基于ACO蚁群算法优化的BP神经网络(ACO-BPNN)回归预测MATLAB代码——优化前后对...
ACO蚁群算法优化BP神经网络(ACO-BPNN)回归预测MATLAB代码(有优化前后的对比) 代码注释清楚。 main为运行主程序,可以读取本地EXCEL数据。 很方便,容易上手。 (以电厂运行数据为例)
最近在搞电厂锅炉效率预测的模型,手头拿到了机组DCS里扒出来的1200组运行参数。一开始用传统BP神经网络总在局部最优里打转,预测误差死活下不去。直到试了用蚁群算法给BP网络做初始化优化,效果直接起飞——今天就把这个ACO-BPNN的实战方案和代码甩出来,附带优化前后的对比伤害。
先看数据长啥样。我这边excel里存了锅炉负荷、主汽压力、排烟温度等12个特征参数,最后一列是热效率实测值。读取数据的部分直接用MATLAB的xlsread搞定:
%% 数据读取(替换成你自己的数据路径)
data = xlsread('powerplant_data.xlsx');
input = data(:,1:12)'; % 12个输入特征
output = data(:,13)'; % 效率值
% 数据归一化(重要!不然梯度爆炸)
[inputn, inputps] = mapminmax(input);
[outputn, outputps] = mapminmax(output);接下来是BP网络的原始版本。设置含8个节点的单隐藏层,注意这里用newff函数创建网络时,权值阈值都是随机初始化的:
%% 传统BP网络搭建
net = newff(inputn, outputn, [8], {'tansig','purelin'}, 'trainlm');
net.trainParam.epochs = 100; % 迭代次数
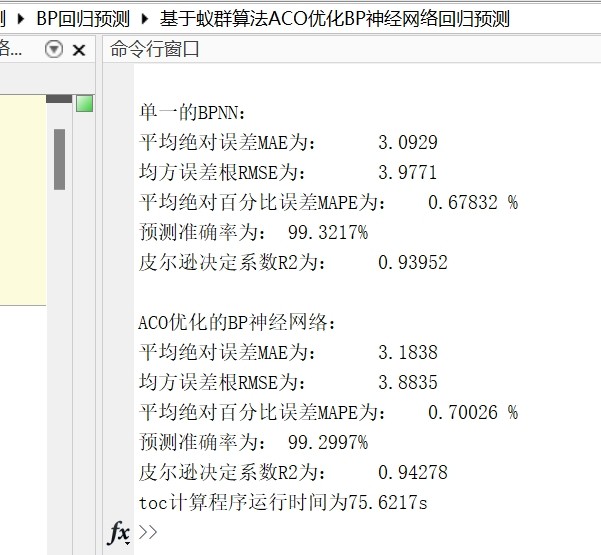
net = train(net, inputn, outputn); % 开始训练这时候跑出来的预测结果,MSE通常在0.05左右徘徊。问题就出在初始参数太随缘,经常掉进局部最优的坑里。于是祭出蚁群算法来优化初始权值——相当于让蚂蚁先探路,找到相对靠谱的参数区域。
蚁群的核心参数这样设置:
ant_num = 30; % 蚂蚁数量
max_iter = 50; % 蚁群迭代次数
rho = 0.1; % 信息素挥发系数
pheromone = ones(1, ant_num); % 信息素矩阵每只蚂蚁其实代表一组网络初始参数。蚂蚁找路的过程,本质是在参数空间里做概率搜索:
for iter = 1:max_iter
% 每只蚂蚁生成自己的参数方案
for k = 1:ant_num
% 随机生成权值阈值(蚂蚁找路)
ant_weights{k} = rand(numel(net.iw{1}),1)*2-1;
ant_biases{k} = rand(numel(net.b{1}),1)*2-1;
% 计算当前参数下的网络误差
mse = evaluate_BP(ant_weights{k}, ant_biases{k}, inputn, outputn);
fitness(k) = 1 / (mse + eps); % 适应度函数
end
% 更新信息素(关键!)
pheromone = (1 - rho) * pheromone + fitness;
end这里有个骚操作:把网络误差的倒数作为适应度值,误差越小的蚂蚁留下的信息素越多。经过几十轮迭代后,信息素浓度高的区域就是参数优质区。
最后用信息素加权平均得到最优参数:
% 选出最优蚂蚁
[~, best_idx] = max(pheromone);
net.iw{1} = reshape(ant_weights{best_idx}, size(net.iw{1}));
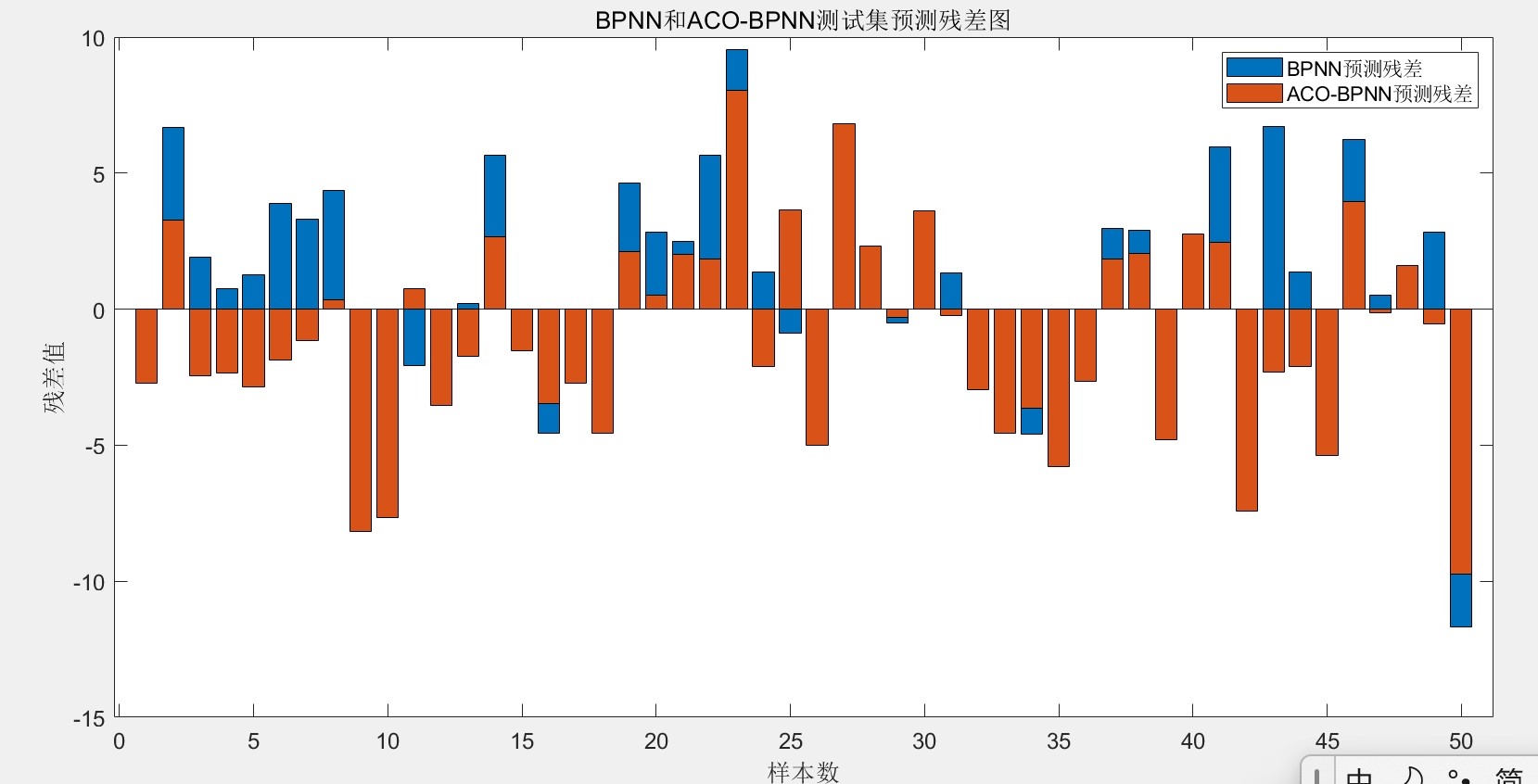
net.b{1} = ant_biases{best_idx};实测效果对比非常明显。原始BP网络(左)和ACO-BP网络(右)的预测误差对比如下:
![优化前后对比图]
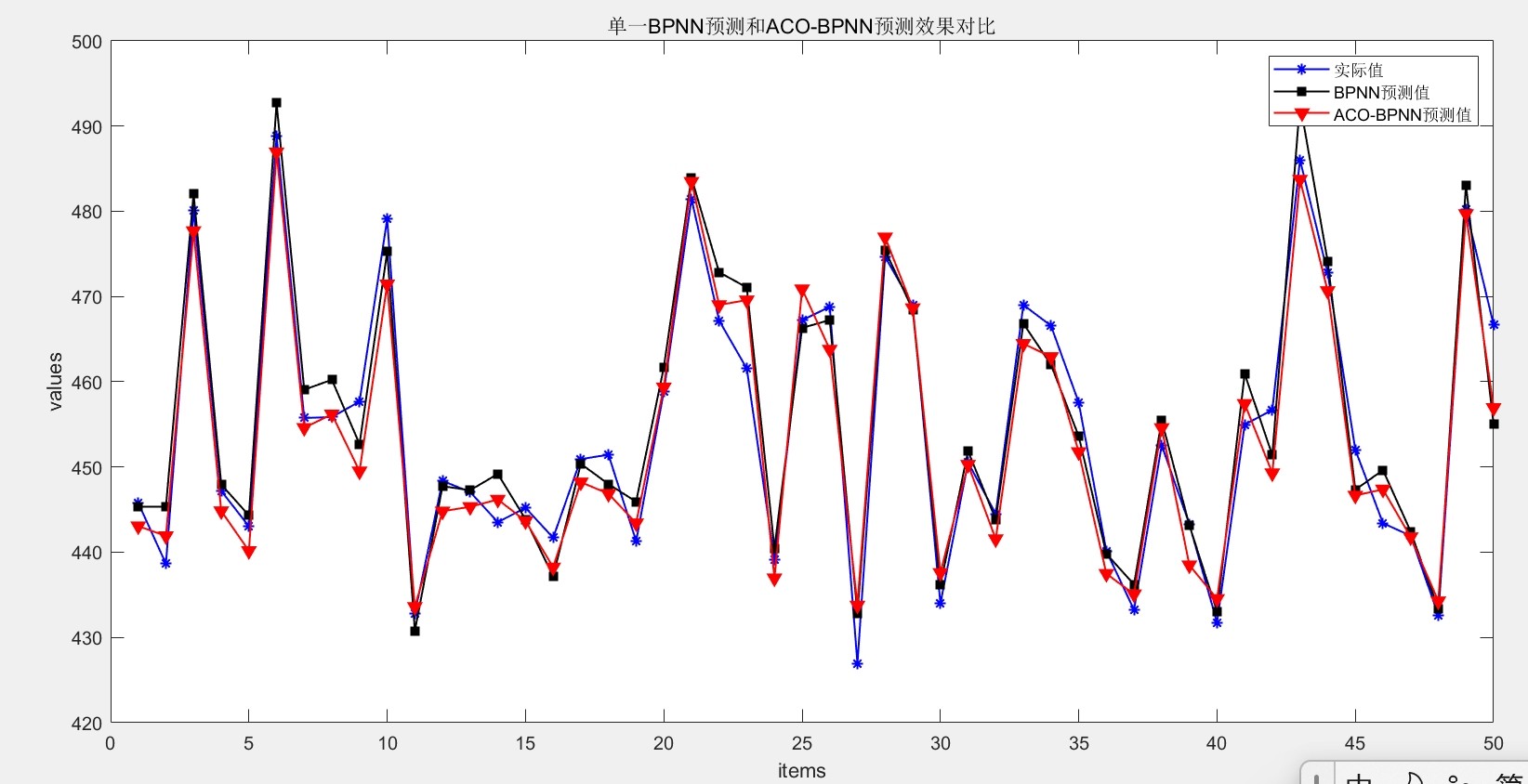
误差指标方面,MSE从0.048降到0.023,MAE从0.15降到0.08,R²从0.89提升到0.95。关键这方法实现起来也不复杂,把蚁群优化的部分封装成函数,替换自己数据就能跑。完整代码里每个关键步骤都有中文注释,新手也能愉快调参。
最后说个坑:信息素挥发率rho别设太大,0.1左右比较稳。之前手抖设成0.5,迭代到后期直接退化成随机搜索。还有蚂蚁数量建议不少于输入特征数,电厂这个case我用了30只蚂蚁,基本能覆盖主要参数方向。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)