【完整源码+数据集+部署教程】哥伦比亚手语分割系统源码&数据集分享 [yolov8-seg-AFPN-P345&yolov8-seg-RCSOSA等50+全套改进创新点发刊_一键训练教程_Web前端
【完整源码+数据集+部署教程】哥伦比亚手语分割系统源码&数据集分享[yolov8-seg-AFPN-P345&yolov8-seg-RCSOSA等50+全套改进创新点发刊_一键训练教程_Web前端
背景意义
随着信息技术的迅猛发展,人工智能在各个领域的应用日益广泛,尤其是在计算机视觉和自然语言处理领域。手语作为一种重要的交流方式,尤其在聋哑人群体中扮演着不可或缺的角色。然而,由于手语的表达方式与口语存在显著差异,传统的语音识别和文本翻译技术难以满足手语翻译的需求。因此,基于计算机视觉的手语识别与分割技术应运而生,成为提升聋哑人群体沟通能力的重要工具。
在这一背景下,哥伦比亚手语(Lengua de Señas Colombiana, LSC)的研究尤为重要。LSC作为哥伦比亚的官方手语,其独特的手势和符号体系不仅承载着丰富的文化内涵,也反映了当地的社会习俗和语言特征。尽管已有一些研究致力于手语识别,但针对哥伦比亚手语的系统化研究仍然相对较少。因此,构建一个高效、准确的哥伦比亚手语分割系统具有重要的学术价值和社会意义。
本研究基于改进的YOLOv8模型,旨在实现对哥伦比亚手语的实例分割。YOLO(You Only Look Once)系列模型因其高效的实时检测能力而广泛应用于目标检测领域。通过对YOLOv8进行改进,能够更好地适应手语分割的需求,提升模型在复杂背景下的分割精度和速度。本研究所使用的数据集包含1600张图像,涵盖21个手语类别,包括字母a到y。这一数据集的构建为手语识别提供了丰富的样本支持,能够有效训练和验证模型的性能。
手语分割系统的构建不仅有助于提高手语识别的准确性,还能为后续的手语翻译、教育和人机交互等应用奠定基础。通过将手语转化为可视化的信息,能够有效促进聋哑人与社会的沟通,提升他们的生活质量。此外,手语识别技术的进步也将推动相关领域的研究,如智能家居、虚拟助手等,使得这些技术能够更好地服务于不同的用户群体。
综上所述,基于改进YOLOv8的哥伦比亚手语分割系统的研究,不仅具有重要的理论意义,也具备广泛的应用前景。通过这一研究,期望能够填补哥伦比亚手语研究领域的空白,推动手语识别技术的发展,为聋哑人群体的沟通提供更为有效的解决方案。未来,随着技术的不断进步和数据集的不断丰富,手语识别系统有望在更大范围内得到应用,助力实现无障碍沟通的理想目标。
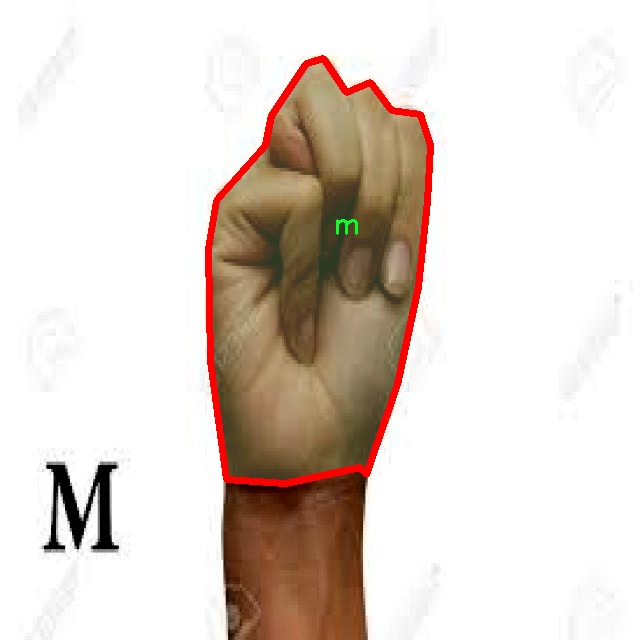
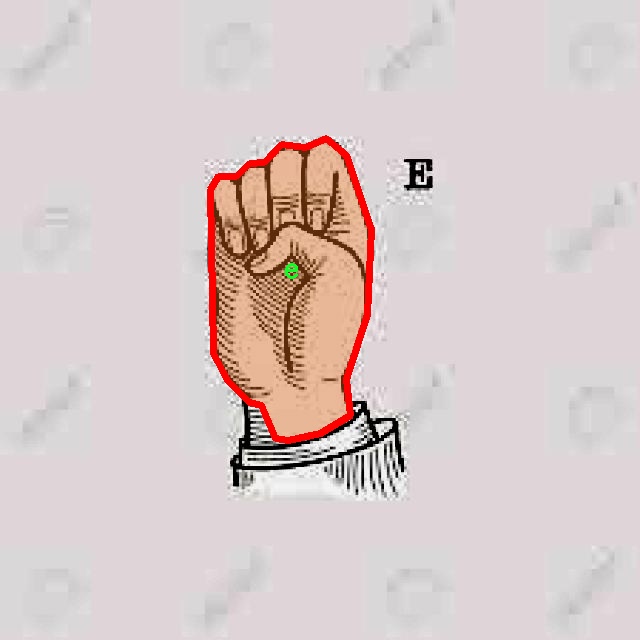
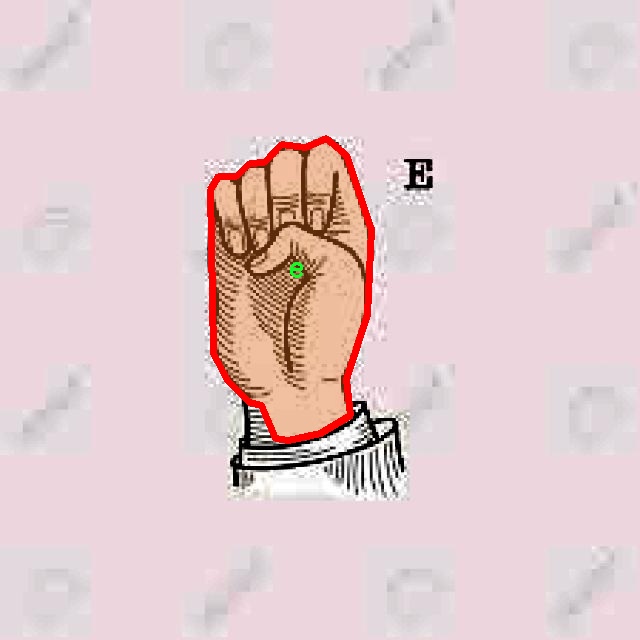
图片效果
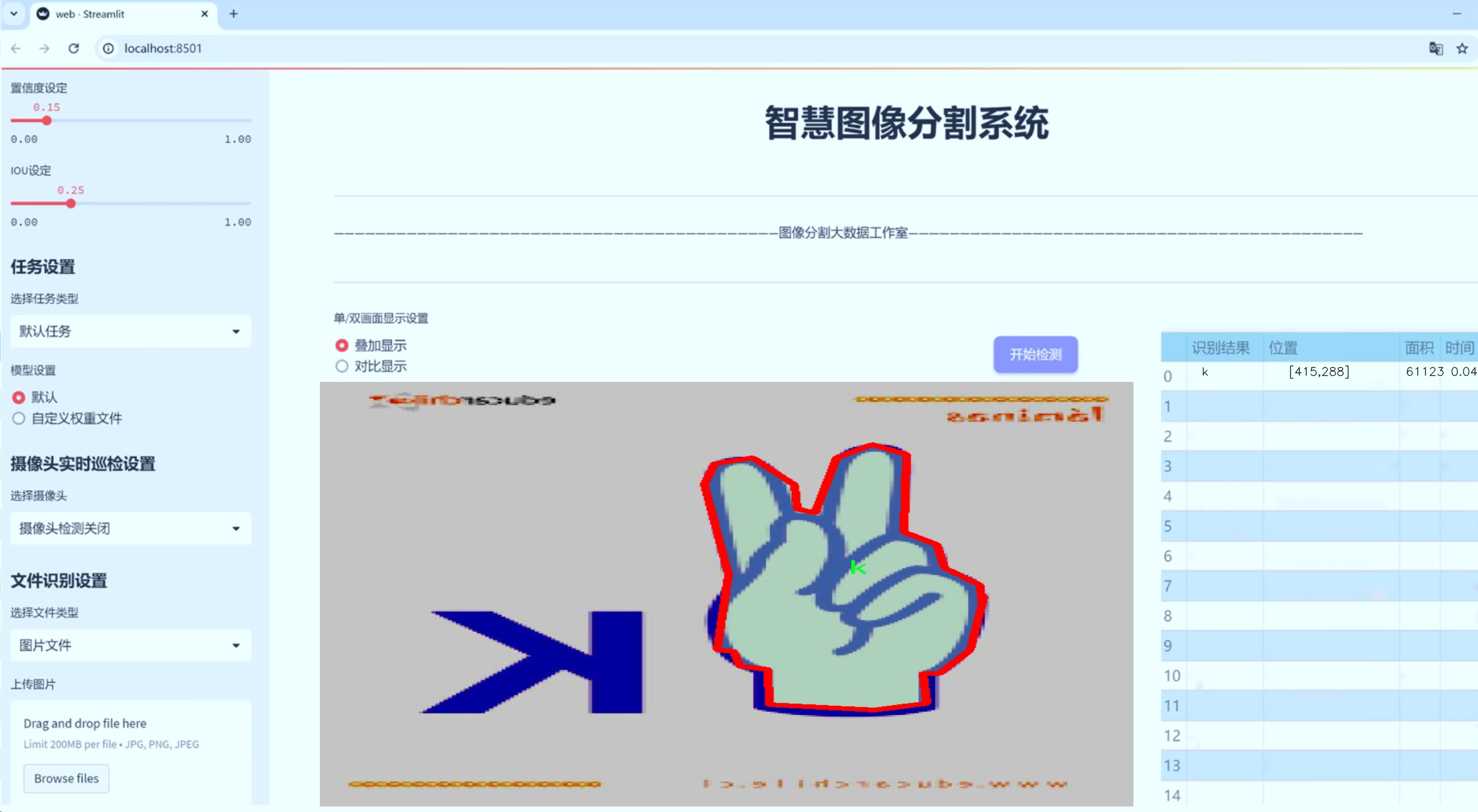
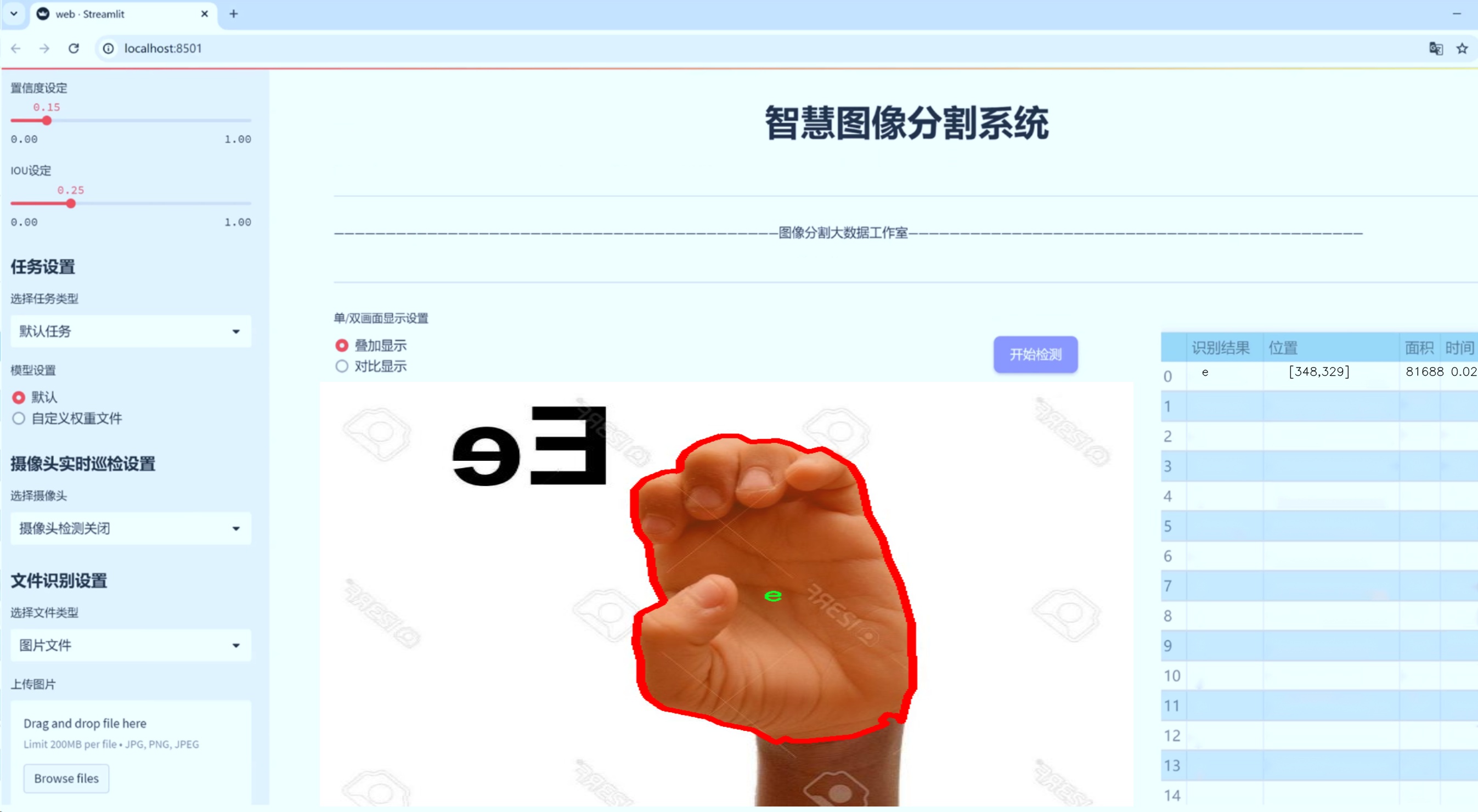
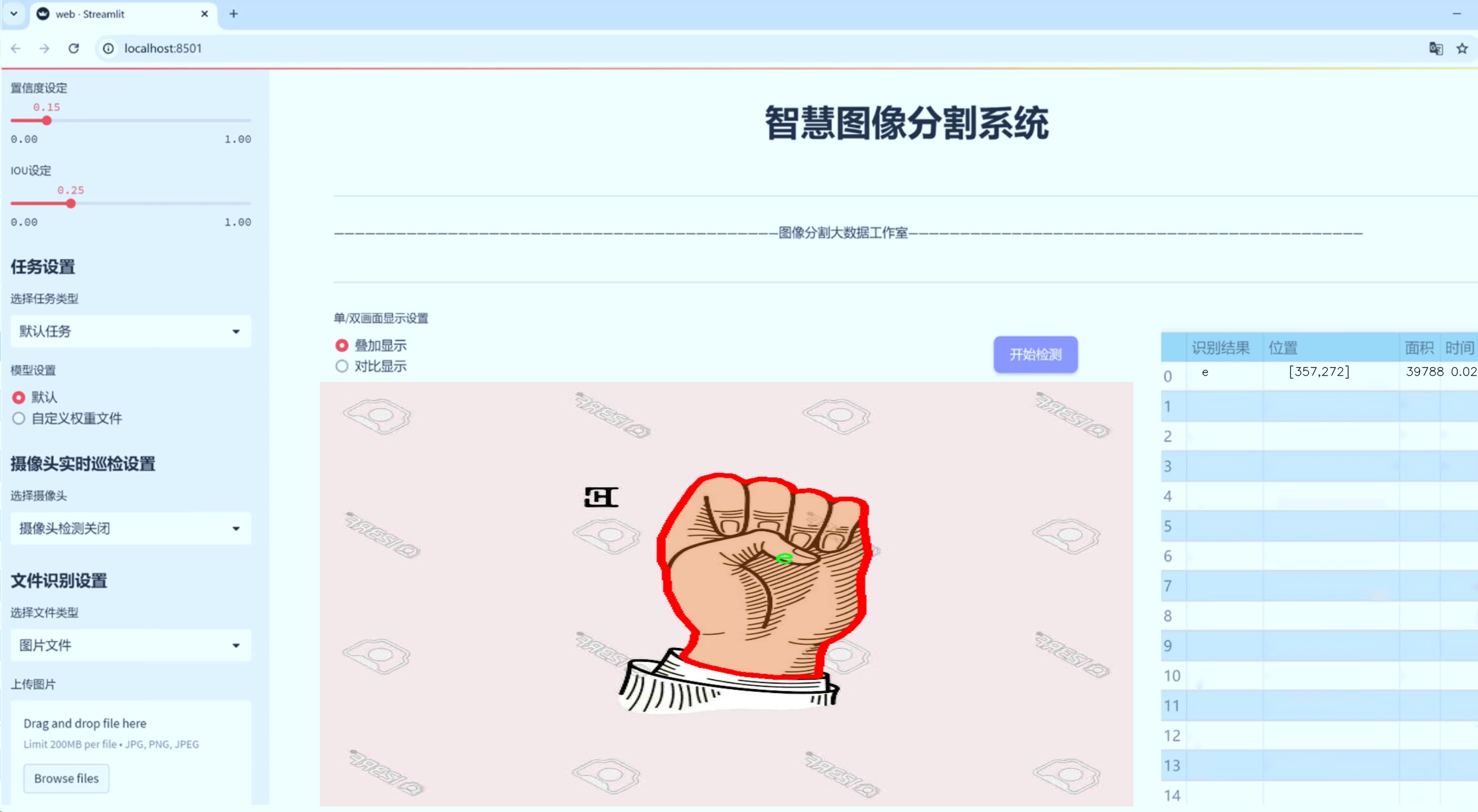
数据集信息
在本研究中,我们使用了名为“LenguaSenasColombiana”的数据集,以训练和改进YOLOv8-seg模型,旨在实现高效的哥伦比亚手语分割系统。该数据集专门针对哥伦比亚手语的特征进行构建,涵盖了21个不同的手语类别。这些类别分别为:‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘i’, ‘k’, ‘l’, ‘m’, ‘n’, ‘o’, ‘p’, ‘q’, ‘r’, ‘t’, ‘u’, ‘v’, ‘w’, ‘x’, ‘y’。每个类别代表了哥伦比亚手语中的一个基本手势,构成了该语言的基础词汇。
数据集的设计充分考虑了手语的多样性和复杂性。每个手势在不同的背景、光照条件和手部姿态下均进行了采集,以确保模型在实际应用中的鲁棒性和准确性。数据集中包含了大量的图像和视频数据,这些数据通过专业的手语使用者进行标注,确保了每个手势的准确性和一致性。为了提高模型的泛化能力,数据集还包括了不同年龄、性别和肤色的手语使用者,反映了哥伦比亚社会的多样性。
在数据预处理阶段,我们对图像进行了标准化处理,包括尺寸调整、颜色空间转换和数据增强等。这些步骤旨在提高模型的训练效率和分割精度。此外,数据集中还提供了详细的标注信息,包括每个手势的边界框和分割掩码,便于YOLOv8-seg模型进行有效的学习和推理。
在训练过程中,我们采用了交叉验证的方法,以评估模型在不同数据子集上的表现。这种方法不仅能够帮助我们识别模型的潜在过拟合问题,还能为模型的调优提供重要的反馈。通过不断调整超参数和网络结构,我们力求在手势识别的准确性和实时性之间找到最佳平衡。
值得一提的是,哥伦比亚手语作为一种视觉语言,其表达方式与口语有着显著的不同。因此,在模型训练中,我们特别关注手势的动态特征和时序信息。这使得我们不仅能够识别静态手势,还能有效捕捉手势的变化过程,从而提高模型在实际应用中的实用性。
总之,“LenguaSenasColombiana”数据集为我们提供了一个丰富的资源,以支持YOLOv8-seg模型在哥伦比亚手语分割任务中的训练与评估。通过充分利用这一数据集,我们期望能够推动手语识别技术的发展,为听障人士提供更为便捷的沟通工具,并促进社会对手语文化的理解与尊重。随着研究的深入,我们相信这一系统将在未来的应用中展现出巨大的潜力和价值。
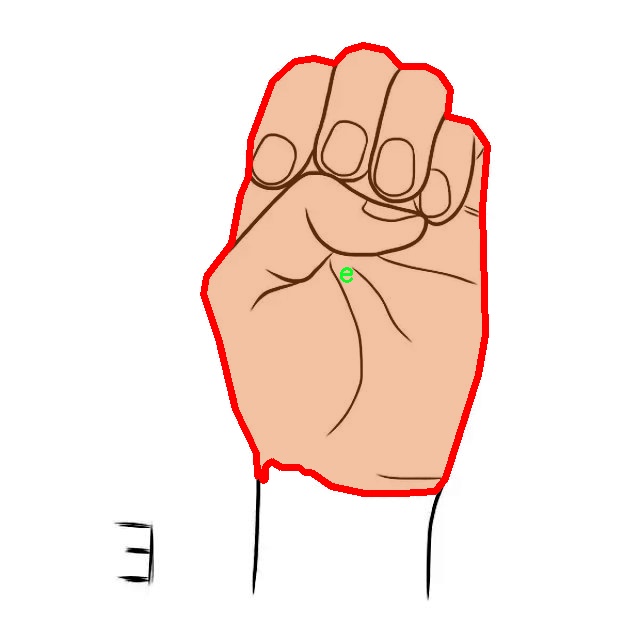
核心代码
```python
import os
import torch
import yaml
from ultralytics import YOLO # 导入YOLO模型库
if __name__ == '__main__': # 确保该模块被直接运行时才执行以下代码
# 设置训练参数
workers = 1 # 数据加载的工作进程数量
batch = 8 # 每个批次的样本数量
device = "0" if torch.cuda.is_available() else "cpu" # 检查是否有可用的GPU,如果没有则使用CPU
# 获取数据集配置文件的绝对路径
data_path = abs_path(f'datasets/data/data.yaml', path_type='current')
# 将路径转换为Unix风格
unix_style_path = data_path.replace(os.sep, '/')
# 获取数据集目录路径
directory_path = os.path.dirname(unix_style_path)
# 读取YAML文件,保持原有顺序
with open(data_path, 'r') as file:
data = yaml.load(file, Loader=yaml.FullLoader)
# 修改数据集路径
if 'train' in data and 'val' in data and 'test' in data:
data['train'] = directory_path + '/train' # 设置训练集路径
data['val'] = directory_path + '/val' # 设置验证集路径
data['test'] = directory_path + '/test' # 设置测试集路径
# 将修改后的数据写回YAML文件
with open(data_path, 'w') as file:
yaml.safe_dump(data, file, sort_keys=False)
# 加载YOLO模型
model = YOLO(r"C:\codeseg\codenew\50+种YOLOv8算法改进源码大全和调试加载训练教程(非必要)\改进YOLOv8模型配置文件\yolov8-seg-C2f-Faster.yaml").load("./weights/yolov8s-seg.pt")
# 开始训练模型
results = model.train(
data=data_path, # 指定训练数据的配置文件路径
device=device, # 使用的设备(GPU或CPU)
workers=workers, # 数据加载的工作进程数量
imgsz=640, # 输入图像的大小为640x640
epochs=100, # 训练100个epoch
batch=batch, # 每个批次的大小为8
)
代码分析:
- 导入必要的库:导入了操作系统、PyTorch、YAML解析库和YOLO模型库。
- 主程序入口:使用
if __name__ == '__main__':确保代码仅在直接运行时执行。 - 参数设置:
workers:设置数据加载的工作进程数量。batch:设置每个批次的样本数量。device:根据是否有可用的GPU来选择设备。
- 数据集路径处理:
- 获取数据集配置文件的绝对路径,并转换为Unix风格的路径。
- 读取YAML文件并修改训练、验证和测试集的路径。
- 模型加载:加载YOLO模型及其预训练权重。
- 模型训练:调用
model.train()方法开始训练,传入数据路径、设备、工作进程数量、图像大小、训练轮数和批次大小等参数。
以上是代码的核心部分和详细注释,帮助理解其功能和结构。```
这个程序文件train.py的主要功能是使用YOLO(You Only Look Once)模型进行目标检测的训练。首先,程序导入了一些必要的库,包括操作系统处理库os、深度学习框架torch、YAML文件处理库yaml以及YOLO模型的实现库ultralytics。此外,还导入了matplotlib库,用于可视化,但在这里主要是为了设置其后端为’TkAgg’。
在__main__模块中,程序首先定义了一些训练参数,包括工作进程数workers、批次大小batch、以及设备类型device。设备类型的选择基于是否有可用的GPU,如果有则使用GPU(设备编号为0),否则使用CPU。
接下来,程序通过abs_path函数获取数据集配置文件data.yaml的绝对路径,并将路径中的分隔符统一为Unix风格。然后,程序读取该YAML文件并解析其内容,确保在修改路径时保持原有的顺序。如果YAML文件中包含’train’、'val’和’test’字段,程序将这些字段的值修改为相应的训练、验证和测试数据集的路径,并将修改后的内容写回到YAML文件中。
接下来,程序加载YOLO模型。这里指定了一个YOLOv8的配置文件,并加载了预训练的权重文件。程序中有注释提到,不同的模型大小和配置对设备的要求不同,因此如果遇到显存不足的错误,可以尝试使用其他模型。
最后,程序调用model.train方法开始训练模型,传入训练数据的配置文件路径、设备类型、工作进程数、输入图像大小、训练的epoch数量以及批次大小等参数。训练过程将在指定的设备上进行,使用的图像大小为640x640,训练100个epoch,每个批次包含8张图像。
总体来说,这个程序文件的结构清晰,主要功能是配置并启动YOLO模型的训练过程,同时处理数据集路径的配置。
```python
class BOTrack(STrack):
"""
BOTrack类是YOLOv8中STrack类的扩展版本,增加了物体跟踪的功能。
"""
shared_kalman = KalmanFilterXYWH() # 所有BOTrack实例共享的卡尔曼滤波器
def __init__(self, tlwh, score, cls, feat=None, feat_history=50):
"""初始化BOTrack实例,设置初始参数,包括特征历史长度、平滑因子和当前特征。"""
super().__init__(tlwh, score, cls) # 调用父类构造函数
self.smooth_feat = None # 平滑特征向量
self.curr_feat = None # 当前特征向量
if feat is not None:
self.update_features(feat) # 如果提供了特征,则更新特征
self.features = deque([], maxlen=feat_history) # 存储特征向量的双端队列,最大长度为feat_history
self.alpha = 0.9 # 指数移动平均的平滑因子
def update_features(self, feat):
"""更新特征向量,并使用指数移动平均进行平滑处理。"""
feat /= np.linalg.norm(feat) # 归一化特征向量
self.curr_feat = feat # 更新当前特征
if self.smooth_feat is None:
self.smooth_feat = feat # 如果平滑特征为空,则直接赋值
else:
# 使用指数移动平均更新平滑特征
self.smooth_feat = self.alpha * self.smooth_feat + (1 - self.alpha) * feat
self.features.append(feat) # 将当前特征添加到特征队列中
self.smooth_feat /= np.linalg.norm(self.smooth_feat) # 归一化平滑特征
def predict(self):
"""使用卡尔曼滤波器预测状态的均值和协方差。"""
mean_state = self.mean.copy() # 复制当前均值状态
if self.state != TrackState.Tracked:
mean_state[6] = 0 # 如果状态不是跟踪状态,则将速度设为0
mean_state[7] = 0
# 使用卡尔曼滤波器进行预测
self.mean, self.covariance = self.kalman_filter.predict(mean_state, self.covariance)
@property
def tlwh(self):
"""获取当前边界框位置,格式为 (左上角x, 左上角y, 宽度, 高度)。"""
if self.mean is None:
return self._tlwh.copy() # 如果均值为空,返回原始边界框
ret = self.mean[:4].copy() # 复制均值的前四个元素
ret[:2] -= ret[2:] / 2 # 计算左上角坐标
return ret # 返回计算后的边界框
class BOTSORT(BYTETracker):
"""
BOTSORT类是BYTETracker类的扩展版本,专为YOLOv8设计,支持ReID和GMC算法的物体跟踪。
"""
def __init__(self, args, frame_rate=30):
"""初始化BOTSORT实例,设置ReID模块和GMC算法。"""
super().__init__(args, frame_rate) # 调用父类构造函数
self.proximity_thresh = args.proximity_thresh # 空间接近阈值
self.appearance_thresh = args.appearance_thresh # 外观相似性阈值
if args.with_reid:
self.encoder = None # 如果启用ReID,初始化编码器(此处未实现)
self.gmc = GMC(method=args.gmc_method) # 初始化GMC算法实例
def init_track(self, dets, scores, cls, img=None):
"""使用检测结果、分数和类别初始化跟踪。"""
if len(dets) == 0:
return [] # 如果没有检测结果,返回空列表
# 如果启用ReID并且编码器存在,则使用编码器进行特征提取
if self.args.with_reid and self.encoder is not None:
features_keep = self.encoder.inference(img, dets)
return [BOTrack(xyxy, s, c, f) for (xyxy, s, c, f) in zip(dets, scores, cls, features_keep)]
else:
return [BOTrack(xyxy, s, c) for (xyxy, s, c) in zip(dets, scores, cls)] # 仅使用检测结果初始化
def get_dists(self, tracks, detections):
"""计算跟踪和检测之间的距离,使用IoU和(可选)ReID嵌入。"""
dists = matching.iou_distance(tracks, detections) # 计算IoU距离
dists_mask = (dists > self.proximity_thresh) # 创建距离掩码
# 结合得分
dists = matching.fuse_score(dists, detections)
# 如果启用ReID,计算嵌入距离
if self.args.with_reid and self.encoder is not None:
emb_dists = matching.embedding_distance(tracks, detections) / 2.0
emb_dists[emb_dists > self.appearance_thresh] = 1.0 # 超过阈值的嵌入距离设为1
emb_dists[dists_mask] = 1.0 # 使用掩码
dists = np.minimum(dists, emb_dists) # 取最小值
return dists # 返回计算后的距离
def multi_predict(self, tracks):
"""使用YOLOv8模型预测和跟踪多个物体。"""
BOTrack.multi_predict(tracks) # 调用BOTrack的多重预测方法
以上代码展示了BOTrack和BOTSORT类的核心功能,包括物体跟踪的初始化、特征更新、状态预测和距离计算等关键方法。```
这个程序文件 bot_sort.py 是用于对象跟踪的实现,特别是与 YOLOv8 目标检测模型结合使用的 BOTracker 和 BOTSORT 类。该文件包含了多个类和方法,旨在通过使用卡尔曼滤波器和外观特征来实现高效的对象跟踪。
首先,BOTrack 类是 STrack 类的扩展,增加了对象跟踪的功能。它包含了一些重要的属性,例如共享的卡尔曼滤波器、平滑的特征向量、当前特征向量以及一个用于存储特征向量的双端队列。构造函数中初始化了这些属性,并允许用户传入特征向量。update_features 方法用于更新特征向量,并通过指数移动平均进行平滑处理。
predict 方法使用卡尔曼滤波器预测对象的状态,re_activate 和 update 方法用于在跟踪过程中更新对象的特征和状态。tlwh 属性返回当前对象的位置,以 (左上角 x, 左上角 y, 宽度, 高度) 的格式表示。multi_predict 方法可以对多个对象进行状态预测,而 convert_coords 和 tlwh_to_xywh 方法则用于坐标格式的转换。
接下来,BOTSORT 类是 BYTETracker 类的扩展,专为 YOLOv8 设计,支持对象跟踪、ReID(重识别)和 GMC(全局运动一致性)算法。构造函数中初始化了一些与跟踪相关的参数,并根据用户的设置决定是否启用 ReID 模块。get_kalmanfilter 方法返回一个卡尔曼滤波器的实例。
init_track 方法用于根据检测结果初始化跟踪对象,支持使用 ReID 特征进行初始化。get_dists 方法计算跟踪对象与检测对象之间的距离,结合了 IoU(交并比)和可选的 ReID 嵌入距离。最后,multi_predict 方法用于对多个对象进行预测和跟踪。
整体来看,这个文件实现了一个高效的对象跟踪系统,能够处理多个对象的跟踪任务,并结合了外观特征和运动模型来提高跟踪的准确性和鲁棒性。
```python
import sys
import subprocess
def run_script(script_path):
"""
使用当前 Python 环境运行指定的脚本。
Args:
script_path (str): 要运行的脚本路径
Returns:
None
"""
# 获取当前 Python 解释器的路径
python_path = sys.executable
# 构建运行命令,使用 streamlit 运行指定的脚本
command = f'"{python_path}" -m streamlit run "{script_path}"'
# 执行命令,并等待其完成
result = subprocess.run(command, shell=True)
# 检查命令执行的返回码,如果不为0,表示出错
if result.returncode != 0:
print("脚本运行出错。")
# 实例化并运行应用
if __name__ == "__main__":
# 指定要运行的脚本路径
script_path = "web.py" # 这里可以替换为实际的脚本路径
# 调用函数运行脚本
run_script(script_path)
注释说明:
-
导入模块:
sys:用于访问与 Python 解释器紧密相关的变量和函数。subprocess:用于执行外部命令。
-
run_script函数:- 该函数接受一个脚本路径作为参数,并使用当前 Python 环境来运行该脚本。
- 使用
sys.executable获取当前 Python 解释器的路径,以确保使用正确的 Python 环境。 - 构建一个命令字符串,使用
streamlit模块来运行指定的脚本。 - 使用
subprocess.run执行命令,并通过shell=True允许在 shell 中执行。 - 检查命令的返回码,如果返回码不为0,表示脚本运行过程中出现了错误。
-
主程序部分:
- 在
if __name__ == "__main__":块中,指定要运行的脚本路径,并调用run_script函数来执行该脚本。```
这个程序文件的主要功能是通过当前的 Python 环境来运行一个指定的脚本,具体来说是一个名为web.py的脚本。首先,程序导入了必要的模块,包括sys、os和subprocess,这些模块提供了与系统交互和执行外部命令的功能。此外,还导入了abs_path函数,这个函数可能用于获取脚本的绝对路径。
- 在
在 run_script 函数中,首先获取当前 Python 解释器的路径,这样可以确保使用正确的 Python 环境来运行脚本。接着,构建一个命令字符串,该命令使用 streamlit 模块来运行指定的脚本。streamlit 是一个用于构建数据应用的库,命令的格式为 python -m streamlit run script_path。
然后,使用 subprocess.run 方法执行这个命令。这个方法会在一个新的子进程中运行命令,并等待其完成。如果命令执行后返回的状态码不为零,表示脚本运行出错,程序会打印出相应的错误信息。
在文件的最后部分,使用 if __name__ == "__main__": 语句来确保只有在直接运行该文件时才会执行后面的代码。这里指定了要运行的脚本路径,即 web.py,并调用 run_script 函数来执行这个脚本。
总体来说,这个程序的设计简单明了,主要用于方便地通过命令行运行一个 Streamlit 应用脚本。
```python
# 导入必要的模型和工具
from ultralytics.models import RTDETR, SAM, YOLO # 导入不同的目标检测模型
from ultralytics.models.fastsam import FastSAM # 导入快速SAM模型
from ultralytics.models.nas import NAS # 导入神经架构搜索模型
from ultralytics.utils import SETTINGS as settings # 导入设置配置
from ultralytics.utils.checks import check_yolo as checks # 导入YOLO检查工具
from ultralytics.utils.downloads import download # 导入下载工具
# 定义模块的版本
__version__ = '8.0.202'
# 定义模块的公开接口,方便外部调用
__all__ = '__version__', 'YOLO', 'NAS', 'SAM', 'FastSAM', 'RTDETR', 'checks', 'download', 'settings'
注释说明:
- 导入模型和工具:代码中导入了多个模型(如YOLO、RTDETR等)和实用工具(如下载和检查功能),这些是实现目标检测和相关功能的核心组件。
- 版本定义:通过
__version__变量定义了当前模块的版本,便于版本管理和追踪。 - 公开接口:
__all__定义了模块的公开接口,确保只有指定的部分可以被外部访问,提升了模块的封装性。```
这个程序文件是Ultralytics库的初始化文件,文件名为__init__.py,用于定义库的版本和导入相关模块。首先,文件声明了库的版本为8.0.202,这有助于用户和开发者了解当前使用的库版本。
接下来,文件从ultralytics.models模块中导入了多个模型,包括RTDETR、SAM和YOLO,这些模型是Ultralytics库中用于目标检测和分割的核心组件。此外,还从ultralytics.models.fastsam导入了FastSAM,这是一个快速的分割模型。文件还导入了NAS,这可能与神经架构搜索相关。
在工具方面,文件从ultralytics.utils模块中导入了SETTINGS,用于配置和设置库的参数。同时,导入了check_yolo函数,用于进行YOLO模型的检查,确保模型的有效性和兼容性。此外,还导入了download函数,用于处理文件下载。
最后,文件通过__all__变量定义了模块的公共接口,列出了可以被外部访问的对象,包括版本号、各个模型、检查函数、下载函数和设置。这使得用户在使用这个库时,可以方便地访问这些功能和组件。整体来看,这个文件为Ultralytics库的使用提供了基础的结构和功能导入。
```python
# 导入模块
from .afpn import * # 导入自适应特征金字塔网络(AFPN)相关的功能
from .attention import * # 导入注意力机制相关的功能
from .block import * # 导入网络中使用的基本模块
from .head import * # 导入网络的头部结构,通常用于输出
from .rep_block import * # 导入重复模块,可能用于构建深层网络
from .kernel_warehouse import * # 导入内核仓库,可能用于存储和管理卷积核
from .dynamic_snake_conv import * # 导入动态蛇形卷积相关的功能
from .orepa import * # 导入OREPA(可能是某种特定的网络结构或方法)
from .RFAConv import * # 导入RFA卷积相关的功能
注释说明:
- 模块导入:代码中使用了相对导入的方式,导入了多个模块。这些模块可能是构建深度学习模型的不同组件或功能。
- 功能概述:
afpn:自适应特征金字塔网络,通常用于提高目标检测和分割任务中的特征提取能力。attention:注意力机制模块,用于增强模型对重要特征的关注。block:基本模块,可能是构建网络的基础组件。head:网络的输出部分,负责生成最终的预测结果。rep_block:重复模块,可能用于构建深层网络的重复结构。kernel_warehouse:管理卷积核的模块,可能用于动态选择或优化卷积核。dynamic_snake_conv:动态蛇形卷积,可能是一种特殊的卷积操作。orepa:特定的网络结构或方法,具体功能需要根据上下文进一步了解。RFAConv:RFA卷积,可能是一种改进的卷积方法,用于提高特征提取能力。
通过这些模块的组合,可以构建出复杂的深度学习模型,适用于各种计算机视觉任务。```
这个程序文件 __init__.py 是一个 Python 包的初始化文件,位于 ultralytics/nn/extra_modules/ 目录下。它的主要功能是导入该目录下的多个模块,使得这些模块在包被导入时能够被直接访问。
文件中的每一行代码都使用了相对导入的方式,从当前目录中导入不同的模块。这些模块分别是:
afpn:可能是实现某种特征金字塔网络(FPN)的模块。attention:通常与注意力机制相关,可能用于增强模型对重要特征的关注。block:可能定义了一些基本的网络结构块,用于构建更复杂的神经网络。head:通常指的是网络的输出部分,可能包含分类或回归的头部结构。rep_block:可能是实现某种重复结构的模块,常用于构建深层网络。kernel_warehouse:可能与卷积核的管理或存储相关,提供了一些操作卷积核的功能。dynamic_snake_conv:可能是实现动态卷积的模块,可能用于提升卷积操作的灵活性。orepa:具体功能不明,可能是某种特定的网络结构或操作。RFAConv:可能是实现某种特定卷积操作的模块,可能与特征提取或变换相关。
通过这个 __init__.py 文件,用户在导入 ultralytics.nn.extra_modules 包时,可以直接使用这些模块中的功能,而无需单独导入每一个模块。这种做法提高了代码的可读性和使用的便利性。
```python
# 导入必要的库
import requests
from ultralytics.hub.auth import Auth # 导入身份验证模块
from ultralytics.utils import LOGGER, SETTINGS # 导入日志记录和设置模块
from ultralytics.data.utils import HUBDatasetStats # 导入数据集统计工具
def login(api_key=''):
"""
使用提供的API密钥登录Ultralytics HUB API。
参数:
api_key (str, optional): API密钥或API密钥与模型ID的组合。
示例:
hub.login('API_KEY')
"""
Auth(api_key, verbose=True) # 调用Auth类进行身份验证
def logout():
"""
从Ultralytics HUB注销,移除设置文件中的API密钥。
要再次登录,请使用'yolo hub login'。
示例:
hub.logout()
"""
SETTINGS['api_key'] = '' # 清空API密钥
SETTINGS.save() # 保存设置
LOGGER.info("logged out ✅. To log in again, use 'yolo hub login'.") # 记录注销信息
def reset_model(model_id=''):
"""将训练过的模型重置为未训练状态。"""
# 向API发送POST请求以重置模型
r = requests.post(f'{HUB_API_ROOT}/model-reset', json={'apiKey': Auth().api_key, 'modelId': model_id})
if r.status_code == 200:
LOGGER.info('Model reset successfully') # 记录成功信息
else:
LOGGER.warning(f'Model reset failure {r.status_code} {r.reason}') # 记录失败信息
def export_model(model_id='', format='torchscript'):
"""将模型导出为指定格式。"""
# 确保格式是支持的导出格式
assert format in export_fmts_hub(), f"Unsupported export format '{format}'"
# 向API发送POST请求以导出模型
r = requests.post(f'{HUB_API_ROOT}/v1/models/{model_id}/export',
json={'format': format},
headers={'x-api-key': Auth().api_key})
assert r.status_code == 200, f'{format} export failure {r.status_code} {r.reason}' # 检查请求是否成功
LOGGER.info(f'{format} export started ✅') # 记录导出开始的信息
def check_dataset(path='', task='detect'):
"""
在上传之前检查HUB数据集Zip文件的错误。
参数:
path (str, optional): 数据集Zip文件的路径,默认为''。
task (str, optional): 数据集任务,默认为'detect'。
示例:
check_dataset('path/to/coco8.zip', task='detect') # 检查检测数据集
"""
HUBDatasetStats(path=path, task=task).get_json() # 获取数据集统计信息
LOGGER.info('Checks completed correctly ✅. Upload this dataset to HUB.') # 记录检查完成的信息
代码核心部分说明:
- 登录和注销功能:提供了用户通过API密钥登录和注销Ultralytics HUB的功能。
- 模型重置:允许用户将训练过的模型重置为未训练状态。
- 模型导出:支持将模型导出为多种格式,并进行相应的API请求。
- 数据集检查:在上传数据集之前,检查数据集的有效性,以确保其符合要求。```
这个程序文件是Ultralytics YOLO的一个模块,主要用于与Ultralytics HUB进行交互。文件中包含了一些用于登录、登出、模型重置、导出模型、检查数据集等功能的函数。
首先,login函数用于通过提供的API密钥登录Ultralytics HUB API。用户可以传入一个API密钥,函数会创建一个Auth对象来处理认证。如果登录成功,用户可以使用HUB的功能。
接下来,logout函数用于登出Ultralytics HUB。它会清空存储在设置文件中的API密钥,并记录登出信息。用户在需要重新登录时,可以使用yolo hub login命令。
reset_model函数允许用户将训练过的模型重置为未训练状态。它通过向HUB API发送POST请求来实现这一点,并根据响应状态码记录重置是否成功。
export_fmts_hub函数返回一个支持的导出格式列表,用户可以根据这些格式导出模型。它从ultralytics.engine.exporter模块中获取支持的格式,并添加一些特定的格式。
export_model函数用于将模型导出为指定格式。用户需要提供模型ID和导出格式,函数会检查格式是否受支持,然后向HUB API发送请求以开始导出过程。
get_export函数用于获取已导出的模型的字典,其中包含下载链接。它会检查导出格式的有效性,并向HUB API发送请求以获取导出信息。
最后,check_dataset函数用于在上传数据集到HUB之前进行错误检查。用户可以提供数据集的路径和任务类型(如检测、分割、姿态估计等),函数会检查数据集的有效性,并记录检查结果。如果检查通过,用户可以将数据集上传到指定的HUB网址。
整体来看,这个模块提供了一系列便捷的函数,使得用户能够方便地与Ultralytics HUB进行交互,管理模型和数据集。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献92条内容
已为社区贡献92条内容

所有评论(0)