变分推断:从理论推导到数据可视化
变分推断(Variational Inference, VI)理论涉及贝叶斯公式中先验、似然、证据及后验等组成部分的变换与计算。掌握基础的概率知识,基本能跟随推导过程,得到变分推断的优化目标函数:Evidence Lower Bound(ELBO)。但是由于缺乏数值计算层面上的直观认识,推导过程中的逻辑关系难以定性理解,如:后验概率常被冠以难以解决的(intractable)标签,而变分推断的优化目标ELBO中的概率项又都默认为可解决的(tractable)。这些理解缺失严重阻碍对于变分推断的灵活应用甚至变革创新。本文尝试通过设计简单实验,建立概率推导与数值实验之间的联系,帮助填补上述理论与直觉的鸿沟。
一、贝叶斯推断(Bayesian Inference)
贝叶斯推断是机器学习的一个分支,利用概率分布和贝叶斯定理对真实世界的不确定性进行描述并做出预测。其对先验概率的主观判断,以及利用观测值对先验概率进行迭代更新的过程,突出了模型的“可解释性”。其中“可解释性”也包含对于主观判断的偏差引起的模型及推错误的诠释。贝叶斯推断后验概率分布的求解过程,天然包含了随机变量预测的不确定性量化。
与之对应,深度学习是机器学习的另一个分支,从数据中自动提取特征和模式。通过复杂的非线性变换和梯度下降,学习一个从输入到输出的庞大的参数化函数,强调模型的表达能力。然而其模型参数的工作机制是一个“黑箱”,无论预测结果正确与否,都无法追溯其逻辑的源头。对于预测结果不确定性的量化,深度学习往往利用频率学派方法,通过多折交叉验证统计获得。
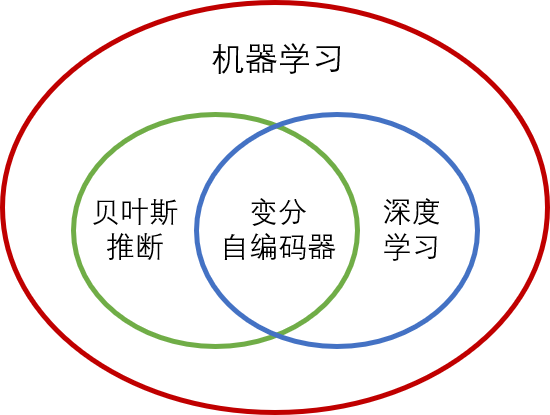
贝叶斯推断的缺点是可扩展性差(Scalability),对于大规模数据运算非常慢。变分推断是解决上述扩展性差问题的一种数值方法,也是目前贝叶斯推断领域重点研究方向之一。变分自编码器(Variational Autoencoder, VAE)的发明,利用深度学习的函数拟合能力学习变分推断中拟合分布,将机器学习的两个分支联系到了一起。从这个角度,贝叶斯推断在机器学习中的定位如下图所示。
二、问题描述
已知数据样本是由一个2-模态的混合高斯模型生成,即根据采样点所属模态,
,采样点模态
符合参数为
的伯努利分布,
。给定采样点
,估计模型参数。
令代表模型参数。
为随机变量,其中
为不可观测到的,称为隐藏变量(Latent variable)。
频率学派认为模型参数是未知且确定的,通过构造并最大化对数似然函数(Log Likelihood, ll),对模型参数进行点估计:
贝叶斯学派与之不同,将模型参数看做具有一定分布的随机变量,与隐藏变量同等分析,模型学习(Model learning)也与变量推断(Variable inference)统一起来。参数估计演变为基于先验分布
及观测证据
的参数后验分布估计问题,即我们所熟悉的贝叶斯公式:
将作为隐藏变量一部分呢,统一用
代表,公式(2.3)重新回到贝叶斯公式的最简单形式,同时具有更加丰富内涵:
基于以上模型,我们可以回答两类预测问题:
问题1:(边际概率,Marginal)计算随机变量取某一特定值的概率
。如:图像生成应用中,对目标空间的图像进行采样,获得新的图片。
问题2:(最大后验,MAP)给定一个观察值,计算最大可能的隐藏变量赋值。如:模型参数估计;基于病人影像、实验室检验、病史等检测结果,判断肿瘤的良恶性。
贝叶斯推断的可解决性(tractability)分析的重要前提为联合概率密度分布对任何具体参数实现
容易计算其概率密度。因为根据条件概率公式,这个联合概率密度为似然值
与先验值
的乘积,而这两个概率成分是模型的输入,具有可解析的概率密度计算公式。
如在单变量高斯模型中,可观测变量,
为唯一隐藏变量,其先验为均值为0,方差为
的高斯分布:
。则
。可方便对任意
组合求解。
贝叶斯推断的难点来自于公式(2.5)分母中求解边缘概率的计算。根据全概率公式:
大多数情况下,隐藏随机变量是连续空间的高维向量,公式(2.6)中针对隐藏变量的积分大多是情况下是不能解决的(intractable),是贝叶斯推断“不可解决性”论断的来源。
贝叶斯推断的数值方法核心可以总结为:避免求解边缘概率,具体方法分为两种:采样(Markov Chain Monte Carlo, MCMC)与变分推断(Variational Inference, VI)。
下面借助单模态、单变量高斯模型实验,理解两种数值求解方法。
三、单模态单变量高斯模型实验
3.1、数据模拟
利用Python pymc概率编程模块建模。假设由单变量高斯分布采样得到数据样本
。高斯分布的参数
为待推断隐藏变量。
import numpy as np
import scipy.stats as stats
mu0, sd0 = 10, 3 # 待求解的隐变量
nb_samples = 1000
# 模拟生成1000个采样点
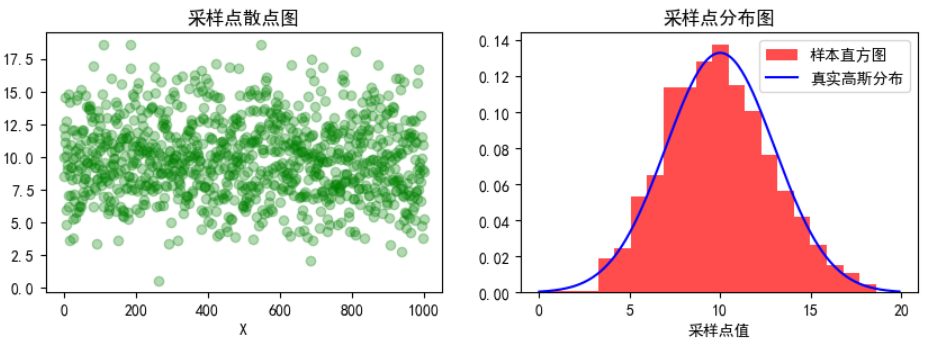
X = np.random.normal(loc=mu0, scale=sd0, size=nb_samples)模拟采样点散点图及其分布在如下图所示。
3.2、数据建模
为隐变量,对其先验分布没有特殊偏好,所以令
,其中
代表半正态分布,由于方差只能取正数,
在贝叶斯建模常用作方差参数的弱信息先验。
根据贝叶斯公式:
对应pymc代码如下:
with pm.Model() as simple_model:
mu = pm.Normal('mu', mu=0, sigma=10)
sd = pm.HalfNormal('sd', sigma=10)
# 通过observed参数将样本传入模型
likelihood = pm.Normal('obs', mu=mu, sigma=sd, observed=X)3.3、贝叶斯推断
概率推断的目的是找到隐藏变量(此处等同于高斯分布模型参数)在观测数据
条件下的后验概率,即公式(3.1)。根据前面分析,公式(3.1)求解难点在于分母的每一个样本点取值的边际概率(针对这个简单例子,
可直接解析,即:
,但此处仅为简化示例,认为真实情况下其不可解决)。
3.3.1、蒙特卡洛采样
蒙特卡洛方法,基于公式(3.2),直接对后验分布进行采样,根据贝叶斯公式分子的可解析性,并通过比较样本间的相对概率,构建Markov采样链,使得采样点大概率地落到后验分布概率密度高的地方,同时保障概率密度低的位置有机会采到样本。最终采样结果通过直方图分析得到后验概率。从而有效避开不可解决的
边际概率。
pymc库中具体的蒙特卡洛算法全称为马尔科夫链蒙特卡洛(MCMC)。以下代码完成蒙特卡洛采样(采样2000个点),并绘制隐变量后验分布采样结果及分布:
with simple_model:
trace = pm.sample(draws=2000, tune=1000) 采样结果存在于中,考察其中后验采样结果:
print(trace.posterior.mu.shape)
print(trace.posterior.sd.shape)
# 输出:
(4, 2000)
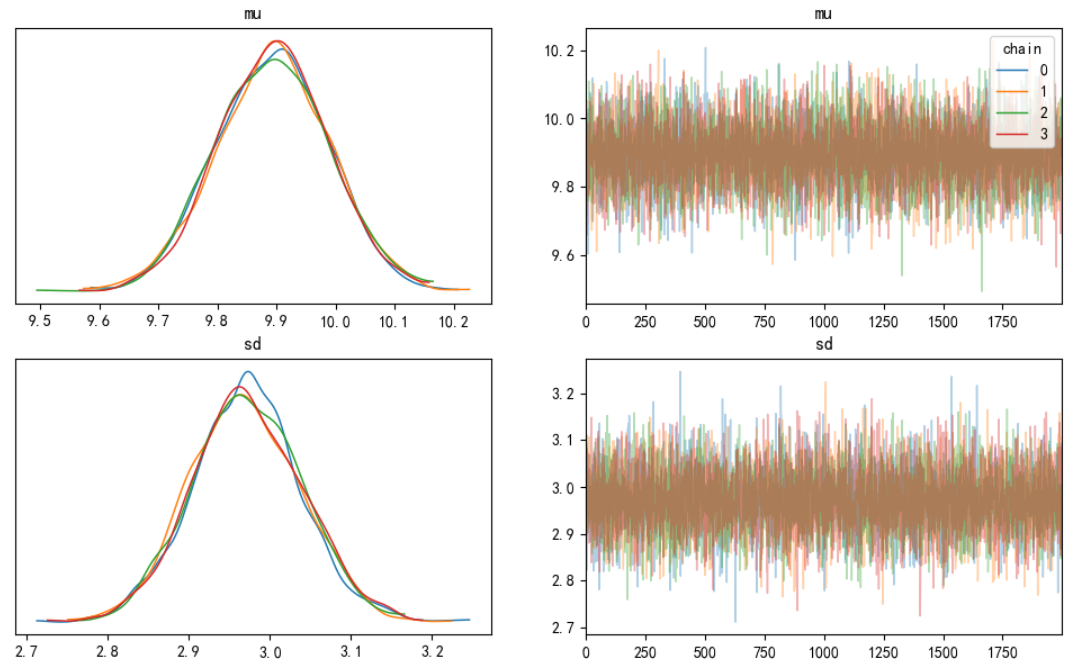
(4, 2000) 得到两个形状均为(4, 2000)的numpy数组。第一维度4代表蒙特卡洛采样默认启动4个采样马尔科夫链,分别从不同的初始点开始采样,每个线程采集参数(draws)指定的2000个样本。绘制结果如下图所示。图中右侧为隐藏变量采样散点图,四种颜色分别代表4个采样链条。左侧为采样点直方图拟合曲线。可以看到四个采样链条都收敛到同一个后验分布,而分布的均值接近正态分布的真实参数
。
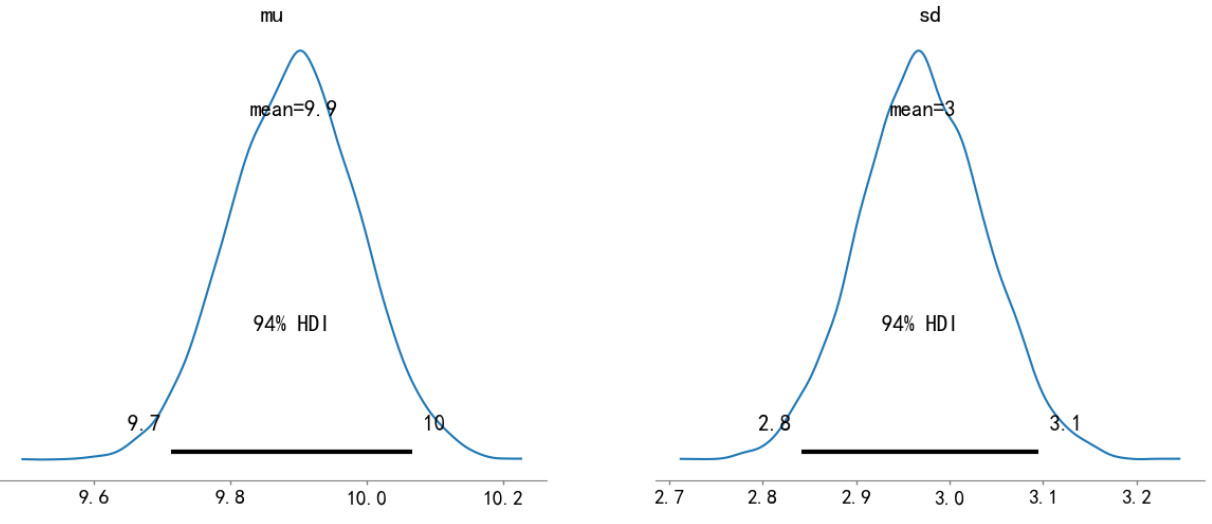
下图为隐变量采样链条平均后验分布,参数的均值都与隐变量真实值吻合,高密度区间(High Density Interval, HDI)为包含94\%概率质量的参数估计区间。对于未知变量的不确定性量化是贝叶斯推断的最大优势之一,而HDI区间会随着样本量的增加而变窄。
蒙特卡洛采样方法具有思路简洁,结果精准的特定。针对概率推断问题,只需未知随机变量进行贝叶斯建模,其他交给采样算法即可。但是当采样空间维度升高时,蒙特卡洛方法会变得非常慢,阻碍其在实际问题中的适用。
3.3.2、变分推断
让我们重新审视需要求解的目标后验分布:
我们希望得到隐变量的后验分布
,同时等式右侧分母的
求解需要对变量
进行积分,是不可解决的。
变分推断的思路为找到一个简单的、可方便采样及解析的分布来逼近
,从而达到求解随机变量
后验分布的效果,并可应用于下游的应用。而对于概率分布
与
,其相似性用
散度来量化。目标是找到一个简单的分布
,使得
散度最小。
公式(3.3)中随机变量与
分布无关,所以可以提到期望求解外面。
根据公式(3.3),最小化散度等同于最大化
。同时我们观察到式
中只包含联合概率密度及简单的概率分布q,所以针对每一个
可方便解析随机变量
的概率密度值。将其作为优化对象,是可解决的。
同时由于散度恒为非负值,所以
永远小于
。二者相等只有在
时,即
散度为0时成立。我们的优化对象可视为
的下界,由于
在贝叶斯公式中被称为对数证据(Log Evidence),优化对象也称作证据下界(Evidence Lower Bound, ELBO):
以为优化目标函数,拟合可解析的分布
参数,使其接近实际后验分布
,用于概率推断。由于拟合的对象为概率密度函数,这种贝叶斯推断方法被称为变分推断(Variational Inference, VI)。
利用pymc中对于变分推断的实现,重新求解章节(3.1)中关于单变量高斯分布参数后验分布推断问题。
with simple_model:
approx = pm.fit(n=30000, method='advi') 延用同样的章节(3.2)中建模方式,不同于蒙特卡洛采样方法,这里调用拟合方法,拟合目标分布函数族
,拟合过程中损失
参数及最终分布参数存储于
变量中。下图显示优化过程中
收敛情况。pymc优化目标位
,所以随着迭代增加,数值越来越小。
plt.plot(approx.hist)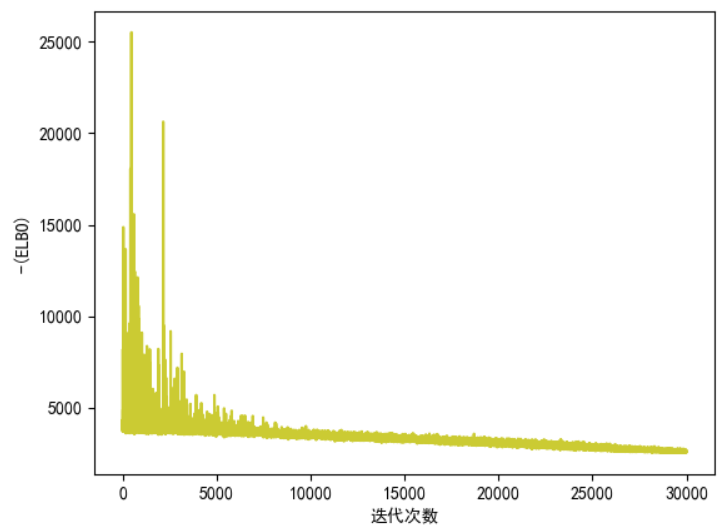
pymc变分推断使用平均场假设,即使用协方差为0的多元高斯分布拟合。以下代码打印拟合的高斯分布参数。可以看到拟合的后验分布高斯参数
的均值分别为
与真实分布
接近。以下代码的第二行输出为
各自后验方差。
print(approx.mean.eval())
print(approx.std.eval())
# 输出
[8.85644685 1.17206178]
[0.37829601 0.02744696] 拟合好后验分布后,可以使用同样方法,对后验采样(在
上采样,性能更加好),得到隐变量
的推断。以下代码对拟合后验分布采样1000个点,并打印采样结果尺寸。
# 在拟合后验分布上采样1000个点
samples = approx.sample(1000)
print(samples.posterior.mu.shape)
print(samples.posterior.sd.shape)
# 输出:
(1, 1000)
(1, 1000)对以上采样结果绘制,如下图,可以看到变分推断拟合的后验概率均值与方差。
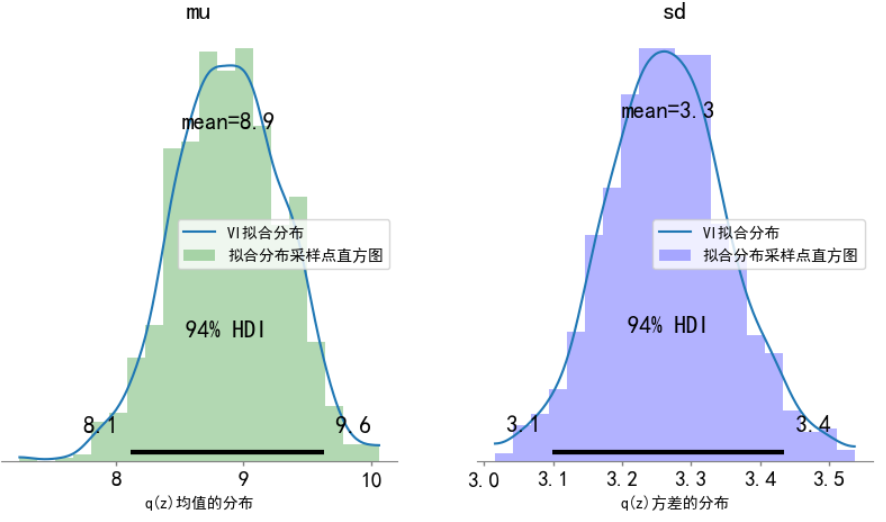
四、总结
本文利用pymc编程,结合单变量高斯分布简单例子,将贝叶斯推断中通过采样与变分两种方法求解后验的过程进行了数据可视化,辅助理解贝叶斯理论的本质。
但是真实数据、真是模型往往非常复杂。比如章节(2)中的双模态高斯混合模型,隐变量中除了两个高斯分布的参数,还多了一个样本状态随机变量,确定采样点来自于哪个高斯分布,在双模态情况下符合一个伯努利分布
。而伯努利分布属于离散分布,pymc中不能用梯度下降法求解其变分分布。所以虽然变分推断ELBO目标函数方便求解其每一个样本的联合概率密度,但是其对
的参数优化还是非常复杂。在后续文章中会展示双模态高斯分布的变分拟合推导过程。此时变分自编码器出现了,深度学习由于其强大的函数拟合能力,非常高效地解决了这个问题。
归纳一下以上的演化过程:
贝叶斯公式:“忽闻海上有仙山,山在虚无缥缈间。”
(可以完美描述不确定的世界,求解是不可解决的。)
蒙特卡洛采样:“君在阴兮影不见,愿为影兮随君身。”
(避免求解边际概率,可完整描绘后验概率)
变分推断:“牡丹花好空入目,天涯何处无芳草。”
(精准描绘的采样方法太慢,用一个简单的概率模型将就一下也很好。)
Mean field方法:“苔痕上阶绿,草色入帘青。”
(进一步简化概率模型,统一用高斯分布,随机变量之间认为相互独立。)
变分自编码器:“此间乐,不思蜀也。”
(深度学习一个神经网络可以拟合世界,原来的方法已经回不去了。)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)