人工神经网络-四种优化方法 (SGD、Momentum、Adam、AdaGrad)
摘要:深度学习优化方法比较:SGD随机抽取样本计算梯度,计算成本低但震荡明显;Momentum通过动量减少震荡,加速收敛;Adam结合动量和自适应学习率,通用性强且稳定;AdaGrad适合稀疏数据但后期学习率衰减过快。建议:通用任务选Adam,稀疏数据用AdaGrad,快速收敛选Momentum,基础对比用SGD。参数优化受数据质量、模型结构、初始化策略等多因素影响,虽存在随机性但主要依赖可控因素
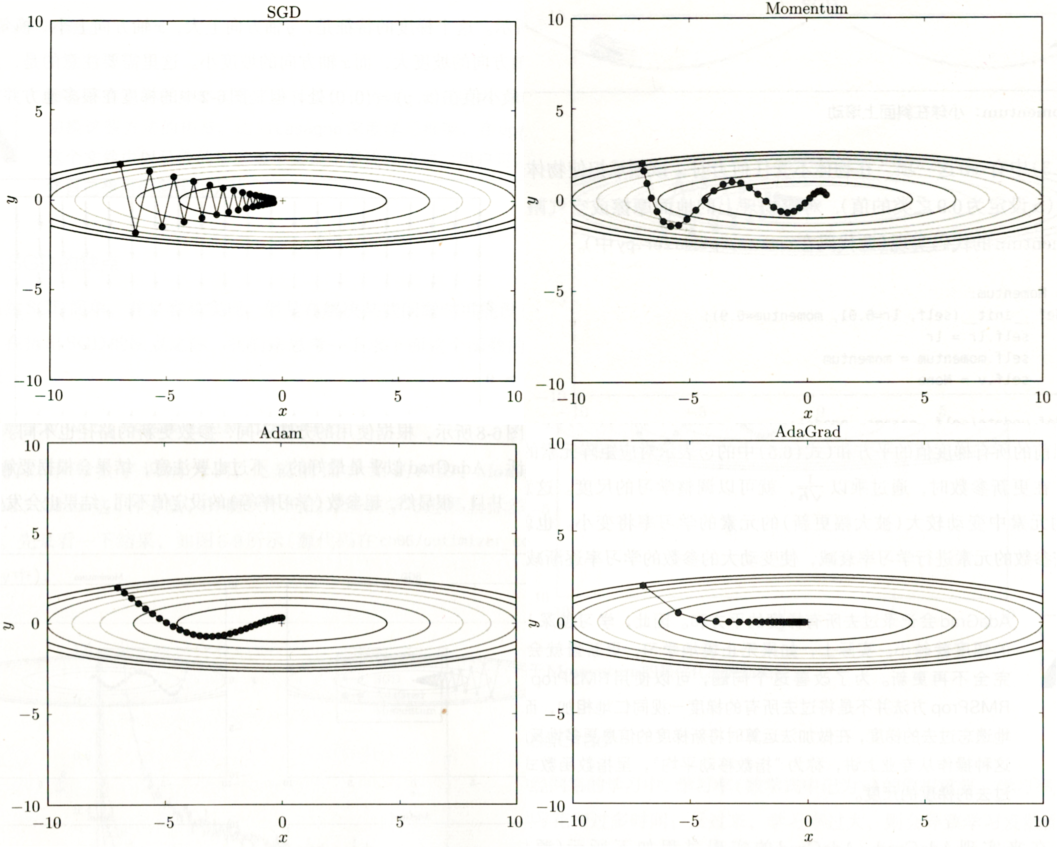
深度学习中 4 种经典优化方法(SGD、Momentum、Adam、AdaGrad),它们的核心特点和适用场景如下:
1. SGD(随机梯度下降)
- 核心特点:每次迭代随机抽取单个 / 小批样本计算梯度,沿梯度反方向更新参数,是最基础的优化方法。
- 可视化表现(图中):路径波动大、方向不稳定,在损失函数的 “山谷” 区域(等高线密集处)会来回震荡,收敛速度较慢。
- 优势:计算成本低、训练速度快,引入的梯度噪声可能帮助跳出局部最优。
- 劣势:梯度方向不稳定,容易在最优解附近震荡,对学习率敏感。
2. Momentum(动量法)
- 核心特点:引入 “动量”(历史梯度的加权平均),模拟物理中的惯性 ——积累之前的梯度方向,减少当前梯度的随机波动。
- 可视化表现(图中):路径更平滑、震荡减少,能快速 “冲过” 损失函数的平缓区域,向最优解方向加速收敛。
- 优势:抑制梯度噪声,加快收敛速度,减少震荡。
- 劣势:可能因惯性 “冲过” 最优解,后期需要调整学习率来稳定。
3. Adam(自适应矩估计)
- 核心特点:结合了 **Momentum(动量)和AdaGrad(自适应学习率)** 的优点:
- 维护梯度的一阶矩(动量,类似 Momentum);
- 维护梯度的二阶矩(自适应调整每个参数的学习率)。
- 可视化表现(图中):路径平滑且精准,能快速向最优解收敛,几乎无多余震荡。
- 优势:自适应学习率(无需手动调参)、收敛快、稳定性强,是目前深度学习中最常用的优化方法。
- 劣势:在某些任务(如生成模型)中可能收敛到 “次优解”,但通用性极强。
4. AdaGrad(自适应梯度)
- 核心特点:对每个参数单独调整学习率—— 参数的梯度越大,学习率衰减越快(累计梯度的平方和的平方根作为学习率的分母)。
- 可视化表现(图中):前期快速向最优解靠近,但后期学习率衰减过快,容易 “停滞” 在最优解附近(无法继续优化)。
- 优势:适合稀疏数据(如自然语言处理),对高频参数(梯度大)降学习率,对低频参数(梯度小)保学习率。
- 劣势:学习率单调递减,后期可能因学习率过小而停止收敛。
总结:如何选择优化方法?
- 若追求通用性和省心:优先选 Adam(大部分场景表现最优);
- 若数据是稀疏型(如文本):可选 AdaGrad;
- 若需更快的前期收敛:可选 Momentum;
- 若需基础参考 / 对比:用 SGD 做基线。
(注:实际应用中,Adam 的变体(如 AdamW)会更常用,解决了 Adam 的权重衰减问题)
| 优化方法 | 核心参数 | 核心特性 | 适用场景 | 优缺点总结 |
|---|---|---|---|---|
| SGD(随机梯度下降) | 学习率(lr):需手动调整(常用 0.01/0.001) |
1. 随机抽单个 / 小批样本算梯度,沿反方向更新; 2. 梯度噪声大,路径震荡; 3. 无自适应机制,所有参数共用一个学习率 |
1. 作为基线模型(对比其他优化器效果); 2. 数据量小、特征维度低的简单任务; 3. 需精细调学习率的场景 |
✅ 优点:计算成本最低、训练速度快,噪声可能跳出局部最优; ❌ 缺点:震荡严重、收敛慢,对学习率敏感,需配合学习率衰减 |
| Momentum(动量法) |
1. 学习率(lr); 2. 动量系数(γ,常用 0.9) |
1. 积累历史梯度的加权平均(动量),模拟惯性; 2. 减少震荡,加速沿主导方向收敛; 3. 仍共用一个学习率 |
1. 损失函数表面崎岖(震荡明显)的任务; 2. 深度学习常规任务(如图像分类); 3. 希望加快前期收敛的场景 |
✅ 优点:抑制噪声、收敛更快,比 SGD 稳定; ❌ 缺点:可能冲过最优解,需后期调整学习率 |
| Adam(自适应矩估计) |
1. 学习率(lr,默认 0.001); 2. 一阶矩系数(β₁,默认 0.9); 3. 二阶矩系数(β₂,默认 0.999); 4. 数值稳定项(ε,默认 1e-8) |
1. 结合 Momentum(一阶矩)和 AdaGrad(二阶矩); 2. 自适应调整每个参数的学习率; 3. 梯度平滑,收敛快且稳定 |
1. 绝大多数深度学习任务(图像、文本、语音等);2. 数据量庞大、特征维度高的场景;3. 不想手动调参的快速迭代场景 |
✅ 优点:通用性最强、收敛快、稳定性高,无需复杂调参;❌ 缺点:部分生成任务可能收敛到次优解,权重衰减效果需优化(可换 AdamW) |
| AdaGrad(自适应梯度) |
1. 初始学习率(lr,常用 0.01); 2. 数值稳定项(ε,默认 1e-8) |
1. 累计每个参数的梯度平方和,自适应降低高频参数学习率; 2. 学习率单调递减,后期衰减快 |
1. 稀疏数据任务(如自然语言处理、推荐系统);2. 低频特征需要保留学习率的场景 |
✅ 优点:适合稀疏数据,无需手动调整学习率; ❌ 缺点:学习率后期过小,易停滞收敛,不适合长期训练 |
补充使用小贴士
- 优先选择:日常开发中,Adam 是默认首选(通用性最强),若需更优的权重衰减效果,可替换为 AdamW(Adam 的改进版,优化了正则项);
- 学习率调整:SGD/Momentum 需配合学习率衰减(如 StepLR、CosineAnnealingLR),Adam 通常使用默认学习率即可;
- 稀疏数据:文本、推荐等稀疏场景,可尝试 AdaGrad 或其改进版 RMSProp(解决 AdaGrad 后期停滞问题)。
1. 提供足够多的样本是否有利于找到合适的参数?
答案:多数情况下是有利的,但并非 “越多越好”
- 足够的样本能覆盖数据的分布规律,帮助模型学习到更泛化的特征,减少过拟合风险;
- 但样本过多(尤其是重复 / 低质量样本)会增加训练成本,甚至让模型学到噪声,反而影响参数优化。
2. 只要有足够的时间是否总能找到合适的参数?
答案:不能
- 神经网络的参数优化是 “非凸优化” 问题,存在大量局部最优解,训练时间再长也可能卡在局部最优,无法达到全局最优;
- 此外,数据本身的质量、模型结构的合理性等因素,也会限制参数优化的效果(比如数据分布混乱,再久也学不到有效规律)。
3. 参数的初始化状态是否会影响参数寻优的结果?
答案:会,且影响很大
- 糟糕的初始化(比如参数值过大 / 过小)可能导致 “梯度消失 / 爆炸”,让训练无法收敛;
- 合适的初始化(如 He 初始化、Xavier 初始化)能让梯度保持在合理范围,帮助模型更快接近最优参数;
- 不同初始化也可能让模型收敛到不同的局部最优解,最终参数的效果会有差异。
4. 找到合适的参数是否要依靠运气?
答案:不完全是,但有 “运气成分”
- 模型设计(结构、损失函数)、优化算法(Adam、SGD)、初始化策略等是 “可控因素”,能大幅降低对运气的依赖;
- 但由于非凸优化的特性,参数寻优确实存在一定随机性(比如不同初始化可能收敛到不同局部最优),所以会有少量运气的影响。
神经网络参数优化关键因素总结
一、数据层面
- 样本数量:足够且覆盖数据分布的样本,帮助模型学习泛化特征;但避免冗余 / 低质量样本。
- 样本质量:干净、标注准确的数据是参数优化的基础,噪声数据会误导参数学习。
二、训练过程层面
- 优化算法:选择合适的算法(如 SGD、Adam),决定参数更新的效率与方向。
- 训练时间:足够的迭代次数让参数逐步收敛,但过长易过拟合 / 卡在局部最优。
- 初始化策略:合理的初始化(He/Xavier)避免梯度问题,影响收敛速度与最终参数质量。
三、模型与目标层面
- 模型结构:匹配任务的网络结构(如 CNN 适合图像),决定参数优化的 “潜力上限”。
- 损失函数:合理的损失函数(如交叉熵、MSE)引导参数向最优方向更新。
四、随机性与运气
- 非凸优化的局部最优特性,会让不同初始化 / 训练过程收敛到不同结果,存在少量随机性,但可控因素(算法、初始化等)可降低运气的影响。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 32
32 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)