手把手教你卷积神经网络(CNN)模型:模型性能评估和预测策略
------正文开始--------N6-甲基腺苷(m6A)是真核生物中最常见的mRNA修饰类型,参与mRNA剪接、稳定性调控和翻译等关键过程。研究表明,m6A修饰异常与多种疾病密切相关,包括癌症、神经退行性疾病等。传统实验方法鉴定m6A位点成本高且耗时长,而机器学习方法特别是深度学习,为高效预测mRNA修饰位点提供了新思路。
小伙伴们好,我是小嬛。专注于人工智能、计算机视觉领域相关分享研究。【目标检测、图像分类、图像分割、目标跟踪等项目都可做,也可做不同模型对比实验;需要的可联系(备注来意)】
-------正文开始--------
引言:mRNA修饰预测的重要性
N6-甲基腺苷(m6A)是真核生物中最常见的mRNA修饰类型,参与mRNA剪接、稳定性调控和翻译等关键过程。研究表明,m6A修饰异常与多种疾病密切相关,包括癌症、神经退行性疾病等。传统实验方法鉴定m6A位点成本高且耗时长,而机器学习方法特别是深度学习,为高效预测mRNA修饰位点提供了新思路。
在此系列的前四篇里我们已经系统回顾了很多具有代表性的m6A-SNP预测模型,在接下来几篇我们将深入解析模型原理/代码实现和最新的深度学习研究成果,展示人工智能如何助力RNA修饰功能研究。
本篇将承接上篇继续解析如何构建卷积神经网络(CNN)来预测mRNA序列中的m6A修饰位点,主要涵盖模型性能评估、预测策略。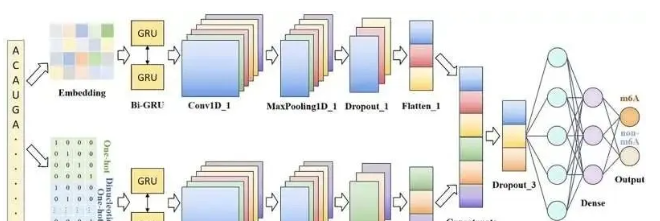 四、评估与预测策略
四、评估与预测策略
基础评估指标

准确率 (Accuracy):整体预测正确率
查准率 (Precision):预测为正的样本中,多少是真正的正样本
查全率 (Recall):所有正样本中,模型能识别出来多少
F1 值 (F1-score):Precision 和 Recall 的调和平均,更平衡的指标
混淆矩阵:直观展示 TP/TN/FP/FN
ROC 曲线与 AUC:评估整体分类能力
PR 曲线与 AUPRC:在类别不平衡时更敏感,重点反映模型对正类的识别表现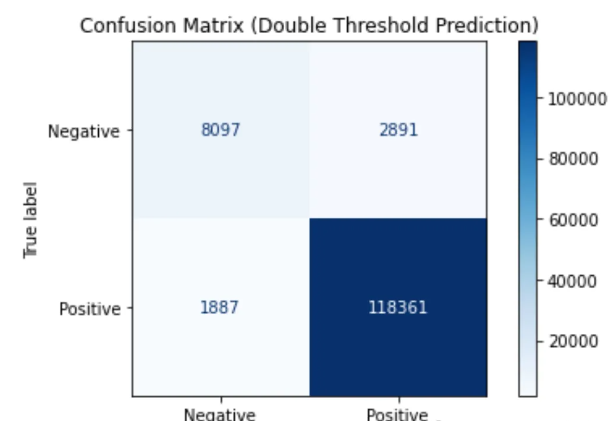
2. 双阈值策略
传统单阈值问题:
-
基础评估指标输出
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score y_pred = (model.predict(X_test) > 0.5).astype(int) print("Accuracy:", accuracy_score(y_test, y_pred)) print("Precision:", precision_score(y_test, y_pred)) print("Recall:", recall_score(y_test, y_pred)) print("F1:", f1_score(y_test, y_pred)) -
混淆矩阵
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay import matplotlib.pyplot as plt cm = confusion_matrix(y_test, y_pred) disp = ConfusionMatrixDisplay(confusion_matrix=cm) disp.plot() plt.show() -
ROC曲线与AUC
from sklearn.metrics import roc_curve, roc_auc_score y_prob = model.predict(X_test).ravel() fpr, tpr, _ = roc_curve(y_test, y_prob) auc_val = roc_auc_score(y_test, y_prob) plt.plot(fpr, tpr, label=f"ROC curve (AUC={auc_val:.2f})") plt.xlabel("False Positive Rate") plt.ylabel("True Positive Rate") plt.legend() plt.show() -
PR曲线与AUPRC
from sklearn.metrics import precision_recall_curve, average_precision_score precision, recall, _ = precision_recall_curve(y_test, y_prob) ap = average_precision_score(y_test, y_prob) plt.plot(recall, precision, label=f"PR curve (AP={ap:.2f})") plt.xlabel("Recall") plt.ylabel("Precision") plt.legend() plt.show() -
正负样本概率分布密度图
import seaborn as sns #可以用于调整阈值 sns.kdeplot(y_prob[y_test==0], label="Negative") sns.kdeplot(y_prob[y_test==1], label="Positive") plt.xlabel("Predicted probability") plt.ylabel("Density") plt.legend() plt.show()为什么选择AUPRC?
-
正负样本高度不平衡时更可靠
-
直接反映模型对正样本的识别能力
-
0.5阈值不适合不平衡数据
-
大量样本处于中间模糊区域
双阈值方案:
def double_threshold_classify(prob, low=..., high=...): #可以自行根据密度图选择
if prob >= high:
return 1 # 高置信度正样本
elif prob <= low:
return 0 # 高置信度负样本
else:
return -1 # 不确定区域优势:
-
只保留高置信度预测
-
减少边界误判
-
提升结果可靠性
五、模型部署与RNA变异预测
SNP效应预测流程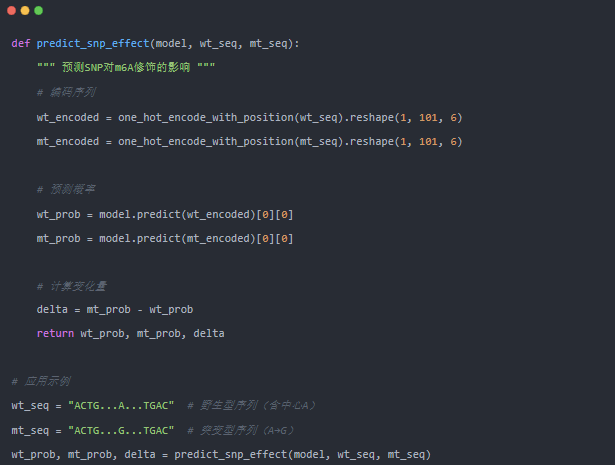
可以使用双重筛选标准进行预测
1.首先依据模型验证阶段确定的分数阈值筛选出高置信度的m6A预测位点;
2.再对Δscore应用Z-score标准化,筛选出变化幅度显著(Z>2或Z<-2)的样本。
只有同时满足分数阈值和显著性要求的突变,才被认定为真正的gain或loss事件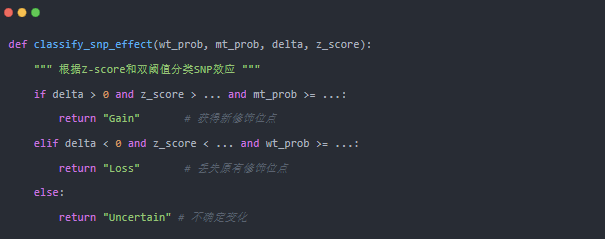
公众号(AI技术星球)回复暗号:977C
 好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)