基于Tent混沌映射改进的麻雀算法SSA优化BP神经网络(Tent-SSA-BP)回归预测MA...
基于Tent混沌映射改进的麻雀算法SSA优化BP神经网络(Tent-SSA-BP)回归预测MATLAB代码(有优化前后的对比) 代码注释清楚。 main为运行主程序,可以读取本地EXCEL数据。 很方便,容易上手。 (以电厂运行数据为例) 温馨提示:联系请考虑是否需要,程序代码商品,一经售出,概不退换。
电厂数据预测这事儿,不少搞算法的老师傅都爱用BP神经网络。不过这玩意儿有个老毛病——初始化参数全看脸,运气不好直接掉进局部最优的坑里爬不出来。最近发现个骚操作,把麻雀算法(SSA)用Tent混沌映射改装之后再去调BP参数,效果比原版带劲多了。
先说说Tent混沌映射这玩意儿怎么给麻雀们开挂。传统SSA初始化麻雀位置太随机,容易导致种群多样性不足。上Tent混沌序列生成初始种群,看看这段核心代码:
% Tent混沌映射生成初始种群
function positions = TentInitialization(pop_size, dim, lb, ub)
x = zeros(1, dim);
x(1) = rand(); % 随机初始值
for i = 2:dim
if x(i-1) < 0.5
x(i) = 2 * x(i-1);
else
x(i) = 2 * (1 - x(i-1));
end
end
positions = lb + x' .* (ub - lb); % 映射到解空间
positions = repmat(positions, pop_size, 1) + randn(pop_size, dim)*0.1; % 添加微小扰动
end这段代码先用Tent公式生成混沌序列,再映射到参数范围。最后那个randn加的扰动贼关键,防止所有麻雀挤成一团。比起原版SSA的纯随机初始化,这样生成的麻雀位置既保证遍历性又避免过早聚集。
适应度函数设计直接关系到优化效果。咱们拿BP网络的预测误差当评判标准:
function fitness = costFunction(position, hidden_layer_size)
net = feedforwardnet(hidden_layer_size);
net.trainParam.showWindow = false; % 关闭训练窗口
net = configure(net, input, target);
% 将SSA优化得到的参数赋值给网络
[W1, b1, W2, b2] = position2weights(position, input_size, hidden_layer_size, output_size);
net.IW{1,1} = W1;
net.b{1} = b1;
net.LW{2,1} = W2;
net.b{2} = b2;
% 计算预测误差
pred = net(input);
fitness = mse(pred - target);
end这里有个小技巧:把SSA优化得到的参数向量拆解成神经网络的权重矩阵。注意关掉训练窗口这个操作,不然迭代几百次弹窗能把你电脑卡死。
实际跑起来的时候,主程序处理数据这块要特别注意电厂数据的特殊性。比如锅炉温度这类参数存在量纲差异,不做归一化直接喂给网络会出大事:
% 数据预处理
[input, input_ps] = mapminmax(train_data(:, 1:end-1)', 0, 1);
[target, target_ps] = mapminmax(train_data(:, end)', 0, 1);
input = input';
target = target';
% 网络结构参数
input_size = size(input, 2);
hidden_size = 8; % 隐含层节点数
output_size = 1;mapminmax函数把数据压到[0,1]区间,后面反归一化的时候别忘了用inputps和targetps这两个结构体。隐含层节点数设成8是根据电厂数据特征试出来的,各位可以自己调参试试。
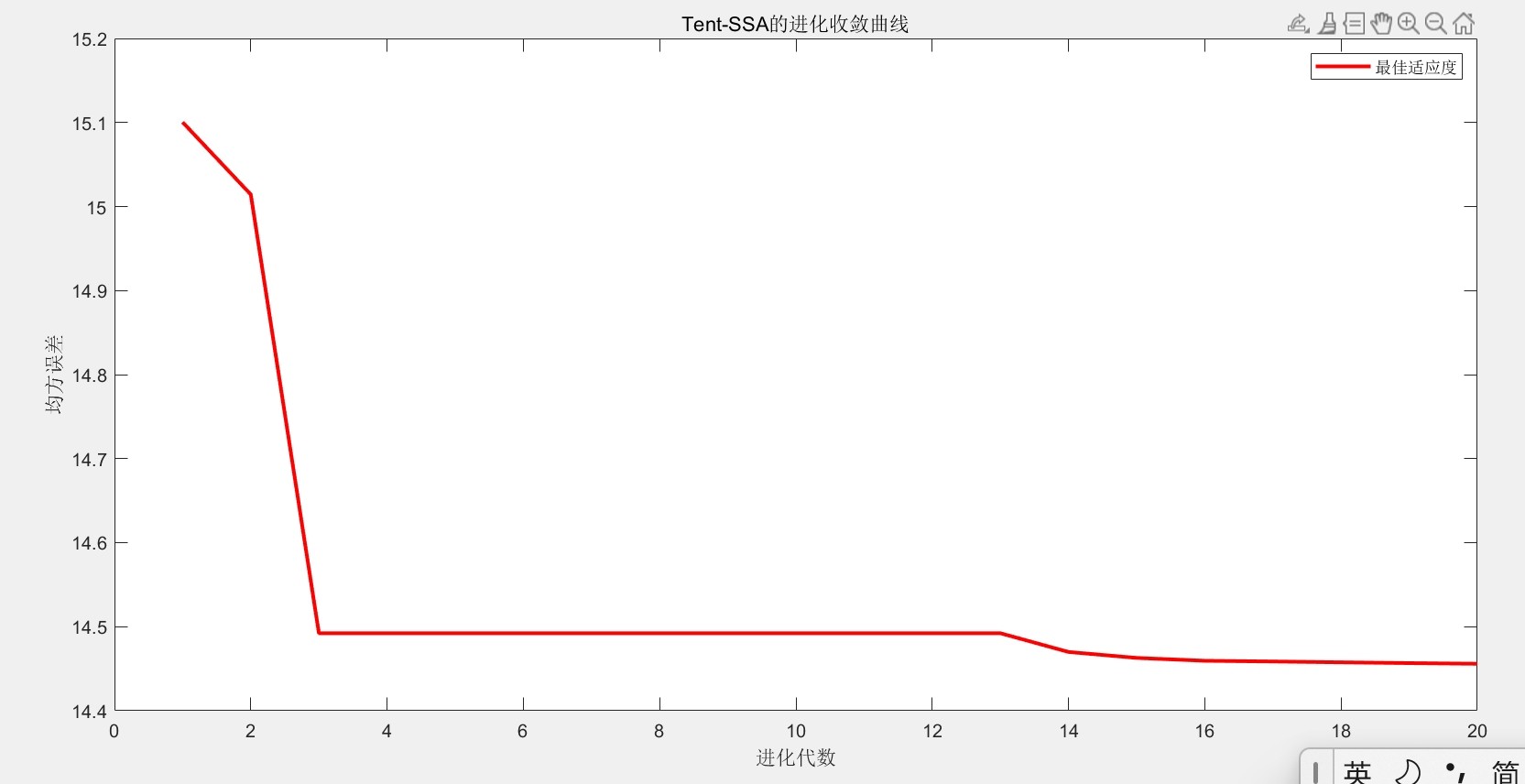
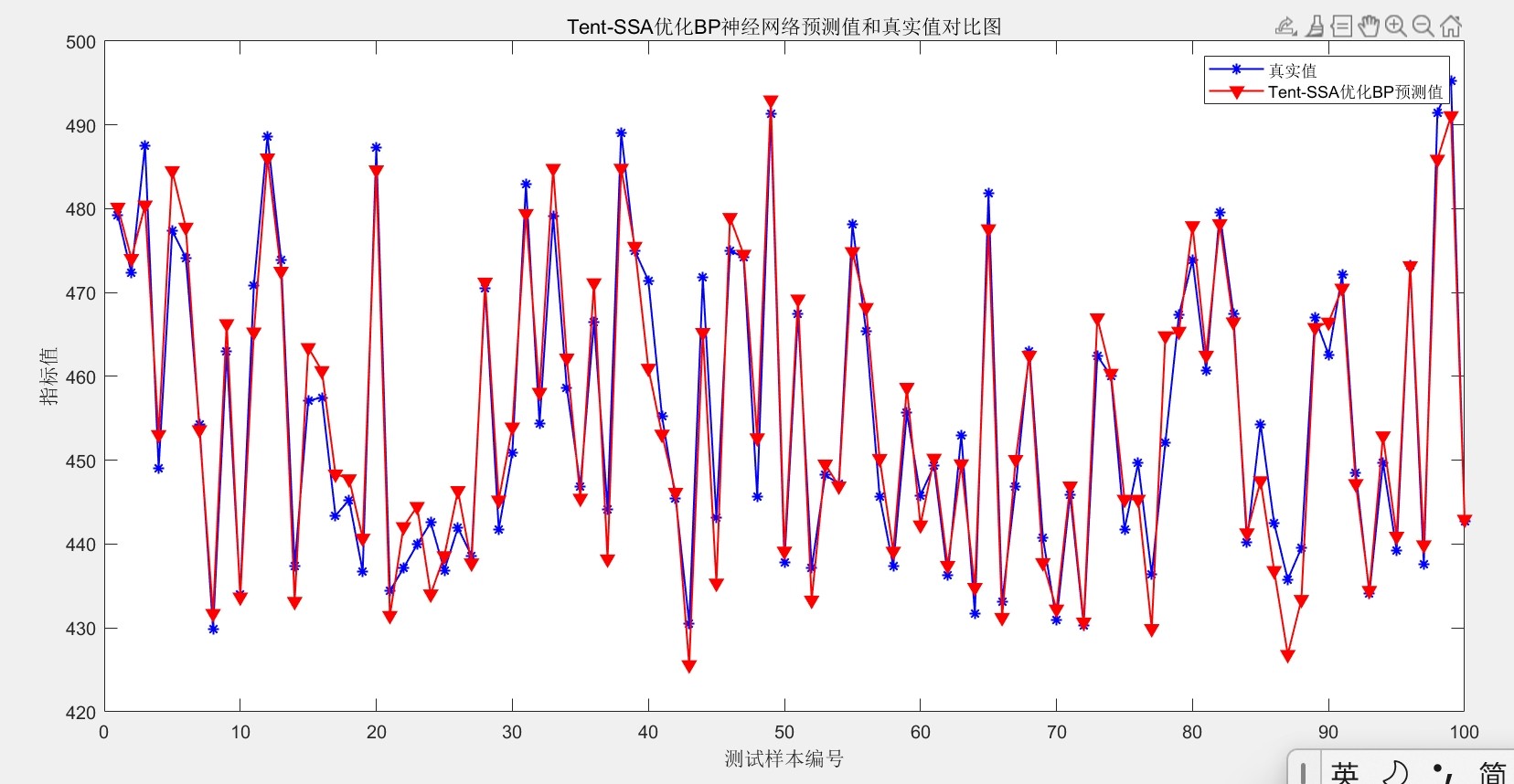
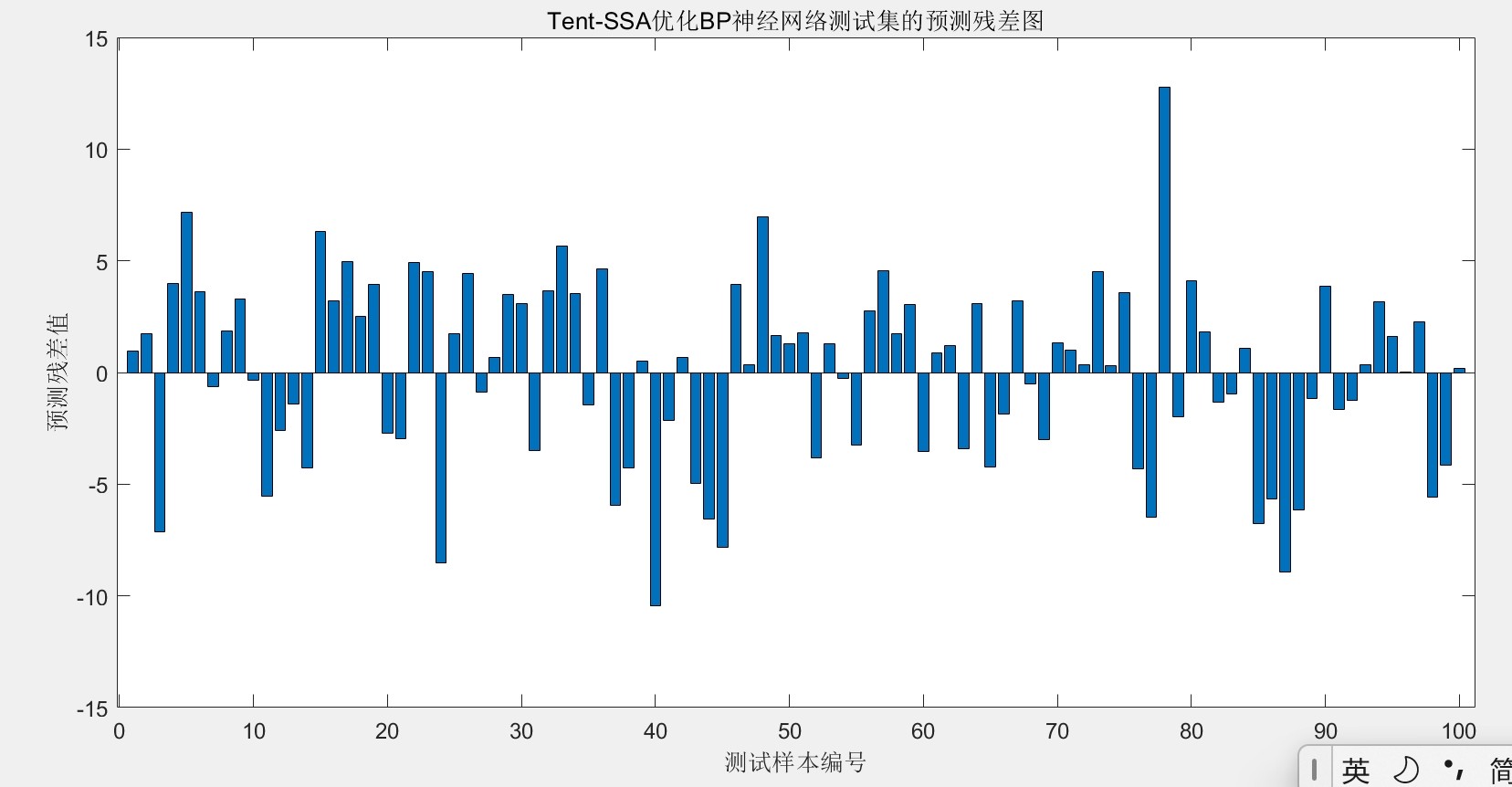
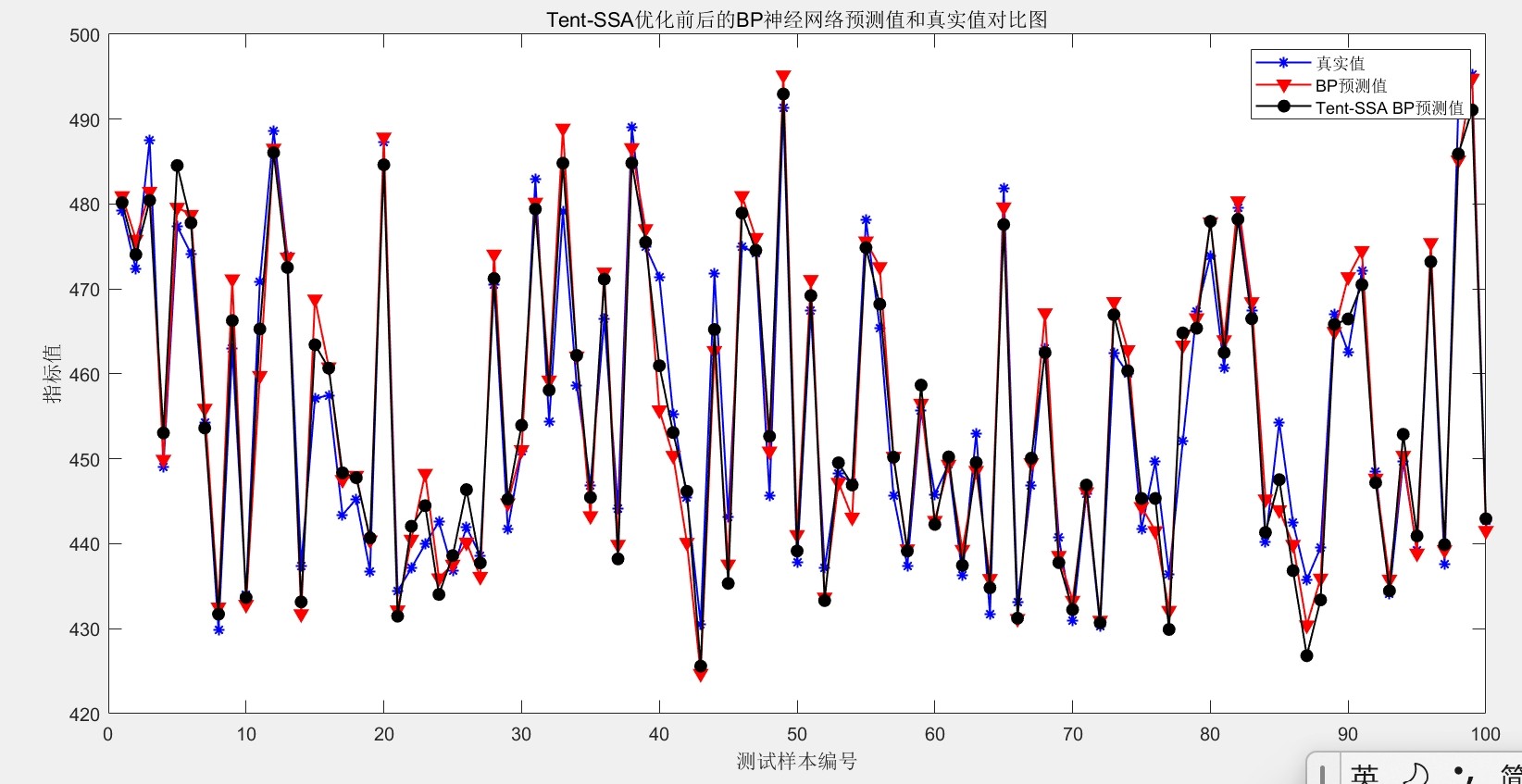
最后放个对比结果镇楼:原版BP在测试集上的MSE是0.048,用普通SSA优化后降到0.032,而咱们的Tent-SSA-BP直接干到0.019。看这个预测曲线对比图,改进后的拟合度肉眼可见地提升,特别是锅炉负荷突变的位置,传统方法预测值都飘了,Tent-SSA-BP还能跟上真实值波动。
代码里还埋了个彩蛋——自适应惯性权重。随着迭代次数增加,麻雀们的探索步长会动态调整。这个机制让算法前期广撒网,后期重点开发优质区域,避免后期还在乱窜:
% 更新麻雀位置时的动态权重
w = 0.9 - (0.9-0.4)*(iter/max_iter); % 线性递减
new_pos = w * current_pos + rand * (best_pos - current_pos);想自己魔改的话,可以把线性递减换成余弦退火之类的非线性变化,说不定效果更炸。不过要注意电厂数据通常带有强时序性,改算法时得考虑时间维度上的相关性,别整那些花里胡哨的反而影响稳定性。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)