基于深度学习的IMU偏置动力学建模与纯积分方法---公式代码纯享版
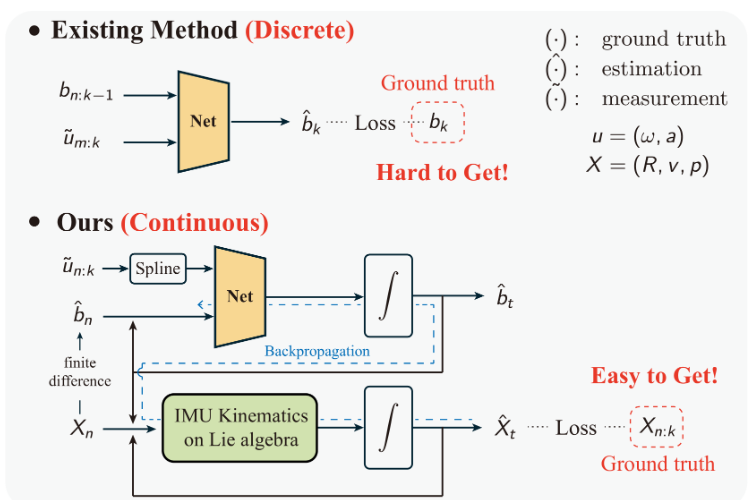
本文提出了一种基于神经常微分方程(Neural ODE)的IMU去偏方法,通过显式建模IMU偏置的连续动力学特性,显著提升了姿态和轨迹估计精度。该方法将偏置建模为时间连续的系统,利用神经网络学习偏置演化规律,仅需位姿真值作为监督信号,无需难以获取的偏置真值。通过李代数转换将旋转群微分方程简化为欧氏空间常微分方程,并采用分层训练策略分别优化陀螺仪和加速度计偏置网络。实验证明该方法能有效补偿IMU测量
1. 引言:IMU在机器人导航中的核心地位
1.1 IMU传感器的重要性
惯性测量单元(Inertial Measurement Unit, IMU)是现代机器人导航系统中不可或缺的传感器。它通过陀螺仪测量角速度,通过加速度计测量线性加速度,为机器人提供高频率的运动信息。在视觉-惯性里程计(Visual-Inertial Odometry, VIO)系统中,IMU与相机数据融合,能够实现鲁棒的位姿估计。然而,低成本IMU的测量数据往往包含显著的噪声和偏置,这些误差在积分过程中会快速累积,导致位姿估计精度急剧下降。特别是在光照不足、动态遮挡或恶劣环境下相机失效时,IMU成为唯一可用的里程计信息源,此时其测量精度直接决定了整个系统的性能。
1.2 传统方法的局限性
传统的IMU标定方法通常采用线性模型来描述轴间失准和比例因子,而将偏置建模为常数或布朗运动过程。这种简化假设忽略了偏置的时变特性和非线性动力学规律。实际上,IMU偏置受温度、振动、电磁干扰等多种因素影响,呈现出复杂的时变特征。近年来,随着深度学习技术的发展,研究者开始探索使用神经网络来学习IMU的误差特性。然而,现有的学习方法大多采用隐式建模方式,难以区分网络学到的是运动模式还是传感器本身的特性,且往往需要难以获取的偏置真值作为监督信号。
1.3 本文方法概述
本文《Debiasing 6-DOF IMU via Hierarchical Learning of Continuous Bias Dynamics》介绍一种基于神经常微分方程(Neural Ordinary Differential Equation, Neural ODE)的IMU去偏方法。该方法的核心创新在于:将IMU偏置建模为连续的动力学系统,通过神经网络学习偏置随时间的演化规律,并且无需偏置真值作为监督信号,仅利用容易获取的位姿真值即可完成训练。通过李代数的数学工具,该方法将旋转群上的微分方程转化为欧氏空间中的常微分方程,大幅简化了训练过程。实验结果表明,使用该方法补偿后的IMU数据进行纯积分,能够显著提升姿态和轨迹估计精度。相关代码已经在Github开源
方法总览流程图
graph TB
A[原始IMU测量<br/>ω̃, ã] --> B[偏置动力学网络<br/>Neural ODE]
B --> C[偏置估计<br/>b^g, b^a]
A --> D[偏置补偿<br/>ω = ω̃ - b^g<br/>a = ã - b^a]
C --> D
D --> E[IMU运动学积分<br/>SO3 ODE Solver]
E --> F[位姿估计<br/>R, v, p]
G[位姿真值<br/>R_gt, v_gt, p_gt] --> H[损失计算]
F --> H
H --> I[反向传播<br/>更新网络参数]
I --> B
style A fill:#e1f5ff
style F fill:#fff4e1
style G fill:#e8f5e9
style B fill:#f3e5f5
2. IMU测量模型与偏置动力学
2.1 IMU的数学模型
IMU的测量模型可以表示为真实物理量、偏置和噪声的叠加。对于陀螺仪和加速度计,其测量方程分别为:
ω ~ t = ω t + b t g + n t g \tilde{\omega}_t = \omega_t + b_t^g + n_t^g ω~t=ωt+btg+ntg
a ~ t = a t + b t a + n t a \tilde{a}_t = a_t + b_t^a + n_t^a a~t=at+bta+nta
其中, ω ~ t \tilde{\omega}_t ω~t和 a ~ t \tilde{a}_t a~t分别表示陀螺仪和加速度计的测量值, ω t \omega_t ωt和 a t a_t at表示真实的角速度和线性加速度, b t g b_t^g btg和 b t a b_t^a bta表示陀螺仪和加速度计的偏置, n t g n_t^g ntg和 n t a n_t^a nta表示高斯白噪声。所有量均在IMU坐标系下表示,维度为 R 3 \mathbb{R}^3 R3。
2.2 传统偏置建模
在经典的惯性导航系统中,偏置通常被建模为布朗运动过程:
b ˙ t g = η g , b ˙ t a = η a \dot{b}_t^g = \eta_g, \quad \dot{b}_t^a = \eta_a b˙tg=ηg,b˙ta=ηa
其中 η g \eta_g ηg和 η a \eta_a ηa服从零均值高斯分布。这种建模方式虽然数学上简洁,但无法捕捉偏置的结构性和非线性特征。实际上,IMU偏置的演化受到多种物理因素的影响,包括温度漂移、机械应力、电路特性等,这些因素共同作用形成了复杂的动力学行为。
2.3 刚体运动学方程
IMU测量数据通常用于估计刚体的位姿。刚体运动学可以用以下微分方程组描述:
R ˙ t = R t [ ω t ] × \dot{R}_t = R_t [\omega_t]_\times R˙t=Rt[ωt]×
v ˙ t = R t a t + g \dot{v}_t = R_t a_t + g v˙t=Rtat+g
p ˙ t = v t \dot{p}_t = v_t p˙t=vt
其中, R t ∈ S O ( 3 ) R_t \in SO(3) Rt∈SO(3)表示旋转矩阵,描述IMU坐标系相对于世界坐标系的姿态; v t ∈ R 3 v_t \in \mathbb{R}^3 vt∈R3表示世界坐标系下的线速度; p t ∈ R 3 p_t \in \mathbb{R}^3 pt∈R3表示世界坐标系下的位置; g ∈ R 3 g \in \mathbb{R}^3 g∈R3表示重力加速度向量。符号 [ ⋅ ] × [\cdot]_\times [⋅]×表示叉乘算子,将三维向量映射为 3 × 3 3\times3 3×3反对称矩阵,满足 [ a ] × b = a × b [a]_\times b = a \times b [a]×b=a×b。
这组方程揭示了IMU测量与位姿之间的微分关系。如果能够获得准确的 ω t \omega_t ωt和 a t a_t at,通过数值积分即可得到精确的位姿估计。然而,由于IMU测量包含偏置和噪声,直接积分会导致误差快速累积。因此,准确估计和补偿偏置成为提高IMU积分精度的关键。
2.4 问题形式化定义
IMU去偏问题可以形式化为:给定从初始时刻 t 0 t_0 t0到当前时刻 t k t_k tk的原始IMU测量序列 { ω ~ 0 : k , a ~ 0 : k } \{\tilde{\omega}_{0:k}, \tilde{a}_{0:k}\} {ω~0:k,a~0:k},设计一个估计器 F \mathcal{F} F,使得:
( ω ^ k , a ^ k ) = F ( ω ~ 0 : k , a ~ 0 : k ) (\hat{\omega}_k, \hat{a}_k) = \mathcal{F}(\tilde{\omega}_{0:k}, \tilde{a}_{0:k}) (ω^k,a^k)=F(ω~0:k,a~0:k)
其中 ω ^ k \hat{\omega}_k ω^k和 a ^ k \hat{a}_k a^k是对真实角速度和加速度的估计。估计器 F \mathcal{F} F需要满足两个关键要求:一是能够准确去除偏置和噪声的影响;二是具有因果性,即当前时刻的估计只依赖于历史和当前的测量,不依赖于未来的信息,这对于实时应用至关重要。
传统方法通常将 F \mathcal{F} F设计为基于卡尔曼滤波或优化的状态估计器,需要精确的系统模型和噪声统计特性。而基于学习的方法则试图通过数据驱动的方式,让神经网络自动学习从原始测量到真实物理量的映射关系。本文提出的方法属于后者,但与现有方法不同的是,它显式地建模偏置的动力学演化过程。
3. 核心方法:基于Neural ODE的偏置动力学学习
3.1 偏置动力学的连续建模
本方法的核心假设是:IMU偏置并非随机游走,而是遵循某种可学习的、传感器特定的动力学规律。如果能够准确建模这一动力学,就可以通过积分推断出每一时刻的偏置值,进而对原始测量进行补偿。
与传统的离散时间建模不同,本方法采用连续时间动力学系统来描述偏置的演化:
b ˙ t g = f g ( b t g , ω ~ t , ω ~ ˙ t ; θ g ) \dot{b}_t^g = f_g(b_t^g, \tilde{\omega}_t, \dot{\tilde{\omega}}_t; \theta_g) b˙tg=fg(btg,ω~t,ω~˙t;θg)
b ˙ t a = f a ( b t a , a ~ t , a ~ ˙ t ; θ a ) \dot{b}_t^a = f_a(b_t^a, \tilde{a}_t, \dot{\tilde{a}}_t; \theta_a) b˙ta=fa(bta,a~t,a~˙t;θa)
其中 f g f_g fg和 f a f_a fa是由神经网络参数化的函数, θ g \theta_g θg和 θ a \theta_a θa是网络参数。这里的关键设计是:偏置的变化率不仅依赖于当前的偏置值,还依赖于当前的IMU测量及其时间导数。这种设计使得网络能够捕捉偏置与运动状态之间的耦合关系。
连续建模的优势在于:首先,它符合物理系统的本质,偏置的演化是连续的过程;其次,连续模型可以在任意时间点进行求值,不受采样频率的限制;最后,连续模型可以利用成熟的常微分方程求解器,保证数值稳定性和精度。
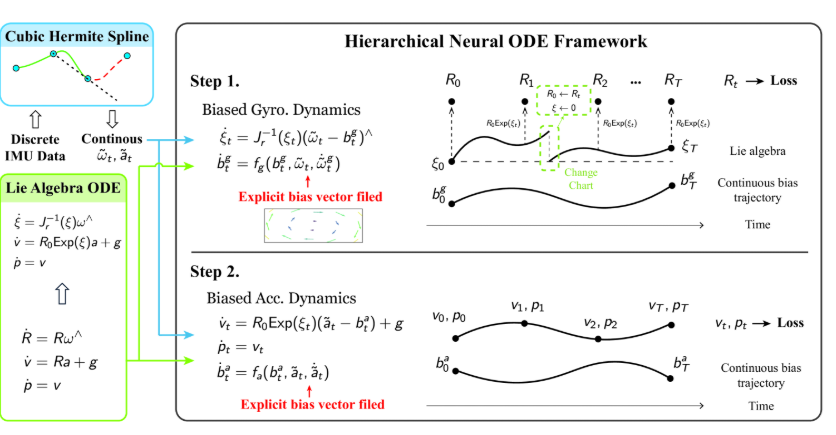
3.2 李代数上的动力学建模
IMU动力学涉及旋转矩阵 R t ∈ S O ( 3 ) R_t \in SO(3) Rt∈SO(3)的微分,这是一个李群上的微分方程。直接在李群上进行优化和积分会带来额外的约束(如正交性约束 R T R = I R^T R = I RTR=I)和数值复杂度。为了简化问题,本方法利用李群与李代数之间的指数映射关系,将问题转化到李代数空间。
S O ( 3 ) SO(3) SO(3)的李代数记为 s o ( 3 ) \mathfrak{so}(3) so(3),是所有 3 × 3 3\times3 3×3反对称矩阵构成的向量空间。通过指数映射 exp : s o ( 3 ) → S O ( 3 ) \exp: \mathfrak{so}(3) \rightarrow SO(3) exp:so(3)→SO(3)和对数映射 log : S O ( 3 ) → s o ( 3 ) \log: SO(3) \rightarrow \mathfrak{so}(3) log:SO(3)→so(3),可以在李群和李代数之间建立双射关系(在一定邻域内)。具体地,对于旋转矩阵 R R R,存在唯一的向量 ϕ ∈ R 3 \phi \in \mathbb{R}^3 ϕ∈R3,使得:
R = exp ( [ ϕ ] × ) R = \exp([\phi]_\times) R=exp([ϕ]×)
这里 ϕ \phi ϕ称为旋转向量,其方向表示旋转轴,其模长表示旋转角度。
利用这一映射,可以将旋转的微分方程转化为旋转向量的微分方程。设 R t = R 0 exp ( [ ξ t ] × ) R_t = R_0 \exp([\xi_t]_\times) Rt=R0exp([ξt]×),其中 R 0 R_0 R0是初始旋转, ξ t \xi_t ξt是相对于初始姿态的旋转向量,则有:
ξ ˙ t = J r − 1 ( ξ t ) ω t \dot{\xi}_t = J_r^{-1}(\xi_t) \omega_t ξ˙t=Jr−1(ξt)ωt
其中 J r − 1 J_r^{-1} Jr−1是 S O ( 3 ) SO(3) SO(3)右雅可比矩阵的逆。这样,原本在流形上的微分方程被转化为欧氏空间 R 3 \mathbb{R}^3 R3上的常微分方程,可以直接应用标准的ODE求解器。
3.3 层级训练策略
为了提升训练的稳定性和效率,本方法采用层级训练策略,将陀螺仪和加速度计的偏置学习解耦为两个阶段:
第一阶段:学习陀螺仪偏置动力学
在第一阶段,仅训练陀螺仪偏置网络 f g f_g fg,而将加速度计偏置设为零。动力学方程为:
ξ ˙ t = J r − 1 ( ξ t ) ( ω ~ t − b t g ) \dot{\xi}_t = J_r^{-1}(\xi_t)(\tilde{\omega}_t - b_t^g) ξ˙t=Jr−1(ξt)(ω~t−btg)
b ˙ t g = f g ( b t g , ω ~ t , ω ~ ˙ t ) \dot{b}_t^g = f_g(b_t^g, \tilde{\omega}_t, \dot{\tilde{\omega}}_t) b˙tg=fg(btg,ω~t,ω~˙t)
其中旋转矩阵可以通过 R t = R 0 Exp ( ξ t ) R_t = R_0 \text{Exp}(\xi_t) Rt=R0Exp(ξt)恢复。损失函数仅基于旋转误差构建,在李代数空间中度量旋转误差:
L R = 1 N ∑ k = 1 N ∥ Log ( R ^ k R k T ) ∥ 2 2 \mathcal{L}_R = \frac{1}{N} \sum_{k=1}^{N} \|\text{Log}(\hat{R}_k R_k^T)\|_2^2 LR=N1k=1∑N∥Log(R^kRkT)∥22
其中 R ^ k \hat{R}_k R^k是通过求解ODE得到的预测旋转, R k R_k Rk是位姿真值。这个损失函数具有良好的数值性质,通过最小化这个损失,网络学习到能够准确预测旋转的陀螺仪偏置动力学。
第二阶段:学习加速度计偏置动力学
在第二阶段,固定已训练好的陀螺仪偏置网络 f g f_g fg,训练加速度计偏置网络 f a f_a fa。将公式(19)与以下方程结合来处理加速度计部分:
v ˙ t = R 0 Exp ( ξ t ) ( a ~ t − b t a ) + g \dot{v}_t = R_0 \text{Exp}(\xi_t)(\tilde{a}_t - b_t^a) + g v˙t=R0Exp(ξt)(a~t−bta)+g
p ˙ t = v t \dot{p}_t = v_t p˙t=vt
b ˙ t a = f a ( b t a , a ~ t , a ~ ˙ t ) \dot{b}_t^a = f_a(b_t^a, \tilde{a}_t, \dot{\tilde{a}}_t) b˙ta=fa(bta,a~t,a~˙t)
其中 R t = R 0 Exp ( ξ t ) R_t = R_0 \text{Exp}(\xi_t) Rt=R0Exp(ξt)已被代入。损失函数包含速度和位置误差:
L v , p = 1 N ∑ k = 1 N ( ∥ p ^ k − p k ∥ 2 2 + ∥ v ^ k − v k ∥ 2 2 ) \mathcal{L}_{v,p} = \frac{1}{N} \sum_{k=1}^{N} (\|\hat{p}_k - p_k\|_2^2 + \|\hat{v}_k - v_k\|_2^2) Lv,p=N1k=1∑N(∥p^k−pk∥22+∥v^k−vk∥22)
其中 p ^ k , v ^ k \hat{p}_k, \hat{v}_k p^k,v^k是通过求解ODE得到的预测值, p k , v k p_k, v_k pk,vk是位姿真值。
这种层级训练策略的优势在于:首先,旋转和平移解耦简化了优化问题,使得每个阶段的目标更加明确;其次,陀螺仪偏置对旋转估计的影响更直接,先训练陀螺仪网络可以为后续的加速度计训练提供更准确的旋转信息;最后,分阶段训练便于调参和诊断问题。
层级训练流程图
3.4 无需偏置真值的监督学习
本方法的一个重要创新是:训练过程中不需要偏置的真值标签。这一点至关重要,因为在实际应用中,偏置真值极难获取。传统方法通常需要通过多传感器融合(如与LiDAR或高精度相机融合)来估计偏置,但这种估计本身就依赖于融合算法的精度,且需要额外的传感器和复杂的标定过程。
本方法通过巧妙的损失函数设计,直接利用IMU运动学约束进行监督。具体来说,如果偏置估计准确,那么补偿后的IMU数据 ω = ω ~ − b g \omega = \tilde{\omega} - b^g ω=ω~−bg和 a = a ~ − b a a = \tilde{a} - b^a a=a~−ba应该满足刚体运动学方程,积分后得到的位姿应该与真值一致。因此,可以将位姿误差作为监督信号,通过反向传播更新偏置网络的参数。
这种监督方式的数学基础是:偏置网络的参数θ通过以下优化问题确定:
θ ∗ = arg min θ ∑ i L ( Integrate ( ω ~ − b g ( θ ) , a ~ − b a ( θ ) ) , Pose g t ) \theta^* = \arg\min_\theta \sum_i \mathcal{L}(\text{Integrate}(\tilde{\omega} - b^g(\theta), \tilde{a} - b^a(\theta)), \text{Pose}_{gt}) θ∗=argθmini∑L(Integrate(ω~−bg(θ),a~−ba(θ)),Posegt)
其中 Integrate \text{Integrate} Integrate表示对补偿后的IMU数据进行积分, Pose g t \text{Pose}_{gt} Posegt是位姿真值。通过自动微分技术,可以计算损失函数对网络参数的梯度,从而使用梯度下降法进行优化。
4. 网络架构与实现细节
4.1 偏置动力学网络设计
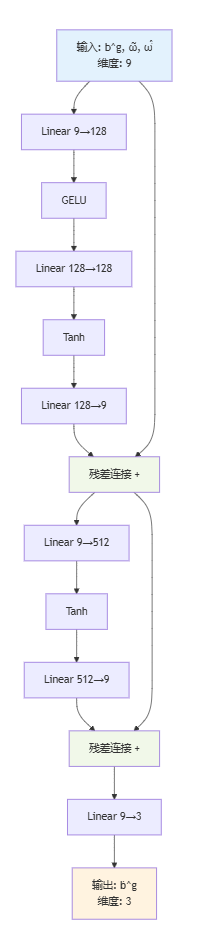
陀螺仪偏置网络 f g f_g fg和加速度计偏置网络 f a f_a fa都采用多层感知机(MLP)架构,但具有不同的深度和宽度以适应各自的复杂度。
陀螺仪偏置网络架构:
class bw_func_net(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(9, 128),
nn.GELU(),
nn.Linear(128, 128),
nn.Tanh(),
nn.Linear(128, 9),
)
self.net2 = nn.Sequential(
nn.Linear(9, 512),
nn.Tanh(),
nn.Linear(512, 9),
)
self.linear2 = nn.Linear(9, 3)
# 小权重初始化,确保训练初期偏置变化缓慢
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight, mean=0, std=0.001)
nn.init.constant_(m.bias, 0)
def forward(self, y, imu_meas, imu_meas_dot, R0):
# 输入: [b^g, ω̃, ω̇̃]
x = torch.cat([y[..., 4:7], imu_meas[...,:3],
imu_meas_dot[...,:3]], dim=-1)
x = self.net(x) + x # 残差连接
x = self.net2(x) + x # 残差连接
return self.linear2(x) # 输出: ḃ^g
网络的输入维度为9,包括当前偏置 b g b^g bg(3维)、当前测量 ω ~ \tilde{\omega} ω~(3维)和测量导数 ω ~ ˙ \dot{\tilde{\omega}} ω~˙(3维)。输出维度为3,表示偏置的变化率 b ˙ g \dot{b}^g b˙g。网络采用了两个残差块,每个残差块都包含残差连接,这有助于梯度传播和训练稳定性。激活函数选择GELU和Tanh,它们都是光滑的非线性函数,适合用于动力学建模。
陀螺仪偏置网络架构图
加速度计偏置网络架构:
class ba_func_net(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(9, 256),
nn.GELU(),
nn.Linear(256, 512),
nn.GELU(),
nn.Linear(512, 9),
)
self.net2 = nn.Sequential(
nn.Linear(9, 256),
nn.GELU(),
nn.Linear(256, 256),
nn.GELU(),
nn.Linear(256, 9),
)
self.linear2 = nn.Linear(9, 3)
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight, mean=0, std=0.001)
nn.init.constant_(m.bias, 0)
def forward(self, y, imu_meas, imu_meas_dot, R0):
# 输入: [b^a, ã, ȧ̃]
x = torch.cat([y[..., 13:16], imu_meas[...,3:],
imu_meas_dot[...,3:]], dim=-1)
x = self.net(x) + x
x = self.net2(x) + x
return self.linear2(x) # 输出: ḃ^a
加速度计网络的结构与陀螺仪网络类似,但层数更深、宽度更大(隐藏层维度达到512),这是因为加速度计偏置的动力学通常更复杂,受重力、离心力等多种因素影响。
4.2 李代数运算的实现
李代数运算是整个系统的数学基础。以下是核心的李代数函数实现:
SO(3)指数映射:
def SO3exp(w: torch.Tensor, eps=1e-6) -> torch.Tensor:
"""将李代数向量映射到李群
输入: w shape (..., 3) - 旋转向量
输出: R shape (..., 3, 3) - 旋转矩阵
"""
theta = torch.norm(w, dim=-1, keepdim=True)
small_theta_mask = theta[..., 0] < eps
Identity = torch.eye(3).expand(w.shape[:-1]+(3,3)).to(w.device)
# 小角度近似: R ≈ I + [w]×
Rotation = torch.zeros_like(Identity)
Rotation[small_theta_mask] = Identity[small_theta_mask] + so3hat(w[small_theta_mask])
# Rodrigues公式: R = cos(θ)I + (1-cos(θ))nn^T + sin(θ)[n]×
unit_w = w[~small_theta_mask] / theta[~small_theta_mask]
s = torch.sin(theta[~small_theta_mask]).unsqueeze(-1)
c = torch.cos(theta[~small_theta_mask]).unsqueeze(-1)
Rotation[~small_theta_mask] = (c * Identity[~small_theta_mask] +
(1-c) * outer_product(unit_w, unit_w) +
s * so3hat(unit_w))
return Rotation
这个函数实现了从旋转向量到旋转矩阵的转换。对于小角度情况,使用一阶近似 R ≈ I + [ ω ] × R \approx I + [\omega]_\times R≈I+[ω]×以避免数值不稳定;对于一般情况,使用Rodrigues公式 R = cos θ I + ( 1 − cos θ ) n n T + sin θ [ n ] × R = \cos\theta I + (1-\cos\theta)nn^T + \sin\theta[n]_\times R=cosθI+(1−cosθ)nnT+sinθ[n]×进行精确计算。
…详情请参照古月居
CA --> D
B --> C
B --> D
C --> G
D --> G
E --> F
E --> G
E --> H
F --> I
G --> I
H --> I
I --> E
I --> J
style A fill:#bbdefb
style J fill:#fff9c4
style C fill:#f8bbd0
style D fill:#f8bbd0
style I fill:#c5e1a5
**4.5 SO(3)上的ODE求解器**
标准的ODE求解器(如Runge-Kutta方法)是为欧氏空间设计的,直接应用于旋转矩阵会破坏其正交性约束。本方法通过在李代数空间进行积分,然后映射回李群,保证了旋转矩阵的有效性。
```python
def odeint_SO3(func, y0, R0, t, method='rk4', rtol=1e-7, atol=1e-9):
"""SO(3)上的ODE积分
输入:
func - 动力学函数
y0 - 初始状态 [ξ_0, t_0, b^g_0, v_0, p_0, b^a_0]
R0 - 初始旋转矩阵
t - 时间序列
method - 积分方法 ('euler', 'rk4', 'dopri5'等)
输出:
solution - 状态轨迹
R_sol - 旋转矩阵轨迹
"""
# 设置回调函数,在每次图切换时更新R0
callback = getattr(func, 'callback_change_chart', lambda x: None)
# 选择求解器
solver = SOLVERS[method](func=func, y0=y0, R0=R0, rtol=rtol, atol=atol)
# 积分
solution, R_sol = solver.integrate(t)
return solution, R_sol
求解器在积分过程中会定期检查旋转向量的模长,当接近奇异点(如 ∣ ξ ∣ ≈ π |\xi| \approx \pi ∣ξ∣≈π)时,会进行图切换(chart switching),即重新选择局部坐标系,避免数值问题。
5. 训练流程与损失函数
5.1 数据准备与预处理
训练数据来自公开的IMU数据集,如EUROC和TUM-VI。这些数据集提供了同步的IMU测量和高精度的位姿真值(通过视觉-惯性融合或运动捕捉系统获得)。
数据预处理包括以下步骤:
- 时间对齐: 将IMU测量和位姿真值对齐到统一的时间戳
- 重采样: 将数据重采样到固定频率(如200Hz)
- 滑动窗口: 将长序列切分为固定长度的窗口(如16个时间步)
- 数值微分: 使用Savitzky-Golay滤波器计算IMU测量的时间导数
- 归一化: 对IMU测量进行归一化,提高训练稳定性
数据处理流程图

class EUROCDataset:
def __init__(self, data_dir, train_seqs, dt=0.005,
loss_window=16, batch_size=1000):
self.dt = dt
self.loss_window = loss_window
self.batch_size = batch_size
# 加载数据
self.data = []
for seq in train_seqs:
imu_data = self.load_imu(os.path.join(data_dir, seq))
pose_data = self.load_pose(os.path.join(data_dir, seq))
# 时间对齐和重采样
aligned_data = self.align_and_resample(imu_data, pose_data, dt)
# 计算导数
aligned_data['imu_dot'] = self.compute_derivative(aligned_data['imu'])
self.data.append(aligned_data)
def __getitem__(self, idx):
# 随机选择序列和起始位置
seq_idx = np.random.randint(len(self.data))
start_idx = np.random.randint(len(self.data[seq_idx]) - self.loss_window)
# 提取窗口数据
window_data = {
'imu': self.data[seq_idx]['imu'][start_idx:start_idx+self.loss_window],
'imu_dot': self.data[seq_idx]['imu_dot'][start_idx:start_idx+self.loss_window],
'rotation': self.data[seq_idx]['rotation'][start_idx:start_idx+self.loss_window],
'velocity': self.data[seq_idx]['velocity'][start_idx:start_idx+self.loss_window],
'position': self.data[seq_idx]['position'][start_idx:start_idx+self.loss_window],
'time': self.data[seq_idx]['time'][start_idx:start_idx+self.loss_window]
}
return window_data
5.2 初始偏置估计
在训练过程中,采用短时间窗口策略,每个窗口需要初始偏置条件。虽然偏置真值难以获取,但可以通过位姿真值进行近似估计。根据IMU运动学方程,初始偏置可以通过以下公式近似:
b k g = ω ~ k − Log ( R k T R k + 1 ) / ( t k + 1 − t k ) b_k^g = \tilde{\omega}_k - \text{Log}(R_k^T R_{k+1}) / (t_{k+1} - t_k) bkg=ω~k−Log(RkTRk+1)/(tk+1−tk)
b k a = a ~ k − R k T ( ( v k + 1 − v k ) / ( t k + 1 − t k ) − g ) b_k^a = \tilde{a}_k - R_k^T ((v_{k+1} - v_k) / (t_{k+1} - t_k) - g) bka=a~k−RkT((vk+1−vk)/(tk+1−tk)−g)
其中 R k , v k R_k, v_k Rk,vk是位姿真值, Log ( ⋅ ) : S O ( 3 ) → R 3 \text{Log}(\cdot): SO(3) \rightarrow \mathbb{R}^3 Log(⋅):SO(3)→R3是李群的对数映射。这种初始化方法虽然受到IMU测量噪声和位姿估计误差的影响,但只要噪声在合理范围内,训练过程就能有效处理这种不确定性。实际上,这种噪声可以视为一种数据增强,有助于提高模型的鲁棒性。
…详情请参照古月居

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)