面向未来的工业大数据架构:时序数据库(TSDB)选型避坑指南和国产化思考
一、引言
工业4.0和数字化转型的高歌猛进,过去只要每10分钟记录一次电表的读数;现在,在智能制造、风力发电、新能源车联网等场景成千上万个传感器正以毫秒级的频率疯狂吐出数据。数据进入 写入吞吐 和查询延时 的生死时速。
很多团队习惯用 MySQL 或 PostgreSQL 等关系型数据库处理时序数据。但随着测点数量从几千膨胀到百万级,基于 B+ 树的索引结构面对海量并发写入时,磁盘 I/O 迅速饱和,写入性能断崖式下跌。为解决写入问题,不少企业转向 HBase 或 Cassandra 等 NoSQL 方案,甚至搭建庞大的 Hadoop 生态。随之而来的是沉重的运维负担、高昂的硬件成本、复杂查询延迟:在一个通用的 KV 存储上跑通复杂的时序聚合分析要付出非常大的开发代价。
“写入扛不住、存下来查不出、存储成本像滚雪球一样爆炸”,是很多物联网平台面临的真实困境。
所以,要回归数据本质,寻找专为时间序列设计的数据库架构(TSDB)。但开源和商业产品琳琅满目,如何构建一个既能适应边缘计算资源受限,又能满足云端海量分析的“端-边-云”协同架构?
这篇文章就从技术底层原理出发,梳理时序数据库的选型逻辑,以 Apache IoTDB 为代表的新一代国产化时序数据库解决“卡脖子”难题。
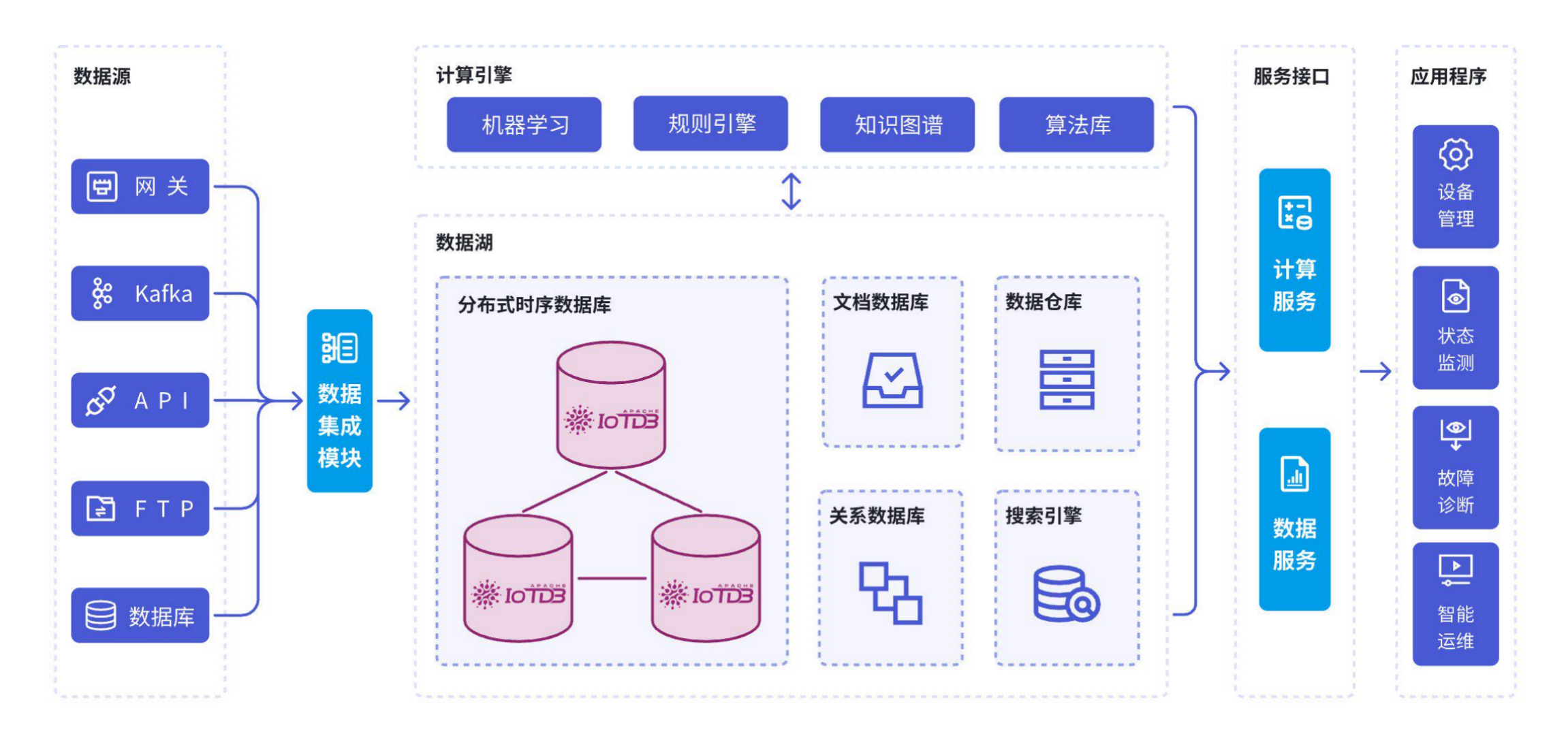
二、选型维度
没有一款数据库是“银弹”,只有最适合业务场景的架构。 工业物联网(IIoT)和大数据监控场景的选型评估的核心维度已超越简单的“读写速度”,而是向着成本、架构灵活性和生态融合度演进。
(1)写入性能:从 B+ 树到 LSM-Tree。物联网数据的典型特征是高并发、高频次、追加写 。OLTP 数据库用 B+ 树索引,为“读”优化的结构。数以亿计的测点数据涌入时,B+ 树会频繁触发页分裂和大量的随机磁盘 I/O,容易写入性能雪崩。
所以, TSDB 必须用LSM-Tree 或类似的变种架构。这种架构把随机写转化为顺序写: 数据先在内存排序,然后批量刷入磁盘。最大化利用磁盘带宽,轻松支撑每秒千万级的数据点写入。此外,选型时还要关注数据库对乱序数据 的处理能力,毕竟在网络不稳定的工业现场,数据迟到是家常便饭,数据库不能因此而阻塞或崩溃。
(2)存储成本:海量数据面前,存储成本直接决定项目的利润率。时序数据有很高的冗余度。如果数据库只是简单存储 Raw Data(原始数据),那么 PB 级的存储费用就是天文数字。优秀的 TSDB 必须内置针对不同数据类型的列式压缩算法:
- Gorilla/Chimp 算法: 对浮点数进行异或压缩。
- RLE(游程编码): 对状态值进行连续压缩。
- Delta-of-Delta: 对时间戳进行差值压缩。
优秀的压缩算法能达到 10:1 甚至 50:1 的压缩比。这不仅节省昂贵的存储硬件,更重要的是,更小的数据就是更少的磁盘 I/O 读取,间接提升查询速度。
(3)查询灵活:TSDB 更重要的是趋势和聚合。选型要重点考察数据库是否原生支持以下能力,而不是依赖应用层去代码实现:
- 降采样。
- 时间窗口聚合: 快速计算滑动窗口内的最大值、最小值、平均值。
- 复杂分析支持: 是否支持自定义函数,能否在数据库内部直接完成傅里叶变换、异常检测等计算,实现“计算下推”,减少网络传输。
(4)生态兼容:TSDB 绝不能是一个孤立的存储桶。必须能无缝融入现有的技术栈。
- 可视化: 是否原生支持 Grafana?是否需要复杂的插件?
- 采集: 能否直接对接 MQTT、OPC UA 等工业协议?
- 大数据: 能否与 Spark、Flink 深度集成?
这一点至关重要。如果一款数据库要写大量的 ETL 代码才能把数据导出来做分析,那它的维护成本就是灾难性的。
(建议此处插入一张技术架构图:展示 TSDB 在大数据架构中承上启下的位置,连接采集端与分析端)
三、国外竞品 InfluxDB
时序数据库(TSDB)的江湖排位 InfluxDB 长期霸榜 DB-Engines 榜首。优秀的开发者体验、活跃的社区、TIG(Telegraf + InfluxDB + Grafana)技术栈的流行,成为很多团队的默认选择。
随着业务从简单的“服务器监控”向复杂的“工业物联网(IIoT)”演进,这位昔日的王者开始显露出疲态。面对海量设备接入和高可用集群需求,InfluxDB 的架构局限性逐渐成为了业务扩展的“天花板”。
(1)时间线爆炸:这是 InfluxDB 最著名的阿喀琉斯之踵。InfluxDB 的数据模型依赖 Tags(标签)构建倒排索引。这种设计在服务器监控场景下表现匪好。但在工业场景下,情况完全不同;InfluxDB 的索引数量呈指数级爆炸。
后果: 倒排索引消耗很大的内存。时间线数量达到百万级以上,InfluxDB 进程会因内存耗尽(OOM)而频繁崩溃,导致写入中断。虽然官方推出 TSM 和 TSI 引擎缓解,但在超大规模设备接入场景下,依然是难以根除的。
(2)集群能力的缺失。企业级应用的高可用(HA)和水平扩展是底线。InfluxDB 长期用“Open Core”商业策略:开源版本仅支持单机部署。所以:
- 单点故障风险: 一旦服务器宕机,数据写入即刻停止。
- 无法水平扩容: 单机磁盘或 CPU 达到瓶颈时,无法通过简单“加机器”来分担负载,只能被迫进行昂贵、复杂的垂直升级(买更贵的服务器)。
虽然 InfluxDB 企业版支持集群,授权费用很贵,是一笔难以承受的 TCO(总拥有成本)。相比之下,原生开源且支持分布式集群的替代方案更划算。
(3)IT 监控 vs. OT 建模:InfluxDB 的基因诞生于 IT 运维监控,Tag-Value 的扁平模型非常适合描述“CPU 使用率”、“Web 响应时间”。但 OT(运营技术)领域,物理世界是层级化的。InfluxDB 把这种层级关系“打平”成一个个 Tag,不仅造成数据存储的冗余,也让查询特定层级变复杂、低效。工业场景要一种能原生映射**“树形结构”**的数据模型,而不是强行套用 IT 监控的扁平逻辑。
(4)工业现场,因为网络抖动或传感器故障,数据要回填或修正。InfluxDB 对历史数据的更新和删除操作不友好,非常消耗资源,甚至引发严重的性能抖动。对于需要频繁进行数据清洗和校准的工业大数据平台,这一点往往让人头疼不已。
InfluxDB 依然是一款优秀的软件,但在**“千万级设备接入”、“低成本集群化部署”以及“复杂的工业层级建模”** 显得力不从心。
这不是它不够好,而是场景不对。
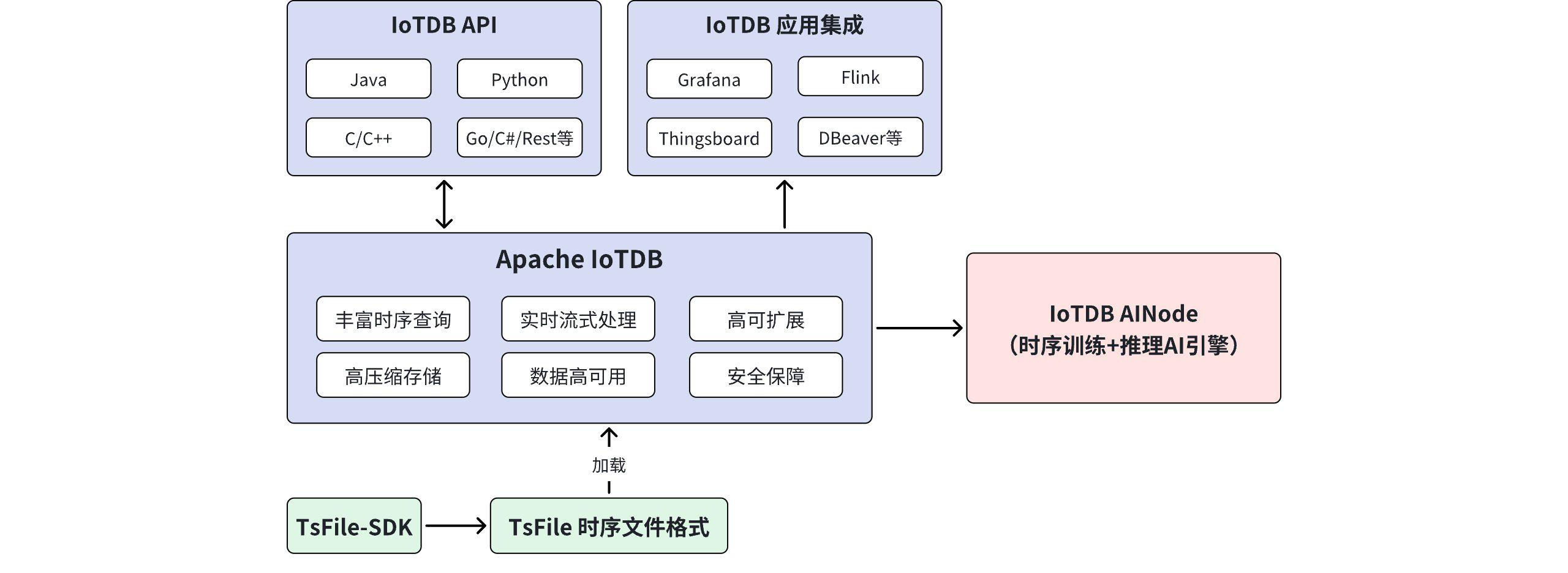
四、Apache IoTDB 的架构优势
InfluxDB 是 IT 监控时代的王者,Apache IoTDB 就是为工业物联网(IIoT)量身定制的。
Apache IoTDB 是由清华大学发起、在 Apache 基金会孵化毕业的顶级项目,IoTDB 从第一行代码开始,就摒弃传统数据库的通用包袱,完全针对工业场景进行架构重构。不只是一个数据库,更是一套完整的时序数据管理引擎。
(1)针对 InfluxDB 因 Tag 过多导致的索引爆炸问题,IoTDB 用**“树形模式”**。
- 原理: 把物理世界的层级结构直接映射为存储路径。
- 优势: 这种设计不用倒排索引。不管是 10 万台设备还是 1000 万台设备,IoTDB 只要沿着树根向下查找,路径即索引。彻底解决高基数带来的内存崩溃问题。同等硬件下,IoTDB 能支撑的设备数量级是普通 TSDB 的 10 倍以上,查询延迟也不会随着设备数量增加而剧烈波动。
(2)TsFile 存储格式:IoTDB 的底层存储引擎用了一种自研的文件格式——TsFile。可以理解为时序数据领域的 Parquet 或 ORC。
- 列式存和编码: TsFile 能根据数据类型(整数、浮点、布尔)自动选择最优的编码算法(。
- 极致压缩: 工业场景下,TsFile 的磁盘占用仅为原始数据的 1/10 甚至 1/50。对每天产生 TB 级数据的工厂,每年能节省数百万的硬盘采购成本。
- 开放生态: TsFile 是开放标准格式。Spark、Flink 等大数据引擎可以直接读取 TsFile 文件进行分析,不用经过数据库查询接口。
(3)“端-边-云”原生协同:这是 IoTDB 最具杀伤力的特性之一。工业现场网络环境不稳定,且带宽昂贵。普通的方案是“边缘端存一份,云端再存一份”,数据同步非常困难。
IoTDB 的 轻量级边缘计算 方案:
- 边缘侧: 可以在资源受限的工控机运行 IoTDB 边缘版,进行数据采集和初步清洗。
- TsFile Sync 技术: 边缘端生成的 TsFile 文件,可以用专有的同步工具,增量、压缩、断点续传地发送到云端。
- 云端: 接收数据文件并直接加载。
(4)针对乱序和低延迟优化的 LSM 引擎。IoTDB 对传统的 LSM-Tree 进行针对性改良。
- 乱序处理: 工业传感器数据经常因为网络延迟而“迟到”。IoTDB 优化内存排序和刷盘策略,能快速处理乱序写入,不会像某些数据库那样触发昂贵的重写操作。
- 极速写入: 单机即可支撑千万数据点/秒的写入吞吐。
- 丰富查询: 原生支持降采样、最新值查询、时间对齐等工业常用查询,且支持标准 SQL 语法。
五、企业级落地和服务保障
个人开发者,开源社区版或许已经足够;但对能源、轨交、制造等关乎国计民生的核心业务,企业要的不只是代码,更是确定性、安全性和兜底保障。Timecho 出生。
Timecho 成立于 2021 年,核心团队直接源自清华大学软件学院,不只是 Apache IoTDB 的发起者,更是目前拥有最多 PMC(项目管理委员会成员)和 Committer(代码提交者)的团队。
基于开源内核,Timecho 推出企业级发行版 TimechoDB(IoTDB Enterprise),针对高端场景进行大量“加固”和“增值”:
- 开源版的集群部署和运维依赖命令行,门槛较高。TimechoDB 提供全图形化的管理控制台,像操作云服务一样,轻松监控集群状态、扩缩容节点、管理存储配额。
- 工业数据是企业的核心资产。商业版补齐细粒度的RBAC 权限控制、数据加密存储、操作审计日志以及白名单机制,完全符合等保 2.0 等合规要求。
- 对金融级或国家级基础设施的高可用需求,TimechoDB 提供更强大的跨数据中心同步和双活方案,极端灾难下数据不丢、服务不停。
开源版本(获取最新技术,自行部署): https://iotdb.apache.org/zh/Download/
企业级服务和支持,企业版官网: https://timecho.com
“国产化替代”的大潮下,数据库的兼容性是硬指标。Timecho 积极响应国家信创战略,完成和国产软硬件生态的全面适配:
- 国产 CPU: 完美运行在飞腾、鲲鹏、龙芯、海光、申威等国产芯片架构。
- 国产操作系统: 跟麒麟(Kylin)、统信(UOS)、欧拉(openEuler)等操作系统深度兼容。
这种全栈式的国产化适配,让 Timecho 成为央国企、军工及关键基础设施领域进行**“去 IOE”和替换 InfluxDB** 时的首选方案。
TimechoDB 不是实验室的玩具,已经在中国最复杂的工业场景证明自己:
- 国家电网/南方电网: 管理数亿个智能电表测点,支撑电网全链路数据分析。
- 中车集团: 在复兴号高铁、地铁列车上进行车载边缘存储,实现毫秒级故障预警。
- 长安汽车: 支撑车联网平台,处理百万级车辆的高并发实时数据写入。
六、总结
不是 InfluxDB 不够优秀,而是时代变了。
- InfluxDB 属于 IT 运维监控的时代,胜在生态早、起步快。
- Apache IoTDB 属于万物互联的工业 4.0 时代,胜在懂工业、架构新、成本低。
IoTDB 不用树形模型理顺复杂的设备关系,用TsFile 把存储成本压缩到了极致,用端边云协同打通数据的任督二脉,更通过 Timecho 实现国产化信创的自主可控。
-
官方网站: https://iotdb.apache.org/ ,最新文档、下载安装包、查看 API 指南。*
-
Timecho 官网: https://www.timecho.com/


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 31
31 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)