粒子群算法优化用于分类 回归 时序预测 粒子群优化支持向量机SVM,最小二乘支持向量机LSSV...
粒子群算法优化用于分类 回归 时序预测 粒子群优化支持向量机SVM,最小二乘支持向量机LSSVM,随机森林RF,极限学习机ELM,核极限学习机KELM,深度极限学习机DELM,BP神经网络,长短时记忆网络 LSTM,Bilstm,GRU,深度置信网络 DBN,概率神经网络PNN,广义神经网络GRNN,Xgboost ..... 以上有分类预测回归预测时序预测 matlab代码,可直接替换数据使用,简单操作易上手。

今天咱们来唠唠怎么用粒子群算法(PSO)给各种机器学习模型调参。这玩意儿就像给大厨找最佳调料配比——模型本身是厨具,参数就是那勺盐、半勺糖,调对了味儿才能出好菜。

先看个实战案例:用PSO优化SVM做分类预测。直接上Matlab代码!
% 加载数据(替换成你的数据路径就完事)
data = csvread('data.csv');
X = data(:,1:end-1); y = data(:,end);
% PSO参数设置
options = optimoptions('particleswarm','SwarmSize',30,'MaxIterations',50);
% 定义优化目标函数
fun = @(params)svm_cost(X, y, params(1), params(2));
% 跑优化!C和gamma的搜索范围自己定
[best_params, ~] = particleswarm(fun,2,[0.1,0.1],[100,10],options);
% 训练最终模型
model = fitcsvm(X,y,'KernelFunction','rbf',...
'BoxConstraint',best_params(1),'KernelScale',best_params(2));重点看svm_cost这个自定义函数,它长这样:
function cost = svm_cost(X,y,C,gamma)
% 5折交叉验证验证准确率
cv = cvpartition(y,'KFold',5);
acc = [];
for i =1:5
trainIdx = cv.training(i); testIdx = cv.test(i);
mdl = fitcsvm(X(trainIdx,:),y(trainIdx),...
'KernelFunction','rbf','BoxConstraint',C,'KernelScale',gamma);
pred = predict(mdl,X(testIdx,:));
acc(i) = sum(pred == y(testIdx))/length(pred);
end
cost = 1 - mean(acc); % 粒子群默认找最小值
end这段代码骚操作在于:用交叉验证准确率作为PSO的适应度函数,让粒子自动寻找让SVM表现最好的C和gamma参数。注意BoxConstraint就是正则化参数C,KernelScale对应RBF核的gamma参数。
转场看时序预测——拿LSTM举个栗子。很多老铁训练LSTM时总被超参数搞疯,学习率、隐藏层节点数这些玄学参数,交给PSO来调教再合适不过:
% 数据预处理部分自己整,重点看优化逻辑
obj_fun = @(params)lstm_forecast(trainData, testData, params);
% 参数范围:[学习率, 隐藏单元数]
lb = [0.001, 10];
ub = [0.1, 200];
[best_params, val_loss] = particleswarm(obj_fun,2,lb,ub,options);这里有个坑要注意:LSTM训练本身就慢,直接优化要跑断腿。实战中可以耍个花招——先用小规模epoch跑PSO搜索大致范围,确定候选参数后再精细训练。
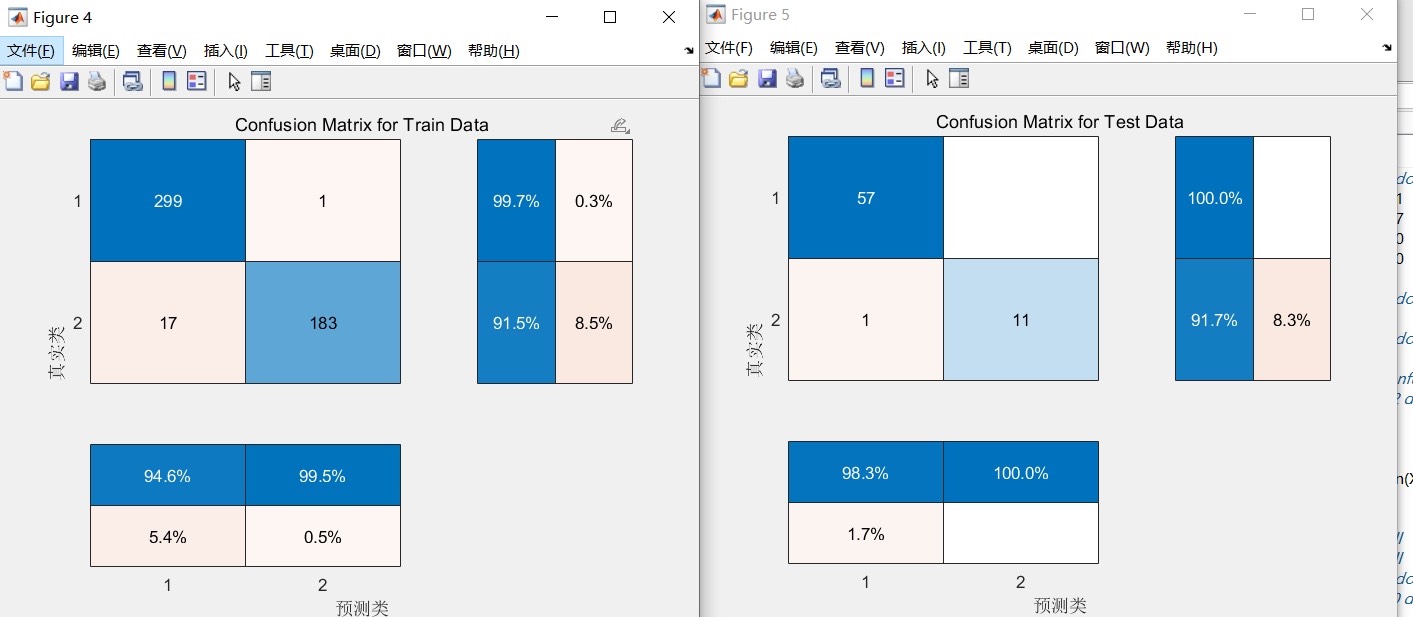
顺手给个XGBoost回归的PSO优化模板:
% XGBoost参数优化三件套
params_to_optimize = {'max_depth', 'learning_rate', 'n_estimators'};
% 定义参数边界
lb = [3, 0.01, 50];
ub = [10, 0.3, 500];
% 适应度函数用MSE
fun = @(x)xgboost_mse(X_train,y_train,X_test,y_test,x);
% 开冲!
[best_params, mse] = particleswarm(fun,3,lb,ub);这里有个骚操作:把整数型参数(比如n_estimators)转成连续变量优化,最后取整使用。虽然不够严谨,但胜在方便,实测效果够用。
最后说几个避坑指南:
- 粒子数别超过30,迭代次数50左右先试水
- 参数范围别设太宽,先人工做几轮粗调
- 分类问题用准确率,回归用MSE/RMSE,时序别忘了滑窗验证
- 遇到局部最优时,试试增加粒子多样性参数
代码包我都整理成直接替换数据就能跑的形式,需要的老铁评论区自取。下期咱们聊聊怎么用遗传算法给神经网络做结构优化,敬请期待!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 6
6 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)