计算机视觉·DETR
·
DETR
核心创新点
- 不需要手工设计的锚框了
- 不再需要NMS等繁琐的操作。
方法
图像特征编码
首先通过CNN+1x1卷积得到特征图,这一步是提取图像特征,同时为了减少图像token的长度。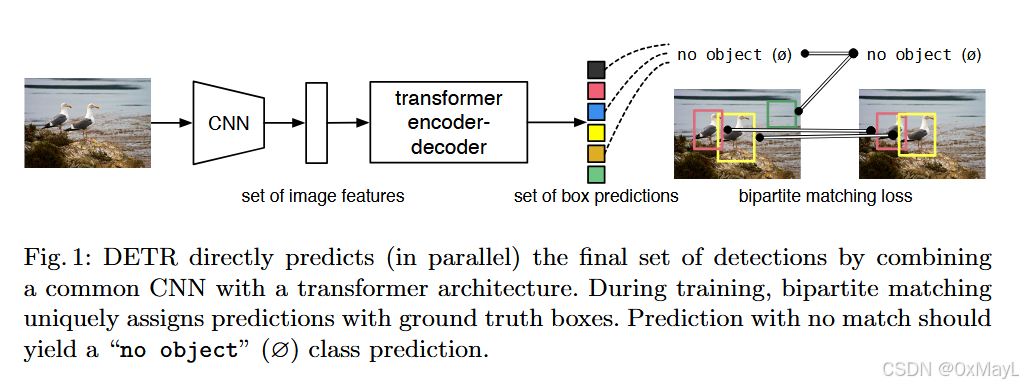
Transformer
-
DETR设计了N个可以学习的query ∈RN×D\in R^{N\times D}∈RN×D,其中N=100,表示查询的数量
-
如何理解这些查询?每一个查询都会生成一个分类和锚框,N的数量大于图像中实际存在的数量。
-
这些query向量首先经过自注意力进行交互。
-
然后作为注意力矩阵中的Q和来自图像特征(编码器输出)的Q和K进行交互。
最终输出的维度也是RN×DR^{N\times D}RN×D,这N个锚框经过FFN分别得到分类结果和锚框坐标。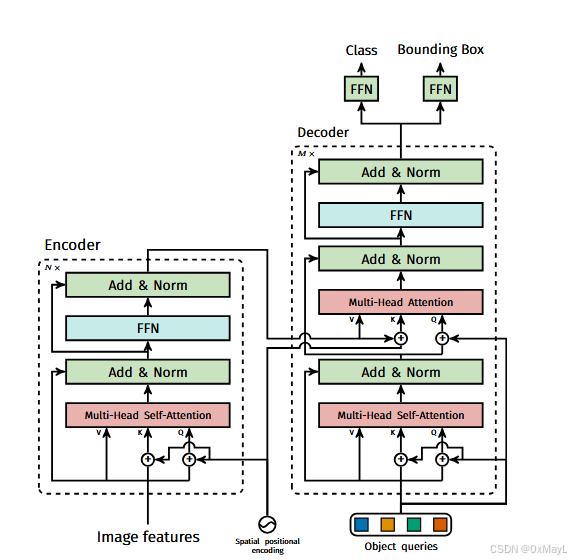
损失计算
由于N的数量肯定是大于图像中真实锚框的数量和标签集M,因此作者引入了一个No Object作为新的标签集。
就像NMS一样,作者需要减少锚框的数量。
具体来说,使用匈牙利二分图匹配算法得到生成的锚框与真实锚框之间的匹配关系,就是一个关系矩阵C∈RM×N\in R^{M\times N}∈RM×N
真实锚框一定有一个生成的锚框对应,但反之不一定。
分类和锚框损失
- 对于有与真实锚框对应关系的查询结果(准确来说是该查询向量经过transformer和FFN输出后的标签和锚框坐标),分别计算交叉熵和L1损失
- 对于没有与任何真实锚框匹配的查询结果,也需要计算分类损失,其中"真实类别"为作者引入了的No Object类别。
- 对于锚框损失,没有匹配上的查询结果不需要计算。
- 最后,只对匹配上的查结果计算GIoU 损失,用于进一步优化锚框之间的重叠程度。
总损失:N个分类损失,M个锚框和GIoU损失
前者优化预测类别,后者直接优化锚框及其重叠程度。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)