RTX5090 VS RTX 5080 Laptop 做大模型训练比较
摘要:作者分享了RTX 5080笔记本(16G显存/64G内存/U9 CPU)的大模型开发使用体验。测试显示,使用lmdeploy加载7B模型时需CUDA 12.8编译包,相比vllm可节省1/3显存,但16G显存限制上下文token约5000。微调测试中,在未突破硬件上限时,5080笔记本比云端5090慢3-4倍;突破上限后预计差距达6-8倍。同时发现相同参数下,不同GPU训练效果存在差异。本文
本想买个5090的本子做开发+轻训练,但是性价比不高,退而求其次,就买了 RTX 5080 Laptop (16G)的笔记本。内存64G,U9 CPU。因为主要是做开发,所以主要针对开发方面的需求做了一些比较,作为大家的前车之鉴。
加载大模型
vllm加载 7B没问题。
lmdeploy 推的时候遇到了坑,TurboMind 的 CUDA内核未针对你的显卡架构编译;你的 GPU 为 RTX 5080 Laptop ,算力 sm_120 。还好找到了解决方案:官方说明针对 RTX 50 系列需使用 CUDA 12.8 编译的预构建包;否则运行 TurboMind 可能出现错误。
source /home/miniconda3/bin/activate && conda activate lmdeploy && pip uninstall -y lmdeploy && pip install https://github.com/InternLM/lmdeploy/releases/download/v0.10.2/lmdeploy-0.10.2+cu128-cp310-cp310-manylinux2014_x86_64.whl```
lmdeploy确实比vllm的显存优化做的好,从nvitop的 MEM上就能看到差异,应该能比vllm少三分之一。但是由于16G显存确实太小,留给上下文的token只能优化到5000左右,应该还可以再优化,我没再研究,参数配置如下:
lmdeploy serve api_server --dtype bfloat16 --cache-max-entry-count 0.9 --quant-policy 8 /home/peter/LLM/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
量化的大模型(GGUF)需要llama,我不常用就没测,估计可以到32B。
微调大模型
微调参数
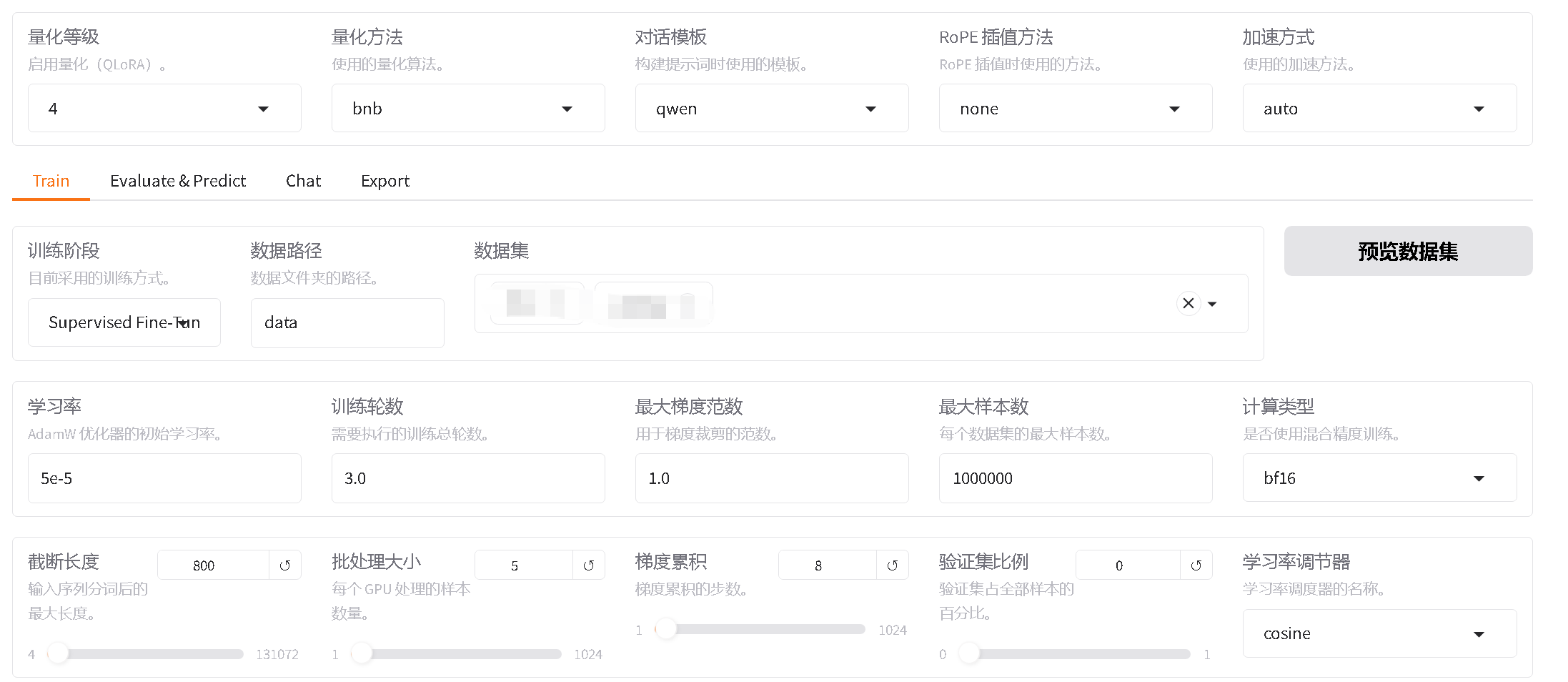
速度
我的5080 Laptop 和云端租赁的 5090 做了对比,同样参数下(批次5,最大长度800),且前提是训练量没有突破 5080 Laptop的上线(GPU的 MEM和 UTL满格):
相差速度3-4倍
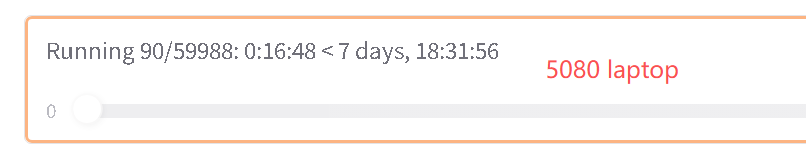
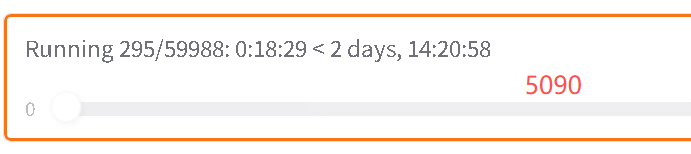
但这是不突破 5080 laptop上限的前提下,否则应该是6-8倍,可参考nvitop推算:
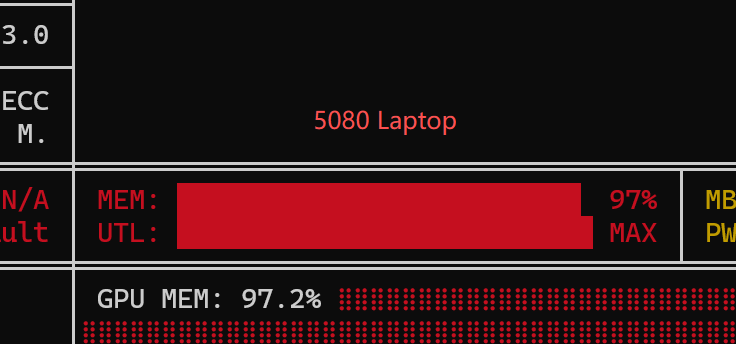
效果
虽然训练参数相同,但由于GPU硬件不同,训练效果也不同,5090可以增加更大的batch,获得更好的效果: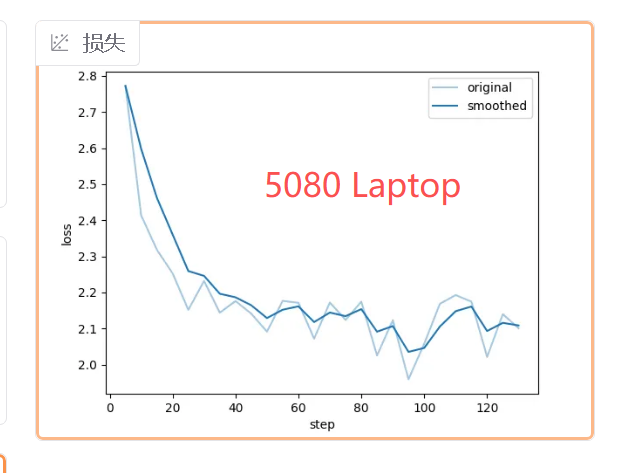
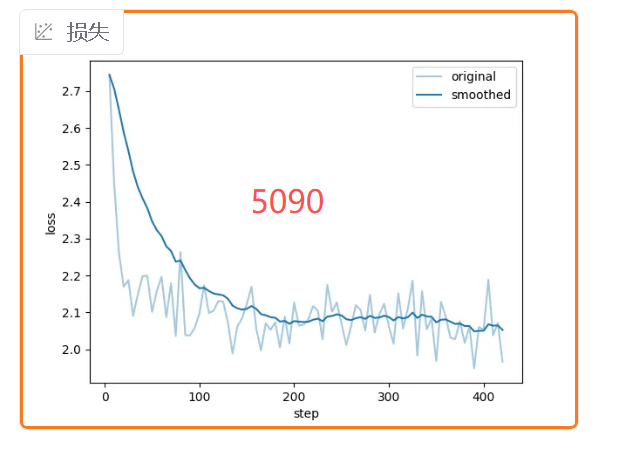
最后
5080 laptop可以正常使用 7B 左右的模型,其实还是不错的,可以做一些小型的LLM应用项目开发和实验性模型训练,正式训练还是要上5090 及以上,效果和速度会更好,性价比也高。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)