【完整源码+数据集+部署教程】Github图像验证识别系统源码&数据集分享 [yolov8-seg-C2f-Faster-EMA&yolov8-seg-SPPF-LSKA等50+全套改进创新点发刊_
【完整源码+数据集+部署教程】Github图像验证识别系统源码&数据集分享[yolov8-seg-C2f-Faster-EMA&yolov8-seg-SPPF-LSKA等50+全套改进创新点发刊_
背景意义
随着人工智能技术的迅猛发展,计算机视觉领域的应用日益广泛,尤其是在图像识别和目标检测方面。YOLO(You Only Look Once)系列模型因其高效性和实时性,成为了目标检测领域的重要工具。YOLOv8作为该系列的最新版本,结合了深度学习的先进技术,进一步提升了检测精度和速度。然而,尽管YOLOv8在许多应用场景中表现出色,但在特定领域,尤其是图像验证和识别系统的构建中,仍然存在一些挑战。
本研究旨在基于改进的YOLOv8模型,构建一个针对Github图像验证的识别系统。Github作为全球最大的开源代码托管平台,拥有海量的图像资源,涵盖了从软件开发到数据科学等多个领域。随着开源项目的不断增加,如何有效地对Github中的图像进行分类和验证,成为了一个亟待解决的问题。现有的图像处理技术往往无法满足这一需求,特别是在处理复杂场景和多类别图像时,识别准确率和效率均显得不足。因此,基于YOLOv8的改进,开发一个高效的图像验证识别系统,具有重要的学术价值和实际意义。
在本研究中,我们将使用一个包含1800张图像的数据集,该数据集涵盖了12个类别,具体包括120、150、180、210、240、270、30、300、330、360、60和90等不同的类目。这些类别的多样性使得图像验证系统的设计和实现面临更大的挑战。通过对这些图像进行实例分割,我们能够更精确地识别出图像中的各个对象,从而提高系统的整体性能。此外,针对YOLOv8模型的改进将集中在网络结构的优化、数据增强技术的应用以及训练策略的调整等方面,以期在保持实时性的同时,进一步提升识别精度。
本研究的意义不仅在于推动计算机视觉技术的发展,更在于为Github平台上的图像资源管理提供一种有效的解决方案。通过构建高效的图像验证识别系统,开发者和用户能够更快速地找到所需的图像资源,进而提高工作效率。此外,该系统的成功实施还将为其他开源平台的图像管理提供借鉴,推动相关领域的研究和应用。
综上所述,基于改进YOLOv8的Github图像验证识别系统的研究,不仅具有重要的理论价值,还具备广泛的应用前景。通过对图像识别技术的深入探索,我们期望能够为开源社区的可持续发展贡献一份力量,同时为计算机视觉领域的研究提供新的思路和方法。
图片效果
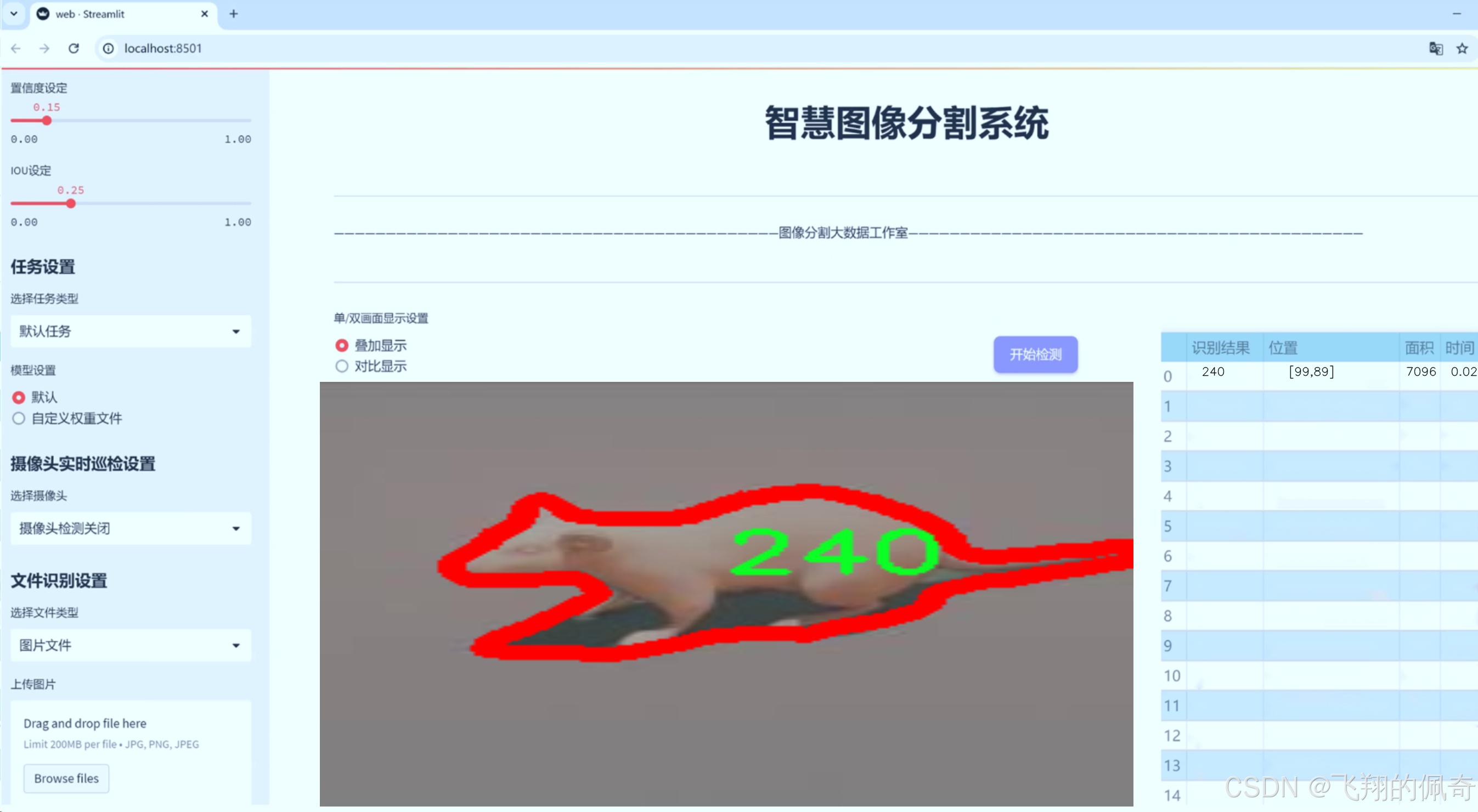
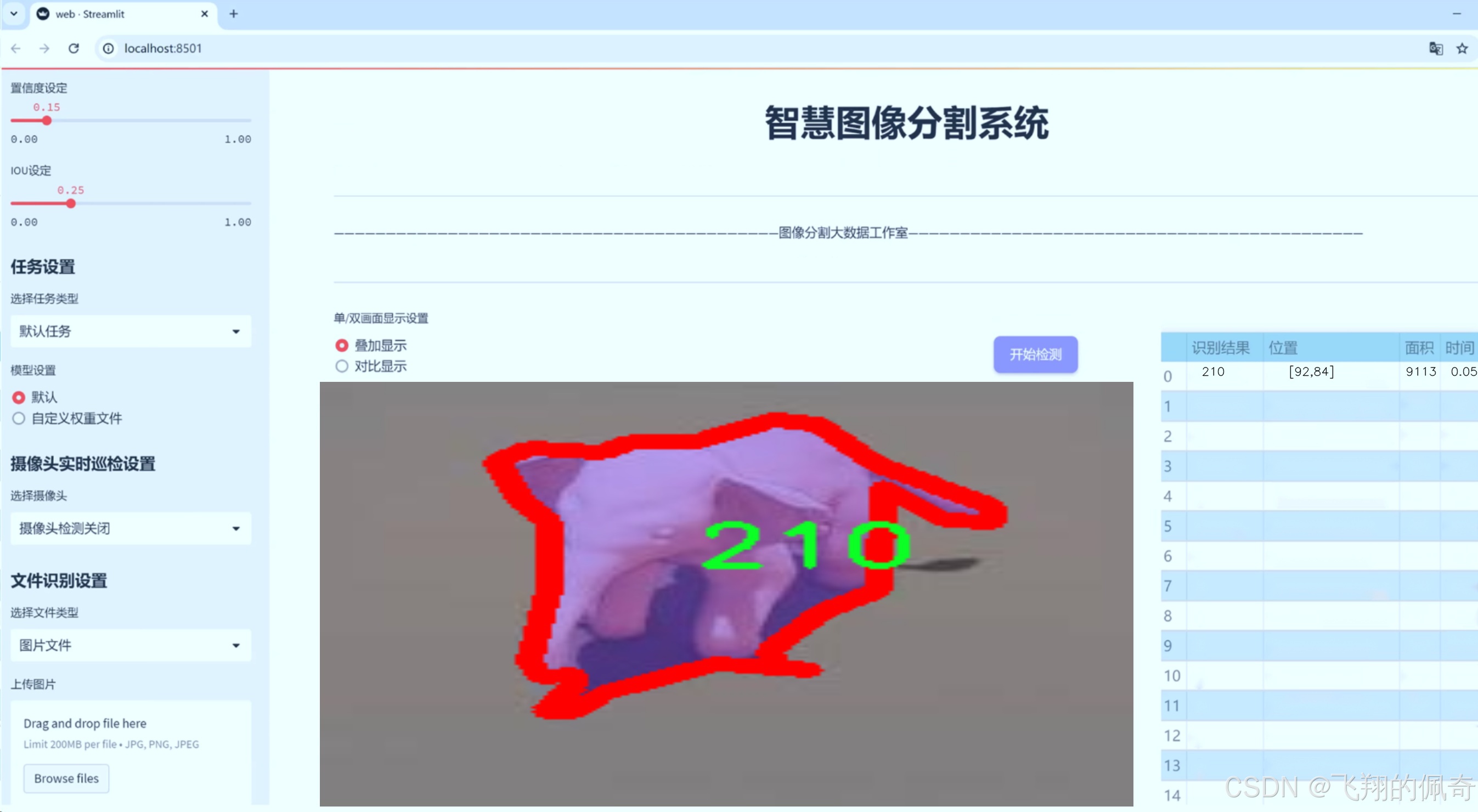
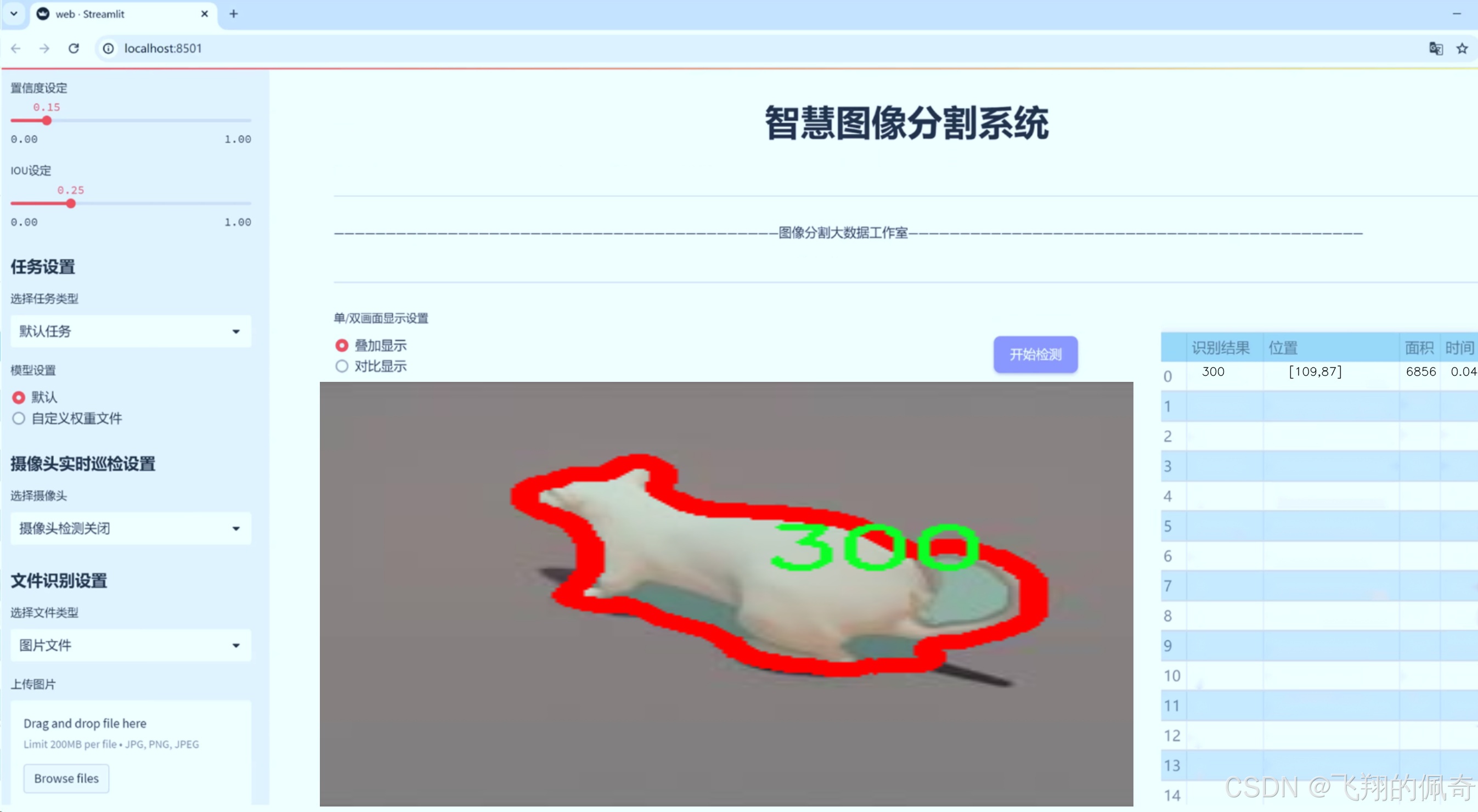
数据集信息
在本研究中,我们使用的数据集名为“24907r598327803081309-”,该数据集专门为改进YOLOv8-seg的图像验证识别系统而设计。数据集的构建旨在提供丰富且多样化的图像样本,以增强模型在实际应用中的表现和准确性。数据集包含12个类别,分别为‘120’,‘150’,‘180’,‘210’,‘240’,‘270’,‘30’,‘300’,‘330’,‘360’,‘60’和‘90’。这些类别代表了不同的目标对象或场景,能够帮助模型在多种情况下进行有效的识别和分类。
数据集的设计考虑到了图像的多样性和复杂性,以确保模型在训练过程中能够接触到广泛的样本。每个类别都包含大量的图像,这些图像在拍摄时考虑到了不同的光照条件、角度和背景,以模拟真实世界中的应用场景。例如,类别‘120’可能代表某种特定的物体,而在数据集中,该物体可能在不同的环境中出现,如室内、室外、白天和夜晚等。这种多样性不仅增强了模型的鲁棒性,还提高了其在未知数据上的泛化能力。
在数据集的构建过程中,我们特别关注了图像的标注质量。每张图像都经过仔细的标注,确保目标对象的边界框和类别标签的准确性。这种高质量的标注对于训练深度学习模型至关重要,因为它直接影响到模型的学习效果和最终的识别精度。此外,数据集还经过了预处理,以确保图像的统一性和标准化,使得模型在训练时能够更快地收敛。
为了评估模型的性能,我们将数据集划分为训练集和验证集。训练集用于模型的训练,而验证集则用于评估模型在未见数据上的表现。这种划分方法能够有效地防止模型的过拟合,确保其在实际应用中的可靠性和有效性。通过不断迭代和优化,我们期望在YOLOv8-seg的基础上,进一步提升图像识别的准确性和效率。
在数据集的使用过程中,我们还考虑到了数据增强技术的应用。通过对图像进行旋转、缩放、裁剪和颜色调整等操作,我们能够生成更多的训练样本,从而丰富数据集的多样性。这种数据增强策略不仅提高了模型的鲁棒性,还有效地扩展了训练数据的规模,为模型的训练提供了更为丰富的特征信息。
综上所述,数据集“24907r598327803081309-”为改进YOLOv8-seg的图像验证识别系统提供了坚实的基础。通过精心设计的类别结构、严格的标注质量和有效的数据增强策略,我们期望该数据集能够在模型训练中发挥重要作用,推动图像识别技术的进一步发展和应用。



核心代码
```python
# Ultralytics YOLO 🚀, AGPL-3.0 license
# 从当前包中导入三个类:DetectionPredictor、DetectionTrainer 和 DetectionValidator
from .predict import DetectionPredictor # 导入用于目标检测预测的类
from .train import DetectionTrainer # 导入用于训练目标检测模型的类
from .val import DetectionValidator # 导入用于验证目标检测模型的类
# 定义当前模块的公共接口,指定可以被外部访问的类
__all__ = 'DetectionPredictor', 'DetectionTrainer', 'DetectionValidator'
代码分析:
-
导入模块:
- 代码中通过相对导入的方式引入了三个核心类,分别用于目标检测的预测、训练和验证。这些类是实现 YOLO(You Only Look Once)目标检测算法的关键组件。
-
公共接口:
__all__变量用于定义模块的公共接口,只有在使用from module import *语句时,列出的类才会被导入。这是一种控制模块导出内容的方式,确保外部用户只访问到指定的类。
核心部分:
- 该代码的核心在于三个类的导入和
__all__的定义,确保了模块的结构清晰且易于使用。```
这个文件是Ultralytics YOLO项目中的一个初始化文件,通常用于定义模块的公共接口。在这个文件中,首先有一个注释,说明了项目的名称(Ultralytics YOLO)以及其许可证类型(AGPL-3.0)。接下来,文件通过相对导入的方式引入了三个类:DetectionPredictor、DetectionTrainer和DetectionValidator,分别来自于predict、train和val模块。
DetectionPredictor类通常用于处理目标检测的预测任务,负责加载模型并对输入数据进行推理,输出检测结果。DetectionTrainer类则用于训练模型,包含了训练过程中的各种设置和操作,如数据加载、损失计算和模型更新等。DetectionValidator类用于验证模型的性能,通常会在训练后对模型进行评估,以确保其在未见数据上的表现。
最后,__all__变量定义了模块的公共接口,表示当使用from module import *语句时,只有DetectionPredictor、DetectionTrainer和DetectionValidator这三个类会被导入。这种做法有助于控制模块的可见性,避免不必要的命名冲突,并使得模块的使用更加清晰和简洁。总的来说,这个文件的主要作用是将目标检测相关的功能模块组织在一起,方便其他部分的调用和使用。
import sys
import subprocess
def run_script(script_path):
"""
使用当前 Python 环境运行指定的脚本。
Args:
script_path (str): 要运行的脚本路径
Returns:
None
"""
# 获取当前 Python 解释器的路径
python_path = sys.executable
# 构建运行命令,使用 streamlit 运行指定的脚本
command = f'"{python_path}" -m streamlit run "{script_path}"'
# 执行命令并获取结果
result = subprocess.run(command, shell=True)
# 检查命令执行是否成功
if result.returncode != 0:
print("脚本运行出错。")
# 主程序入口
if __name__ == "__main__":
# 指定要运行的脚本路径
script_path = "web.py" # 这里可以直接指定脚本名
# 调用函数运行脚本
run_script(script_path)
代码注释说明:
-
导入模块:
sys:用于访问与 Python 解释器相关的变量和函数。subprocess:用于执行外部命令和与其交互。
-
定义
run_script函数:- 该函数接受一个参数
script_path,表示要运行的 Python 脚本的路径。 - 函数内部首先获取当前 Python 解释器的路径,以便在命令中使用。
- 该函数接受一个参数
-
构建命令:
- 使用
streamlit模块运行指定的脚本。命令格式为:python -m streamlit run <script_path>。
- 使用
-
执行命令:
- 使用
subprocess.run方法执行构建的命令,并将shell参数设置为True,允许在 shell 中执行命令。 - 通过
result.returncode检查命令的执行结果。如果返回码不为 0,表示脚本运行出错。
- 使用
-
主程序入口:
- 使用
if __name__ == "__main__":确保该部分代码仅在直接运行脚本时执行。 - 指定要运行的脚本路径(这里直接使用脚本名
web.py)。 - 调用
run_script函数来执行指定的脚本。```
这个程序文件的主要功能是使用当前的 Python 环境来运行一个指定的脚本,具体来说是运行一个名为web.py的脚本。程序首先导入了必要的模块,包括sys、os和subprocess,这些模块分别用于获取系统信息、操作系统功能和执行外部命令。
- 使用
在程序中定义了一个名为 run_script 的函数,该函数接受一个参数 script_path,这个参数是要运行的脚本的路径。函数内部首先获取当前 Python 解释器的路径,这通过 sys.executable 实现。接着,构建一个命令字符串,命令的格式是使用 Python 解释器来运行 streamlit 模块,并指定要运行的脚本路径。
随后,使用 subprocess.run 方法执行构建好的命令。这个方法会在一个新的 shell 中运行命令,并等待命令执行完成。如果命令执行的返回码不为零,表示脚本运行出错,程序会打印出相应的错误信息。
在文件的最后部分,使用 if __name__ == "__main__": 语句来确保只有在直接运行该文件时才会执行后面的代码。这里指定了要运行的脚本路径 web.py,并调用 run_script 函数来执行这个脚本。
总的来说,这个程序的目的是方便地在当前 Python 环境中运行一个特定的脚本,并处理可能出现的错误。
# Ultralytics YOLO 🚀, AGPL-3.0 license
from pathlib import Path # 导入Path类,用于处理文件路径
from ultralytics.engine.model import Model # 从ultralytics库中导入Model类
from .predict import FastSAMPredictor # 导入FastSAMPredictor类,用于预测
from .val import FastSAMValidator # 导入FastSAMValidator类,用于验证
class FastSAM(Model):
"""
FastSAM模型接口。
示例:
```python
from ultralytics import FastSAM
model = FastSAM('last.pt') # 加载模型
results = model.predict('ultralytics/assets/bus.jpg') # 进行预测
```
"""
def __init__(self, model='FastSAM-x.pt'):
"""初始化FastSAM类,调用父类Model的初始化方法,并设置默认模型。"""
# 如果传入的模型名称是'FastSAM.pt',则将其替换为'FastSAM-x.pt'
if str(model) == 'FastSAM.pt':
model = 'FastSAM-x.pt'
# 确保模型文件的后缀不是.yaml或.yml,FastSAM模型只支持预训练模型
assert Path(model).suffix not in ('.yaml', '.yml'), 'FastSAM models only support pre-trained models.'
# 调用父类的初始化方法,设置模型和任务类型为'segment'
super().__init__(model=model, task='segment')
@property
def task_map(self):
"""返回一个字典,将分割任务映射到相应的预测器和验证器类。"""
return {'segment': {'predictor': FastSAMPredictor, 'validator': FastSAMValidator}}
代码核心部分说明:
- 类定义:
FastSAM类继承自Model类,表示FastSAM模型的接口。 - 初始化方法:
__init__方法用于初始化模型,确保使用的是有效的预训练模型,并设置任务类型为分割(segment)。 - 任务映射:
task_map属性返回一个字典,映射分割任务到相应的预测器和验证器类,便于后续的模型使用和扩展。```
这个程序文件定义了一个名为FastSAM的类,它是一个用于图像分割的模型接口,继承自Model类。文件开头的注释表明这是 Ultralytics YOLO 的一部分,并且遵循 AGPL-3.0 许可证。
在 FastSAM 类的文档字符串中,提供了一个简单的使用示例,展示了如何导入 FastSAM 类并使用它加载模型以及进行预测。示例中,用户可以通过传入模型文件名(如 'last.pt')来创建模型实例,并调用 predict 方法对指定的图像进行预测。
构造函数 __init__ 中,默认参数为 'FastSAM-x.pt',这意味着如果用户传入的模型名称是 'FastSAM.pt',则会自动更改为 'FastSAM-x.pt'。构造函数中还有一个断言,确保传入的模型文件名后缀不是 .yaml 或 .yml,因为 FastSAM 模型只支持预训练模型文件。
task_map 属性返回一个字典,该字典将分割任务映射到相应的预测器和验证器类。具体来说,它将 'segment' 任务映射到 FastSAMPredictor 和 FastSAMValidator 类,这些类负责处理模型的预测和验证过程。
总体而言,这个文件提供了一个清晰的接口,用于加载和使用 FastSAM 模型进行图像分割任务,同时确保用户遵循特定的模型文件格式。
```python
import torch
import torch.nn.functional as F
def multi_scale_deformable_attn_pytorch(value: torch.Tensor, value_spatial_shapes: torch.Tensor,
sampling_locations: torch.Tensor,
attention_weights: torch.Tensor) -> torch.Tensor:
"""
多尺度可变形注意力机制。
参数:
- value: 输入特征图,形状为 (batch_size, 通道数, num_heads, embed_dims)
- value_spatial_shapes: 特征图的空间形状,形状为 (num_levels, 2),每一行表示一个特征图的高和宽
- sampling_locations: 采样位置,形状为 (batch_size, num_queries, num_heads, num_levels, num_points, 2)
- attention_weights: 注意力权重,形状为 (batch_size, num_heads, num_queries, num_levels, num_points)
返回:
- output: 经过多尺度可变形注意力机制处理后的输出,形状为 (batch_size, num_queries, num_heads * embed_dims)
"""
# 获取输入的维度信息
bs, _, num_heads, embed_dims = value.shape # bs: batch size
_, num_queries, _, num_levels, num_points, _ = sampling_locations.shape # num_queries: 查询数量
# 将输入特征图根据空间形状分割成多个特征图
value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes], dim=1)
# 将采样位置转换到[-1, 1]的范围
sampling_grids = 2 * sampling_locations - 1
sampling_value_list = []
# 遍历每个特征图的层级
for level, (H_, W_) in enumerate(value_spatial_shapes):
# 对特征图进行变形和重排
value_l_ = (value_list[level].flatten(2).transpose(1, 2).reshape(bs * num_heads, embed_dims, H_, W_))
# 处理当前层级的采样位置
sampling_grid_l_ = sampling_grids[:, :, :, level].transpose(1, 2).flatten(0, 1)
# 使用双线性插值从特征图中采样
sampling_value_l_ = F.grid_sample(value_l_,
sampling_grid_l_,
mode='bilinear',
padding_mode='zeros',
align_corners=False)
sampling_value_list.append(sampling_value_l_)
# 将注意力权重调整形状以便后续计算
attention_weights = attention_weights.transpose(1, 2).reshape(bs * num_heads, 1, num_queries,
num_levels * num_points)
# 计算最终输出
output = ((torch.stack(sampling_value_list, dim=-2).flatten(-2) * attention_weights).sum(-1).view(
bs, num_heads * embed_dims, num_queries))
return output.transpose(1, 2).contiguous() # 返回形状为 (batch_size, num_queries, num_heads * embed_dims) 的输出
代码说明:
-
输入参数:
value:输入特征图,包含多个头部和嵌入维度。value_spatial_shapes:每个特征图的空间维度(高和宽)。sampling_locations:指定要采样的位置。attention_weights:每个查询的注意力权重。
-
主要过程:
- 将输入特征图分割成多个层级。
- 将采样位置转换到[-1, 1]范围,以便进行双线性插值。
- 对每个层级的特征图进行重排和采样。
- 最后,结合注意力权重计算输出。
-
输出:
- 返回经过多尺度可变形注意力机制处理后的特征,形状为
(batch_size, num_queries, num_heads * embed_dims)。```
这个程序文件是一个用于实现多尺度可变形注意力机制的工具模块,主要用于深度学习框架PyTorch中,特别是在YOLO(You Only Look Once)模型的上下文中。文件中包含了一些常用的工具函数和类,以下是对代码的逐行解释。
- 返回经过多尺度可变形注意力机制处理后的特征,形状为
首先,文件导入了一些必要的库,包括copy、math、numpy和torch,以及PyTorch的神经网络模块。__all__定义了模块的公共接口,表示该模块对外暴露的函数。
_get_clones(module, n)函数用于克隆给定的模块,返回一个包含n个深拷贝的模块列表。这在构建具有多个相同层的网络时非常有用。
bias_init_with_prob(prior_prob=0.01)函数用于根据给定的概率值初始化卷积或全连接层的偏置。它使用了对数几率的公式,将概率转换为偏置值。
linear_init_(module)函数用于初始化线性模块的权重和偏置。它使用均匀分布在[-bound, bound]范围内初始化权重和偏置,其中bound是根据模块的输入特征数计算得出的。
inverse_sigmoid(x, eps=1e-5)函数计算张量的反sigmoid函数。它首先将输入限制在0到1之间,然后计算反sigmoid值,避免了数值不稳定性。
multi_scale_deformable_attn_pytorch函数实现了多尺度可变形注意力机制。该函数接收多个输入参数,包括值张量、空间形状、采样位置和注意力权重。函数内部首先获取输入张量的形状信息,然后将值张量按照空间形状进行分割,接着计算采样网格。对于每个尺度的值,使用F.grid_sample函数进行双线性插值采样,得到采样值列表。最后,利用注意力权重对采样值进行加权求和,输出最终的结果。
整体来看,这个模块提供了一些基础的工具函数,主要用于神经网络中参数的初始化和多尺度注意力机制的实现,能够帮助提升模型的性能和灵活性。
```python
import json
from collections import defaultdict
from pathlib import Path
import numpy as np
from ultralytics.utils import TQDM, LOGGER
from ultralytics.utils.files import increment_path
def coco91_to_coco80_class():
"""
将 COCO 数据集中的 91 类别 ID 转换为 80 类别 ID。
返回一个列表,索引表示 80 类别 ID,值为对应的 91 类别 ID。
"""
return [
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, None, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, None, 24, 25, None,
None, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, None, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50,
51, 52, 53, 54, 55, 56, 57, 58, 59, None, 60, None, None, 61, None, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72,
None, 73, 74, 75, 76, 77, 78, 79, None
]
def convert_coco(labels_dir='../coco/annotations/', save_dir='coco_converted/', cls91to80=True):
"""
将 COCO 数据集的标注转换为 YOLO 格式的标注。
参数:
labels_dir (str): COCO 数据集标注文件的路径。
save_dir (str): 保存转换后结果的路径。
cls91to80 (bool): 是否将 91 类别 ID 映射到 80 类别 ID。
"""
# 创建保存目录
save_dir = increment_path(save_dir) # 如果目录已存在则递增
for p in save_dir / 'labels', save_dir / 'images':
p.mkdir(parents=True, exist_ok=True) # 创建目录
# 获取 COCO 80 类别映射
coco80 = coco91_to_coco80_class()
# 处理每个 JSON 文件
for json_file in sorted(Path(labels_dir).resolve().glob('*.json')):
fn = Path(save_dir) / 'labels' / json_file.stem.replace('instances_', '') # 生成文件夹名称
fn.mkdir(parents=True, exist_ok=True)
with open(json_file) as f:
data = json.load(f)
# 创建图像字典
images = {f'{x["id"]:d}': x for x in data['images']}
# 创建图像-标注字典
imgToAnns = defaultdict(list)
for ann in data['annotations']:
imgToAnns[ann['image_id']].append(ann)
# 写入标注文件
for img_id, anns in TQDM(imgToAnns.items(), desc=f'Annotations {json_file}'):
img = images[f'{img_id:d}']
h, w, f = img['height'], img['width'], img['file_name']
bboxes = [] # 存储边界框
for ann in anns:
if ann['iscrowd']:
continue # 跳过人群标注
# COCO 的边界框格式为 [左上角 x, 左上角 y, 宽度, 高度]
box = np.array(ann['bbox'], dtype=np.float64)
box[:2] += box[2:] / 2 # 转换为中心点坐标
box[[0, 2]] /= w # 归一化 x
box[[1, 3]] /= h # 归一化 y
if box[2] <= 0 or box[3] <= 0: # 如果宽度或高度小于等于 0
continue
cls = coco80[ann['category_id'] - 1] if cls91to80 else ann['category_id'] - 1 # 类别
box = [cls] + box.tolist() # 组合类别和边界框
if box not in bboxes:
bboxes.append(box)
# 写入标注文件
with open((fn / f).with_suffix('.txt'), 'a') as file:
for bbox in bboxes:
file.write(('%g ' * len(bbox)).rstrip() % bbox + '\n')
LOGGER.info(f'COCO 数据成功转换。\n结果保存到 {save_dir.resolve()}')
代码注释说明:
-
coco91_to_coco80_class: 此函数用于将 COCO 数据集中 91 个类别的 ID 转换为 80 个类别的 ID,返回一个列表,其中索引表示 80 类别 ID,值为对应的 91 类别 ID。
-
convert_coco: 该函数将 COCO 数据集的标注文件转换为 YOLO 格式的标注文件。它会创建保存目录,读取 JSON 格式的标注文件,处理每个图像的标注,并将结果写入到新的文本文件中。
-
标注处理: 在处理标注时,函数会将 COCO 的边界框格式转换为 YOLO 所需的格式,并进行归一化处理。同时,支持将类别 ID 从 91 转换为 80。
-
文件写入: 最后,函数将处理后的边界框信息写入到相应的文本文件中,完成标注的转换。```
这个程序文件主要用于将COCO数据集的标注格式转换为YOLO模型所需的格式,同时也支持将DOTA数据集的标注转换为YOLO的方向性边界框(OBB)格式。文件中包含多个函数,每个函数的功能和实现方式都有所不同。
首先,文件定义了两个函数coco91_to_coco80_class和coco80_to_coco91_class,它们分别用于将COCO数据集中91个类别的ID转换为80个类别的ID,以及反向转换。这两个函数返回的列表中,索引对应于80个类别的ID,而值则是对应的91个类别的ID。这种转换对于在不同模型和数据集之间共享标注信息非常重要。
接下来是convert_coco函数,它是文件的核心功能之一。该函数的目的是将COCO数据集的标注文件转换为YOLO格式。函数接受多个参数,包括标注文件的目录、保存结果的目录、是否使用分割掩码和关键点等。函数首先创建保存结果的目录,然后读取指定目录下的所有JSON标注文件。对于每个标注文件,函数会解析图像信息和对应的标注,提取边界框、分割和关键点信息,并将其转换为YOLO格式。转换过程中,边界框的坐标会进行归一化处理,以适应YOLO的要求。最后,生成的标注文件会被保存到指定的目录中。
convert_dota_to_yolo_obb函数则专门用于将DOTA数据集的标注转换为YOLO OBB格式。该函数处理DOTA数据集中的训练和验证图像,读取原始标签并将其转换为YOLO OBB格式。函数内部定义了一个辅助函数convert_label,用于处理单个图像的标注转换。该函数会读取原始标签文件,提取类别和坐标信息,并进行归一化处理后保存到新的标签文件中。
此外,文件中还定义了min_index和merge_multi_segment两个辅助函数。min_index函数用于计算两个二维点数组之间的最短距离索引,而merge_multi_segment函数则用于将多个分割线段合并为一个列表,以便于后续处理。
总体而言,这个程序文件实现了从COCO和DOTA数据集到YOLO格式的标注转换,具有很好的实用性和灵活性,适合于深度学习模型的训练和评估。
```python
import os
import torch
import yaml
from ultralytics import YOLO # 导入YOLO模型库
if __name__ == '__main__': # 确保该模块被直接运行时才执行以下代码
# 设置训练参数
workers = 1 # 数据加载的工作进程数
batch = 8 # 每个批次的样本数量
device = "0" if torch.cuda.is_available() else "cpu" # 检查是否有可用的GPU,如果没有则使用CPU
# 获取数据集的yaml配置文件的绝对路径
data_path = abs_path(f'datasets/data/data.yaml', path_type='current')
# 将路径转换为Unix风格
unix_style_path = data_path.replace(os.sep, '/')
# 获取目录路径
directory_path = os.path.dirname(unix_style_path)
# 读取YAML文件,保持原有顺序
with open(data_path, 'r') as file:
data = yaml.load(file, Loader=yaml.FullLoader)
# 修改数据集路径
if 'train' in data and 'val' in data and 'test' in data:
data['train'] = directory_path + '/train' # 设置训练集路径
data['val'] = directory_path + '/val' # 设置验证集路径
data['test'] = directory_path + '/test' # 设置测试集路径
# 将修改后的数据写回YAML文件
with open(data_path, 'w') as file:
yaml.safe_dump(data, file, sort_keys=False)
# 加载YOLO模型配置和预训练权重
model = YOLO(r"C:\codeseg\codenew\50+种YOLOv8算法改进源码大全和调试加载训练教程(非必要)\改进YOLOv8模型配置文件\yolov8-seg-C2f-Faster.yaml").load("./weights/yolov8s-seg.pt")
# 开始训练模型
results = model.train(
data=data_path, # 指定训练数据的配置文件路径
device=device, # 指定训练设备
workers=workers, # 指定数据加载的工作进程数
imgsz=640, # 指定输入图像的大小为640x640
epochs=100, # 指定训练100个epoch
batch=batch, # 指定每个批次的大小为8
)
代码注释说明:
- 导入必要的库:引入了处理文件路径、深度学习框架(PyTorch)、YAML文件处理和YOLO模型的库。
- 设置训练参数:定义了数据加载的工作进程数、批次大小和训练设备(GPU或CPU)。
- 获取数据集路径:通过
abs_path函数获取数据集配置文件的绝对路径,并将其转换为Unix风格的路径。 - 读取和修改YAML文件:读取YAML文件内容,修改训练、验证和测试集的路径,并将修改后的内容写回文件。
- 加载YOLO模型:根据指定的配置文件和预训练权重加载YOLO模型。
- 训练模型:调用
model.train方法开始训练,传入必要的参数,包括数据路径、设备、工作进程数、图像大小、训练轮数和批次大小。```
该程序文件train.py是一个用于训练 YOLO(You Only Look Once)模型的脚本。首先,它导入了必要的库,包括操作系统相关的os、深度学习框架torch、YAML 文件处理库yaml、YOLO 模型库ultralytics和路径处理工具abs_path。此外,它还设置了 Matplotlib 的后端为TkAgg,以便于可视化。
在 __main__ 块中,程序首先定义了一些训练参数,包括工作进程数 workers 和批次大小 batch。批次大小可以根据计算机的显存和内存进行调整,以避免显存溢出。接着,程序检查是否有可用的 GPU,如果有,则将设备设置为 “0”(表示使用第一个 GPU),否则使用 CPU。
接下来,程序构建了数据集配置文件的绝对路径,并将路径格式转换为 Unix 风格。然后,它读取指定的 YAML 文件,并保持原有的顺序。程序检查 YAML 文件中是否包含 train、val 和 test 字段,如果存在,则将这些字段的路径修改为当前目录下的 train、val 和 test 子目录。修改完成后,程序将更新后的数据写回到 YAML 文件中。
程序还提醒用户,不同的模型对设备的要求不同,如果遇到错误,可以尝试使用其他模型进行测试。接着,程序加载了一个 YOLOv8 模型的配置文件,并加载了预训练的权重文件。
最后,程序调用 model.train() 方法开始训练模型,指定了训练数据的配置文件路径、设备、工作进程数、输入图像大小(640x640)、训练的 epoch 数(100)以及批次大小。通过这些设置,程序能够有效地进行模型训练。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献242条内容
已为社区贡献242条内容

所有评论(0)