四、python其它高级语法
本文介绍了Python中的迭代器和生成器概念。迭代器通过实现__iter__和__next__方法实现惰性加载,示例演示了自定义迭代器模拟range功能。生成器是迭代器的语法糖,通过推导式或yield关键字创建,具有内存占用小的优势(示例显示生成器仅占用192字节,而列表占用8448728字节)。此外还介绍了property属性的两种实现方式:装饰器方式(@property和@属性名.setter
目录
1、迭代器
1.1、回顾for循环
for i in 可迭代类型: print(i)可迭代类型是指那些可以被迭代(即逐个访问元素)的数据类型,内置可迭代类型有:list、tuple、str、set、dict。
除了内置的可迭代类型,你还可以通过实现 __iter__ 方法来创建自定义的可迭代对象。
1.2、迭代器介绍
概述:
自定义的类, 只要重写了 __iter__( ) 和 __next__( ) 方法, 就可以称为 迭代器。
可迭代对象和迭代器的区别:
- 可迭代对象:实现了 __iter__ 方法的对象,该方法返回一个迭代器。
- 迭代器:实现了 __iter__ 和 __next__ 方法的对象。__iter__ 方法返回迭代器本身,__next__ 方法返回下一个元素,当没有更多元素时抛出 StopIteration 异常。
目的:
- 隐藏底层的逻辑, 让用户使用更方便。
- 惰性加载, 用的时候才会获取。
1.3、示例代码
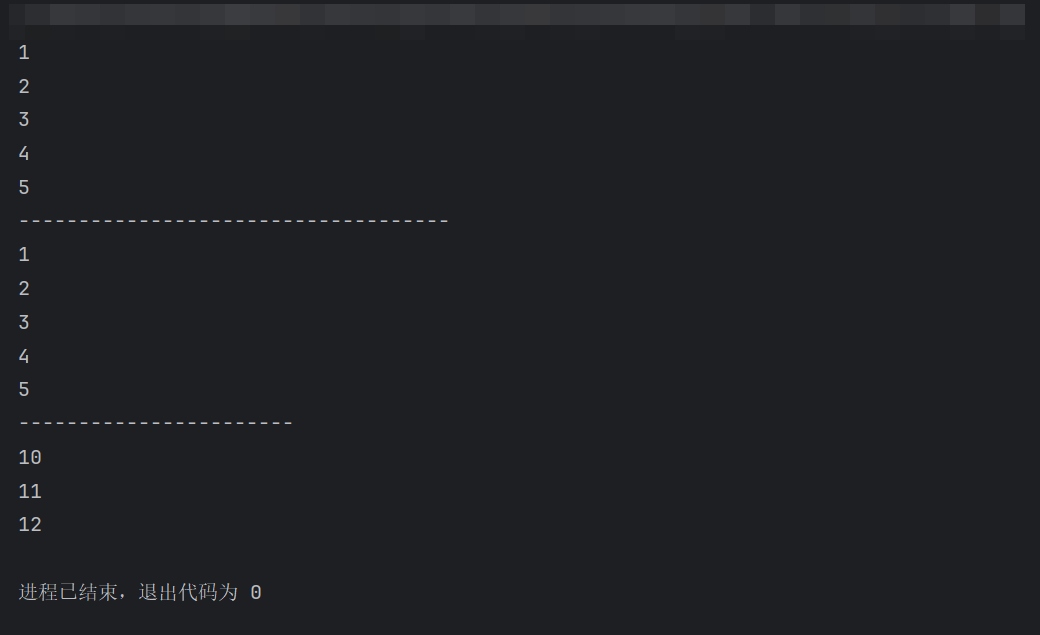
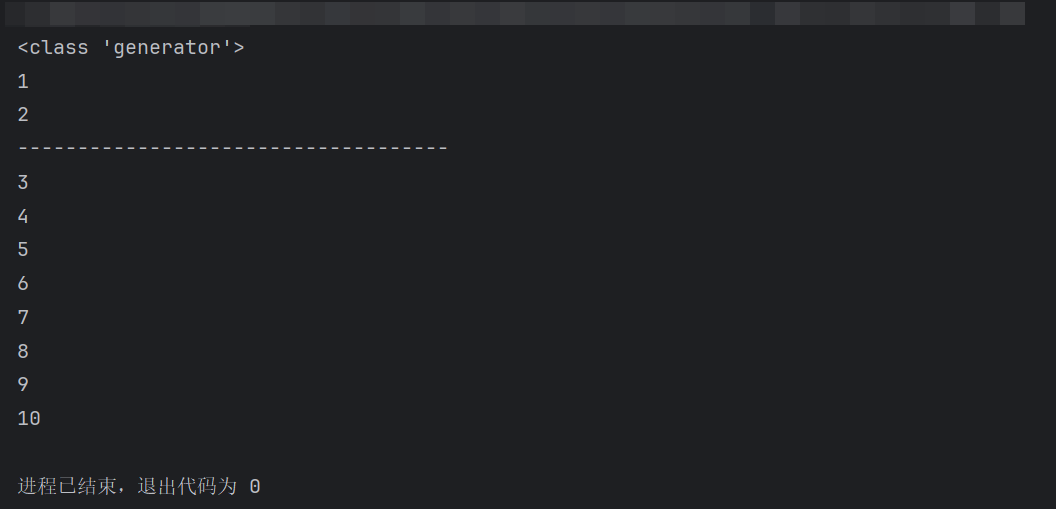
# 需求: 模拟range(1, 6), 自定义 迭代器实现同等逻辑. # 场景1: 回顾 range()用法. for i in range(1, 6): print(i) print('-' * 36) # 场景2: 自定义迭代器. # 1. 自定义 迭代器类. class MyIterator: # 2. 通过init魔法方法, 初始化属性, 指定: 范围. def __init__(self, start, end): self.current_value = start # 当前值, 默认为 开始值. self.end = end # 结束值. # 3. 重写iterator魔法方法, 返回当前对象(即: 迭代器对象). def __iter__(self): return self # 4. 重写next魔法方法, 返回当前值, 并更新当前值. def __next__(self): # 4.1 判断当前值范围是否合法. if self.current_value >= self.end: raise StopIteration # 抛出异常, 迭代结束. # 4.2 走这里, 说明当前值合法, 返回当前值, 并更新当前值. # value = self.current_value # value = 1 2 3 4 5 # self.current_value += 1 # self.current_value = 2 3 4 5 6 # return value # 1 2 3 4 5 # 效果同上, 代码更简单 self.current_value += 1 # self.current_value = 2 3 4 5 6 return self.current_value - 1 # 1 2 3 4 5 # 5. 创建迭代器对象, 并遍历. # 5.1 for循环 for i in MyIterator(1, 6): print(i) print('-' * 23) # 5.2 next()函数 my_itr = MyIterator(10, 13) print(next(my_itr)) # 10 print(next(my_itr)) # 11 print(next(my_itr)) # 12 # print(next(my_itr)) # raise StopIteration # 抛出异常, 迭代结束.
迭代器中的每个值都只能被取出来一次。
2、生成器
概念:
根据程序员制定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,可以节约大量的内存。
在 Python 中,生成器是迭代器的一个特殊子集—— 所有生成器都是迭代器,但并非所有迭代器都是生成器。两者的核心关联是都遵循迭代器协议,但生成器通过更简洁的语法实现了迭代器的核心能力(惰性求值、逐个产出数据),是迭代器的语法糖 + 功能增强版。
创建生成器的方式:
- 生成器推导式
- yield 关键字
2.1、推导式写法
推导式回顾:
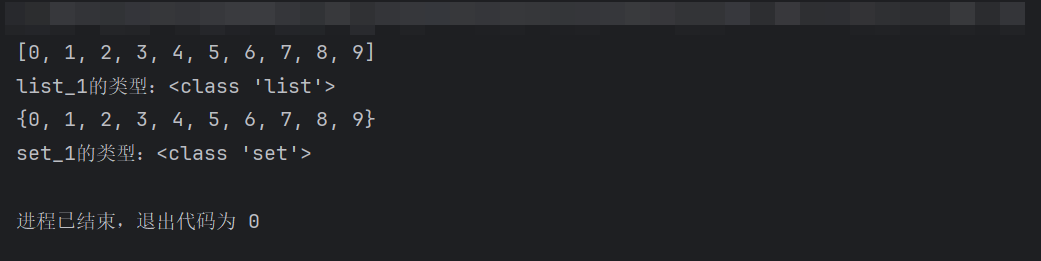
# 列表推导式 list_1 = [x for x in range(10)] print(list_1) print(f"list_1的类型:{type(list_1)}") # 集合推导式 set_1 = {x for x in range(10)} print(set_1) print(f"set_1的类型:{type(set_1)}")
# 是元组推导式吗? y = (x for x in range(10)) print(y) print(f"y的类型:{type(y)}")
这个表达式不是元组推导式。Python 中根本没有 “元组推导式” 这个语法 , (x for x in range(10)) 实际上是 生成器表达式(generator expression)

生成器(generator)推导式
语法:
(x for x in 可迭代对象 [if 条件])注意点:
# 创建生成器 # 注意1:括号()代表 这是一个生成器,不是元组 # 注意2:括号()里面写的是数据的生成规则,返回一个对象, # 对象内不是存的数据,而是产生数据的规则 my_generator = (i * 2 for i in range(5)) # 根据注意2 print(my_generator) # next获取生成器下一个值 # value = next(my_generator) # print(value) # 遍历生成器 for value in my_generator: print(value)
生成器相关函数:
- next函数获取生成器中的下一个值
- for循环遍历生成器中的每一个值
示例:
演示生成器之 推导式写法。
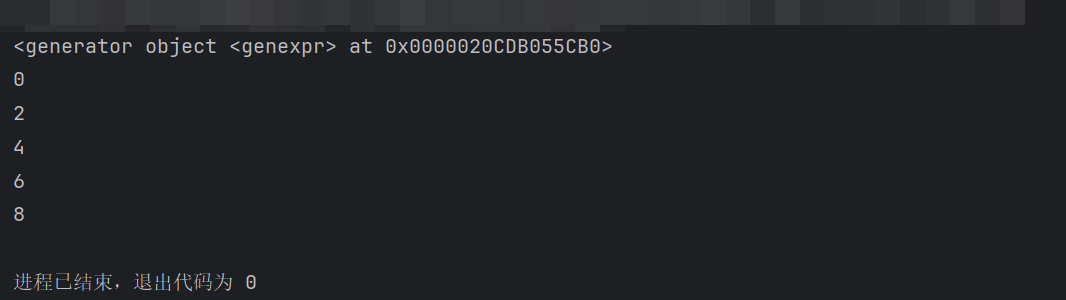
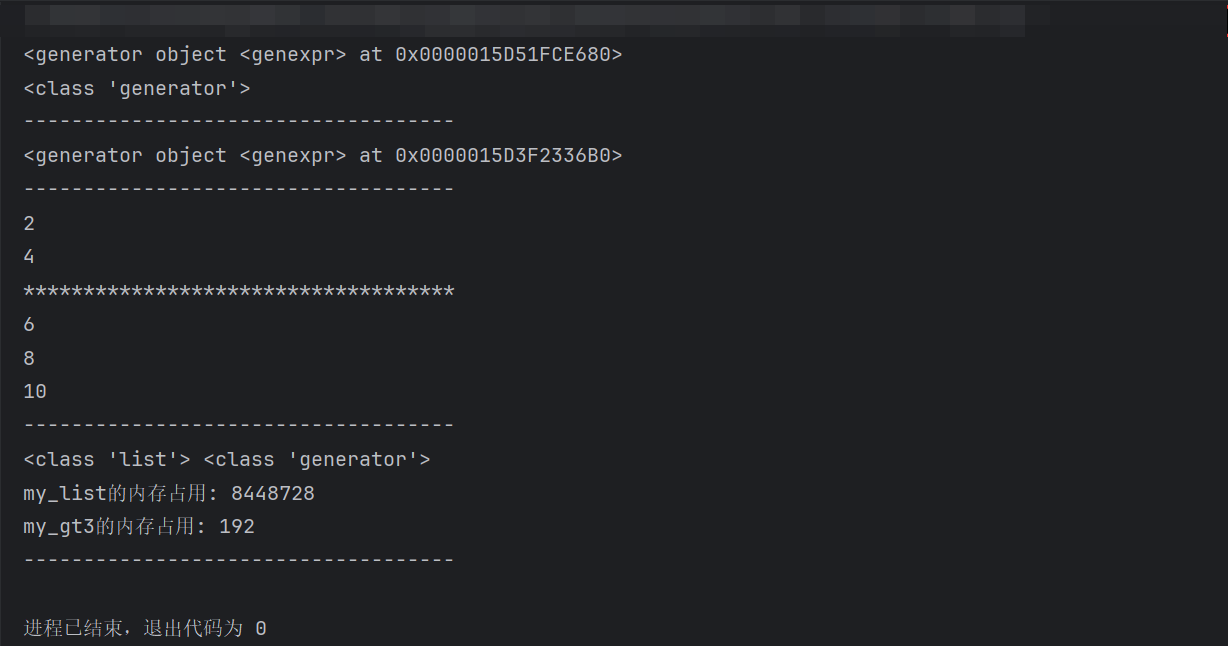
import sys # system: 系统模块 # 场景1: 生成器 推导式写法. # 需求1: 生成1 ~ 10之间的整数. my_generator = (i for i in range(1, 11)) print(my_generator) print(type(my_generator)) # <class 'generator'> print('-' * 36) # 需求2: 生成 1 ~ 10 之间的偶数. my_gt2 = (i for i in range(1, 11) if i % 2 == 0) print(my_gt2) print('-' * 36) # 需求3: 如何从生成器中获取数据. # 思路1: next() print(next(my_gt2)) # 2 print(next(my_gt2)) # 4 print('*' * 36) for i in my_gt2: print(i) # 6, 8, 10 print('-' * 36) # 验证 生成器的目的 就是可以减少内存占用. my_list = [i for i in range(1000000)] my_gt3 = (i for i in range(1000000)) print(type(my_list), type(my_gt3)) # 查看my_list的内存空间占用. print(f'my_list的内存占用: {sys.getsizeof(my_list)}') print(f'my_gt3的内存占用: {sys.getsizeof(my_gt3)}') print('-' * 36)
总结
- 内存占用:列表 my_list 占用 8448728 字节,生成器 my_gt3 仅占用 192 字节。这体现了生成器的核心优势 ——按需生成元素,大幅节省内存(列表需一次性存储所有元素,生成器仅保存 “生成规则”)。
- 生成器只能迭代一次(迭代后元素 “耗尽”),列表可多次迭代。
- 适用场景:处理百万级、甚至更大规模的数据时,生成器能避免内存溢出,适合 “流式处理”(如读取大文件、数据管道等)。
2.2、yield关键字写法
yield关键字的作用(特性):
- 将yield后面的值返回
- 在yield这个地方卡着(阻塞)
案例
演示生成器之 推导式写法。
通过yield方式, 获取到生成器之 1 ~ 10之间的整数.
# 回顾: 推导式写法. my_g = (i for i in range(1, 11)) # yield方式如下. # 1.定义函数, 存储到生成器中, 并返回. def my_fun(): # my_list = [] # 创建 # for i in range(1, 11): # my_list.append(i) # 添加 # return my_list # 返回 # 效果类似于上边的代码. # yield在这里做了三件事儿: 1.创建生成器对象. 2.把值存储到生成器中. 3.返回生成器. for i in range(1, 11): yield i # 2.测试. my_g2 = my_fun() print(type(my_g2)) # <class 'generator'> print(next(my_g2)) print(next(my_g2)) print('-' * 36) for i in my_g2: print(i)
3、Property属性
property属性的介绍:
负责把一个方法(类中的)当做属性进行使用,这样做可以简化代码使用。
定义property属性有两种方式:
- 装饰器方式
- 类属性方式
3.1、装饰器用法
property的装饰器语法:
@property # 修饰 获取值的函数 @获取值的函数名.setter # 修饰 设置(修改)值的函数之后, 就可以直接 .上述的函数名来当做变量直接用。
案例:
定义学生类, 私有属性 age, 通过property实现简化调用
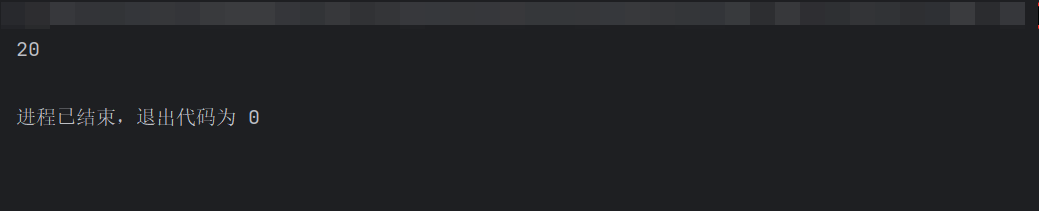
# 1. 定义学生类. class Student: # 1.1 私有属性. def __init__(self): self.__age = 18 # 1.2 提供公共的方式方式 @property def age(self): return self.__age @age.setter def age(self, age): # 可以在这里对传入的age值做判断, 但是一般不做, 重要字段才会做判断. # 因为实际开发中数据是从前端传过来的, 已经做过判断了, 这里做属于二次校验. self.__age = age # 2. 测试 if __name__ == '__main__': # 2.1 创建学生对象. s = Student() # 2.2. 设置值 s.age = 20 # 2.3 获取值 print(s.age)
注意:获取私有属性的方法要在修改私有属性的方法之前。
3.2、类属性用法
property类属性的语法:
类属性名 = property(获取值的函数名, 设置值的函数名)之后, 就可以直接 .上述的函数名 来当做变量直接用.
案例:
定义学生类, 私有 age属性, 通过property充当类属性用。
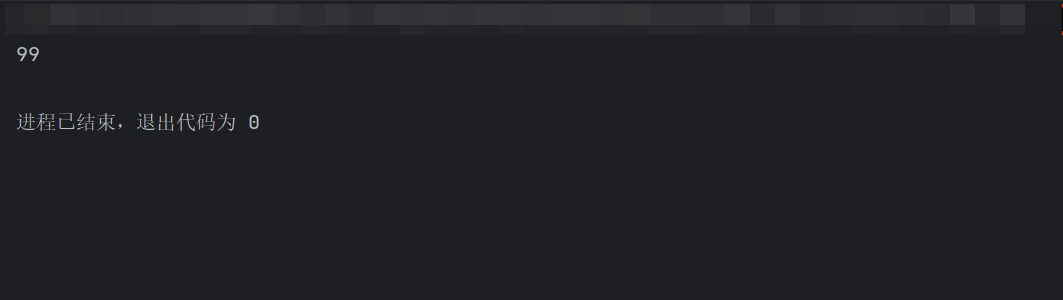
# 1. 定义学生类. class Student: # 1.1 私有age属性. def __init__(self): self.__age = 20 # 1.2 公共的访问方式. def get_age(self): return self.__age def set_age(self, age): self.__age = age # 1.3 封装上述的公共方式为 类属性 # 参1: 获取值的函数名, 参2: 设置值的函数名 age = property(get_age, set_age) # 2. 测试 if __name__ == '__main__': # 2.1 创建学生对象. s = Student() # 2.2. 设置值 s.age = 99 # 2.3 获取值 print(s.age)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)