PNN概率神经网络分类预测:从理论到Matlab实战
·
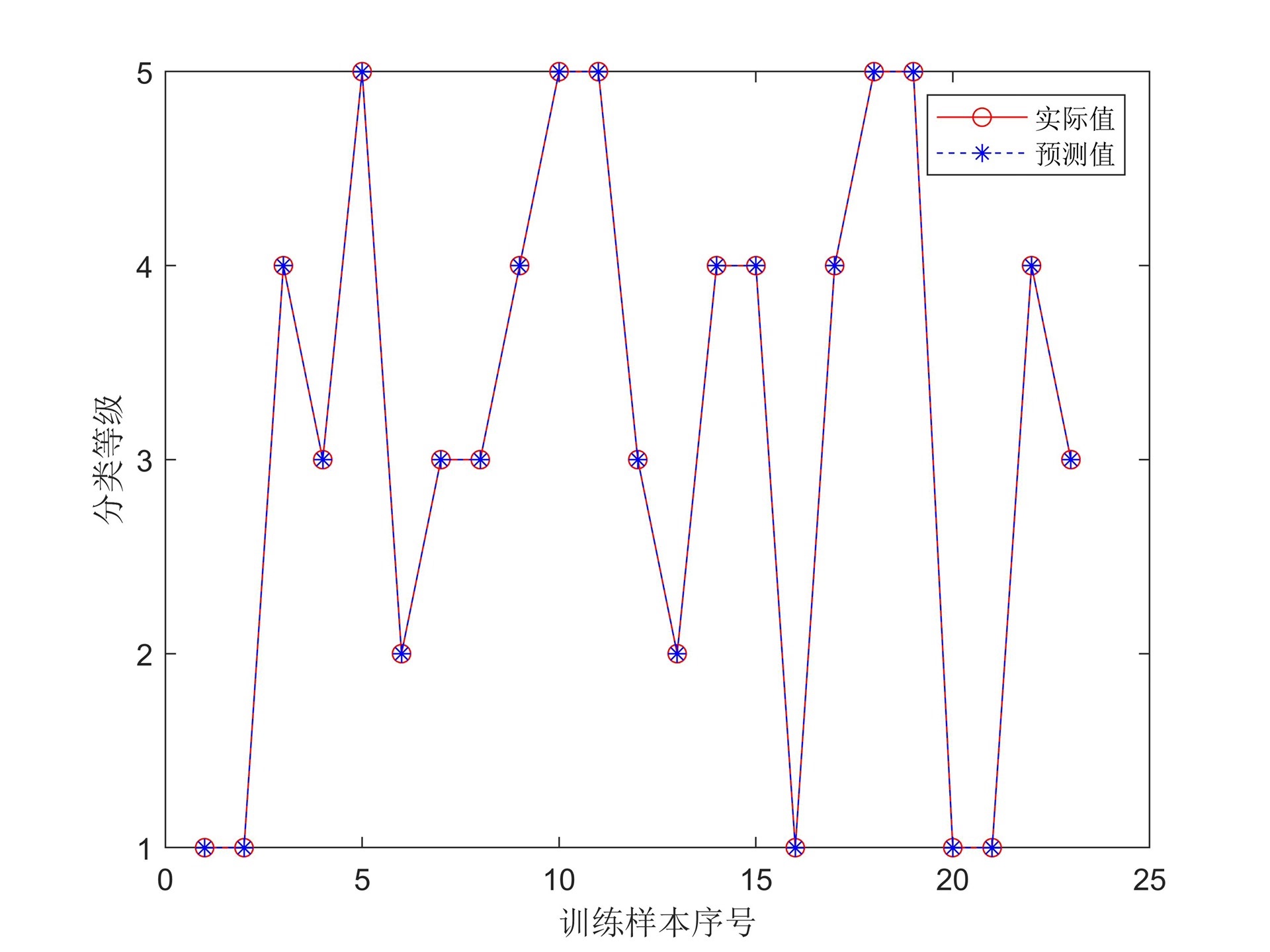
PNN概率神经网络分类预测 先根据训练数据选择合适的平滑因子,再对测试集进行预测 matlab代码,备注详细,根据自己需要修改案例数据即可
在机器学习的众多分类算法中,PNN(概率神经网络)以其独特的优势脱颖而出,常用于模式识别和分类任务。今天咱们就来唠唠如何用PNN进行分类预测,还会给出Matlab代码示例,大家按需修改案例数据就能上手。
一、PNN原理简要
PNN基于贝叶斯决策理论和Parzen窗概率密度估计方法。简单说,它通过计算样本到各类别中心的距离,依据概率密度来判断样本归属哪一类。其中,平滑因子是关键参数,它就像一个调节阀,控制着概率密度估计的平滑程度。平滑因子过小,模型对噪声敏感,容易过拟合;平滑因子过大,模型又会过于平滑,导致欠拟合。所以,选好平滑因子对PNN性能至关重要。
二、Matlab代码实现及分析
% 1. 加载数据
load fisheriris;
% 这里用经典的鸢尾花数据集举例,iris是特征数据,species是类别标签
features = meas;
labels = species;
% 2. 划分训练集和测试集
cv = cvpartition(labels, 'HoldOut', 0.3);
trainIdx = training(cv);
testIdx = test(cv);
trainFeatures = features(trainIdx, :);
trainLabels = labels(trainIdx);
testFeatures = features(testIdx, :);
testLabels = labels(testIdx);
% 3. 选择平滑因子(这里用试错法简单示例,实际应用可更复杂)
sigma = 0.1;
while true
net = newpnn(trainFeatures', trainLabels, sigma);
% newpnn函数创建PNN网络,第一个参数是训练特征转置,第二个是训练标签,第三个是平滑因子
predictedLabels = sim(net, testFeatures');
% sim函数对测试集进行预测
accuracy = sum(strcmp(predictedLabels', testLabels)) / numel(testLabels);
% 计算预测准确率
if accuracy > 0.8 % 假设期望准确率大于80%
break;
end
sigma = sigma + 0.1;
end
% 4. 输出结果
disp(['选择的平滑因子为: ', num2str(sigma)]);
disp(['预测准确率为: ', num2str(accuracy * 100), '%']);代码分析
- 数据加载:使用
load fisheriris加载鸢尾花数据集,这是Matlab自带的经典数据集。meas包含了花的各种特征,像萼片和花瓣的长度、宽度等,我们把它赋值给features;species是对应的类别标签,赋值给labels。 - 数据划分:
cvpartition函数将数据集按70%训练,30%测试的比例划分。training和test函数分别获取训练集和测试集的索引。然后根据索引提取出对应的特征和标签。 - 平滑因子选择:这里采用简单的试错法。从初始平滑因子
sigma = 0.1开始,每次增加0.1。用newpnn创建PNN网络并使用sim函数进行预测,计算预测准确率。当准确率大于设定的80%时,停止循环,确定合适的平滑因子。 - 结果输出:最后输出选择的平滑因子和预测准确率,让我们清楚了解模型性能。
通过上述代码和分析,大家应该对PNN概率神经网络分类预测在Matlab中的实现有了更清晰的认识。在实际应用中,大家可以根据自己的数据特点,灵活调整代码,比如采用更科学的平滑因子选择方法,或者优化数据预处理步骤等,来进一步提升模型性能。希望这篇博文能帮助大家在PNN的应用上迈出坚实的一步!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)