利用NSGA-III算法优化随机森林模型超参数:通过Optuna库实现可视化调参与3D曲面图展示
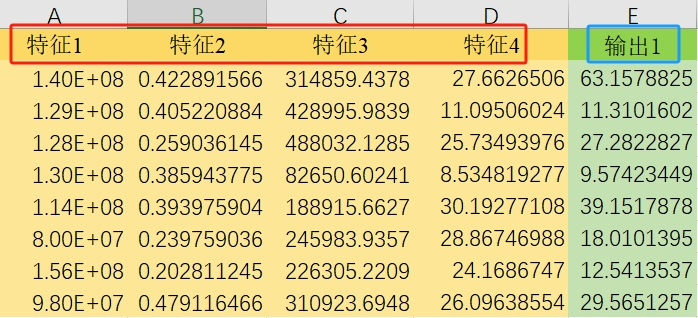
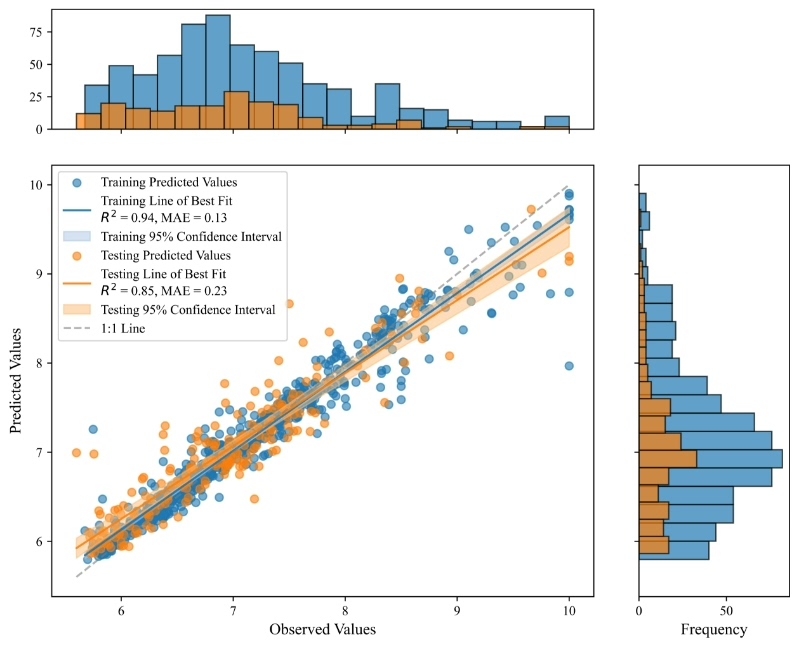
利用NSGA-III算法优化机器学习模型 通过Optuna库实现机器学习模型超参数的优化与可视化,通过精心设计的目标函数,将搜索多个超参数空间,最终确定使模型性能最优的参数组合 为了更直观地展示调参过程,最后利用3D曲面图对调参效果进行可视化 本案例优化的是随机森林的超参数,优化算法采用NGSA-III,优化的算法和预测模型可以根据要求修改,如NSGA-II,MOEA/D 一键运行代码生成的图片包括:光滑3D曲面图展示RMSE变化(图1) 相关系数气泡热力图(图2) 训练集与测试集预测值对比及置信区间可视化(图3)
调参这事儿,说多了都是泪。尤其是随机森林这种参数大户,nestimators、maxdepth、minsamplessplit这几个兄弟凑一块儿,简直能玩出排列组合的花来。不过今天咱们换个姿势——用NSGA-III算法带着Optuna库玩转多目标优化,顺手还能把调参过程拍成3D大片。
先扔个目标函数镇楼:
def objective(trial):
n_estimators = trial.suggest_int('n_estimators', 50, 300)
max_depth = trial.suggest_categorical('max_depth', [None, 10, 20, 30])
min_samples_split = trial.suggest_float('min_samples_split', 0.1, 1.0)
model = RandomForestRegressor(
n_estimators=n_estimators,
max_depth=max_depth,
min_samples_split=min_samples_split,
n_jobs=-1
)
cv_rmse = -cross_val_score(model, X_train, y_train,
cv=5, scoring='neg_root_mean_squared_error').mean()
model.fit(X_train, y_train)
test_rmse = mean_squared_error(y_test, model.predict(X_test), squared=False)
return cv_rmse, test_rmse这函数里藏着两个心机:交叉验证误差和测试集误差要同时最小化。Optuna的suggest方法像开盲盒一样在参数空间里探索,NSGA-III则负责在帕累托前沿上找平衡点。
跑优化的时候记得打开进度条,不然等到天荒地老:
study = optuna.create_study(
directions=['minimize', 'minimize'],
sampler=optuna.samplers.NSGAIISampler()
)
study.optimize(objective, n_trials=100, show_progress_bar=True)这里有个冷知识——NSGA-III在Optuna里其实用NSGA-II实现的,不过对于大多数场景够用了。要是遇到特别复杂的高维空间,可以试试自定义参考点生成策略。
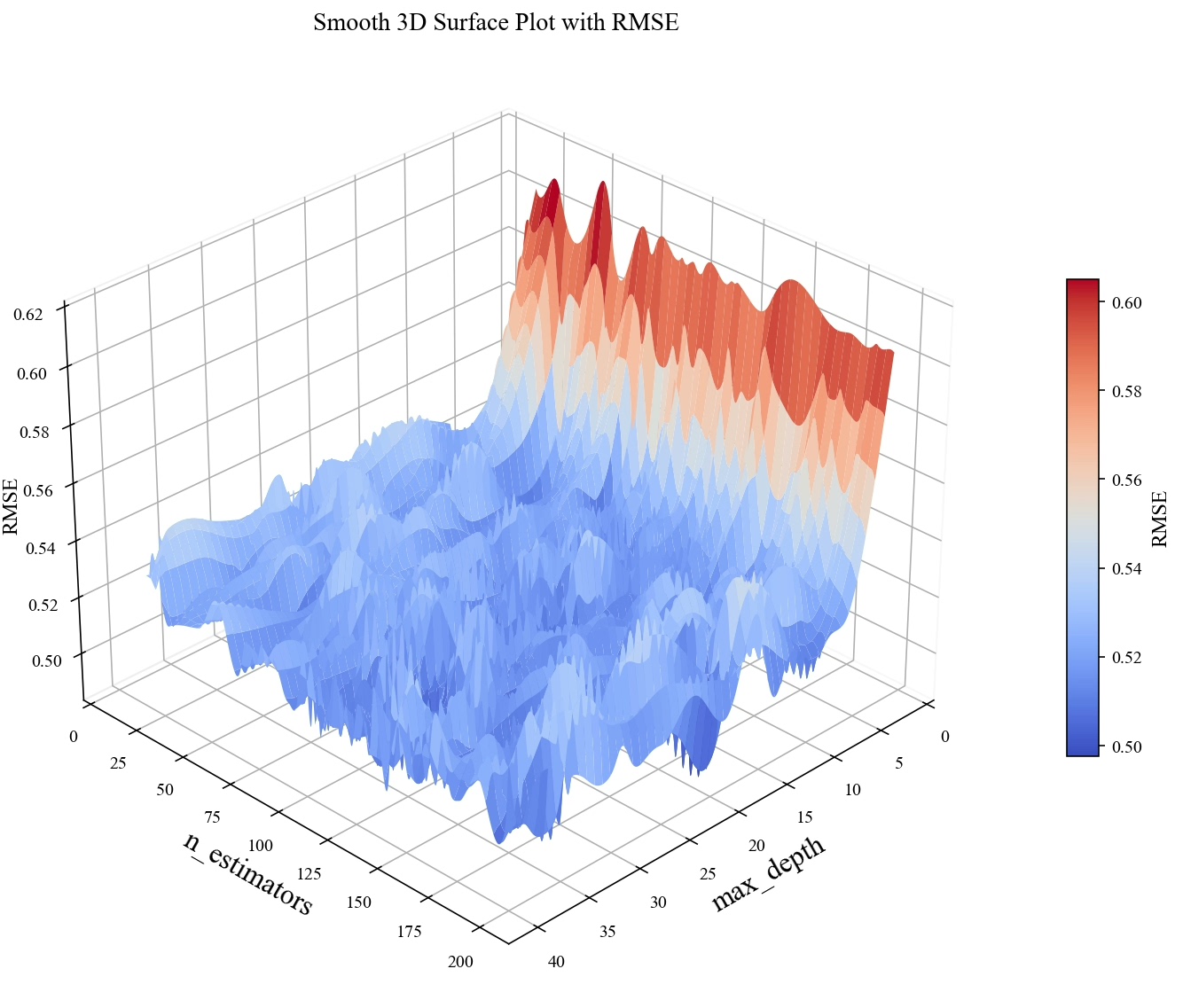
跑完优化后,3D可视化才是重头戏:
from mpl_toolkits.mplot3d import Axes3D
trials_df = study.trials_dataframe()
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111, projection='3d')
surf = ax.plot_trisurf(trials_df['params_n_estimators'],
trials_df['params_max_depth'],
trials_df['value_0'],
cmap='viridis', edgecolor='none')
ax.view_init(30, 45)
plt.colorbar(surf, pad=0.1)这个曲面图能看出参数间的微妙关系——比如当nestimators超过200后,模型对maxdepth的敏感度会突然降低,就像喝饱了水的海绵,再怎么拧也挤不出更多效果。
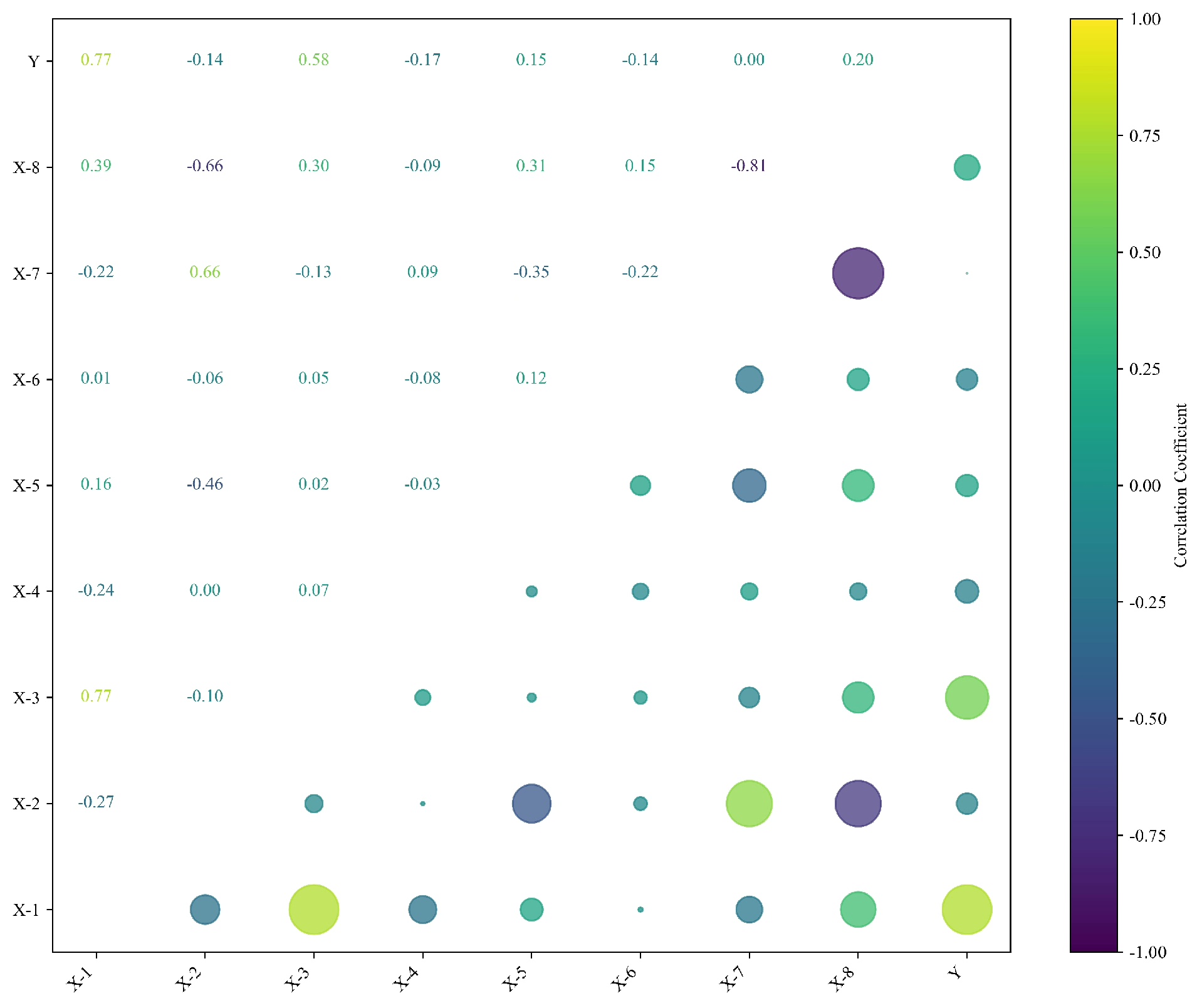
最后用热力图给特征重要性做个CT扫描:
best_model = RandomForestRegressor(**study.best_params)
best_model.fit(X_train, y_train)
corr_matrix = pd.DataFrame(X_train).corr()
sns.heatmap(corr_matrix, annot=True, fmt=".2f",
cmap='coolwarm', mask=np.triu(corr_matrix))
plt.scatter(range(len(corr_matrix)), range(len(corr_matrix)),
s=best_model.feature_importances_*1000,
c='orange', edgecolors='black')气泡大小代表特征重要性,颜色深浅显示特征间的相关性。有时候会发现某些强相关特征的重要性反而低,这种反直觉的现象正是集成模型的魅力所在。
整个过程跑下来,最深的体会是——好的调参就像煮拉面,火候(迭代次数)、配料(参数范围)、汤底(目标函数)缺一不可。NSGA-III这种多目标优化算法,本质上是在帮我们找那个"鲜味物质浓度最高,同时不破坏口感"的黄金平衡点。下次遇到需要兼顾多个指标的优化任务,不妨让帕累托前沿当你的私人厨师。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)