【2026高分大数据毕设选题】基于Hadoop+Spark的农产品供应价格数据可视化分析系统 |1w条数据集(可用于毕业设计)
本文介绍了一个基于Hadoop+Spark的农产品供应价格数据可视化分析系统。该系统采用大数据技术框架,结合Python、Django、Vue.js和Echarts等技术,实现了农产品价格数据的采集、清洗、分析与可视化功能。系统包含产品、价格、地区和商家四个维度的分析模块,支持1万条数据集处理,适用于毕业设计项目。通过Hadoop进行分布式存储,Spark进行实时分析,结合机器学习算法实现价格预测
🔥作者:雨晨源码🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💕💕文末获取源码
文章目录
本次文章主要是介绍基于Hadoop+Spark的农产品供应价格数据可视化分析系统 |1w条数据集(可用于毕业设计)
1、农产品供应价格数据可视化分析系统-前言介绍
1.1背景
随着全球农业产业的发展与电子商务的兴起,农产品供应链的价格变动成为了市场参与者关注的焦点。农产品价格受多种因素影响,包括生产季节、市场需求、运输成本、天气变化、政治因素等。对于农产品供应商、零售商以及消费者来说,精准的价格预测与市场趋势分析至关重要。然而,现有的农产品价格分析往往局限于传统的数据处理方法,缺乏实时、动态且多维度的分析能力。尤其是在面对海量的农产品价格数据时,传统数据库和分析工具无法提供足够的处理能力,难以提供准确的决策支持。因此,开发一个基于大数据技术的农产品供应价格数据可视化分析系统,不仅能提升数据处理效率,也能帮助各方决策者实时掌握价格趋势,为供应链管理提供更精准的指导。
1.2课题功能、技术
本课题构建了一套基于Hadoop、Spark、Hive的大数据分析架构,结合Python语言、Django后端框架、Vue.js前端框架与Echarts可视化技术的农产品供应价格数据可视化分析系统。系统主要包括四大分析模块:产品维度分析、价格维度分析、地区维度分析和商家维度分析。通过大数据处理框架,系统能够高效地从多个数据源采集农产品的价格、供需、商家信息等数据,并基于这些数据进行实时分析。系统支持对农产品价格的历史趋势分析、未来价格预测、区域价格差异、各商家价格竞争力的分析,并通过Echarts实现清晰的图表展示。系统采用Django作为后端框架进行数据接口开发,利用Vue.js搭建动态交互式前端,确保用户体验流畅,数据展示直观。
1.3 意义
该系统的开发不仅为农产品供应链各环节提供了高效的价格分析工具,也为政府部门、农业企业、农产品零售商、消费者等各方提供了一个精准的市场动态监控平台。通过基于大数据技术的分析,用户可以实时查看不同产品、不同地区的价格走势,识别价格波动的原因,从而帮助各方作出更加科学的决策。同时,该系统提供的可视化分析功能,使得数据展示更加直观、易懂,大大提升了决策效率与准确性。随着大数据技术在农业领域的不断应用,这种基于数据分析的农产品价格决策支持系统将为整个产业链的可持续发展提供有力保障。
2、农产品供应价格数据可视化分析系统-研究内容
(1)数据采集与清洗:通过爬虫技术从多个电商平台、农业市场、政府数据开放平台等渠道采集农产品价格数据。然后使用Python中的Pandas库进行数据清洗,去除重复数据、填补缺失值,并处理异常值,确保数据的准确性与完整性,准备好用于分析和展示。
(2)大数据处理与分析:利用Hadoop进行大数据存储和分布式计算,结合Spark对采集的数据进行清洗、处理和分析。通过对价格、销量、地域等多维数据的处理,使用Spark进行实时数据分析、价格趋势预测,并通过Hive进行高效的数据查询和管理。
(3)数据可视化:采用Echarts和Vue.js实现数据的动态可视化展示。通过图表(如折线图、柱状图、热力图)展示农产品价格的历史趋势、区域差异、商家竞争力等分析结果,支持用户交互操作,实时查看不同时间段、不同区域的数据表现,增强用户体验。
(4)Web框架搭建:使用Django框架搭建后端系统,提供数据存储、处理和API接口服务。前端使用Vue.js进行开发,提供用户交互界面,实现数据展示、用户权限管理、交互式查询等功能,确保系统的高效运行与流畅操作体验。
(5)系统测试:进行单元测试、集成测试和系统负载测试,确保系统的稳定性、性能和安全性。使用压力测试工具模拟大量用户访问,检查系统在高负载下的响应速度与数据处理能力,确保数据实时更新,保证系统上线后的高效运行。
3、农产品供应价格数据可视化分析系统-开发技术与环境
- 开发语言:Python
- 大数据:Hadoop+Spark+Hive
- 数据处理:pandas
- 后端框架:Django
- 前端:Vue
- 数据库:MySQL
- 算法:K-means算法
- 开发工具:Pycharm
4、农产品供应价格数据可视化分析系统-功能介绍
1、数据管理:信息列表展示。
2、词云图:词云图。
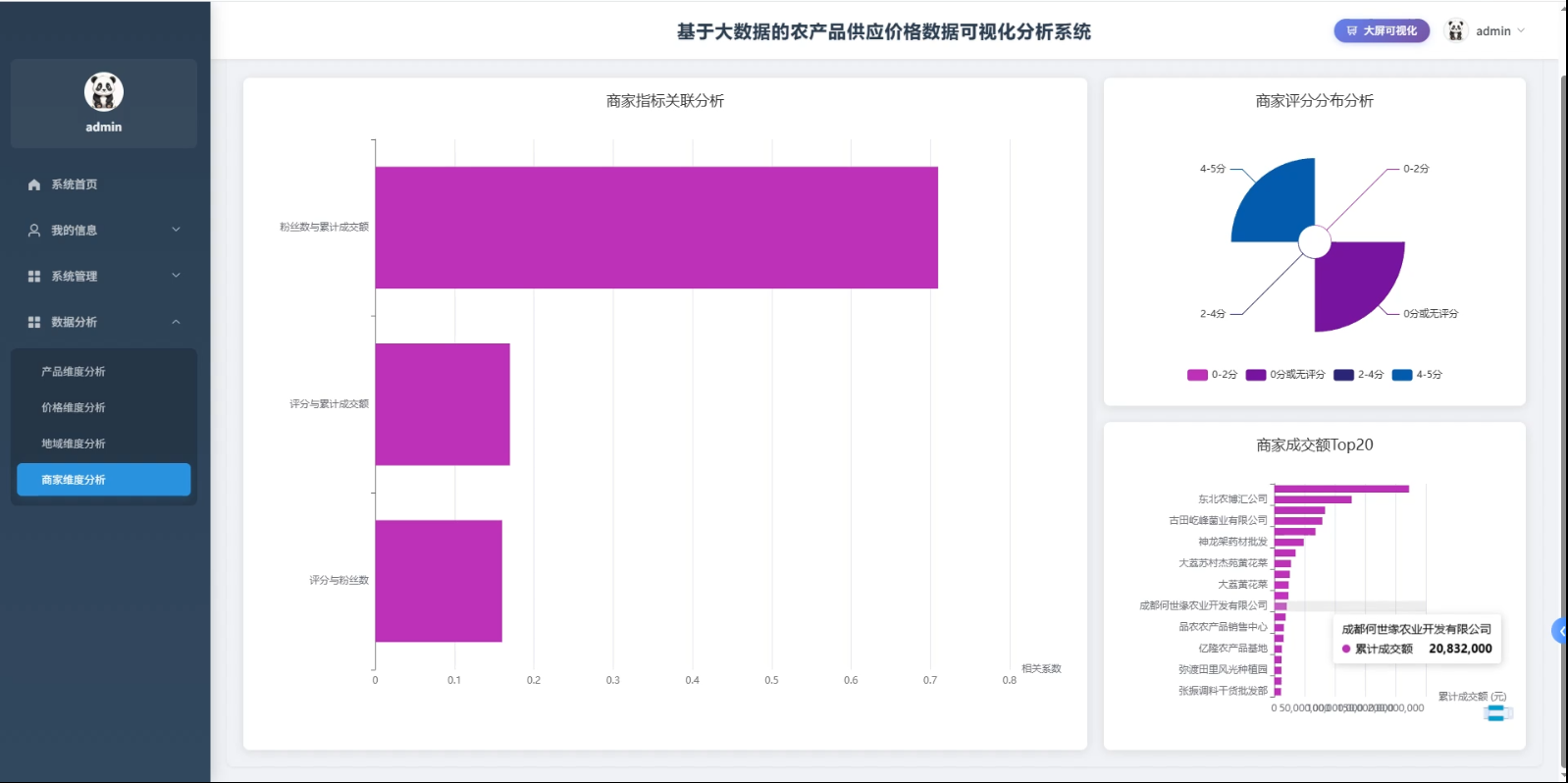
3、可视化分析:产品维度分析、价格维度分析、地城维度分析、商家维度分析
4、系统管理:登录注册、个人信息修改。
5、农产品供应价格数据可视化分析系统-论文参考
6、农产品供应价格数据可视化分析系统-成果展示
6.1演示视频
【2026高分大数据毕设选题】基于Hadoop+Spark的农产品供应价格数据可视化分析系统(可用于毕业设计)
6.2演示图片
☀️首页☀️
☀️登录☀️
☀️可视化分析☀️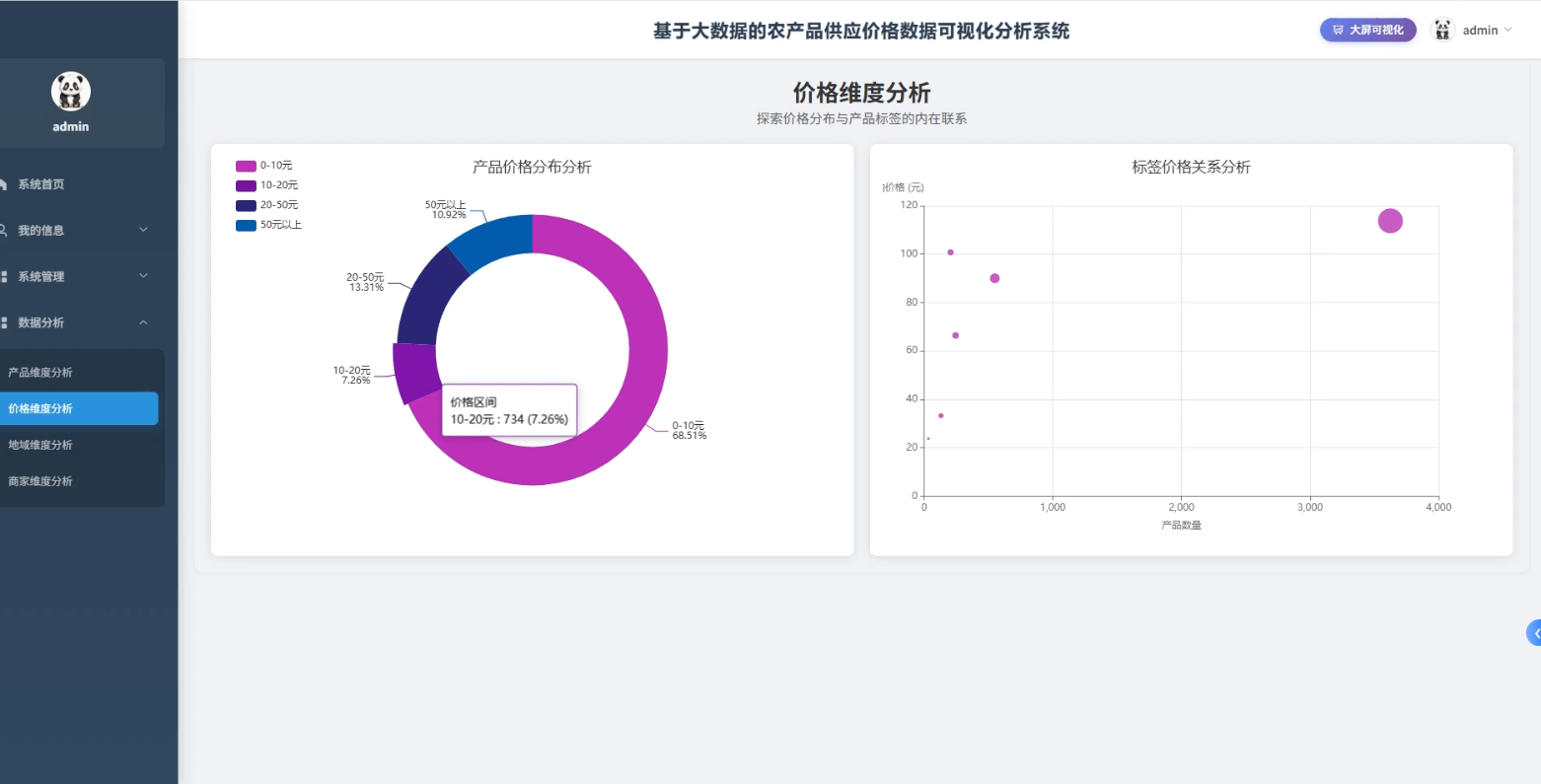
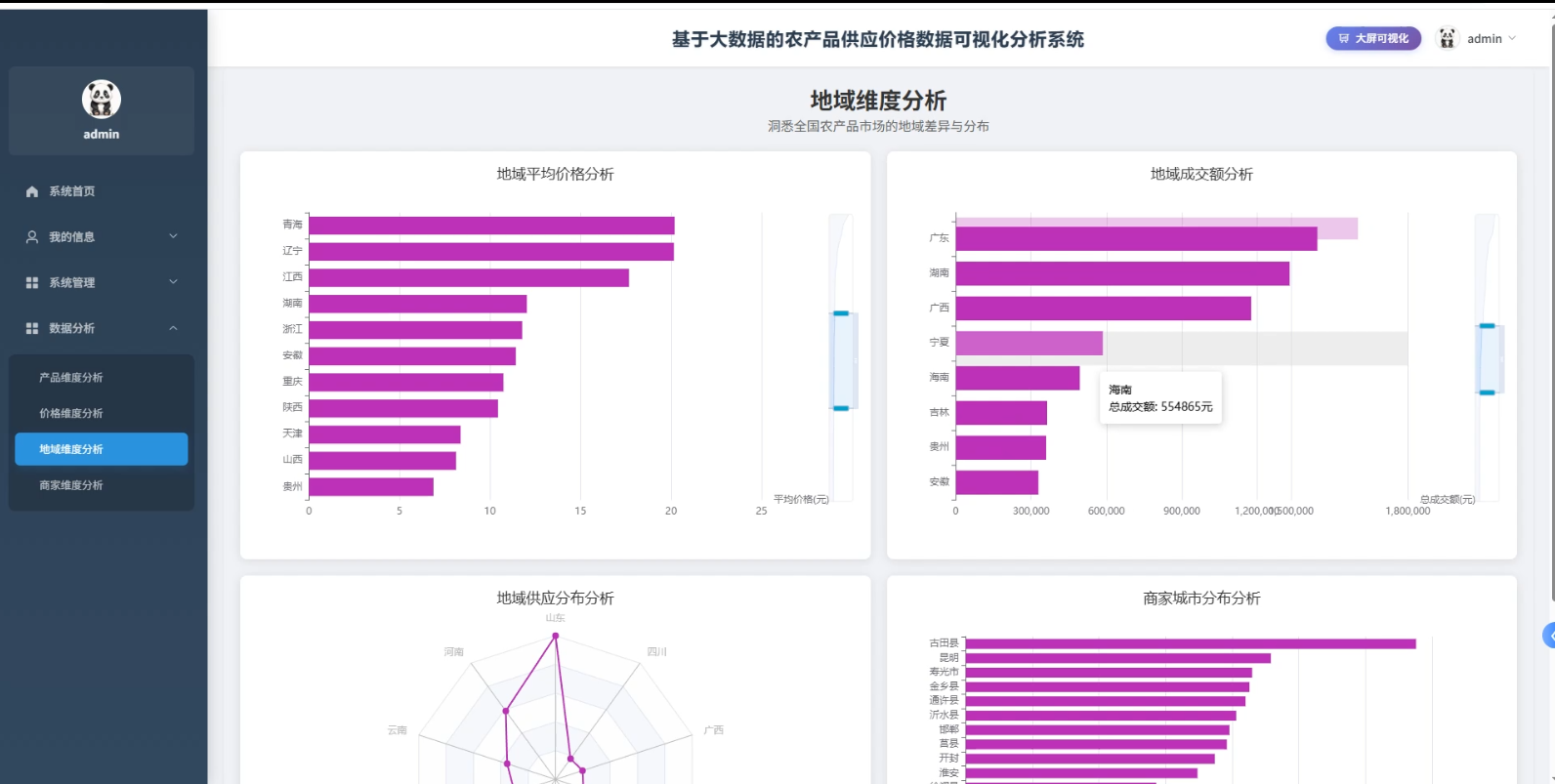
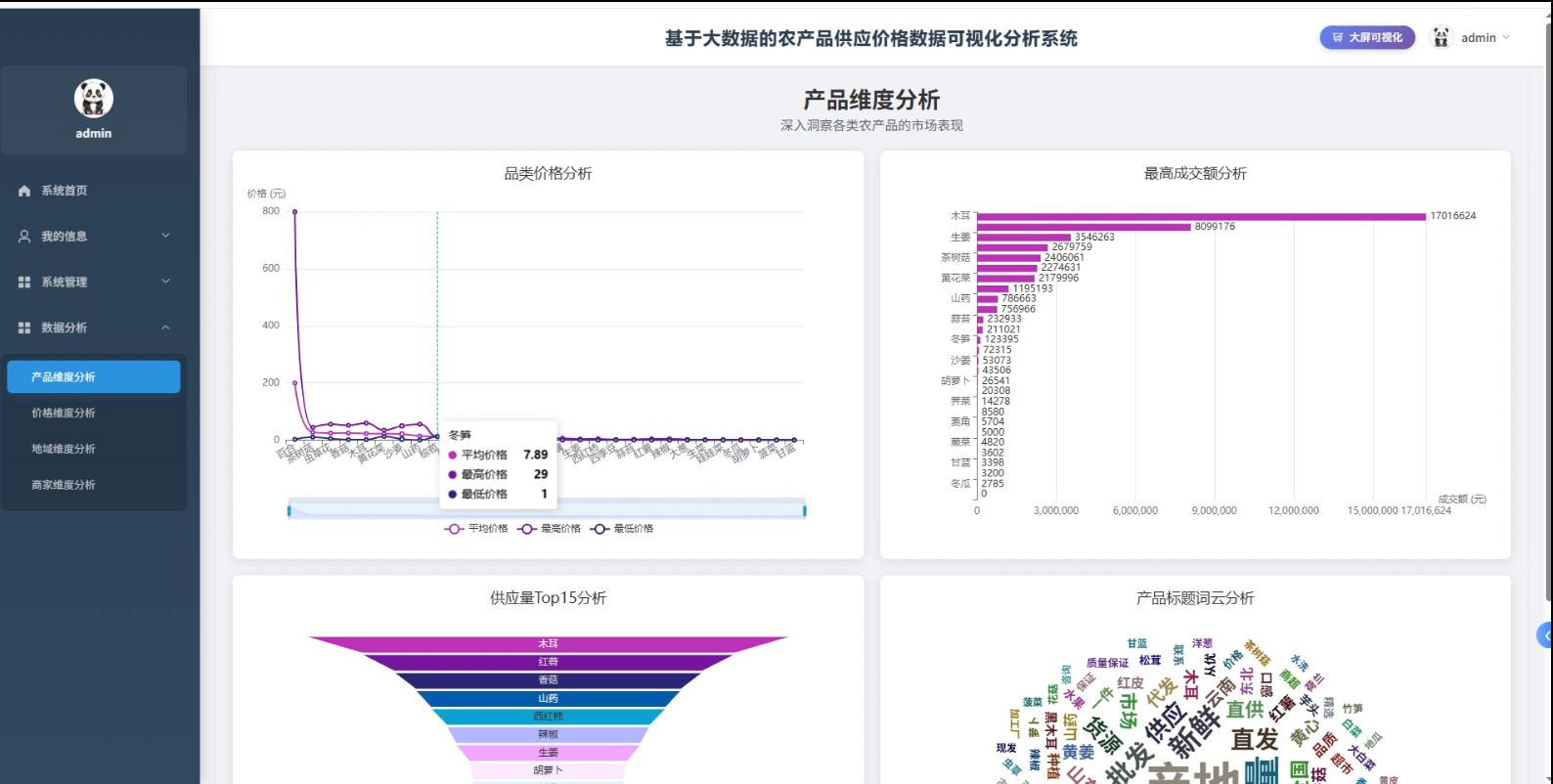
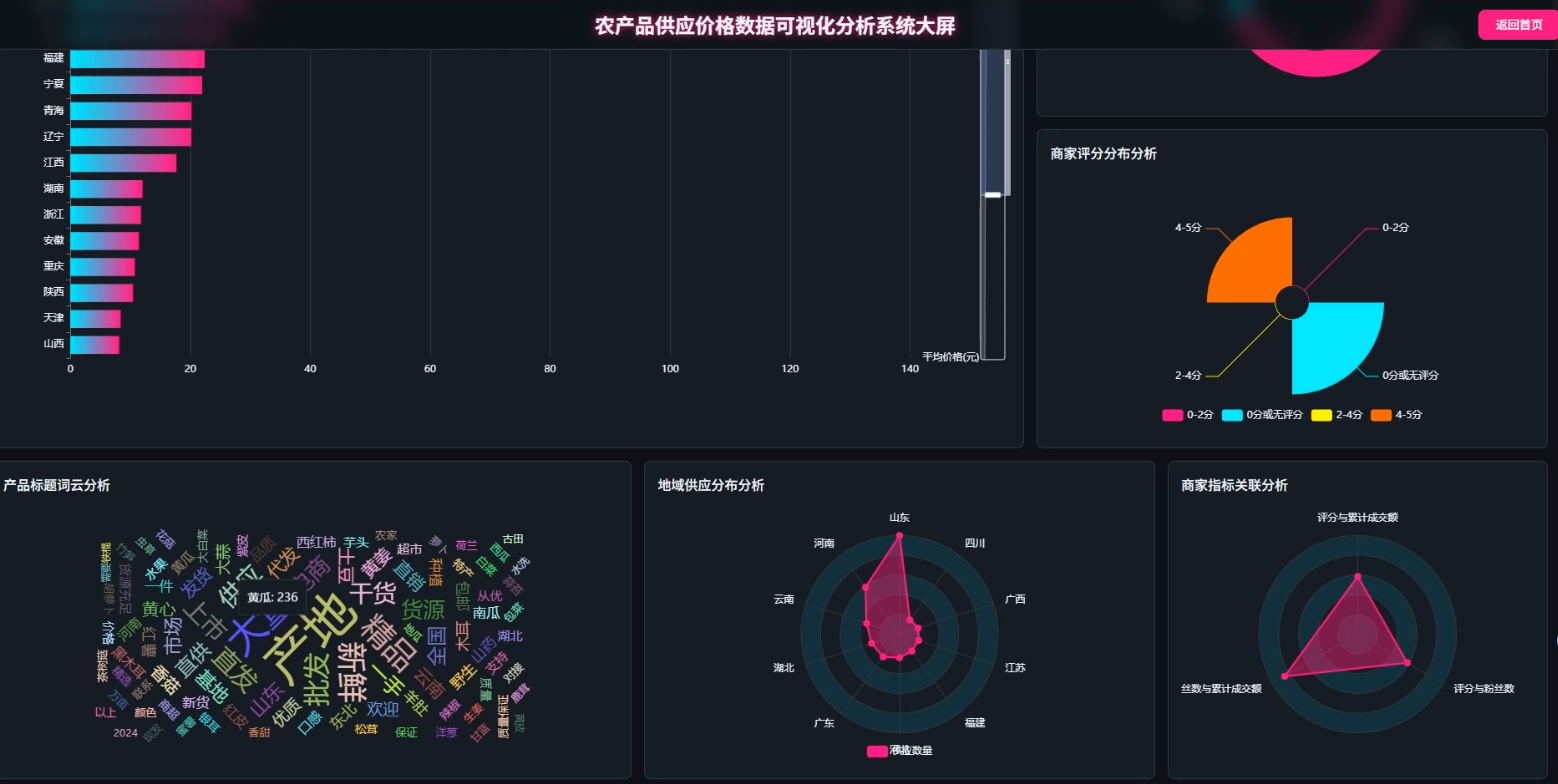
☀️大屏☀️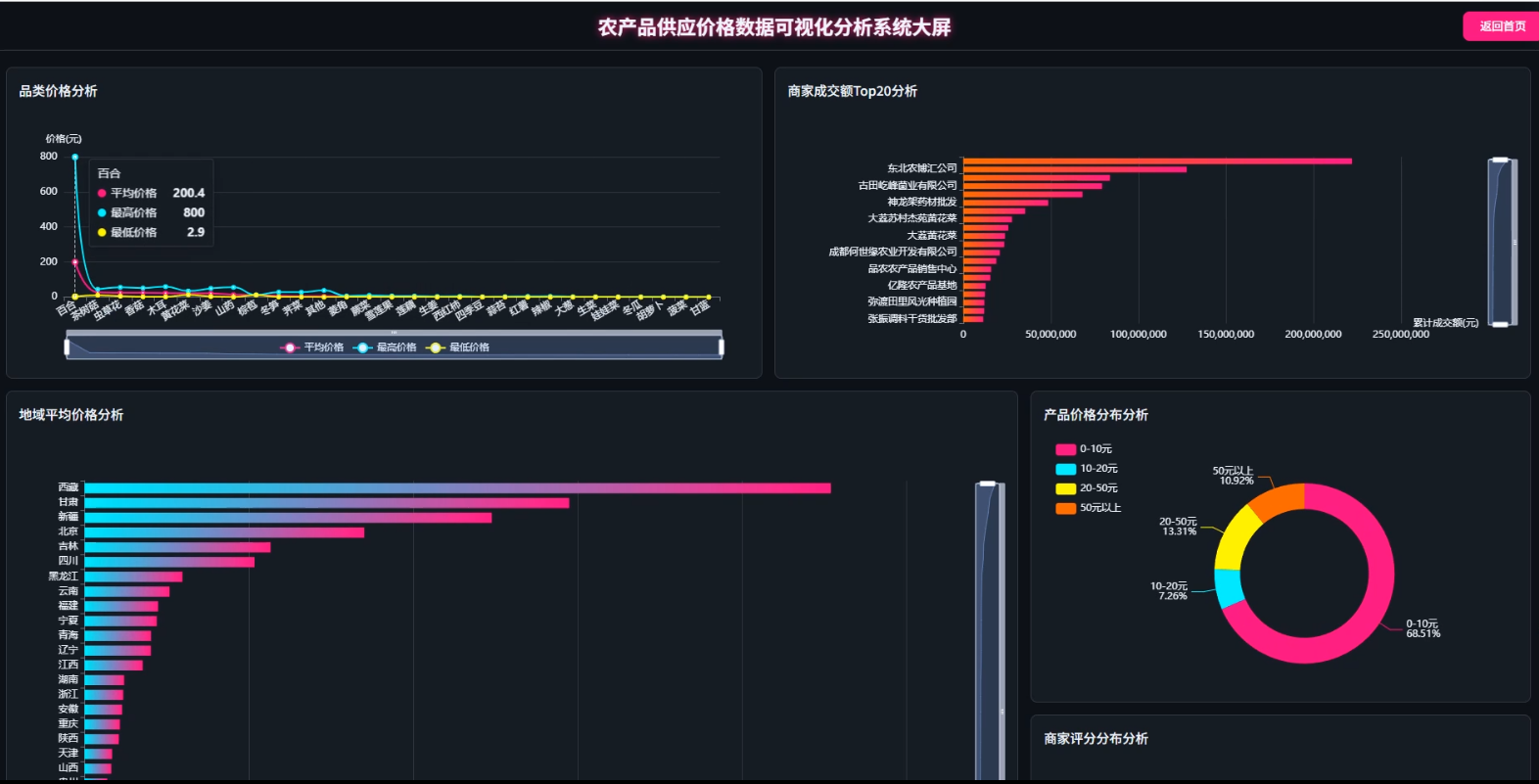
☀️XX数据管理☀️
7、代码展示
1.数据清洗【代码如下(示例):】
import pandas as pd
import numpy as np
# 读取农产品价格数据(假设CSV格式)
data = pd.read_csv('agriculture_prices.csv')
# 查看数据的基本信息
print(data.info())
# 删除重复数据
data = data.drop_duplicates()
# 填补缺失值:
# 对于数值型数据,如价格,将缺失值用该列的均值填充
data['price'] = data['price'].fillna(data['price'].mean())
# 对于文本数据,如商品名称,将缺失值填充为'未知'
data['product_name'] = data['product_name'].fillna('未知')
# 去除异常值:价格列的值应该是大于0的
data = data[data['price'] > 0]
# 转换日期列格式
data['date'] = pd.to_datetime(data['date'])
# 标准化文本数据(例如,转换为小写)
data['product_name'] = data['product_name'].apply(lambda x: x.lower() if isinstance(x, str) else x)
# 去除文本中的特殊字符
import re
data['product_name'] = data['product_name'].apply(lambda x: re.sub(r'[^a-zA-Z0-9\s]', '', x))
# 数据集的统计信息
print(data.describe())
# 输出清洗后的数据样本
print(data.head())
# 将清洗后的数据保存为新的CSV文件
data.to_csv('cleaned_agriculture_prices.csv', index=False)
2.大数据处理【代码如下( 示例):】
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, udf
from pyspark.ml.feature import Tokenizer, HashingTF, IDF
from pyspark.ml import Pipeline
from pyspark.ml.regression import LinearRegression
from pyspark.sql.types import IntegerType, StringType
import re
# 创建Spark会话
spark = SparkSession.builder.appName("AgriculturePriceAnalysis").getOrCreate()
# 读取农产品价格数据
data = spark.read.csv('cleaned_agriculture_prices.csv', header=True, inferSchema=True)
# 查看数据
data.show(5)
# 去除空值:删除包含空值的行
data = data.na.drop()
# 数据预处理:清理文本数据(去除特殊字符)
def clean_text(text):
if text is not None:
text = text.lower()
text = re.sub(r'[^a-zA-Z0-9\s]', '', text)
return text
# 注册UDF清理文本数据
clean_text_udf = udf(clean_text, StringType())
data = data.withColumn("cleaned_product_name", clean_text_udf(col("product_name")))
# 使用Tokenizer将商品名称转换为单词列表
tokenizer = Tokenizer(inputCol="cleaned_product_name", outputCol="words")
# 使用HashingTF将单词列表转换为TF特征
hashingTF = HashingTF(inputCol="words", outputCol="raw_features", numFeatures=10000)
# 使用IDF进行TF-IDF加权
idf = IDF(inputCol="raw_features", outputCol="features")
# 假设我们有一个目标变量‘price’,用线性回归模型来预测价格
lr = LinearRegression(featuresCol="features", labelCol="price")
# 构建Pipeline
pipeline = Pipeline(stages=[tokenizer, hashingTF, idf, lr])
# 数据集拆分为训练集和测试集
train_data, test_data = data.randomSplit([0.8, 0.2], seed=1234)
# 训练模型
model = pipeline.fit(train_data)
# 在测试集上进行预测
predictions = model.transform(test_data)
# 输出预测结果
predictions.select("product_name", "price", "prediction").show(5)
# 计算预测误差(例如,均方误差)
from pyspark.ml.evaluation import RegressionEvaluator
evaluator = RegressionEvaluator(labelCol="price", predictionCol="prediction", metricName="rmse")
rmse = evaluator.evaluate(predictions)
print(f"Root Mean Squared Error (RMSE) on test data = {rmse}")
# 保存预测结果
predictions.select("product_name", "price", "prediction").write.csv('predictions.csv', header=True)
# 停止Spark会话
spark.stop()
8、结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)