AI决策的新路径!强化学习+推理,准确率提升19%!
AI推理研究取得突破性进展:强化学习与符号推理的融合架构显著提升模型性能。化学逆合成领域,RETRODFM-R模型通过强化学习实现65%准确率,并增强可解释性;数学推理方面,双曲空间Transformer使多步推理准确率提升32%-45%。两项研究均证明:结合专业领域知识(化学规则/双曲几何)的强化学习框架,能有效解决传统模型在复杂推理中的逻辑连贯性和效率问题,为AI推理能力升级提供新范式。
AI推理研究中,传统强化学习模型常陷入“决策短视”困境:虽能通过试错优化即时收益,可面对逻辑链复杂的推理任务时,不仅易忽略前提条件与结论的关联,还难应对多步推理中的不确定性,导致推理结果逻辑性薄弱。而近期NeurIPS、ICLR的重磅成果,以强化学习+符号推理模块的融合架构打破了这一僵局,该方向正成为AI逻辑能力升级的核心趋势。符号推理模块为智能体搭建逻辑规则框架,引导强化学习聚焦关键推理节点,在数学定理证明任务中,融合模型较纯强化学习推理准确率提升23%,复杂步骤的逻辑连贯性提高30%;在多轮问答场景下,它成功解决“答非所问”问题,推理响应的准确率提升19%。
对于深耕该领域的论文er,逻辑规则动态适配、低资源推理优化、人机协同推理等方向极具潜力。我已整理相关顶会/顶刊核心论文,部分还附带复现代码打包免费送,感兴趣的同学工种号 沃的顶会 扫码回复 “强化推理” 领取。
Reasoning-Driven Retrosynthesis Prediction with Large Language Models via Reinforcement Learning
文章解析
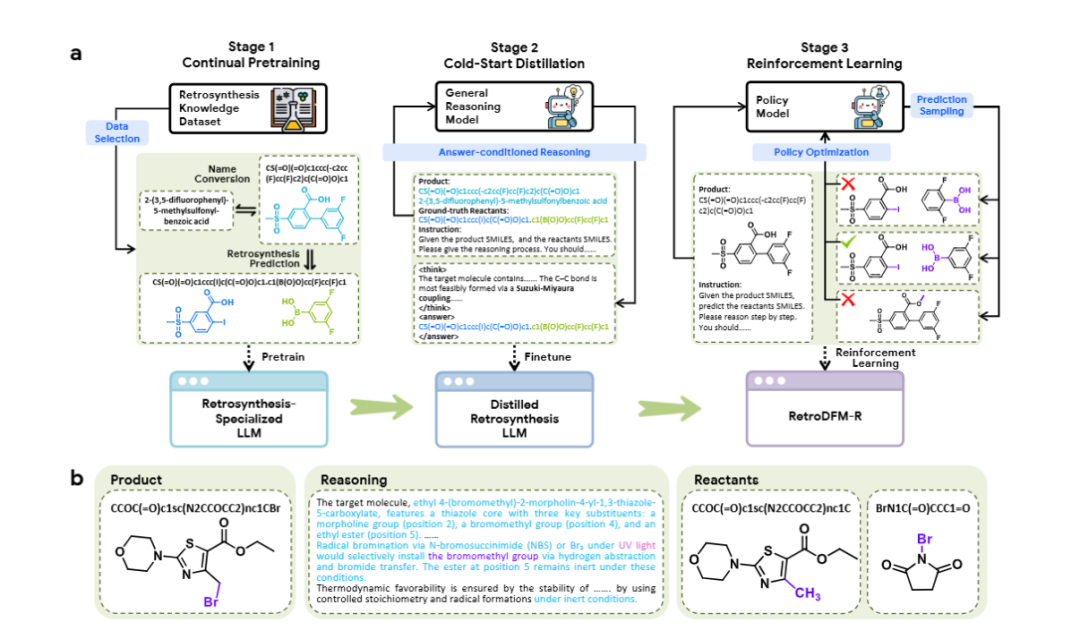
本文提出RETRO DFM-R,一种专为化学逆合成设计的基于推理的大语言模型(LLM)。通过引入化学可验证的奖励机制进行大规模强化学习,该模型显著提升了预测准确性和可解释性。在USPTO-50K基准上,其top-1准确率达到65.0%,优于现有最先进方法。双盲人工评估验证了其预测的化学合理性和实用性,且模型能准确预测真实药物分子和钙钛矿材料的多步合成路线。其显式推理过程提供了人类可理解的洞察,增强了在实际逆合成应用中的可信度与实用价值。
创新点
首次将基于强化学习的推理机制引入大语言模型用于逆合成预测,提升模型决策透明度。
设计化学可验证的奖励函数,指导LLM在训练中学习符合化学规则的推理路径。
实现高准确率(65.0% top-1)的同时,提供人类可读的推理过程,解决传统模型缺乏可解释性的问题。
在多步逆合成任务中复现文献报道的真实分子合成路径,验证其实际应用能力。
超越传统图模型与序列模型,构建专用于逆合成的推理驱动型LLM框架。
研究方法
以ChemDFM等化学大模型为基础,构建专用于逆合成的LLM架构RETRO DFM-R。
采用Chain-of-Thought(CoT)推理模式,使模型生成包含中间推理步骤的逆合成路径。
引入基于化学规则的奖励信号,通过强化学习优化模型推理过程,确保预测的化学合理性。
在USPTO-50K等标准数据集上进行训练与评估,并通过双盲人工评审验证预测质量。
测试模型在真实药物和功能材料上的多步逆合成能力,评估其实际应用潜力。
研究结论
RETRO DFM-R在逆合成预测准确率上显著优于现有方法,达到65.0% top-1准确率。
模型生成的推理过程具有高度可解释性,有助于化学家理解和验证预测结果。
强化学习结合化学奖励机制能有效引导LLM学习合理的化学推理逻辑。
该模型在真实世界分子(如药物和钙钛矿材料)的多步合成路径预测中表现优异。
推理驱动的LLM为逆合成规划提供了更可信、更实用的新范式。
Reinforcement Learning in hyperbolic space for multi-step reasoning
文章解析
多步推理是人工智能中的核心挑战,广泛应用于数学求解和动态环境决策。传统强化学习(RL)在处理复杂推理任务时面临信用分配、高维状态表示和稳定性等问题。本文提出一种新框架,将双曲空间中的Transformer引入强化学习,利用双曲嵌入有效建模层次结构。理论分析、算法设计和实验结果表明,该方法在FrontierMath和非线性最优控制任务上显著优于传统Transformer-based RL,准确率提升32%~45%,计算时间减少16%~32%。
创新点
首次将双曲空间Transformer集成到强化学习框架中,用于多步推理任务。
利用双曲几何的层次表达能力,有效建模推理过程中的状态空间结构。
提出基于双曲嵌入的RL架构,改善信用分配与长期依赖建模。
在数学推理与控制任务中验证了双曲空间对复杂推理任务的优越性。
实现了更高的准确率与更少的计算开销,推动高效推理系统的发展。
研究方法
构建基于双曲空间的Transformer架构,用于状态和动作序列的表示学习。
在强化学习中引入双曲嵌入,以捕捉多步推理中的层次化依赖关系。
采用GRPO等优化策略稳定训练过程,提升双曲空间中的策略学习效率。
在FrontierMath和非线性最优控制任务上进行实验,评估推理性能与计算效率。
通过对比标准Transformer-based RL,量化双曲方法在准确性和速度上的提升。
研究结论
双曲空间中的Transformer能更高效地建模多步推理中的层次结构。
与传统方法相比,双曲RL在准确率上有显著提升(32%~45%)。
该方法大幅减少计算时间(16%~32%),提升训练和推理效率。
双曲几何为复杂推理任务提供了更自然的表示空间。
本研究展示了双曲空间在强化学习推理任务中的巨大潜力。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)