业内首个RL+VLA汇总:强化学习如何推动 VLA 走向真实世界?
去年大部分自驾VLM/VLA方向的工作都在基于SFT微调,数据量大的全参微调,数据量小的基于LoRA微调。:提出AutoDrive-R²这一VLA框架,通过“监督微调+强化学习”两阶段训练,结合含自我反思的CoT数据集与物理基奖励机制,解决现有VLA模型推理不足和轨迹物理不可行的问题,实现精准轨迹规划。:针对VLMs在自动驾驶运动规划中过度依赖历史输入、推理与规划结果错位的问题,提出Drive-R
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
最近有几位同学咨询柱哥自驾方向VLA+RL的工作推荐,一直没来得及整理。今天带大家从近期十一篇VLA + RL工作上,一览该领域的历程......
去年大部分自驾VLM/VLA方向的工作都在基于SFT微调,数据量大的全参微调,数据量小的基于LoRA微调。效果是有的,但幻觉问题也比较严重。本质上还是监督学习,为了进一步提升模型的泛化能力和推理能力,学术界和工业界把目光转向了RL。本文汇总的工业涵盖新国立、斯坦福、清北复交、华科中科大等高校、小米、英伟达、阿里、博世、理想、华为诺亚等公司,基本上可以指明业界头部的研究方向。
MindDrive
-
论文标题:MindDrive: A Vision-Language-Action Model for Autonomous Driving via Online Reinforcement Learning
-
论文链接:https://arxiv.org/abs/2512.13636
-
项目主页:https://xiaomi-mlab.github.io/MindDrive/
-
提出机构:华中科技大学、小米汽车
-
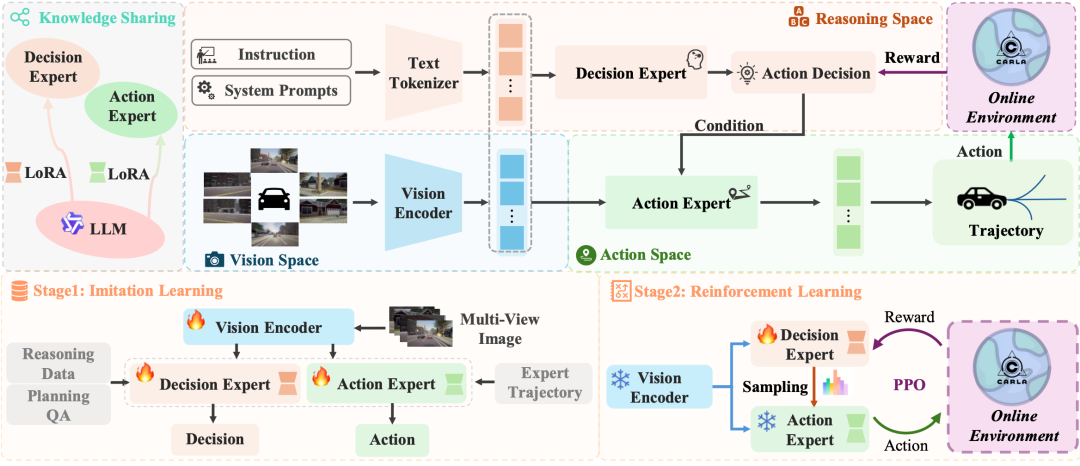
一句话总结:为解决VLA模型在线强化学习中连续动作空间探索低效的问题,提出MindDrive框架,通过双专家(决策专家+动作专家)架构将动作空间转化为离散语言决策空间,实现高效在线RL训练。
-
核心贡献:
-
设计双LoRA适配器架构,决策专家负责场景推理与语言决策,动作专家将决策映射为可行轨迹,建立语言-动作动态映射。
-
构建基于CARLA模拟器的在线闭环RL框架,采用稀疏奖励与PPO算法,结合KL正则化避免灾难性遗忘。
-
在Bench2Drive基准上以轻量Qwen-0.5B模型实现78.04的驾驶分数与55.09%的成功率,超越同规模SOTA模型。
-
WAM-Diff
-
论文标题:WAM-Diff: A Masked Diffusion VLA Framework with MoE and Online Reinforcement Learning for Autonomous Driving
-
论文链接:https://arxiv.org/abs/2512.11872
-
项目主页:https://github.com/fudan-generativevision/WAM-Diff
-
提出机构:复旦大学、银王智能科技有限公司
-
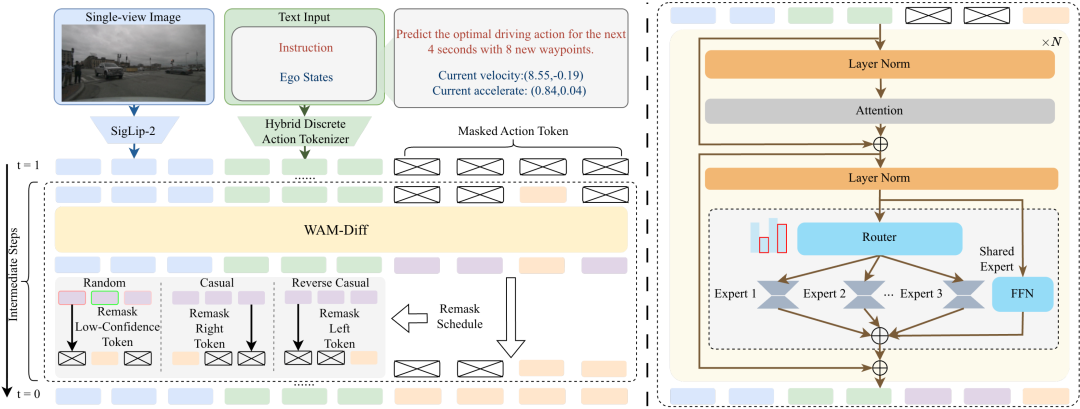
一句话总结:提出WAM-Diff端到端自动驾驶VLA框架,采用离散掩码扩散迭代优化未来轨迹序列,结合稀疏MoE架构和GSPO在线强化学习,在NAVSIM基准上实现优异性能。
-
核心贡献:
-
系统适配掩码扩散用于自动驾驶,支持因果、逆因果等灵活解码顺序,适配不同驾驶场景。
-
引入稀疏MoE架构并联合训练运动预测与驾驶导向VQA任务,提升模型扩展能力与场景理解能力。
-
集成GSPO在线强化学习优化序列级驾驶奖励,在安全、舒适性等多维度提升驾驶性能。
-
LCDrive
-
论文标题:Latent Chain-of-Thought World Modeling for End-to-End Autonomous Driving
-
论文链接:https://arxiv.org/abs/2512.10226
-
提出机构:得克萨斯大学奥斯汀分校、NVIDIA、斯坦福大学
-
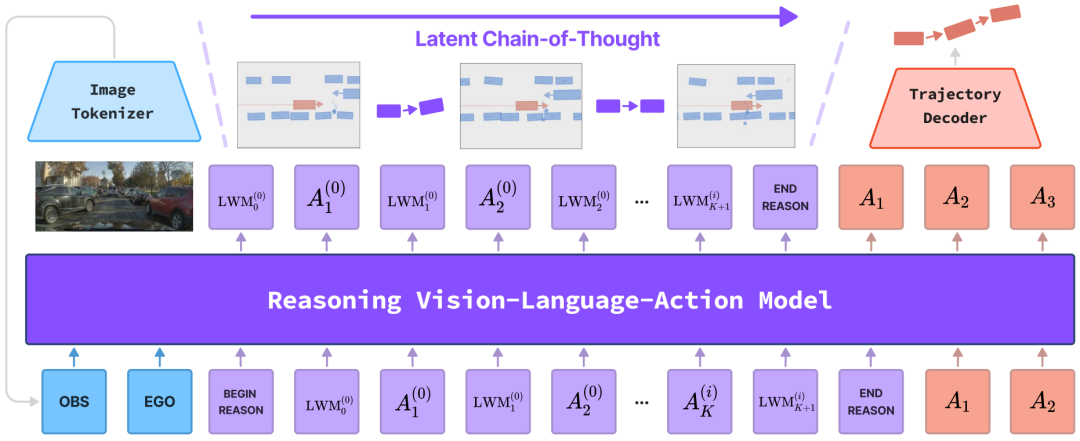
一句话总结:针对文本链推理在自动驾驶中时空表达不足、 latency高的问题,提出LCDrive模型,采用动作对齐的 latent 语言进行推理,通过三阶段训练实现高效推理与决策一体化。
-
核心贡献:
-
设计 latent 链推理机制,交替使用动作提议令牌与 latent 世界模型令牌,在向量空间模拟反事实未来,提升推理效率与精度。
-
提出三阶段训练 pipeline(非推理预训练、 latent 链冷启动、闭环强化学习),强化推理与动作的对齐。
-
在PhysicalAI-AV数据集上验证,相比文本链推理基线,实现更快推理、更优轨迹质量与更强的RL提升效果。
-
Reasoning-VLA
-
论文标题:Reasoning-VLA: A Fast and General Vision-Language-Action Reasoning Model for Autonomous Driving
-
论文链接:https://arxiv.org/abs/2511.19912
-
项目主页:https://github.com/xipi702/Reasoning-VLA
-
提出机构:兰州大学、新加坡国立大学、中国科学技术大学、清华大学、新南威尔士大学
-
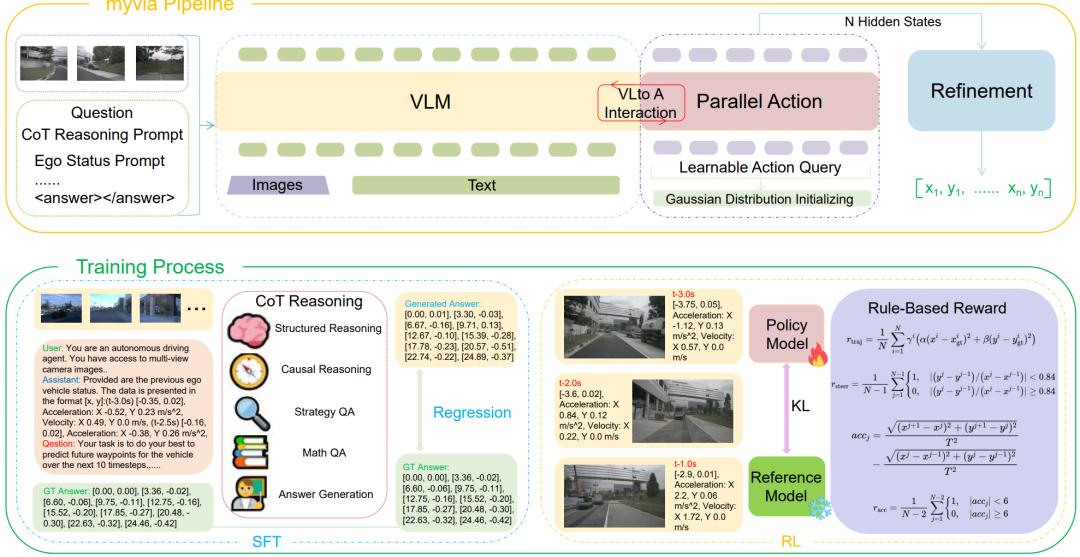
一句话总结:提出Reasoning-VLA高效VLA框架,通过可学习动作查询与推理增强型VLM交互实现并行轨迹生成,融合8个公开数据集构建统一训练数据,经SFT与RL微调实现高性能与强泛化。
-
核心贡献:
-
设计可学习动作查询(基于真实轨迹高斯采样初始化),与VLM跨注意力交互,支持一步并行生成连续轨迹。
-
构建统一的思维链推理数据集,融合8个自动驾驶数据集,提升模型跨场景与车辆配置的泛化能力。
-
采用SFT+RL两阶段训练策略,结合物理轨迹与车辆动力学奖励,强化模型推理与规划能力。
-
Alpamayo-R1
-
论文标题:Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail
-
论文链接:https://arxiv.org/abs/2511.00088
-
项目主页:https://github.com/NVlabs/alpasim(关联仿真工具开源,模型后续计划开源)
-
提出机构:NVIDIA
-
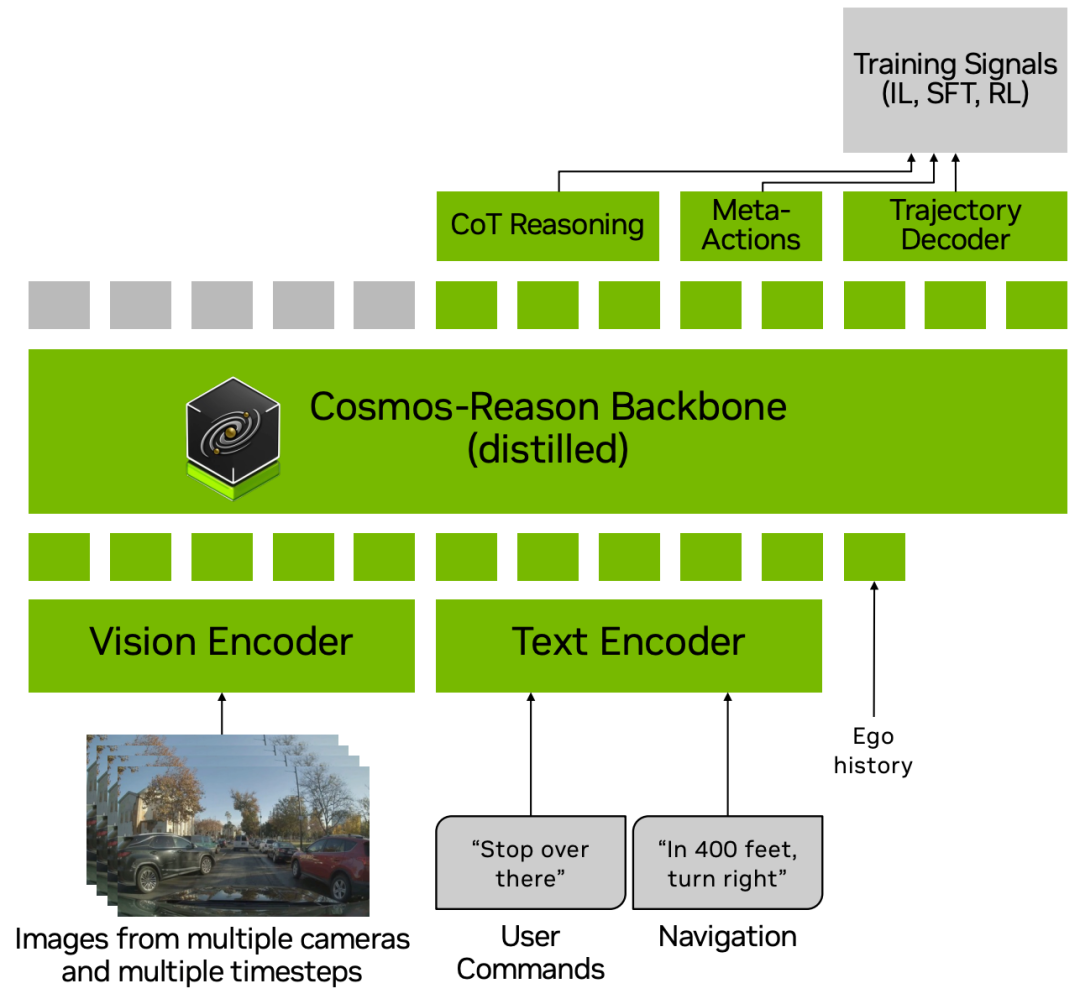
一句话总结:提出Alpamayo-R1 VLA模型,通过因果链(CoC)数据集、模块化架构(Cosmos-Reason骨干+扩散轨迹解码器)和多阶段训练(动作模态注入+SFT+RL),桥接推理与动作预测,提升长尾场景泛化能力与实时部署性能。
-
核心贡献:
-
构建CoC数据集,通过人机结合标注 pipeline 生成决策接地的因果推理轨迹,解决现有数据因果混淆、描述模糊的问题,为推理训练提供高质量监督。
-
设计模块化架构,融合物理AI预训练的VLM骨干与流匹配轨迹解码器,兼顾复杂场景推理能力与动力学可行的轨迹生成,实现99ms实时推理延迟。
-
采用RL后训练优化推理质量、推理-动作一致性和轨迹安全性, closed-loop 仿真中off-road率降低35%,close encounter率降低25%,实车测试验证城市道路部署能力。
-
AdaThinkDrive
-
论文标题:AdaThinkDrive: Adaptive Thinking via Reinforcement Learning for Autonomous Driving
-
论文链接:https://arxiv.org/abs/2509.13769
-
提出机构:清华大学、小米汽车、澳门大学、南洋理工大学、北京大学
-
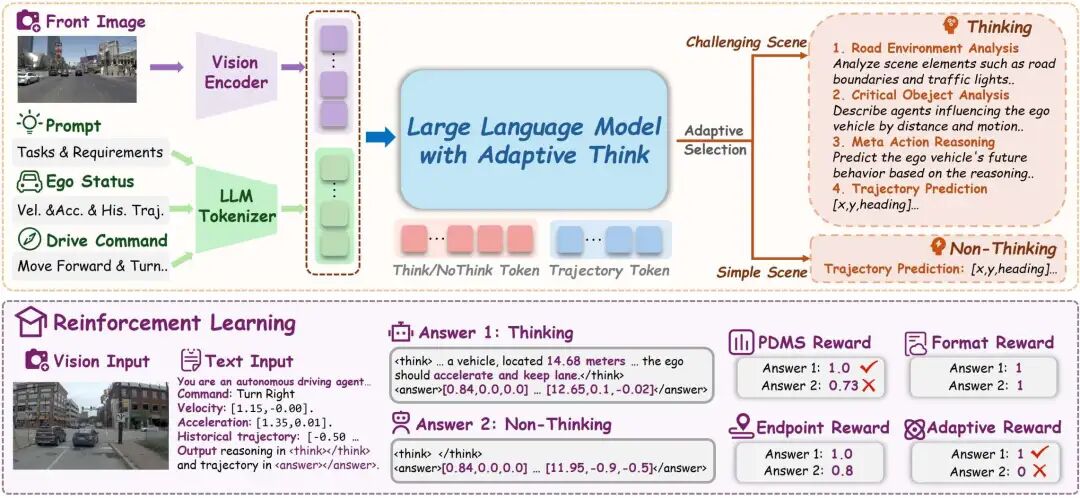
一句话总结:提出AdaThinkDrive VLA框架,基于“快速响应/慢速思考”双模式机制,通过预训练、双模式SFT和GRPO强化学习(含自适应思考奖励),解决CoT在简单场景过度推理的问题,平衡自动驾驶的决策准确性与推理效率。
-
核心贡献:
-
揭示现有CoT方法的场景适配缺陷,设计自适应推理策略,让模型根据场景复杂度动态选择直接预测或CoT推理,避免冗余计算。
-
构建双模式SFT数据集(含推理型和直接响应型数据),搭配融合PDMS、端点奖励的自适应思考奖励,引导模型智能选择推理时机。
-
在Navsim基准测试中取得90.3的PDMS分数,较最优视觉基线提升1.7点,同时较“始终推理”基线减少14%推理时间,实现性能与效率双赢。
-
AutoDrive-R²
-
论文标题:AutoDrive-R²: Incentivizing Reasoning and Self-Reflection Capacity for VLA Model in Autonomous Driving
-
论文链接:https://arxiv.org/abs/2509.01944
-
提出机构:阿里巴巴集团、昆士兰大学、兰州大学、凯斯西储大学
-
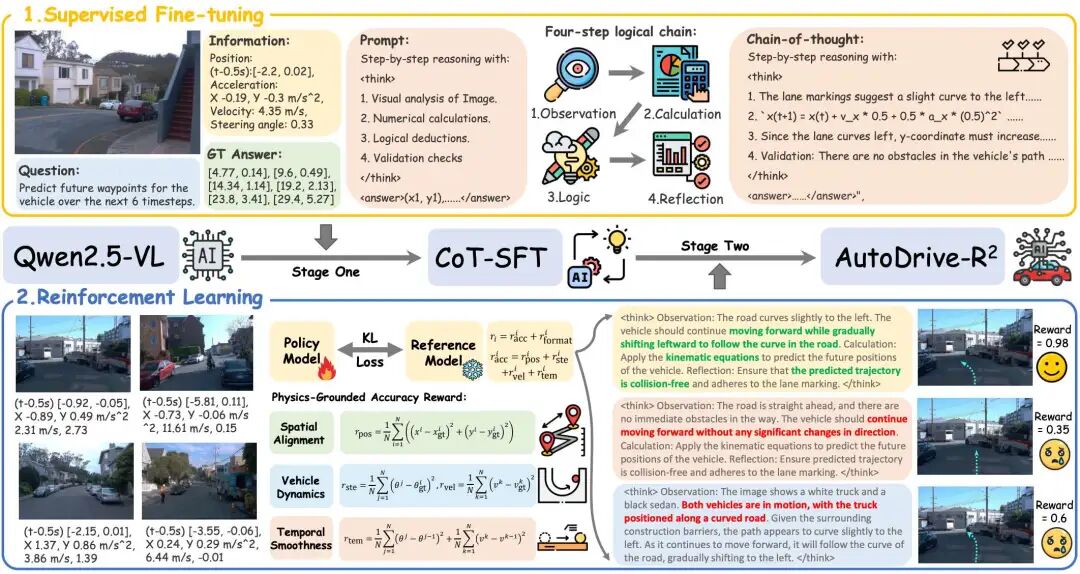
一句话总结:提出AutoDrive-R²这一VLA框架,通过“监督微调+强化学习”两阶段训练,结合含自我反思的CoT数据集与物理基奖励机制,解决现有VLA模型推理不足和轨迹物理不可行的问题,实现精准轨迹规划。
-
核心贡献:
-
构建nuScenesR²-6K数据集,创新采用“观察-计算-逻辑推理-反思验证”四步逻辑链,为监督微调提供高质量因果推理数据,夯实模型基础认知能力。
-
设计融合空间对齐、车辆动力学和时间平滑性的物理基奖励框架,结合GRPO算法优化,确保轨迹满足真实驾驶的物理约束与舒适性要求。
-
在nuScenes和Waymo数据集上实现SOTA性能,7B版本平均L2误差低至0.20m,零样本迁移能力突出,较EMMA+等模型降低33.3%误差。
-
IRL-VLA
-
论文标题:IRL-VLA: Training an Vision-Language-Action Policy via Reward World Model for End-to-End Autonomous Driving
-
论文链接:https://arxiv.org/abs/2508.06571
-
项目主页:https://github.com/IRLVLA/IRL-VLA
-
提出机构:博世(中国)投资有限公司、上海大学、上海交通大学、博世汽车部件(苏州)有限公司、清华大学
-
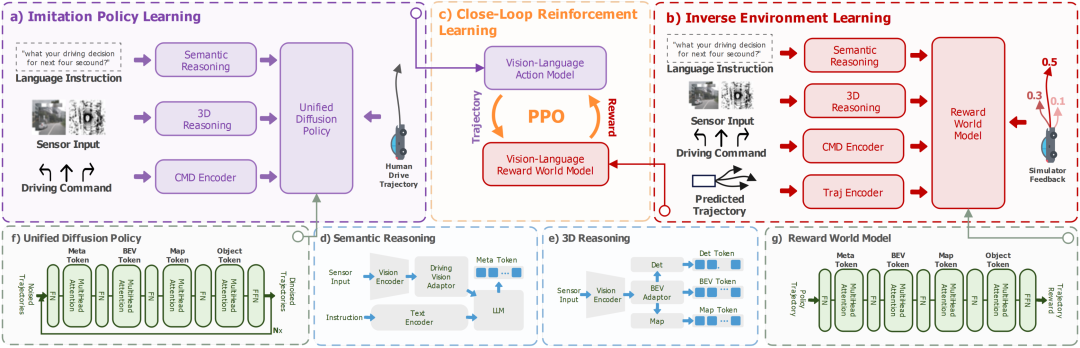
一句话总结:为解决VLA模型依赖开环模仿学习、闭环训练受限于仿真器的问题,提出IRL-VLA框架,通过模仿学习预训练、逆强化学习构建奖励世界模型、PPO强化学习微调三阶段,实现高效闭环训练。
-
核心贡献:
-
提出轻量级奖励世界模型(RWM),基于逆强化学习从多模态数据中学习奖励结构,规避仿真器依赖与域迁移问题。
-
设计融合语义推理、3D推理与扩散规划器的VLA架构,兼顾场景理解与多模态轨迹生成。
-
在NAVSIM v2基准上取得SOTA性能,获CVPR2025自动驾驶挑战赛亚军,是首个不依赖仿真器的传感器输入闭环VLA方法。
-
DriveAgent-R1
-
论文标题:DriveAgent-R1: Advancing VLM-based Autonomous Driving with Active Perception and Hybrid Thinking
-
论文链接:https://arxiv.org/abs/2507.20879
-
提出机构:上海启智研究院、理想汽车、同济大学、清华大学
-
一句话总结:提出DriveAgent-R1自动驾驶智能体,创新融合主动感知与混合思维框架,通过三阶段渐进式训练(SFT+级联RL),实现简单场景高效文本推理与复杂场景工具增强视觉推理的自适应切换,兼顾性能与部署效率。
-
核心贡献:
-
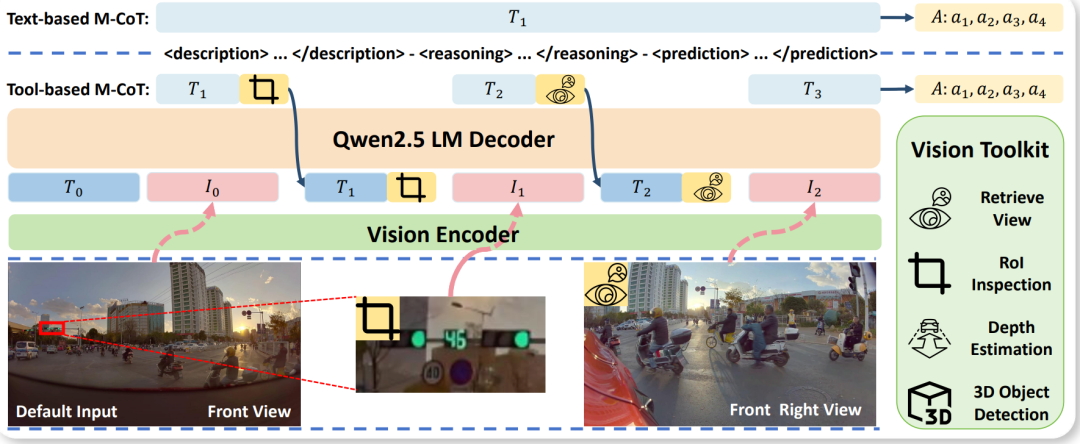
首次将主动感知应用于高级行为规划,设计含Retrieve View、RoI Inspection等工具的视觉 toolkit,主动获取关键视觉证据,提升决策可靠性与可解释性。
-
提出混合思维框架,结合文本推理与工具增强推理,搭配MP-GRPO算法的级联RL训练,让模型能根据场景复杂度自适应选择最优推理模式。
-
仅3B参数就达到与GPT-5和人类驾驶相当的性能,Drive-Internal测试集工具使用后准确率提升6.07%,推理延迟较被动感知方法降低20%以上。
-
Drive-R1
-
论文标题:Drive-R1: Bridging Reasoning and Planning in VLMs for Autonomous Driving with Reinforcement Learning
-
论文链接:https://arxiv.org/abs/2506.18234
-
提出机构:中国科学技术大学、华为诺亚方舟实验室
-
一句话总结:针对VLMs在自动驾驶运动规划中过度依赖历史输入、推理与规划结果错位的问题,提出Drive-R1模型,通过包含长短链推理数据的监督微调与强化学习框架,实现场景推理与运动规划的衔接。
-
核心贡献:
-
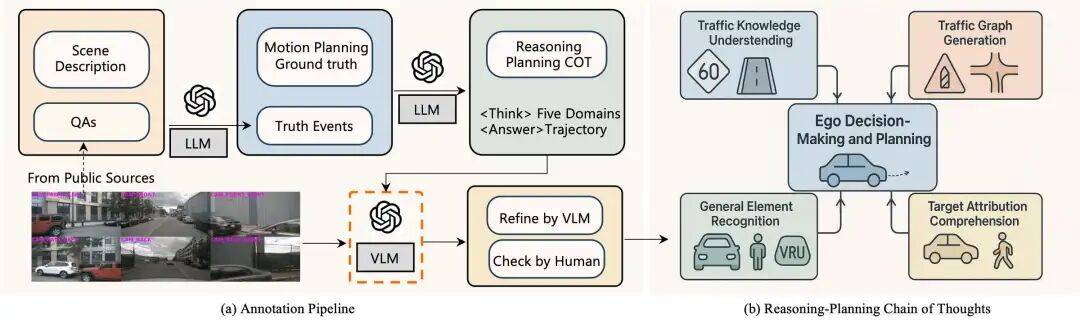
构建了涵盖交通知识理解等五大领域的RP-COT数据集,提供长短链推理标注,使模型学习视觉关联的结构化推理路径。
-
设计基于GRPO的强化学习机制,结合轨迹准确性、元动作正确性等多维度奖励,对齐推理过程与规划结果。
-
在nuScenes和DriveLM-nuScenes基准上实现SOTA性能,为VLMs在自动驾驶中融合推理与规划提供了有效方法。
-
ReCogDrive
-
论文标题:ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
-
论文链接:https://arxiv.org/abs/2506.08052
-
项目主页:https://github.com/xiaomi-research/recogdrive
-
提出机构:华中科技大学、小米汽车
-
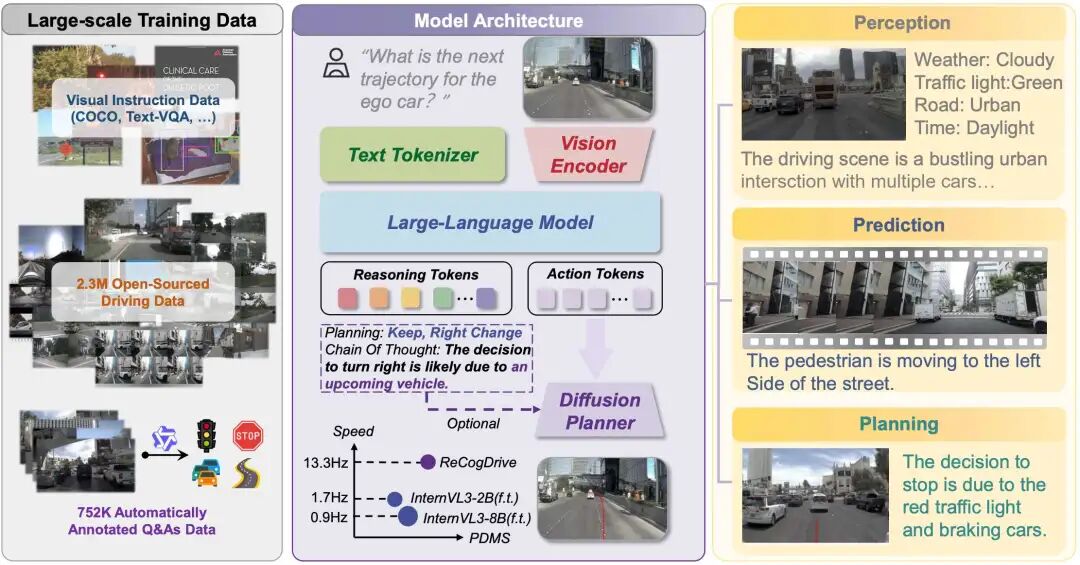
一句话总结:提出ReCogDrive框架,融合VLM认知推理与扩散规划器,通过分层数据管道注入驾驶先验,结合DiffGRPO强化学习优化,在NAVSIM等基准实现SOTA性能。
-
核心贡献:
-
设计生成、精炼、质控三阶段分层数据管道,构建大规模VQA数据集,为VLM注入类人驾驶认知先验。
-
提出认知引导扩散规划器,将VLM潜在语义表示转化为连续稳定轨迹,解决语言-动作模态不匹配问题。
-
提出DiffGRPO强化学习算法,基于模拟器奖励优化规划器,提升驾驶安全性与舒适性,突破模仿学习局限。
-
自动驾驶之心
端到端与VLA自动驾驶小班课!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)