yolov8 训练
本文记录了在RK3399开发板上使用YOLOv8n模型进行目标检测(以人脸检测为例)的完整流程。作者对比了YOLOv8n和NanoDet的性能差异,最终选择YOLOv8n进行实现。主要内容包括:1) 数据准备与标注转换,使用LabelImg工具标注2000张图片并转换为YOLO格式;2) 模型训练,配置YAML文件并训练100个epoch;3) 模型验证与导出,测试模型效果并转换为TorchScr
还是老板子:rk3399,需要进行目标检测,类似人脸框检测吧,看了下还是用yolov8吧,速度精度都还可以,开始准备选择是naodet 但是可能是我的数据质量问题吧,精度一直达不到,所以最后综合考虑还是选择了yolo家族的yolov8n,这里记录下训练过程方便后续记忆
| 对比项 | YOLOv8n | NanoDet |
|---|---|---|
| 模型结构 | 更现代(Anchor-free + PAFPN) | 轻量但较旧(基于 ShuffleNet/GhostNet) |
| 精度上限 | 高(COCO mAP ~37.3) | 中(COCO mAP ~20~25) |
| 社区支持 | 官方维护(Ultralytics),生态完善 | 社区维护,更新慢 |
| 部署友好性 | 支持 ONNX / TensorRT / NCNN / OpenVINO | 主要依赖 NCNN,RK3399 适配需手动 |
| 数据敏感度 | 对标注质量要求高,但容错更强 | 小模型对噪声更敏感,易欠拟合 |
地址:https://github.com/ultralytics/ultralytics
代码准备:git clone https://github.com/ultralytics/ultralytics.git
一、数据准备
首先准备数据,检测对象的数据,网络爬取或者现场采集,大约2000张各种不同种类的照片,比如最简单采集的人脸照片,这里不暴露项目内容,采用人脸替代吧。
1.1 数据标注
LabelImg 下载地址:https://github.com/HumanSignal/labelImg/releases
通过标注矩形框进行数据标准,可以先标注一部分,然后训练出模型,然后通过模型标注剩余的图片,然后再手工微调,这样数据标注就可以提速了,也可以在少数数据量的情况下用数据增强(原图旋转、翻转、加噪点、马赛克等)
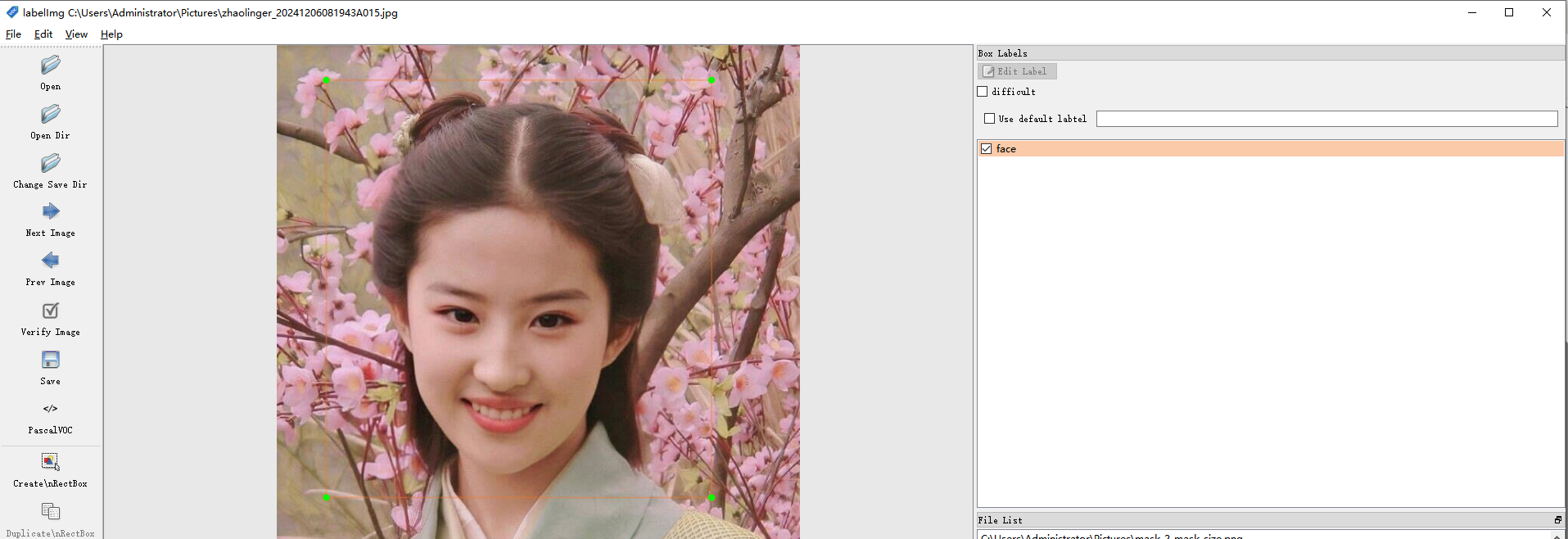
数据标注之后会 一个xml文件
具体如下,就是把图片地址、尺寸及目标类型和矩形框的坐标进行标注了
<!-- 整个标注文档的根元素,表示这是一个目标检测的标注 -->
<annotation>
<!-- 图像所属的文件夹名称(通常用于组织数据集结构) -->
<folder>OXIIIT</folder>
<!-- 图像文件名(不含路径) -->
<filename>4000.jpg</filename>
<!-- 图像来源信息 -->
<source>
<!-- 数据集名称 -->
<database>Dataset</database>
<!-- 标注类型或来源(此处为缩写 OXIIIT,可能指 Oxford-IIIT) -->
<annotation>OXIIIT</annotation>
<!-- 图像原始来源 -->
<image>none</image>
</source>
<!-- 图像尺寸信息 -->
<size>
<!-- 图像宽度(像素) -->
<width>500</width>
<!-- 图像高度(像素) -->
<height>667</height>
<!-- 图像通道数(3 表示 RGB 彩色图) -->
<depth>3</depth>
</size>
<!-- 是否包含分割掩码(1 表示有,0 表示无;目标检测任务通常为 0) -->
<segmented>0</segmented>
<!-- 一个目标对象的标注信息(可有多个 <object>) -->
<object>
<!-- 目标类别名称(此处为 "face",但注意:原 Oxford-IIIT Pet 数据集通常标注宠物品种,这里可能是自定义修改) -->
<name>face</name>
<!-- 目标姿态(如 Frontal、Left、Right 等,常用于人脸或物体朝向) -->
<pose>Frontal</pose>
<!-- 是否被截断(1 表示目标在图像边界被裁切,0 表示完整) -->
<truncated>0</truncated>
<!-- 是否被遮挡(1 表示部分不可见,0 表示完全可见) -->
<occluded>0</occluded>
<!-- 边界框坐标(以像素为单位) -->
<bndbox>
<!-- 左上角 x 坐标 -->
<xmin>90</xmin>
<!-- 左上角 y 坐标 -->
<ymin>147</ymin>
<!-- 右下角 x 坐标 -->
<xmax>333</xmax>
<!-- 右下角 y 坐标 -->
<ymax>374</ymax>
</bndbox>
<!-- 是否为“难例”(1 表示模糊、极小或难以识别,通常训练时可忽略;0 表示正常样本) -->
<difficult>0</difficult>
</object>
</annotation>1.2 数据格式转换
标注完成转换成yolov8的数据格式,yolov8默认的图片和标注位置对应
数据构造格式:
data
|__ images
├─ 001.jpg
├─ 002.jpg
├─ ..
└─ NNN.jpg
|__ labels
├─ 001.txt
├─ 002.txt
├─ ..
└─ NNN.txt把xml格式转换为txt格式,txt格式如下
<class_id> <x_center> <y_center> <width> <height>
0 0.631667 0.287500 0.153333 0.215000| 字段 | 值 | 含义 |
|---|---|---|
class_id |
0 |
类别索引,表示第 0 类(例如:face、person 等,具体看你的 data.yaml 中的 names 定义) |
x_center |
0.631667 |
目标边界框中心点的 x 坐标(归一化) |
y_center |
0.287500 |
目标边界框中心点的 y 坐标(归一化) |
width |
0.153333 |
边界框宽度(归一化) |
height |
0.215000 |
边界框高度(归一化) |
提供一段转换代码
import io
import os
import shutil
import xml.etree.ElementTree as ET
from pathlib import Path
def convert_voc_to_yolo(xml_file, output_dir,class_mapping=None):
"""
将单个 Pascal VOC XML 文件转换为 YOLO 格式的 .txt 标签文件
Args:
xml_file: 输入 XML 文件路径
output_dir: 输出 .txt 文件目录
class_mapping: 类别名到 ID 的映射,例如 {"cat": 0}
"""
if class_mapping is None:
class_mapping = {"cat": 0, "dog": 1} # 默认只处理 cat -> 0
tree = ET.parse(xml_file)
root = tree.getroot()
# 获取图像尺寸
size = root.find('size')
if size is None:
raise ValueError(f"XML {xml_file} 缺少 <size> 标签")
img_w = int(size.find('width').text)
img_h = int(size.find('height').text)
lines = []
for obj in root.findall('object'):
name = obj.find('name').text
if name not in class_mapping:
continue # 跳过非目标类别(如 dog)
bndbox = obj.find('bndbox')
xmin = float(bndbox.find('xmin').text)
ymin = float(bndbox.find('ymin').text)
xmax = float(bndbox.find('xmax').text)
ymax = float(bndbox.find('ymax').text)
# 转换为 YOLO 格式
x_center = (xmin + xmax) / 2.0 / img_w
y_center = (ymin + ymax) / 2.0 / img_h
width = (xmax - xmin) / img_w
height = (ymax - ymin) / img_h
class_id = class_mapping[name]
lines.append(f"{class_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}")
# 写入 .txt 文件(与 XML 同名)
output_path = output_dir + '\\' + filename + ".txt"
with open(output_path, 'w') as f:
f.write("\n".join(lines))
return filename
#获取目录下的所有文件
def get_all_files_os_walk(root_dir):
all_files = []
for dirpath, dirnames, filenames in os.walk(root_dir):
for filename in filenames:
full_path = os.path.join(dirpath, filename)
all_files.append(full_path)
return all_files
#获取文件名称
def get_all_filenames_os_walk(root_dir):
filenames = []
for dirpath, dirnames, files in os.walk(root_dir):
for file in files:
filenames.append(file) # 只取文件名,不含路径
return filenames
#拷贝原始文件到目的
def copy(src, path):
pass
cur_path = r'F:\work\code\python\yolov8\ultralytics-train\ultralytics\data'
cur_path_img_images = cur_path +r'\labels\test2017\img'
cur_path_label_xmls = cur_path +r'\labels\test2017\xml'
cur_path_img_train = cur_path +r'\images\train'
cur_path_label_train = cur_path +r'\labels\train'
cur_path_label_val = cur_path +r'\labels\val'
filenames = get_all_filenames_os_walk(cur_path_img_images)
#遍历
total_index = 0
for filename in filenames:
itmes = filename.split('.')
xmlFileName = cur_path_label_xmls+'\\'+itmes[0]+'.xml'
print('filename:'+str(total_index))
if (itmes[1] not in {"jpg","png","JPEG","PNG"} ):
continue
if os.path.exists(xmlFileName):
index = 0
hasType = False
with open(xmlFileName, "r", encoding="utf-8") as f:
content = f.read() # 返回 list,每行末尾保留 \n
content = str(content)
if content is None:
shutil.copy2(cur_path_img_images + '\\' + filename,
cur_path_img_train + "\\no_" + str(total_index) + '.' + itmes[1])
total_index += 1
continue
if content.find('face') >= 0:
print('face')
continue
else:
shutil.copy2(cur_path_img_images + '\\' + filename,
cur_path_img_train + "\\no_" + str(total_index) + '.' + itmes[1])
total_index += 1
continue
# 拷贝文件(保留元数据,如修改时间)
objname = convert_voc_to_yolo(xmlFileName, cur_path_label_train)
shutil.copy2(cur_path_img_images+'\\'+filename, cur_path_img_train+"\\"+objname+'.'+itmes[1])
print(cur_path_img_images+'\\'+filename)
total_index += 1
else:
shutil.copy2(cur_path_img_images+'\\'+filename, cur_path_img_train+"\\no_"+str(total_index) +'.'+itmes[1])
total_index += 1
print('it is ok')修改对应的目录,即可
- 遍历
test2017/xml目录下的所有 Pascal VOC 格式(.xml)标注文件; - 将每个
.xml文件中的目标框信息转换为 YOLO 格式的归一化坐标(.txt); - 将对应的图像文件(位于
test2017/img)复制到输出目录images/train/; - 将生成的 YOLO 标注文件保存到
labels/train/目录下,文件名与图像一致; - 自动创建目标目录(若不存在),并确保图像与标签一一对应。
原始目录
test2017/
├── img/
│ ├── 0001.jpg
│ ├── 0002.jpg
│ └── ...
└── xml/
├── 0001.xml
├── 0002.xml
└── ...输出目录
images/
└── train/
├── 0001.jpg
├── 0002.jpg
└── ...
labels/
└── train/
├── 0001.txt
├── 0002.txt
└── ...到这里数据格式就转换好了。
二、训练
2.1 修改配置文件
我的数据放到 F:/work/code/python/yolov8/ultralytics-train/data下面
我在这里创建一个yaml的配置文件:face_yolov8n.yaml
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# COCO8 dataset (first 8 images from COCO train2017) by Ultralytics
# Documentation: https://docs.ultralytics.com/datasets/detect/coco8/
# Example usage: yolo train data=coco8.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco8 ← downloads here (1 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
# 数据集根目录路径(所有图像和标签路径都相对于此路径)
path: F:/work/code/python/yolov8/ultralytics-train/data # dataset root dir
# 训练集图像所在目录(相对 path 的路径)
train: images/train_q # train images (relative to 'path') 4 images
# 验证集图像所在目录(相对 path 的路径)
val: images/val # val images (relative to 'path') 4 images
# 测试集图像所在目录(可选,若不使用测试集可删除或注释掉)
test: images/test # test images (optional)
# 类别名称列表,按类别索引(class_id)顺序定义
# 注意:YOLOv8 要求此处使用字典格式 {id: name},且 id 必须从 0 开始连续
names:
0: face # 类别 ID 0 对应的类别名称为 "face"-
实际训练图像路径为:
F:/work/code/python/yolov8/ultralytics-train/data/images/train/xxx.jpg -
标签文件位置:YOLOv8 会自动在与
images同级的labels目录下查找对应.txt文件。
即:若图像在images/train/001.jpg,则标签应位于labels/train/001.txt
2.2 环境
python:3.10 安装 pip install ultralytics pip install polars
2.3 训练代码
这边选择的是yolov8n.pt,图片大小选择320x320
from ultralytics import YOLO
# 加载预训练模型
model = YOLO('yolov8n.pt')
path = r"F:\work\code\python\yolov8\ultralytics-train\ultralytics\data"
datayaml = path + "/data/face_yolov8n.yaml"
# Train the model on the COCO8 dataset for 100 epochs
train_results = model.train(
data=datayaml, # Path to dataset configuration file
epochs=100, # Number of training epochs
imgsz=320, # Image size for training
lr0=0.001, # 降低学习率,避免破坏预训练特征
batch=32,
device=0, # Device to run on (e.g., 'cpu', 0, [0,1,2,3])
name='face_detection'
)
# Evaluate the model's performance on the validation set
metrics = model.val()
# Perform object detection on an image
# results = model(path+"data/images/test/face_300.jpg") # Predict on an image
# results[0].show() # Display results
# Export the model to ONNX format for deployment
path = model.export(format="onnx") # Returns the path to the exported model
执行完成后,会在runs-yolov8n_320_320目录下包含训练后的模型
F:\work\code\python\yolov8\ultralytics-train\ultralytics\runs-yolov8n_320_320\detect\face_detection4\weights 下面包含有
beast.pt 最优的模型
last.pt 最后生成的模型
一般都是选择beast.pt ,训练选择last.pt
2.4 推理验证
把模型拷贝到跟目录F:\work\code\python\yolov8\ultralytics-train\ultralytics,然后模型名称修改为
yolov8n_beast.pt
推理一张图片,是否正常显示画脸框
import cv2
import torch
from matplotlib import pyplot as plt
from ultralytics import YOLO
# 加载预训练模型(自动下载 if not exists)
model = YOLO("yolov8n_beast.pt")
# 推理(支持单张图、多图、视频、URL 等)
print(model .model.nc) # 应该输出 2
# 方法1:通过 Ultralytics API 查看
print("Detect layer output channels (cv3):", [m[-1].out_channels for m in model .model.model[-1].cv3])
# 方法2:直接读取 state_dict
ckpt = torch.load("yolov8n_beast.pt", map_location="cpu")
print("Checkpoint nc:", ckpt['model'].nc if 'model' in ckpt else "Not found")
# 检查检测头最后卷积层的权重形状(应为 [2, ...])
if 'model' in ckpt:
state_dict = ckpt['model'].state_dict()
for k, v in state_dict.items():
if 'cv3' in k and 'weight' in k:
print(f"{k}: {v.shape}") # 应该看到 torch.Size([2, ..., ..., ...])
results = model.predict(
source=r"F:\work\code\python\yolov8\ultralytics-train\ultralytics\data\images\test\1.jpg", # 输入源
conf=0.25, # 置信度阈值
iou=0.45, # NMS 的 IoU 阈值
save=True, # 是否保存结果
show=False, # 是否实时显示(需 GUI 环境)
device="cpu" # 或 "cuda:0"
)
# 遍历结果(每张图一个 result 对象)
for result in results:
boxes = result.boxes # 边界框
masks = result.masks # 分割掩码(如果模型支持)
probs = result.probs # 分类概率(分类任务)
orig_img = result.orig_img # 原始图像 (HWC, BGR)
annotated_frame = result.plot()
# 转 BGR -> RGB(因为 OpenCV 是 BGR,matplotlib 是 RGB)
rgb_img = cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12, 8))
plt.imshow(rgb_img)
plt.axis("off")
plt.show()
# 打印检测到的类别和坐标
for box in boxes:
cls_id = int(box.cls.item())
conf = float(box.conf.item())
xyxy = box.xyxy[0].tolist() # [x1, y1, x2, y2]
print(f"Class: {cls_id}, Conf: {conf:.2f}, Box: {xyxy}")
三、部署
如果部署到rk板子,有几种选择,有npu的部署为rknn的模型,如果没有如rk3399 没有npu,那么部署onnx 或者ncnn模型,这里推荐ncnn,腾讯开源多年比较成熟。
3.1 环境
安装环境:
pip3 install -U ultralytics pnnx ncnn 创建ncnn目录 mkdir ncnn && cd ncnn
3.2 导出torchscript
把模型修改为yolov8n.pt 拷贝到ncnn下面
执行命令
yolo export model=yolov8n.pt format=torchscript导出了模型:yolov8n.torchscript
pnnx yolov8n.torchscript3.3 修改pnnx文件
编辑 yolov8n_pnnx.py
修改如下
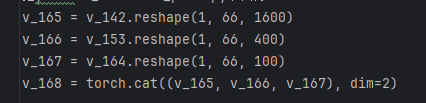
修改为
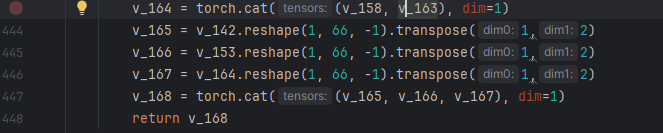
v_168后面直接return掉,然后后面的删除掉,这里去掉后,那么nms后面执行部分就需要再代码里面处理了,这样可以优化速度,不去除那么直接返回分类结果
3.4 重新导出yolov8 ncnn
执行如下命令重新导出,ncnn
这里我的文件是yolov8n_pnnx.py,所以import 这个名称,如果是其他的请导入其他名称
python -c "import yolov8n_pnnx; yolov8n_pnnx.export_torchscript()"
python -c "import yolov8n_pnnx; yolov8n_pnnx.export_ncnn()"然后获取最新的ncnn文件
后面部署到板子或者android请参考:https://zhuanlan.zhihu.com/p/16030630352
这里最新已经不需要先转onnx再转ncnn,挺方便一步到位ncnn
后续:在rk3399的android下面发现,执行需要大概300ms左右才能执行一帧,速度有点慢,后面再试试剪枝、蒸馏,量化好像之前试过不加速,反量化还可能耗费时间。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 31
31 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)