强化学习入门学习第二课 —— 基础方法 :SARSA vs Q-learning
摘要:本文深入解析强化学习中SARSA和Q-learning这对"双胞胎"算法的核心区别。SARSA采用on-policy策略,基于实际执行动作更新Q值,学习风格保守安全;Q-learning采用off-policy策略,基于最优动作更新Q值,追求理论最优解。通过悬崖行走实验对比发现:SARSA学会安全绕远路(平均奖励-20),Q-learning选择冒险捷径(平均奖励-15但
目录
导读:在强化学习的世界里,SARSA 和 Q-learning 就像一对性格迥异的双胞胎——它们有着相似的血统(都是时序差分学习),却走出了截然不同的人生道路。一个谨慎保守,一个大胆冒进。今天,让我们深入探索这两位"老朋友"的奥秘!
1. 引言:时序差分学习的两员大将
在强化学习中,智能体需要通过与环境交互来学习最优策略。时序差分(Temporal Difference, TD)学习是一种核心方法,它结合了蒙特卡洛方法的采样思想和动态规划的自举(bootstrapping)思想。
SARSA 和 Q-learning 都是基于 TD 学习的价值迭代算法,它们的目标都是学习动作价值函数 ——即在状态
下采取动作
能获得的期望累积回报。
但它们的核心区别在于:更新 Q 值时,对下一步动作的处理方式不同。
2. SARSA:说到做到的"老实人"
2.1 名字的由来
SARSA 这个名字本身就是一个绝妙的助记符:

画面感:想象一个小机器人站在迷宫入口。它先观察当前位置(S),然后决定往右走(A),获得了-1的惩罚(R),到达新位置(S'),接着它真的往前走了一步(A')。这个完整的五元组就是 SARSA 的一次学习经历!
2.2 核心公式
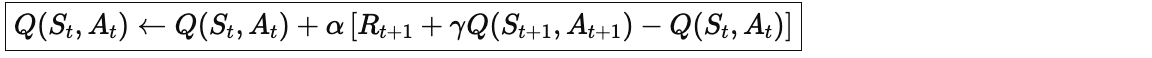
公式解读:
-
:学习率,控制新信息的接受程度(0~1)
-
:折扣因子,体现对未来奖励的重视程度(0~1)
-
:TD 目标(实际走的那一步的价值)
-
:TD 误差(惊喜程度)
2.3 关键特性:On-Policy(同策略)
SARSA 是一个On-Policy算法,这意味着:
-
它用什么策略采集数据,就用什么策略更新 Q 值
-
下一步的动作
是真实执行的动作
-
探索(如 ε-greedy)会直接影响学习结果
💡 通俗理解:SARSA 就像一个诚实的日记作者,它记录的是"我今天实际做了什么",而不是"我本应该做什么"。
3. Q-learning:心怀理想的"乐观派"
3.1 核心思想
Q-learning 由 Watkins 在 1989 年提出,是强化学习领域最重要的突破之一。它的核心思想是:即使我现在因为探索选择了次优动作,我也假设未来的自己会做出最优选择。
3.2 核心公式
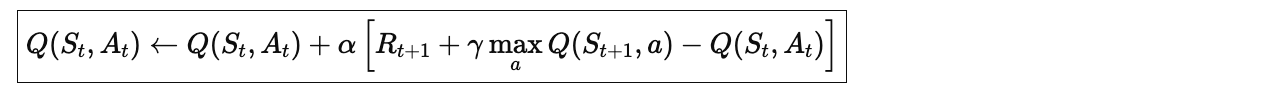
与 SARSA 的关键区别:
-
SARSA:
—— 下一步实际采取的动作的价值
-
Q-learning:
—— 下一步最优动作的价值
画面感:想象一个探险家在岔路口。左边是安全的小路,右边是危险但可能有宝藏的山洞。即使这次他因为好奇心选择了去山洞(探索),他在评估这个决定时,还是会想:"如果我下次到了山洞深处,我肯定会做出最明智的选择!"这就是 Q-learning 的乐观精神!
3.3 关键特性:Off-Policy(异策略)
Q-learning 是一个Off-Policy算法:
-
行为策略(Behavior Policy):用于探索环境、收集数据(如 ε-greedy)
-
目标策略(Target Policy):用于更新 Q 值(贪婪策略,总选 max)
-
两个策略可以不同!
💡 通俗理解:Q-learning 就像一个有两套标准的人——"我可以随便玩玩探索世界,但在评估时,我只考虑最优的可能性"。
4. 灵魂对比:一张表看懂所有差异
| 对比维度 | SARSA 🛡️ | Q-learning ⚡ |
|---|---|---|
| 策略类型 | On-Policy(同策略) | Off-Policy(异策略) |
| 更新依据 | 下一步实际执行的动作 | 下一步最优动作 |
| 公式关键项 | $Q(S_{t+1}, A_{t+1})$ | $\max_a Q(S_{t+1}, a)$ |
| 探索的影响 | 探索直接影响 Q 值更新 | 探索不影响目标策略 |
| 收敛目标 | 当前策略的 Q 值 | 最优策略的 Q 值 |
| 学习风格 | 保守、安全、考虑风险 | 激进、乐观、追求最优 |
| 适用场景 | 安全敏感、试错成本高 | 模拟环境、追求最优解 |
| 性格比喻 | 稳重的风险管理者 | 大胆的理想主义者 |
5. 代码实现:手把手带你实现
让我们用经典的悬崖行走(Cliff Walking)环境来实现并对比这两个算法!
5.1 环境介绍
环境可视化:
┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐ │ │ │ │ │ │ │ │ │ │ │ │ │ ├───┼───┼───┼───┼───┼───┼───┼───┼───┼───┼───┼───┤ │ │ │ │ │ │ │ │ │ │ │ │ │ ├───┼───┼───┼───┼───┼───┼───┼───┼───┼───┼───┼───┤ │ │ │ │ │ │ │ │ │ │ │ │ │ ├───┼───┼───┼───┼───┼───┼───┼───┼───┼───┼───┼───┤ │ S │ C │ C │ C │ C │ C │ C │ C │ C │ C │ C │ G │ └───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘ S = 起点 | G = 终点 | C = 悬崖(掉下去回到起点,奖励-100) 普通移动奖励:-1
5.2 完整代码实现
import numpy as np
import matplotlib.pyplot as plt
from collections import defaultdict
# ==================== 环境定义 ====================
class CliffWalkingEnv:
"""悬崖行走环境"""
def __init__(self):
self.rows = 4
self.cols = 12
self.start = (3, 0) # 左下角起点
self.goal = (3, 11) # 右下角终点
self.cliff = [(3, i) for i in range(1, 11)] # 悬崖位置
self.state = self.start
# 动作:上(0)、右(1)、下(2)、左(3)
self.actions = [(-1, 0), (0, 1), (1, 0), (0, -1)]
self.action_names = ['↑', '→', '↓', '←']
def reset(self):
"""重置环境"""
self.state = self.start
return self.state
def step(self, action):
"""执行动作,返回 (下一状态, 奖励, 是否结束)"""
row, col = self.state
d_row, d_col = self.actions[action]
# 计算新位置(边界检查)
new_row = max(0, min(self.rows - 1, row + d_row))
new_col = max(0, min(self.cols - 1, col + d_col))
new_state = (new_row, new_col)
# 判断奖励和是否结束
if new_state in self.cliff:
# 掉下悬崖!回到起点,大惩罚
return self.start, -100, False
elif new_state == self.goal:
# 到达终点!
return new_state, -1, True
else:
# 普通移动
self.state = new_state
return new_state, -1, False
# ==================== ε-greedy 策略 ====================
def epsilon_greedy(Q, state, epsilon, n_actions=4):
"""ε-贪婪策略选择动作"""
if np.random.random() < epsilon:
return np.random.randint(n_actions) # 随机探索
else:
# 贪婪选择(如有多个最大值,随机选一个)
q_values = [Q[(state, a)] for a in range(n_actions)]
max_q = max(q_values)
best_actions = [a for a in range(n_actions) if q_values[a] == max_q]
return np.random.choice(best_actions)
# ==================== SARSA 算法 ====================
def sarsa(env, episodes=500, alpha=0.1, gamma=0.99, epsilon=0.1):
"""
SARSA: State-Action-Reward-State-Action
On-Policy TD Control
"""
Q = defaultdict(float) # Q表初始化为0
rewards_per_episode = []
for episode in range(episodes):
state = env.reset()
action = epsilon_greedy(Q, state, epsilon) # 选择初始动作
total_reward = 0
while True:
# 执行动作
next_state, reward, done = env.step(action)
total_reward += reward
# 🌟 SARSA 核心:选择下一个实际要执行的动作
next_action = epsilon_greedy(Q, next_state, epsilon)
# 🌟 更新 Q 值(使用实际的 next_action)
td_target = reward + gamma * Q[(next_state, next_action)] * (1 - done)
td_error = td_target - Q[(state, action)]
Q[(state, action)] += alpha * td_error
if done:
break
# 转移到下一步
state = next_state
action = next_action # 🌟 实际执行这个动作
rewards_per_episode.append(total_reward)
return Q, rewards_per_episode
# ==================== Q-learning 算法 ====================
def q_learning(env, episodes=500, alpha=0.1, gamma=0.99, epsilon=0.1):
"""
Q-learning: Off-Policy TD Control
"""
Q = defaultdict(float)
rewards_per_episode = []
for episode in range(episodes):
state = env.reset()
total_reward = 0
while True:
# 用 ε-greedy 选择动作(行为策略)
action = epsilon_greedy(Q, state, epsilon)
# 执行动作
next_state, reward, done = env.step(action)
total_reward += reward
# 🌟 Q-learning 核心:使用 max Q 值更新
max_next_q = max([Q[(next_state, a)] for a in range(4)]) if not done else 0
# 🌟 更新 Q 值(使用最优动作的 Q 值)
td_target = reward + gamma * max_next_q
td_error = td_target - Q[(state, action)]
Q[(state, action)] += alpha * td_error
if done:
break
state = next_state
rewards_per_episode.append(total_reward)
return Q, rewards_per_episode
# ==================== 可视化函数 ====================
def visualize_policy(Q, env, title):
"""可视化学习到的策略"""
policy_grid = np.empty((env.rows, env.cols), dtype=str)
for row in range(env.rows):
for col in range(env.cols):
state = (row, col)
if state == env.goal:
policy_grid[row, col] = 'G'
elif state in env.cliff:
policy_grid[row, col] = 'X'
elif state == env.start:
q_values = [Q[(state, a)] for a in range(4)]
best_action = np.argmax(q_values)
policy_grid[row, col] = 'S' + env.action_names[best_action]
else:
q_values = [Q[(state, a)] for a in range(4)]
best_action = np.argmax(q_values)
policy_grid[row, col] = env.action_names[best_action]
print(f"\n{'='*40}")
print(f" {title}")
print('='*40)
for row in policy_grid:
print(' | '.join(f'{cell:^3}' for cell in row))
print('='*40)
def plot_rewards(sarsa_rewards, ql_rewards, window=10):
"""绘制学习曲线对比图"""
def smooth(data, window):
return np.convolve(data, np.ones(window)/window, mode='valid')
plt.figure(figsize=(12, 5))
# 原始曲线(透明)
plt.plot(sarsa_rewards, alpha=0.3, color='blue')
plt.plot(ql_rewards, alpha=0.3, color='red')
# 平滑曲线
plt.plot(smooth(sarsa_rewards, window), color='blue',
linewidth=2, label='SARSA')
plt.plot(smooth(ql_rewards, window), color='red',
linewidth=2, label='Q-learning')
plt.xlabel('Episode', fontsize=12)
plt.ylabel('Total Reward', fontsize=12)
plt.title('SARSA vs Q-learning: Learning Curve Comparison', fontsize=14)
plt.legend(fontsize=11)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# ==================== 主程序 ====================
if __name__ == "__main__":
# 创建环境
env = CliffWalkingEnv()
# 训练两个算法
print("🚀 Training SARSA...")
Q_sarsa, rewards_sarsa = sarsa(env, episodes=500)
print("🚀 Training Q-learning...")
env_ql = CliffWalkingEnv() # 新环境实例
Q_ql, rewards_ql = q_learning(env_ql, episodes=500)
# 可视化策略
visualize_policy(Q_sarsa, env, "SARSA Learned Policy (Safe Path)")
visualize_policy(Q_ql, env, "Q-learning Learned Policy (Optimal Path)")
# 绘制学习曲线
plot_rewards(rewards_sarsa, rewards_ql)
# 打印统计信息
print(f"\n📊 Final 50 Episodes Average Reward:")
print(f" SARSA: {np.mean(rewards_sarsa[-50:]):.2f}")
print(f" Q-learning: {np.mean(rewards_ql[-50:]):.2f}")
6. 实验结果分析:殊途同归?不!
6.1 学习到的策略对比
SARSA 学习到的路径:
→ → → → → → → → → → → ↓ ↑ → → → → → → → → → → ↓ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ → ↓ S X X X X X X X X X X G特点:绕远路!SARSA 学会了沿着上方安全通道走,远离悬崖。虽然路径更长(约15步),但几乎不会掉下悬崖。
🎨 Q-learning 学习到的路径:
→ → → → → → → → → → → ↓ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↓ ↑ → → → → → → → → → → ↓ S X X X X X X X X X X G特点:贴着悬崖走!Q-learning 学到了理论最短路径(约13步),但由于 ε-greedy 探索,实际执行时经常掉下悬崖。
6.2 学习曲线解读
学习曲线图描述:
想象一张折线图,横轴是训练回合数(0-500),纵轴是每回合的累计奖励(-100 到 0)。
蓝色线(SARSA):波动较小,稳定在 -20 左右。曲线平滑,像一条宁静的河流。
红色线(Q-learning):频繁出现 -100 的尖峰(掉悬崖了!),但整体均值更高(约 -15)。曲线剧烈波动,像心电图一样刺激。
关键洞察:
-
Q-learning 的期望奖励更高(因为学到了最优路径)
-
但 Q-learning 的方差更大(经常掉悬崖)
-
SARSA 更稳定可靠,适合风险敏感场景
6.3 为什么会这样?
数学解释:
对于 SARSA,更新时考虑的是实际会执行的动作。在悬崖边,由于 ε-greedy 策略有 10% 概率随机选择动作,可能会选择"向下走"掉下悬崖。SARSA 把这个风险算进了 Q 值,所以悬崖边的状态 Q 值会变低,策略会倾向于远离悬崖。
对于 Q-learning,更新时考虑的是最优动作(向右走)。即使实际可能掉下悬崖,它在评估时忽略了这个风险,认为"我下次肯定会做最优选择"。所以悬崖边的 Q 值保持较高,策略会"无畏地"贴着悬崖走。
人生哲理:SARSA 像一个经历过社会毒打的中年人,知道"理想很丰满,现实很骨感";Q-learning 像一个初出茅庐的年轻人,坚信"我命由我不由天"!
7. 算法选择指南:什么时候用谁?
7.1 选择 SARSA 的场景
-
机器人控制:真实机器人摔倒成本很高
-
自动驾驶:不能假设"下次一定会刹车成功"
-
医疗决策:试错成本是人命
-
金融交易:探索性交易也要纳入风险评估
口诀:安全第一,稳中求进
7.2 选择 Q-learning 的场景
-
游戏 AI:模拟环境,可以无限重来
-
离线学习:已有数据集,无法控制数据收集策略
-
追求最优解:需要找到理论最优策略
-
策略评估:用次优策略收集数据,评估最优策略
💡 口诀:追求极致,勇往直前
8. 进阶思考:超越 SARSA 和 Q-learning
8.1 Expected SARSA
一个折中方案,介于 SARSA 和 Q-learning 之间:
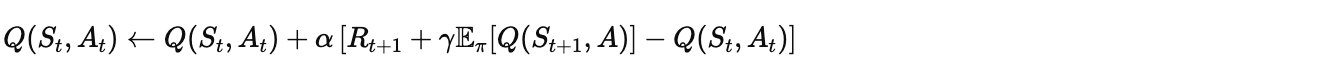
其中期望值为:

8.2 Double Q-learning
解决 Q-learning 的过估计问题,使用两个 Q 表交替更新。
8.3 深度强化学习
将 Q 表替换为深度神经网络,就诞生了 DQN 和它的各种变体!
9. 总结:一图胜千言

结语 ✨
SARSA 和 Q-learning 没有绝对的优劣之分,它们代表了强化学习中两种不同的哲学:
-
SARSA 告诉我们:"要根据自己的实际能力来评估价值,不要好高骛远。"
-
Q-learning 告诉我们:"要相信自己的潜力,永远朝着最优目标前进。"
作为强化学习的基石算法,理解它们的区别和本质,是迈向深度强化学习的重要一步。希望这篇文章能够帮助你彻底搞懂这对"双胞胎"!
如果这篇文章对你有帮助,别忘了点赞收藏哦! 👍⭐
有任何问题欢迎在评论区留言讨论~ 💬

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)