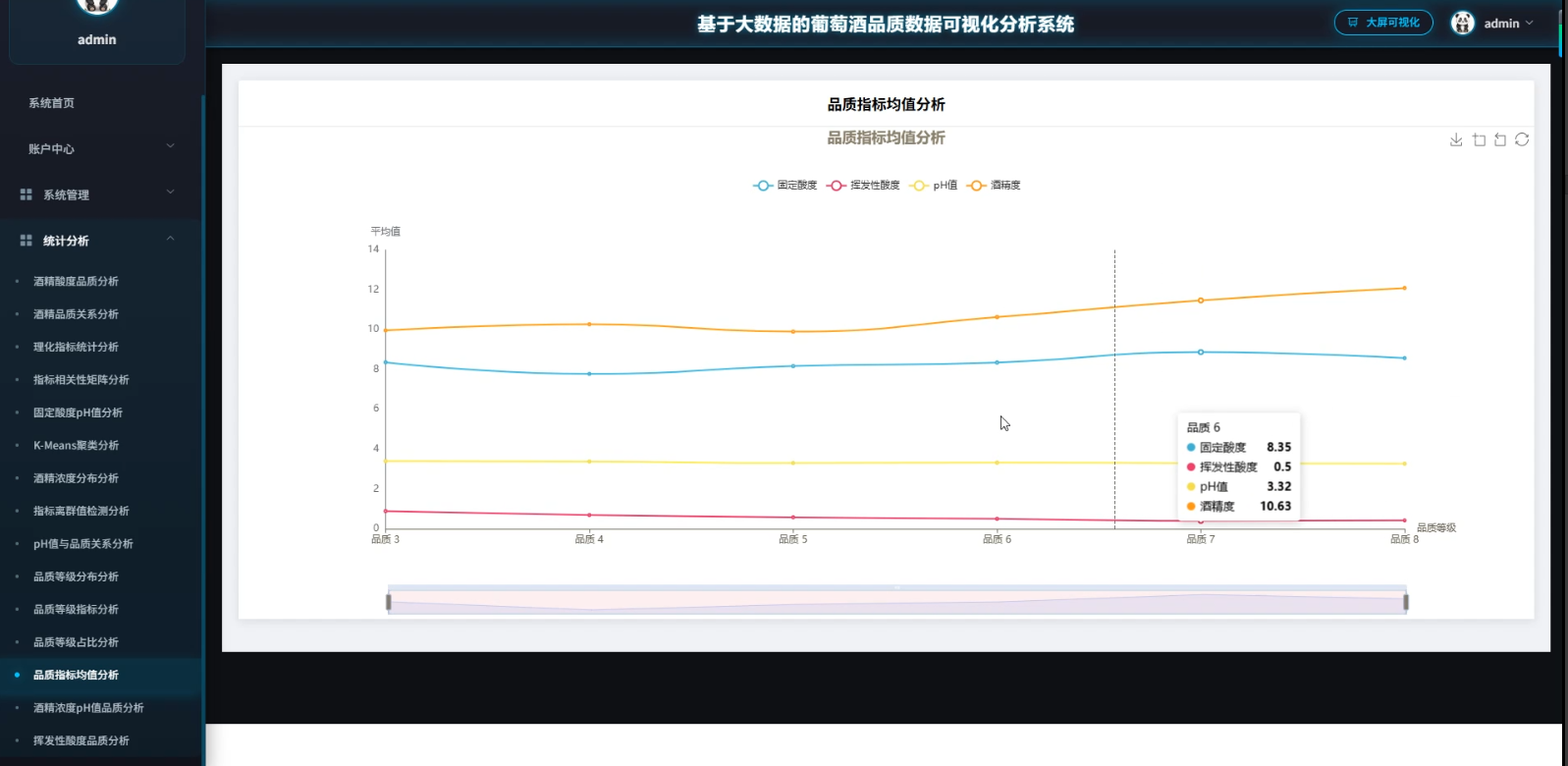
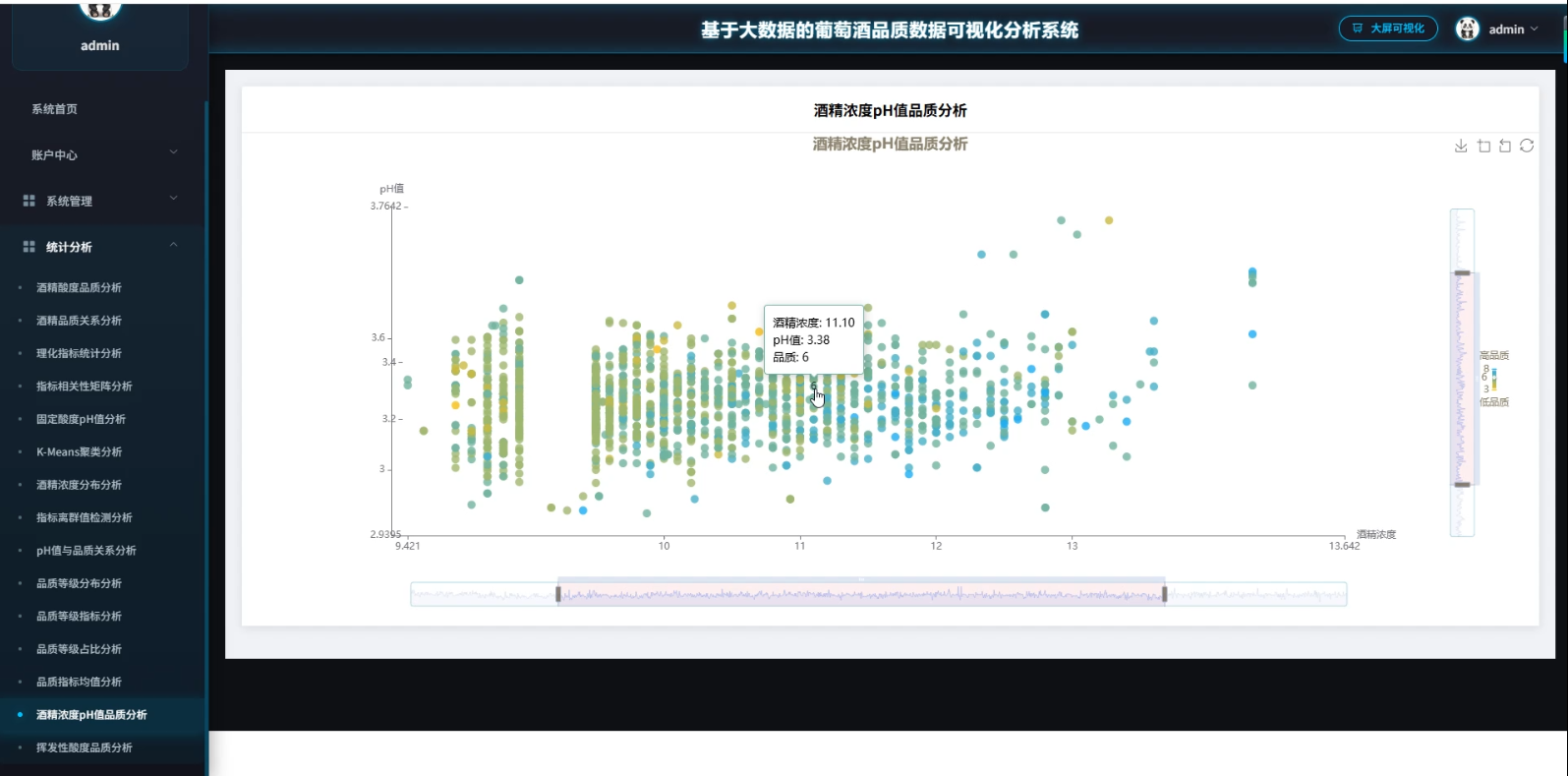
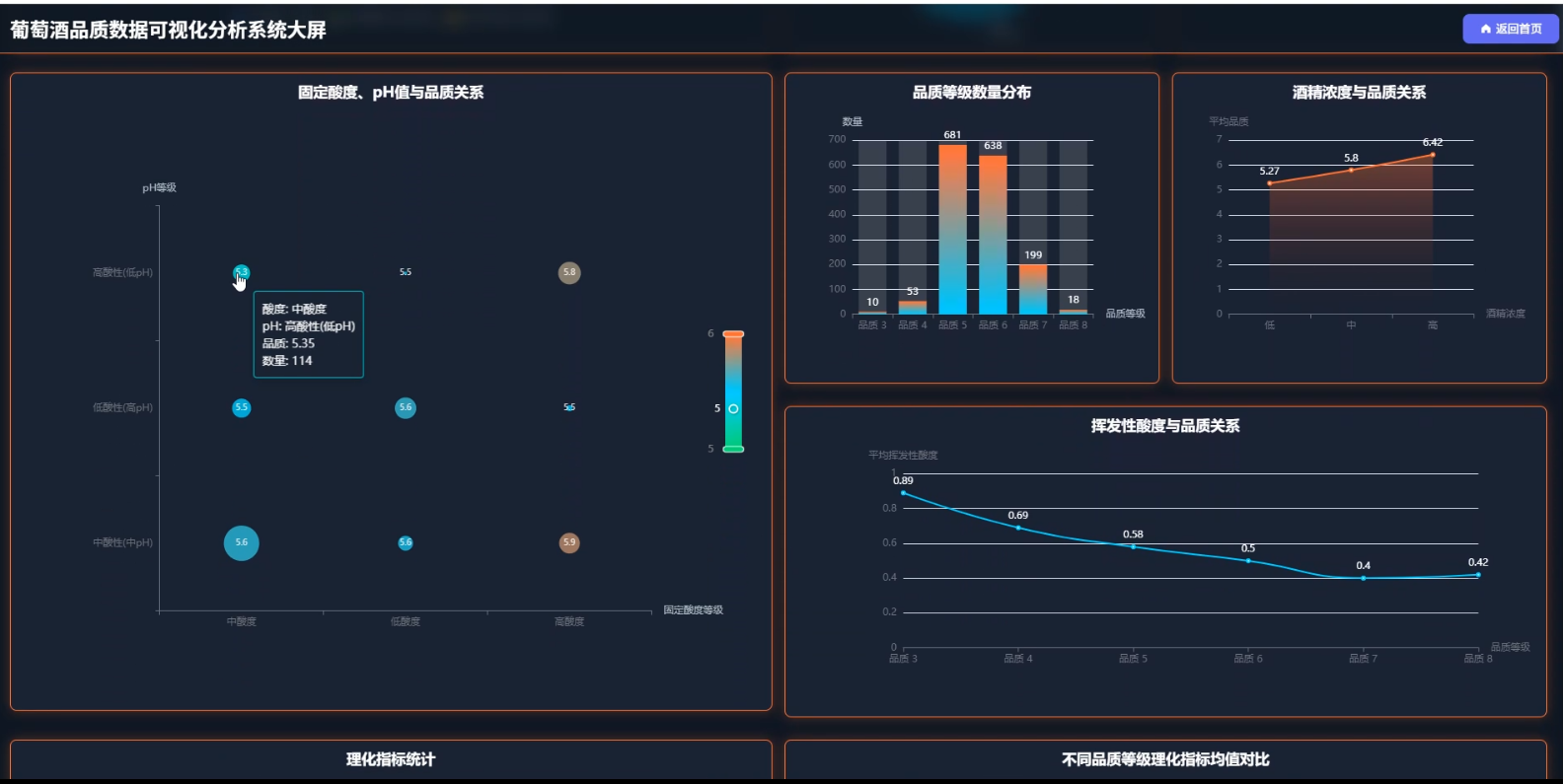
☀️大屏☀️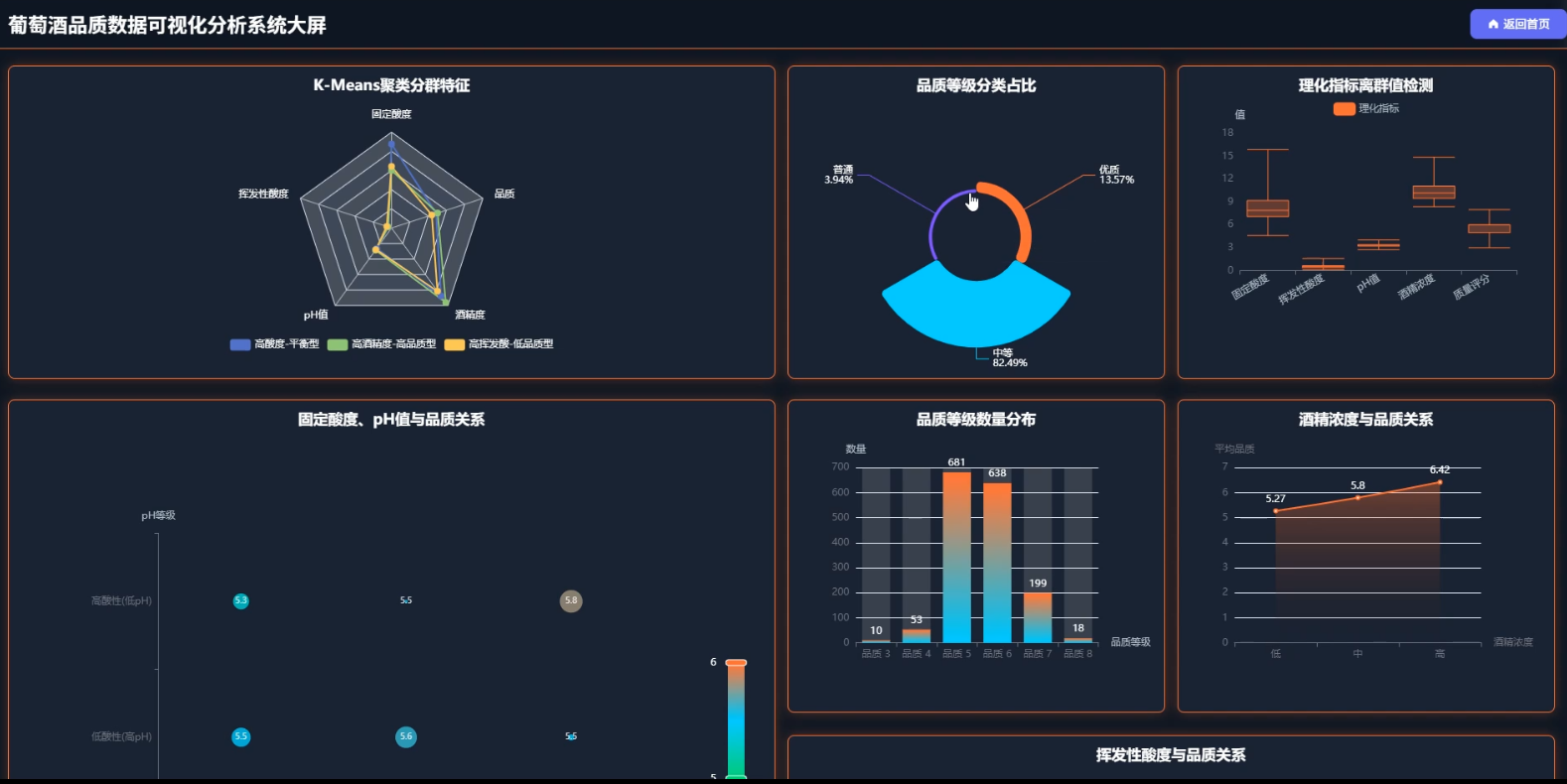
☀️XX数据管理☀️
7、代码展示
1.数据清洗【代码如下(示例):】
class WineDataCleaner:
def __init__(self, file_path):
self.file_path = file_path
self.raw_data = None
self.cleaned_data = None
def load_data(self):
"""加载原始葡萄酒数据"""
try:
self.raw_data = pd.read_csv(self.file_path, sep=';')
print(f"数据加载成功,共{len(self.raw_data)}条记录")
print(f"数据列名: {list(self.raw_data.columns)}")
return self.raw_data
except Exception as e:
print(f"数据加载失败: {e}")
return None
def check_data_quality(self):
"""检查数据质量"""
print("\n=== 数据质量检查 ===")
print(f"数据形状: {self.raw_data.shape}")
print(f"缺失值统计:\n{self.raw_data.isnull().sum()}")
print(f"重复数据数量: {self.raw_data.duplicated().sum()}")
print(f"数据类型:\n{self.raw_data.dtypes}")
# 检查异常值
numeric_cols = self.raw_data.select_dtypes(include=[np.number]).columns
for col in numeric_cols:
Q1 = self.raw_data[col].quantile(0.25)
Q3 = self.raw_data[col].quantile(0.75)
IQR = Q3 - Q1
outliers = self.raw_data[(self.raw_data[col] < Q1 - 1.5*IQR) |
(self.raw_data[col] > Q3 + 1.5*IQR)]
print(f"{col}列异常值数量: {len(outliers)}")
2.大数据处理【代码如下( 示例):】
# 计算相关性
correlation_matrix = Correlation.corr(feature_df, "features").collect()[0][0]
print("相关性矩阵计算完成")
return quality_stats, correlation_matrix
def perform_clustering_analysis(self, k=3):
"""执行K-Means聚类分析"""
print(f"\n=== K-Means聚类分析 (k={k}) ===")
# 选择用于聚类的特征
feature_cols = ["alcohol", "pH", "fixed_acidity", "volatile_acidity"]
# 特征组装
assembler = VectorAssembler(inputCols=feature_cols, outputCol="raw_features")
assembled_df = assembler.transform(self.wine_df)
# 特征标准化
scaler = StandardScaler(inputCol="raw_features", outputCol="scaled_features")
scaler_model = scaler.fit(assembled_df)
scaled_df = scaler_model.transform(assembled_df)
# K-Means聚类
kmeans = KMeans(featuresCol="scaled_features", predictionCol="cluster", k=k)
kmeans_model = kmeans.fit(scaled_df)
# 预测聚类结果
clustered_df = kmeans_model.transform(scaled_df)
# 显示聚类中心
centers = kmeans_model.clusterCenters()
print("聚类中心:")
for i, center in enumerate(centers):
print(f"Cluster {i}: {center}")
# 聚类统计
cluster_stats = clustered_df.groupBy("cluster").agg(
count("*").alias("cluster_size"),
avg("quality").alias("avg_quality"),
avg("alcohol").alias("avg_alcohol")
).orderBy("cluster")
print("聚类统计信息:")
cluster_stats.show()
return clustered_df, cluster_stats
def save_to_hive(self, table_name="wine_analysis_results"):
"""将分析结果保存到Hive表"""
try:
# 创建临时视图
self.wine_df.createOrReplaceTempView("wine_temp")
# 执行SQL查询并保存到Hive
result_df = self.spark.sql("""
SELECT
quality,
COUNT(*) as count,
AVG(alcohol) as avg_alcohol,
AVG(pH) as avg_pH,
STDDEV(alcohol) as stddev_alcohol
FROM wine_temp
GROUP BY quality
ORDER BY quality
""")
# 保存到Hive表
result_df.write.mode("overwrite").saveAsTable(table_name)
print(f"分析结果已保存到Hive表: {table_name}")
except Exception as e:
print(f"保存到Hive失败: {e}")
def close_spark_session(self):
"""关闭Spark会话"""
self.spark.stop()
print("Spark会话已关闭")
8、结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 23
23 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)