【完整源码+数据集+部署教程】道路缺陷分割系统源码&数据集分享 [yolov8-seg-EfficientRepBiPAN&yolov8-seg-AFPN-P345等50+全套改进创新点发刊_一键训
背景意义
随着城市化进程的加快,交通基础设施的建设与维护显得尤为重要。道路作为城市交通的主要枢纽,其质量直接影响到交通安全与通行效率。然而,随着时间的推移,路面由于自然因素和交通荷载的影响,往往会出现各种缺陷,如裂缝、坑洞、间隙等。这些道路缺陷不仅影响了车辆的行驶安全,还可能导致交通事故的发生,给社会带来巨大的经济损失。因此,及时、准确地检测和分割道路缺陷,成为了道路维护管理中的一项重要任务。
近年来,深度学习技术的迅猛发展为计算机视觉领域带来了革命性的变化,尤其是在图像分割任务中表现出色。YOLO(You Only Look Once)系列模型以其高效的实时检测能力和良好的准确性,逐渐成为目标检测和分割任务中的主流选择。YOLOv8作为该系列的最新版本,进一步提升了模型的性能,适应了更复杂的应用场景。然而,现有的YOLOv8模型在道路缺陷分割任务中的应用仍存在一定的局限性,特别是在对细小缺陷的识别和分割精度方面。因此,基于改进YOLOv8的道路缺陷分割系统的研究具有重要的现实意义。
本研究将利用gapDet数据集,该数据集包含2400张图像,涵盖了五类道路缺陷,包括沥青、裂缝、间隙、物体和坑洞。这些类别的细分不仅有助于提高模型的分类精度,也为后续的道路维护提供了更加细致的数据支持。通过对这些缺陷进行有效的分割和识别,能够为道路管理部门提供实时的监测数据,帮助其制定科学合理的维护计划,降低道路事故的发生率,提高交通安全。
此外,研究中将对YOLOv8模型进行改进,针对道路缺陷的特征进行优化,以提高模型在分割任务中的表现。通过引入多尺度特征融合、注意力机制等先进技术,期望能够增强模型对细小缺陷的敏感性和分割精度。这不仅有助于提升模型的性能,也为相关领域的研究提供了新的思路和方法。
综上所述,基于改进YOLOv8的道路缺陷分割系统的研究,不仅能够为道路维护提供有效的技术支持,还能推动计算机视觉技术在实际应用中的发展。通过实现高效、准确的道路缺陷检测与分割,能够为提升城市交通基础设施的安全性和可靠性做出积极贡献。此项研究的开展,必将为道路管理的智能化、精细化提供有力的支撑,具有重要的学术价值和应用前景。
图片效果
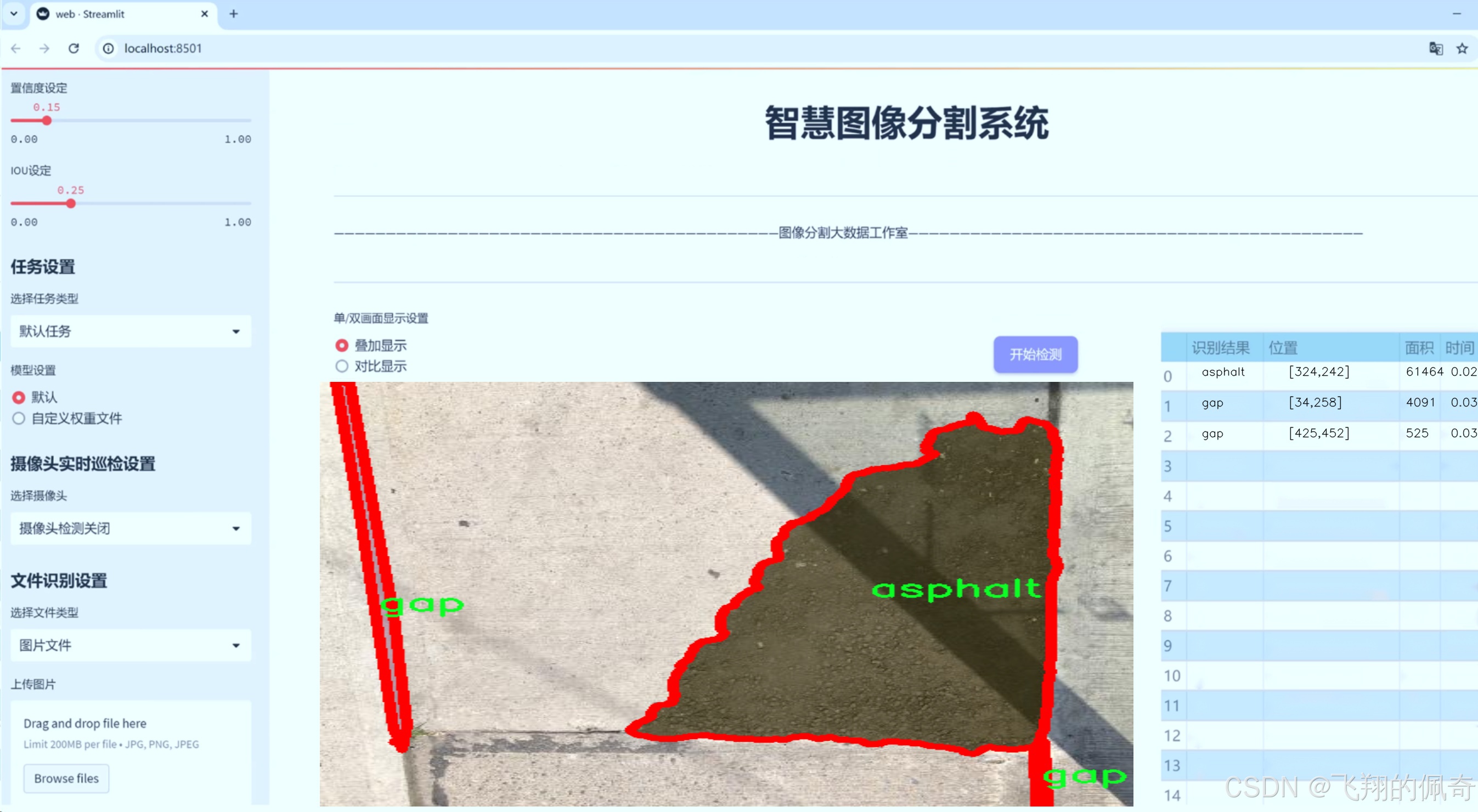
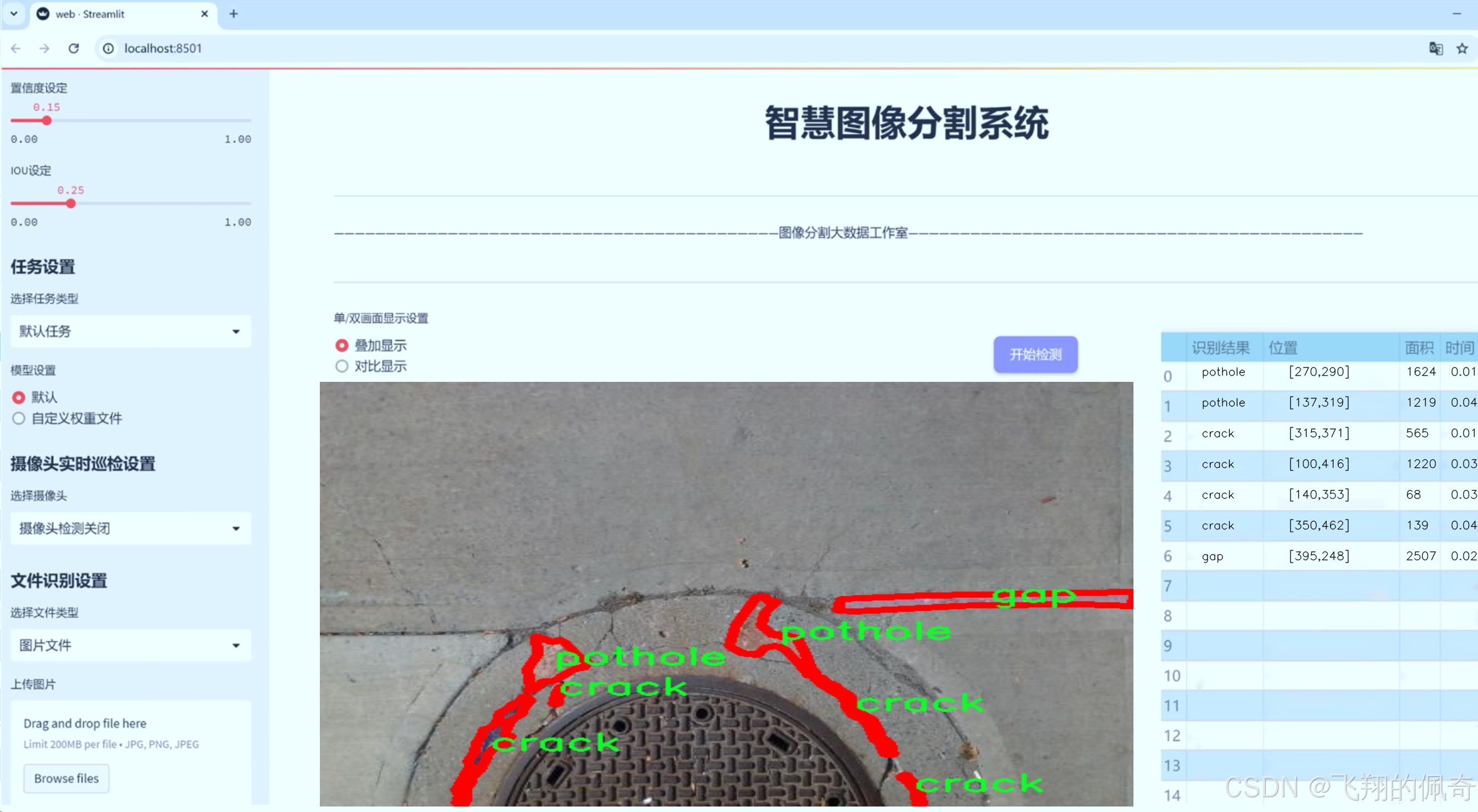
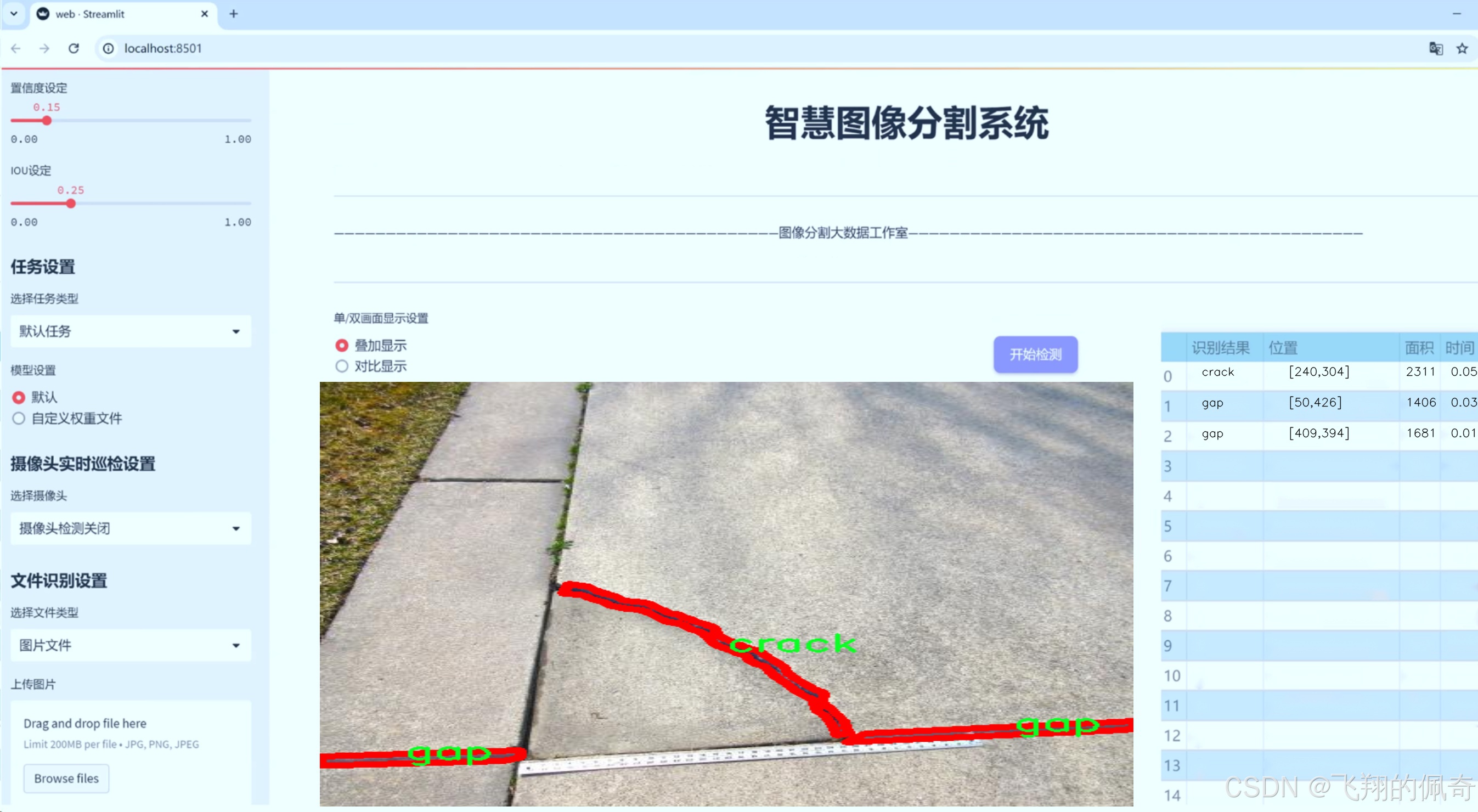
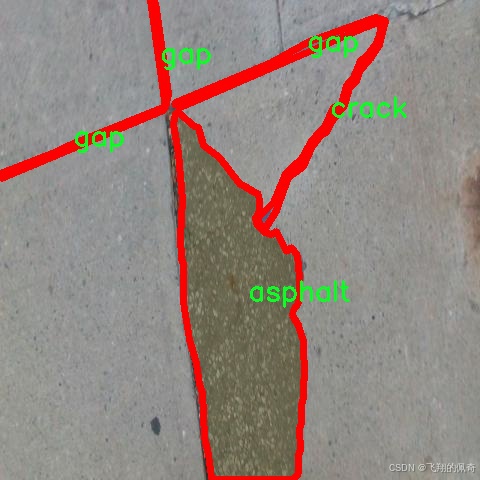
数据集信息
在现代道路维护与管理中,准确识别和分类道路缺陷是确保交通安全和延长道路使用寿命的关键。为此,本研究选用了名为“gapDet”的数据集,以支持改进YOLOv8-seg的道路缺陷分割系统。该数据集专注于道路表面的不同缺陷,提供了丰富的标注信息,旨在为深度学习模型的训练提供高质量的数据支持。
“gapDet”数据集包含四个主要类别,分别是“asphalt”(沥青)、“crack”(裂缝)、“gap”(缝隙)和“pothole”(坑洞)。这些类别涵盖了道路表面常见的缺陷类型,每种缺陷都可能对行车安全造成不同程度的影响。例如,沥青的质量直接关系到道路的平整度和耐用性,而裂缝和缝隙则可能导致车辆的颠簸和损坏,坑洞则是最为严重的缺陷,可能引发交通事故。因此,准确地识别和分类这些缺陷,对于及时维护和修复道路至关重要。
在数据集的构建过程中,研究团队采用了多种数据采集技术,包括高分辨率摄像头和激光扫描设备,以确保捕捉到的图像具有足够的清晰度和细节。这些图像经过精心标注,确保每个缺陷类别都能被准确识别。数据集中的每一张图像都配有相应的标注文件,详细记录了缺陷的类别、位置和尺寸等信息。这种精细的标注方式为YOLOv8-seg模型的训练提供了坚实的基础,使其能够在实际应用中实现高效的缺陷检测与分割。
“gapDet”数据集的设计不仅考虑了缺陷的多样性,还兼顾了不同环境和光照条件下的图像采集。这意味着数据集中包含了在不同天气、时间和路况下拍摄的图像,从而增强了模型的泛化能力。通过这样的多样性,YOLOv8-seg模型能够更好地适应实际应用场景,提高道路缺陷检测的准确性和鲁棒性。
此外,数据集的使用还可以促进相关领域的研究与发展。随着智能交通系统的不断进步,如何利用深度学习技术实现自动化的道路维护和管理,已成为一个重要的研究方向。通过对“gapDet”数据集的深入分析和应用,研究人员可以探索更为先进的算法和模型,推动道路缺陷检测技术的创新与进步。
总之,“gapDet”数据集为改进YOLOv8-seg的道路缺陷分割系统提供了丰富的训练素材和坚实的理论基础。其涵盖的四个类别不仅反映了道路缺陷的多样性,也为模型的训练和评估提供了全面的视角。通过充分利用这一数据集,研究团队期望能够实现更高效、更准确的道路缺陷检测,进而为道路安全和维护管理提供有力支持。



核心代码
```python
# --------------------------------------------------------
# InternImage
# Copyright (c) 2022 OpenGVLab
# Licensed under The MIT License [see LICENSE for details]
# --------------------------------------------------------
import os
import glob
import torch
from torch.utils.cpp_extension import CUDA_HOME, CppExtension, CUDAExtension
from setuptools import find_packages, setup
# 定义所需的Python包
requirements = ["torch", "torchvision"]
def get_extensions():
# 获取当前文件目录
this_dir = os.path.dirname(os.path.abspath(__file__))
# 定义扩展源代码目录
extensions_dir = os.path.join(this_dir, "src")
# 查找主C++文件和CPU/CUDA源文件
main_file = glob.glob(os.path.join(extensions_dir, "*.cpp"))
source_cpu = glob.glob(os.path.join(extensions_dir, "cpu", "*.cpp"))
source_cuda = glob.glob(os.path.join(extensions_dir, "cuda", "*.cu"))
# 将主文件和CPU源文件合并
sources = main_file + source_cpu
extension = CppExtension # 默认使用C++扩展
extra_compile_args = {"cxx": []} # 额外编译参数
define_macros = [] # 定义宏
# 检查CUDA是否可用
if torch.cuda.is_available() and CUDA_HOME is not None:
extension = CUDAExtension # 使用CUDA扩展
sources += source_cuda # 添加CUDA源文件
define_macros += [("WITH_CUDA", None)] # 定义CUDA宏
extra_compile_args["nvcc"] = [] # 可以添加CUDA编译参数
else:
raise NotImplementedError('Cuda is not available') # 如果CUDA不可用,抛出异常
# 生成完整的源文件路径
sources = [os.path.join(extensions_dir, s) for s in sources]
include_dirs = [extensions_dir] # 包含目录
# 创建扩展模块
ext_modules = [
extension(
"DCNv3", # 扩展模块名称
sources, # 源文件列表
include_dirs=include_dirs, # 包含目录
define_macros=define_macros, # 定义的宏
extra_compile_args=extra_compile_args, # 额外编译参数
)
]
return ext_modules # 返回扩展模块列表
# 设置包信息
setup(
name="DCNv3", # 包名称
version="1.1", # 包版本
author="InternImage", # 作者
url="https://github.com/OpenGVLab/InternImage", # 项目链接
description="PyTorch Wrapper for CUDA Functions of DCNv3", # 描述
packages=find_packages(exclude=("configs", "tests")), # 查找包,排除特定目录
ext_modules=get_extensions(), # 获取扩展模块
cmdclass={"build_ext": torch.utils.cpp_extension.BuildExtension}, # 自定义构建扩展命令
)
代码分析与注释
-
导入必要的库:
os和glob用于文件和目录操作。torch是PyTorch库,提供深度学习功能。torch.utils.cpp_extension提供C++和CUDA扩展的支持。setuptools用于打包和分发Python项目。
-
get_extensions函数:- 该函数负责查找源代码文件并构建PyTorch的C++/CUDA扩展。
- 使用
glob模块查找指定目录下的所有C++和CUDA源文件。 - 根据CUDA的可用性选择使用
CppExtension或CUDAExtension。 - 生成扩展模块所需的所有参数,并返回扩展模块列表。
-
setup函数:- 该函数定义了包的元数据和构建信息。
- 包括名称、版本、作者、描述、需要的包、扩展模块等信息。
这个代码主要用于构建一个PyTorch的扩展模块,允许用户在PyTorch中使用自定义的CUDA功能。```
这个 setup.py 文件是用于配置和构建一个名为 DCNv3 的 Python 扩展模块,主要是为 PyTorch 提供 CUDA 函数的封装。文件的开头包含了一些版权信息和许可证声明,表明该代码的版权归 OpenGVLab 所有,并且遵循 MIT 许可证。
首先,文件导入了一些必要的模块,包括 os 和 glob 用于文件路径处理,torch 用于深度学习框架的功能,setuptools 用于打包和分发 Python 包。此外,还从 torch.utils.cpp_extension 导入了 CUDA_HOME、CppExtension 和 CUDAExtension,这些是用于编译 C++ 和 CUDA 扩展的工具。
接下来,定义了一个 requirements 列表,列出了该模块所依赖的 Python 包,这里包括 torch 和 torchvision。
函数 get_extensions() 的主要功能是收集需要编译的源文件并配置扩展模块。首先,它获取当前文件的目录,并构建出包含源文件的路径。然后,通过 glob 模块查找主文件、CPU 和 CUDA 源文件,分别存储在 main_file、source_cpu 和 source_cuda 列表中。
在构建源文件列表时,默认使用 CppExtension,并初始化一些编译参数和宏定义。如果检测到 CUDA 可用,且 CUDA_HOME 不为 None,则切换到使用 CUDAExtension,并将 CUDA 源文件添加到源文件列表中,同时定义了一个宏 WITH_CUDA。如果 CUDA 不可用,则抛出一个 NotImplementedError,提示用户 CUDA 不可用。
所有的源文件路径都被转换为绝对路径,并设置了包含目录。最后,创建了一个扩展模块的列表 ext_modules,其中包含了模块的名称、源文件、包含目录、宏定义和编译参数。
在文件的最后,调用 setup() 函数来配置包的元数据,包括包的名称、版本、作者、项目网址、描述信息,以及要排除的包(如 configs 和 tests)。同时,将通过 get_extensions() 函数获取的扩展模块传递给 ext_modules 参数,并指定 cmdclass 为 torch.utils.cpp_extension.BuildExtension,以便在构建时使用 PyTorch 的扩展构建工具。
总的来说,这个 setup.py 文件是一个典型的用于构建 PyTorch C++/CUDA 扩展的配置文件,旨在提供高效的深度学习功能。
```以下是经过简化和注释的核心代码部分,主要集中在 Bboxes 和 Instances 类的实现上:
import numpy as np
class Bboxes:
"""
处理边界框的类,支持多种格式('xyxy', 'xywh', 'ltwh')。
"""
def __init__(self, bboxes, format='xyxy') -> None:
"""初始化 Bboxes 类,接收边界框数据和格式。"""
# 确保格式有效
assert format in ['xyxy', 'xywh', 'ltwh'], f'无效的边界框格式: {format}'
# 将一维数组转换为二维数组
bboxes = bboxes[None, :] if bboxes.ndim == 1 else bboxes
assert bboxes.ndim == 2 and bboxes.shape[1] == 4 # 确保是二维且每个框有4个坐标
self.bboxes = bboxes # 存储边界框
self.format = format # 存储格式
def convert(self, format):
"""转换边界框格式。"""
assert format in ['xyxy', 'xywh', 'ltwh'], f'无效的边界框格式: {format}'
if self.format == format:
return # 如果格式相同,则不需要转换
# 根据当前格式和目标格式选择转换函数
func = self._get_conversion_function(format)
self.bboxes = func(self.bboxes) # 执行转换
self.format = format # 更新格式
def _get_conversion_function(self, format):
"""根据当前格式和目标格式返回相应的转换函数。"""
if self.format == 'xyxy':
return xyxy2xywh if format == 'xywh' else xyxy2ltwh
elif self.format == 'xywh':
return xywh2xyxy if format == 'xyxy' else xywh2ltwh
else:
return ltwh2xyxy if format == 'xyxy' else ltwh2xywh
def areas(self):
"""计算并返回每个边界框的面积。"""
self.convert('xyxy') # 转换为 'xyxy' 格式以计算面积
return (self.bboxes[:, 2] - self.bboxes[:, 0]) * (self.bboxes[:, 3] - self.bboxes[:, 1]) # 计算面积
def __len__(self):
"""返回边界框的数量。"""
return len(self.bboxes)
class Instances:
"""
存储图像中检测到的对象的边界框、分段和关键点的容器。
"""
def __init__(self, bboxes, segments=None, keypoints=None, bbox_format='xywh', normalized=True) -> None:
"""初始化 Instances 类,接收边界框、分段和关键点数据。"""
self._bboxes = Bboxes(bboxes=bboxes, format=bbox_format) # 初始化边界框
self.keypoints = keypoints # 存储关键点
self.normalized = normalized # 标记是否归一化
# 处理分段数据
if segments is None:
segments = []
self.segments = self._process_segments(segments)
def _process_segments(self, segments):
"""处理分段数据,确保其形状正确。"""
if len(segments) > 0:
segments = resample_segments(segments) # 重采样分段
return np.stack(segments, axis=0) # 转换为3D数组
return np.zeros((0, 1000, 2), dtype=np.float32) # 返回空数组
def convert_bbox(self, format):
"""转换边界框格式。"""
self._bboxes.convert(format=format)
@property
def bbox_areas(self):
"""计算边界框的面积。"""
return self._bboxes.areas()
def scale(self, scale_w, scale_h, bbox_only=False):
"""缩放边界框、分段和关键点。"""
self._bboxes.mul(scale=(scale_w, scale_h, scale_w, scale_h)) # 缩放边界框
if not bbox_only:
self._scale_segments_and_keypoints(scale_w, scale_h) # 同时缩放分段和关键点
def _scale_segments_and_keypoints(self, scale_w, scale_h):
"""缩放分段和关键点。"""
self.segments[..., 0] *= scale_w
self.segments[..., 1] *= scale_h
if self.keypoints is not None:
self.keypoints[..., 0] *= scale_w
self.keypoints[..., 1] *= scale_h
def __len__(self):
"""返回实例的数量。"""
return len(self._bboxes)
@property
def bboxes(self):
"""返回边界框。"""
return self._bboxes.bboxes
代码注释说明
- Bboxes 类: 该类用于处理边界框,支持多种格式(‘xyxy’, ‘xywh’, ‘ltwh’)。它提供了初始化、格式转换、面积计算等功能。
- Instances 类: 该类用于存储图像中检测到的对象的边界框、分段和关键点。它提供了初始化、格式转换、缩放等功能。
- 注释: 每个方法和类都有详细的注释,说明其功能和参数,以便于理解和使用。```
这个程序文件定义了两个主要的类:Bboxes和Instances,用于处理图像中的边界框(bounding boxes)、分割(segments)和关键点(keypoints)。文件中还包含了一些辅助函数和类型定义。
首先,Bboxes类用于管理边界框。它支持多种边界框格式,包括xyxy(左上角和右下角坐标)、xywh(中心坐标和宽高)以及ltwh(左上角坐标和宽高)。在初始化时,Bboxes类会检查输入的格式是否有效,并确保边界框数据是一个二维的NumPy数组。该类提供了多种方法来转换边界框格式、计算面积、缩放、添加偏移量等。
Bboxes类的主要方法包括:
convert(format):将边界框从一种格式转换为另一种格式。areas():计算每个边界框的面积。mul(scale):根据给定的缩放因子缩放边界框。add(offset):根据给定的偏移量调整边界框的位置。__len__():返回边界框的数量。concatenate(boxes_list):将多个Bboxes对象合并为一个新的Bboxes对象。
接下来,Instances类是一个容器,用于存储图像中检测到的对象的边界框、分割和关键点。它在初始化时接收边界框、分割和关键点的数组,并将其存储为类的属性。Instances类同样提供了多种方法来处理这些数据,包括格式转换、缩放、归一化、去除零面积的边界框等。
Instances类的主要方法包括:
convert_bbox(format):转换边界框的格式。scale(scale_w, scale_h, bbox_only=False):根据给定的宽度和高度缩放边界框、分割和关键点。denormalize(w, h):将归一化的坐标转换为绝对坐标。normalize(w, h):将绝对坐标转换为归一化坐标。add_padding(padw, padh):在边界框、分割和关键点上添加填充。__getitem__(index):通过索引获取特定的实例或一组实例。flipud(h)和fliplr(w):分别用于垂直和水平翻转边界框、分割和关键点的坐标。clip(w, h):将边界框、分割和关键点的值限制在图像边界内。remove_zero_area_boxes():移除面积为零的边界框。update(bboxes, segments=None, keypoints=None):更新实例的边界框、分割和关键点。__len__():返回实例的数量。concatenate(instances_list):将多个Instances对象合并为一个新的Instances对象。
整体而言,这个文件提供了一个灵活的框架,用于处理计算机视觉任务中的边界框、分割和关键点数据,适用于YOLO等目标检测算法的实现。
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
class DFL(nn.Module):
"""
分布焦点损失(DFL)的核心模块。
该模块用于计算目标检测中的焦点损失,帮助模型更好地聚焦于难以分类的样本。
"""
def __init__(self, c1=16):
"""初始化一个卷积层,输入通道数为c1,输出通道数为1。"""
super().__init__()
# 创建一个卷积层,输入通道为c1,输出通道为1,卷积核大小为1,不使用偏置
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
# 初始化卷积层的权重为0到c1的范围
x = torch.arange(c1, dtype=torch.float)
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1 # 保存输入通道数
def forward(self, x):
"""对输入张量x应用DFL模块并返回结果。"""
b, c, a = x.shape # 获取输入的批量大小、通道数和锚框数
# 对输入进行变形和softmax处理后通过卷积层,最后再变形为输出格式
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
class Proto(nn.Module):
"""YOLOv8的掩码原型模块,用于分割模型。"""
def __init__(self, c1, c_=256, c2=32):
"""
初始化YOLOv8掩码原型模块,指定原型和掩码的数量。
参数包括输入通道数c1,原型数量c_,掩码数量c2。
"""
super().__init__()
self.cv1 = Conv(c1, c_, k=3) # 第一个卷积层
self.upsample = nn.ConvTranspose2d(c_, c_, 2, 2, 0, bias=True) # 上采样层
self.cv2 = Conv(c_, c_, k=3) # 第二个卷积层
self.cv3 = Conv(c_, c2) # 第三个卷积层
def forward(self, x):
"""通过上采样和卷积层执行前向传播。"""
return self.cv3(self.cv2(self.upsample(self.cv1(x))))
class Bottleneck(nn.Module):
"""标准的瓶颈模块。"""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""
初始化瓶颈模块,指定输入输出通道、是否使用shortcut、分组数、卷积核大小和扩展比例。
"""
super().__init__()
c_ = int(c2 * e) # 计算隐藏通道数
self.cv1 = Conv(c1, c_, k[0], 1) # 第一个卷积层
self.cv2 = Conv(c_, c2, k[1], 1, g=g) # 第二个卷积层
self.add = shortcut and c1 == c2 # 判断是否使用shortcut连接
def forward(self, x):
"""执行前向传播,应用YOLO FPN到输入数据。"""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
"""CSP瓶颈模块,包含3个卷积层。"""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
"""初始化CSP瓶颈模块,指定输入输出通道、卷积层数量、shortcut、分组和扩展。"""
super().__init__()
c_ = int(c2 * e) # 计算隐藏通道数
self.cv1 = Conv(c1, c_, 1, 1) # 第一个卷积层
self.cv2 = Conv(c1, c_, 1, 1) # 第二个卷积层
self.cv3 = Conv(2 * c_, c2, 1) # 第三个卷积层
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n))) # 中间的瓶颈层
def forward(self, x):
"""执行前向传播,返回经过CSP瓶颈模块的输出。"""
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1)) # 将两个分支的输出连接并通过第三个卷积层
# 其他模块如C2、C2f、C3x等可以根据需要添加
以上代码片段保留了最核心的部分,并对每个类和方法进行了详细的中文注释,便于理解其功能和用途。```
这个程序文件是一个用于构建深度学习模型的模块,主要涉及到YOLO(You Only Look Once)系列模型的构建,特别是YOLOv8。文件中定义了多个神经网络模块,主要用于特征提取和处理,使用了PyTorch框架。
首先,文件导入了必要的库,包括torch和torch.nn,这些是构建神经网络的基础库。接着,文件定义了一些常用的卷积层模块,如Conv、DWConv、GhostConv等,这些模块在后续的类中被广泛使用。
接下来,文件中定义了多个类,每个类代表一个特定的网络模块。以下是一些主要模块的简要说明:
-
DFL(Distribution Focal Loss):这个模块实现了分布焦点损失的计算,主要用于目标检测任务中的损失函数。它通过卷积层将输入的特征图转换为一个新的特征图,进而计算损失。
-
Proto:这是YOLOv8中的一个掩码原型模块,主要用于分割模型。它通过一系列卷积和上采样操作,将输入特征图转换为掩码输出。
-
HGStem:这是PPHGNetV2的StemBlock,包含多个卷积层和一个最大池化层,用于提取输入图像的特征。
-
HGBlock:这是PPHGNetV2中的一个块,包含多个卷积层和可选的轻量卷积(LightConv),用于特征的进一步处理。
-
SPP(Spatial Pyramid Pooling):这个模块实现了空间金字塔池化,能够处理不同尺度的特征图,以增强模型的鲁棒性。
-
C1、C2、C3等:这些类实现了不同配置的CSP(Cross Stage Partial)瓶颈模块,CSP瓶颈是为了提高网络的学习能力和特征提取能力而设计的。每个类都有不同的卷积层配置和数量。
-
GhostBottleneck:实现了GhostNet中的瓶颈结构,旨在减少模型的参数量和计算量,同时保持较好的性能。
-
Bottleneck和BottleneckCSP:这两个类实现了标准的瓶颈结构和CSP瓶颈结构,分别用于特征的提取和增强。
这些模块的设计旨在通过不同的卷积操作和结构组合,提高YOLO模型在目标检测和分割任务中的性能。每个模块都有自己的前向传播方法,定义了如何将输入数据通过一系列操作转换为输出特征图。
总体而言,这个文件是YOLO系列模型的重要组成部分,提供了多种构建块,以便在实际应用中灵活组合和使用。
```python
import os
import torch
import yaml
from ultralytics import YOLO # 导入YOLO模型库
if __name__ == '__main__': # 确保该模块被直接运行时才执行以下代码
# 设置训练参数
workers = 1 # 数据加载的工作进程数量
batch = 8 # 每个批次的样本数量
device = "0" if torch.cuda.is_available() else "cpu" # 判断是否使用GPU
# 获取数据集配置文件的绝对路径
data_path = abs_path(f'datasets/data/data.yaml', path_type='current')
# 将路径格式转换为Unix风格
unix_style_path = data_path.replace(os.sep, '/')
# 获取数据集所在目录的路径
directory_path = os.path.dirname(unix_style_path)
# 读取YAML文件,保持原有顺序
with open(data_path, 'r') as file:
data = yaml.load(file, Loader=yaml.FullLoader)
# 修改YAML文件中的路径项
if 'train' in data and 'val' in data and 'test' in data:
data['train'] = directory_path + '/train' # 更新训练集路径
data['val'] = directory_path + '/val' # 更新验证集路径
data['test'] = directory_path + '/test' # 更新测试集路径
# 将修改后的数据写回YAML文件
with open(data_path, 'w') as file:
yaml.safe_dump(data, file, sort_keys=False)
# 加载YOLO模型,指定配置文件和预训练权重
model = YOLO(r"C:\codeseg\codenew\50+种YOLOv8算法改进源码大全和调试加载训练教程(非必要)\改进YOLOv8模型配置文件\yolov8-seg-C2f-Faster.yaml").load("./weights/yolov8s-seg.pt")
# 开始训练模型
results = model.train(
data=data_path, # 指定训练数据的配置文件路径
device=device, # 指定使用的设备(GPU或CPU)
workers=workers, # 指定数据加载的工作进程数量
imgsz=640, # 指定输入图像的大小为640x640
epochs=100, # 指定训练的轮数为100
batch=batch, # 指定每个批次的样本数量
)
代码说明:
- 导入库:导入必要的库,包括操作系统库、PyTorch、YAML解析库和YOLO模型库。
- 设置训练参数:定义数据加载的工作进程数量、批次大小和设备(GPU或CPU)。
- 获取数据集配置文件路径:通过
abs_path函数获取数据集的YAML配置文件的绝对路径,并将其转换为Unix风格的路径。 - 读取和修改YAML文件:读取YAML文件,更新训练、验证和测试集的路径,并将修改后的内容写回文件。
- 加载YOLO模型:根据指定的配置文件和预训练权重加载YOLO模型。
- 训练模型:调用
train方法开始训练,传入训练数据路径、设备、工作进程数量、图像大小、训练轮数和批次大小等参数。```
该程序文件train.py是一个用于训练 YOLO(You Only Look Once)模型的脚本。首先,它导入了必要的库,包括操作系统库os、深度学习框架torch、YAML 处理库yaml、YOLO 模型库ultralytics以及用于图形界面的matplotlib。在程序的主入口中,首先设置了一些训练参数,如工作进程数workers、批次大小batch和设备类型device。设备类型会根据是否有可用的 GPU 来选择,如果有则使用 GPU(“0”),否则使用 CPU。
接下来,程序通过 abs_path 函数获取数据集配置文件的绝对路径,该配置文件是一个 YAML 文件,通常包含训练、验证和测试数据的路径。然后,程序将路径中的分隔符统一为 UNIX 风格的斜杠,并提取出目录路径。
程序打开 YAML 文件并读取其内容,使用 yaml.load 方法将其解析为 Python 字典。接着,程序检查字典中是否包含 train、val 和 test 这几个键,如果存在,则将这些键对应的路径修改为当前目录下的 train、val 和 test 子目录。修改完成后,程序将更新后的字典写回到 YAML 文件中,确保路径的正确性。
在模型加载部分,程序使用 YOLO 类加载指定的模型配置文件,并从指定的权重文件中加载预训练模型。这里提到不同模型对设备的要求不同,如果出现错误,可以尝试其他模型配置文件。
最后,程序调用 model.train 方法开始训练模型,传入的参数包括数据配置文件路径、设备类型、工作进程数、输入图像大小(640x640)、训练的 epoch 数(100)以及批次大小(8)。通过这些设置,程序将开始进行模型的训练过程。
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
# 自适应填充函数,用于确保卷积输出的尺寸与输入相同
def autopad(k, p=None, d=1): # k: kernel size, p: padding, d: dilation
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # 实际的卷积核大小
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # 自动填充
return p
# Swish激活函数
class swish(nn.Module):
def forward(self, x):
return x * torch.sigmoid(x)
# DyReLU激活函数,具有动态调整的特性
class DyReLU(nn.Module):
def __init__(self, inp, reduction=4, lambda_a=1.0, use_bias=True):
super(DyReLU, self).__init__()
self.oup = inp
self.lambda_a = lambda_a * 2
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化
# 计算压缩比
squeeze = inp // reduction
self.fc = nn.Sequential(
nn.Linear(inp, squeeze),
nn.ReLU(inplace=True),
nn.Linear(squeeze, self.oup * 2), # 输出两个参数
nn.Sigmoid() # 使用Sigmoid激活
)
def forward(self, x):
b, c, h, w = x.size()
y = self.avg_pool(x).view(b, c) # 池化后展平
y = self.fc(y).view(b, self.oup * 2, 1, 1) # 通过全连接层
a1, b1 = torch.split(y, self.oup, dim=1) # 分割输出
a1 = (a1 - 0.5) * self.lambda_a + 1.0 # 动态调整
out = x * a1 + b1 # 计算输出
return out
# DyHeadBlock类,包含多种注意力机制
class DyHeadBlock(nn.Module):
def __init__(self, in_channels, norm_type='GN'):
super().__init__()
self.spatial_conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1) # 空间卷积
self.offset_conv = nn.Conv2d(in_channels, 3 * 3 * 3, kernel_size=3, padding=1) # 偏移卷积
self.scale_attn_module = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, 1, 1),
nn.ReLU(inplace=True)
)
def forward(self, x):
offset_and_mask = self.offset_conv(x) # 计算偏移和掩码
offset = offset_and_mask[:, :6, :, :] # 提取偏移
mask = offset_and_mask[:, 6:, :, :].sigmoid() # 计算掩码
mid_feat = self.spatial_conv(x) # 中间特征
scale_attn = self.scale_attn_module(mid_feat) # 计算缩放注意力
return mid_feat * scale_attn # 返回加权特征
# Fusion类,用于融合多个输入特征
class Fusion(nn.Module):
def __init__(self, inc_list):
super().__init__()
self.fusion_conv = nn.ModuleList([nn.Conv2d(inc, inc, 1) for inc in inc_list]) # 融合卷积
def forward(self, x):
for i in range(len(x)):
x[i] = self.fusion_conv[i](x[i]) # 应用融合卷积
return torch.cat(x, dim=1) # 连接特征
# 示例:使用DyHeadBlock和Fusion类
if __name__ == "__main__":
# 创建输入张量
input_tensor = torch.randn(1, 64, 32, 32) # Batch size 1, 64 channels, 32x32 size
dy_head_block = DyHeadBlock(in_channels=64)
output_tensor = dy_head_block(input_tensor)
print("Output shape from DyHeadBlock:", output_tensor.shape)
# 使用Fusion类
fusion_layer = Fusion(inc_list=[64, 64, 64])
fused_output = fusion_layer([output_tensor, output_tensor, output_tensor])
print("Output shape from Fusion:", fused_output.shape)
代码说明:
- autopad: 自动计算填充,以确保卷积输出的尺寸与输入相同。
- swish: 实现Swish激活函数。
- DyReLU: 动态ReLU激活函数,根据输入动态调整参数。
- DyHeadBlock: 该类实现了多种注意力机制的头部,使用卷积和偏移计算来生成加权特征。
- Fusion: 融合多个输入特征的类,使用卷积进行特征融合。
示例:
在主程序中,创建了一个输入张量,并通过DyHeadBlock和Fusion类进行处理,输出了它们的形状以验证功能。```
这个程序文件 ultralytics\nn\extra_modules\block.py 是一个用于构建深度学习模型的模块,主要使用 PyTorch 框架。该文件定义了多个神经网络组件,包括不同类型的卷积层、注意力机制、以及一些特定的块(Block),这些块可以组合成更复杂的网络结构。
首先,文件导入了必要的库,包括 PyTorch 的核心库 torch 和 torch.nn,以及一些其他的工具库,比如 einops 用于张量重排,math 和 numpy 用于数学计算。此外,还导入了一些自定义模块,例如卷积模块和注意力模块。
文件中定义了许多类和函数,主要包括以下几个部分:
-
自动填充函数:
autopad函数用于根据卷积核大小和膨胀率自动计算填充大小,以确保输出尺寸与输入相同。 -
激活函数:定义了多种激活函数的类,包括
swish、h_swish和h_sigmoid,这些激活函数在深度学习中用于引入非线性。 -
动态 ReLU 和动态卷积:
DyReLU和DyDCNv2类实现了动态激活和动态卷积操作,这些操作根据输入特征的不同动态调整参数。 -
头部块(Head Block):
DyHeadBlock和DyHeadBlockWithDCNV3类实现了具有不同注意力机制的头部块,这些块通常用于目标检测和图像分割任务。 -
融合模块:
Fusion类实现了不同特征图的融合方法,包括加权融合和自适应融合等。 -
各种卷积块:定义了多种卷积块,如
Partial_conv3、Faster_Block、Bottleneck等,这些块可以用于构建更复杂的网络结构。 -
注意力机制:实现了多种注意力机制的模块,包括
OD_Attention、SCConv、CSPStage等,这些模块用于增强网络对重要特征的关注。 -
上下文引导块:
ContextGuidedBlock和ContextGuidedBlock_Down类实现了上下文引导机制,旨在利用上下文信息来增强特征表示。 -
其他模块:文件中还定义了许多其他模块和块,如
C3、C2f、DWR、RFAConv等,这些模块和块可以组合成完整的网络架构。
整个文件的结构和设计表明,它是为了构建一个灵活且强大的深度学习模型而设计的,支持多种特征提取和融合策略,适用于计算机视觉任务。每个模块都可以独立使用,也可以组合在一起形成更复杂的网络结构,以适应不同的应用需求。
```python
import time
import pandas as pd
from ultralytics import YOLO
from ultralytics.utils import select_device, check_yolo
def benchmark(model='yolov8n.pt', imgsz=160, device='cpu', verbose=False):
"""
对YOLO模型进行基准测试,评估不同格式的速度和准确性。
参数:
model (str): 模型文件的路径,默认为'yolov8n.pt'。
imgsz (int): 用于基准测试的图像大小,默认为160。
device (str): 运行基准测试的设备,可以是'cpu'或'cuda',默认为'cpu'。
verbose (bool): 如果为True,则在基准测试失败时抛出异常,默认为False。
返回:
df (pandas.DataFrame): 包含每种格式的基准测试结果的数据框,包括文件大小、指标和推理时间。
"""
pd.options.display.max_columns = 10 # 设置显示的最大列数
pd.options.display.width = 120 # 设置显示的宽度
device = select_device(device, verbose=False) # 选择设备
model = YOLO(model) # 加载YOLO模型
results = [] # 存储结果的列表
start_time = time.time() # 记录开始时间
# 遍历不同的导出格式
for i, (name, format, suffix, cpu, gpu) in export_formats().iterrows():
emoji, filename = '❌', None # 默认导出状态为失败
try:
# 检查导出格式的支持性
if 'cpu' in device.type:
assert cpu, 'CPU不支持推理'
if 'cuda' in device.type:
assert gpu, 'GPU不支持推理'
# 导出模型
if format == '-':
filename = model.ckpt_path or model.cfg # PyTorch格式
else:
filename = model.export(imgsz=imgsz, format=format, device=device, verbose=False)
exported_model = YOLO(filename) # 加载导出的模型
assert suffix in str(filename), '导出失败'
emoji = '✅' # 导出成功
# 进行推理
exported_model.predict('path/to/sample/image.jpg', imgsz=imgsz, device=device)
# 验证模型
results_dict = exported_model.val(data='path/to/dataset.yaml', batch=1, imgsz=imgsz, device=device)
metric, speed = results_dict.results_dict['mAP'], results_dict.speed['inference']
results.append([name, emoji, round(file_size(filename), 1), round(metric, 4), round(speed, 2)])
except Exception as e:
if verbose:
raise e # 如果verbose为True,抛出异常
results.append([name, emoji, None, None, None]) # 记录失败的结果
# 打印结果
check_yolo(device=device) # 打印系统信息
df = pd.DataFrame(results, columns=['Format', 'Status', 'Size (MB)', 'Metric', 'Inference time (ms/im)'])
print(df) # 输出结果数据框
return df # 返回结果数据框
代码核心部分说明:
- 导入必要的库:导入了
time、pandas和YOLO模型相关的库。 - benchmark函数:该函数是代码的核心,负责对YOLO模型进行基准测试。
- 参数说明:包括模型路径、图像大小、设备类型和详细模式。
- 结果存储:使用列表
results来存储每种格式的测试结果。 - 导出格式遍历:通过
export_formats()函数遍历不同的模型导出格式,并进行相应的导出和推理。 - 异常处理:使用
try-except结构来捕获可能的错误,并在verbose模式下抛出异常。 - 结果输出:将结果整理成
pandas.DataFrame格式并打印输出。
注意事项:
- 在实际使用中,需要替换
'path/to/sample/image.jpg'和'path/to/dataset.yaml'为实际的图像和数据集路径。 - 该代码依赖于Ultralytics YOLO库的实现,确保环境中已正确安装相关依赖。```
这个程序文件benchmarks.py是用于基准测试 YOLO 模型的速度和准确性,主要功能是评估不同格式的 YOLO 模型在推理时的性能。文件的开头部分包含了使用说明,用户可以通过导入ProfileModels和benchmark函数来进行模型的基准测试。
在代码中,首先定义了 benchmark 函数,该函数接受多个参数,包括模型路径、数据集、图像大小、是否使用半精度和 INT8 精度、设备类型(CPU 或 CUDA)以及是否详细输出。函数的主要功能是对指定的 YOLO 模型进行基准测试,输出包括文件大小、评估指标和推理时间等信息。
在 benchmark 函数内部,首先通过 select_device 函数选择运行设备,然后加载模型。接着,程序遍历支持的导出格式(如 PyTorch、ONNX、TensorRT 等),并尝试导出模型。对于每种格式,程序会进行推理测试,并计算评估指标和推理速度。测试结果会被记录到一个列表中,最后以 Pandas DataFrame 的形式返回,并输出到日志文件中。
此外,文件中还定义了 ProfileModels 类,用于对不同模型进行性能分析。该类可以接受模型路径,并设置多种参数,如定时运行次数、预热运行次数、最小运行时间和图像大小等。ProfileModels 类的 profile 方法会遍历指定的模型文件,导出 ONNX 和 TensorRT 格式,并对它们进行基准测试,最后输出结果。
ProfileModels 类还包含了一些辅助方法,如 get_files 用于获取模型文件路径,get_onnx_model_info 用于获取 ONNX 模型的信息,profile_tensorrt_model 和 profile_onnx_model 分别用于对 TensorRT 和 ONNX 模型进行性能分析。
总体来说,这个文件的核心功能是提供一个框架来评估和比较不同格式的 YOLO 模型在推理时的性能,帮助用户选择最适合其需求的模型格式。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献242条内容
已为社区贡献242条内容

所有评论(0)