【hadoop+spark原创项目】基于大数据的体脂数据可视化分析系统(包调试运行好)
本文介绍了一个基于大数据的体脂数据可视化分析系统,该系统运用Python、Hadoop、Spark等技术,实现了体脂数据的采集、清洗、分析及可视化功能。系统通过Django和Vue框架搭建前后端,利用Echarts展示健康指标分布、BMI健康评估等可视化图表,帮助用户直观了解健康状况。核心功能包括数据管理、词云生成、多维度健康分析及系统管理。该研究为个人健康管理和行业决策提供了数据支持,具有较高的
🔥作者:雨晨源码🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💕💕文末获取源码
文章目录
本次文章主要是介绍基于大数据的体脂数据可视化分析系统
1、体脂数据可视化分析系统-前言介绍
1.1背景
随着现代生活方式的改变,肥胖、心血管疾病、糖尿病等慢性疾病的发病率不断攀升,健康管理已经成为人们日常生活的重要组成部分。体脂率、BMI(身体质量指数)、腰臀比等体征指标,已成为评估个体健康状况的重要标准。体脂数据作为衡量人体脂肪含量的重要指标,能反映一个人整体的健康状况,尤其是与肥胖、代谢紊乱等疾病的相关性愈加显著。然而,在现代社会中,体脂数据大多数是分散在不同的健康记录中,缺乏一个系统化的分析平台。现有的健康管理工具虽然能够提供个体化数据,但通常缺乏足够的深度分析和数据可视化,不能够精准地为用户提供个性化的健康建议和全面的健康风险评估。因此,如何对大量体脂数据进行科学有效的收集、处理、分析和可视化,帮助用户理解自己的健康状况,并根据数据做出相应的健康决策,成为了亟待解决的核心问题。
1.2课题功能、技术
本课题旨在构建一个基于大数据技术的体脂数据可视化分析系统,系统能够对用户的体脂率、BMI、腰臀比等健康指标进行全面的分析与可视化展示。系统通过大数据技术(Hadoop、Spark、Hive)对体脂数据进行高效存储和实时处理,使用Python进行数据清洗与分析,采用Django框架构建后端,Vue框架负责前端展示。系统的功能模块包括核心指标分布分析、年龄结构体脂分析、BMI健康评估分析、BMI与体脂率一致性分析、腰臀比健康风险分析等。通过这些分析功能,系统不仅能够对体脂数据进行全面的展示,还能深入挖掘数据背后的健康趋势,帮助用户全面了解其健康状况,及时发现潜在的健康风险。此外,Echarts可视化技术能够将复杂的健康数据转化为直观易懂的图表,提供实时的健康状态反馈。
1.3 意义
本课题的研究和开发,不仅为个体用户提供了科学、高效、个性化的健康管理工具,也为医疗、健身、保险等相关行业提供了数据驱动的决策支持。通过对体脂、BMI、腰臀比等指标的深度分析,用户可以更清晰地了解自己的健康状况,及时做出健康调整,降低慢性病的风险。系统的可视化展示功能将复杂的体脂数据转化为易于理解的图表,帮助用户直观地把握自己的健康变化趋势,并为健康管理提供科学的依据。在行业层面,随着健康意识的提高,该系统具有广阔的应用前景,尤其是在健康管理、健身行业、医疗健康咨询等领域具有巨大的市场潜力。通过该系统,用户能够在大数据分析和可视化的支持下,实现更加个性化、精细化的健康管理,从而提高整体的生活质量,推动健康产业的发展与创新。
2、体脂数据可视化分析系统-研究内容
(1)数据采集与清洗:通过爬虫技术或API接口从健身平台和健康管理应用中采集用户体脂、BMI、腰臀比等健康数据。利用Pandas进行数据清洗,处理缺失值、异常值、重复数据,并确保数据格式统一,为后续分析提供干净的输入数据。
(2)大数据处理与分析:采用Hadoop和Spark进行大规模体脂数据的分布式处理。通过Spark进行实时数据分析,挖掘体脂、BMI等健康指标与用户年龄、性别等因素的关联性,使用Hive进行数据仓库管理,支持高效的数据查询和分析。
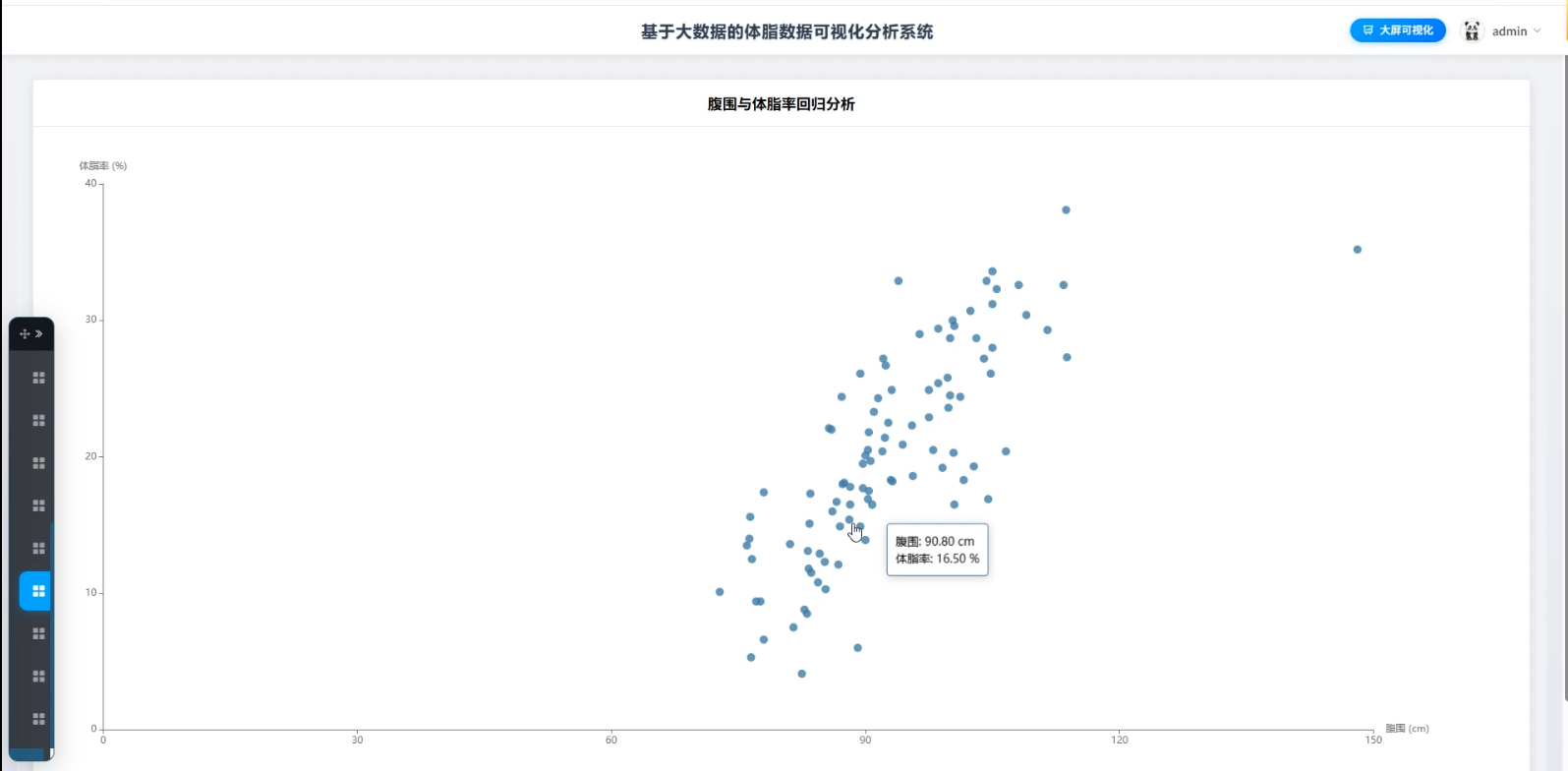
(3)数据可视化:结合Echarts和Vue框架,实现用户体脂、BMI、腰臀比等健康数据的动态可视化展示。通过柱状图、折线图、散点图等方式,清晰地展示各项健康指标的变化趋势,帮助用户直观了解个人健康状况及其风险。
(4)Web框架搭建:使用Django框架构建后端服务,提供用户管理、数据处理、分析结果展示等功能。前端采用Vue框架,通过API接口与后端交互,提供简洁、交互性强的用户界面,实现数据的实时查询与展示。
(5)系统测试:进行功能测试、性能测试和安全测试,确保系统稳定运行。通过模拟高并发场景,测试数据处理速度和响应时间,发现并修复潜在的漏洞,确保用户数据的安全性及系统的高可用性。
3、体脂数据可视化分析系统-开发技术与环境
- 开发语言:Python
- 大数据:Hadoop+Spark+Hive
- 数据处理:pandas
- 后端框架:Django
- 前端:Vue
- 数据库:MySQL
- 算法:K-means算法
- 开发工具:Pycharm
4、体脂数据可视化分析系统-功能介绍
1、数据管理:信息列表展示。
2、词云图:词云图。
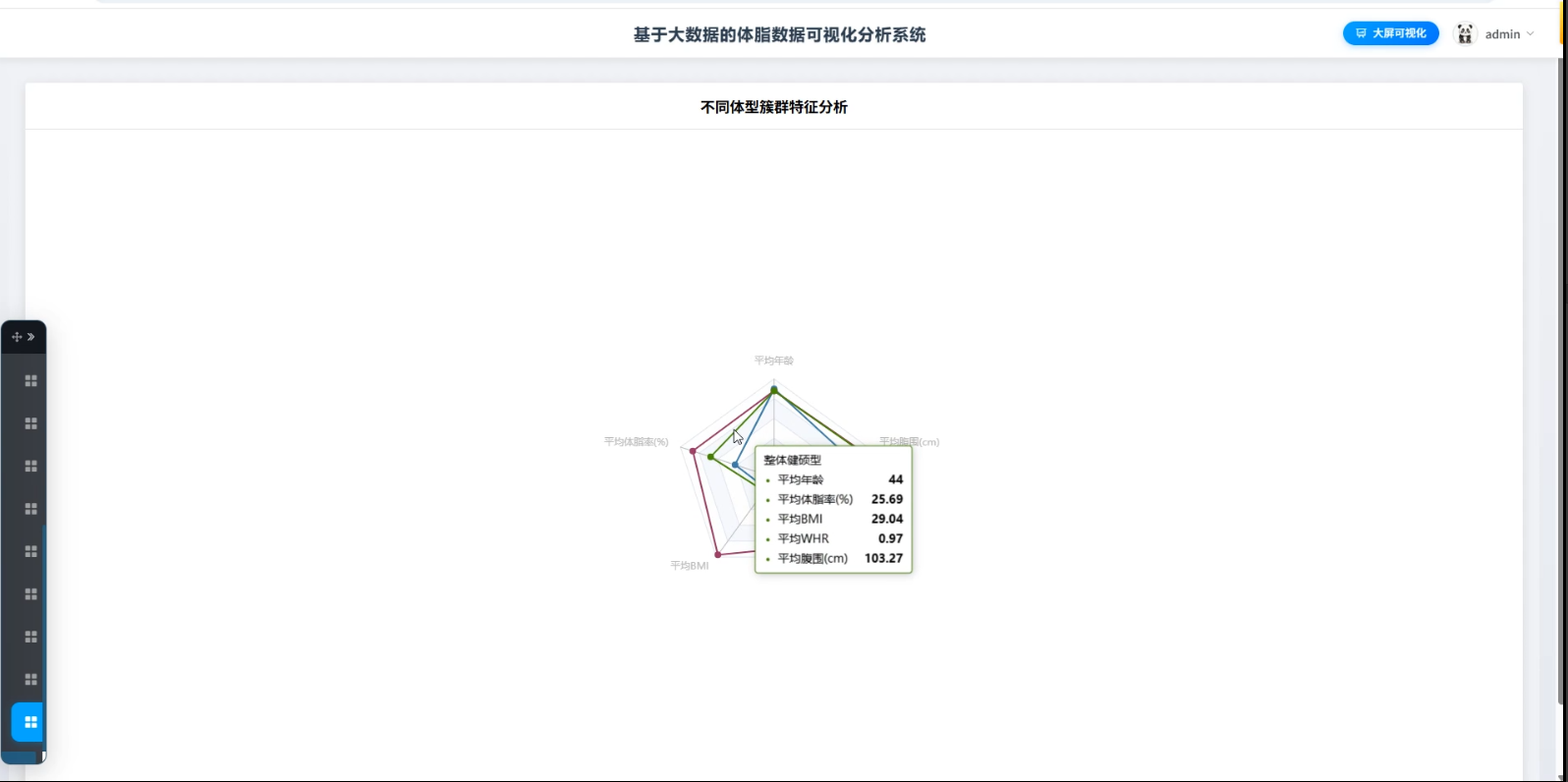
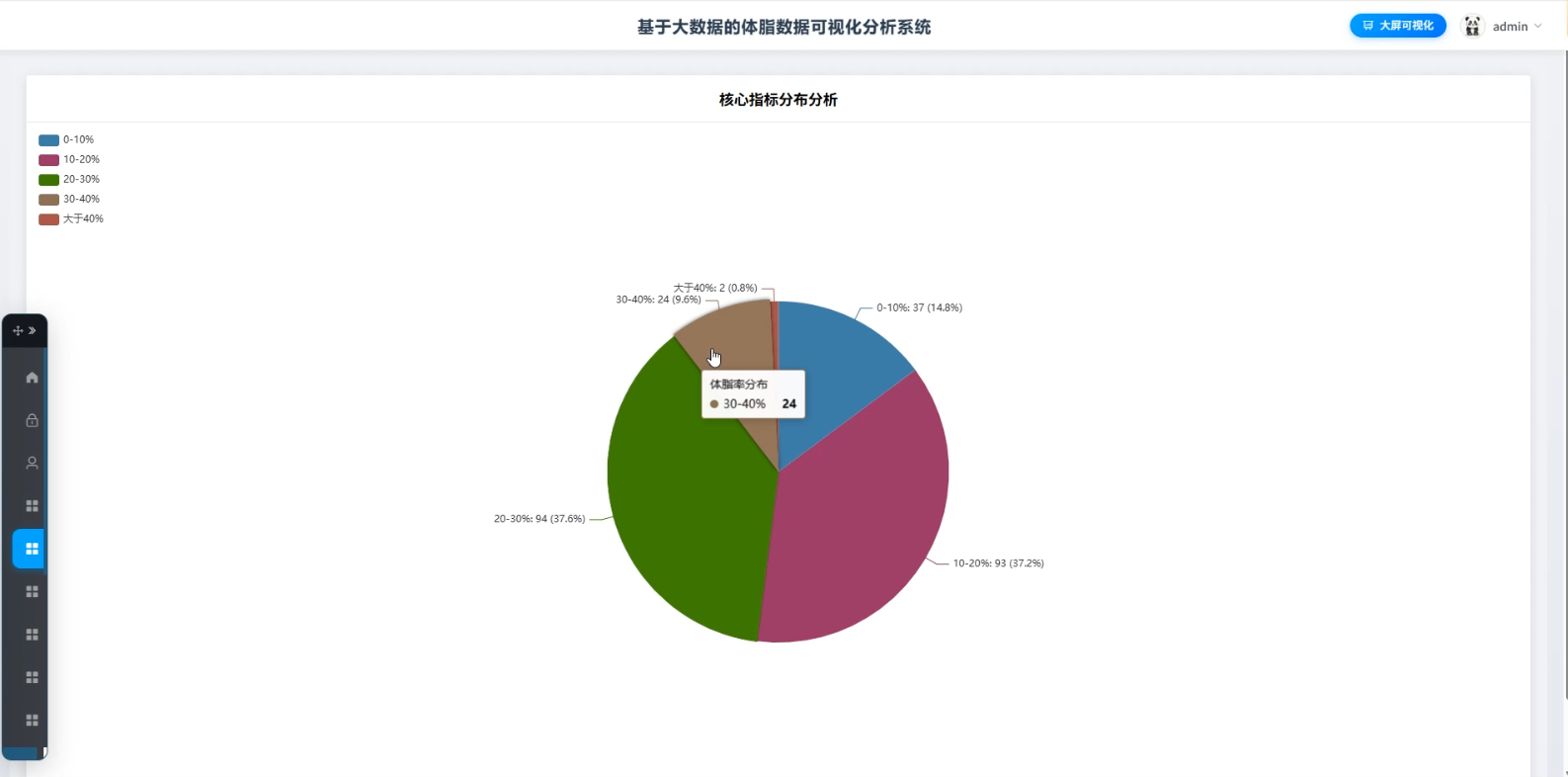
3、可视化分析:核心指标分布分析、年龄结构体脂分析、BMI健康评估分析、BMI与体脂率一致性分析、腰臀比健康风险分析
4、系统管理:登录注册、个人信息修改。
5、体脂数据可视化分析系统-论文参考
6、体脂数据可视化分析系统-成果展示
6.1演示视频
【hadoop+spark原创项目】基于大数据的体脂数据可视化分析系统(包调试运行好)
6.2演示图片
☀️首页☀️
☀️登录☀️
☀️可视化分析☀️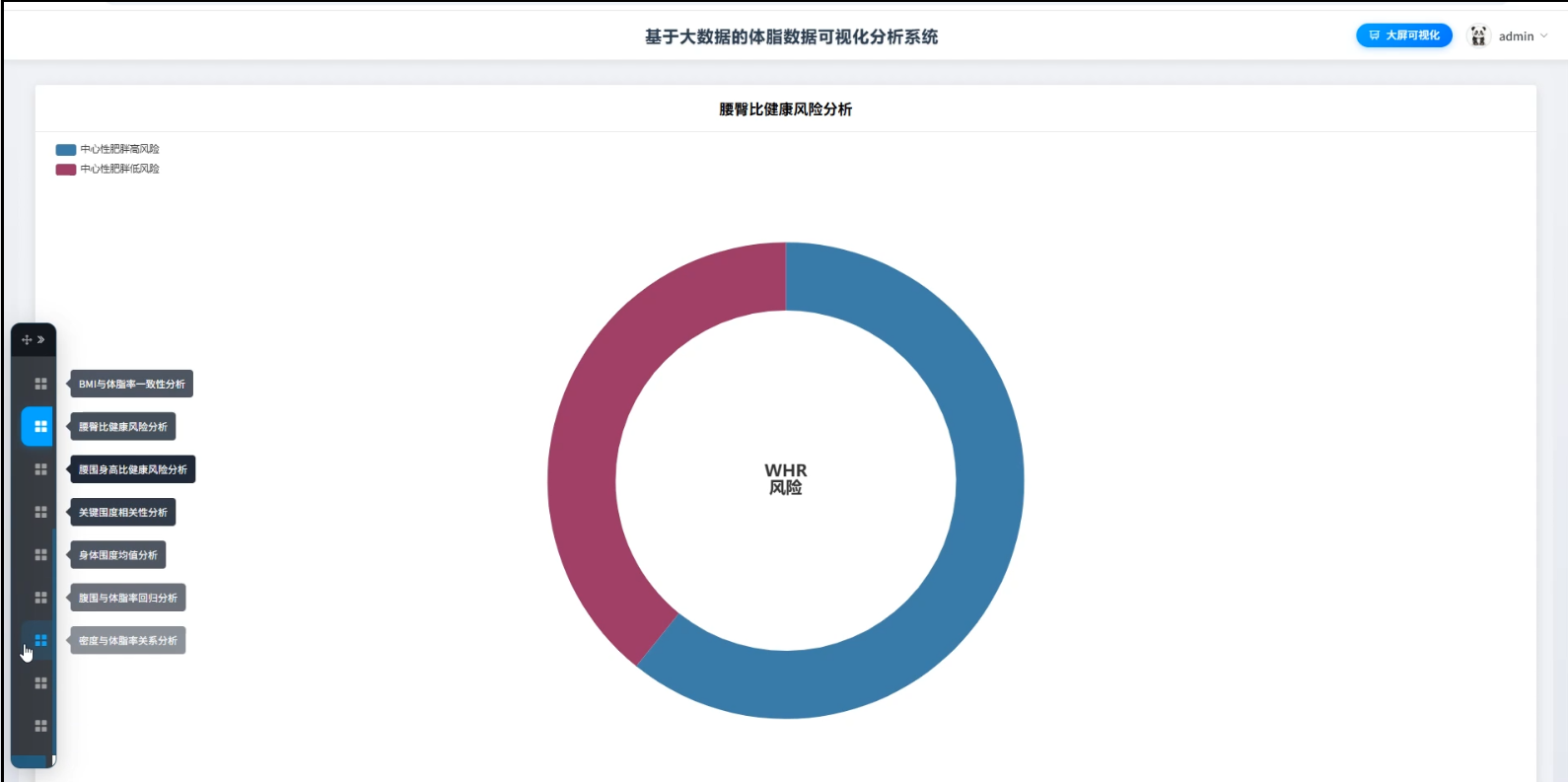
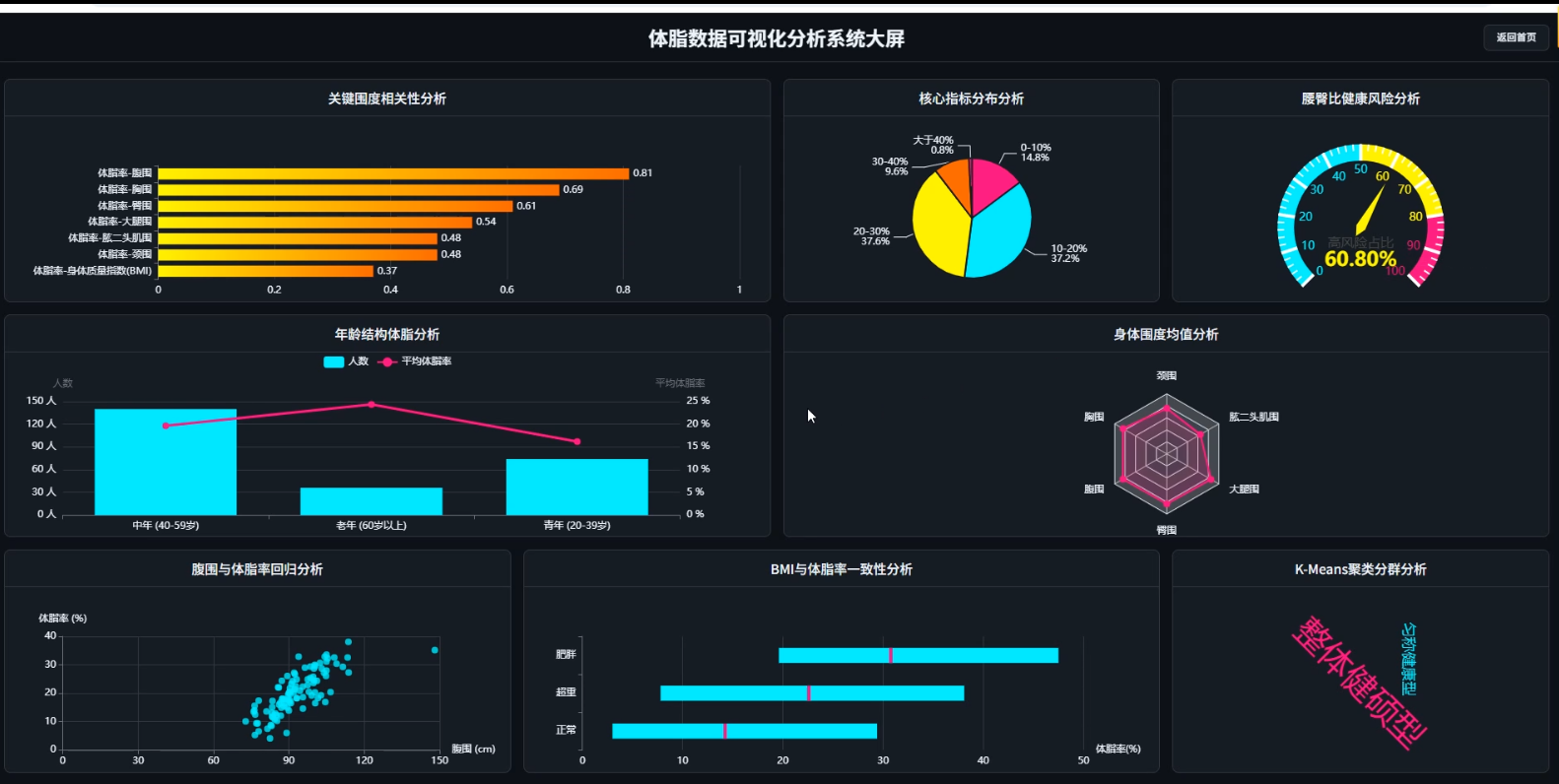
☀️大屏☀️
☀️XX数据管理☀️
7、代码展示
1.数据清洗【代码如下(示例):】
import pandas as pd
import numpy as np
from scipy import stats
# 读取数据
df = pd.read_csv('body_fat_data.csv')
# 1. 删除完全重复的行
df = df.drop_duplicates()
# 2. 处理缺失值:对数值型列用均值填充
df['BMI'] = df['BMI'].fillna(df['BMI'].mean())
df['body_fat'] = df['body_fat'].fillna(df['body_fat'].median()) # 对体脂率用中位数填充
df['waist_hip_ratio'] = df['waist_hip_ratio'].fillna(df['waist_hip_ratio'].mean())
# 3. 处理缺失值:对分类变量用众数填充
df['gender'] = df['gender'].fillna(df['gender'].mode()[0])
# 4. 处理异常值:通过Z-score方法检测并去除异常值
df = df[(np.abs(stats.zscore(df['BMI'])) < 3) & (np.abs(stats.zscore(df['body_fat'])) < 3)]
# 5. 处理日期格式:确保日期列转换为标准日期格式
df['date'] = pd.to_datetime(df['date'], errors='coerce')
# 6. 重命名列名,确保列名一致且易于理解
df.rename(columns={'body_fat': 'body_fat_percentage', 'waist_hip_ratio': 'wh_ratio'}, inplace=True)
# 7. 将数值型特征标准化(均值为0,标准差为1)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df[['BMI', 'body_fat_percentage']] = scaler.fit_transform(df[['BMI', 'body_fat_percentage']])
# 8. 检查数据类型是否符合预期
print(df.dtypes)
# 9. 删除不需要的列(例如,用户ID)
df.drop(columns=['user_id'], inplace=True)
# 10. 输出清洗后的数据
df.to_csv('cleaned_body_fat_data.csv', index=False)
# 输出清洗后的数据的前五行
print(df.head())
2.大数据处理【代码如下( 示例):】
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, sum, count, when
# 初始化Spark会话
spark = SparkSession.builder \
.appName("BodyFatDataAnalysis") \
.getOrCreate()
# 读取CSV文件到Spark DataFrame
df = spark.read.csv('body_fat_data.csv', header=True, inferSchema=True)
# 1. 数据预览,查看前五行数据
df.show(5)
# 2. 删除含有缺失值的行
df_clean = df.na.drop()
# 3. 异常值处理:BMI值小于10或大于50被视为异常,剔除
df_clean = df_clean.filter((col('BMI') > 10) & (col('BMI') < 50))
# 4. 计算每个性别的平均BMI和体脂率
gender_stats = df_clean.groupBy('gender').agg(
avg('BMI').alias('avg_BMI'),
avg('body_fat_percentage').alias('avg_body_fat')
)
# 5. 计算体脂率与BMI的相关性
df_clean = df_clean.withColumn('bmi_vs_fat_ratio', col('BMI') / col('body_fat_percentage'))
df_clean.createOrReplaceTempView("df_view")
correlation_result = spark.sql("""
SELECT corr(BMI, body_fat_percentage) as correlation_bmi_fat
FROM df_view
""")
# 6. 按年龄段分析体脂率与BMI的关系
df_clean = df_clean.withColumn(
'age_group',
when(col('age') < 20, 'Under 20')
.when((col('age') >= 20) & (col('age') < 30), '20-29')
.when((col('age') >= 30) & (col('age') < 40), '30-39')
.when((col('age') >= 40) & (col('age') < 50), '40-49')
.otherwise('50+')
)
age_group_stats = df_clean.groupBy('age_group').agg(
avg('BMI').alias('avg_BMI'),
avg('body_fat_percentage').alias('avg_body_fat')
)
# 7. 按性别和年龄组进行分组分析
age_gender_stats = df_clean.groupBy('gender', 'age_group').agg(
avg('BMI').alias('avg_BMI'),
avg('body_fat_percentage').alias('avg_body_fat')
)
# 8. 将分析结果保存到HDFS或本地文件
age_gender_stats.write.csv('age_gender_body_fat_analysis.csv', header=True)
gender_stats.write.csv('gender_body_fat_stats.csv', header=True)
# 9. 输出相关性分析结果
correlation_result.show()
# 停止Spark会话
spark.stop()
8、结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 39
39 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)