TensorFlow(深度学习框架)(吴恩达深度学习笔记)
·
目录
1.TensorFlow(深度学习框架)
(1)介绍
- 深度学习编程框架(deep learning programming frameworks),可以帮助你实现神经网络模型。TensorFlow就是其中之一,它基本涵盖了所有的反向传播,你只需要定义正向传播 过程,使用TensorFlow的编程风格 就可以快速实现模型训练。
(2)示例
import numpy as np
import tensorflow as tf
# 用tf.Variable()来定义训练参数
w = tf.Variable(0,dtype = tf.float32)
# 定义损失函数: J(w)=w² - 10w +25
cost = w**2 - 10w +2 5
# 使用一般梯度下降法(也可以选择Adam……),学习率设为0.01,目的时最小化cost:
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
# 定义全局变量(w, b……)的初始化
init = tf.global_variables_initializer()
# 最后下面的几行是惯用表达式(TensorFlow风格):
# 开启了一个TensorFlow session。
session = tf.Sessions()
session.run(init)
# 现在让我们输入:
session.run(train)
# 它所做的就是运行一步梯度下降法。
# 接下来在运行了一步梯度下降法后,让我们评估一下w的值,再print:
print(session.run(w))
# 现在我们运行梯度下降1000次迭代:
for i in range(1000):
session.run(train)
print(session.run(w))
# session 最后要关闭
session.close()
(3)语法
- 占位符(placeholders)。
- 占位符是一个对象,它的值只能在稍后指定,要指定占位符的值,可以使用一个feed字典(feed_dict变量)来传入。
# 创建占位符变量,指定类型和名字
x = tf.placeholder(tf.int64, name="x")
print(sess.run(2 * x,feed_dict={x:3}))
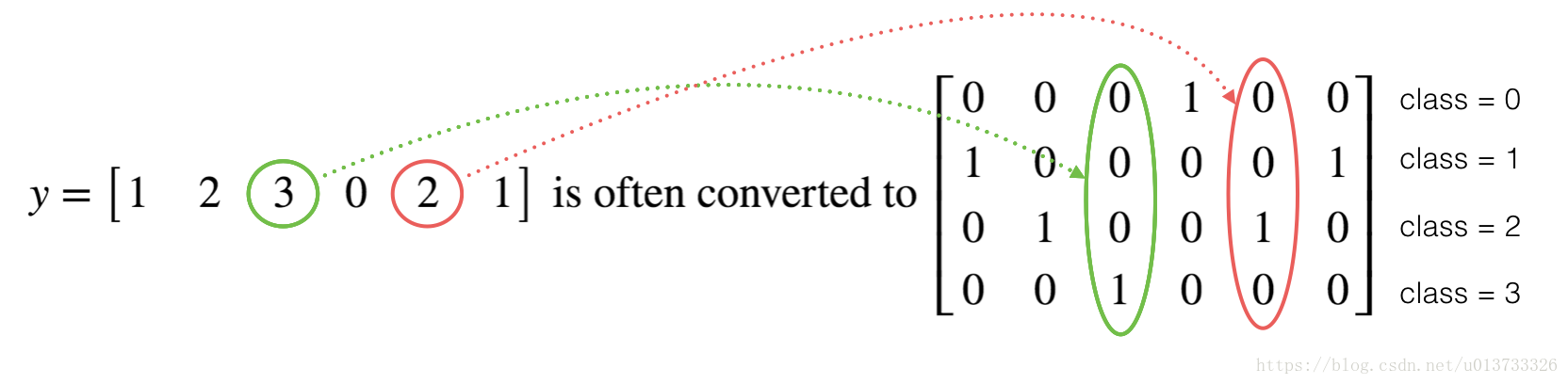
- 独热编码(0、1编码)
- 很多时候在深度学习中 y 向量的维度是从 0 到 C−1 的,C是指分类的类别数量,如果C = 4,那么对y 而言你可能需要有以下的转换方式:
(4)训练过程示例
-
分类手势图片:0,1,2,3,4,5

-
训练集样本数 = 1080,测试集样本数 = 120
X_train.shape: (12288, 1080) Y_train.shape: (6, 1080)
X_test.shape: (12288, 120) Y_test.shape: (6, 120) -
初始化神经网络的参数
def initialize_parameters():
"""
初始化神经网络的参数,参数的维度如下:
W1 : [25, 12288]
b1 : [25, 1]
W2 : [12, 25]
b2 : [12, 1]
W3 : [6, 12]
b3 : [6, 1]
返回:
parameters - 包含了W和b的字典
"""
tf.set_random_seed(1) #指定随机种子
W1 = tf.get_variable("W1",[25,12288],initializer=tf.contrib.layers.xavier_initializer(seed=1))
b1 = tf.get_variable("b1",[25,1],initializer=tf.zeros_initializer())
W2 = tf.get_variable("W2", [12, 25], initializer = tf.contrib.layers.xavier_initializer(seed=1))
b2 = tf.get_variable("b2", [12, 1], initializer = tf.zeros_initializer())
W3 = tf.get_variable("W3", [6, 12], initializer = tf.contrib.layers.xavier_initializer(seed=1))
b3 = tf.get_variable("b3", [6, 1], initializer = tf.zeros_initializer())
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2,
"W3": W3,
"b3": b3}
return parameters
- 创建占位符
def create_placeholders(n_x, n_y):
"""
为TensorFlow会话创建占位符
参数:
n_x - 一个实数,图片向量的大小(64*64*3 = 12288)
n_y - 一个实数,分类数(从0到5,所以n_y = 6)
返回:
X - 一个数据输入的占位符,维度为[n_x, None],dtype = "float"
Y - 一个对应输入的标签的占位符,维度为[n_Y,None],dtype = "float"
提示:
使用None,因为它让我们可以灵活处理占位符提供的样本数量。
"""
X = tf.placeholder(tf.float32, [n_x, None], name="X")
Y = tf.placeholder(tf.float32, [n_y, None], name="Y")
return X, Y
- 正向传播
def forward_propagation(X, parameters):
"""
正向传播:LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SOFTMAX
参数:
X - 输入数据的占位符,维度为(输入节点数量,样本数量)
parameters - 包含了W和b的参数的字典
返回:
Z3 - 最后一个LINEAR节点的输出
"""
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
W3 = parameters['W3']
b3 = parameters['b3']
Z1 = tf.matmul(W1,X) + b1 # Z1 = np.dot(W1, X) + b1
A1 = tf.nn.relu(Z1) # A1 = relu(Z1)
Z2 = tf.add(tf.matmul(W2, A1), b2) # Z2 = np.dot(W2, a1) + b2
A2 = tf.nn.relu(Z2) # A2 = relu(Z2)
Z3 = tf.add(tf.matmul(W3, A2), b3) # Z3 = np.dot(W3,Z2) + b3
return Z3
# 成本函数
def compute_cost(Z3, Y):
"""
参数:
Z3 - 前向传播的结果
Y - 标签,一个占位符,和Z3的维度相同
返回:
cost - 成本值
"""
logits = tf.transpose(Z3) # 转置
labels = tf.transpose(Y) # 转置
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels))
return cost
- 构建模型
def model(X_train, Y_train, X_test, Y_test,
learning_rate=0.0001, num_epochs=100, minibatch_size=32,
print_cost=True, is_plot=True):
"""
参数:
X_train - 训练集,维度为(输入大小= 12288, 样本数量 = 1080)
Y_train - 训练集分类数量,维度为(输出大小 = 6, 样本数量 = 1080)
X_test - 测试集,维度为(输入大小 = 12288, 样本数量 = 120)
Y_test - 测试集分类数量,维度为(输出大小 = 6, 样本数量 = 120)
learning_rate - 学习速率
num_epochs - 整个训练集的遍历次数
mini_batch_size - 每个小批量数据集的大小
print_cost - 是否打印成本,每100代打印一次
is_plot - 是否绘制曲线图
返回:
parameters - 学习后的参数
"""
ops.reset_default_graph() # 能够重新运行模型而不覆盖tf变量
tf.set_random_seed(1)
seed = 3
(n_x , m) = X_train.shape # 获取输入节点数量和样本数
n_y = Y_train.shape[0] # 获取输出节点数量
costs = [] # 成本集
# 给X和Y创建placeholder
X,Y = create_placeholders(n_x,n_y)
# 初始化参数
parameters = initialize_parameters()
# 前向传播
Z3 = forward_propagation(X,parameters)
# 计算成本
cost = compute_cost(Z3,Y)
# 反向传播,使用Adam优化
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
# 初始化所有的变量
init = tf.global_variables_initializer()
# 开始会话并计算
with tf.Session() as sess:
# 初始化
sess.run(init)
# 正常训练的循环
for epoch in range(num_epochs):
epoch_cost = 0 # 每代的成本
num_minibatches = int(m / minibatch_size) # minibatch的总数量
seed = seed + 1
minibatches = tf_utils.random_mini_batches(X_train, Y_train, minibatch_size,seed)
for minibatch in minibatches:
# 选择一个minibatch
(minibatch_X, minibatch_Y) = minibatch
# 数据已经准备好了,开始运行session
_ , minibatch_cost = sess.run([optimizer,cost],feed_dict={X:minibatch_X,Y:minibatch_Y})
# 计算这个minibatch在这一代中所占的误差
epoch_cost = epoch_cost + minibatch_cost / num_minibatches
# 记录并打印成本
# 记录成本
if epoch % 5 == 0:
costs.append(epoch_cost)
# 是否打印:
if print_cost and epoch % 20 == 0:
print("epoch = " + str(epoch) + " epoch_cost = " + str(epoch_cost))
# 保存学习后的参数
parameters = sess.run(parameters)
print("参数已经保存到session。")
# 计算当前的预测结果
correct_prediction = tf.equal(tf.argmax(Z3),tf.argmax(Y))
# 计算准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction,"float"))
print("训练集的准确率:", accuracy.eval({X: X_train, Y: Y_train}))
print("测试集的准确率:", accuracy.eval({X: X_test, Y: Y_test}))
return parameters

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)