国产数据库迁移实战:Vastbase改造指南
1.迁移背景
随着国产数据库的发展越来越好以及不被卡脖子等强需求,政府机关、国企、银行等甲方逐步改造系统支持国产数据库以保证数据的安全性不被窃取;原有微服务项目改造支持国产化也成为趋势,由于之前公司做了几款国产数据库的评估,有神通、海量等数据库,也因此写了一遍SpringBoot + JPA + 神通数据库文档,但最终也没有落地,最后还是采用了vastbase海量数据,直接上干货。
2.vastbase海量数据库
官网:vastbase官网
exBase:exBase文档
3.改造指南
maven依赖
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.5.4</version>
</dependency>配置yml文件
spring:
datasource:
driver-class-name: org.postgresql.Driver
url: jdbc:postgresql://127.0.0.1:5432/test?currentSchema=test_base&CserverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&autoReconnect=true&useSSL=false
username: test
password: test@123
jpa:
# 此处是重写了PostgreSQL方言
database-platform: com.test.common.CustomPostgreSQLDialect
showSql: false
hibernate:
ddl-auto: validate
use-new-id-generator-mappings: false
open-in-view: true
properties:
hibernate:
enable_lazy_load_no_trans: truevastbase海量数据库与神通数据库类似,数据库下面是schemes,scheme中才是表,因此在配置url中指定了数据库test,currentSchema指定具体的scheme以及时区等;由于vastbase是基于openGauss内核开发的企业级关系型数据库,而openGauss又是基于PostgreSQL进行开发的企业级关系型数据库,因此数据库驱动使用了org.postgresql.Driver。对于方言可以继续使用MySql的方言,但需要设置vastbase兼容MySql模式改造成本小,但更换了数据库本质上已不是MySql数据库,兼容不代表所有MySql的操作都支持,个人还是推荐使用PostgreSQL方言,虽大改造成本要高于使用MySql方言,但后期更换其它国产数据库的改造成本会小很多。本文主要是使用PostgreSQL方言。
MySql迁移VastbaseG100数据库

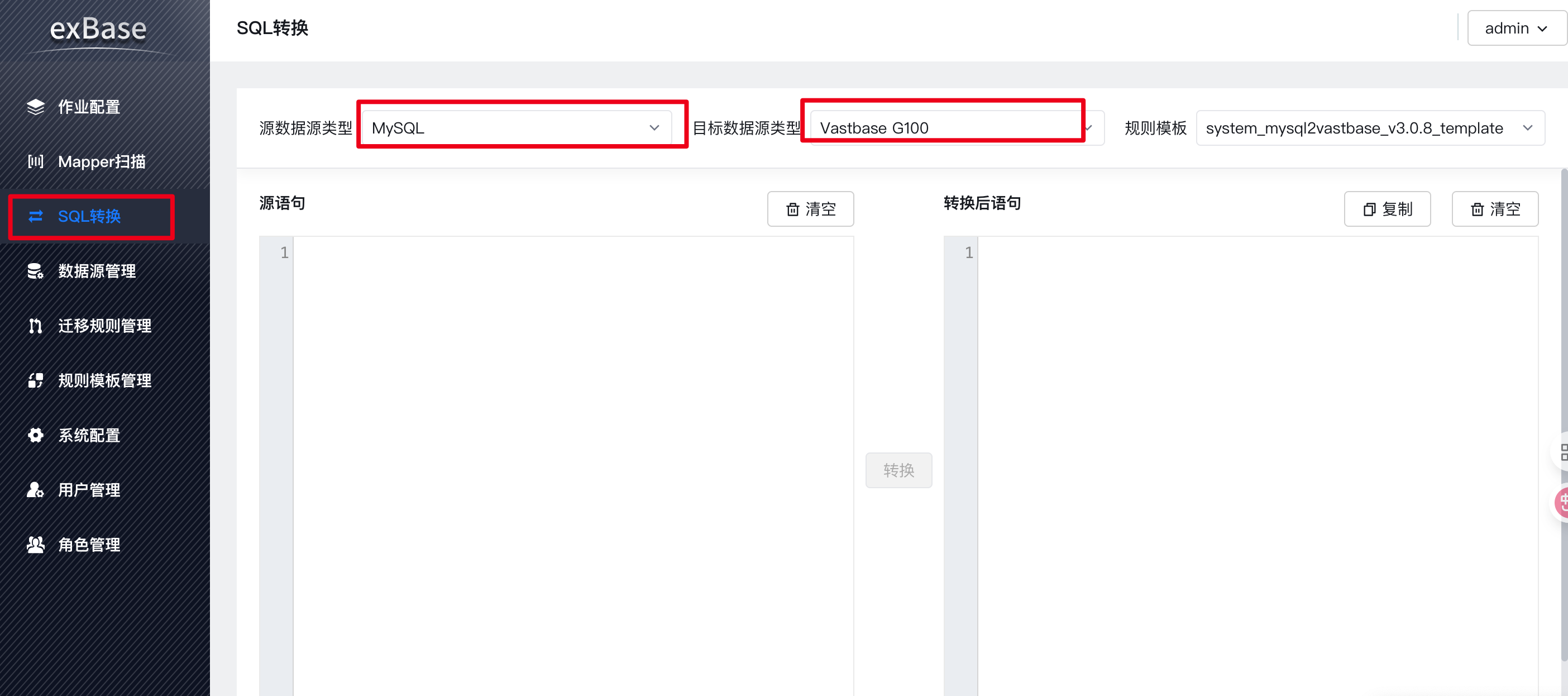
官网推荐使用exBase进行数据库迁移,主要涉及数据源的管理,需要连上MySql和VastbaseG100数据库,在作业配置中创建一个任务进行迁移;由于这是不同数据库之间的迁移,支持的数据库字段类型也不太一样,可以在迁移规则管理创建自己所需要的规则,否则就需要自己在数据库迁移完后对vastbase数据库中的表字段类型做调整来写sql脚本;
在项目实际开发中有着JPA的HQL语句还有原生SQL语句的写法,涉及原生SQL是否支持vastbaseG100可以使用exBase中的SQL转换功能,看看是否需要对原生SQL语句进行改造;
问题1:MySql中bit,tinyint需要根据实际情况改成bool,int2,并且代码表映射实体中涉及如下代码也需要改造。
@Column(name = "aa", columnDefinition = "tinyint")
private Integer aa;
@Column(name = "bb", columnDefinition = "smallint")
private Integer bb;
改成
@Column(name = "aa", columnDefinition = "int2")
private Integer aa;
@Column(name = "bb", columnDefinition = "int2")
private Integer bb;问题2:如果启动项目报Schema-validation: missing sequence [hibernate_sequence] ,在MySql使用序列会创建一张序列表,但VastbaseG100中有专门管理序列并不是表,因此删除表并创建序列。
-- 删除现有的表
DROP TABLE IF EXISTS test_base.hibernate_sequence;
-- 创建真正的序列
CREATE SEQUENCE test_base.hibernate_sequence
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;问题3:如果启动项目报:Caused by: org.postgresql.util.PSQLException: Bad value for type long : 170141183460469231731687303715884105727
说明序列中有超过Long最大值的数据可以参考其他人的处理,如下是使用(Vastbase G100 V2.2 (Build 15) Release) compiled at 2025-09-04 20:47:53 commit 28199 last mr product name:Vastbase G100 version:V2.2 (Build 15) Release patch:10 commit:28199 openGauss version:5.0.0 host:aarch64-unknown-linux-gnu版本的解决办法,在Vastbase G100上执行如下命令后重新迁移数据库则完美解决。友情提示:迁移数据库最好不要与其他人共用同一个数据库,例如你所使用的scheme中没有maximum_value = 170141183460469231731687303715884105727,但其他人的scheme中有,项目启动中可能会扫描整个数据库下的所有序列(这个分项目,有的项目启动不会扫描而有的项目启动会扫描,这个可能与使用的spring版本有关,具体没针对spring版本测试,但改造过程中两者都遇到了),依然会继续报错;
// 设置 SQL 模式兼容
vb_guc set -c "sql_mode='PAD_CHAR_TO_FULL_LENGTH,IGNORE_SPACE,ANSI_QUOTES'"
// 查询vastbase数据库命令是否生效
show b_format_behavior_compat_options;如果想知道具体是哪些scheme中的序列报错可以使用如下语句查询:
// 查询当前数据库下存在超过long最大值的序列
select * from information_schema.sequences where maximum_value='170141183460469231731687303715884105727';
// 查询当前scheme下是否存在超过long最大值的序列
select * from information_schema.sequences where maximum_value='170141183460469231731687303715884105727' and sequence_schema='xx'
// 按scheme分组统计存在超过long最大值的序列在每个scheme上的个数
select sequence_schema, count(*) from information_schema.sequences where maximum_value='170141183460469231731687303715884105727' group by sequence_schema问题4:如果启动项目报:Caused by: org.postgresql.util.PSQLException: Bad value for type long : 18446744073709551615
说明MySql某些表的主键有无符号的bigint,可以使用如下语句进行查询具体的报错序列好定位出是哪些表的问题(sequence_name = tablename_id_sql,可知具体报错的表),然后直接修改MySql表中主键ID去除无符号标识,最后再重新迁移到vastbaseG100数据库中,就得到修复。还有一种方案影响比较小,备份有问题的表并删除,从新创建表并导入数,该方案适合迁移数据库数据量比较多的情况。
select * from information_schema.sequences where maximum_value='18446744073709551615';问题5:上面说了使用PostgreSQL方言但却重写了,其原因是由于代码中并不是所有的表映射实体中指定了表ID主键使用表自动增长,没有指定的会在VastbaseG100中默认使用序列且所有表共用hibernate_sequence,效率会低,建议使用表主键自动增长。而重写方言就是默认使用主键自动增长。之前也想过通过hibernate配置让其使用主键自动增长,可惜没有实现,最后还是重写了。说到VastbaseG100主键自动增长,其实底层还是使用的序列,它会为每张表默认创建一个tablename_id_sql序列。
import org.hibernate.dialect.PostgreSQL92Dialect;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CustomPostgreSQLDialect extends PostgreSQL92Dialect {
public CustomPostgreSQLDialect() {
super();
}
@Override
public String getNativeIdentifierGeneratorStrategy() {
return "identity";
}
}问题6:如果Spring项目中也使用了traffic-starter-quartz框架来做定时任务,则改造中需要注意MySql迁移到VastbaseG100数据库中涉及定时任务的表最好全部删除,然后使用tables_postgres.sql重新创建。
spring:
quartz:
job-store-type: jdbc
jdbc:
schema: classpath:org/quartz/impl/jdbcjobstore/tables_mysql.sql
initialize-schema: never
properties:
org.quartz.jobStore.isClustered: true
org.quartz.jobStore.tablePrefix: QRTZ_
org.quartz.scheduler.instanceId: AUTO
改造成
spring:
quartz:
job-store-type: jdbc
jdbc:
schema: classpath:org/quartz/impl/jdbcjobstore/tables_postgres.sql
initialize-schema: never
properties:
org.quartz.jobStore.isClustered: true
org.quartz.jobStore.tablePrefix: QRTZ_
org.quartz.scheduler.instanceId: AUTO
org.quartz.jobStore.driverDelegateClass: org.quartz.impl.jdbcjobstore.PostgreSQLDelegate问题7:迁移数据时报外键约束错误
解决方案:在迁移数据前禁用外键约束,并在迁移完成后启用外键约束;
-- 禁用外键约束
ALTER TABLE table_name DISABLE TRIGGER ALL;
-- 重新启用外键约束
ALTER TABLE table_name ENABLE TRIGGER ALL;
问题8:由于mysql表字段是vastbase数据库的关键字导致迁移失败,比如offset等关键字
解决方案1:对mysql表中含有offset的表临时修改成offset_value,迁移完成后再次修改会offset;
ALTER TABLE table_name CHANGE COLUMN offset offset_value INT DEFAULT NULL;
ALTER TABLE table_name CHANGE COLUMN offset_value offset INT DEFAULT NULL;
解决方案2:使用exBase工具在创建迁移作业配置时对含有关键字的表做单独的字段映射(只有创建作业配置时可以,修改时不可以),以避免关键字作为字段或表名;
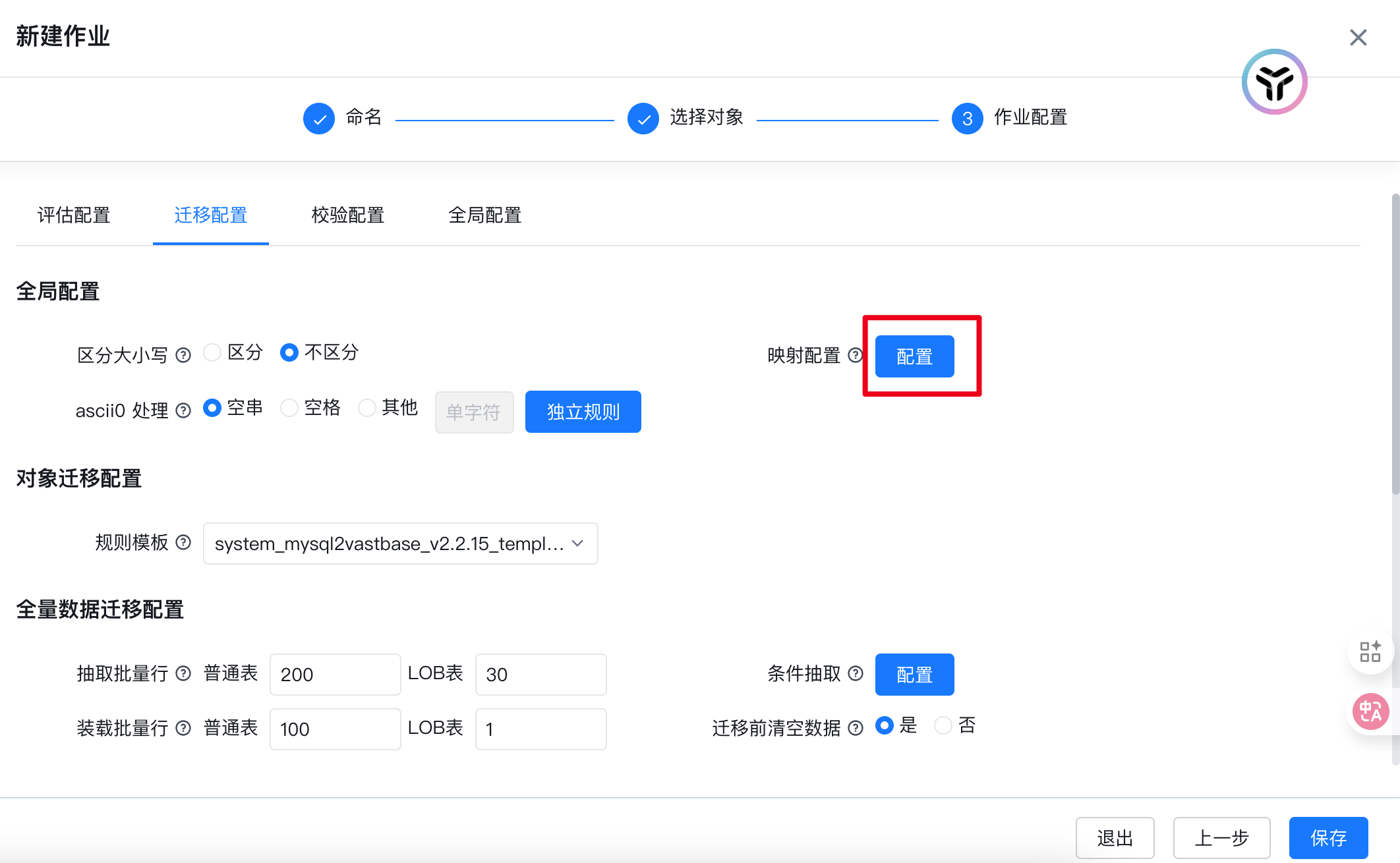
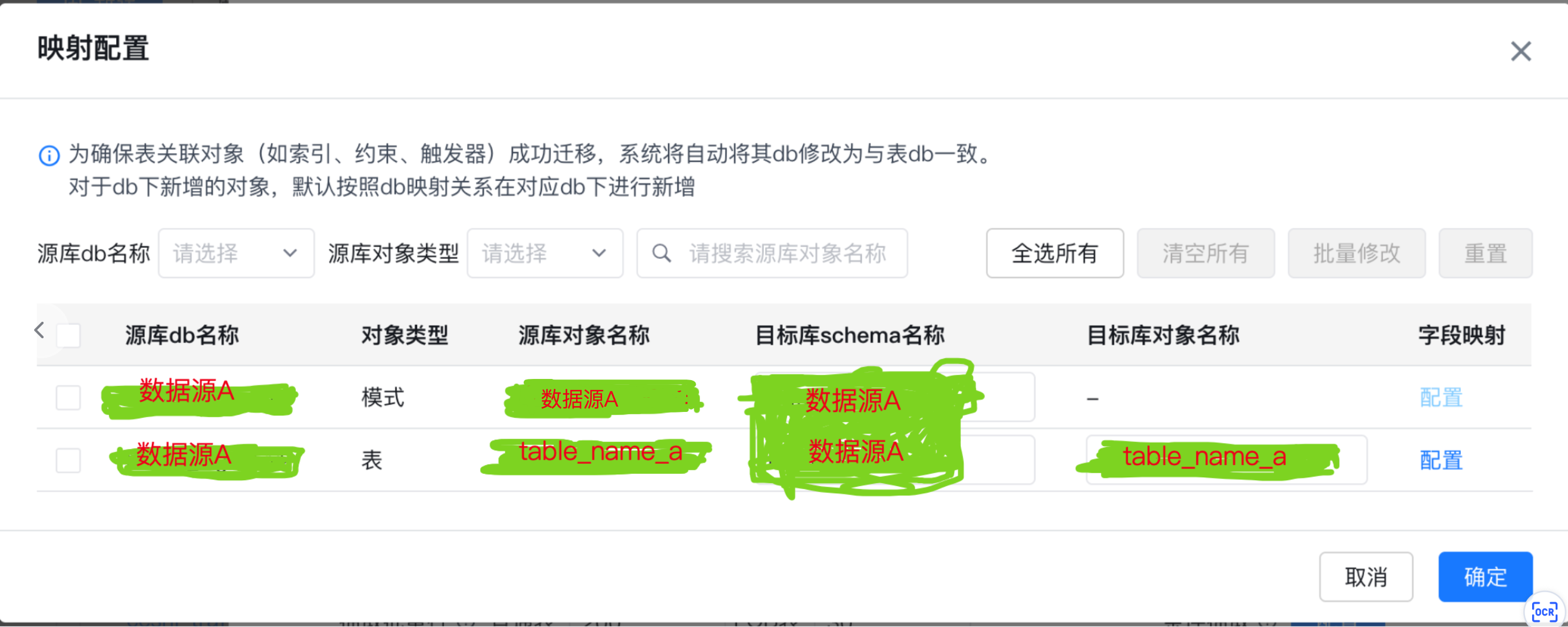
在此处增加一个额外的功能:指定目标数据库中的schema,即默认迁移选择的schema为原数据库的名称无法更改可以在此处更改成需要迁移的schema、映射table_name、映射表字段;
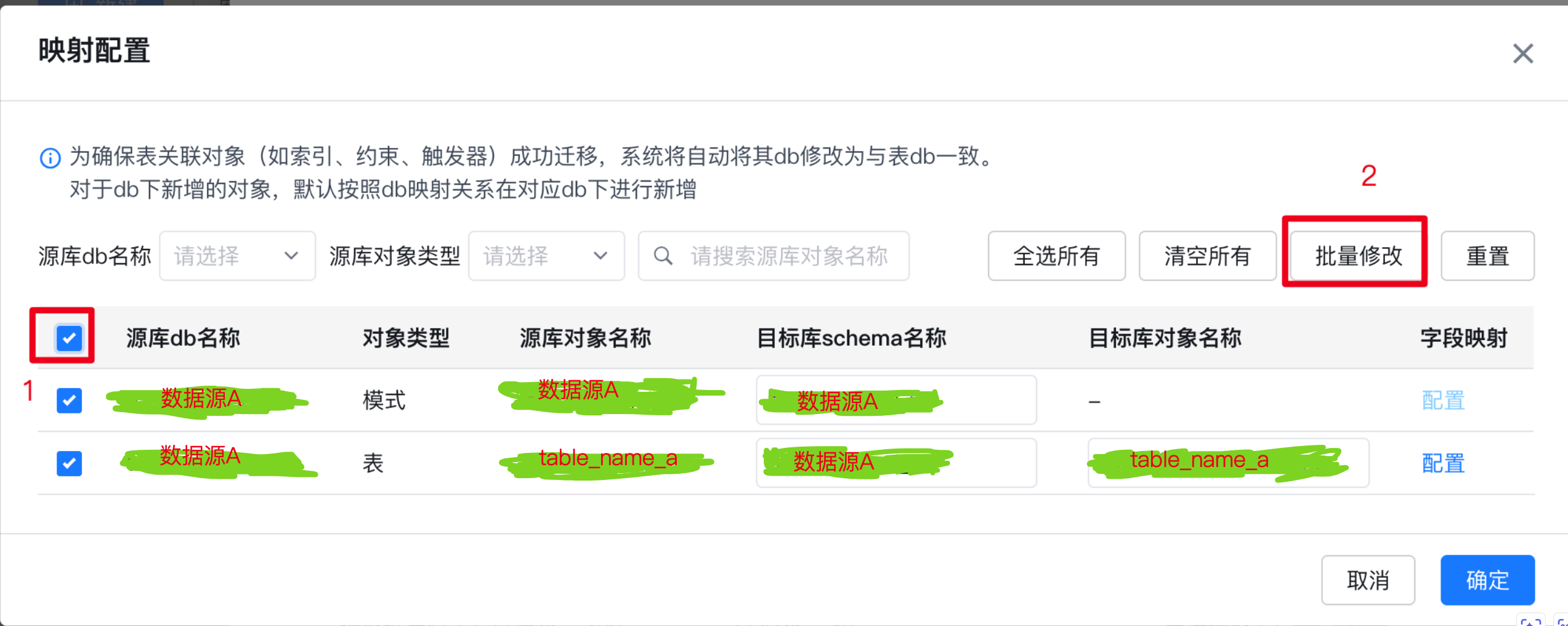
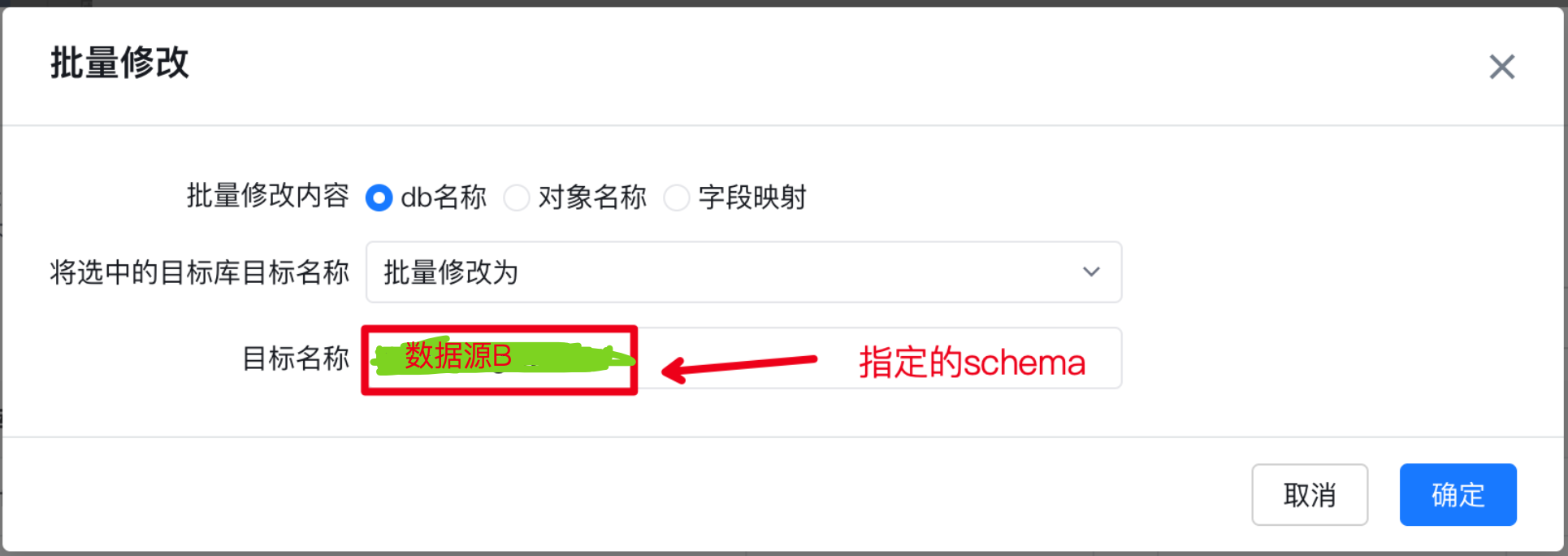
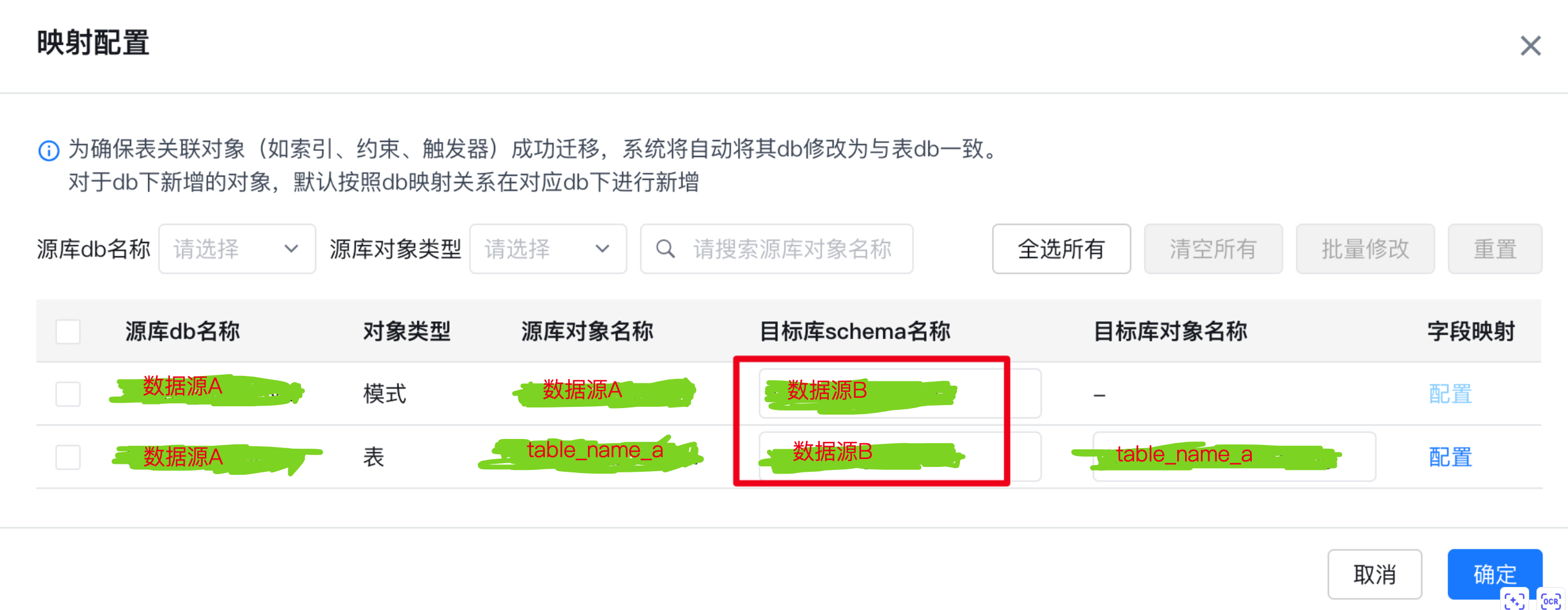
表名映射需选择对象名称进行修改,继续我们的表映射字段修改,特别提醒:需要保证目标数据库中没有修改映射的表,否则无法修改字段映射
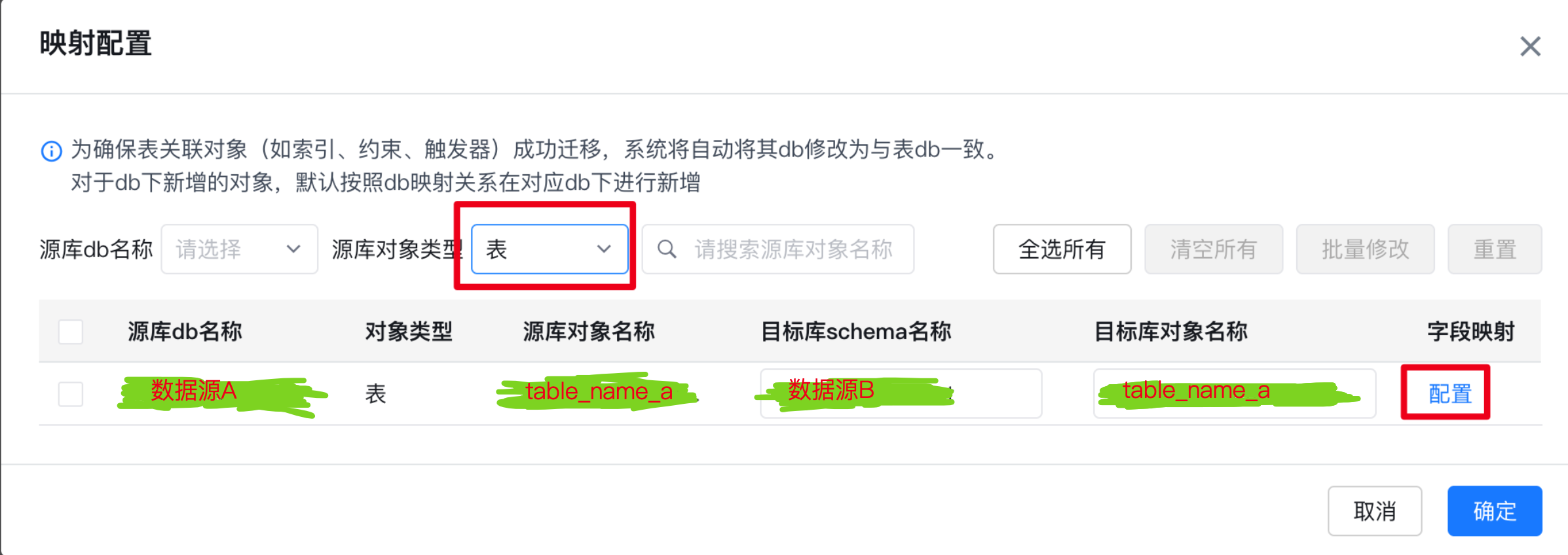
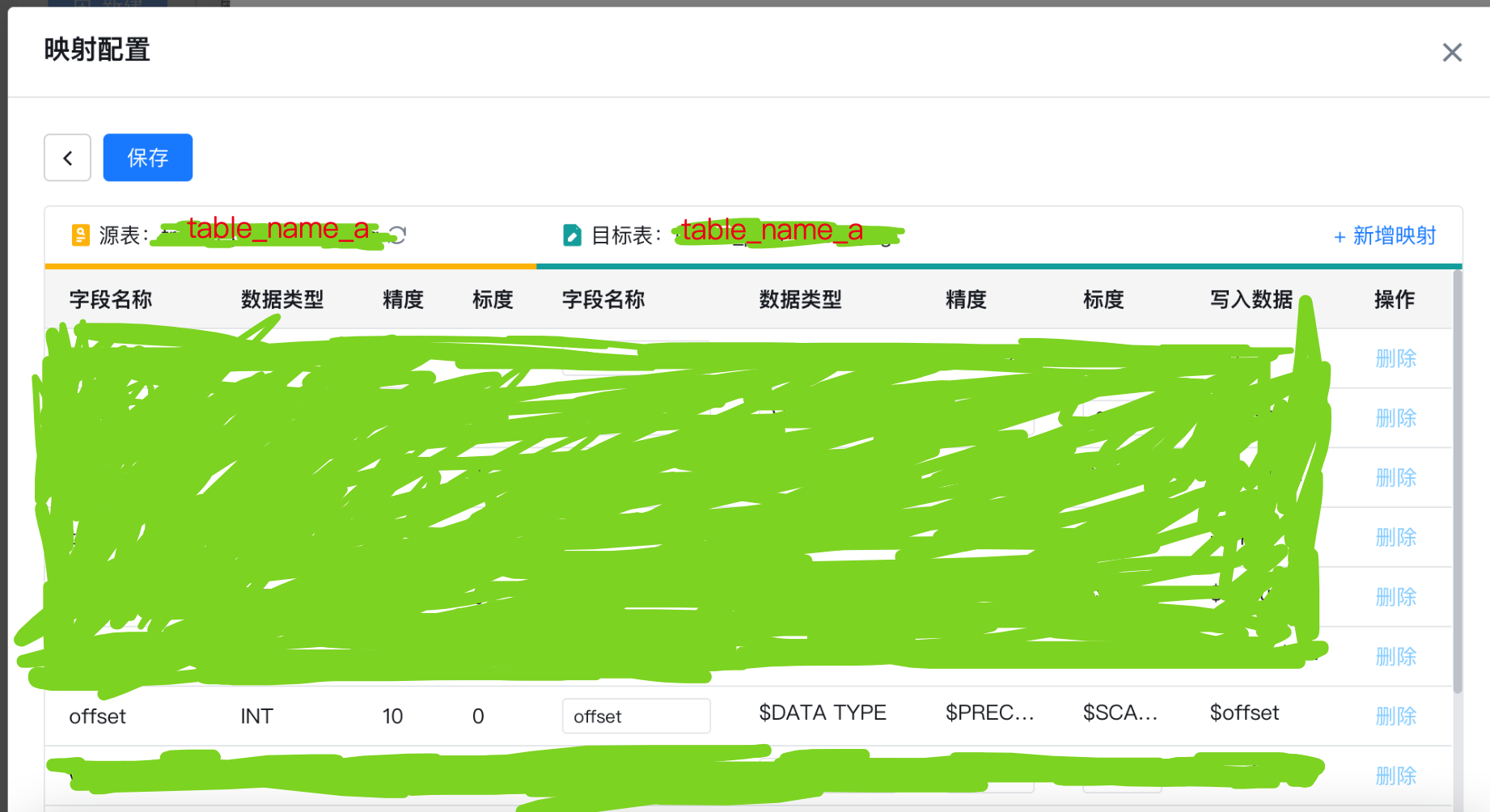
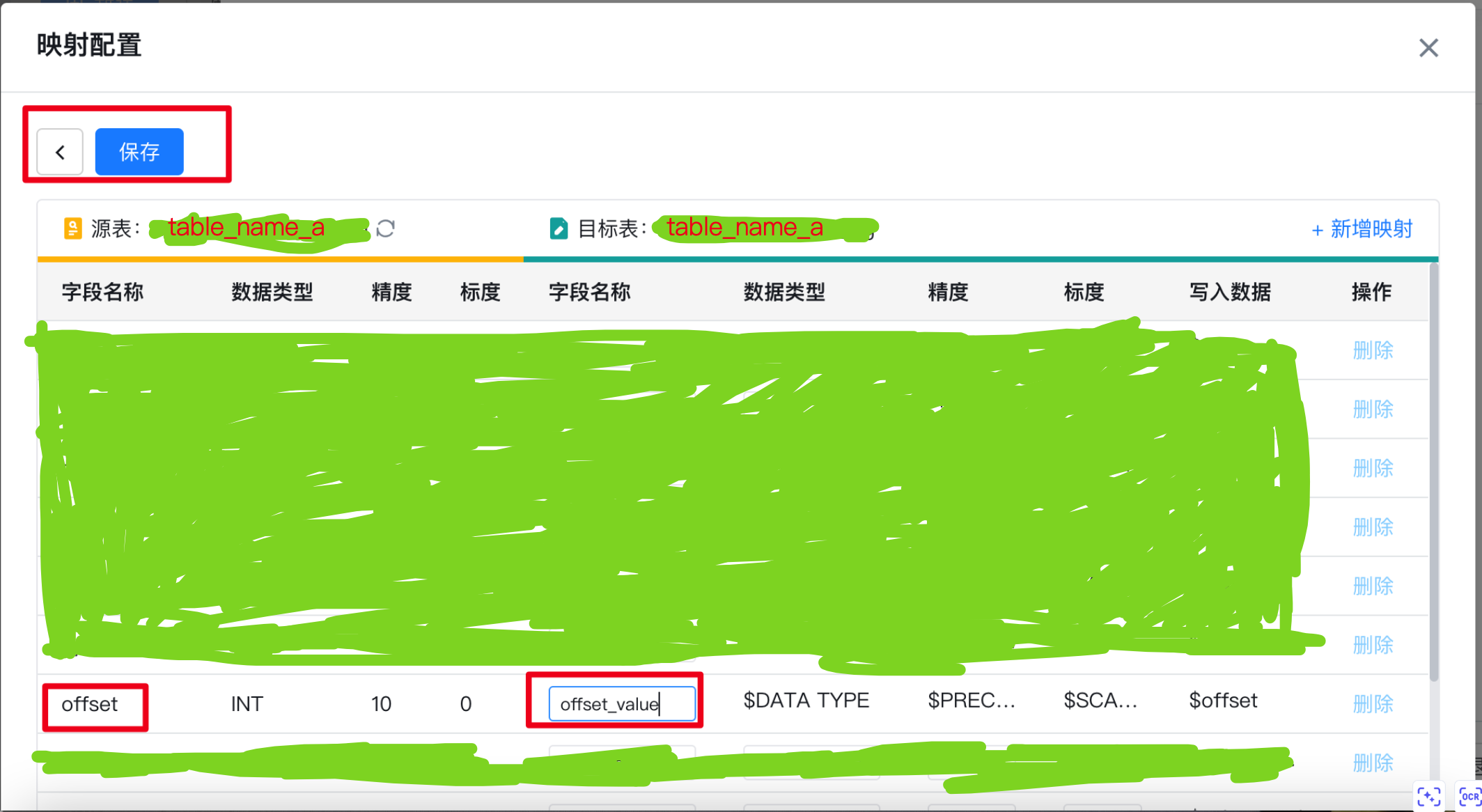
保存后完成作业配置,就可以愉快的迁移表结构和数据库了不会再出现关键字报错;
以上就是本次项目改造中所遇到的相关问题以及解决方案,希望对也在改造VastbaseG100的同学有所帮助。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)