【完整源码+数据集+部署教程】舞台设备分割系统源码&数据集分享 [yolov8-seg-KernelWarehouse&yolov8-seg-EfficientHead等50+全套改进创新点发刊_一
【完整源码+数据集+部署教程】舞台设备分割系统源码&数据集分享[yolov8-seg-KernelWarehouse&yolov8-seg-EfficientHead等50+全套改进创新点发刊_一
背景意义
随着舞台表演艺术的不断发展,舞台设备的复杂性和多样性日益增加。现代舞台设计不仅要求设备的功能性和安全性,还强调视觉效果和艺术表现力。在此背景下,如何高效、准确地识别和分割舞台设备,成为了提升舞台制作效率和安全性的重要课题。传统的舞台设备管理方法往往依赖人工检查和手动标记,不仅耗时耗力,而且容易出现误差,无法满足现代舞台制作对实时性和准确性的高要求。因此,基于计算机视觉的自动化设备分割系统应运而生,成为解决这一问题的有效途径。
本研究旨在基于改进的YOLOv8模型,构建一个高效的舞台设备分割系统。YOLO(You Only Look Once)系列模型因其快速的检测速度和较高的准确率,已成为目标检测领域的主流算法之一。YOLOv8作为该系列的最新版本,进一步优化了检测精度和实时性,特别适合于动态变化的舞台环境。通过对YOLOv8的改进,我们可以在保持高效检测的同时,提升对舞台设备的分割能力,从而实现对舞台设备的智能管理。
本研究所使用的数据集包含4400张图像,涵盖51类舞台设备,涉及从基本的舞台支架到复杂的LED视频屏幕等多种设备。这一丰富的数据集为模型的训练和测试提供了坚实的基础,使得模型能够在多样化的设备环境中进行有效的学习和识别。通过对不同类别设备的实例分割,系统不仅能够识别设备的存在,还能准确划分其边界,为后续的舞台设计和安全管理提供重要的数据支持。
此外,舞台设备的智能分割系统在实际应用中具有广泛的意义。首先,它能够大幅度提高舞台设备的管理效率,减少人工成本,降低人为错误的风险。其次,通过实时监控和分析舞台设备的状态,能够及时发现潜在的安全隐患,保障演出过程中的安全性。最后,随着舞台设备管理的智能化,能够为舞台设计师提供更为精准的数据支持,促进舞台艺术的创新与发展。
综上所述,基于改进YOLOv8的舞台设备分割系统的研究,不仅具有重要的学术价值,也在实际应用中展现出广阔的前景。通过本研究的开展,我们期望能够为舞台设备的智能管理提供新的思路和方法,推动舞台艺术与科技的深度融合。
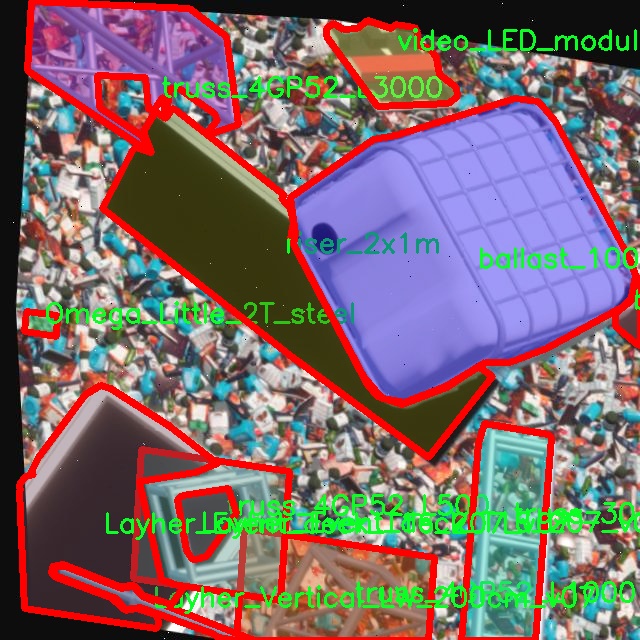
图片效果
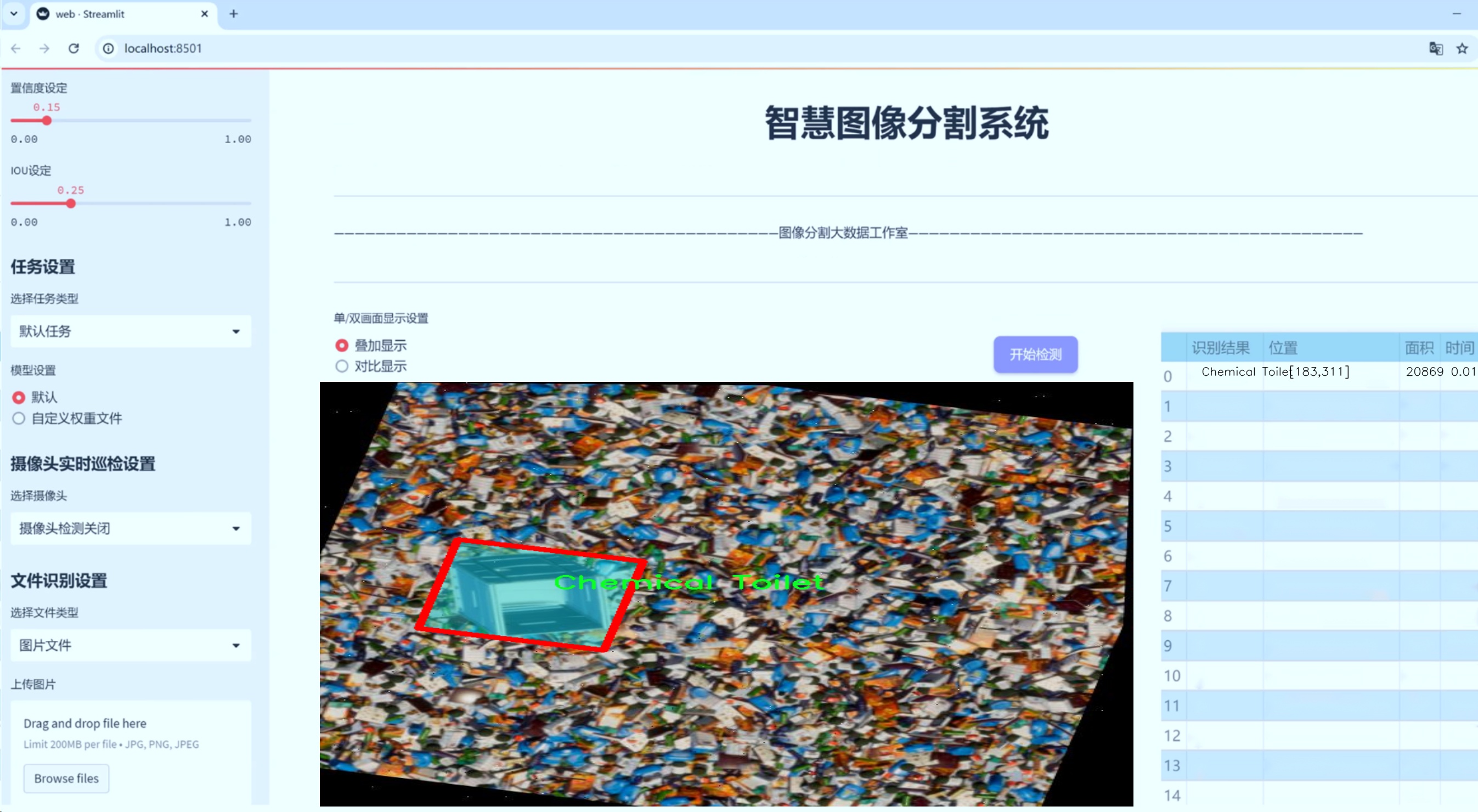
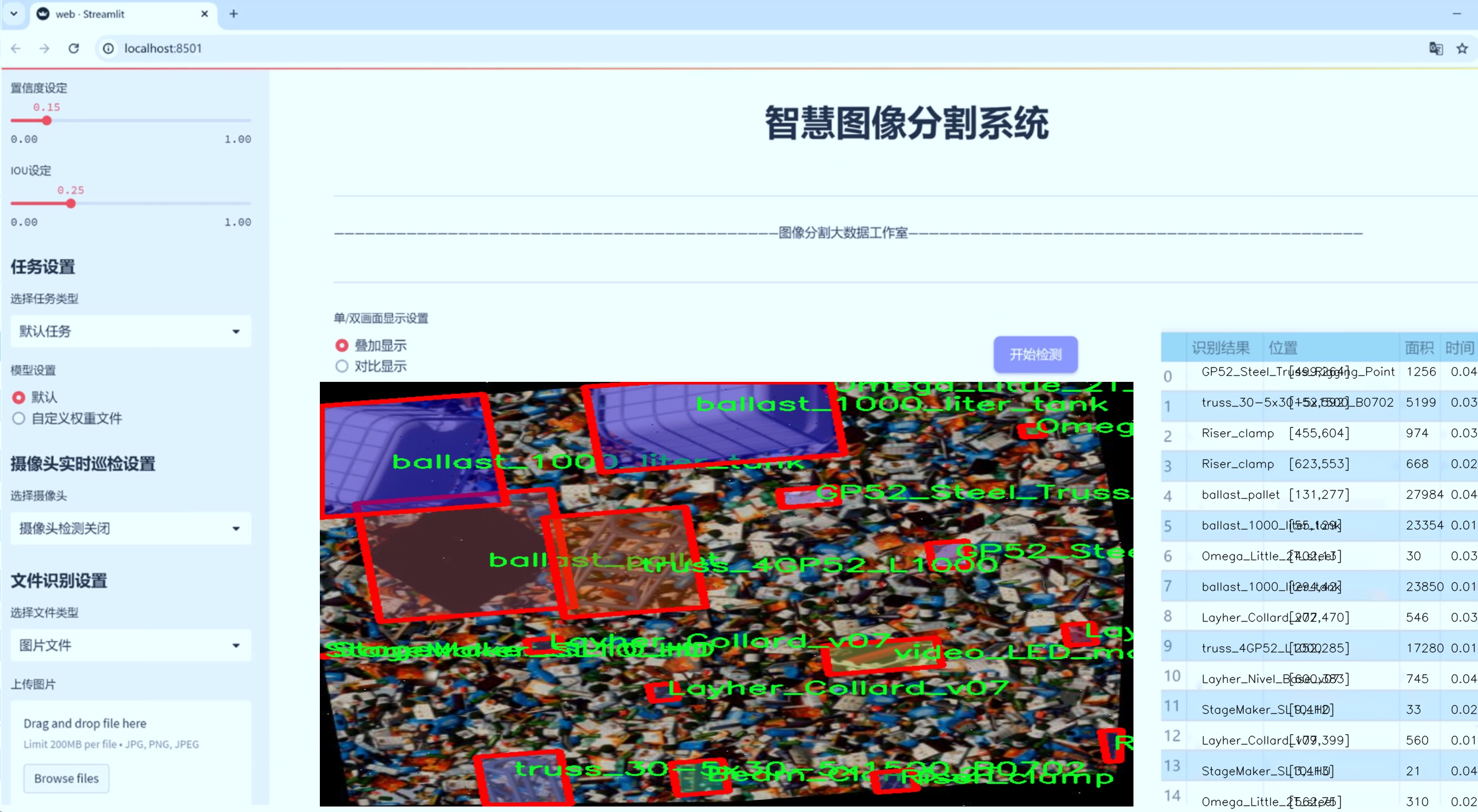
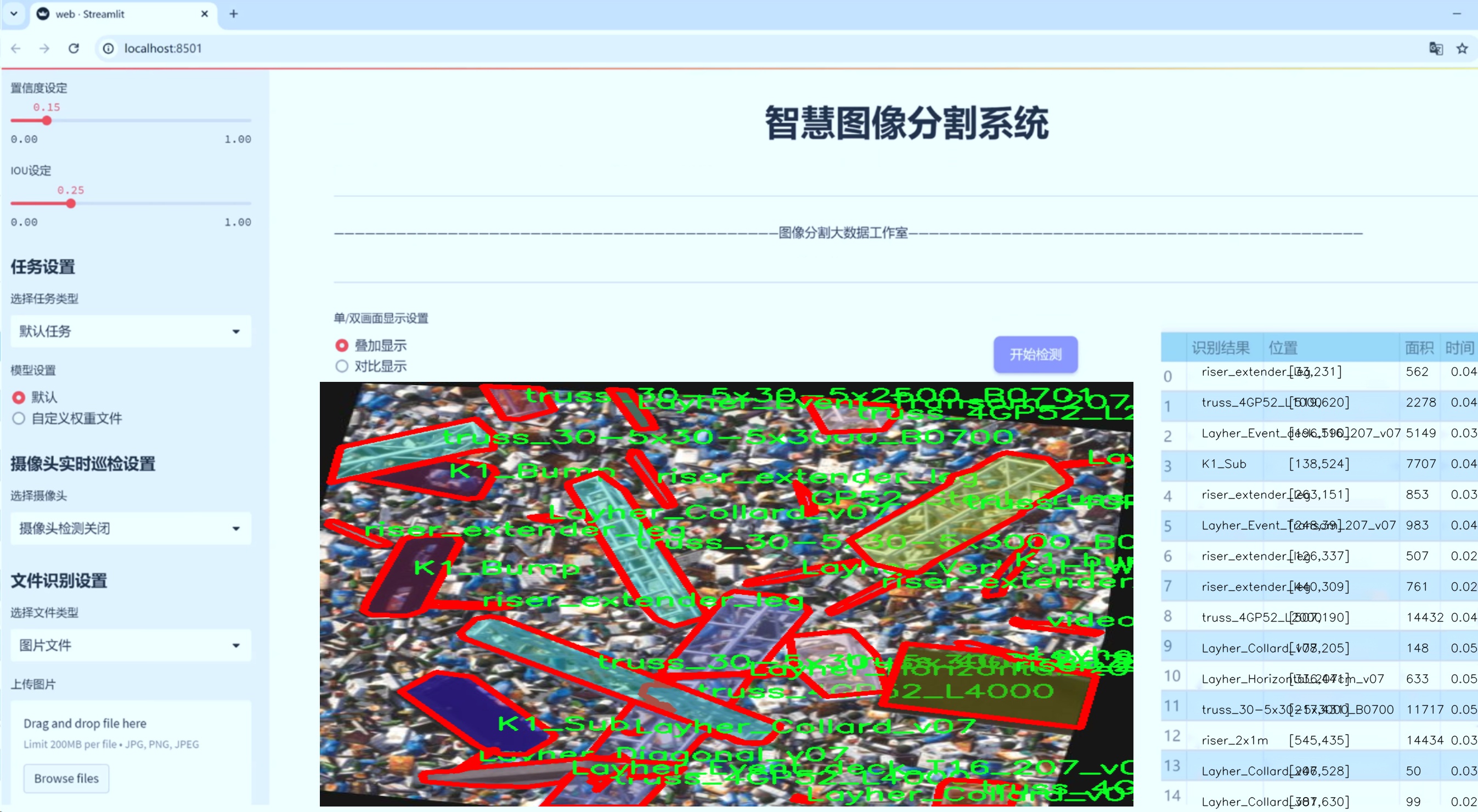
数据集信息
在现代舞台设备管理与应用中,精确的设备分割与识别是确保演出安全与顺利进行的关键因素。为此,我们构建了一个名为“IS v01”的数据集,旨在为改进YOLOv8-seg的舞台设备分割系统提供丰富的训练数据。该数据集包含51个类别,涵盖了多种舞台设备,确保了模型在多样化场景下的有效性与鲁棒性。
“IS v01”数据集的类别设计充分考虑了舞台搭建与演出过程中常见的设备,具体类别包括但不限于:Beam_Clamp_2T、Chemical Toilet、Complete Stack 8x K1 SB on wheels、Dressing_room_v2等。这些类别的选择不仅反映了舞台设备的多样性,还体现了实际应用中的需求。例如,Chemical Toilet的存在是为了满足演出现场的基本卫生需求,而Dressing_room_v2则为演职人员提供了更为便利的更衣空间。
在数据集的构建过程中,我们确保每个类别的样本数量充足且质量高,以便于模型能够在训练中学习到每种设备的特征。比如,K1系列设备(如K1 4xSB 16xTop Array、K1_Bump、K1_Pin等)在现代舞台搭建中占据了重要地位,数据集中对这些设备的详细标注将极大提升模型的识别能力。此外,数据集中还包含了多种类型的支撑与连接设备,如truss系列(如truss_30-5x30-5x1000_B0703、truss_4GP52_L2000等),这些设备在舞台结构的稳定性与安全性方面发挥着不可或缺的作用。
数据集的设计不仅限于静态设备的识别,还考虑到了动态环境中的应用场景。例如,LED Video Screen 6mx4m的加入,反映了现代舞台对视觉效果的追求,同时也增加了模型在处理动态影像时的复杂性。此外,诸如PowerPlant_400kva等设备的存在,确保了舞台在电力供应方面的安全与稳定,这对于大型演出尤为重要。
通过对这些类别的精细划分与标注,“IS v01”数据集为YOLOv8-seg模型的训练提供了坚实的基础。我们相信,借助这一数据集,模型将能够在多种复杂场景中实现高效的设备分割与识别,进而提升舞台设备管理的智能化水平。未来,我们还计划持续扩展数据集的规模与类别,以适应不断变化的舞台技术与设备需求,推动舞台设备管理的进一步发展与创新。



核心代码
```python
# 导入必要的库
from ultralytics.utils import LOGGER, SETTINGS, TESTS_RUNNING, checks
import os
import re
from pathlib import Path
# 尝试导入DVCLive并进行版本检查
try:
assert not TESTS_RUNNING # 确保不在测试运行中
assert SETTINGS['dvc'] is True # 确保集成已启用
import dvclive
assert checks.check_version('dvclive', '2.11.0', verbose=True)
live = None # DVCLive日志实例
_processed_plots = {} # 存储已处理的图表
_training_epoch = False # 标记当前是否为训练周期
except (ImportError, AssertionError, TypeError):
dvclive = None # 如果导入失败,则将dvclive设置为None
def _log_images(path, prefix=''):
"""记录指定路径的图像,使用可选前缀。"""
if live: # 如果DVCLive已初始化
name = path.name
# 根据批次分组图像,以便在UI中启用滑块
m = re.search(r'_batch(\d+)', name)
if m:
ni = m[1]
new_stem = re.sub(r'_batch(\d+)', '_batch', path.stem)
name = (Path(new_stem) / ni).with_suffix(path.suffix)
live.log_image(os.path.join(prefix, name), path) # 记录图像
def _log_plots(plots, prefix=''):
"""记录训练进度的图像,如果之前未处理过。"""
for name, params in plots.items():
timestamp = params['timestamp']
if _processed_plots.get(name) != timestamp: # 检查是否已处理
_log_images(name, prefix) # 记录图像
_processed_plots[name] = timestamp # 更新已处理的图表时间戳
def on_pretrain_routine_start(trainer):
"""在预训练例程开始时初始化DVCLive日志记录。"""
try:
global live
live = dvclive.Live(save_dvc_exp=True, cache_images=True) # 初始化DVCLive
LOGGER.info("DVCLive已检测到,自动记录已启用。")
except Exception as e:
LOGGER.warning(f'警告 ⚠️ DVCLive安装但未正确初始化,未记录此运行。{e}')
def on_train_start(trainer):
"""如果DVCLive日志记录处于活动状态,则记录训练参数。"""
if live:
live.log_params(trainer.args) # 记录训练参数
def on_fit_epoch_end(trainer):
"""在每个训练周期结束时记录训练指标和模型信息。"""
global _training_epoch
if live and _training_epoch: # 如果DVCLive已初始化且当前为训练周期
all_metrics = {**trainer.label_loss_items(trainer.tloss, prefix='train'), **trainer.metrics, **trainer.lr}
for metric, value in all_metrics.items():
live.log_metric(metric, value) # 记录每个指标
_log_plots(trainer.plots, 'train') # 记录训练图表
live.next_step() # 进入下一个步骤
_training_epoch = False # 重置训练周期标记
def on_train_end(trainer):
"""在训练结束时记录最佳指标、图表和混淆矩阵。"""
if live:
all_metrics = {**trainer.label_loss_items(trainer.tloss, prefix='train'), **trainer.metrics, **trainer.lr}
for metric, value in all_metrics.items():
live.log_metric(metric, value, plot=False) # 记录最佳指标
_log_plots(trainer.plots, 'val') # 记录验证图表
# 记录混淆矩阵
if trainer.best.exists():
live.log_artifact(trainer.best, copy=True, type='model') # 记录最佳模型
live.end() # 结束日志记录
# 定义回调函数
callbacks = {
'on_pretrain_routine_start': on_pretrain_routine_start,
'on_train_start': on_train_start,
'on_fit_epoch_end': on_fit_epoch_end,
'on_train_end': on_train_end
} if dvclive else {}
代码注释说明:
- 导入模块:导入所需的库和模块,包括日志记录和路径处理。
- DVCLive初始化:尝试导入DVCLive并进行版本检查,确保日志记录功能可用。
- 图像和图表记录:定义了记录图像和图表的函数,确保在训练过程中可以跟踪进度。
- 训练过程中的回调:定义了在训练开始、结束和每个周期结束时的回调函数,以记录训练参数和指标。```
这个文件是Ultralytics YOLO项目中的一个回调模块,主要用于集成DVCLive库以记录训练过程中的各种信息。首先,文件导入了一些必要的模块和设置,包括日志记录器、设置参数和检查函数。接着,文件尝试导入DVCLive库,并进行一些基本的版本检查和条件判断,以确保在适当的环境下运行。
在文件中,定义了几个私有函数和一些回调函数,这些函数在训练的不同阶段被调用,以记录训练的状态和结果。首先,_log_images函数用于记录指定路径下的图像,并在UI中通过批次分组来实现滑动条的功能。_log_plots函数则用于记录训练过程中的图像,如果这些图像之前没有被处理过。_log_confusion_matrix函数用于记录混淆矩阵,帮助分析模型的分类性能。
接下来,文件定义了一系列的回调函数,例如on_pretrain_routine_start和on_pretrain_routine_end,分别在预训练开始和结束时被调用,用于初始化DVCLive记录器和记录训练过程中的图像。on_train_start函数在训练开始时记录训练参数,而on_train_epoch_start函数则在每个训练周期开始时设置一个全局变量,指示当前处于训练周期中。
on_fit_epoch_end函数在每个训练周期结束时被调用,记录训练指标和模型信息,并准备进入下一个步骤。最后,on_train_end函数在训练结束时记录最佳指标、图像和混淆矩阵,并结束DVCLive的记录。
最后,文件将这些回调函数组织成一个字典,方便在训练过程中调用。如果DVCLive未成功导入或初始化,则该字典将为空,确保程序的健壮性。总的来说,这个文件通过与DVCLive的集成,提供了一种有效的方式来监控和记录YOLO模型的训练过程。
import sys
import subprocess
def run_script(script_path):
"""
使用当前 Python 环境运行指定的脚本。
Args:
script_path (str): 要运行的脚本路径
Returns:
None
"""
# 获取当前 Python 解释器的路径
python_path = sys.executable
# 构建运行命令,使用 streamlit 运行指定的脚本
command = f'"{python_path}" -m streamlit run "{script_path}"'
# 执行命令
result = subprocess.run(command, shell=True)
# 检查命令执行结果,如果返回码不为0,表示出错
if result.returncode != 0:
print("脚本运行出错。")
# 主程序入口
if __name__ == "__main__":
# 指定要运行的脚本路径
script_path = "web.py" # 这里可以直接指定脚本名,假设在当前目录下
# 调用函数运行脚本
run_script(script_path)
代码核心部分说明:
-
导入模块:
sys:用于获取当前 Python 解释器的路径。subprocess:用于执行外部命令。
-
run_script函数:- 该函数接受一个脚本路径作为参数,并使用当前 Python 环境运行该脚本。
- 使用
sys.executable获取当前 Python 解释器的路径。 - 构建一个命令字符串,使用
streamlit模块运行指定的脚本。 - 使用
subprocess.run执行构建的命令,并检查返回码以判断脚本是否成功运行。
-
主程序入口:
- 当脚本作为主程序运行时,指定要运行的脚本路径(这里假设为
web.py)。 - 调用
run_script函数执行指定的脚本。```
这个程序文件名为ui.py,主要功能是通过当前的 Python 环境运行一个指定的脚本,具体是使用 Streamlit 来启动一个 Web 应用。
- 当脚本作为主程序运行时,指定要运行的脚本路径(这里假设为
程序首先导入了必要的模块,包括 sys、os 和 subprocess,以及一个自定义的 abs_path 函数,这个函数来自于 QtFusion.path 模块,可能用于获取文件的绝对路径。
接下来,定义了一个名为 run_script 的函数,该函数接受一个参数 script_path,表示要运行的脚本的路径。在函数内部,首先获取当前 Python 解释器的路径,存储在 python_path 变量中。然后,构建一个命令字符串,使用 Streamlit 运行指定的脚本。命令的格式是 "{python_path}" -m streamlit run "{script_path}",其中 {python_path} 和 {script_path} 会被实际的路径替换。
使用 subprocess.run 方法执行构建好的命令,shell=True 参数允许在 shell 中执行命令。执行后,检查返回码 result.returncode,如果不等于 0,表示脚本运行出错,程序会打印出相应的错误信息。
在文件的最后部分,使用 if __name__ == "__main__": 来判断是否直接运行该脚本。如果是,则指定要运行的脚本路径为 web.py,并调用 run_script 函数来执行这个脚本。
总体来看,这个程序的作用是为一个 Streamlit 应用提供一个启动入口,确保在正确的 Python 环境中运行指定的 Web 应用脚本。
```python
# 导入必要的库和模块
from ultralytics.utils import SETTINGS
# 尝试导入Ray库并验证Ray Tune集成是否启用
try:
assert SETTINGS['raytune'] is True # 验证Ray Tune集成是否启用
import ray
from ray import tune
from ray.air import session
except (ImportError, AssertionError):
tune = None # 如果导入失败或集成未启用,则将tune设置为None
def on_fit_epoch_end(trainer):
"""在每个训练周期结束时,将训练指标发送到Ray Tune。"""
if ray.tune.is_session_enabled(): # 检查Ray Tune会话是否启用
metrics = trainer.metrics # 获取当前训练的指标
metrics['epoch'] = trainer.epoch # 将当前周期数添加到指标中
session.report(metrics) # 向Ray Tune报告当前的训练指标
# 定义回调函数,如果tune可用,则在训练结束时调用on_fit_epoch_end
callbacks = {
'on_fit_epoch_end': on_fit_epoch_end,
} if tune else {}
代码说明:
- 导入模块:首先导入了
SETTINGS,用于检查Ray Tune的集成状态。 - 异常处理:通过
try-except结构来导入Ray相关模块,并确保Ray Tune集成已启用。如果未启用或导入失败,则将tune设置为None。 - 回调函数:定义了
on_fit_epoch_end函数,该函数在每个训练周期结束时被调用。它会检查Ray Tune会话是否启用,如果启用,则获取当前的训练指标并将其报告给Ray Tune。 - 回调字典:根据
tune是否可用,定义一个回调字典callbacks,其中包含on_fit_epoch_end函数。这使得在训练过程中可以动态地使用Ray Tune进行指标监控。```
这个程序文件是Ultralytics YOLO项目中的一个回调函数模块,主要用于与Ray Tune集成,以便在训练过程中进行超参数调优。首先,文件通过导入SETTINGS来检查Ray Tune集成是否启用。如果SETTINGS['raytune']为True,则尝试导入Ray库及其相关模块;如果导入失败或集成未启用,则将tune设置为None。
在这个模块中,定义了一个名为on_fit_epoch_end的函数,它会在每个训练周期结束时被调用。该函数的主要功能是将训练过程中的指标(metrics)发送到Ray Tune。具体来说,它首先检查Ray Tune的会话是否已启用,如果启用,则从训练器(trainer)中获取当前的指标,并将当前的训练周期(epoch)添加到指标中。最后,使用session.report(metrics)将这些指标报告给Ray Tune,以便进行后续的分析和调优。
最后,模块定义了一个callbacks字典,其中包含了on_fit_epoch_end回调函数,如果tune为None,则该字典为空。这种设计使得在不需要Ray Tune的情况下,代码仍然可以正常运行,而不会引发错误。整体来看,这个文件的目的是为Ultralytics YOLO的训练过程提供与Ray Tune的集成支持,以便更好地进行模型的超参数优化。
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
class ImageEncoderViT(nn.Module):
"""
使用视觉变换器(ViT)架构的图像编码器,将图像编码为紧凑的潜在空间。
编码器将图像分割为补丁,并通过一系列变换块处理这些补丁。
最终的编码表示通过一个颈部模块生成。
"""
def __init__(self, img_size: int = 1024, patch_size: int = 16, in_chans: int = 3, embed_dim: int = 768, depth: int = 12, out_chans: int = 256):
"""
初始化图像编码器的参数。
Args:
img_size (int): 输入图像的大小。
patch_size (int): 每个补丁的大小。
in_chans (int): 输入图像的通道数。
embed_dim (int): 补丁嵌入的维度。
depth (int): ViT的深度(变换块的数量)。
out_chans (int): 输出通道数。
"""
super().__init__()
self.img_size = img_size
# 初始化补丁嵌入模块
self.patch_embed = PatchEmbed(
kernel_size=(patch_size, patch_size),
stride=(patch_size, patch_size),
in_chans=in_chans,
embed_dim=embed_dim,
)
# 初始化变换块
self.blocks = nn.ModuleList()
for _ in range(depth):
block = Block(dim=embed_dim)
self.blocks.append(block)
# 颈部模块,用于进一步处理输出
self.neck = nn.Sequential(
nn.Conv2d(embed_dim, out_chans, kernel_size=1, bias=False),
nn.LayerNorm(out_chans),
nn.Conv2d(out_chans, out_chans, kernel_size=3, padding=1, bias=False),
nn.LayerNorm(out_chans),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""通过补丁嵌入、变换块和颈部模块处理输入。"""
x = self.patch_embed(x) # 将输入图像分割为补丁并嵌入
for blk in self.blocks: # 通过每个变换块
x = blk(x)
return self.neck(x.permute(0, 3, 1, 2)) # 调整维度并通过颈部模块
class Block(nn.Module):
"""变换块,包含多头注意力和前馈网络。"""
def __init__(self, dim: int):
"""
初始化变换块的参数。
Args:
dim (int): 输入通道数。
"""
super().__init__()
self.norm1 = nn.LayerNorm(dim) # 归一化层
self.attn = Attention(dim) # 注意力机制
self.norm2 = nn.LayerNorm(dim) # 归一化层
self.mlp = MLPBlock(embedding_dim=dim) # 前馈网络
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""执行变换块的前向传播。"""
shortcut = x # 残差连接
x = self.norm1(x) # 归一化
x = self.attn(x) # 注意力机制
x = shortcut + x # 残差连接
return x + self.mlp(self.norm2(x)) # 通过前馈网络并返回
class Attention(nn.Module):
"""多头注意力模块。"""
def __init__(self, dim: int):
"""
初始化注意力模块的参数。
Args:
dim (int): 输入通道数。
"""
super().__init__()
self.qkv = nn.Linear(dim, dim * 3) # 查询、键、值的线性变换
self.proj = nn.Linear(dim, dim) # 输出的线性变换
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""执行注意力机制的前向传播。"""
B, H, W, _ = x.shape # 获取输入的形状
qkv = self.qkv(x).reshape(B, H * W, 3, -1).permute(2, 0, 3, 1) # 计算qkv
q, k, v = qkv.unbind(0) # 分离q、k、v
attn = (q @ k.transpose(-2, -1)) * (q.size(-1) ** -0.5) # 计算注意力权重
attn = attn.softmax(dim=-1) # 归一化
x = (attn @ v).view(B, H, W, -1) # 计算输出
return self.proj(x) # 通过线性变换输出
class PatchEmbed(nn.Module):
"""图像到补丁嵌入的模块。"""
def __init__(self, kernel_size: Tuple[int, int] = (16, 16), in_chans: int = 3, embed_dim: int = 768):
"""
初始化补丁嵌入模块。
Args:
kernel_size (Tuple): 卷积核大小。
in_chans (int): 输入图像的通道数。
embed_dim (int): 补丁嵌入的维度。
"""
super().__init__()
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=kernel_size) # 卷积层用于补丁嵌入
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""计算补丁嵌入。"""
return self.proj(x).permute(0, 2, 3, 1) # 将输出维度调整为[B, H, W, C]
代码核心部分说明:
- ImageEncoderViT:图像编码器,使用ViT架构将图像编码为潜在空间。包含补丁嵌入、变换块和颈部模块。
- Block:变换块,包含多头注意力机制和前馈网络,支持残差连接。
- Attention:多头注意力模块,计算查询、键、值的线性变换并计算注意力权重。
- PatchEmbed:将输入图像分割为补丁并进行嵌入的模块,使用卷积层实现。
这些核心部分共同构成了一个基于ViT的图像编码器的基础结构。```
这个程序文件定义了一个图像编码器和一个提示编码器,主要用于图像处理和深度学习模型中的特征提取。文件中包含多个类,每个类都有其特定的功能。
首先,ImageEncoderViT类实现了一个基于视觉变换器(ViT)架构的图像编码器。该编码器的主要任务是将输入图像编码为一个紧凑的潜在空间表示。它通过将图像分割成多个小块(patches),并通过一系列的变换块(transformer blocks)处理这些小块来实现。该类的构造函数中定义了多个参数,包括输入图像的大小、补丁的大小、嵌入维度、变换块的深度、注意力头的数量等。编码器还包括一个“neck”模块,用于进一步处理输出。
在forward方法中,输入图像首先通过补丁嵌入模块进行处理,如果存在位置嵌入,则将其添加到输出中。接着,输出经过所有的变换块,最后通过neck模块生成最终的编码表示。
接下来是PromptEncoder类,它用于编码不同类型的提示信息,包括点、框和掩码。这些提示信息用于输入到SAM(Segment Anything Model)的掩码解码器中。该类生成稀疏和密集的嵌入表示。构造函数中定义了嵌入维度、输入图像大小、掩码输入通道数等参数,并初始化了多个嵌入模块。
forward方法负责处理输入的点、框和掩码,返回稀疏和密集的嵌入表示。它首先获取批量大小,然后根据输入的提示类型调用相应的嵌入方法,最后返回生成的嵌入。
PositionEmbeddingRandom类用于生成随机空间频率的位置信息编码。它的构造函数中初始化了一个高斯矩阵,用于生成位置编码。forward方法根据指定的大小生成位置编码。
Block类实现了变换器块,支持窗口注意力和残差传播。它的构造函数中定义了多个参数,包括输入通道数、注意力头的数量、MLP比率等。forward方法执行前向传播,计算注意力和MLP的输出。
Attention类实现了多头注意力机制,支持相对位置嵌入。它的构造函数中定义了输入通道数、注意力头的数量等参数。forward方法计算注意力分数并应用到输入上。
此外,文件中还定义了一些辅助函数,如window_partition和window_unpartition,用于将输入张量划分为窗口和恢复原始形状,以及get_rel_pos和add_decomposed_rel_pos,用于处理相对位置嵌入。
最后,PatchEmbed类实现了图像到补丁嵌入的转换,通过卷积操作将输入图像转换为补丁嵌入表示。
整体来看,这个程序文件通过定义多个类和方法,实现了一个功能强大的图像编码器和提示编码器,能够有效地处理图像数据并提取特征。
```python
import json
import time
from pathlib import Path
import numpy as np
import torch
from ultralytics.cfg import get_cfg, get_save_dir
from ultralytics.nn.autobackend import AutoBackend
from ultralytics.utils import LOGGER, TQDM, callbacks
from ultralytics.utils.checks import check_imgsz
from ultralytics.utils.ops import Profile
from ultralytics.utils.torch_utils import select_device, smart_inference_mode
class BaseValidator:
"""
BaseValidator 类用于创建验证器的基类。
属性:
args: 验证器的配置参数。
dataloader: 用于验证的数据加载器。
model: 要验证的模型。
device: 用于验证的设备。
speed: 记录处理速度的字典。
save_dir: 保存结果的目录。
"""
def __init__(self, dataloader=None, save_dir=None, args=None):
"""
初始化 BaseValidator 实例。
参数:
dataloader: 用于验证的数据加载器。
save_dir: 保存结果的目录。
args: 验证器的配置参数。
"""
self.args = get_cfg(overrides=args) # 获取配置
self.dataloader = dataloader # 数据加载器
self.model = None # 模型初始化
self.device = None # 设备初始化
self.save_dir = save_dir or get_save_dir(self.args) # 保存目录
self.speed = {'preprocess': 0.0, 'inference': 0.0, 'loss': 0.0, 'postprocess': 0.0} # 速度记录
@smart_inference_mode()
def __call__(self, model=None):
"""
支持验证预训练模型或正在训练的模型。
"""
model = AutoBackend(model or self.args.model, device=select_device(self.args.device)) # 初始化模型
self.device = model.device # 更新设备
self.dataloader = self.dataloader or self.get_dataloader(self.args.data, self.args.batch) # 获取数据加载器
# 进行验证过程
for batch_i, batch in enumerate(TQDM(self.dataloader)):
# 预处理
batch = self.preprocess(batch)
# 推理
preds = model(batch['img'])
# 更新指标
self.update_metrics(preds, batch)
stats = self.get_stats() # 获取统计信息
self.print_results() # 打印结果
return stats # 返回统计信息
def preprocess(self, batch):
"""预处理输入批次数据。"""
return batch # 返回处理后的批次数据
def update_metrics(self, preds, batch):
"""根据预测结果和批次数据更新指标。"""
pass # 更新指标的具体实现
def get_stats(self):
"""返回模型性能的统计信息。"""
return {} # 返回空字典,实际实现中应返回统计信息
def print_results(self):
"""打印模型预测的结果。"""
pass # 打印结果的具体实现
def get_dataloader(self, dataset_path, batch_size):
"""根据数据集路径和批量大小获取数据加载器。"""
raise NotImplementedError('get_dataloader function not implemented for this validator') # 抛出未实现异常
代码注释说明:
- 类定义:
BaseValidator类是验证器的基类,负责处理模型验证的核心逻辑。 - 初始化方法:
__init__方法用于初始化验证器的配置、数据加载器、模型和设备等。 - 调用方法:
__call__方法是验证的主要入口,支持对预训练模型或正在训练的模型进行验证。 - 预处理方法:
preprocess方法用于对输入批次数据进行预处理,具体实现可以根据需求扩展。 - 更新指标方法:
update_metrics方法用于根据模型的预测结果和实际批次数据更新性能指标,具体实现待完善。 - 获取统计信息:
get_stats方法返回模型性能的统计信息,当前实现返回空字典。 - 打印结果:
print_results方法用于打印模型的预测结果,具体实现待完善。 - 获取数据加载器:
get_dataloader方法用于根据数据集路径和批量大小获取数据加载器,当前实现抛出未实现异常。
这些核心部分和注释提供了代码的基本结构和功能概述,便于理解和扩展。```
这个程序文件 ultralytics/engine/validator.py 是一个用于验证 YOLO 模型准确性的基类,主要用于在数据集的测试或验证分割上评估模型的性能。该文件包含了一个名为 BaseValidator 的类,该类负责处理模型验证的各个步骤,包括数据加载、模型推理、损失计算、结果统计等。
在文件开头,提供了使用该验证器的示例命令,说明可以使用不同格式的模型文件进行验证,包括 PyTorch、ONNX、TensorRT 等格式。接下来,文件导入了一些必要的库和模块,包括 JSON 处理、时间管理、路径操作、NumPy 和 PyTorch。
BaseValidator 类的构造函数初始化了一些重要的属性,例如数据加载器、保存结果的目录、进度条、模型配置等。构造函数还会检查输入图像的尺寸,并创建保存结果的目录。
该类的核心功能通过 __call__ 方法实现,该方法支持对预训练模型或正在训练的模型进行验证。根据传入的参数,方法会选择合适的设备(如 CPU 或 GPU),并根据模型类型加载相应的模型。接着,它会检查数据集的有效性,并创建数据加载器。
在验证过程中,程序会记录每个批次的处理时间,并更新性能指标。它还会在每个批次结束时运行回调函数,以便在验证过程中执行自定义操作。最终,验证结果会被打印出来,并根据需要保存为 JSON 格式。
BaseValidator 类还定义了一些辅助方法,例如 match_predictions 用于将预测结果与真实标签进行匹配,add_callback 和 run_callbacks 用于管理回调函数,get_dataloader 和 build_dataset 用于数据加载(这两个方法需要在子类中实现)。
此外,还有一些方法用于预处理和后处理数据,初始化和更新性能指标,以及获取和检查统计信息。这些方法的具体实现通常会在子类中定义,以适应不同的验证需求。
总体而言,这个文件为 YOLO 模型的验证提供了一个灵活的框架,允许用户根据不同的需求进行扩展和定制。
```python
import os
import torch
import yaml
from ultralytics import YOLO # 导入YOLO模型库
if __name__ == '__main__': # 确保该模块被直接运行时才执行以下代码
# 设置训练参数
workers = 1 # 数据加载的工作进程数
batch = 8 # 每个批次的样本数量,需根据显存/内存调整
device = "0" if torch.cuda.is_available() else "cpu" # 判断是否使用GPU
# 获取数据集配置文件的绝对路径
data_path = abs_path(f'datasets/data/data.yaml', path_type='current')
# 将路径格式转换为Unix风格
unix_style_path = data_path.replace(os.sep, '/')
# 获取目录路径
directory_path = os.path.dirname(unix_style_path)
# 读取YAML文件,保持原有顺序
with open(data_path, 'r') as file:
data = yaml.load(file, Loader=yaml.FullLoader)
# 修改数据集路径
if 'train' in data and 'val' in data and 'test' in data:
data['train'] = directory_path + '/train' # 设置训练集路径
data['val'] = directory_path + '/val' # 设置验证集路径
data['test'] = directory_path + '/test' # 设置测试集路径
# 将修改后的数据写回YAML文件
with open(data_path, 'w') as file:
yaml.safe_dump(data, file, sort_keys=False)
# 加载YOLO模型配置和预训练权重
model = YOLO(r"C:\codeseg\codenew\50+种YOLOv8算法改进源码大全和调试加载训练教程(非必要)\改进YOLOv8模型配置文件\yolov8-seg-C2f-Faster.yaml").load("./weights/yolov8s-seg.pt")
# 开始训练模型
results = model.train(
data=data_path, # 指定训练数据的配置文件路径
device=device, # 指定使用的设备(GPU或CPU)
workers=workers, # 指定数据加载的工作进程数
imgsz=640, # 输入图像的大小
epochs=100, # 训练的轮数
batch=batch, # 每个批次的样本数量
)
代码注释说明:
- 导入库:导入必要的库,包括操作系统库、PyTorch、YAML解析库和YOLO模型库。
- 主程序入口:使用
if __name__ == '__main__':确保只有在直接运行该脚本时才执行以下代码。 - 训练参数设置:设置数据加载的工作进程数、批次大小和设备类型(GPU或CPU)。
- 数据集路径处理:获取数据集配置文件的绝对路径,并将其转换为Unix风格路径,方便后续处理。
- 读取和修改YAML文件:读取YAML文件,修改训练、验证和测试集的路径,并将修改后的内容写回文件。
- 加载YOLO模型:根据指定的配置文件和预训练权重加载YOLO模型。
- 模型训练:调用模型的
train方法开始训练,传入数据路径、设备、工作进程数、图像大小、训练轮数和批次大小等参数。```
该程序文件train.py的主要功能是使用YOLO(You Only Look Once)模型进行目标检测的训练。程序首先导入了必要的库,包括操作系统相关的os、深度学习框架torch、YAML文件处理库yaml、YOLO模型的库ultralytics以及用于图形界面的matplotlib。
在程序的主入口部分,首先设置了一些训练参数,包括工作进程数workers、批次大小batch和设备类型device。设备类型的选择是基于当前系统是否支持CUDA,如果支持则使用GPU(设备编号为"0"),否则使用CPU。
接下来,程序通过abs_path函数获取数据集配置文件data.yaml的绝对路径,并将其转换为Unix风格的路径。然后,程序读取该YAML文件,解析其中的数据,并获取数据集的目录路径。特别地,程序检查YAML文件中是否包含train、val和test字段,如果存在,则将这些字段的路径修改为相对于数据集目录的路径,并将修改后的内容写回到YAML文件中。
程序中还提到,不同的YOLO模型对设备的要求不同,如果当前模型出现错误,可以尝试其他模型进行测试。接着,程序加载了一个YOLOv8模型的配置文件,并加载了预训练的权重文件。
最后,程序调用model.train()方法开始训练模型,传入了训练数据的配置文件路径、设备类型、工作进程数、输入图像大小、训练的epoch数量以及批次大小等参数。通过这些设置,程序能够有效地进行目标检测模型的训练。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 27
27 0
0- 0



 已为社区贡献92条内容
已为社区贡献92条内容

所有评论(0)