近端策略优化(PPO)优化PID控制器,打开强化学习算法新方式
本期采用SIMULINK搭建强化学习优化PID控制模型,采用近端策略优化(Proximal Policy Optimization, PPO)算法实现对PID的优化控制。实验设置了一个常见的二阶模型,模型可随意更改。
PPO原理概述
PPO算法由OpenAI 在 2017年 提出。PPO是一种策略梯度方法,用于解决强化学习中的连续控制问题。它的主要目标是:在保证训练稳定性的同时,实现高效的采样效率。PPO算法专注于简化训练过程,克服传统策略梯度方法(如TRPO)的计算复杂性,同时保证训练效果。
在传统的策略梯度方法中,我们通过收集数据来更新我们的策略(即Actor),但更新后的策略与收集数据时的旧策略会相差很大。这会导致两个问题:
-
训练不稳定:一次不好的更新可能会让策略性能急剧下降,且难以恢复。
-
采样效率低:由于策略变化太大,之前收集的数据就不再适用于新的策略,必须重新采样,非常浪费。
PPO通过一个巧妙的设计解决了这个问题:它限制新策略和旧策略之间的差异,确保每次更新都只是“一小步”,避免破坏性的巨大更新。
PPO是对策略梯度算法(policy gradient, PG)的一种改进,通过策略critic与动作actor相互配合学习使智能体agent得 到的奖励最大化,即actor-critic算法,如图:
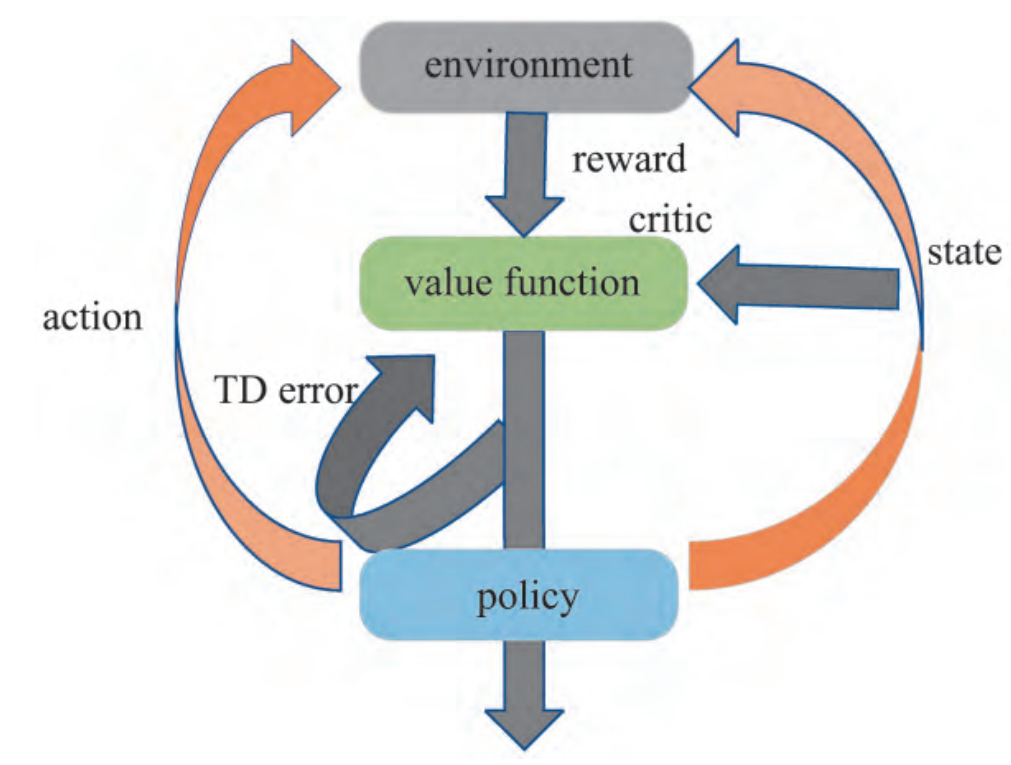
在PG算法中,不同训练步长对训练效果影响 较大。在训练时,较小的步长会导致训练过程出 现局部难以收敛的情况,反之,就会导致梯度增 长过快而丢失训练细节,因此,PPO修改了最初 的PG公式,不再使用PG算法而是加入了新的目 标函数,并使用了import sampling重要采样方法, 解决了PG算法对于训练步长难以确定的缺点,提 升了训练效果和速度。
PPO控制器设计
PID 算法由于其易用性和可靠性,被广泛应 用于各种工业控制场景,是控制中十分经典的算法,PID算法由P(比例环节)、I(积分环节)、D(微 分调节)组成。在调节误差 e 时,P 环节越大调节 速度越快,但会给系统带来振荡;I环节可对输入 量进行调整,用于消除静态误差,值越大调节速 度越快,同样也会带来振荡;D 环节可对误差的 趋势进行预测,提前做出预判性调整,可减小振 荡,但会引入高频噪声。因为 PID 算法的上述特 点,在一些非线性系统下,会表现出时滞性和振荡性且依赖于工作人员的专业经验,因此,本期在 PID 的基础上加入 PPO 算法进行 PID 参数整定 以提升控制性能并达到自适应效果,克服传统 PID算法单一参数的缺点。
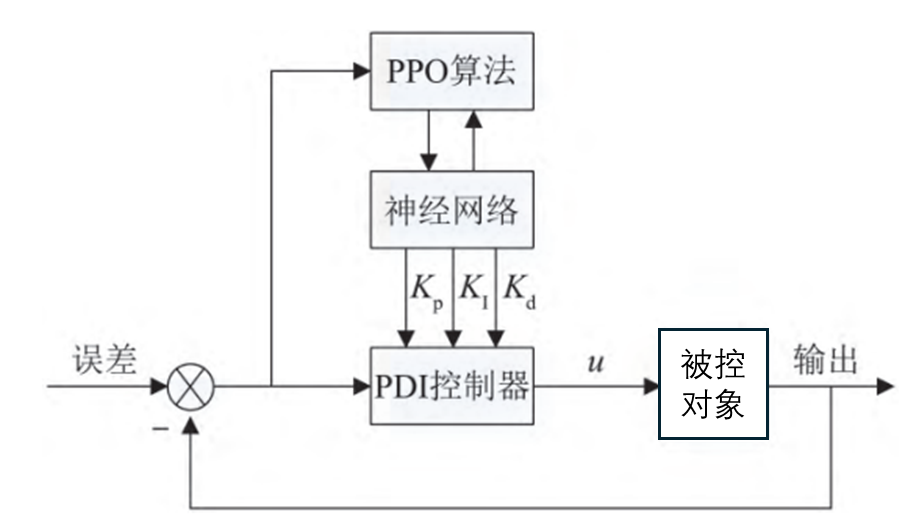
奖励函数设置
奖励函数在PPO-PID中直接影响智能体行为和控制策略的学习过程。一个合理设计的奖励函数能够引导智能体在调整PID参数时,优化控制性能,而不合理的奖励函数则可能导致控制效果差,甚至使智能体偏离期望的控制行为。
本期代码奖励函数设置为经典的ITAE指标,并考虑加权控制器U的变化能量(防止控制器频繁动作)。
时间乘绝对误差积分(ITAE)公式如下:
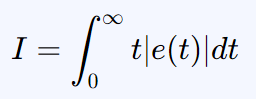
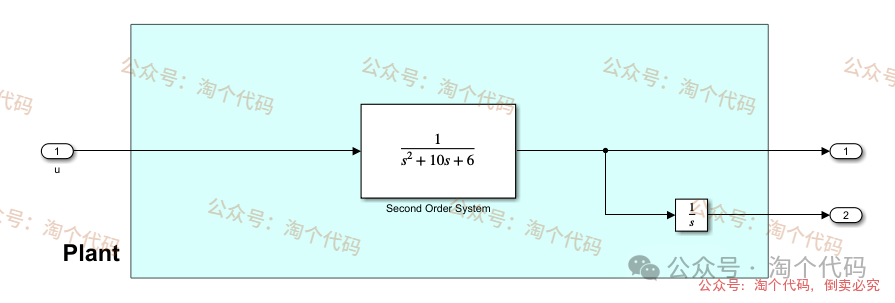
被控对象采用simulink搭建,简单易修改!这里采用一个典型的二阶系统。你也可以修改这里为任何模型!
结果展示
案例1:输入为阶跃信号
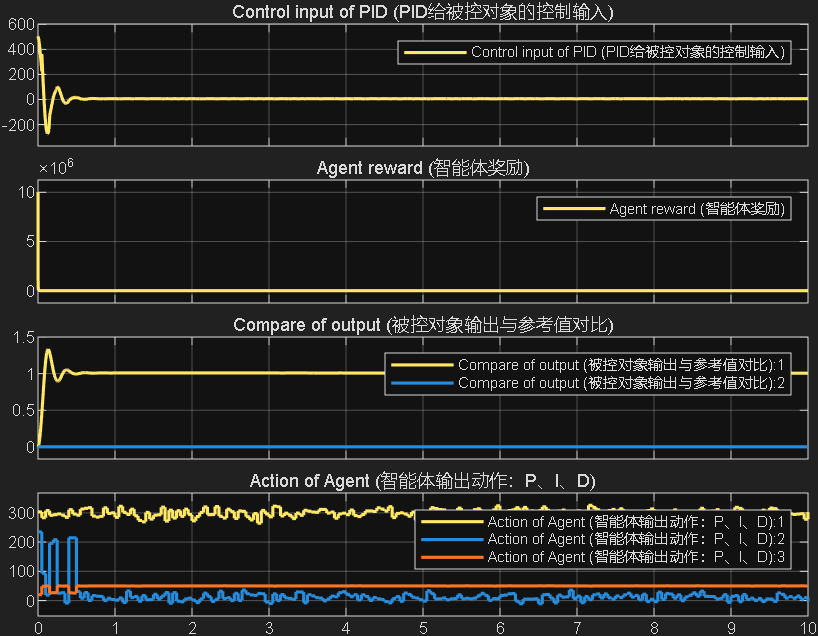
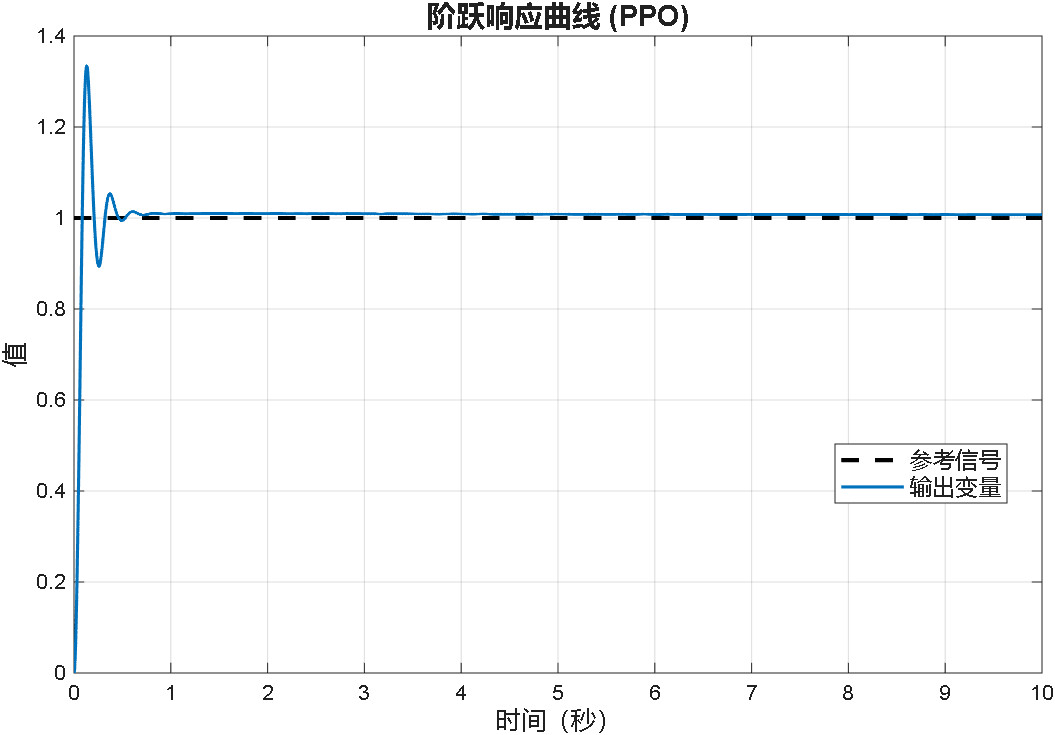
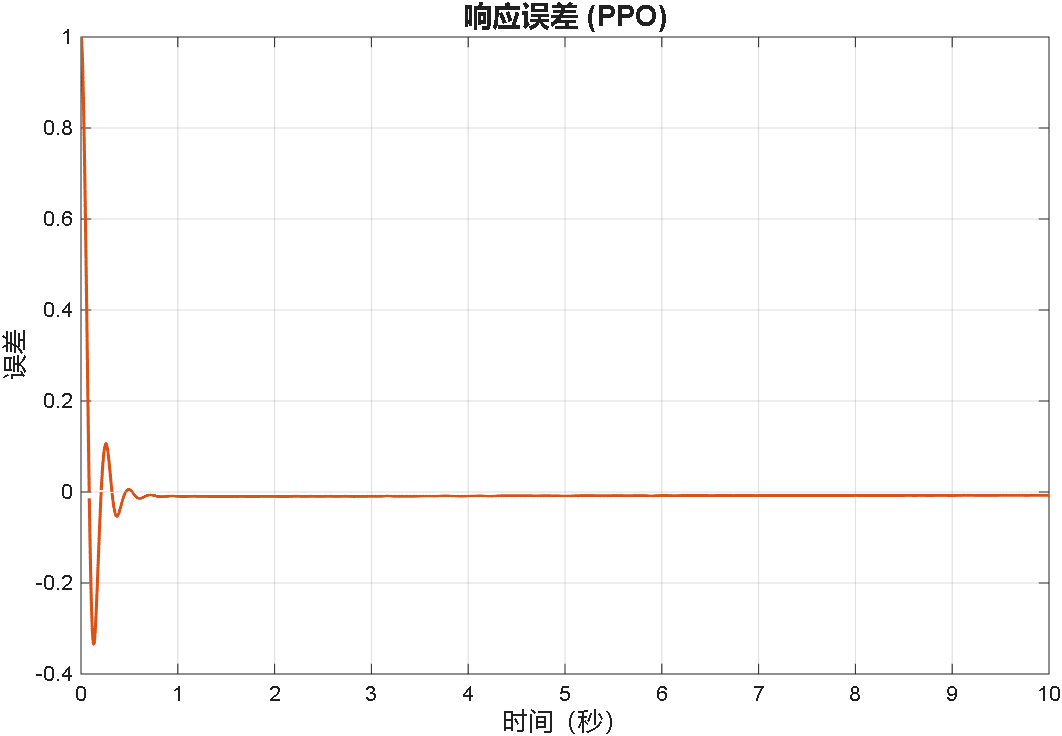
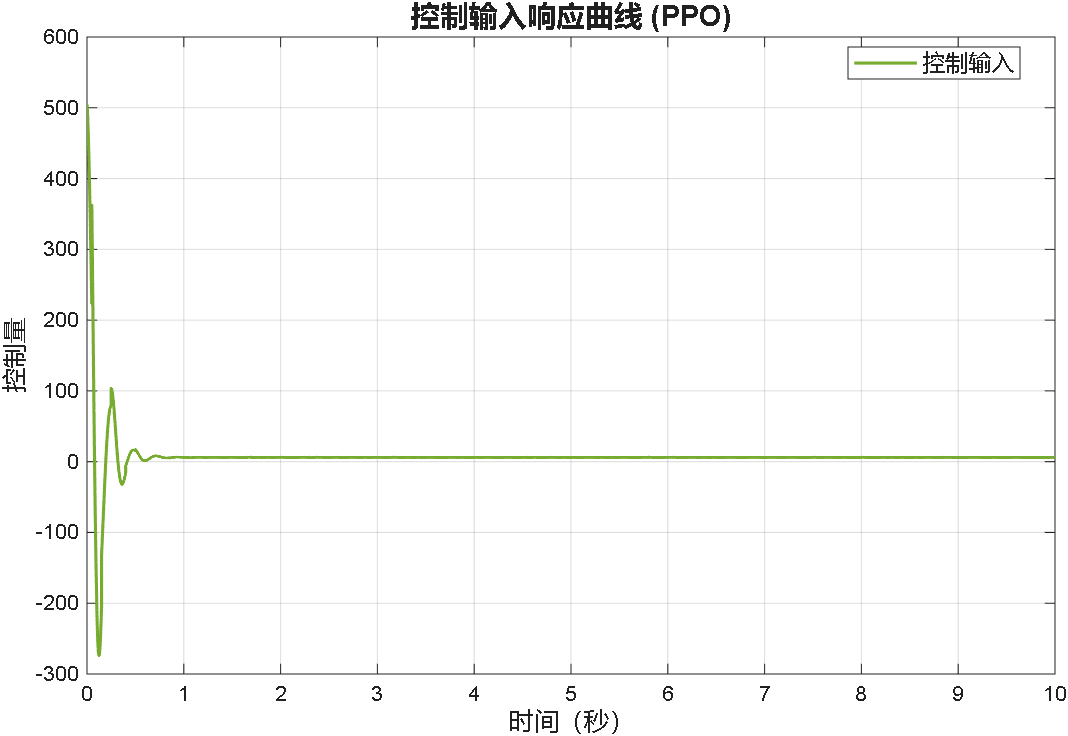
案例2:输入为正弦信号
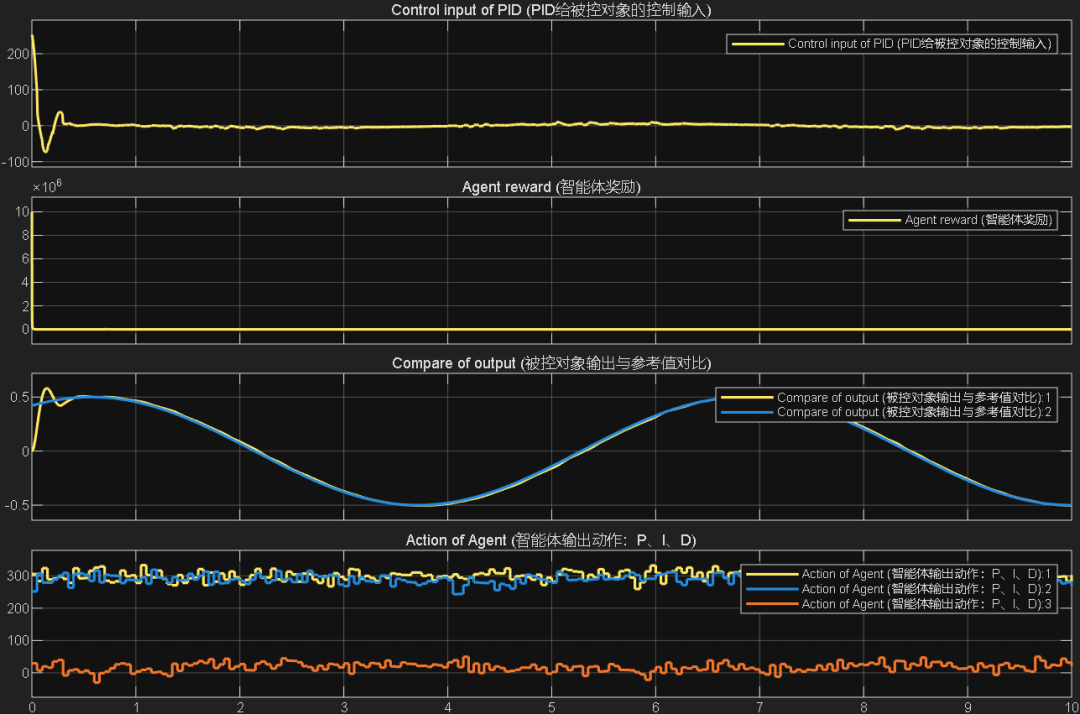
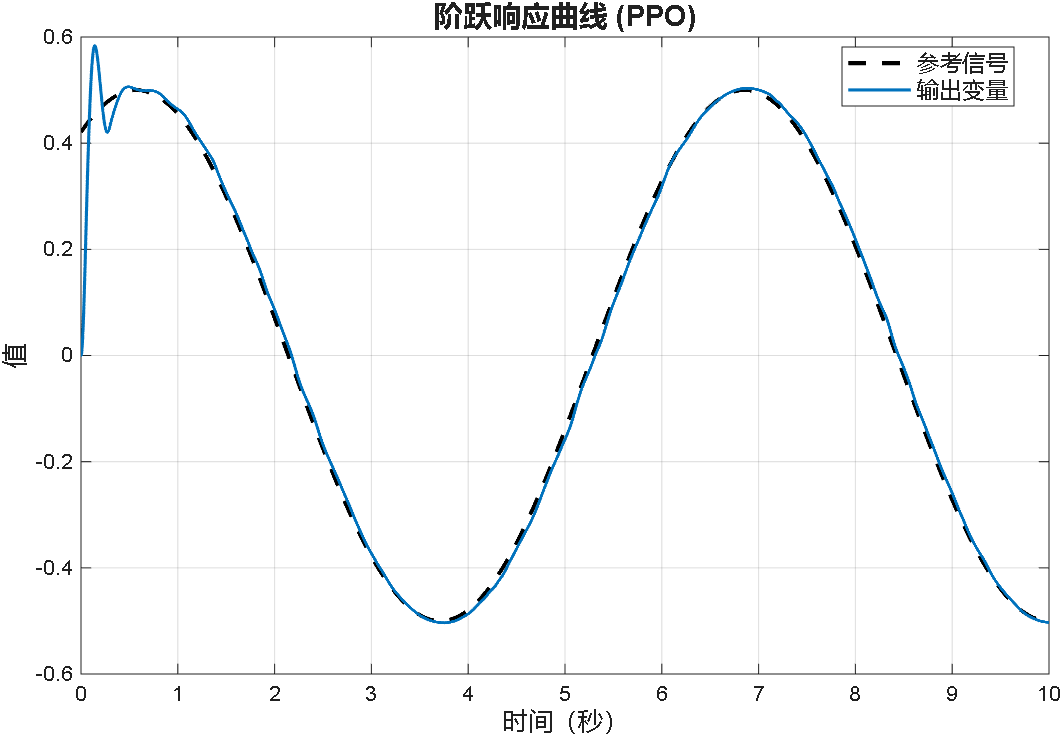
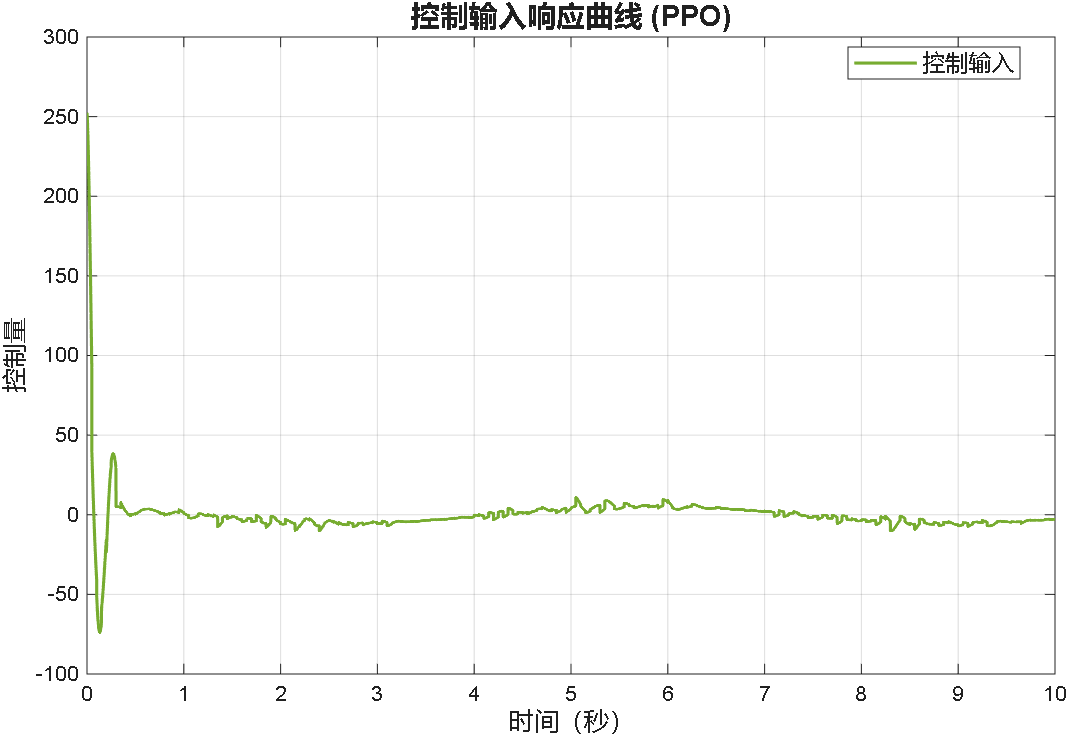
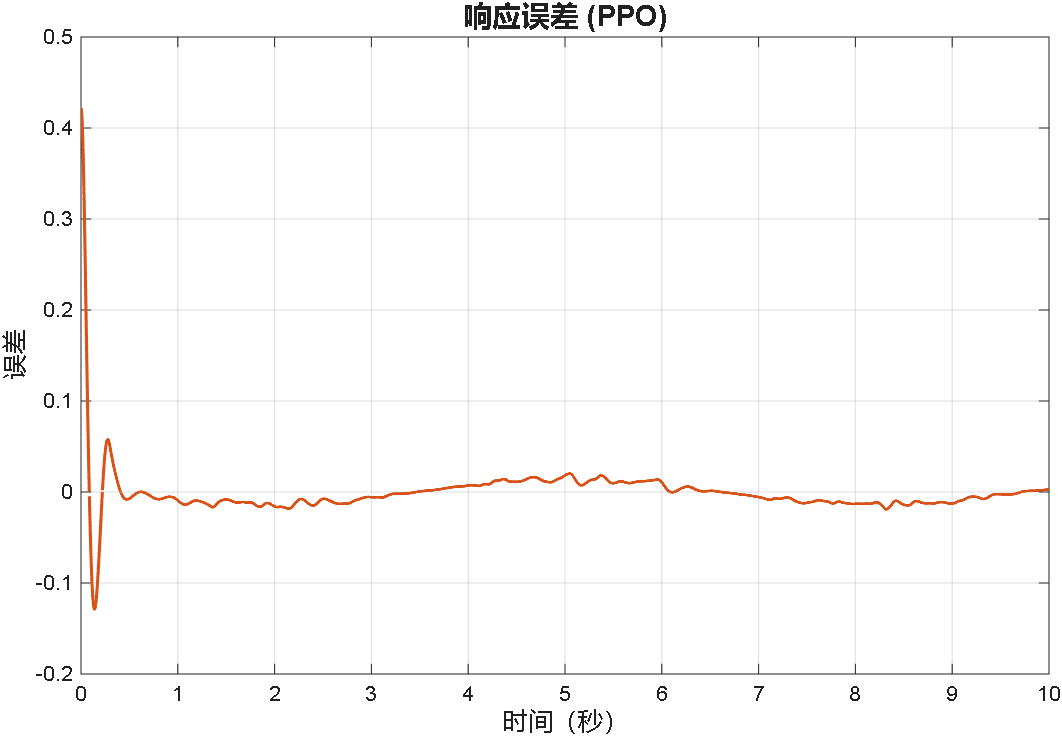
案例3:前两秒为阶跃,之后突变为正弦
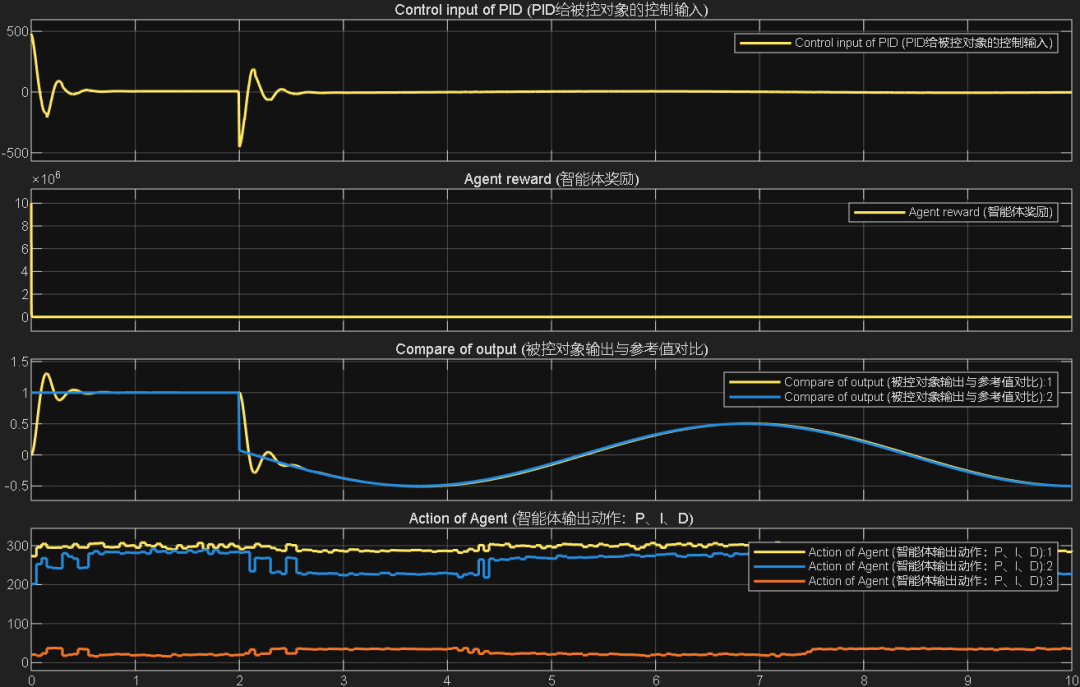
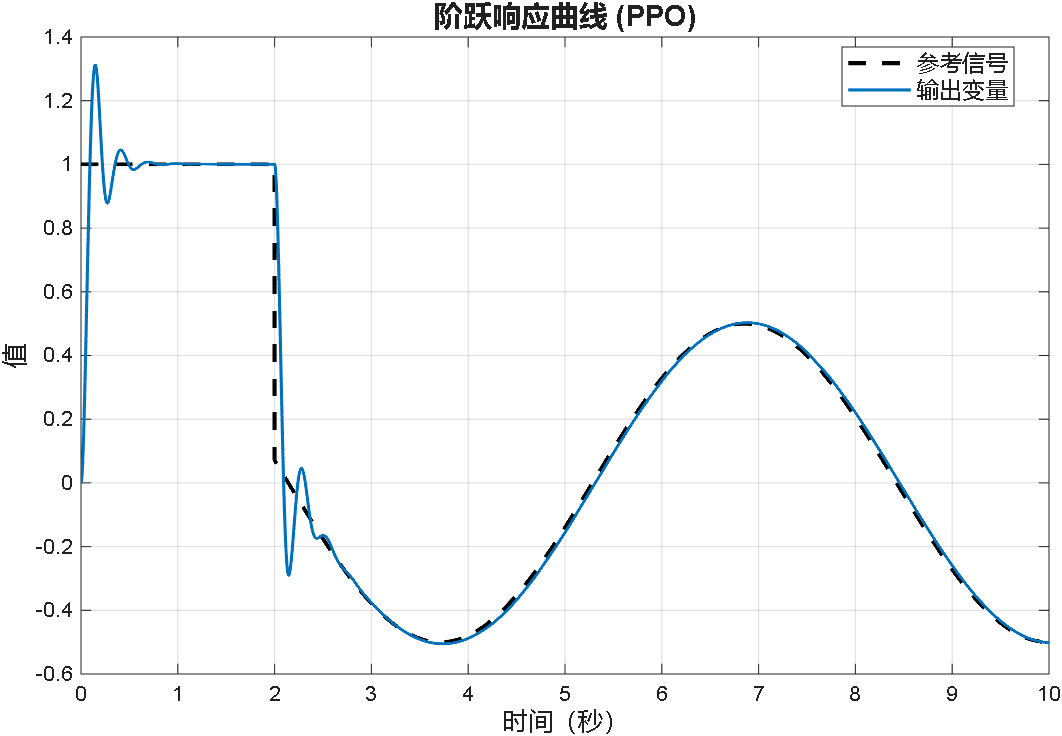
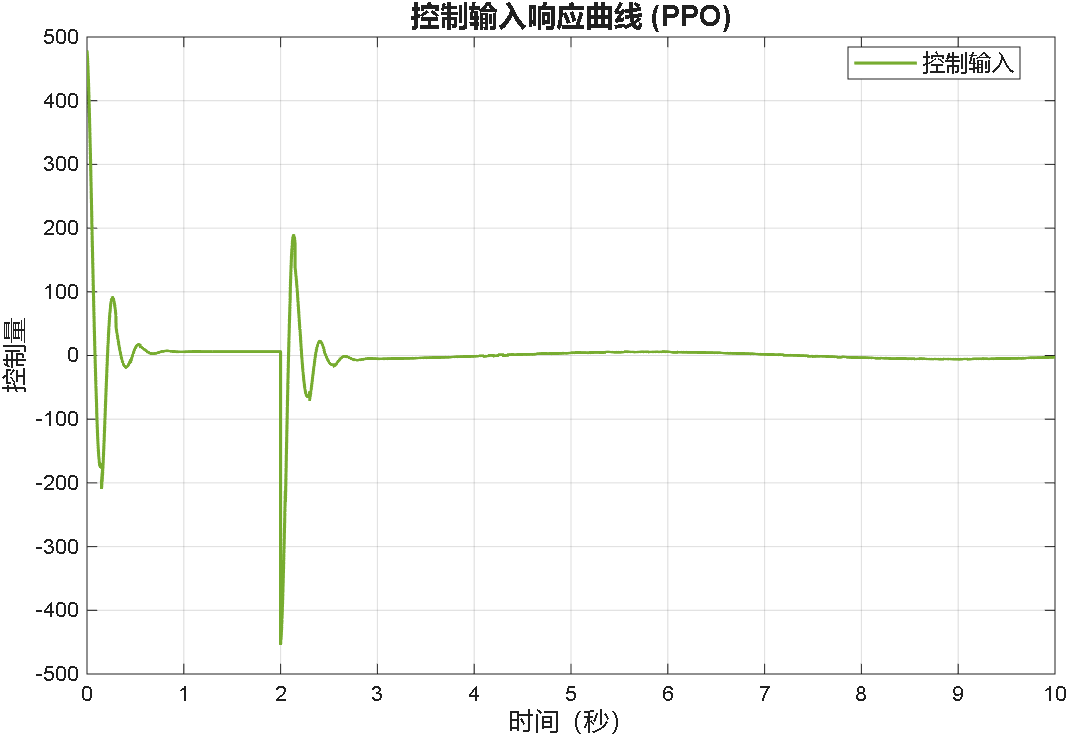
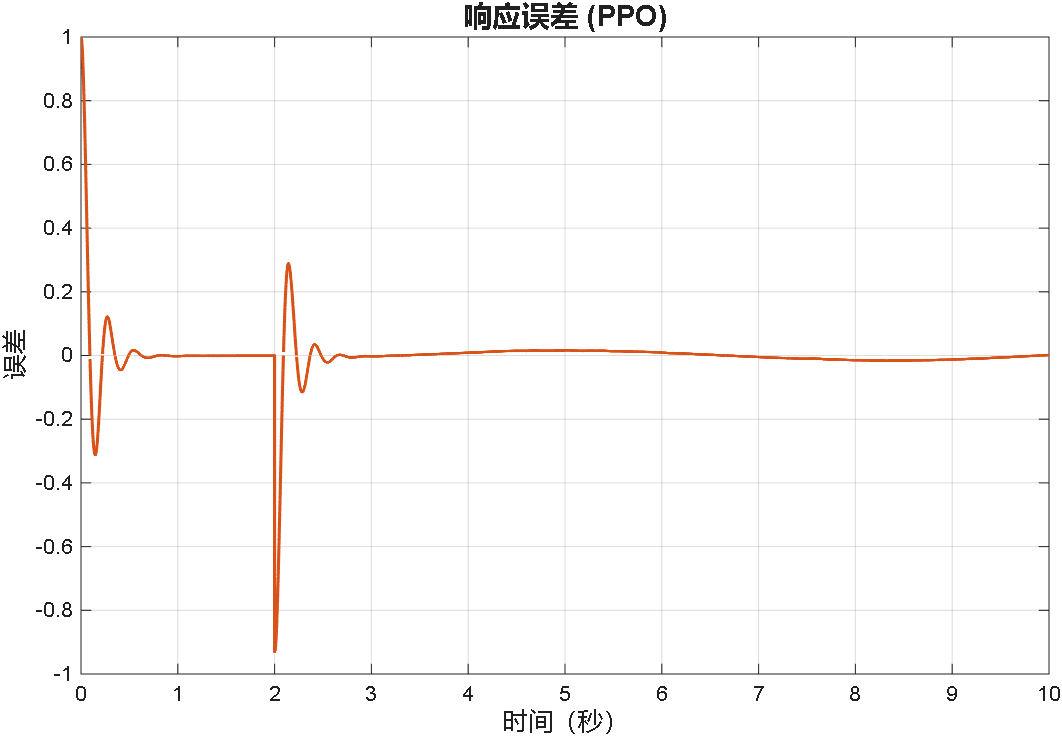
综合以上三个案例可以看出,PPO在优化PID参数方面的性能,绝对杠杠滴!无论怎么变输入,控制器就是能跟踪上。
代码目录

执行此程序,必须使用2024a以上版本的MATLAB。
代码获取
链接:
点击下方卡片获取
获取更多代码:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)