机器学习053:深度学习【经典神经网络】Transformer -- BERT、GPT与ViT
Transformer架构及其衍生模型(如BERT、GPT和ViT)正在推动人工智能的革命性发展。这些模型通过自注意力机制实现了对文本和图像的深度理解与生成,打破了传统序列处理的限制。BERT擅长上下文理解,GPT专注于文本生成,ViT则将Transformer应用于视觉领域。尽管这些模型在搜索、翻译、医疗等领域表现出色,但仍面临计算资源消耗大、数据需求高和可解释性差等挑战。随着技术进步,Tran
智能助手的“思考方式”
想象一下这样的场景:当你在手机上问Siri“附近有什么好吃的川菜馆”,它不仅能理解“川菜”是一种辣味菜肴,还能结合你的位置推荐具体餐厅;当你用谷歌翻译将中文文档转为英文时,它保持了原文的语义连贯性;当你在社交平台上传照片时,系统能自动识别图中的朋友并建议你标记他们。
这些看似“智能”的背后,都离不开一类革命性的神经网络——Transformer架构及其衍生模型。今天,我们就一起揭开BERT、GPT和ViT的神秘面纱,看看它们如何让机器学会“理解”和“创造”。
一、分类归属:Transformer家族的家谱
在神经网络大家庭中的位置
让我们先建立一个坐标系来定位这些技术:
按网络结构拓扑划分:
- Transformer 属于“自注意力网络”(Self-Attention Networks),它打破了传统序列处理的固定模式
- BERT 和 GPT 是Transformer的两个重要变体,像是一对性格迥异的双胞胎
- ViT(Vision Transformer)是将Transformer移植到图像领域的跨界选手
按功能用途划分:
- BERT:属于“理解型网络”,擅长从上下文中挖掘深层含义(像仔细阅读的学者)
- GPT系列:属于“生成型网络”,擅长根据已有信息创造新内容(像灵感迸发的作家)
- ViT:属于“视觉理解网络”,让计算机“看懂”图像内容
按训练方式划分:
- BERT:双向预训练(同时看前后文)
- GPT:单向自回归训练(从左到右逐步生成)
- ViT:将图像拆分为“视觉单词”进行训练
历史背景与核心问题
时间线:
- 2017年:Google团队发表《Attention Is All You Need》论文,Transformer诞生
- 2018年:BERT(Bidirectional Encoder Representations from Transformers)问世
- 2018-2023年:GPT-1到GPT-4相继推出,能力不断增强
- 2020年:ViT(Vision Transformer)出现,颠覆传统图像处理方式
要解决的核心问题:
- 传统RNN/LSTM的瓶颈:处理长文本时速度慢,难以捕捉远距离依赖关系
- 单向理解的局限:早期语言模型只能从左到右阅读,无法同时利用全文信息
- 图像与文本的割裂:计算机视觉和自然语言处理长期使用不同架构
关键人物:Ashish Vaswani(Transformer主要作者)、Jacob Devlin(BERT主要作者)、Alec Radford(GPT主要作者)
二、底层原理:Transformer如何“思考”
核心类比:图书馆的信息检索系统
想象一个巨大的智能图书馆:
传统图书馆(RNN/LSTM):图书管理员必须从第一本书开始,一本接一本地翻阅,想找后面的信息必须经过前面的所有书(顺序处理,速度慢)
Transformer图书馆:有一个超级检索系统,可以同时查看所有书籍的关联(并行处理),并且知道:
- “苹果”这个词在美食书籍和科技书籍中的不同含义(上下文感知)
- “他打开了门”中的“他”指的是前文提到的“小明”(长距离依赖)
核心设计:自注意力机制(Self-Attention)
通俗定义:让每个词都“环顾四周”,看看其他词对自己的理解有什么帮助
文字描述逻辑:
- 分词:将句子拆成单词,如“猫|坐在|垫子|上”
- 三要素生成:为每个词创建三个向量:
- 查询向量(Query):我想要什么信息?(如“坐”想知道谁在坐)
- 键向量(Key):我有什么信息?(如“猫”有“动物”这个信息)
- 值向量(Value):我的具体内容是什么?(如“猫”的具体特征)
- 匹配计算:计算每个词的Query与其他词的Key的匹配程度
- 信息整合:根据匹配程度,加权汇总所有词的Value
简单公式示意(了解即可):
注意力分数 = softmax( (Q × K^T) / √d_k )
输出 = 注意力分数 × V
其中d_k是向量的维度,√d_k是为了防止数值过大
BERT的特殊设计:双向掩码训练
类比:像做“完形填空”练习
BERT在训练时,会随机遮盖句子中的一些词(如15%),然后让模型根据前后所有词来预测被遮盖的词。这迫使它学会真正的双向理解。
GPT的特殊设计:单向自回归
类比:像写小说,一个字一个字地往下写
GPT只使用Transformer的解码器部分,训练时只能看到当前词之前的信息,然后预测下一个词。这种设计使它特别擅长生成连贯文本。
ViT的核心创新:图像分块处理
类比:将一幅画切割成拼图小块,然后像处理文字一样处理这些“视觉单词”
- 将图像分割成固定大小的块(如16×16像素)
- 每个块展平为向量,加上位置编码(记住每个块在原图中的位置)
- 送入Transformer进行处理
三、局限性:没有完美的模型
1. 计算资源消耗大
为什么:自注意力机制需要计算所有词对之间的关系,如果有n个词,就需要计算n²个注意力分数。
类比:在一个有1000人的会议上,如果每个人都要和其他999人交流一次,就需要近50万次交流!
实际影响:训练大型Transformer模型需要大量GPU和电力,个人电脑难以承受。
2. 需要大量标注数据
为什么:Transformer的强大能力部分来自于在海量数据上预训练。BERT的训练用了整个英文维基百科(25亿词)和图书语料库。
类比:要成为某个领域的专家,需要阅读该领域成千上万的书籍和论文。
实际影响:对于小众语言或专业领域,可能没有足够的数据训练出好模型。
3. “黑箱”特性明显
为什么:即使我们知道注意力机制在关注某些词,但我们很难完全理解模型内部的决策过程。
类比:我们知道某个厨师用了哪些食材,但不清楚他具体的烹饪秘诀。
实际影响:在医疗、法律等需要可解释性的领域,应用受到限制。
4. 生成内容可能“编造事实”
特别是GPT系列:它们擅长生成流畅文本,但无法保证内容真实性。
为什么:模型的目标是生成“看起来合理”的文本,而不是“绝对真实”的文本。
实际影响:可能生成看似可信的虚假信息,需要人工核查。
四、使用范围:什么任务适合它们?
适合使用Transformer的场景
BERT擅长:
- ✅ 文本分类(如情感分析、垃圾邮件检测)
- ✅ 问答系统(如智能客服、知识问答)
- ✅ 命名实体识别(从文本中提取人名、地名等)
- ✅ 语义相似度计算(判断两句话意思是否相近)
GPT系列擅长:
- ✅ 文本生成(写作助手、创意文案)
- ✅ 对话系统(聊天机器人)
- ✅ 代码生成(辅助编程)
- ✅ 文本续写(自动补全句子)
ViT擅长:
- ✅ 图像分类(识别图片中的物体)
- ✅ 目标检测(找出图中的特定物体)
- ✅ 图像分割(将图像分成有意义的区域)
不适合使用Transformer的场景
谨慎使用的情况:
- ❌ 实时性要求极高的系统:自注意力计算相对耗时
- ❌ 数据极度稀缺的领域:小数据难以发挥Transformer优势
- ❌ 需要完全可解释性的场景:如医疗诊断、自动驾驶
- ❌ 资源受限的嵌入式设备:模型太大,难以部署
传统方法可能更好的情况:
- 小规模文本分类:朴素贝叶斯或简单CNN可能足够
- 简单的时间序列预测:传统RNN或统计方法可能更有效
- 结构化数据预测:梯度提升树(如XGBoost)可能表现更好
五、应用场景:Transformer在我们身边
1. 智能搜索引擎(BERT的应用)
场景:你在百度搜索“苹果最新产品多少钱”
传统搜索引擎:只会查找包含“苹果”、“最新”、“产品”、“多少钱”这些关键词的网页
使用BERT的搜索引擎:
- 理解“苹果”在这里指的是科技公司,而不是水果
- 知道“最新产品”可能指iPhone 15而不是MacBook
- 能整合不同网页的信息,给出综合答案
BERT的作用:像一位理解力强的图书管理员,不仅找关键词,还理解问题的真正意图。
2. 智能写作助手(GPT的应用)
场景:使用Notion AI帮助撰写工作报告
你输入:“总结第三季度销售数据,重点突出华东地区的增长”
GPT生成:
“第三季度公司整体销售额达到1.2亿元,同比增长15%。其中华东地区表现尤为亮眼,实现销售额4500万元,同比增长28%,占总销售额的37.5%…”
GPT的作用:像一位经验丰富的秘书,根据你的要求组织语言和内容。
3. 医学影像分析(ViT的应用)
场景:医院使用AI辅助诊断肺部CT影像
传统方法:需要医生仔细查看每一张切片图像
使用ViT的系统:
- 将CT扫描的数百张图像分块处理
- 自动识别可疑结节、肿块等异常
- 标记出需要医生重点关注的区域
- 提供初步的诊断建议
ViT的作用:像一位不知疲倦的实习医生,先完成初步筛查,让专家医生聚焦关键问题。
4. 多语言实时翻译(Transformer全家福)
场景:Zoom会议中的实时翻译功能
系统工作流程:
- 语音识别(类似BERT的理解):将语音转为文字,理解上下文
- 机器翻译(Transformer核心):将一种语言翻译为另一种,保持语义连贯
- 语音合成(类似GPT的生成):将翻译后的文字转为自然语音
整个过程中,不同类型的Transformer模型协同工作,实现无缝交流。
5. 个性化内容推荐(BERT+Transformer)
场景:YouTube为你推荐下一个视频
系统如何工作:
- 分析你观看过的视频标题、描述、字幕(使用BERT理解内容)
- 结合其他类似用户的观看模式(使用注意力机制找出模式)
- 预测你可能感兴趣的下一个视频
- 生成推荐理由(“因为你看了A,可能会喜欢B”)
六、动手实践:用BERT进行情感分析
即使没有数学背景,我们也可以通过代码直观感受BERT的能力。以下是一个简单的Python示例:
# 情感分析示例:判断评论是正面还是负面
# 无需自己训练模型,直接使用预训练好的BERT
# 首先安装必要库(在命令行中运行):
# pip install transformers torch
from transformers import pipeline
# 加载预训练的情感分析模型(底层是BERT)
# 这就像是请来一位已经读过海量书评的专家
classifier = pipeline("sentiment-analysis")
# 准备一些测试评论
reviews = [
"这部电影太精彩了,演员演技都在线,剧情扣人心弦!",
"非常失望,剧情老套,特效也很廉价。",
"中规中矩,没什么亮点但也不差。",
"这款手机电池续航超强,拍照效果也很惊艳!",
"服务态度极差,再也不会光顾这家店了。"
]
# 让模型分析每条评论的情感
print("=== 情感分析结果 ===")
for review in reviews:
result = classifier(review)[0]
label = "👍 正面" if result['label'] == 'POSITIVE' else "👎 负面"
confidence = result['score'] * 100
print(f"评论:{review}")
print(f"情感:{label} (置信度:{confidence:.1f}%)")
print("-" * 50)
# 你也可以试试自己的句子
your_text = input("\n请输入你想分析的一句话:")
if your_text:
result = classifier(your_text)[0]
label = "正面" if result['label'] == 'POSITIVE' else "负面"
print(f"\n分析结果:{label}情感,置信度{result['score']*100:.1f}%")
这段代码做了什么:
- 从Hugging Face模型库加载了一个预训练好的中文BERT模型
- 这个模型已经学会了中文情感表达的规律
- 它分析每条评论,判断是正面还是负面,并给出置信度
运行结果可能类似:
评论:这部电影太精彩了,演员演技都在线,剧情扣人心弦!
情感:👍 正面 (置信度:99.8%)
------------------------------------------
评论:非常失望,剧情老套,特效也很廉价。
情感:👎 负面 (置信度:99.5%)
------------------------------------------
通过这个简单例子,你可以看到BERT如何理解人类语言中的情感色彩。
七、总结与展望
一句话概括核心价值
Transformer及其衍生模型的核心价值是:让机器学会了真正的“上下文理解”和“关联思维”,打破了传统神经网络处理序列数据的局限性。
学习重点梳理
对于初学者,掌握Transformer家族的关键是理解:
- 自注意力机制:如何让每个词都能“关注”其他相关词
- BERT vs GPT的根本区别:双向理解 vs 单向生成
- 预训练+微调的模式:先在海量数据上学习通用知识,再针对特定任务调整
- 适用场景选择:理解型任务用BERT,生成型任务用GPT,图像任务考虑ViT
未来发展方向
- 多模态融合:让模型同时理解文本、图像、声音等多种信息
- 更高效的架构:减少计算资源消耗,让更多人能用上
- 更好的可解释性:让模型的“思考过程”更透明
- 专业领域适配:为医疗、法律、科学等专业领域定制模型
思维导图:Transformer家族全览
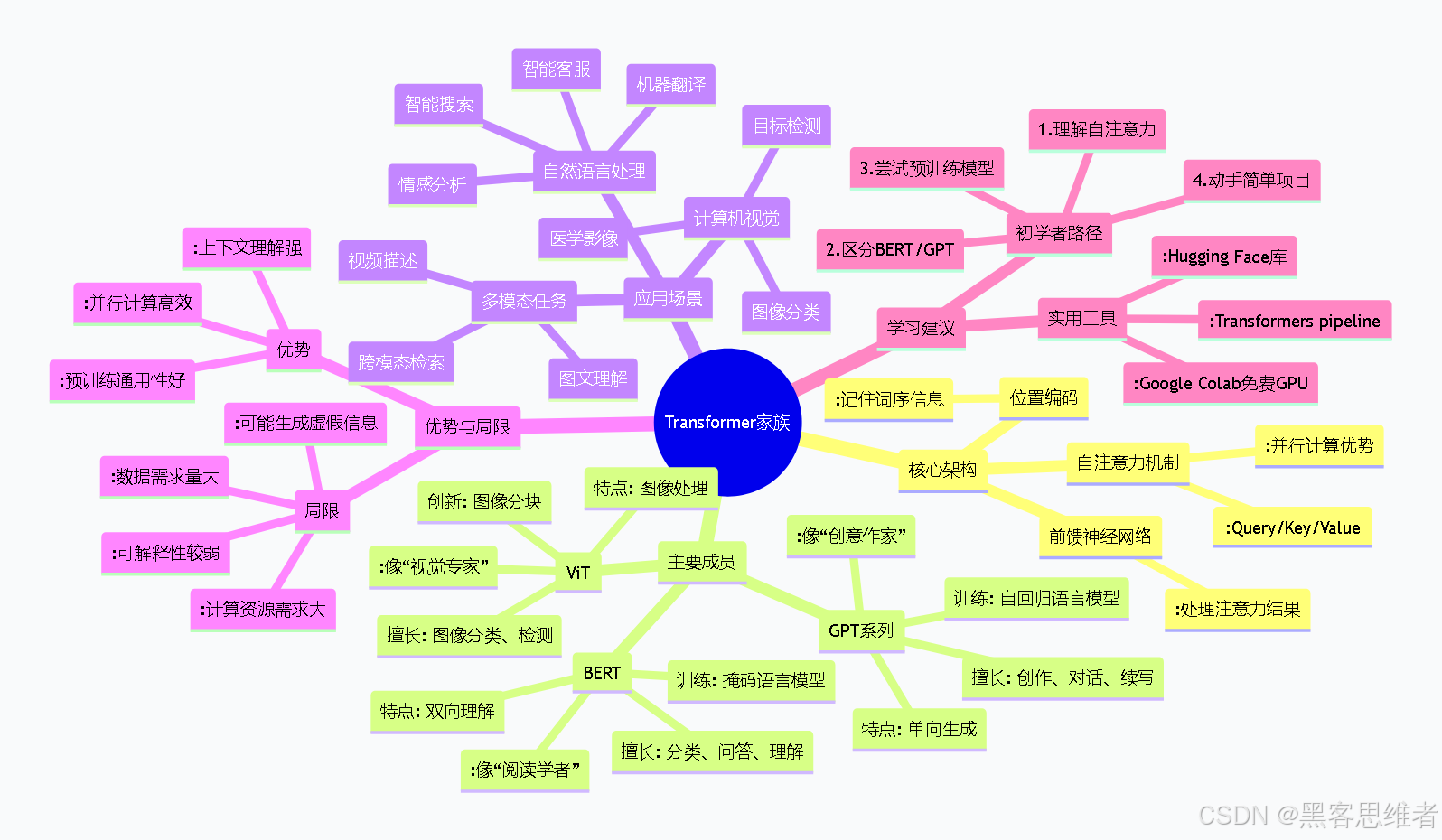
mindmap
root((Transformer家族))
核心架构
自注意力机制
:Query/Key/Value
:并行计算优势
位置编码
:记住词序信息
前馈神经网络
:处理注意力结果
主要成员
BERT
特点: 双向理解
训练: 掩码语言模型
擅长: 分类、问答、理解
:像“阅读学者”
GPT系列
特点: 单向生成
训练: 自回归语言模型
擅长: 创作、对话、续写
:像“创意作家”
ViT
特点: 图像处理
创新: 图像分块
擅长: 图像分类、检测
:像“视觉专家”
应用场景
自然语言处理
智能搜索
机器翻译
情感分析
智能客服
计算机视觉
图像分类
目标检测
医学影像
多模态任务
图文理解
视频描述
跨模态检索
优势与局限
优势
:上下文理解强
:并行计算高效
:预训练通用性好
局限
:计算资源需求大
:数据需求量大
:可解释性较弱
:可能生成虚假信息
学习建议
初学者路径
1.理解自注意力
2.区分BERT/GPT
3.尝试预训练模型
4.动手简单项目
实用工具
:Hugging Face库
:Transformers pipeline
:Google Colab免费GPU

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 58
58 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)