【完整源码+数据集+部署教程】金属缺陷分割系统源码&数据集分享 [yolov8-seg-efficientViT&yolov8-seg-C2f-Parc等50+全套改进创新点发刊_一键训练教程_We
【完整源码+数据集+部署教程】金属缺陷分割系统源码&数据集分享[yolov8-seg-efficientViT&yolov8-seg-C2f-Parc等50+全套改进创新点发刊_一键训练教程_We
背景意义
在现代制造业中,金属材料的质量直接影响到产品的性能和安全性。随着工业自动化和智能制造的快速发展,金属缺陷检测的需求日益增加。传统的金属缺陷检测方法往往依赖于人工目视检查或简单的机器检测,这不仅效率低下,而且容易受到人为因素的影响,导致漏检或误检。因此,开发一种高效、准确的金属缺陷检测系统显得尤为重要。近年来,深度学习技术的迅猛发展为图像处理和目标检测领域带来了新的机遇,尤其是基于卷积神经网络(CNN)的实例分割算法,如YOLO(You Only Look Once)系列,因其高效性和准确性而受到广泛关注。
YOLOv8作为YOLO系列的最新版本,结合了多种先进的技术,具有更强的特征提取能力和更快的推理速度,能够在复杂的工业环境中实时检测和分割金属缺陷。然而,现有的YOLOv8模型在特定应用场景下仍存在一定的局限性,尤其是在金属缺陷的多样性和复杂性方面。因此,基于改进YOLOv8的金属缺陷分割系统的研究具有重要的现实意义。
本研究将使用一个包含1100张图像和20类金属缺陷的综合数据集“merged_metal_defect”,该数据集涵盖了多种金属缺陷类型,如“Bump Mark”、“Fire Crack”、“Heavy wear out”等,反映了金属材料在实际生产过程中可能出现的各种缺陷。这些缺陷不仅影响产品的外观,还可能对其结构完整性和使用寿命造成严重影响。因此,准确识别和分割这些缺陷,对于提高金属材料的质量控制水平,降低生产成本,保障产品安全具有重要意义。
通过对YOLOv8模型的改进,本研究旨在提升金属缺陷的检测精度和分割效果。具体而言,我们将针对数据集中不同缺陷的特征,优化模型的网络结构和训练策略,以提高其对复杂背景和小目标的适应能力。此外,研究还将探讨数据增强、迁移学习等技术在金属缺陷检测中的应用,以进一步提升模型的泛化能力和鲁棒性。
综上所述,基于改进YOLOv8的金属缺陷分割系统的研究,不仅能够推动深度学习技术在工业检测领域的应用,还将为金属材料的质量控制提供新的解决方案。这一研究不仅具有理论价值,也具有广泛的应用前景,将为制造业的智能化转型提供有力支持。通过实现高效、准确的金属缺陷检测,能够显著提升生产效率,降低企业的运营风险,最终实现更高水平的产品质量和安全保障。
图片效果
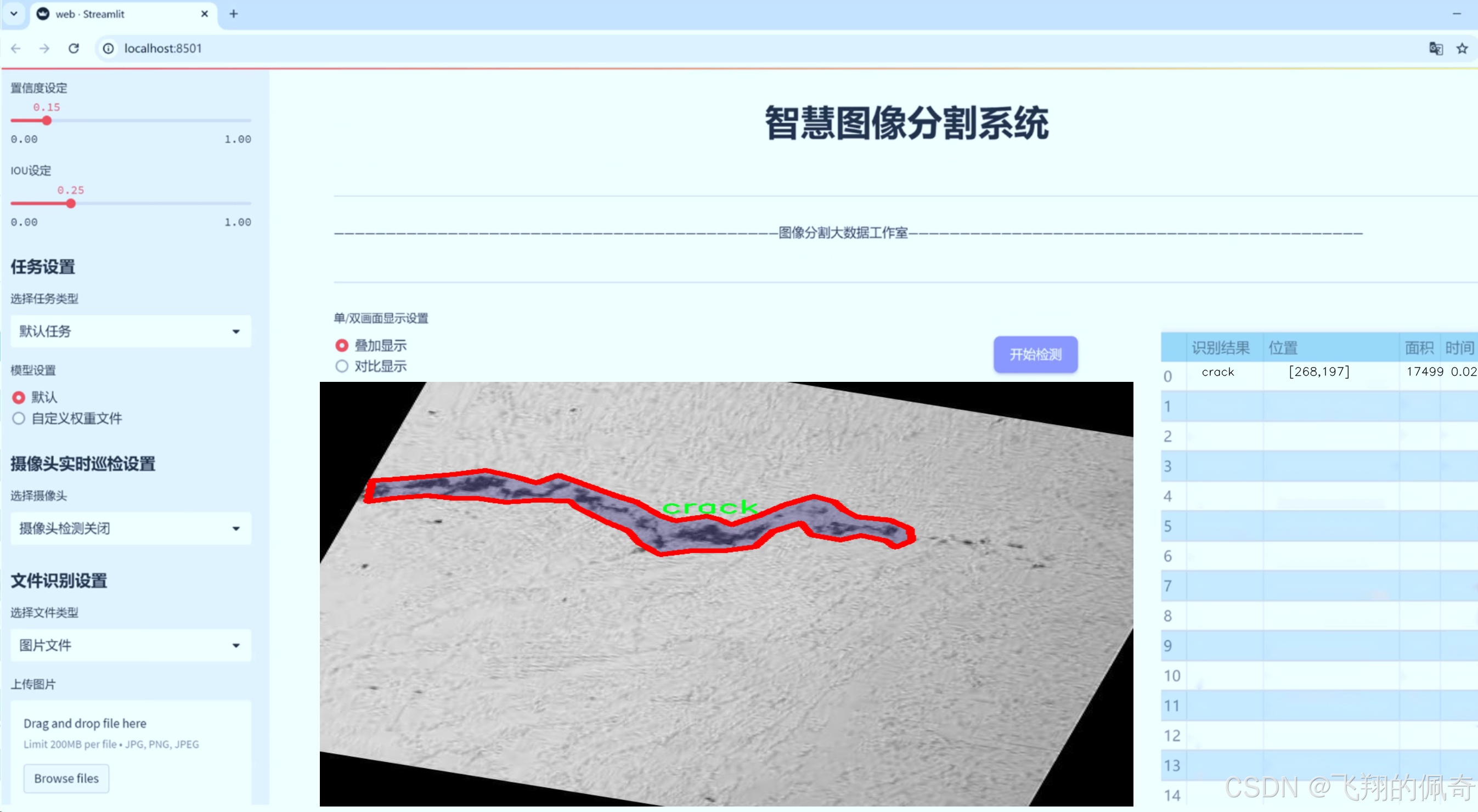
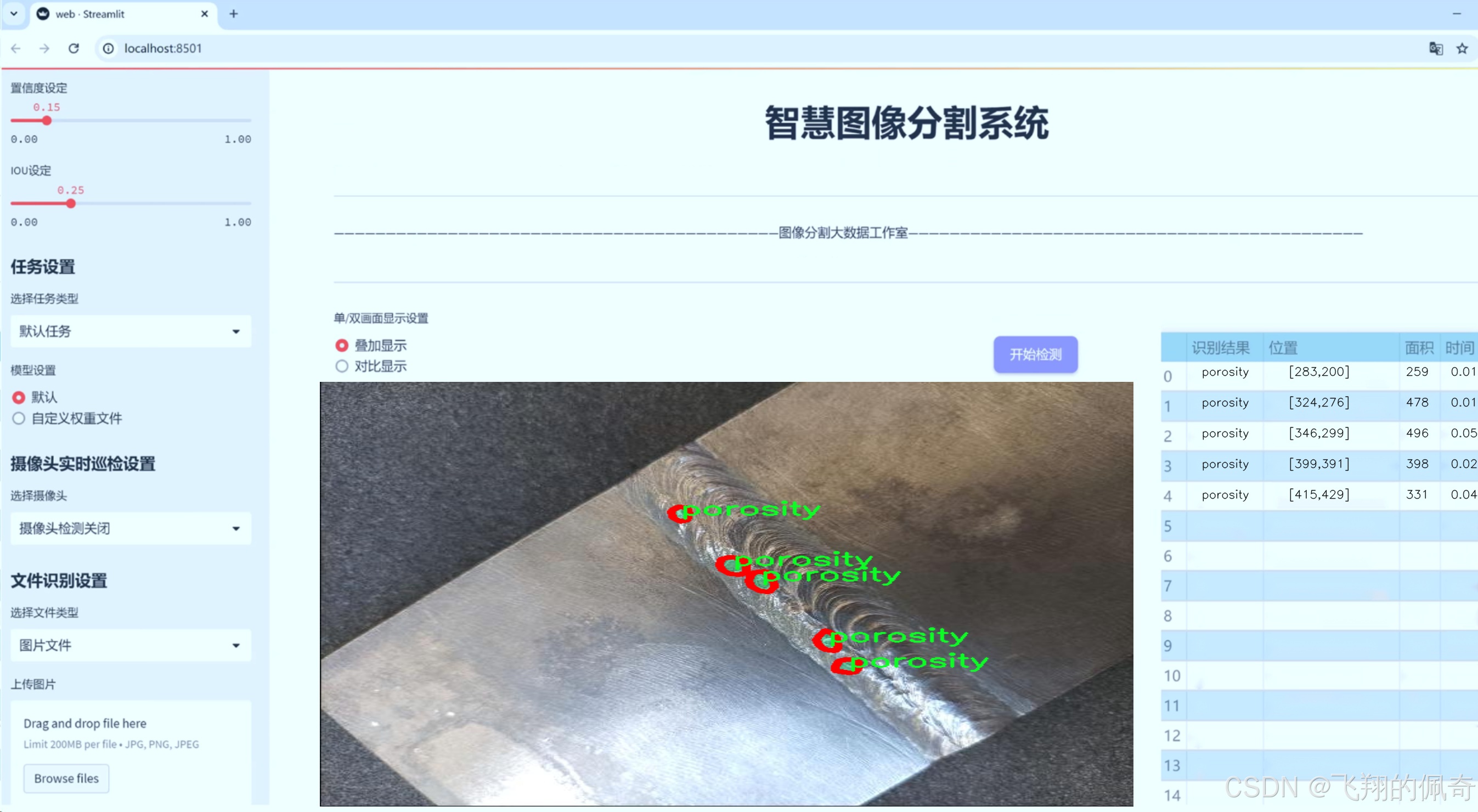
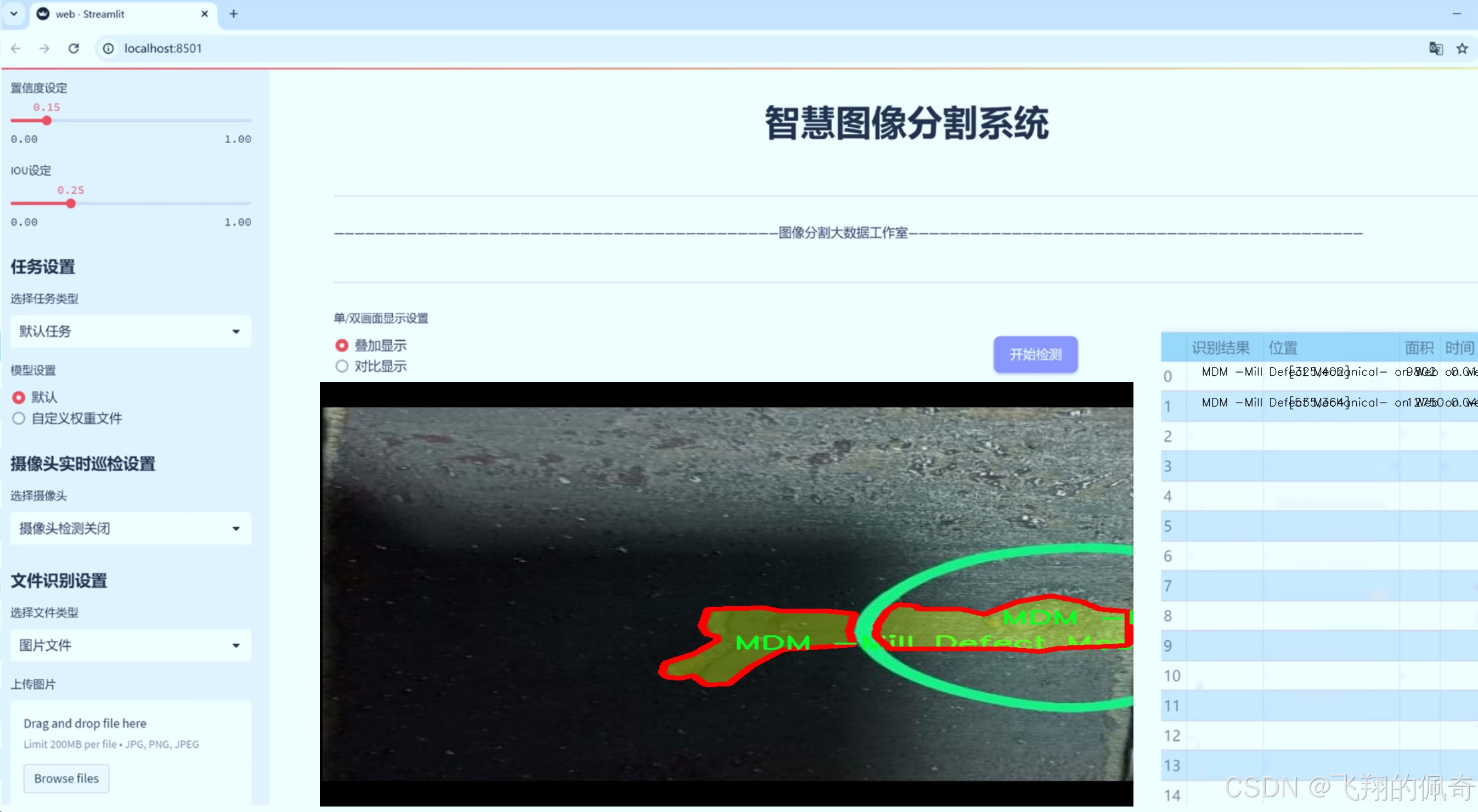
数据集信息
在本研究中,我们采用了名为“merged_metal_defect”的数据集,以训练和改进YOLOv8-seg模型,旨在实现高效的金属缺陷分割系统。该数据集专注于金属材料中的各种缺陷,涵盖了19个不同的类别,每个类别代表了一种特定的缺陷类型。这些缺陷的识别与分割对于金属加工和制造行业至关重要,因为它们直接影响到产品的质量和安全性。
数据集中包含的类别包括“Bump Mark 2-3 steps”、“Fire Crack”、“Flange wavy”、“GM-Guide Mark-”、“Heavy wear out on both top flange”、“Heavy wear out”、“LC -Longitudinal Crack-”、“LNF -Lock not Found- on South flange in Sheet Pile”、“Lap - Sliver on north top Junction”、“Lap on South top flange tip”、“Lap on south outer flange heavy section”、“Lap”、“MDM -Mill Defect Mechanical- on Web on web”、“RPB -Roll Burr Pit- on Web”、“Step in flange”、“Twist in CR-80 Rail”、“Web wavy”、“crack”和“porosity”。这些类别的多样性反映了金属材料在生产和使用过程中可能遭遇的各种缺陷类型,涵盖了从表面缺陷到结构性缺陷的广泛范围。
数据集的构建过程经过精心设计,确保了样本的多样性和代表性。每个类别的样本数量均衡,以避免模型在训练过程中对某些类别的偏向。此外,数据集中的图像均经过专业标注,确保每个缺陷的边界清晰可辨。这种高质量的标注为YOLOv8-seg模型的训练提供了坚实的基础,使其能够在实际应用中实现高精度的缺陷检测和分割。
在数据预处理阶段,我们对图像进行了标准化处理,以提高模型的训练效率和效果。图像的尺寸被统一调整,以适应YOLOv8-seg模型的输入要求。同时,为了增强模型的鲁棒性,我们还采用了数据增强技术,包括随机裁剪、旋转、翻转等操作,以生成更多的训练样本。这些技术的应用不仅丰富了数据集的多样性,还有效提升了模型在面对不同环境和条件下的适应能力。
通过对“merged_metal_defect”数据集的深入分析和应用,我们期望能够显著提升YOLOv8-seg模型在金属缺陷分割任务中的表现。该数据集不仅为模型的训练提供了丰富的样本,还为后续的模型评估和优化奠定了基础。我们相信,借助这一高质量的数据集,所构建的金属缺陷分割系统将能够在实际工业应用中发挥重要作用,帮助企业提高生产效率,降低缺陷率,从而提升产品的整体质量和市场竞争力。




核心代码
```python
import sys
import subprocess
from QtFusion.path import abs_path
def run_script(script_path):
"""
使用当前 Python 环境运行指定的脚本。
Args:
script_path (str): 要运行的脚本路径
"""
# 获取当前 Python 解释器的路径
python_path = sys.executable
# 构建运行命令,使用 streamlit 运行指定的脚本
command = f'"{python_path}" -m streamlit run "{script_path}"'
# 执行命令,并等待其完成
result = subprocess.run(command, shell=True)
# 检查命令执行结果,如果返回码不为0,则表示出错
if result.returncode != 0:
print("脚本运行出错。")
# 主程序入口
if __name__ == "__main__":
# 获取要运行的脚本的绝对路径
script_path = abs_path("web.py")
# 调用函数运行脚本
run_script(script_path)
代码注释说明:
-
导入模块:
sys:用于获取当前 Python 解释器的路径。subprocess:用于执行外部命令。abs_path:从QtFusion.path模块导入的函数,用于获取文件的绝对路径。
-
run_script函数:- 该函数接收一个脚本路径作为参数,并使用当前 Python 环境运行该脚本。
- 使用
sys.executable获取当前 Python 解释器的路径。 - 构建一个命令字符串,使用
streamlit模块运行指定的脚本。 - 使用
subprocess.run执行命令,并检查返回码以判断脚本是否成功运行。
-
主程序入口:
- 在
if __name__ == "__main__":块中,获取要运行的脚本的绝对路径,并调用run_script函数执行该脚本。```
这个文件是一个 Python 脚本,主要功能是通过当前的 Python 环境运行一个指定的脚本,具体来说是运行一个名为web.py的文件。首先,文件导入了几个必要的模块,包括sys、os和subprocess,这些模块分别用于访问 Python 解释器的信息、处理文件路径和执行系统命令。
- 在
在 run_script 函数中,首先获取当前 Python 解释器的路径,存储在 python_path 变量中。接着,构建一个命令字符串,该命令使用 Streamlit 框架来运行指定的脚本。这里使用了 -m streamlit run 命令来启动 Streamlit 应用,并将脚本路径作为参数传入。
随后,使用 subprocess.run 方法执行构建好的命令。这个方法会在一个新的子进程中运行命令,并等待其完成。命令执行完成后,通过检查 result.returncode 来判断脚本是否成功运行。如果返回码不为零,表示脚本运行出错,程序会打印出相应的错误信息。
在文件的最后部分,使用 if __name__ == "__main__": 语句来确保当脚本作为主程序运行时,才会执行后面的代码。这里指定了要运行的脚本路径为 web.py,并调用 run_script 函数来执行它。
总的来说,这个脚本的作用是简化通过 Streamlit 运行一个特定 Python 脚本的过程,使得用户可以方便地启动 Web 应用。
```python
# 导入必要的模块
from .rtdetr import RTDETR # 导入 RTDETR 模块
from .sam import SAM # 导入 SAM 模块
from .yolo import YOLO # 导入 YOLO 模块
# 定义可导出的模块列表
__all__ = 'YOLO', 'RTDETR', 'SAM' # 允许简化导入,指定哪些模块可以被外部访问
代码注释说明:
-
模块导入:
from .rtdetr import RTDETR:从当前包的rtdetr模块中导入RTDETR类或函数。from .sam import SAM:从当前包的sam模块中导入SAM类或函数。from .yolo import YOLO:从当前包的yolo模块中导入YOLO类或函数。
-
可导出模块定义:
__all__是一个特殊变量,用于定义当前模块中可以被外部导入的名称。这里指定了YOLO、RTDETR和SAM,这意味着当使用from module import *时,只会导入这三个模块。这样可以控制模块的可见性,避免不必要的名称冲突。```
这个程序文件是Ultralytics YOLO项目的一部分,主要用于定义和导入模型。文件开头的注释部分表明该项目使用的是AGPL-3.0许可证,说明了其开源性质和使用条款。
接下来的代码通过相对导入的方式引入了三个模型:RTDETR、SAM和YOLO。这些模型分别定义在同一目录下的不同模块中。RTDETR和SAM可能是与YOLO模型相关的其他深度学习模型或工具,具体功能可以根据其各自的实现来理解。
最后,__all__变量的定义是为了控制模块的导入行为。它列出了在使用from module import *语句时,允许被导入的名称。在这里,只有’YOLO’、'RTDETR’和’SAM’这三个模型会被导入,从而简化了用户的导入过程,避免了不必要的命名冲突或混乱。
总体而言,这个文件的主要功能是组织和简化模型的导入,使得用户在使用Ultralytics YOLO库时可以更方便地访问所需的模型。
```python
from pathlib import Path
import torch
from ultralytics.engine.model import Model
from ultralytics.utils.torch_utils import model_info, smart_inference_mode
from .predict import NASPredictor
from .val import NASValidator
class NAS(Model):
"""
YOLO NAS模型用于目标检测。
该类提供了YOLO-NAS模型的接口,并扩展了Ultralytics引擎中的`Model`类。
它旨在通过预训练或自定义训练的YOLO-NAS模型来简化目标检测任务。
"""
def __init__(self, model='yolo_nas_s.pt') -> None:
"""初始化NAS模型,使用提供的或默认的'yolo_nas_s.pt'模型。"""
# 确保提供的模型路径不是YAML配置文件
assert Path(model).suffix not in ('.yaml', '.yml'), 'YOLO-NAS模型仅支持预训练模型。'
# 调用父类构造函数
super().__init__(model, task='detect')
@smart_inference_mode()
def _load(self, weights: str, task: str):
"""加载现有的NAS模型权重,或在未提供权重时创建一个新的NAS模型并使用预训练权重。"""
import super_gradients
suffix = Path(weights).suffix
# 根据权重文件的后缀加载模型
if suffix == '.pt':
self.model = torch.load(weights) # 从.pt文件加载模型
elif suffix == '':
self.model = super_gradients.training.models.get(weights, pretrained_weights='coco') # 获取预训练模型
# 标准化模型
self.model.fuse = lambda verbose=True: self.model # 定义模型融合方法
self.model.stride = torch.tensor([32]) # 设置模型步幅
self.model.names = dict(enumerate(self.model._class_names)) # 设置类别名称
self.model.is_fused = lambda: False # 用于信息获取
self.model.yaml = {} # 用于信息获取
self.model.pt_path = weights # 用于导出
self.model.task = 'detect' # 设置任务类型
def info(self, detailed=False, verbose=True):
"""
记录模型信息。
参数:
detailed (bool): 是否显示模型的详细信息。
verbose (bool): 控制输出的详细程度。
"""
return model_info(self.model, detailed=detailed, verbose=verbose, imgsz=640)
@property
def task_map(self):
"""返回一个字典,将任务映射到相应的预测器和验证器类。"""
return {'detect': {'predictor': NASPredictor, 'validator': NASValidator}}
代码核心部分说明:
- 类定义:
NAS类继承自Model类,主要用于YOLO-NAS模型的目标检测。 - 初始化方法:在
__init__方法中,检查模型文件类型并调用父类的初始化方法。 - 加载模型:
_load方法用于加载模型权重,支持从.pt文件或通过名称获取预训练模型。 - 模型信息:
info方法用于输出模型的详细信息,便于用户了解模型的结构和参数。 - 任务映射:
task_map属性返回一个字典,映射目标检测任务到相应的预测器和验证器类。```
这个程序文件是Ultralytics YOLO(You Only Look Once)系列中的一个模型接口,主要用于实现YOLO-NAS(Neural Architecture Search)模型的对象检测功能。文件的开头包含了版权信息和一个简单的使用示例,展示了如何导入和使用NAS模型进行预测。
在代码中,首先导入了一些必要的库和模块,包括Path(用于处理文件路径)、torch(PyTorch库,用于深度学习)以及Ultralytics引擎中的Model类和一些工具函数。接着,定义了一个名为NAS的类,该类继承自Model类,提供了YOLO-NAS模型的接口。
NAS类的构造函数__init__接受一个参数model,默认值为’yolo_nas_s.pt’,用于初始化模型。构造函数中有一个断言,确保传入的模型路径后缀不是.yaml或.yml,因为YOLO-NAS模型只支持预训练模型,而不支持YAML配置文件。
_load方法用于加载现有的NAS模型权重,或者在未提供权重的情况下创建一个新的NAS模型。该方法根据权重文件的后缀判断是加载本地的.pt文件,还是从super_gradients库中获取预训练模型。加载完成后,模型的一些属性(如fuse、stride、names等)会被标准化,以便后续使用。
info方法用于记录和输出模型的信息,接受两个参数detailed和verbose,用于控制输出的详细程度和冗长程度。
最后,task_map属性返回一个字典,映射任务到相应的预测器和验证器类,当前只支持对象检测任务。
总体而言,这个文件提供了一个清晰的接口,方便用户使用YOLO-NAS模型进行对象检测,并且包含了必要的模型加载和信息记录功能。
```python
import os
import torch
import yaml
from ultralytics import YOLO # 导入YOLO模型库
if __name__ == '__main__': # 确保该模块被直接运行时才执行以下代码
# 设置训练参数
workers = 1 # 数据加载的工作进程数
batch = 8 # 每个批次的样本数量
device = "0" if torch.cuda.is_available() else "cpu" # 检查是否有可用的GPU
# 获取数据集配置文件的绝对路径
data_path = abs_path(f'datasets/data/data.yaml', path_type='current')
# 读取YAML文件并修改路径
with open(data_path, 'r') as file:
data = yaml.load(file, Loader=yaml.FullLoader) # 读取YAML文件内容
# 修改训练、验证和测试数据的路径
if 'train' in data and 'val' in data and 'test' in data:
directory_path = os.path.dirname(data_path.replace(os.sep, '/')) # 获取目录路径
data['train'] = directory_path + '/train' # 更新训练数据路径
data['val'] = directory_path + '/val' # 更新验证数据路径
data['test'] = directory_path + '/test' # 更新测试数据路径
# 将修改后的数据写回YAML文件
with open(data_path, 'w') as file:
yaml.safe_dump(data, file, sort_keys=False) # 保存修改后的数据
# 加载YOLO模型配置和预训练权重
model = YOLO(r"C:\codeseg\codenew\50+种YOLOv8算法改进源码大全和调试加载训练教程(非必要)\改进YOLOv8模型配置文件\yolov8-seg-C2f-Faster.yaml").load("./weights/yolov8s-seg.pt")
# 开始训练模型
results = model.train(
data=data_path, # 指定训练数据的配置文件路径
device=device, # 指定训练设备
workers=workers, # 指定数据加载的工作进程数
imgsz=640, # 输入图像的大小
epochs=100, # 训练的轮数
batch=batch, # 每个批次的样本数量
)
代码注释说明:
- 导入库:导入必要的库,包括
os、torch、yaml和YOLO模型库。 - 主程序入口:使用
if __name__ == '__main__':确保代码只在直接运行时执行。 - 参数设置:
workers:设置数据加载的工作进程数。batch:设置每个批次的样本数量。device:根据是否有可用的GPU选择设备。
- 数据路径处理:
- 读取YAML文件,获取数据集的配置,并更新训练、验证和测试数据的路径。
- 模型加载:加载YOLO模型的配置文件和预训练权重。
- 模型训练:调用
model.train()方法开始训练,传入必要的参数,如数据路径、设备、工作进程数、图像大小和训练轮数。```
该程序文件train.py的主要功能是使用YOLO(You Only Look Once)模型进行目标检测的训练。程序首先导入了必要的库,包括操作系统相关的os、深度学习框架torch、YAML文件处理库yaml以及YOLO模型的实现库ultralytics。此外,还设置了Matplotlib的后端为’TkAgg’,以便于可视化。
在__main__模块中,程序首先设置了一些训练参数,包括工作进程数workers、批次大小batch和设备类型device。设备类型会根据当前是否有可用的GPU(CUDA)进行选择,如果有则使用GPU,否则使用CPU。接着,程序通过abs_path函数获取数据集配置文件data.yaml的绝对路径,并将其转换为Unix风格的路径。
随后,程序读取YAML文件中的内容,并检查是否包含train、val和test这三个字段。如果存在,这些字段的路径会被修改为相对于数据集目录的路径。修改后的数据会被写回到原来的YAML文件中,以确保后续训练可以正确找到数据。
接下来,程序加载YOLO模型的配置文件,并使用预训练的权重文件进行初始化。模型的配置文件路径是硬编码的,指向了本地的一个特定位置。
最后,程序调用model.train方法开始训练模型。训练时指定了数据配置文件的路径、设备、工作进程数、输入图像的大小(640x640)、训练的轮数(100个epoch)以及每个批次的大小(8)。这些参数可以根据实际情况进行调整,以适应不同的硬件条件和训练需求。
总体来说,该程序文件是一个完整的YOLO模型训练脚本,涵盖了数据准备、模型加载和训练过程的各个环节。
```python
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
def calculate_polygon_area(points):
"""
计算多边形的面积,输入应为一个 Nx2 的numpy数组,表示多边形的顶点坐标
"""
if len(points) < 3: # 多边形至少需要3个顶点
return 0
return cv2.contourArea(points)
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
"""
在OpenCV图像上绘制中文文字
"""
# 将图像从 OpenCV 格式(BGR)转换为 PIL 格式(RGB)
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
# 使用指定的字体
font = ImageFont.truetype("simsun.ttc", font_size, encoding="unic")
draw.text(position, text, font=font, fill=color)
# 将图像从 PIL 格式(RGB)转换回 OpenCV 格式(BGR)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
def generate_color_based_on_name(name):
"""
使用哈希函数生成稳定的颜色
"""
hash_object = md5(name.encode())
hex_color = hash_object.hexdigest()[:6] # 取前6位16进制数
r, g, b = int(hex_color[0:2], 16), int(hex_color[2:4], 16), int(hex_color[4:6], 16)
return (b, g, r) # OpenCV 使用BGR格式
def draw_detections(image, info, alpha=0.2):
"""
在图像上绘制检测结果,包括边界框和标签
"""
name, bbox, conf, cls_id, mask = info['class_name'], info['bbox'], info['score'], info['class_id'], info['mask']
x1, y1, x2, y2 = bbox
# 绘制边界框
cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=3)
# 绘制类别名称
image = draw_with_chinese(image, name, (x1, y1 - 10), font_size=20)
return image
def frame_process(image, model, conf_threshold=0.15, iou_threshold=0.5):
"""
处理并预测单个图像帧的内容。
Args:
image (numpy.ndarray): 输入的图像。
model: 训练好的模型。
conf_threshold (float): 置信度阈值。
iou_threshold (float): IOU阈值。
Returns:
tuple: 处理后的图像,检测信息。
"""
pre_img = model.preprocess(image) # 对图像进行预处理
params = {'conf': conf_threshold, 'iou': iou_threshold}
model.set_param(params) # 更新模型参数
pred = model.predict(pre_img) # 使用模型进行预测
det_info = model.postprocess(pred) # 后处理预测结果
# 遍历检测到的对象并绘制
for info in det_info:
image = draw_detections(image, info)
return image, det_info
# 示例:假设有一个训练好的模型实例和输入图像
# model = ... # 加载或创建模型实例
# image = cv2.imread('input_image.jpg') # 读取输入图像
# processed_image, detections = frame_process(image, model)
# cv2.imshow('Detections', processed_image)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
代码核心部分解释:
-
计算多边形面积:
calculate_polygon_area函数用于计算多边形的面积,输入为多边形的顶点坐标。 -
绘制中文文本:
draw_with_chinese函数使用 PIL 库在 OpenCV 图像上绘制中文文本,支持指定位置、字体大小和颜色。 -
生成颜色:
generate_color_based_on_name函数根据输入的名称生成一个稳定的颜色,使用 MD5 哈希算法确保同一名称总是生成相同的颜色。 -
绘制检测结果:
draw_detections函数在图像上绘制检测结果,包括边界框和类别名称。 -
处理图像帧:
frame_process函数对输入图像进行预处理,使用模型进行预测,并绘制检测结果。返回处理后的图像和检测信息。
这些函数构成了图像处理和目标检测的核心逻辑,可以用于实现图像中的目标检测和标注功能。```
这个程序文件 web.py 是一个基于 Streamlit 的图像分割和目标检测系统,主要用于实时处理视频流或上传的图像/视频文件。程序的核心功能包括加载模型、处理图像、进行目标检测、绘制检测结果,并将结果展示在网页上。
程序首先导入了必要的库,包括用于图像处理的 OpenCV、用于数据处理的 NumPy、用于创建网页应用的 Streamlit,以及一些自定义的工具和模型类。接着,定义了一些辅助函数,例如计算多边形面积、在图像上绘制中文文本、生成基于名称的颜色等。
Detection_UI 类是程序的核心,负责初始化和管理整个检测系统。类的构造函数中,设置了模型类型、置信度阈值、IOU 阈值等参数,并初始化了摄像头和文件相关的变量。通过 Streamlit 的功能,构建了用户界面,包括侧边栏的设置、图像和视频的显示区域、结果表格等。
在 setup_sidebar 方法中,用户可以选择模型类型、摄像头、文件类型等,并上传文件。程序支持两种输入方式:实时摄像头输入和上传的图像/视频文件。在 process_camera_or_file 方法中,根据用户的选择,程序会处理摄像头或文件输入,进行目标检测,并实时更新检测结果。
frame_process 方法负责对每一帧图像进行处理,包括预处理、模型预测和后处理。检测到的目标会被绘制在图像上,并记录相关信息,如目标名称、边界框、置信度等。程序还提供了保存检测结果的功能,可以将检测结果保存为 CSV 文件,并在网页上展示。
在用户界面中,程序提供了进度条、图像显示区域和结果表格,用户可以实时查看检测结果和处理进度。用户还可以通过按钮启动检测、导出结果等操作。
总的来说,这个程序实现了一个完整的图像分割和目标检测系统,用户可以通过简单的界面与程序交互,进行实时检测和结果分析。
```python
import os
import glob
import torch
from torch.utils.cpp_extension import CUDA_HOME, CppExtension, CUDAExtension
from setuptools import find_packages, setup
# 定义所需的依赖包
requirements = ["torch", "torchvision"]
def get_extensions():
# 获取当前文件的目录
this_dir = os.path.dirname(os.path.abspath(__file__))
# 定义扩展源代码的目录
extensions_dir = os.path.join(this_dir, "src")
# 获取主文件和CPU、CUDA源文件
main_file = glob.glob(os.path.join(extensions_dir, "*.cpp"))
source_cpu = glob.glob(os.path.join(extensions_dir, "cpu", "*.cpp"))
source_cuda = glob.glob(os.path.join(extensions_dir, "cuda", "*.cu"))
# 将主文件和CPU源文件合并
sources = main_file + source_cpu
extension = CppExtension # 默认使用 CppExtension
extra_compile_args = {"cxx": []} # 编译参数
define_macros = [] # 宏定义
# 检查CUDA是否可用
if torch.cuda.is_available() and CUDA_HOME is not None:
extension = CUDAExtension # 使用 CUDAExtension
sources += source_cuda # 添加CUDA源文件
define_macros += [("WITH_CUDA", None)] # 定义WITH_CUDA宏
extra_compile_args["nvcc"] = [] # 可以添加CUDA编译参数
else:
raise NotImplementedError('Cuda is not available') # 如果CUDA不可用,抛出异常
# 构建源文件的完整路径
sources = [os.path.join(extensions_dir, s) for s in sources]
include_dirs = [extensions_dir] # 包含目录
ext_modules = [
extension(
"DCNv3", # 扩展模块名称
sources, # 源文件列表
include_dirs=include_dirs, # 包含目录
define_macros=define_macros, # 宏定义
extra_compile_args=extra_compile_args, # 编译参数
)
]
return ext_modules # 返回扩展模块列表
# 设置包信息和扩展模块
setup(
name="DCNv3", # 包名称
version="1.1", # 版本号
author="InternImage", # 作者
url="https://github.com/OpenGVLab/InternImage", # 项目链接
description="PyTorch Wrapper for CUDA Functions of DCNv3", # 描述
packages=find_packages(exclude=("configs", "tests")), # 查找包,排除指定目录
ext_modules=get_extensions(), # 获取扩展模块
cmdclass={"build_ext": torch.utils.cpp_extension.BuildExtension}, # 指定构建扩展的命令类
)
代码说明:
- 导入模块:导入必要的库和模块,包括操作系统、文件查找、PyTorch及其扩展工具、以及设置工具。
- 获取扩展函数:
get_extensions函数用于查找并构建 C++ 和 CUDA 扩展模块。- 它会检查 CUDA 是否可用,并根据情况选择合适的扩展类型(
CppExtension或CUDAExtension)。 - 收集源文件并构建扩展模块的参数。
- 它会检查 CUDA 是否可用,并根据情况选择合适的扩展类型(
- 设置包信息:使用
setuptools的setup函数定义包的名称、版本、作者、描述等信息,并指定扩展模块。```
这个程序文件是一个用于设置和编译DCNv3(Deformable Convolutional Networks v3)扩展模块的Python脚本,文件名为setup.py,它使用了setuptools和torch.utils.cpp_extension来实现C++和CUDA的扩展功能。
首先,文件开头包含了一些版权信息和许可证声明,表明该代码是由OpenGVLab开发并遵循MIT许可证。
接下来,程序导入了一些必要的库,包括os和glob用于文件路径处理,torch用于PyTorch相关的操作,以及CUDA_HOME、CppExtension和CUDAExtension用于编译C++和CUDA扩展。
在requirements变量中,定义了该模块所需的依赖包,包括torch和torchvision。
get_extensions函数是该文件的核心部分。它首先获取当前文件的目录,并构建扩展源代码的路径。然后,使用glob模块查找指定目录下的C++和CUDA源文件。具体来说,它查找src目录下的主C++文件、CPU相关的C++文件以及CUDA相关的文件。
接下来,程序将主文件和CPU源文件合并到sources列表中,并初始化extension为CppExtension。如果系统支持CUDA(即torch.cuda.is_available()返回True),则将extension更改为CUDAExtension,并将CUDA源文件添加到sources中。同时,定义了一些宏和编译参数,以便在编译时启用CUDA支持。如果CUDA不可用,程序将抛出一个NotImplementedError异常。
之后,程序将所有源文件的路径添加到sources列表中,并指定包含目录。接着,创建一个扩展模块的列表ext_modules,其中包含了DCNv3扩展的相关信息。
最后,调用setup函数来配置包的基本信息,包括包名、版本、作者、项目网址、描述、需要排除的包(如configs和tests),以及通过get_extensions函数获取的扩展模块。cmdclass参数指定了构建扩展时使用的命令类。
总体来说,这个setup.py文件的主要功能是配置和编译DCNv3的C++和CUDA扩展,使其能够在PyTorch中使用。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 25
25 0
0- 0



 已为社区贡献242条内容
已为社区贡献242条内容

所有评论(0)