抖音电商数据分析
一、项目整体框架
1. 数据来源
- 数据集:抖音电商用户特征_数据集-阿里云天池
- 工具环境:Pyhon(Jupyter Notebook)
2. 项目背景与目标
基于抖音电商用户数据,通过 Python对数据进行清洗和预处理,运用SQL 对用户分层体系(RFM × 生命周期)和行为特征进行精细化分析,并结合用户画像,助力运营决策。
关键业务问题:
1.量化用户价值和流失风险
2.动态划分用户生命周期阶段及对应规模和价值
3.挖掘不同层级用户在人口属性、消费习惯、兴趣偏好上的差异
4.为提高留存、转化与挽回提供差异化策略
3. 数据字段及说明
|
字段名 |
说明 |
|
User_ID |
用户唯一标识 |
|
Age |
用户年龄 |
|
Gender |
用户性别 |
|
Location |
地区(郊区Suburban / 农村Rural / 城市Urban) |
|
Income |
收入水平 |
|
Interests |
兴趣标签,如Sports、Food等 |
|
Last_Login_Days_Ago |
距离最后一次登录的天数 |
|
Purchase_Frequency |
购买频次 |
|
Average_Order_Value |
平均客单价 |
|
Total_Spending |
总消费金额 |
|
Product_Category_Preference |
产品品类偏好,如Apparel、Electronics |
二. 技术栈
1.数据清洗和主表搭建:Python(pandas)
2.数据处理和建表查询:Mysql
3.数据分析可视化:Tableau
三.数据清洗与主表搭建
首先导入必要的数据库并读取表格,检查表格数据。
import pandas as pd
import numpy as np
df = pd.read_csv('user_personalized_features.csv') #读取csv格式文件
df #检查数据
观察表格,可以看到前三列字段属于无效字段,予以删除;User_ID字段数据多余前缀#删去。
df = df.drop(columns=df.columns[[0,1]]) #删除前两列无效值
df['User_ID'] = df['User_ID'].str.lstrip('#') #去掉前缀
df #检查数据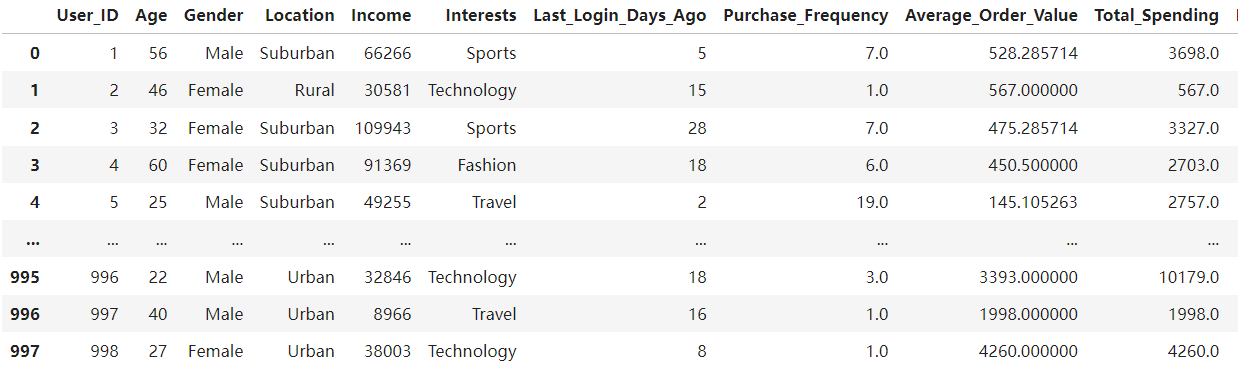
可以看到数据修改成功。
df.info()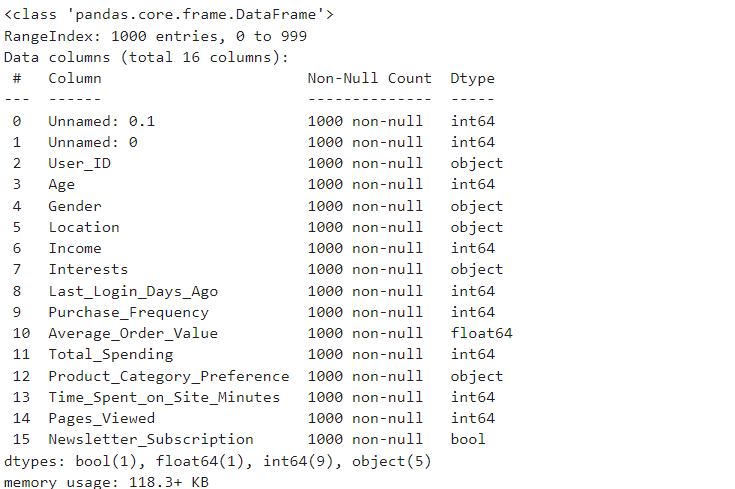
可以看出无null值,但个别字段类型需要修改。
接下来查看详细的数值型字段描述。
df.describe()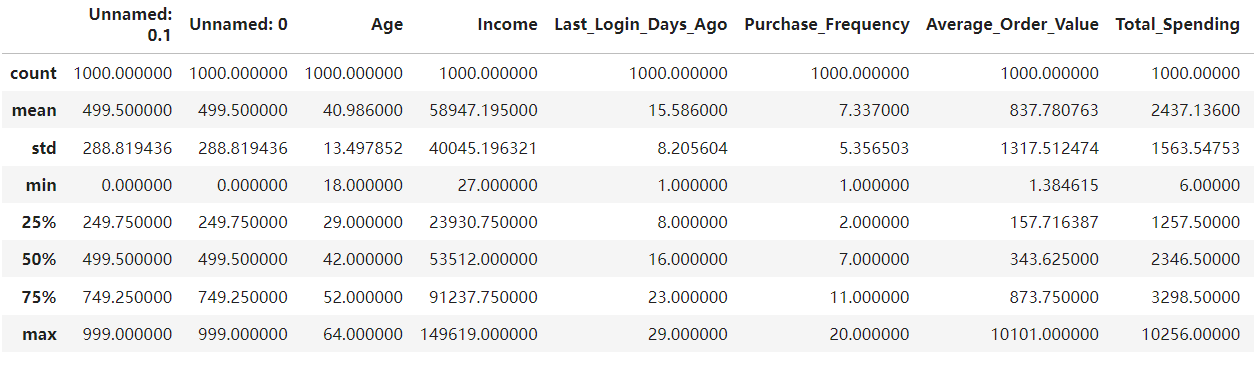
观察数据可以看出,用户购买频次大多在7-11次之间,消费金额在2300-3300之间。
下面来更改部分字段的字段类型。
df['Purchase_Frequency'] = df['Purchase_Frequency'].astype(float)
df['Total_Spending'] = df['Total_Spending'].astype(float)
#为使数据更加详细具体,避免出现误差等问题,消费频次与消费金额数据类型改为float浮点型数值检查修改后的数据类型是否正确。
df.dtypes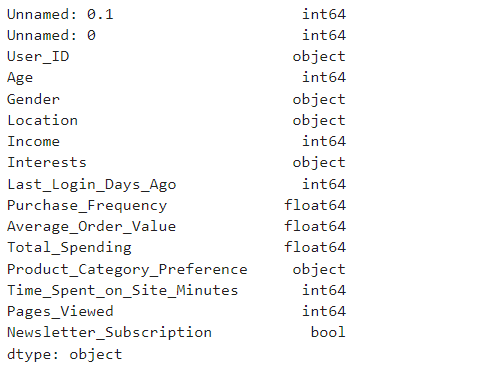
接下来查看是否有重复值。
df.duplicated().sum()![]()
无重复值。
保存处理后的数据
df.to_csv(r'D:\大学\简历\抖音电商用户行为分析\dy.csv',index = False)四.数据处理和建表查询
4.1 数据导入
打开Datagrip,连接MySQL后在相应的数据库导入csv文件
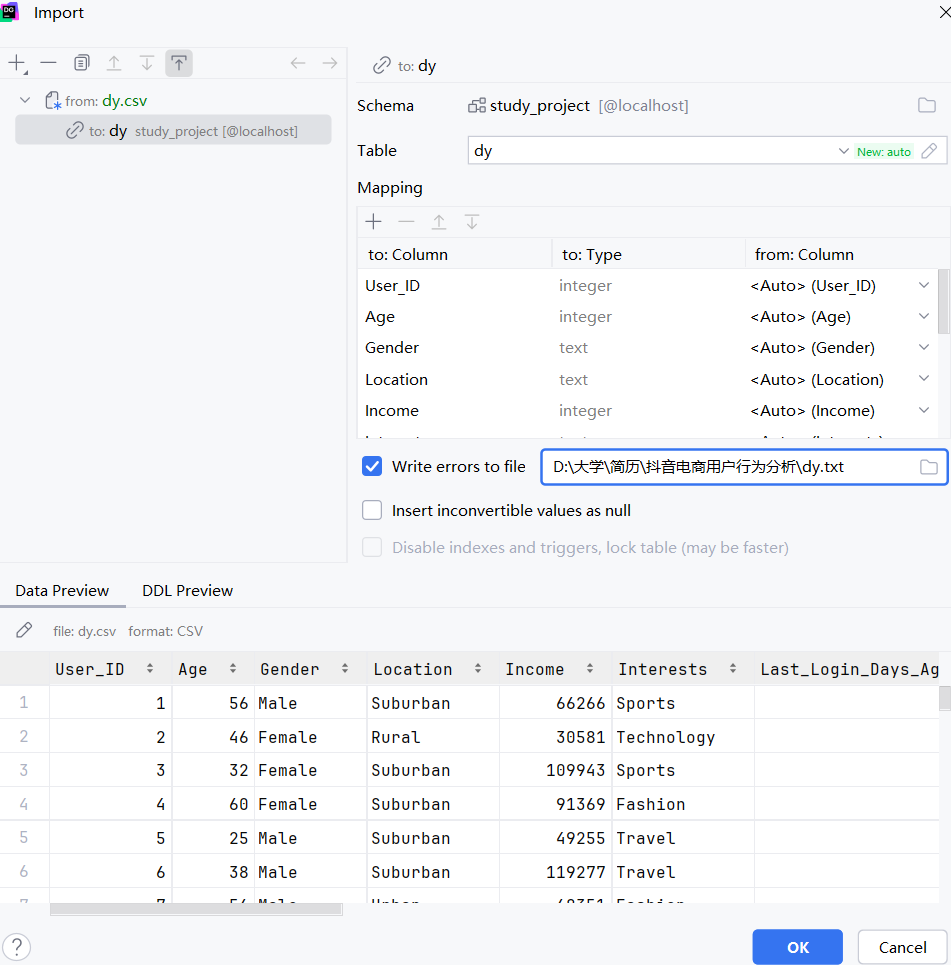
4.2 用户画像分析
核心:定位核心客群与兴趣-品类偏好规律
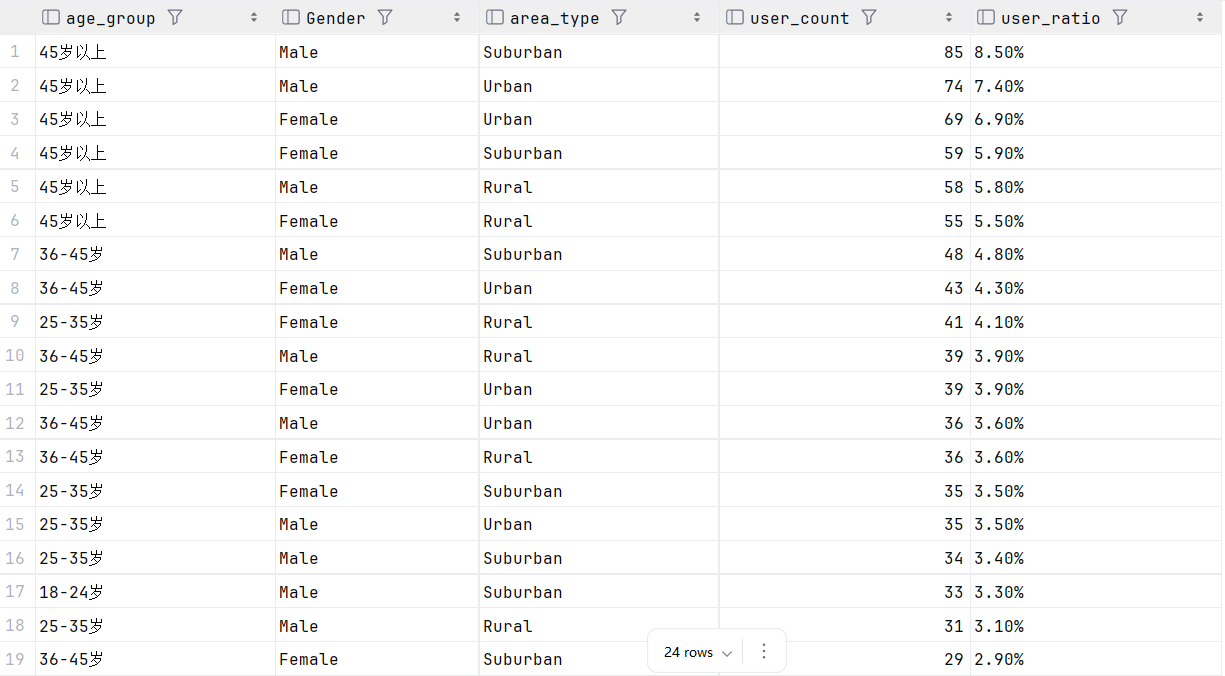
4.2.1 年龄段+性别+地区类型的用户分布统计
SELECT
CASE
WHEN Age < 18 THEN '18岁以下'
WHEN Age BETWEEN 18 AND 24 THEN '18-24岁'
WHEN Age BETWEEN 25 AND 35 THEN '25-35岁'
WHEN Age BETWEEN 36 AND 45 THEN '36-45岁'
ELSE '45岁以上'
END AS age_group,
Gender,
Location AS area_type, -- 郊区Suburban/农村Rural/城市Urban
COUNT(User_ID) AS user_count,
CONCAT(ROUND(COUNT(User_ID)/SUM(COUNT(User_ID)) OVER()*100,2),'%') AS user_ratio
FROM dy
GROUP BY age_group, Gender, area_type
ORDER BY user_count DESC;
4.2.2 品类偏好分布
SELECT
Interests,
Product_Category_Preference AS product_category,
COUNT(User_ID) AS user_count
FROM dy
GROUP BY Interests, product_category
HAVING user_count >= 5 -- 筛选样本量≥5的有效组合
ORDER BY user_count DESC;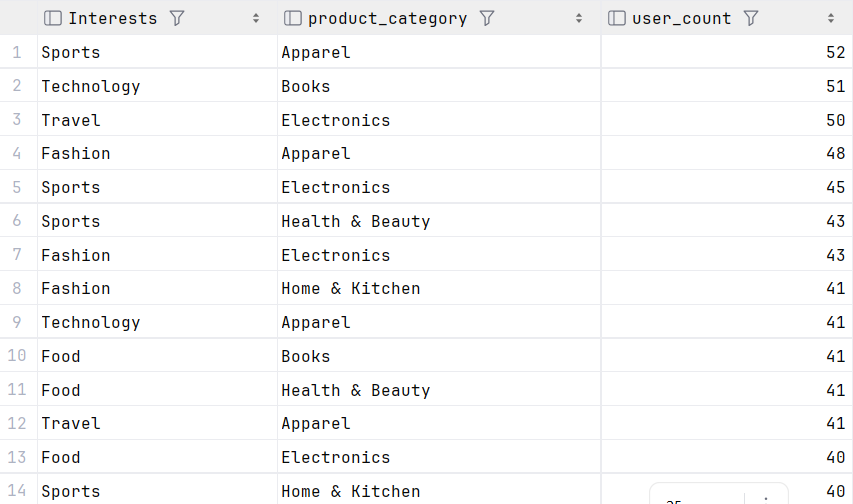
4.3 用户行为特征分析
4.3.1 用户价值分层
RMF 模型是客户关系管理(CRM)和营销分析中常用的一种客户分层模型,通过三个核心指标对客户价值进行量化评估:最近一次消费时间(Recency)、消费频率(Frequency)、消费金额(Monetary),可以帮助企业识别高价值客户、制定精准营销策略。
-
定义 RFM 指标:R(最近一次消费,用
Last_Login_Days_Ago替代,值越小越优质)、F(购买频率Purchase_Frequency)、M(消费金额Total_Spending); -
对 R/F/M 分别打分(1-5 分,5 分为最优);
-
按总分划分用户层级(高价值 / 中价值 / 低价值 / 流失用户)。
WITH rfm_base AS (
SELECT
User_ID,
Last_Login_Days_Ago AS R,
Purchase_Frequency AS F,
Total_Spending AS M
FROM dy
),
rfm_score AS (
SELECT
User_ID,
-- R打分:登录天数越少,分数越高
CASE
WHEN R <= 3 THEN 5
WHEN R <= 7 THEN 4
WHEN R <= 15 THEN 3
WHEN R <= 30 THEN 2
ELSE 1
END AS R_score,
-- F打分:购买频率越高,分数越高
CASE
WHEN F >= 10 THEN 5
WHEN F >= 5 THEN 4
WHEN F >= 3 THEN 3
WHEN F >= 1 THEN 2
ELSE 1
END AS F_score,
-- M打分:消费金额越高,分数越高
CASE
WHEN M >= 5000 THEN 5
WHEN M >= 2000 THEN 4
WHEN M >= 1000 THEN 3
WHEN M >= 500 THEN 2
ELSE 1
END AS M_score
FROM rfm_base
),
rfm_total AS (
SELECT
User_ID,
R_score + F_score + M_score AS Total_score
FROM rfm_score
)
SELECT
User_ID,
Total_score,
CASE
WHEN Total_score >= 12 THEN '高价值用户'
WHEN Total_score >= 8 THEN '中价值用户'
WHEN Total_score >= 4 THEN '低价值用户'
ELSE '流失用户'
END AS User_Level
FROM rfm_total
ORDER BY Total_score DESC;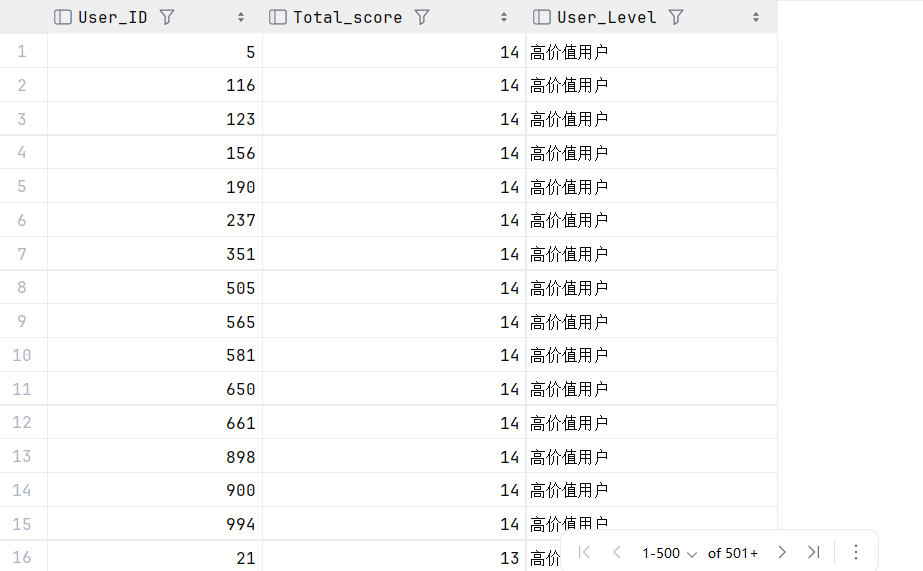
4.3.2 不同用户层级的品类偏好挖掘
-
关联用户分层结果与
Product_Category_Preference品类偏好字段; -
统计各用户层级的品类分布占比;
-
识别高价值用户的核心偏好品类。
WITH user_level AS (
-- 复用子目标1的用户分层逻辑
SELECT
User_ID,
CASE
WHEN (R_score + F_score + M_score) >= 12 THEN '高价值用户'
WHEN (R_score + F_score + M_score) >= 8 THEN '中价值用户'
WHEN (R_score + F_score + M_score) >= 4 THEN '低价值用户'
ELSE '流失用户'
END AS User_Level
FROM (
SELECT
User_ID,
CASE WHEN Last_Login_Days_Ago <=3 THEN 5 WHEN Last_Login_Days_Ago <=7 THEN 4 WHEN Last_Login_Days_Ago <=15 THEN 3 WHEN Last_Login_Days_Ago <=30 THEN 2 ELSE 1 END AS R_score,
CASE WHEN Purchase_Frequency >=10 THEN 5 WHEN Purchase_Frequency >=5 THEN 4 WHEN Purchase_Frequency >=3 THEN 3 WHEN Purchase_Frequency >=1 THEN 2 ELSE 1 END AS F_score,
CASE WHEN Total_Spending >=5000 THEN 5 WHEN Total_Spending >=2000 THEN 4 WHEN Total_Spending >=1000 THEN 3 WHEN Total_Spending >=500 THEN 2 ELSE 1 END AS M_score
FROM dy
) AS temp
)
SELECT
ul.User_Level,
de.Product_Category_Preference,
COUNT(de.User_ID) AS User_Count,
-- 计算该品类在当前用户层级中的占比
ROUND(COUNT(de.User_ID) / SUM(COUNT(de.User_ID)) OVER (PARTITION BY ul.User_Level), 4) * 100 AS Category_Ratio
FROM user_level ul
JOIN dy de ON ul.User_ID = de.User_ID
GROUP BY ul.User_Level, de.Product_Category_Preference
ORDER BY ul.User_Level, Category_Ratio DESC;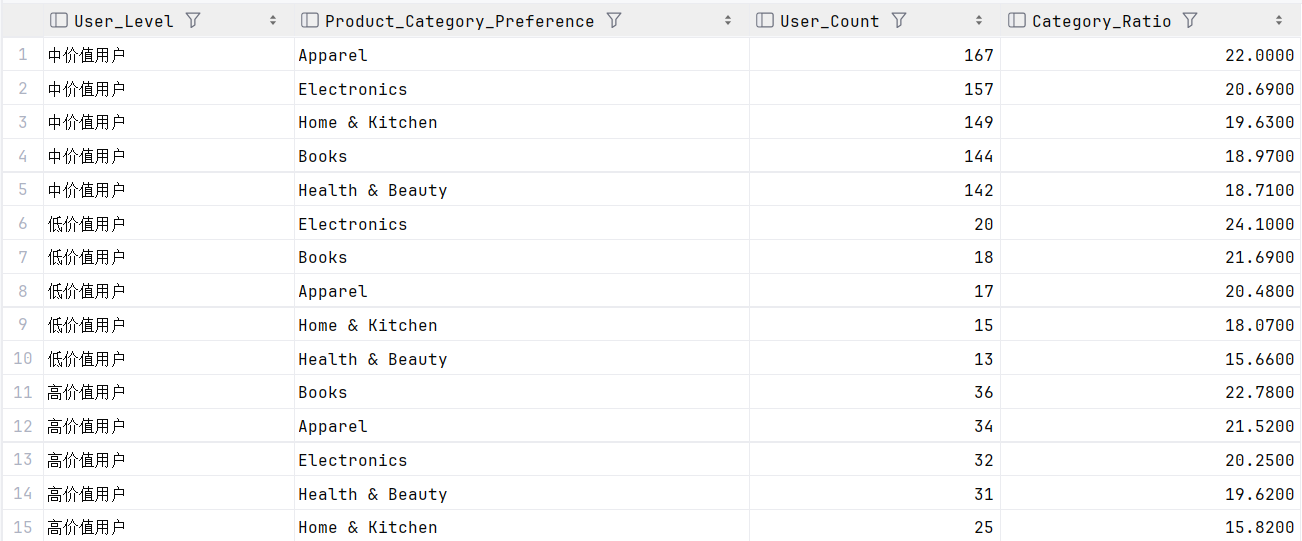
可以看到,中价值用户占比较高。
4.3.3 用户活跃度与消费转化的关联分析
WITH active_level AS (
SELECT
User_ID,
-- 定义活跃等级
CASE
WHEN Last_Login_Days_Ago <= 3 THEN '超高活跃'
WHEN Last_Login_Days_Ago <= 7 THEN '高活跃'
WHEN Last_Login_Days_Ago <= 30 THEN '中活跃'
WHEN Last_Login_Days_Ago <= 90 THEN '低活跃'
ELSE '流失'
END AS Active_Level,
Purchase_Frequency,
Average_Order_Value,
Total_Spending
FROM dy
)
SELECT
Active_Level,
COUNT(User_ID) AS User_Num, -- 各活跃等级用户数
AVG(Purchase_Frequency) AS Avg_Purchase_Freq, -- 平均购买频率
AVG(Average_Order_Value) AS Avg_Order_Value, -- 平均客单价
SUM(Total_Spending) AS Total_Spend -- 总消费额
FROM active_level
GROUP BY Active_Level
ORDER BY
FIELD(Active_Level, '超高活跃', '高活跃', '中活跃', '低活跃', '流失');
4.4 运营策略优化分析
4.4.1 留存转化关键节点分析
CREATE TABLE High_Potential_Repeat_Customers AS
SELECT
User_ID,
Last_Login_Days_Ago,
Product_Category_Preference AS prefer_category,
Average_Order_Value AS avg_order
FROM dy
WHERE Last_Login_Days_Ago <= 7
ORDER BY Purchase_Frequency DESC;
4.4.2 个性化品类推荐模型
CREATE TABLE Category_Preference_Score AS
SELECT
User_ID,
Interests,
Product_Category_Preference AS prefer_category,
ROUND(Purchase_Frequency*0.7 + (Average_Order_Value/1000)*0.3,2) AS recommend_score
FROM dy
ORDER BY recommend_score DESC
LIMIT 1000; -- 取TOP1000高推荐值用户
4.4.3 营销活动高响应人群筛选
输出核心营销人群,提升活动转化
CREATE TABLE Core_user_demographic AS
SELECT
User_ID,
Income,
Purchase_Frequency,
Average_Order_Value,
Total_Spending,
Product_Category_Preference AS prefer_category
FROM dy
WHERE
Purchase_Frequency > 3 -- 月均购买超3次
AND Average_Order_Value > 200 -- 客单价超200
AND Location = 'Urban' -- 城市用户
ORDER BY Total_Spending DESC;
五、抖音电商运营分析简报
用户分布
可以看出,核心用户年龄段为45 岁以上,其次就是36-45这个年龄段。
首先要以45 岁以上群体为核心,这类用户多为家庭主导者,优先推送 Home & Kitchen(家居厨具)、Health & Beauty(健康护理)的 “家庭装”“实用款”,搭配 “满减 + 赠品” 活动(比如买厨具送清洁套装)。
其次是36-45 岁群体。这类用户处于职场中坚 + 家庭责任期,可推荐 Electronics(数码设备,如办公 / 家用小家电)、Apparel(品质服饰)的 “高性价比 + 多功能” 款,比如推送 “职场通勤装 + 家用投影仪” 的组合优惠。

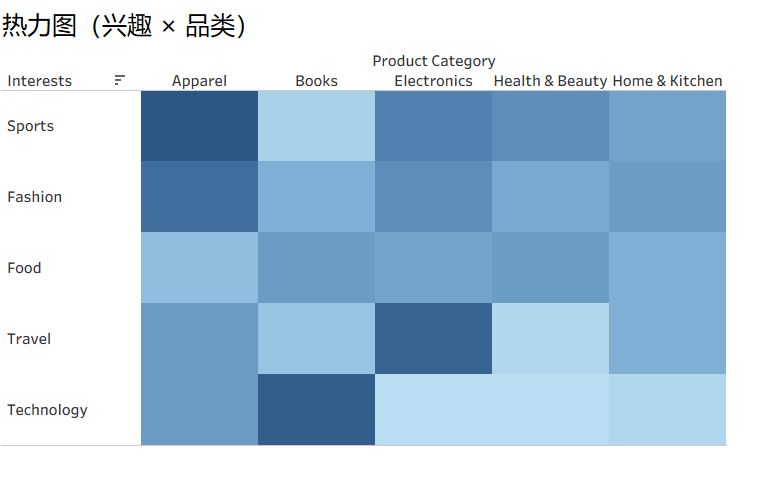
兴趣品类关联分析
- 可以看出“运动-服装”“科技-书本”“旅行-电子类”属于「高兴趣 - 高品类」组合,可直接作为选品和营销的依据。
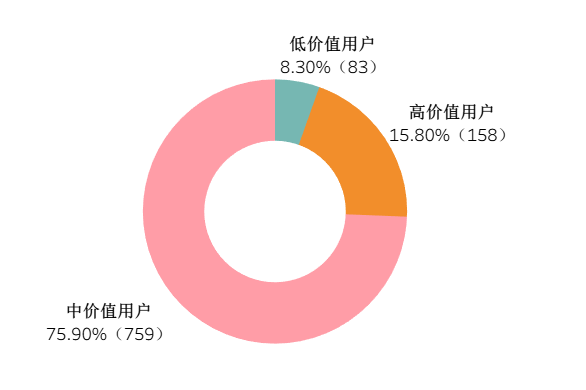
用户分层
用户结构呈 “纺锤形”:中价值用户为主体,占 75.9%,高价值用户仅 15.8%,低价值用户 8.3%。
业务建议:
- 重点转化「中价值用户」:给这部分用户推送 “满减券 + 高频复购品类”(比如日用品),提升其购买频率,往高价值层级迁移;
- 激活「低价值用户」:推送小额无门槛券(比如 5 元券),降低消费决策成本,召回沉默用户。
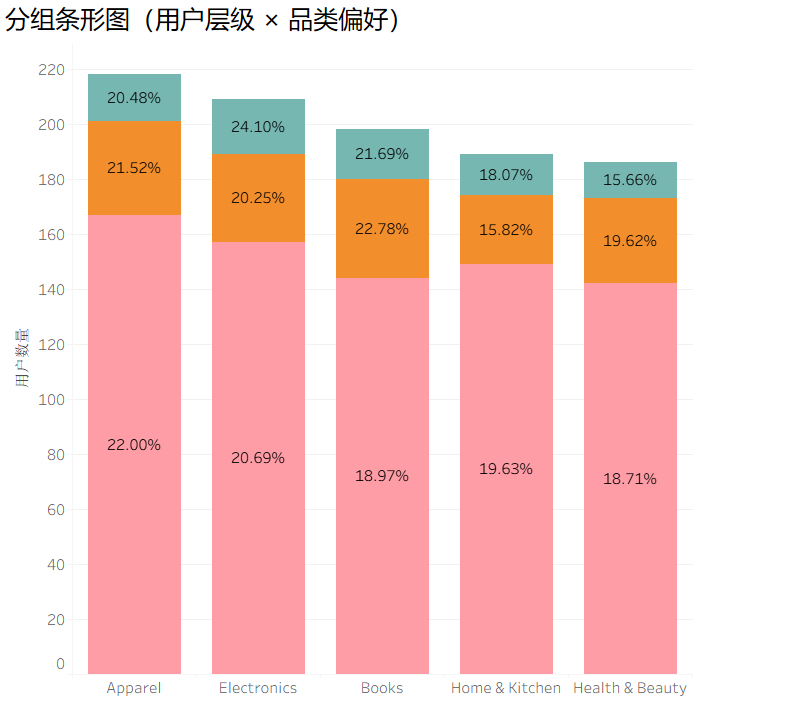
不同层级的用户偏好分析
高价值用户的核心偏好是Apparel(服饰)、Electronics(电子),而中价值用户在所有品类中都是主力群体。
业务建议:
- 给高价值用户推「高端品类」:比如 Apparel 的轻奢款、Electronics 的数码新品,匹配其消费能力;
- 给中价值用户推「高性价比爆款」:比如 Books 的畅销读物、Home & Kitchen 的实用家居,贴合其消费偏好。

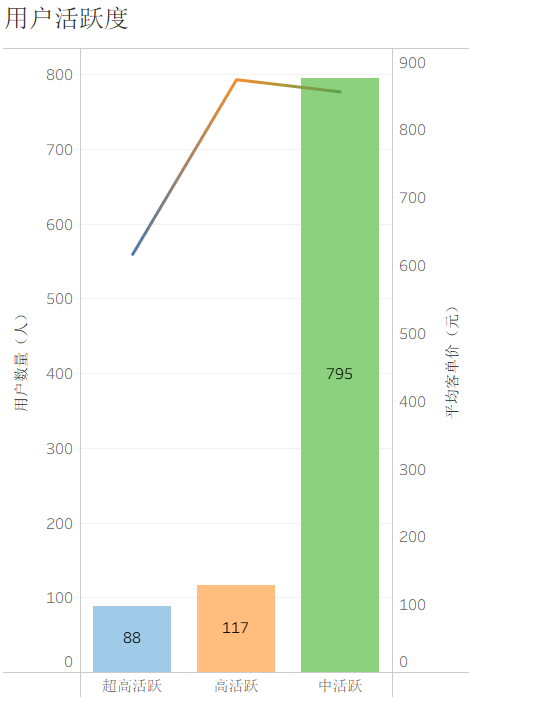
用户活跃度
中活跃用户数最多(795 人),但超高活跃用户的平均客单价最高;活跃等级越高,平均客单价越高,符合 “活跃度→消费能力” 的正相关逻辑。
业务建议
- 维护「超高活跃用户」:给这部分用户开通 “专属客服 + 优先发货” 权益,避免流失;
- 提升「中活跃用户」活跃度:推送 “连续登录领积分” 活动,引导其缩短登录间隔,转化为高活跃用户。
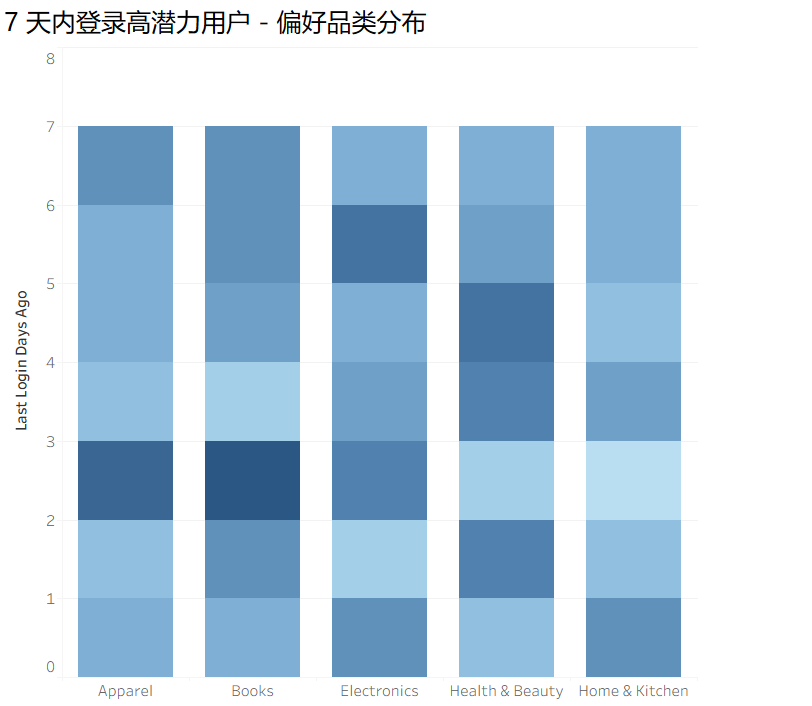
高潜力用户分析
三日内登陆人数较多的为高潜力用户,其核心偏好是Apparel(服饰)、Books(图书),登录间隔短,复购意愿强。
业务建议
- 对这些高潜力用户做「即时复购刺激」:比如 Apparel 品类推送 “买一送一” 活动,Books 品类推送 “新书预售 + 限时折扣”;
- 标记 3 天内登录的用户,加入 “每日新品推送” 名单,缩短其消费周期。
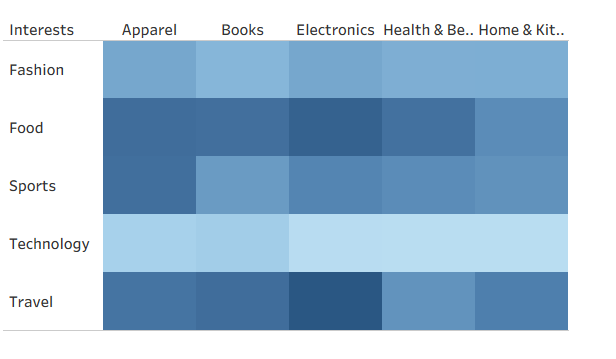
各品类偏好推荐分值
此图可结合品类偏好用户占比进行观察,颜色越深代表该品类偏好价值更高,收益更高。
Food(美食)兴趣用户的色块最深,推荐分值最高,说明这部分用户的 “购买频率 + 客单价” 综合表现最好;而Fashion(时尚)、Sports(运动)兴趣用户的推荐分值也处于较高水平。
业务建议:
- 重点运营 Food 兴趣用户:给他们推送 “美食礼盒 + 会员折扣”,提升其推荐分值对应的转化;
- 把高推荐分用户(比如 Food、Fashion)加入 “私域社群”,做精细化的内容种草(比如美食教程、穿搭分享)。
六、总结
我的第一个SQL分析项目到此结束啦,第一次做还请多多指教~
由于我是初学数据分析,因此无法完全独立完成此项目,参考了教学视频,链接:全网最良心的【数据分析自学课程】它来啦!必备的Excel/SQL/Tableau/Python|求职|简历面试|产品|大厂分析报告制作、戴师兄数据分析入门免费课_哔哩哔哩_bilibili
还有一些前辈的项目:【实战入门】电商平台用户行为与品类运营洞察 - Heywhale.com,基于MySQL的抖音电商数据多维分析 - Heywhale.com
在分析思路上还有很大欠缺,如果有机会会在此基础上完善该项目,欢迎大家提出更好的建议!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)