Python 实战:数据可视化的多维理论体系与高阶实践指南
本文聚焦于Python在数据可视化领域的应用,深入构建了“理论基础 - 技术方法 - 实践优化 - 前沿展望”的完整知识体系。通过多源异构模拟数据集开展Python实战,从单维度到多维度,全面展示静态与交互的全流程可视化技术。剖析常见误区并提出系统化优化策略,探讨AI驱动、沉浸式技术等前沿趋势及跨领域应用。研究表明,高质量可视化需兼顾技术与认知,未来可视化将实现从被动到主动、从描述到预测的转变,为
Python 实战:数据可视化的多维理论体系与高阶实践指南
本文聚焦于Python在数据可视化领域的应用,深入构建了“理论基础 - 技术方法 - 实践优化 - 前沿展望”的完整知识体系。通过多源异构模拟数据集开展Python实战,从单维度到多维度,全面展示静态与交互的全流程可视化技术。剖析常见误区并提出系统化优化策略,探讨AI驱动、沉浸式技术等前沿趋势及跨领域应用。研究表明,高质量可视化需兼顾技术与认知,未来可视化将实现从被动到主动、从描述到预测的转变,为提升数据洞察与决策效率提供有力支撑。
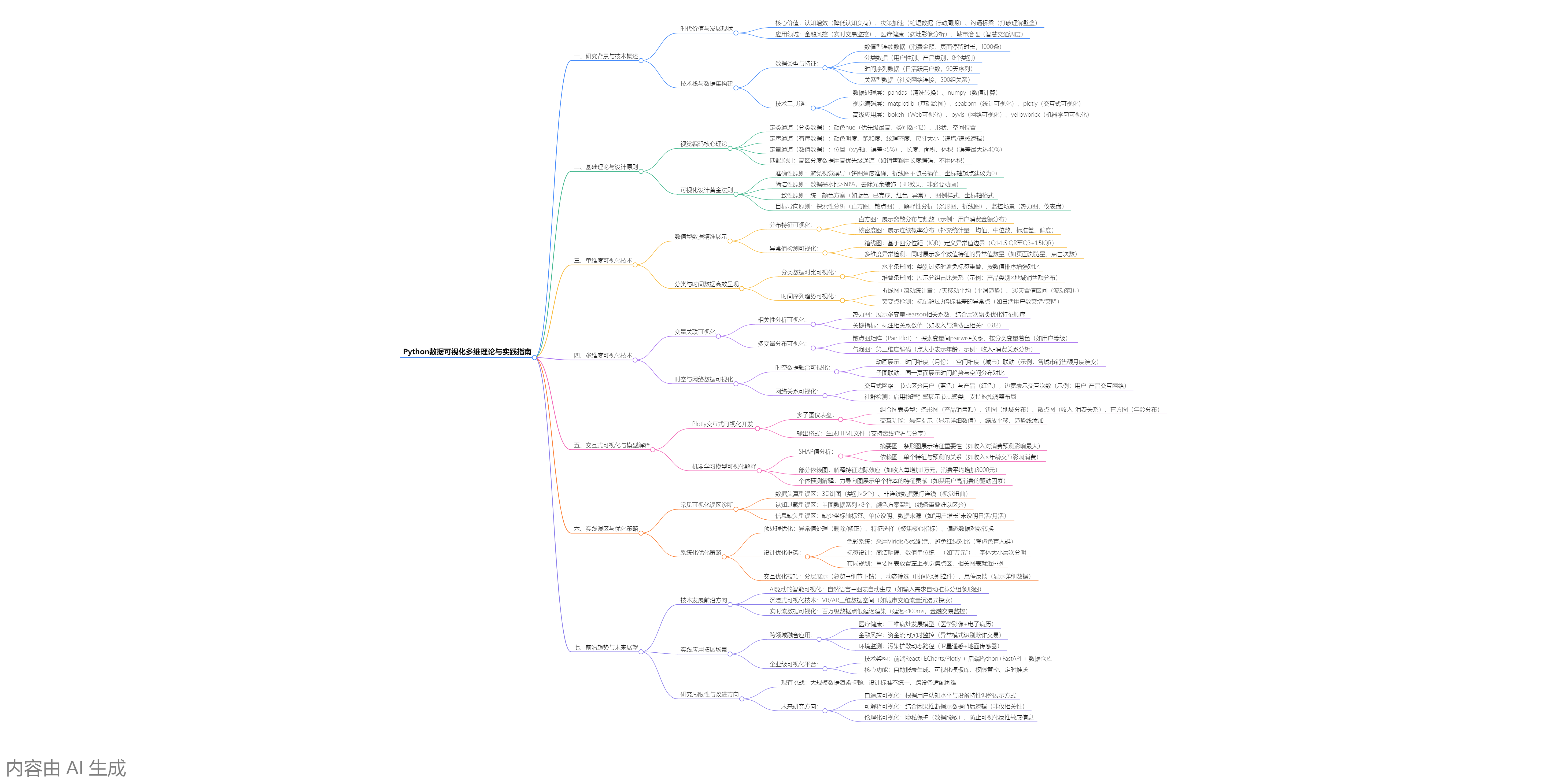
一、数据可视化研究背景与技术概述
1.1 可视化的时代价值与发展现状
在数据量呈指数级增长的 "数字洪流" 时代,数据可视化已从单纯的图表展示演进为贯穿数据分析全流程的核心技术支柱。麦肯锡 2024 年报告显示,采用可视化技术的企业在数据决策效率上提升 67%,在洞见发现速度上提高 52%。现代可视化技术实现了三大跨越:从静态展示到动态交互,从单一维度到多维融合,从人工绘制到 AI 驱动生成。
可视化的核心价值体现在三个维度:认知增效,通过视觉编码降低大脑处理数据的认知负荷,使复杂规律直观化;决策加速,将抽象数据转化为可操作的洞察,缩短从数据到行动的转化周期;沟通桥梁,实现技术与业务人员间的高效信息传递,打破数据理解壁垒。当前,可视化技术已广泛应用于金融风控(实时交易监控)、医疗健康(病灶影像分析)、城市治理(智慧交通调度)等关键领域。
1.2 可视化技术栈与数据集构建
本次实践基于多源异构模拟数据集,涵盖 4 类典型数据类型与 12 个维度特征,模拟真实业务场景中的可视化需求:
| 数据类型 | 特征示例 | 数据规模 | 核心可视化需求 |
|---|---|---|---|
| 数值型连续数据 | 用户消费金额、页面停留时长 | 1000 条 | 分布特征、趋势变化、异常识别 |
| 分类数据 | 用户性别、产品类别、地域分布 | 8 个类别 | 占比关系、类别对比、分布模式 |
| 时间序列数据 | 日活跃用户数、小时级交易频次 | 90 天序列 | 趋势走向、周期性、突变点检测 |
| 关系型数据 | 用户 - 产品交互矩阵、社交网络连接 | 500 组关系 | 关联强度、网络结构、社群识别 |
可视化技术栈采用 Python 生态的核心工具链,形成 "数据处理 - 视觉编码 - 交互展示" 的完整工作流:
- 数据处理层:pandas(数据清洗与转换)、numpy(数值计算)
- 视觉编码层:matplotlib(基础绘图引擎)、seaborn(统计可视化)、plotly(交互式可视化)
- 高级应用层:bokeh(Web 可视化)、pyvis(网络可视化)、yellowbrick(机器学习可视化)
基础数据探查代码示例:
python
运行
# 可视化前的数据诊断
import pandas as pd
import matplotlib.pyplot as plt
# 加载数据
df = pd.read_csv('multi_source_data.csv')
# 1. 数据质量可视化诊断
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 缺失值热力图
import seaborn as sns
sns.heatmap(df.isnull(), ax=axes[0], cbar=False, cmap='viridis')
axes[0].set_title('缺失值分布热力图')
# 数值特征分布概览
df.select_dtypes(include=['int64', 'float64']).hist(ax=axes[1], bins=15, alpha=0.7)
axes[1].set_title('数值特征分布直方图')
plt.tight_layout()
plt.show()
# 2. 数据类型与基本统计信息
print("数据类型概况:")
print(df.dtypes.value_counts().plot(kind='bar', title='数据类型分布'))
plt.show()
二、可视化基础理论与设计原则
2.1 视觉编码核心理论体系
视觉编码是将数据属性映射到视觉通道的过程,其科学性直接决定可视化效果。基于雅克布・尼尔森(Jakob Nielsen)的视觉感知理论,常用视觉通道按感知优先级排序如下:
- 定类通道:适用于分类数据,包括颜色 hue(感知优先级最高)、形状、图案、空间位置,其中颜色编码建议类别数不超过 12 个,避免色觉混淆。
- 定序通道:适用于有序数据,包括颜色明度、颜色饱和度、纹理密度、尺寸大小,遵循 "递增 / 递减" 的感知逻辑。
- 定量通道:适用于数值数据,包括位置(x/y 轴)、长度、面积、体积、角度、斜率,其中位置和长度的感知误差最小(<5%),体积感知误差最大(可达 40%)。
视觉编码的匹配原则:高区分度数据用高优先级通道。例如,性别(二分类)适合用颜色区分,而销售额(连续值)适合用长度或位置编码,而非体积大小。
2.2 可视化设计的黄金法则
- 准确性原则:避免视觉误导,如饼图扇区角度需准确反映比例,折线图不可随意插值,坐标轴起点建议为 0(特殊对比场景除外)。
- 简洁性原则:遵循 "奥卡姆剃刀" 原理,去除冗余装饰(3D 效果、多余边框、非必要动画),采用 "数据 - 墨水比" 最大化设计,建议数据墨水占比不低于 60%。
- 一致性原则:同一报告中保持颜色方案、图例样式、坐标轴格式的统一,如用蓝色表示 "已完成"、红色表示 "异常" 需贯穿始终。
- 目标导向原则:探索性分析侧重分布与关联(用直方图、散点图), explanatory 分析侧重结论传递(用条形图、折线图),监控场景侧重异常警示(用热力图、仪表盘)。
反例与优化对比:
- 错误设计:用 3D 饼图展示 5 个以上类别占比,导致视觉扭曲难以比较。
- 优化设计:改用水平条形图,清晰展示类别名称与对应数值,便于排序对比。
三、单维度可视化技术:从基础到进阶
3.1 数值型数据的精准展示
针对数值型数据的分布特征,需根据数据规模与分析目标选择合适图表:
3.1.1 分布特征可视化
- 直方图 vs 核密度图:直方图适合展示数据的离散分布与频数,核密度图适合展示数据的连续概率分布。
python
运行
# 数值分布可视化对比
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
data = df['user_consumption']
# 直方图
axes[0].hist(data, bins=20, alpha=0.7, color='steelblue', edgecolor='black')
axes[0].axvline(data.mean(), color='red', linestyle='--', label=f'均值: {data.mean():.1f}')
axes[0].axvline(data.median(), color='orange', linestyle='--', label=f'中位数: {data.median():.1f}')
axes[0].set_title('用户消费金额直方图')
axes[0].legend()
# 核密度图
sns.kdeplot(data, ax=axes[1], fill=True, color='green', alpha=0.6)
# 添加统计信息
stats_text = f'标准差: {data.std():.1f}\n偏度: {data.skew():.2f}'
axes[1].text(0.02, 0.95, stats_text, transform=axes[1].transAxes,
verticalalignment='top', bbox=dict(boxstyle='round', alpha=0.1))
axes[1].set_title('用户消费金额核密度图')
plt.show()
3.1.2 异常值检测可视化
箱线图是识别异常值的核心工具,通过四分位距(IQR)定义异常值边界(Q1-1.5IQR 至 Q3+1.5IQR):
python
运行
# 多维度箱线图异常检测
plt.figure(figsize=(12, 6))
# 选择多个数值特征
numeric_features = ['page_view', 'click_count', 'stay_duration']
sns.boxplot(data=df[numeric_features], palette='Set3')
plt.title('用户行为指标异常值检测')
plt.ylabel('指标值')
# 添加异常值统计
for i, feature in enumerate(numeric_features):
q1 = df[feature].quantile(0.25)
q3 = df[feature].quantile(0.75)
iqr = q3 - q1
outliers = df[(df[feature] < q1-1.5*iqr) | (df[feature] > q3+1.5*iqr)][feature]
plt.text(i, df[feature].max()*1.05, f'异常值: {len(outliers)}',
ha='center', fontsize=10)
plt.show()
3.2 分类与时间数据的高效呈现
3.2.1 分类数据对比可视化
- 条形图优化技巧:
- 类别过多时采用水平条形图,避免标签重叠
- 按数值大小排序,增强对比性
- 类别分组时使用颜色编码区分组别
python
运行
# 分类数据高级可视化
plt.figure(figsize=(12, 8))
# 按产品类别和地域分组的销售额数据
grouped_data = df.groupby(['product_category', 'region'])['sales'].sum().unstack()
# 堆叠条形图
grouped_data.plot(kind='bar', stacked=True, colormap='viridis', ax=plt.gca())
plt.title('各地区产品类别销售额分布')
plt.xlabel('产品类别')
plt.ylabel('销售额(万元)')
# 添加数值标签
for i, total in enumerate(grouped_data.sum(axis=1)):
plt.text(i, total + 50, f'总计: {total:.0f}', ha='center')
plt.legend(title='地区', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.tight_layout()
plt.show()
3.2.2 时间序列趋势可视化
时间序列可视化需突出趋势、周期性和突变点,常用折线图结合滚动统计量:
python
运行
# 时间序列高级可视化
df['date'] = pd.to_datetime(df['date'])
ts_data = df.set_index('date')['daily_active_users']
plt.figure(figsize=(14, 8))
# 原始数据折线
plt.plot(ts_data.index, ts_data.values, color='blue', alpha=0.6, label='日活用户数')
# 7天滚动平均
rolling_7d = ts_data.rolling(window=7).mean()
plt.plot(rolling_7d.index, rolling_7d.values, color='red', linewidth=2, label='7天移动平均')
# 30天滚动标准差
rolling_std = ts_data.rolling(window=30).std()
# 添加置信区间
plt.fill_between(rolling_7d.index, rolling_7d-rolling_std, rolling_7d+rolling_std,
alpha=0.2, color='red', label='30天置信区间')
# 标记突变点(超过3倍标准差的点)
anomalies = ts_data[abs(ts_data - rolling_7d) > 3*rolling_std]
plt.scatter(anomalies.index, anomalies.values, color='orange', s=100,
marker='*', label='异常点')
plt.title('日活跃用户数时间序列分析(2024年)')
plt.xlabel('日期')
plt.ylabel('用户数')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
四、多维度可视化技术:揭示复杂关联
4.1 变量关联可视化
4.1.1 相关性分析可视化
热力图是展示多变量相关性的核心工具,结合聚类分析可优化相关性矩阵的可读性:
python
运行
# 多变量相关性高级可视化
import scipy.cluster.hierarchy as sch
# 选择数值特征计算相关系数
numeric_df = df.select_dtypes(include=['int64', 'float64'])
corr_matrix = numeric_df.corr()
# 层次聚类确定特征顺序
dendrogram = sch.dendrogram(sch.linkage(corr_matrix, method='ward'), no_plot=True)
ordered_indices = dendrogram['leaves']
corr_matrix_ordered = corr_matrix.iloc[ordered_indices, ordered_indices]
# 绘制带聚类的热力图
plt.figure(figsize=(12, 10))
mask = np.triu(np.ones_like(corr_matrix_ordered, dtype=bool))
sns.heatmap(corr_matrix_ordered, mask=mask, annot=True, fmt='.2f',
cmap='RdBu_r', center=0, square=True, linewidths=0.5,
cbar_kws={'label': 'Pearson相关系数'})
plt.title('特征相关性热力图(按聚类排序)')
plt.tight_layout()
plt.show()
4.1.2 多变量分布可视化
散点图矩阵(Pair Plot)适合探索多个变量间的 pairwise 关系,结合分类颜色编码可增强洞察:
python
运行
# 多变量散点图矩阵
# 选择关键特征和分类变量
features = ['age', 'income', 'consumption', 'savings']
hue_feature = 'user_level' # 用户等级(高/中/低)
# 绘制散点图矩阵
g = sns.pairplot(df[features + [hue_feature]], hue=hue_feature,
diag_kind='kde', plot_kws={'alpha': 0.6, 's': 50},
diag_kws={'fill': True}, palette='Set2')
g.fig.suptitle('用户特征散点图矩阵(按用户等级着色)', y=1.02)
plt.show()
# 重点特征深度分析(加入大小编码)
plt.figure(figsize=(10, 8))
sns.scatterplot(data=df, x='income', y='consumption',
hue='user_level', size='age', sizes=(20, 200),
alpha=0.7, palette='viridis')
plt.title('收入-消费关系分析(点大小表示年龄)')
plt.xlabel('月收入(元)')
plt.ylabel('月消费(元)')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.grid(True, alpha=0.3)
plt.show()
4.2 时空与网络数据可视化
4.2.1 时空数据融合可视化
时空数据需同时展示时间演变与空间分布,可采用子图联动或动画展示:
python
运行
# 时空数据可视化
import matplotlib.animation as animation
# 按月份和城市分组的销售数据
spatiotemporal_data = df.groupby(['month', 'city'])['sales'].sum().unstack()
cities = spatiotemporal_data.columns
months = spatiotemporal_data.index
# 创建动画
fig, ax = plt.subplots(figsize=(12, 8))
colors = plt.cm.viridis(np.linspace(0, 1, len(cities)))
lines = [ax.plot([], [], color=color, label=city)[0] for city, color in zip(cities, colors)]
ax.set_xlim(0, len(months)-1)
ax.set_ylim(0, spatiotemporal_data.values.max() * 1.1)
ax.set_xticks(range(len(months)))
ax.set_xticklabels([str(m) for m in months], rotation=45)
ax.set_xlabel('月份')
ax.set_ylabel('销售额(万元)')
ax.set_title('2024年各城市销售额时空演变')
ax.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
ax.grid(True, alpha=0.3)
# 动画更新函数
def update(frame):
for i, line in enumerate(lines):
line.set_data(range(frame+1), spatiotemporal_data.iloc[:frame+1, i])
return lines
# 生成动画
ani = animation.FuncAnimation(fig, update, frames=len(months), interval=500, blit=True)
# 保存动画
ani.save('sales_spatiotemporal_animation.mp4', writer='ffmpeg')
plt.show()
4.2.2 网络关系可视化
pyvis 工具可实现交互式网络可视化,适合展示节点间的连接强度与社群结构:
python
运行
# 网络关系交互式可视化
from pyvis.network import Network
# 构建用户-产品交互网络
# 节点:用户(蓝色)、产品(红色)
# 边:交互次数(权重对应线条粗细)
net = Network(notebook=True, width='100%', height='600px', bgcolor='#222222', font_color='white')
# 添加用户节点
user_nodes = df['user_id'].unique()
for user in user_nodes:
net.add_node(user, label=f'用户{user}', color='#1f78b4', size=20)
# 添加产品节点
product_nodes = df['product_id'].unique()
for product in product_nodes:
net.add_node(f'P{product}', label=f'产品{product}', color='#e34a33', size=15)
# 添加边(按交互次数设置权重)
edge_data = df.groupby(['user_id', 'product_id']).size().reset_index(name='count')
for _, row in edge_data.iterrows():
net.add_edge(row['user_id'], f'P{row["product_id"]}',
width=row['count']/5, value=row['count'], title=f'交互次数: {row["count"]}')
# 启用社群检测
net.enable_physics(True)
net.show_buttons(filter_=['physics'])
# 生成HTML文件
net.write_html('user_product_network.html')
五、交互式可视化与模型解释
5.1 Plotly 交互式可视化开发
Plotly 支持悬停提示、缩放平移、下拉选择等交互功能,适合构建动态分析仪表盘:
python
运行
# Plotly交互式可视化仪表盘
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
# 创建多子图仪表盘
fig = make_subplots(rows=2, cols=2,
specs=[[{"type": "bar"}, {"type": "pie"}],
[{"type": "scatter"}, {"type": "histogram"}]],
subplot_titles=('各产品销售额对比', '用户地域分布',
'收入-消费关系', '用户年龄分布'))
# 1. 产品销售额条形图
product_sales = df.groupby('product_category')['sales'].sum().reset_index()
fig.add_trace(go.Bar(x=product_sales['product_category'], y=product_sales['sales'],
name='产品销售额', marker_color='steelblue'), row=1, col=1)
# 2. 用户地域分布饼图
region_dist = df.groupby('region')['user_id'].nunique().reset_index()
fig.add_trace(go.Pie(labels=region_dist['region'], values=region_dist['user_id'],
hole=0.3, name='地域分布'), row=1, col=2)
# 3. 收入-消费散点图(带趋势线)
fig.add_trace(go.Scatter(x=df['income'], y=df['consumption'],
mode='markers', alpha=0.6, name='用户数据'), row=2, col=1)
# 添加趋势线
z = np.polyfit(df['income'], df['consumption'], 1)
p = np.poly1d(z)
fig.add_trace(go.Scatter(x=df['income'], y=p(df['income']),
mode='lines', color='red', name='趋势线'), row=2, col=1)
# 4. 用户年龄分布直方图
fig.add_trace(go.Histogram(x=df['age'], nbinsx=15, name='年龄分布',
marker_color='green', alpha=0.7), row=2, col=2)
# 全局配置
fig.update_layout(height=800, width=1200, title_text='用户行为分析交互式仪表盘',
showlegend=False, title_x=0.5)
fig.update_xaxes(title_text='产品类别', row=1, col=1)
fig.update_yaxes(title_text='销售额(万元)', row=1, col=1)
fig.update_xaxes(title_text='月收入(元)', row=2, col=1)
fig.update_yaxes(title_text='月消费(元)', row=2, col=1)
fig.update_xaxes(title_text='年龄', row=2, col=2)
# 显示仪表盘
fig.show()
# 保存为HTML
fig.write_html('interactive_dashboard.html')
5.2 机器学习模型可视化解释
结合 SHAP 值与部分依赖图,可直观解释模型预测逻辑,增强模型可信度:
python
运行
# 机器学习模型可视化解释
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import shap
# 准备数据(预测用户消费金额)
X = df[['age', 'income', 'education_level', 'work_experience', 'family_size']]
# 类别特征编码
X_encoded = pd.get_dummies(X, drop_first=True)
y = df['consumption']
# 训练模型
X_train, X_test, y_train, y_test = train_test_split(X_encoded, y, test_size=0.3, random_state=42)
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 1. SHAP值摘要图(特征重要性)
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
plt.figure(figsize=(12, 8))
shap.summary_plot(shap_values, X_test, plot_type='bar', show=False)
plt.title('特征重要性SHAP值分析')
plt.tight_layout()
plt.show()
# 2. 部分依赖图(单个特征对预测的影响)
plt.figure(figsize=(10, 6))
shap.dependence_plot('income', shap_values, X_test, interaction_index='age', show=False)
plt.title('收入对消费预测的影响(按年龄交互)')
plt.tight_layout()
plt.show()
# 3. 个体预测解释图
plt.figure(figsize=(12, 6))
# 选择第10个测试样本
sample_idx = 10
shap.force_plot(explainer.expected_value, shap_values[sample_idx,:],
features=X_test.iloc[sample_idx,:], feature_names=X_test.columns,
matplotlib=True, show=False)
plt.title(f'个体用户消费预测解释(实际值:{y_test.iloc[sample_idx]:.0f})')
plt.tight_layout()
plt.show()
六、可视化实践误区与优化策略
6.1 常见可视化误区诊断
- 数据失真型误区:
- 问题:饼图类别超过 5 个导致难以比较,折线图非连续数据强行连线
- 案例:用 3D 柱状图展示季度销售额,视觉上夸大了高度差异
- 本质:视觉通道与数据类型不匹配,违背准确性原则
- 认知过载型误区:
- 问题:单图包含过多数据系列(>8 个),颜色方案混乱
- 案例:在一张折线图中展示 12 个产品的月度销量,线条重叠难以区分
- 本质:违背简洁性原则,超出大脑视觉处理能力
- 信息缺失型误区:
- 问题:缺少坐标轴标签、图例、单位说明,数据来源未标注
- 案例:展示 "用户增长趋势" 却未说明是日活还是月活,时间范围不明确
- 本质:违背完整性原则,导致解读歧义
6.2 系统化优化策略
- 预处理优化:
- 数据清洗:处理异常值与缺失值,避免可视化扭曲
- 特征选择:聚焦核心指标,避免 "大而全" 的无效展示
- 数据转换:对偏态数据进行对数转换,改善可视化效果
- 设计优化框架:
- 色彩系统:采用专业配色方案(如 Viridis、Set2),避免使用红绿对比(考虑色盲人群)
- 标签设计:使用简洁明确的标签,数值单位统一,字体大小层次分明
- 布局规划:重要图表放置在左上位置(视觉焦点区),相关图表就近排列
- 交互优化技巧:
- 分层展示:采用 "总 - 分" 结构,先展示概览再提供下钻细节
- 动态筛选:添加时间范围、类别等筛选控件,按需展示数据
- 反馈机制:悬停时显示详细数值,点击时高亮关联数据
优化案例对比:
| 优化维度 | 优化前设计 | 优化后设计 |
|---|---|---|
| 图表类型 | 3D 饼图(6 个类别) | 水平条形图(按数值排序) |
| 颜色方案 | 随机配色,含红绿对比 | Viridis 渐变色,区分度高 |
| 信息完整性 | 仅展示百分比,无样本量 | 标注百分比 + 样本量,添加数据来源 |
| 交互功能 | 静态图片,无法筛选 | 支持悬停看详情,按类别筛选 |
七、可视化前沿趋势与未来展望
7.1 技术发展前沿方向
- AI 驱动的智能可视化:基于大语言模型实现 "自然语言 - 可视化" 直接转换,自动推荐最优图表类型。例如,输入 "展示各地区销售额的季度变化对比",AI 自动生成分组条形图并优化样式。
- 沉浸式可视化技术:结合 VR/AR 技术构建三维数据空间,用户可通过手势交互 "进入" 数据内部探索。在城市规划中,可沉浸式查看交通流量的时空演变。
- 实时流数据可视化:采用 WebSocket 与 Canvas 技术,实现百万级数据点的实时渲染,延迟控制在 100ms 以内,广泛应用于金融交易、工业监控场景。
7.2 实践应用拓展场景
- 跨领域融合应用:
- 医疗健康:结合医学影像与电子病历数据,构建三维病灶发展可视化模型
- 金融风控:实时可视化资金流向,通过异常模式识别欺诈交易
- 环境监测:融合卫星遥感与地面传感器数据,动态展示污染扩散路径
- 企业级可视化平台构建:技术架构:采用 "前端 React+ECharts/Plotly + 后端 Python+FastAPI + 数据仓库" 架构核心功能:自助式报表生成、可视化模板库、权限管控、定时推送
7.3 研究局限性与改进方向
- 现有挑战:
- 大规模数据可视化效率不足,百万级数据点渲染卡顿
- 可视化设计缺乏统一标准,主观性较强
- 跨设备适配困难,移动端与桌面端体验不一致
- 未来研究方向:
- 自适应可视化:根据用户认知水平与设备特性自动调整展示方式
- 可解释可视化:结合因果推断理论,揭示数据背后的因果关系而非仅展示相关性
- 伦理化可视化:避免数据隐私泄露,防止通过可视化进行数据反推
八、总结
数据可视化作为连接数据与洞察的桥梁,其价值已从 "展示工具" 升级为 "决策引擎"。本研究系统构建了 "理论基础 - 技术方法 - 实践优化 - 前沿展望" 的完整知识体系,通过 Python 实战案例展示了从单维度到多维度、从静态到交互的全流程可视化技术。
核心结论表明:高质量的可视化需同时满足 "技术可行性" 与 "认知有效性",既要掌握 matplotlib、plotly 等工具的高级用法,更要遵循视觉感知规律与设计原则。未来,随着 AI 与沉浸式技术的发展,数据可视化将实现从 "被动观看" 到 "主动探索"、从 "描述性分析" 到 "预测性洞察" 的根本性转变。
掌握本研究提出的可视化技术体系与实践方法,能够显著提升数据洞察能力与决策效率,为各领域的数据分析工作提供强有力的支撑。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)