基于深度强化学习的混合动力汽车能量管理策略探索
基于深度强化学习的混合动力汽车能量管理策略 1.利用DQN算法控制电池和发动机发电机组的功率分配 2.状态量为需求功率和SOC,控制量为EGS功率 3.奖励函数设置为等效油耗和SOC维持 4.可以将DQN换成DDPG或者TD3
在混合动力汽车领域,如何高效地管理能量,实现发动机和电池之间的功率合理分配,一直是研究的热点。深度强化学习技术为这一问题的解决提供了新的思路,今天咱们就来唠唠基于深度强化学习的混合动力汽车能量管理策略,尤其是其中用得较多的一些算法。
DQN算法实现功率分配
咱们先来说说DQN(Deep Q - Network)算法,它在混合动力汽车能量管理里,主要负责控制电池和发动机发电机组的功率分配。
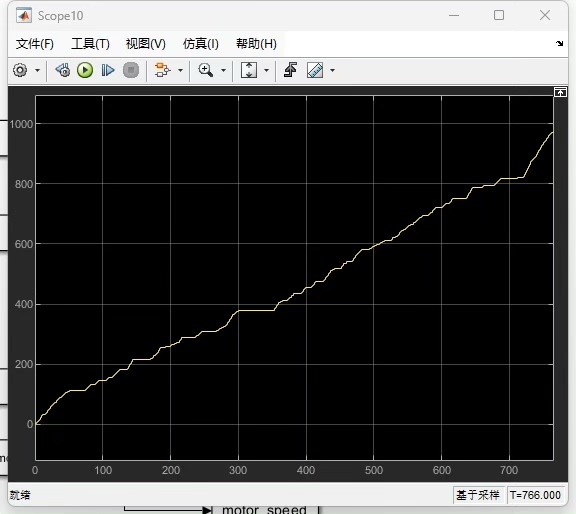
首先,明确一下状态量和控制量。这里状态量选取了需求功率和SOC(State of Charge,电池荷电状态) 。为啥选这俩呢?需求功率反映了汽车当前行驶所需要的能量,而SOC体现了电池当前的电量情况,这两个量能很好地刻画汽车的能量状态。控制量则设为EGS(这里假设是发动机发电机组相关的一个功率控制量)功率。
下面咱看看简单的代码示例(以Python和PyTorch为例,代码仅为示意,实际应用需更多完善):
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
# 定义Q网络
class QNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(QNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_size)
def forward(self, state):
x = torch.relu(self.fc1(state))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# DQN训练过程
def dqn_train(env, state_size, action_size, gamma=0.99, lr=0.001, num_episodes=1000):
q_network = QNetwork(state_size, action_size)
target_network = QNetwork(state_size, action_size)
optimizer = optim.Adam(q_network.parameters(), lr=lr)
criterion = nn.MSELoss()
for episode in range(num_episodes):
state = env.reset()
state = torch.FloatTensor(state).unsqueeze(0)
done = False
while not done:
# 这里简单采用epsilon - greedy策略选动作
epsilon = 0.1
if np.random.rand() < epsilon:
action = np.random.randint(0, action_size)
else:
q_values = q_network(state)
action = torch.argmax(q_values).item()
next_state, reward, done, _ = env.step(action)
next_state = torch.FloatTensor(next_state).unsqueeze(0)
reward = torch.FloatTensor([reward])
with torch.no_grad():
target_q = target_network(next_state)
max_target_q = torch.max(target_q)
target = reward + gamma * max_target_q
q_value = q_network(state)[0][action]
loss = criterion(q_value, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
state = next_state这段代码里,先定义了一个Q网络,它接收状态量作为输入,输出每个动作对应的Q值。在训练过程中,通过不断与环境交互,根据当前状态选择动作,获取奖励和下一个状态,然后更新Q网络的参数,让Q值能更好地指导动作选择。
奖励函数设计
奖励函数在深度强化学习里可是关键一环。在这里,咱们把奖励函数设置为等效油耗和SOC维持。等效油耗反映了汽车能源利用的经济性,SOC维持则保证电池电量能稳定在一个合理范围,避免过充或过放。比如简单的奖励函数计算(代码示意):
def calculate_reward(current_soc, previous_soc, fuel_consumption):
# 假设目标SOC范围在0.4到0.6之间
soc_reward = -abs(current_soc - 0.5)
fuel_reward = -fuel_consumption
return soc_reward + fuel_reward这样设计的奖励函数,促使智能体在决策时既要考虑降低油耗,又要维持合适的SOC。
算法替换:DDPG与TD3
除了DQN,其实还可以将其换成DDPG(Deep Deterministic Policy Gradient)或者TD3(Twin Delayed DDPG) 。
DDPG是基于策略梯度的算法,与DQN不同,它输出的是确定性的动作,而不是像DQN那样从Q值中选动作。它有两个网络,一个是策略网络(Actor)用于输出动作,另一个是价值网络(Critic)用于评估动作价值。
TD3则是在DDPG基础上的改进。TD3引入了两个Critic网络,取两个Q值中的最小值来计算目标Q值,这样可以减少过估计问题。同时,TD3还采用了延迟更新策略,减少策略网络的更新频率,提高算法稳定性。
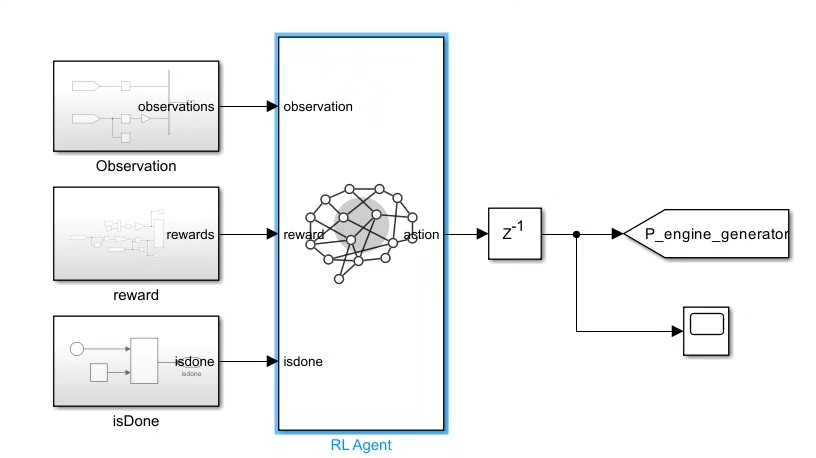
比如DDPG的简单代码框架(同样以Python和PyTorch为例):
# 定义Actor网络
class Actor(nn.Module):
def __init__(self, state_size, action_size):
super(Actor, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_size)
self.tanh = nn.Tanh()
def forward(self, state):
x = torch.relu(self.fc1(state))
x = torch.relu(self.fc2(x))
return self.tanh(self.fc3(x))
# 定义Critic网络
class Critic(nn.Module):
def __init__(self, state_size, action_size):
super(Critic, self).__init__()
self.fc1 = nn.Linear(state_size + action_size, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, 1)
def forward(self, state, action):
x = torch.cat([state, action], dim=1)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# DDPG训练过程
def ddpg_train(env, state_size, action_size, gamma=0.99, tau=0.001, actor_lr=0.0001, critic_lr=0.001, num_episodes=1000):
actor = Actor(state_size, action_size)
target_actor = Actor(state_size, action_size)
critic = Critic(state_size, action_size)
target_critic = Critic(state_size, action_size)
actor_optimizer = optim.Adam(actor.parameters(), lr=actor_lr)
critic_optimizer = optim.Adam(critic.parameters(), lr=critic_lr)
for episode in range(num_episodes):
state = env.reset()
state = torch.FloatTensor(state).unsqueeze(0)
done = False
while not done:
action = actor(state)
# 这里可添加噪声用于探索
action = action + torch.randn_like(action) * 0.1
action = torch.clamp(action, -1, 1)
next_state, reward, done, _ = env.step(action.detach().numpy()[0])
next_state = torch.FloatTensor(next_state).unsqueeze(0)
reward = torch.FloatTensor([reward])
with torch.no_grad():
target_action = target_actor(next_state)
target_q = target_critic(next_state, target_action)
target = reward + gamma * target_q
current_q = critic(state, action)
critic_loss = nn.MSELoss()(current_q, target)
critic_optimizer.zero_grad()
critic_loss.backward()
critic_optimizer.step()
actor_loss = -critic(state, actor(state)).mean()
actor_optimizer.zero_grad()
actor_loss.backward()
actor_optimizer.step()
for target_param, param in zip(target_actor.parameters(), actor.parameters()):
target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)
for target_param, param in zip(target_critic.parameters(), critic.parameters()):
target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)
state = next_state这段DDPG代码,通过Actor网络生成动作,Critic网络评估动作价值,不断更新两个网络的参数,使Actor能生成更好的动作。
总的来说,基于深度强化学习的这些算法为混合动力汽车能量管理策略提供了灵活且有效的解决方案,不同算法各有优劣,在实际应用中可以根据具体场景和需求选择合适的算法来优化混合动力汽车的能量管理。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)