基于一维卷积神经网络的PPG信号心肌梗死预测研究
0 引言
心血管疾病是全球范围内导致死亡的主要原因,其中急性心肌梗死以其高发病率、高致残率和高死亡率,构成了最严重的公共卫生挑战之一[1]。心肌梗死的病理基础是冠状动脉血流急剧减少或中断,导致相应的心肌细胞发生持久性缺血缺氧而坏死。其救治效果具有极强的时间依赖性,“时间就是心肌,时间就是生命”[2]。因此,实现心肌梗死的早期、快速、无创筛查与预警,对于降低患者死亡率、改善预后具有至关重要的意义。
目前,心肌梗死的诊断“金标准”包括心电图、血清生物标志物检测等。然而,这些方法或需要专业的医疗设备与操作人员,或存在侵入性、耗时较长、成本较高等问题,难以广泛应用于日常、连续的家庭或社区健康监测场景。因此,开发一种便捷、低成本的心肌梗死早期筛查技术迫在眉睫。光电容积脉搏波(PPG)技术为此提供了一种极具潜力的解决方案。PPG是一种通过光学方法无创检测皮下微血管血容量变化的技术,其信号形态蕴含了丰富的心血管生理病理信息,如心率、血管弹性及外周阻力等[3]。相较于心电图,PPG信号的采集设备(如智能手机、智能手环、指夹式传感器)极为普及、成本低廉、操作简单,非常适合用于长期、动态的健康监测。 近年来,随着深度学习算法的快速发展,特别是卷积神经网络,在医学信号处理与疾病诊断领域展现出强大的能力。一维卷积神经网络(1D-CNN)能够自动从原始信号中学习并提取具有判别性的深层特征,无需依赖复杂、专业的人工特征工程,非常适用于处理ECG这样的时间序列信号。已有研究成功将1D-CNN应用于基于ECG的心律失常、房颤等疾病的自动诊断[4-5]。
目前,利用PPG信号进行心血管状态评估已成为生物医学工程领域的研究热点。过往研究多集中于通过分析PPG信号的时域特征、频域特征或通过波形分解来间接评血压等与心血管风险相关的参数[6]。这些方法虽然取得了一定成果,但大多依赖于对PPG波形特征的先验知识和手动提取,过程繁琐且特征的鲁棒性和泛化能力有限。基于上述背景,本研究旨在探索并构建一种基于一维卷积神经网络(1D-CNN)的PPG信号分析模型,以实现对心肌梗死的自动识别与预测。
目录
本文完整代码和相关数据可在下载:基于一维卷积神经网络的PPG信号心肌梗死预测研究的完整代码资源
1 数据来源与预处理
在第一工作当中,我们已经详细介绍了数据来源以及预处理的过程。这里简单叙述一下:该数据基于 Kaggle 平台的 Photoplethysmography (PPG) Dataset 展开通过 Python 加载数据并查看基本信息,确认数据集为含 2576 行、2001 列,目标变量 “Label” 分为 “Normal”(无心肌梗死迹象)和 “MI”(心肌梗死相关迹象)两类。接着进行数据查看,绘制前 20 行 PPG 信号变化趋势图,发现部分信号存在明显噪声;绘制标签分布图,得知 “Normal” 标签 1282 个、“MI” 标签 1294 个,两类标签分布均衡。随后进入数据预处理阶段,针对信号噪声问题,采用高斯加权移动滤波方法(窗口大小 51、标准差 5)对数据进行滤波,对比原始信号与滤波后信号,确认达到预期滤波效果,并将所有数据滤波后生成新数据集 “filtered_data”;为简化建模复杂度,基于 PPG 信号 “上升 - 峰值 - 下降 - 谷值” 的周期性特征,利用 find_peaks 函数检测滤波后数据的峰值与谷值,提取第二部分单周期信号,且统一单周期信号长度为 250,经验证提取结果均符合单周期规律,最终生成新数据集 “cycles”,为后续建模分析奠定基础[7]。
此外,为对比所提方法的有效性,我们设置了多组数据对比实验,所采用的数据分为以下三种类型,以全面评估不同数据处理方式对模型效果的影响:(1)一个心动周期内PPG信号(滤波):cycles;(2)多个心动周期内PPG信号(滤波):filtered_data;(3)未处理的数据即多个心动周期内PPG信号(未滤波):PPG_Dataset。
cycles该数据可见:【免费】一个心动周期内的PPG信号资源-CSDN下载
数据来源:Photoplethysmography (PPG) Dataset
详见链接文章中的1.1-1.3节:基于 PPG 信号与机器学习算法的心肌梗死预测研究-CSDN博客
或:基于统计信息融合的PPG时域特征在心肌梗死预测的研究-CSDN博客基于主成分分析的PPG信号特征用于心肌梗死预测研究-CSDN博客
2 一维卷积神经网络
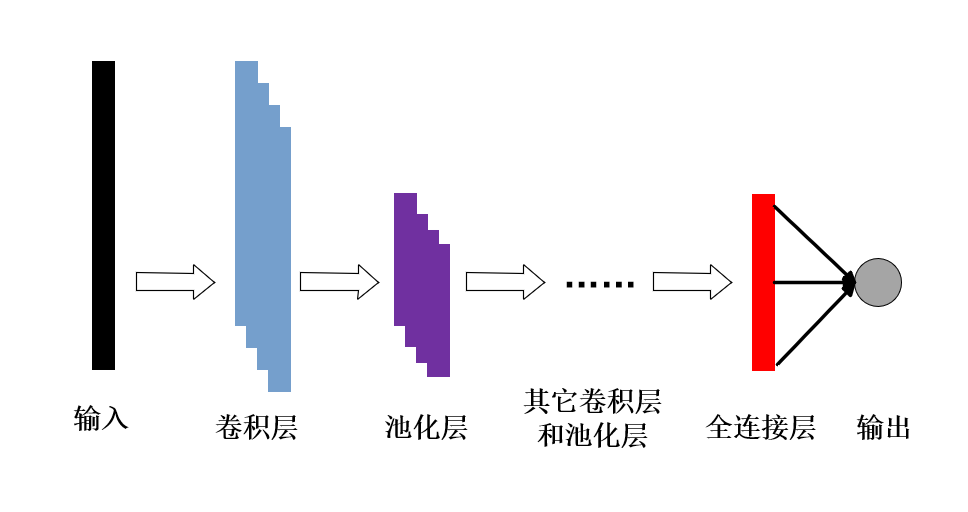
一维卷积神经网络(1D Convolutional Neural Network, 1D CNN)作为卷积神经网络的重要变体,专为处理序列型数据而设计,尤其适用于时间序列、文本等具有时序或顺序依赖关系的数据场景。一维卷积神经网络(1D CNN)的基础架构与二维卷积神经网络(2D CNN)一脉相承,但核心差异在于其卷积运算聚焦于一维序列维度展开。该网络专为适配序列数据的特性设计,典型由以下核心模块层级构成[8]:
输入层:作为模型的数据入口,负责接收一维形态的序列数据(如时间序列、文本编码后的向量序列等),为后续特征提取提供原始输入。
卷积层:作为 1D CNN 的核心功能模块,通过预设的一维卷积核(也称为过滤器)对输入序列执行滑动卷积运算。这一过程能够有效捕捉序列中的局部依赖关系与关键局部特征,而卷积核的尺寸(决定局部特征的覆盖范围)和数量(决定特征提取的维度与丰富度)是影响模型特征学习能力与复杂度的关键超参数。
激活函数层:紧跟在卷积层之后,通过引入非线性变换(如 ReLU、ELU 等)打破数据的线性相关性,显著提升模型对复杂模式的表达能力,让网络能够学习到更具区分度的特征。
池化层:通常衔接于激活函数层之后,核心作用是对高维特征图进行下采样处理。通过保留关键特征信息、剔除冗余数据,既降低了后续计算的复杂度,又能增强模型对输入微小扰动的鲁棒性,助力提升模型的泛化能力。常用的池化策略包括最大池化(保留局部最优特征)和平均池化(融合局部整体特征)。
全连接层:作为网络的决策输出模块,一般位于架构的末端。它将前序卷积、池化过程提取的局部特征进行全局整合与加权映射,最终转化为与任务目标匹配的输出结果(如分类任务的类别概率分布、回归任务的预测值),完成从特征学习到任务决策的闭环。
具体如图所示:
其中,VGG(Visual Geometry Group)是由牛津大学的视觉几何组在2014年提出的一种深度卷积 神经网络架构。VGG网络以其简单而深厚的结构而著称,广泛应用于图像分类、目标检测等计算机视觉任务。VGG网络的核心特点是使用多个小卷积滤波器和相同的步幅,以及使用最大池化层(来降低特征图的尺寸。这种结构相较于使用大卷积核的传统网络在参数上更为有效,能够学习出更深层次的特征[9]。则一个典型的VGG块包含以下组成部分[10]:
- 多个卷积层:使用固定大小的卷积核,并通过填充保持输出尺寸不变。
- ReLU激活函数:为网络增加非线性。
- 最大池化层:用于空间下采样,将特征图的宽和高减半。
基于上述 1D CNN 的核心原理,本文以 VGG 网络架构为基础,构建适用于目标任务的一维卷积神经网络。该网络结构设计如下:整体包含四个卷积块,各卷积块采用 “卷积层 + 池化层” 的经典组合 —— 第一卷积块由 2 个带 ReLU 激活函数的卷积层与后续池化层构成,第二至第四卷积块则均由 3 个带 ReLU 激活函数的卷积层搭配池化层组成;此外,网络末端设置两个全连接层,神经元数量分别为 512 和 256,最终通过输出层的 Sigmoid 激活函数输出预测结果(二分类任务)。对于训练参数,将数据集比例为8:2作为训练集和测试集,其中10%的训练集作为验证集进行训练。选择Adam为优化器,损失函数为:二元交叉熵损失函数,以及批次设置为16,训练轮次为100,并设置了早停法。
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, models
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
df = pd.read_csv('cycles.csv')#单周期
##滤波多周期
# df1 = pd.read_csv('PPG_Dataset.csv')
# label_col = df1.columns[-1]
# df1['numeric_label'] = df1[label_col].map({'MI': 1, 'Normal': 0})
# data = pd.read_csv('filtered_data.csv')
# df = data.assign(numeric_label=df1['numeric_label'])
##不滤波多周期
# df1 = pd.read_csv('PPG_Dataset.csv')
# label_col = df1.columns[-1]
# df1['numeric_label'] = df1[label_col].map({'MI': 1, 'Normal': 0})
# data = pd.read_csv('/PPG_Dataset.csv')
# data =data.drop(columns='Label')
# df = data.assign(numeric_label=df1['numeric_label'])
X = df.iloc[:, 0:250].values
y = df['numeric_label'].values
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_reshaped = X_scaled.reshape(-1, 250, 1)
X_train, X_test, y_train, y_test = train_test_split(
X_reshaped, y, test_size=0.2, random_state=42, stratify=y
)
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy']
)
return model
model = build_vgg_style_1d_cnn(input_shape=(250, 1))
model.summary()
early_stopping = tf.keras.callbacks.EarlyStopping(
monitor='val_loss',
patience=10,
restore_best_weights=True
)
history = model.fit(
X_train, y_train,
batch_size=16,
epochs=100,
validation_split=0.1,
callbacks=[early_stopping],
verbose=1
)3 评价指标
本文基于PPG信号对心肌梗死的预测是个二分类的问题,故采用二分类的评价指标进行模型性能检测。如下[7]:
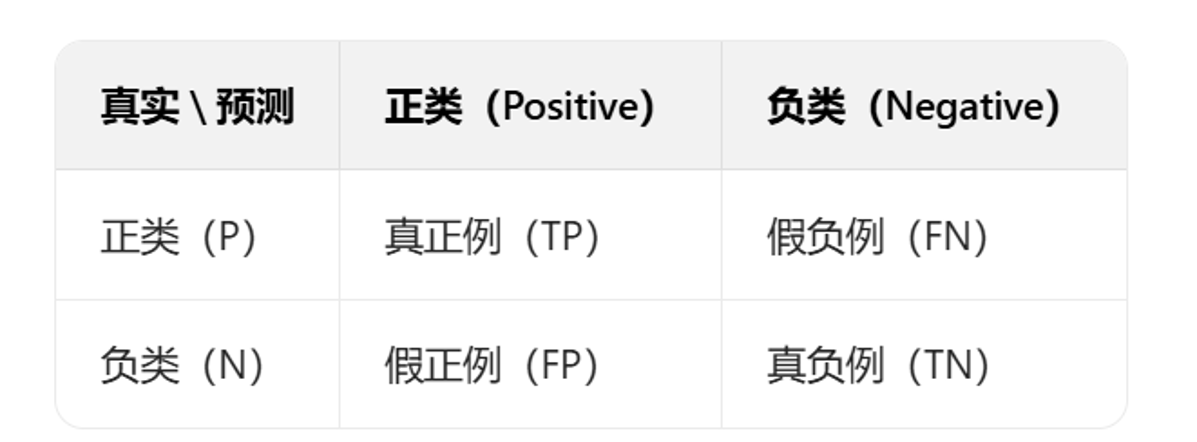
(1)Accuracy(准确率):指模型正确预测的样本数占总样本数的比例,反映模型整体的预测正确性,公式为:
其中 TP 为真阳性,TN 为真阴性,FP 为假阳性,FN 为假阴性。
(2)Precision(精确率 / 精准度):针对模型预测为正类的样本,其中真正为正类的比例,公式为:
(3)Recall(召回率 / 查全率):针对实际为正类的样本,模型成功预测为正类的比例,公式为:
(4)F1 Score(F1 分数):是精确率和召回率的调和平均数,综合衡量两者的表现,公式为:
(5)AUC(Area Under the ROC Curve,ROC 曲线下面积):ROC 曲线以假阳性率(FPR)为横轴、真阳性率(TPR)为纵轴绘制,AUC 是该曲线下的面积,用于评估模型在不同分类阈值下的整体性能,取值范围 0-1,越接近 1 说明模型分类能力越强。
,
具体可见:基于 PPG 信号与机器学习算法的心肌梗死预测研究-CSDN博客
代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
roc_auc_score, roc_curve )
y_pred_prob = model.predict(X_test, verbose=0) (n_samples,1))
y_pred_prob_flat = y_pred_prob.flatten()
y_pred = (y_pred_prob_flat > 0.5).astype(int)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, zero_division=0)
recall = recall_score(y_test, y_pred, zero_division=0)
f1 = f1_score(y_test, y_pred, zero_division=0)
roc_auc = roc_auc_score(y_test, y_pred_prob_flat)
fpr, tpr, _ = roc_curve(y_test, y_pred_prob_flat)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(8, 6), dpi=100)
plt.plot(fpr, tpr, color='darkblue', lw=2, label=f'ROC曲线 (AUC = {roc_auc:.4f})')
plt.plot([0, 1], [0, 1], color='gray', lw=1, linestyle='--')
plt.xlim([-0.01, 1.01])
plt.ylim([-0.01, 1.01])
plt.xlabel('假正例率 (FPR)', fontsize=12)
plt.ylabel('真正例率 (TPR)', fontsize=12)
plt.title('二分类模型 ROC 曲线', fontsize=14, fontweight='bold')
plt.legend(loc='lower right', fontsize=11)
plt.grid(True, alpha=0.3)
plt.tight_layout()
#plt.savefig('roc_curve.png', dpi=300, bbox_inches='tight')
plt.show()
metrics = {
'Accuracy': round(accuracy, 4),
'Precision': round(precision, 4),
'Recall': round(recall, 4),
'F1 Score': round(f1, 4),
'AUC': round(roc_auc, 4)
}
print("分类模型测试集指标:")
for metric_name, value in metrics.items():
print(f"{metric_name}: {value}")4 结果分析
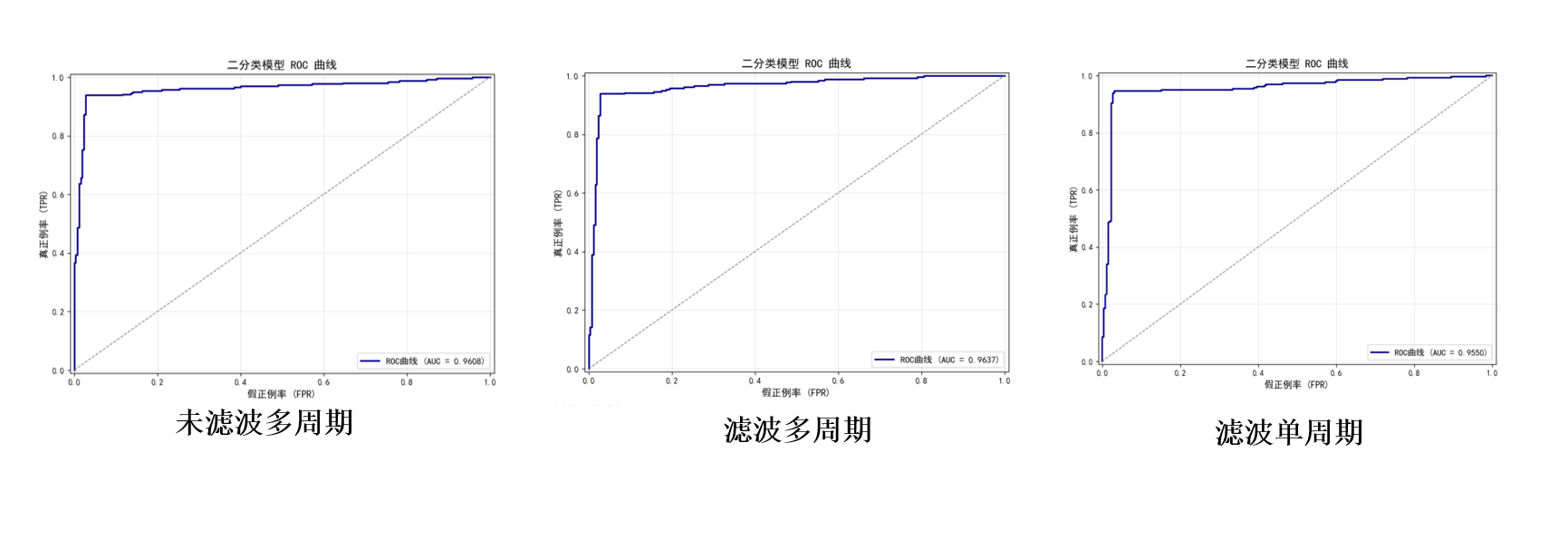
为验证一维卷积神经网络(对 PPG 信号自动提取特征并实现心肌梗死诊断的预测有效性,本文基于前期研究积累的三类数据展开对比实验:滤波后单周期数据(cycles)、滤波后多周期数据(filtered_data)及未滤波多周期数据(PPG_Dataset),通过分别进行预测任务,检验该方法在不同数据周期配置与噪声干扰下的稳定性。具体实验结果如下表所示:实验中,Accuracy、Precision、Recall 及 F1 Score 四项核心分类指标在三类数据场景下表现完全一致;唯一存在差异的指标为 AUC,其数值呈现明确排序:filtered_data > PPG_Dataset > cycles。由上述结果可得出两点关键结论:(1)多周期数据的模型预测效果显著优于单周期数据,表明充分利用 PPG 信号的时序连续性特征,能有效提升模型对心肌梗死的诊断能力;(2)噪声对预测结果存在一定影响(未滤波数据 PPG_Dataset 的 AUC 低于滤波后多周期数据 filtered_data),但相较于数据周期这一因素,噪声带来的影响程度更小。
| Accuracy | Precision | Recall | F1 Score | AUC | |
|---|---|---|---|---|---|
| cycles | 0.9554 | 0.972 | 0.9382 | 0.9548 | 0.955 |
| filtered_data | 0.9554 | 0.972 | 0.9382 | 0.9548 | 0.9637 |
| PPG_Dataset | 0.9554 | 0.972 | 0.9382 | 0.9548 | 0.9608 |
5 讨论
针对本文需要说明的是,所有模型在实验过程中均采用默认参数运行,未经过系统的超参数优化,因此其性能潜力可能尚未得到充分挖掘。此外,当前模型主要依赖时域方面的,未能充分利用频域等其他特征空间中的信息,限制了特征完整性。另外,基于一维卷积神经网络在生理意义上的可解释性较弱,这一局限性值得关注。未来需进一步探究PPG信号中基于一维卷积神经网络提取特征与生理机制之间的关联,同时考虑到该类方法易受样本数量与类型的影响,还应结合多样化样本进行验证。在后续研究中,可通过超参数优化以提升模型性能,并尝试融合时域、频域等多维度特征,构建更丰富的特征表示,从而进一步提高模型的预测精度与泛化能力。
在既往研究中,我们系统性地探索了基于PPG信号的心肌梗死预测方法,涵盖从传统时域特征分析、统计信息融合时域特征提取,到主成分降维特征构建,直至本文采用的一维卷积神经网络自动特征学习。这些研究在数据质量较优的条件下均取得了不错的预测性能,充分证明了PPG信号在心血管疾病风险评估中的潜在价值。然而,现有工作仍存在明显的局限性:在特征层面,我们尚未充分挖掘信号的频域特性、时频联合特征以及多源特征融合的潜力;在模型架构方面,现有方法多局限于传统机器学习范式,未能有效利用深度学习领域的最新进展。
未来研究可从以下几个方向实现突破:特征工程方面,可系统引入频域特征(如功率谱密度、频带能量分布)、时频分析特征(基于小波变换或短时傅里叶变换的时频图特征)以及多尺度特征融合方法;模型创新方面,可探索极限学习机、注意力增强的LSTM、时序卷积网络等先进架构,特别值得关注的是新兴的KAN在非线性关系建模上的独特优势。此外,集成学习框架下的多模型融合策略,以及引入注意力机制实现特征自适应加权,都将显著提升模型的表达能力和泛化性能。从信号特性角度考量,PPG信号虽然具有采集便捷、成本低廉、可重复性强等突出优点,但其信号质量易受测量设备差异、环境噪声干扰、传感器位置变动、个体生理状态波动等多重因素影响,导致信号稳定性和可靠性面临严峻挑战。这在模型构建过程中需要特别关注,应加强数据预处理、质量评估和抗干扰设计。在预测输出形式上,建议从当前的确定性分类向概率化预测转变,通过输出心肌梗死的发病概率,既能够提供更丰富的风险评估信息,又能够增强结果的可解释性。这种概率化输出有助于实现风险分级,为个性化健康管理和临床决策提供更精准的参考依据,推动PPG信号从研究工具向实用化筛查手段的转化。
最终,我们期望通过多维特征挖掘、先进模型构建、信号质量控制与概率化输出的、结合,建立更加精准、稳健、可解释的心肌梗死无创筛查新方法,为心血管疾病的早期预警提供有效的技术支撑。
过往研究的文章链接如下:
(1)基于 PPG 信号与机器学习算法的心肌梗死预测研究-CSDN博客
(2)基于统计信息融合的PPG时域特征在心肌梗死预测的研究-CSDN博客
(3)基于主成分分析的PPG信号特征用于心肌梗死预测研究-CSDN博客
参考
[1] 刘明波, 何新叶, 杨晓红, 等. 《 中国心血管健康与疾病报告 2023》 要点解读[J]. 临床心血管病杂志, 2024, 40(8): 599-616.
[2] 急性心肌梗死(病症)_百度百科
[4]苏良波,彭宏,邓亮,等.基于CNN与BiLSTM相结合的心电信号分类方法[J].中国数字医学,2024,19(06):96-100.
[5] 王建荣,邓黎明,程伟,等.基于CNN-LSTM-SE的心电图分类算法研究[J].测试技术学报,2024,38(03):264-273.
[6] Maqsood S, Xu S, Springer M, et al. A benchmark study of machine learning for analysis of signal feature extraction techniques for blood pressure estimation using photoplethysmography (PPG)[J]. Ieee Access, 2021, 9: 138817-138833.
[7] 基于 PPG 信号与机器学习算法的心肌梗死预测研究-CSDN博客
[9] VGG 网络架构 - yinghualeihenmei - 博客园
[10] (VGG)VGG网络通过模块化设计
注:若有侵权部分,请留言将会删除。
个人观点,仅供参考

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 36
36 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)