HNU 数据挖掘 作业1&作业2
写在前面
有些部分由chatgpt生成,且未经检查,若发现错误或遗漏之处,请在评论区指出,非常感谢!
作业一
1. 什么是数据挖掘?在你的回答中,强调以下问题:
a) 它是一种从数据库、统计学和机器学习发展的技术的简单转换吗?
b) 解释数据库技术发展如何导致数据挖掘。
c) 当把数据挖掘看作知识发现过程时,描述数据挖掘所涉及的步骤。
1. 答
数据挖掘是从大量数据中自动或半自动地发现有意义的模式、关联、趋势和知识的过程。它借助统计学、机器学习、数据库技术等方法,但它不是这些技术的“简单转换”,而是在整合这些技术基础上形成的一套完整的数据驱动知识发现过程。
a)
它是一种从数据库、统计学和机器学习发展的技术的简单转换吗?
不是。虽然数据挖掘使用数据库技术进行高效存储与查询,使用统计方法进行推断和建模,使用机器学习进行模式识别,但数据挖掘的核心是:
·关注大规模数据处理能力
·面向实际数据中的噪声、不完整性、连续更新性
·目标是知识发现而不是单纯分析
·提供可解释、可部署的知识
因此,数据挖掘是一门跨学科、综合性的应用科学,而不是简单叠加。
b)
数据库技术的发展如何导致数据挖掘?
数据库技术的发展为数据挖掘提供了必要的基础:
·数据积累:关系数据库和事务处理系统导致企业积累了海量数据
·数据仓库:为决策支持而设计的数据仓库提供了集成的、历史的、面向主题的数据环境
·OLAP技术:联机分析处理提供了多维数据分析能力
·数据可用性:数据库管理系统提供了高效的数据存储、检索和管理能力
·标准化接口:SQL等标准查询语言为数据访问提供了统一接口
这些发展创造了"数据丰富但信息贫乏"的局面,从而催生了从数据中提取知识的需求。
c)
当把数据挖掘看作知识发现过程(KDD)时涉及的步骤
KDD 的典型步骤:
1. 数据清洗(Cleaning):处理噪声、缺失数据、异常值
2. 数据集成(Integration):来自多个源的数据统一
3. 数据选择(Selection):选择用于分析的属性和数据子集
4. 数据变换(Transformation):规范化、聚合、降维
5. 数据挖掘(Data Mining):应用算法发现模式,如分类、聚类、关联规则
6. 模式评估(Evaluation):判断模式是否有意义
7. 知识表达(Presentation):以可视化、规则等形式呈现最终知识
2. 假定你是Big-University的软件工程师,任务是设计一个数据挖掘系统,分析学校课程数据库。该数据库包括如下信息:每个学生的姓名、地址和状态(例如:本科生或研究生)、所修课程,以及他们累计的GPA(学分平均)。描述你要选取的结构。该结构的每个成分的作用是什么?
2.答
(1)数据源层
存储学校信息:学生姓名、地址、身份(本科/研究生)、课程记录、GPA。
(2)数据预处理层
负责:
·去噪、补全缺失信息
·构造课程-学生矩阵
·处理非结构化字段(如地址)
·数据规范化(如 GPA 0–4 转换)
(3)数据仓库 / 多维数据模型
构建维度:
·学生维度(ID、状态、学院)
·课程维度(课程号、学分)
·成绩维度(GPA、成绩点)
作用:支持 OLAP 分析,为挖掘提供结构化数据。
(4)数据挖掘引擎
选择适合学校场景的功能:
·分类(预测学生是否会挂科)
·聚类(划分类似学习风格的学生)
·关联规则(“选修 A 的学生常选 B”)
·分布分析(GPA 分布、课程难度分布)
(5)模式评估模块
过滤不显著的规则
使用交叉验证评估模型质量
(6)知识表示层
以图表、规则、仪表盘形式向管理员展示分析结果。
3. 定义下列数据挖掘功能:特征化、区分、关联、分类、预测、聚类和演变分析。
3.答
|
功能 |
定义 |
|
特征化(Characterization) |
对目标类数据的一般特性或特征的汇总,生成目标数据的简洁且具有代表性的描述。 |
|
区分(Discrimination) |
将目标类数据对象与对比类对象进行比较,强调区分目标类和对比类的特征差异。 |
|
关联(Association) |
发现数据中属性值之间的关联规则,揭示项目之间同时出现的规律性。 |
|
分类(Classification) |
通过分析已知类别的训练数据集,建立分类模型来预测未知数据对象的类别标签。 |
|
预测(Prediction) |
基于历史数据模式预测未知的或缺失的数据值,通常涉及连续数值的估计。 |
|
聚类(Clustering) |
将数据对象划分为有意义的组或簇,使得同一簇内的对象具有高度相似性,而不同簇间的对象差异显著。 |
|
演变分析(Evolution Analysis) |
描述行为随时间变化的规律、趋势或周期性模式,分析时间序列数据中的动态特性。 |
4. 区分和分类的差别是什么?特征化和聚类的差别是什么?分类和预测呢?对于每一对任务,它们有何相似之处。
4.答
(1)区分和分类
差别:
·区分:比较两个或多个类,找出它们之间的差异
·分类:建立模型来预测新样本的类别标签
相似之处:
·都涉及类别标签的使用
·都可以产生描述性的规则或模式
·都基于已知的类别信息进行分析
(2)特征化和聚类
差别:
·特征化:汇总已知类别的总体特征
·聚类:在未知类别的情况下发现自然分组
相似之处:
·都旨在描述数据的内在结构
·结果都可以用于更好地理解数据分布
·都可能产生数据的一般性描述
(3)分类和预测
差别:
·分类:预测离散的类别标签(名义值)
·预测:预测连续的数值或缺失值
相似之处:
·都是预测性任务
·都需要建立模型来预测未知值
·都使用历史数据来训练预测模型
·评估方法类似(如准确率、误差率等)
作业二
1.假定下面的表从面向属性的归纳导出。
|
class |
Birth_place |
count |
|
Programmer |
Canada |
180 |
|
Others |
120 |
|
|
DBA |
Canada |
20 |
|
Others |
80 |
a) 将该表转换成t-weight和d-weight的交叉表
b) 将类Programmer转换成(双向的)量化描述规则
1. 答
a)
t-weight(类内):
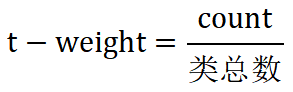
Programmer总数 = 300,DBA总数 = 100。
|
class |
Birth_place |
count |
t-weight |
|
Programmer |
Canada |
180 |
0.60 |
|
Others |
120 |
0.40 |
|
|
DBA |
Canada |
20 |
0.20 |
|
Others |
80 |
0.80 |
d-weight(全局区分度):

对每个 Birth_place 计算:
Canada:max t-weight = max(0.60, 0.20) = 0.60
Others:max t-weight = max(0.40, 0.80) = 0.80
sum = 0.60 + 0.80 = 1.40
所以:
Canada 的 d-weight = 0.60 / 1.40 = 0.4286
Others 的 d-weight = 0.80 / 1.40 = 0.5714
最终交叉表:
|
Birth Place |
t-weight(Programmer) |
t-weight(DBA) |
d-weight |
|
Canada |
0.60 |
0.20 |
0.4286 |
|
Others |
0.40 |
0.80 |
0.5714 |
2. 数据组中age的值如下:
13,15,16,16,19,20,20,21,22,22,25,25,25,25,30,33,33,35,35,35,35,36,40,45,46,52,70
a) 使用按箱平均值平滑对以上数据进行平滑,箱的深度为3。解释你的步骤。
b) 你怎样确定数据中的孤立点
c) 对于数据平滑,还有哪些其他方法
2. 答
a)
1. 先将数据顺序分箱:
箱1: 13,15,16
箱2: 16,19,20
箱3: 20,21,22
箱4: 22,25,25
箱5: 25,25,30
箱6: 33,33,35
箱7: 35,35,36
箱8: 40,45,46
箱9: 52,70
2. 计算每个箱的平均值:
箱1平均值: (13+15+16)/3 ≈ 14.67
箱2平均值: (16+19+20)/3 ≈ 18.33
箱3平均值: (20+21+22)/3 = 21
箱4平均值: (22+25+25)/3 = 24
箱5平均值: (25+25+30)/3 ≈ 26.67
箱6平均值: (33+33+35)/3 ≈ 33.67
箱7平均值: (35+35+35)/3 = 35
箱8平均值: (36+40+45)/3 ≈ 40.33
箱9平均值: (46+52+70)/3 = 56
3. 将每个箱中的数据值替换为箱平均值:
平滑后数据: 14.67,14.67,14.67, 18.33,18.33,18.33, 21,21,21, 24,24,24, 26.67,26.67,26.67, 33.67,33.67,33.67, 35,35,35, 43.33,43.33,43.33, 56,56,56
b)
使用箱线图方法:
计算第一四分位数(Q1)、第三四分位数(Q3)和四分位距(IQR = Q3 - Q1)。
定义下限为 Q1 - 1.5 × IQR,上限为 Q3 + 1.5 × IQR。超出上限或下限的值视为孤立点。
对于本数据:数据共27个,Q1 是第6.75个值(取第6和7值的平均),第6值为20,第7值为20,所以 Q1=20;Q3 是第20.25个值(取第20和21值的平均),第20值为35,第21值为35,所以 Q3=35;IQR=35-20=15。
下限=20-1.5×15=-2.5,上限=35+1.5×15=57.5。
因此,大于57.5和小于-2.5的值是孤立点,即70是孤立点。
c)
按箱中值平滑:用箱的中位数替换箱内值。
按箱边界平滑:用箱的最小值或最大值替换箱内值。
回归平滑:使用回归函数拟合数据,用预测值替换原始值。
聚类平滑:将数据聚类,用簇中心替换数据值。
3. 对于上题age数据,回答以下问题:
a) 使用最小-最大规范化,将age值35转化到[0.0,1.0]区间
b) 使用z-score规范化转换age值35,其中age的标准差为12.94
c) 使用小数定标规范化转换age值35
给出的age数据最小值= 13,最大值= 70。
3. 答
a)
最小-最大规范化
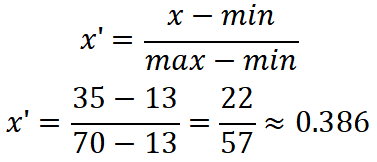
b)
z-score 规范化
给定标准差σ = 12.94,均值μ可计算得到为29.96
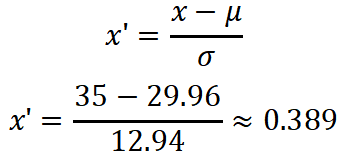
c)
小数定标规范化
最大绝对值70 → 需要d = 2
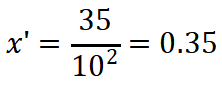
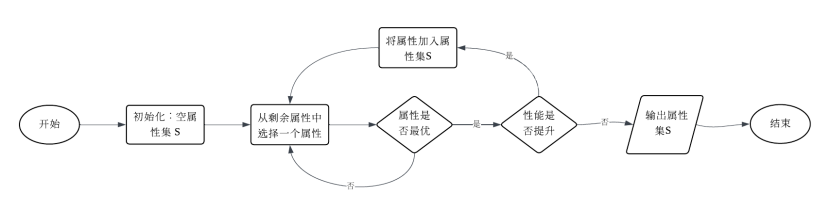
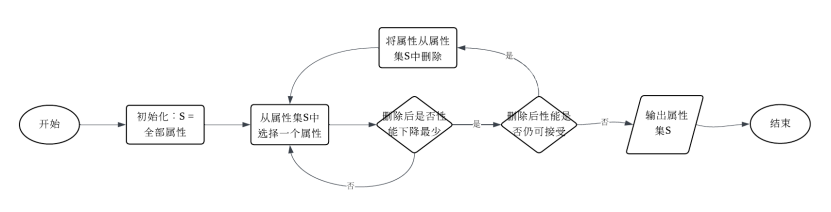
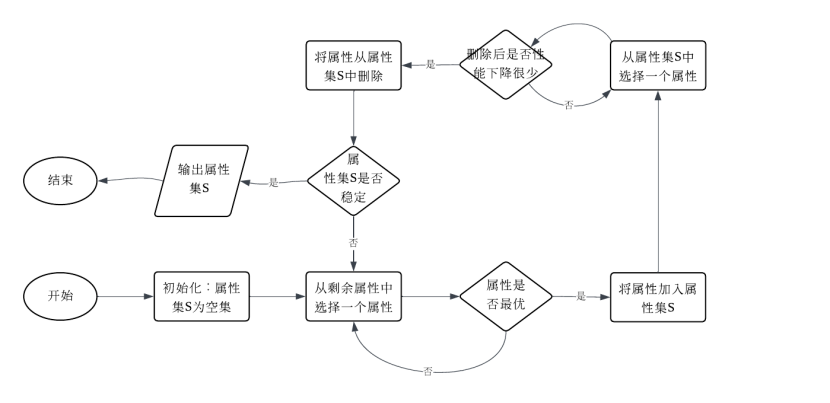
4. 使用流程图概述如下属性子集选择过程
a) 逐步向前选择
b)逐步向后删除
c)逐步向前选择和逐步向后删除的结合
4. 答
a)
b)
c)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)