鲁鹏教授《计算机视觉与深度学习》课程笔记与思考 ——05. 全连接神经网络(中):训练优化的核心工程策略
本文系统阐述了全连接神经网络的训练优化策略,聚焦四大核心问题:1)激活函数选择(ReLU解决梯度消失);2)梯度下降改进(Adam算法融合动量和自适应);3)权重初始化(Xavier/He匹配激活特性);4)批归一化(BN稳定训练)。文章揭示了深度学习工程化的核心思维:每个优化策略都针对具体痛点(如梯度消失、震荡等),而非简单堆砌方法。通过理论推导与实例分析,构建了从模型搭建到高效训练的系统方法论
在上一篇笔记中,我梳理了全连接神经网络的 “基础框架”—— 从 “多层线性变换 + 非线性激活” 突破线性局限,到 “Softmax + 交叉熵” 实现概率化建模,这些内容回答了 “全连接网络是什么” 的问题。但鲁鹏教授在这一讲中强调:“能搭建模型不等于能训好模型”—— 实际训练中,梯度消失 / 爆炸、收敛缓慢、参数初始化不当等问题会直接导致模型 “训不动” 或 “训不好”。因此,这一讲聚焦全连接网络的 “训练优化”,通过激活函数深度解析、梯度下降改进、权重初始化、批归一化四大核心策略,解决 “如何高效训练全连接网络” 的工程问题。本文将结合课程中的数学推导与实例,拆解这些优化策略的底层逻辑,为后续复杂模型(如 CNN)的训练铺垫工程思维。
目录
2. 四类激活函数的梯度对比:从 “Sigmoid 淘汰” 到 “ReLU 主导”
二、梯度下降算法的工程改进:从 “震荡慢收敛” 到 “稳定快收敛”
2. 动量法(Momentum):用 “累加梯度” 抵消震荡
3. 自适应梯度法:Adagrad 与 RMSprop 的 “差异化步长”
(2)RMSprop:改进 Adagrad,仅关注 “近期梯度”
(2)随机初始化( naive ):“权重过大 / 过小,梯度异常”
2. Xavier 初始化:适配 Sigmoid/Tanh 的 “方差匹配” 策略
3. He 初始化:专为 ReLU 设计的 “梯度友好” 方案
五、学习感悟:从 “理论建模” 到 “工程优化” 的思维转变
1. 对 “梯度” 的认知升级:从 “数学工具” 到 “训练命脉”
2. 工程优化的核心逻辑:“针对性解决痛点” 而非 “盲目堆砌方法”
3. 超参数调优的启示:“没有万能参数,只有适配任务的参数”
一、激活函数的深度解析:梯度特性决定训练成败
上一讲我们初步认识了激活函数的 “非线性作用”,但这一讲课程通过 “梯度反向传播” 的视角,揭示了一个更关键的结论:激活函数的梯度特性直接决定模型能否训得动—— 糟糕的梯度特性会导致 “梯度消失” 或 “梯度爆炸”,让前层参数无法更新;而优秀的激活函数能让梯度 “顺畅回传”,保证训练持续推进。
1. 梯度消失与梯度爆炸:链式法则下的 “致命陷阱”
全连接网络的梯度通过 “链式法则” 反向传播,即:某一层参数的梯度 = 后续所有层梯度的乘积。这种 “乘法累积” 特性,会导致两种极端问题:
(1)梯度消失:前层参数 “纹丝不动”
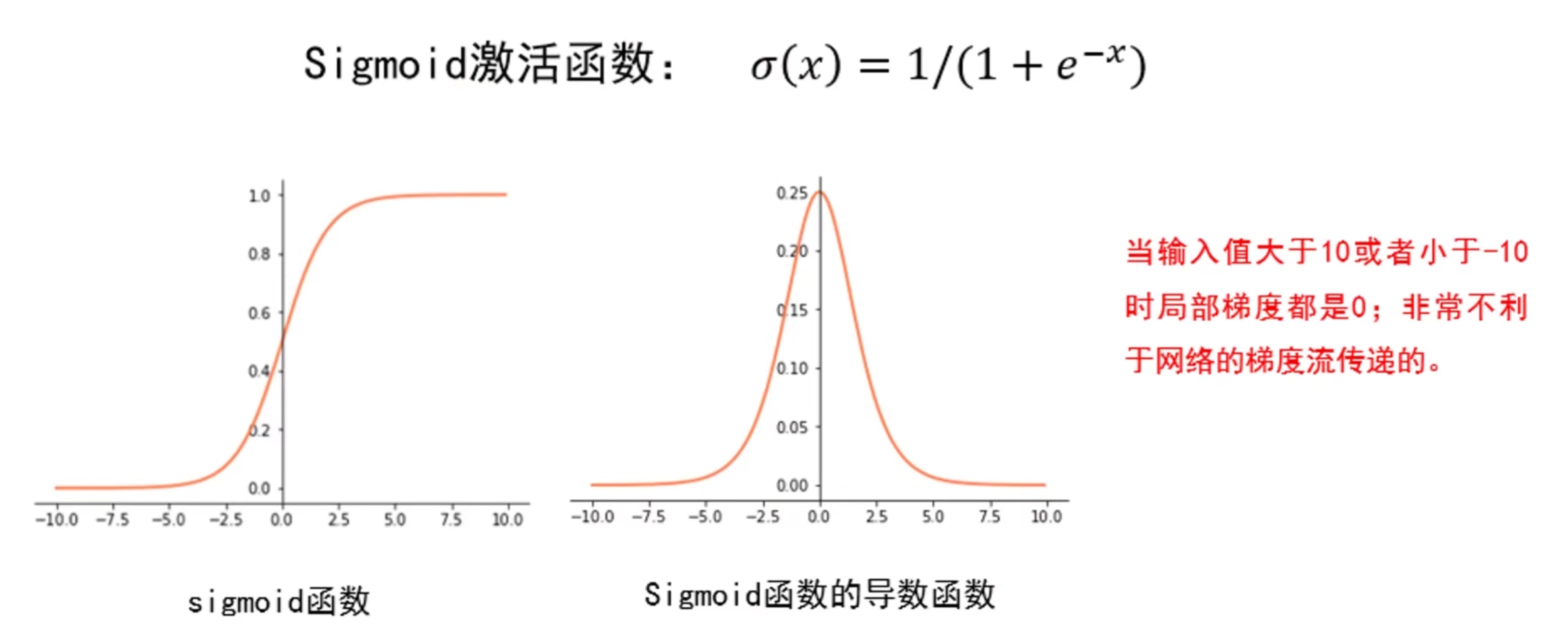
当激活函数的局部梯度小于 1 时(如 Sigmoid 的梯度最大值仅 0.25),多层叠加后梯度会 “指数级衰减”:
- 例:若某网络有 10 层 Sigmoid 激活函数,即使每层梯度都取最大值 0.25,前层梯度 = 0.2510≈9.5×10−7(几乎为 0)。
- 后果:前层参数(如输入层到第一层隐层的权重)的梯度接近 0,参数无法更新,网络 “卡在初始状态”。
课程中用 “Sigmoid 的梯度曲线” 直观展示了这一问题:当输入值绝对值大于 5 时,Sigmoid 的梯度趋近于 0,此时无论后续层梯度如何,前层梯度都会被 “归零”。
(2)梯度爆炸:参数更新 “失控飞散”
当激活函数的局部梯度远大于 1 时(或权重初始化过大),多层叠加后梯度会 “指数级增长”:
- 例:若某层局部梯度为 10,5 层叠加后梯度 = 105=100000(极大值)。
- 后果:参数更新时步长(学习率 × 梯度)过大,导致参数 “跳过最优值” 甚至 “数值溢出”,损失函数震荡不收敛。
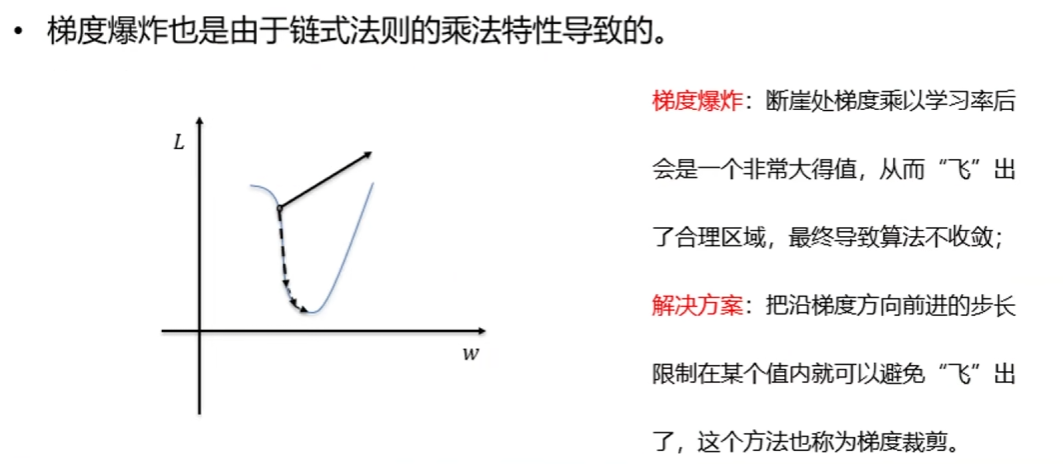
梯度爆炸可通过 “梯度裁剪” 缓解(若梯度超过阈值,强制缩放到阈值内),但梯度消失更难解决 —— 它不是 “数值大小” 问题,而是 “梯度传递中断” 问题,必须从激活函数本身优化。
2. 四类激活函数的梯度对比:从 “Sigmoid 淘汰” 到 “ReLU 主导”
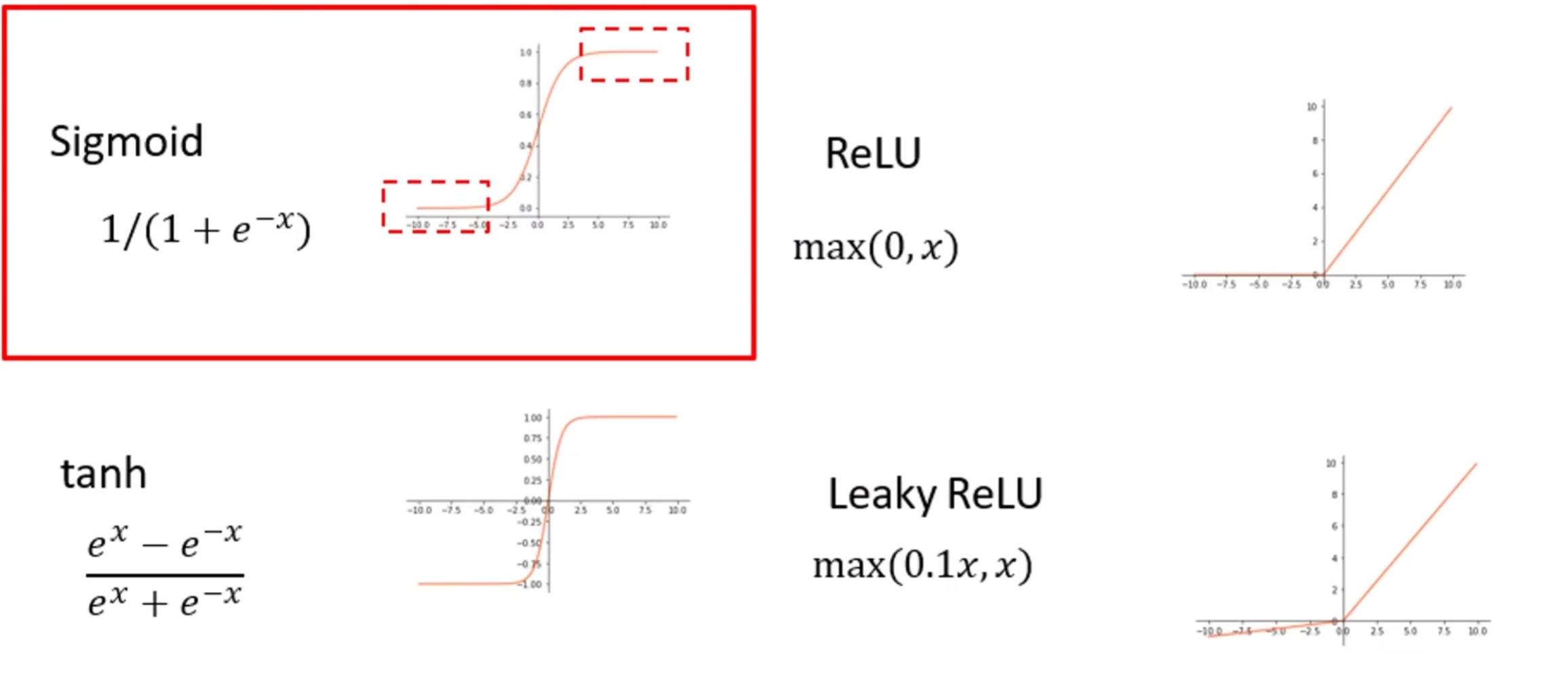
课程通过 “梯度特性” 重新评估了四类经典激活函数,其核心差异如下表所示:
| 激活函数 | 梯度特性 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Sigmoid | 输入∈[-1,1] 时梯度≈0.1~0.25,输入∉[-5,5] 时梯度≈0 | 输出∈[0,1],可表示概率 | 梯度消失严重;计算需指数运算(慢) | 仅输出层(如二分类的概率输出) |
| Tanh | 输入∈[-1,1] 时梯度≈0.4~1,输入∉[-3,3] 时梯度≈0 | 输出∈[-1,1],均值为 0 | 仍存在饱和区梯度消失;计算慢 | 极少用(仅 legacy 模型) |
| ReLU | 输入 > 0 时梯度 = 1,输入≤0 时梯度 = 0 | 计算极快(仅判断正负);无梯度消失(输入 > 0 时) | 输入≤0 时神经元 “死亡”(梯度 = 0) | 隐藏层(主流选择) |
| Leaky ReLU | 输入 > 0 时梯度 = 1,输入≤0 时梯度 = 0.01(小值) | 避免神经元死亡;梯度更顺畅 | 实际效果提升有限;需额外调小梯度参数 | 隐藏层(ReLU 效果差时尝试) |
当前深度学习中,隐藏层几乎不再使用 Sigmoid 和 Tanh—— 它们的饱和区梯度消失会导致深层网络(如 10 层以上)无法训练;而 ReLU 凭借 “梯度稳定(输入> 0 时梯度 = 1)” 和 “计算高效” 的优势,成为隐藏层的 “默认选择”。
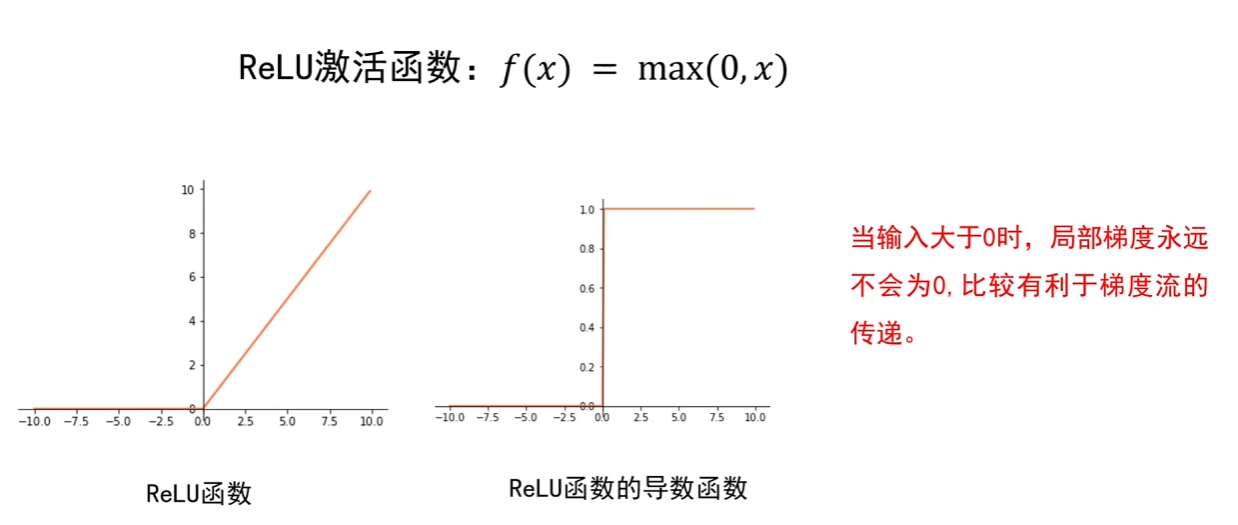
例:若用 ReLU 搭建 20 层全连接网络,只要输入 > 0,梯度就能以 “1” 的系数回传至前层,完全避免梯度消失;即使部分神经元因输入≤0 “死亡”,剩余神经元仍能正常传递梯度。
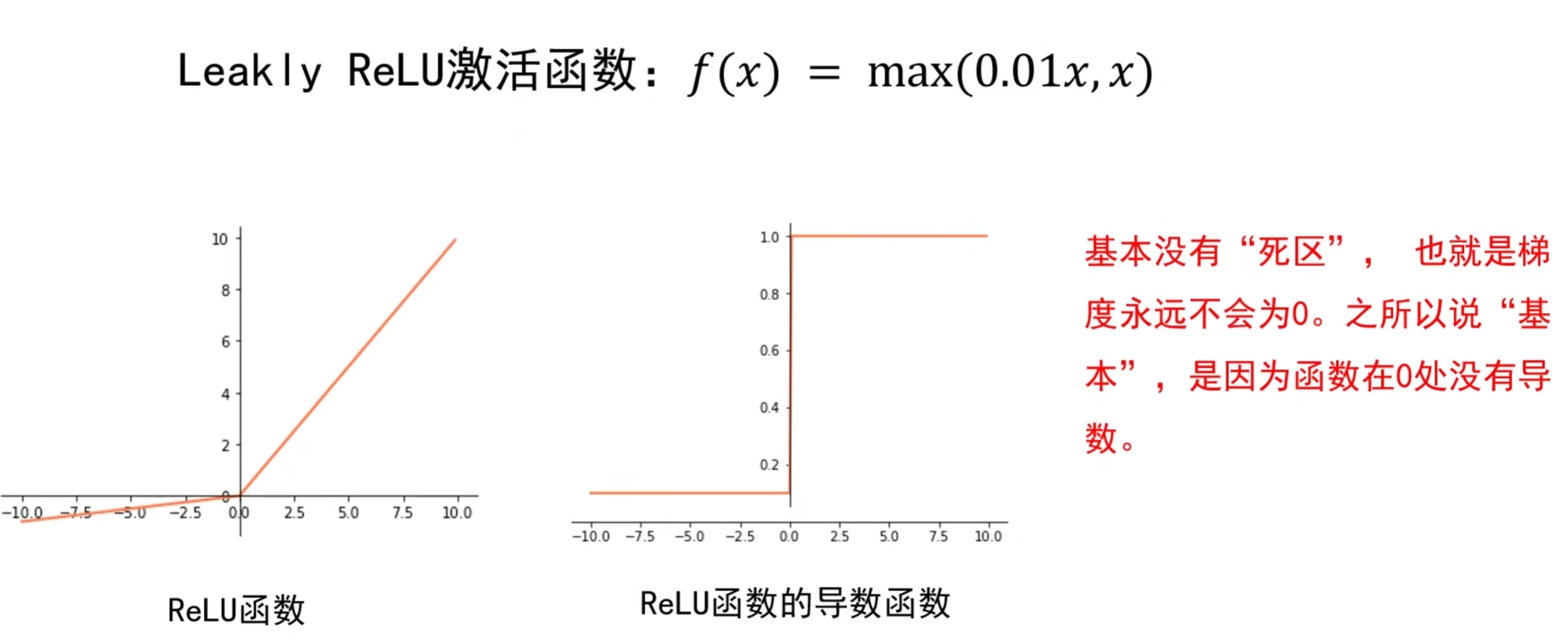
3. 激活函数的选择准则
课程总结了激活函数的 “分层选择” 原则:
- 隐藏层:优先用 ReLU,若出现大量神经元死亡(训练中损失不下降),换用 Leaky ReLU;
- 输出层:根据任务选择 ——
- 二分类:Sigmoid(输出单个概率值∈[0,1]);
- 多分类:Softmax(输出概率分布,配合交叉熵损失);
- 回归任务:无激活函数(输出任意实数)。
核心逻辑:隐藏层优先保证 “梯度顺畅传递”,输出层优先保证 “输出符合任务需求”。

二、梯度下降算法的工程改进:从 “震荡慢收敛” 到 “稳定快收敛”
上一讲我们学习了 “小批量梯度下降”(Mini-batch SGD),它比全样本 SGD 快,但仍存在 “震荡” 和 “收敛慢” 的问题。课程通过 “损失函数地形” 的例子,引出了三种梯度下降改进算法:动量法、自适应梯度法、Adam,逐步解决这些痛点。
1. 随机 / 小批量梯度下降的痛点:震荡与收敛缓慢
课程用 “三维损失函数地形” 直观展示了问题:

- 损失函数在某一方向(如 紫色箭头 方向)“陡峭”,另一方向(如 红色箭头 方向)“平坦”;
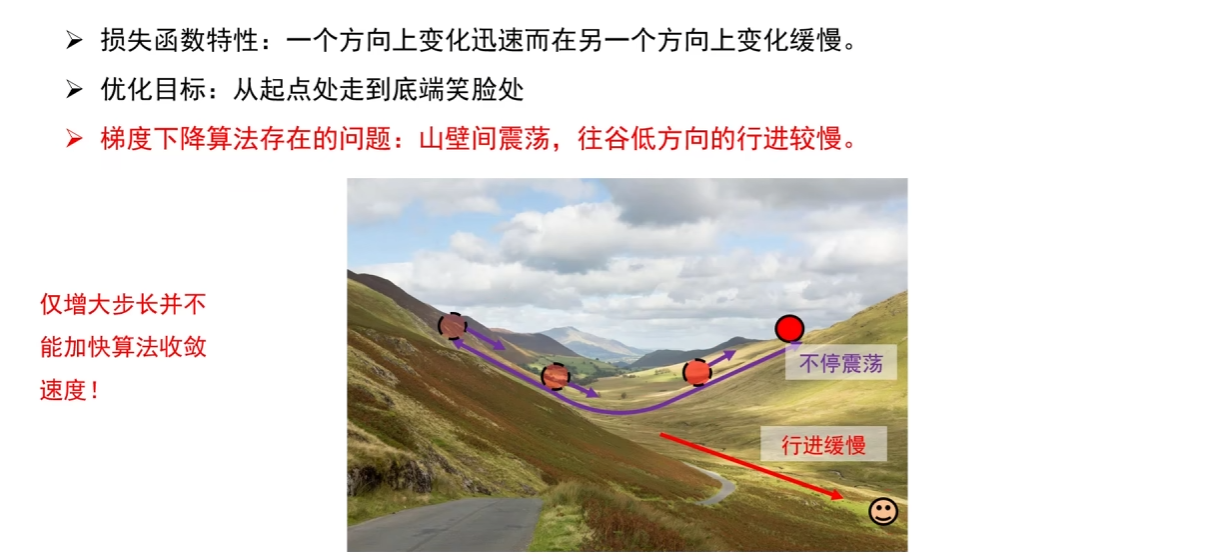
示意图 - 小批量 SGD 在陡峭方向会 “剧烈震荡”(每一步更新方向反复切换),在平坦方向 “缓慢爬行”(梯度小,步长小);
- 后果:大量算力浪费在震荡上,收敛到最优值的速度极慢。
简单增大学习率无法解决问题 —— 会让陡峭方向的震荡更剧烈,甚至溢出;减小学习率则会让平坦方向的收敛更慢。
2. 动量法(Momentum):用 “累加梯度” 抵消震荡
动量法的核心思想:模拟物理中的 “动量”,累加历史梯度的 “惯性”,抵消当前梯度的 “随机震荡”。
(1)数学原理
引入 “动量变量 v”(累加梯度),参数更新公式如下:

(2)如何解决震荡?
- 陡峭方向:当前梯度方向反复切换(如 + g、-g、+g),累加后 vₜ ≈ μ・vₜ₋₁ + g,正负梯度相互抵消,动量逐渐平稳,震荡减弱;
- 平坦方向:当前梯度方向稳定(如持续 + g),累加后 vₜ ≈ μ・vₜ₋₁ + g,动量逐渐增大,步长加快,收敛变快。
课程中比喻:“动量法像给梯度下降加了‘惯性’,让参数更新‘不容易被当前小批量的噪声带偏’,更贴近真实的最优方向。”
(3)动量法的优势:“冲” 出局部最小与鞍点
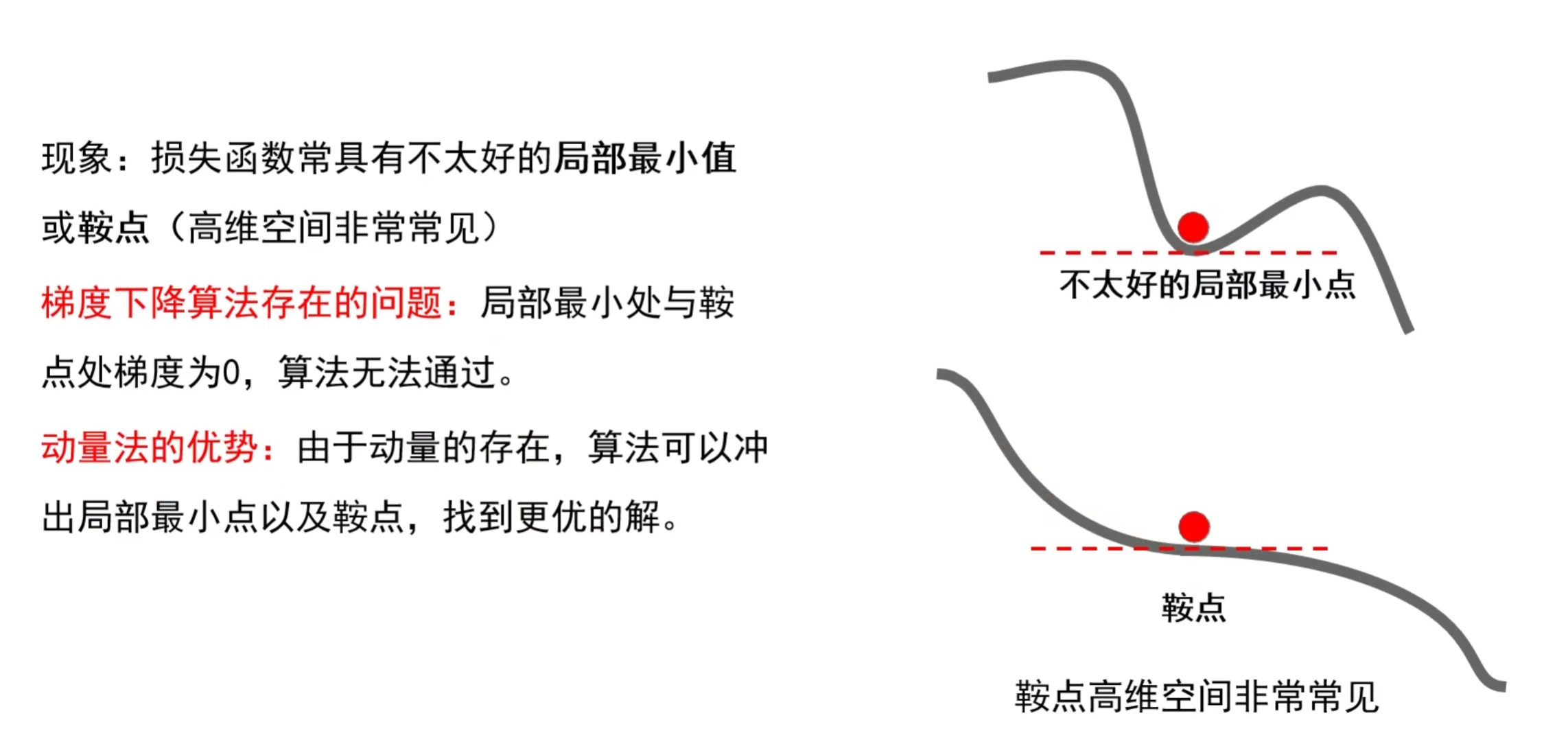
深度学习训练的损失函数不是 “一路顺滑的下坡”,常会遇到两类陷阱 ——「不太理想的局部最小值」(图上方的浅坑),以及「鞍点」(图下方的拐点,在高维训练空间里这类 “平地陷阱” 其实特别常见)。
普通梯度下降是 “跟着当前梯度走”,但局部最小、鞍点处的梯度恰好为 0—— 这会让算法直接 “卡” 在这些次优位置,没法继续向更优的损失谷底前进。
而动量法的核心优势就在这里:它靠历史梯度积累出的 “惯性(速度)”,哪怕遇到梯度为 0 的陷阱,也能带着参数继续向前 “冲”,跳出局部最小与鞍点,最终找到更优的模型参数。
这也是动量法能让深度学习训练更稳定、收敛效果更好的关键原因之一。
3. 自适应梯度法:Adagrad 与 RMSprop 的 “差异化步长”
动量法解决了 “震荡”,但未解决 “不同参数需要不同步长” 的问题 —— 例如,高频更新的参数(如输入层权重)需要小步长,低频更新的参数(如深层隐层权重)需要大步长。自适应梯度法通过 “为每个参数定制步长”,进一步提升收敛速度。

(1)Adagrad:累计梯度平方,适配步长
- 核心思想:参数的步长与 “该参数的累计梯度平方和” 成反比 —— 累计梯度大的参数(高频更新),步长小;累计梯度小的参数(低频更新),步长小。
- 公式:


- 问题:累计平方梯度 rₜ会持续增大,导致步长逐渐趋近于 0,后期收敛停滞。
(2)RMSprop:改进 Adagrad,仅关注 “近期梯度”
- 核心思想:通过累积 “梯度的平方”,用这个累积值动态缩放学习率 —— 梯度波动大的参数,学习率自动变小(防震荡);梯度波动小的参数,学习率自动变大(加速收敛)。
- 公式:

RMSprop法 - 优势:学习率自适应
无需手动为不同参数调学习率,算法自动根据参数的梯度波动调整;既避免了 “梯度大的参数更新震荡”,又加速了 “梯度小的参数收敛”;是 Adam 等更常用优化算法的基础组件之一
(Adam = 动量法 + RMSProp)。
4. Adam 算法:动量法与自适应梯度的 “最优结合”
Adam 算法(Adaptive Moment Estimation,自适应矩估计)是深度学习中最常用的优化算法之一,核心是同时结合了 “动量法的梯度累积(惯性)” 和 “RMSProp 的自适应学习率”,还解决了算法初期的 “冷启动” 问题。
课程指出:Adam 是当前最主流的优化算法—— 它同时融合了动量法的 “惯性抵消震荡” 和 RMSprop 的 “自适应步长”,在绝大多数任务中都能实现 “稳定快收敛”。
(1)核心改进:双累计量
Adam 引入两个累计变量:
动量累计 vₜ(类似 Momentum):捕捉梯度的 “方向惯性”;
自适应累计 Gₜ(类似 RMSprop):捕捉梯度的 “幅度信息”;
同时对两个变量进行 “偏差修正”(解决初始阶段累计量偏小的问题)。
(2)公式流程

(3)Adam 的核心优势
“Adam 几乎不需要手动调优学习率 —— 用默认参数(β₁=0.9,β₂=0.999,η=1e-3)就能在大多数任务中表现优异,是工程实践中的‘首选优化器’。”
兼顾动量 + 自适应:同时拥有动量法的 “防震荡、加速收敛”,和 RMSProp 的 “学习率按需调整”;
缓解冷启动:偏差修正步骤让算法在训练初期也能稳定更新,不用等累积足够多的历史信息。
正因为这些优势,Adam 是现在深度学习(比如 CNN、Transformer)训练中最常用的优化算法之一
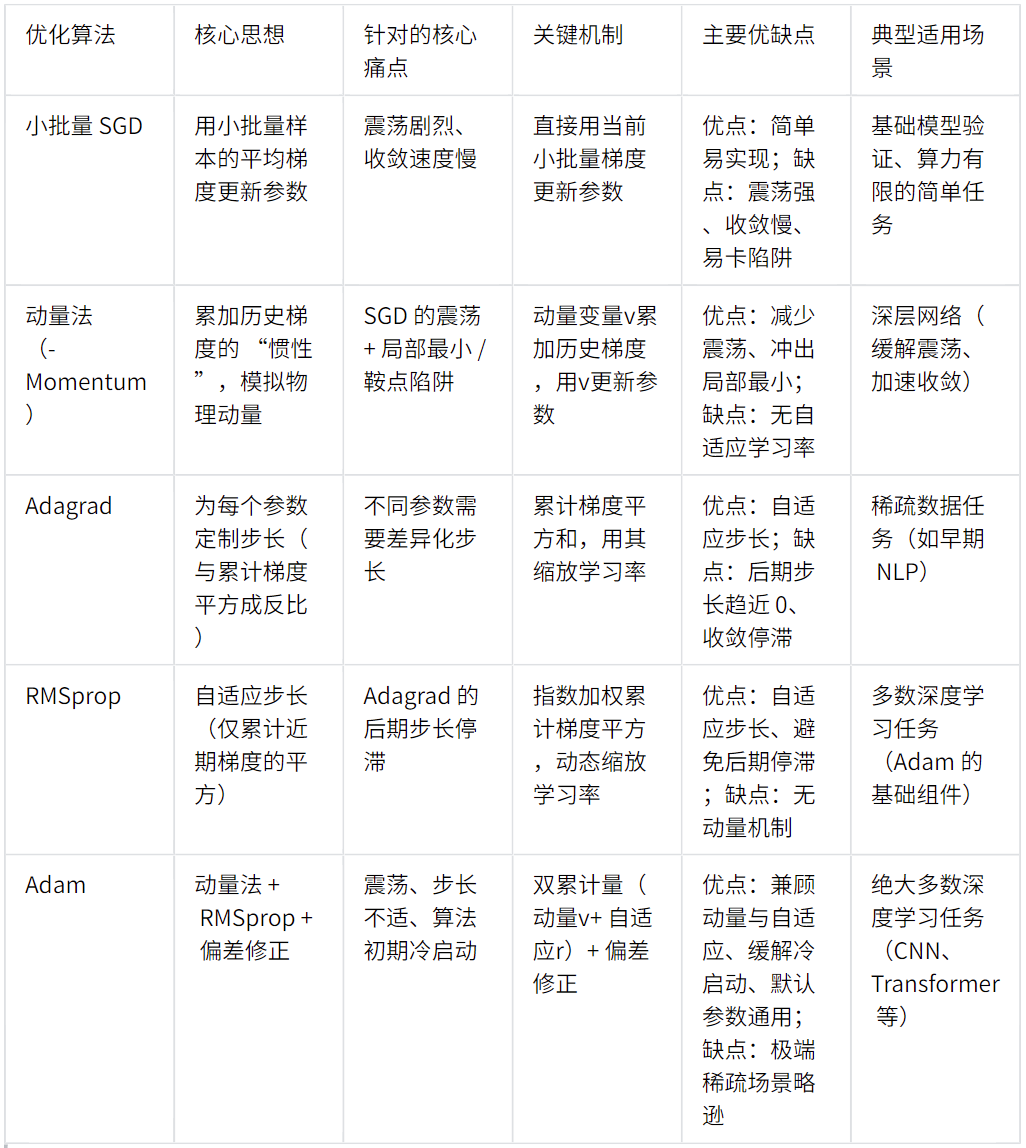
5.总结
三、权重初始化的误区与正确策略:避免 “训练从源头失败”
课程中提到:“很多人认为初始化只是‘随便给个值’,但实际上,权重初始化的好坏直接决定模型能否‘启动训练’”—— 错误的初始化会导致梯度消失 / 爆炸,即使激活函数和优化器选得再好,模型也训不动。
1. 两大错误初始化:全零初始化与随机初始化的问题
(1)全零初始化:“所有神经元一样,训练无效”
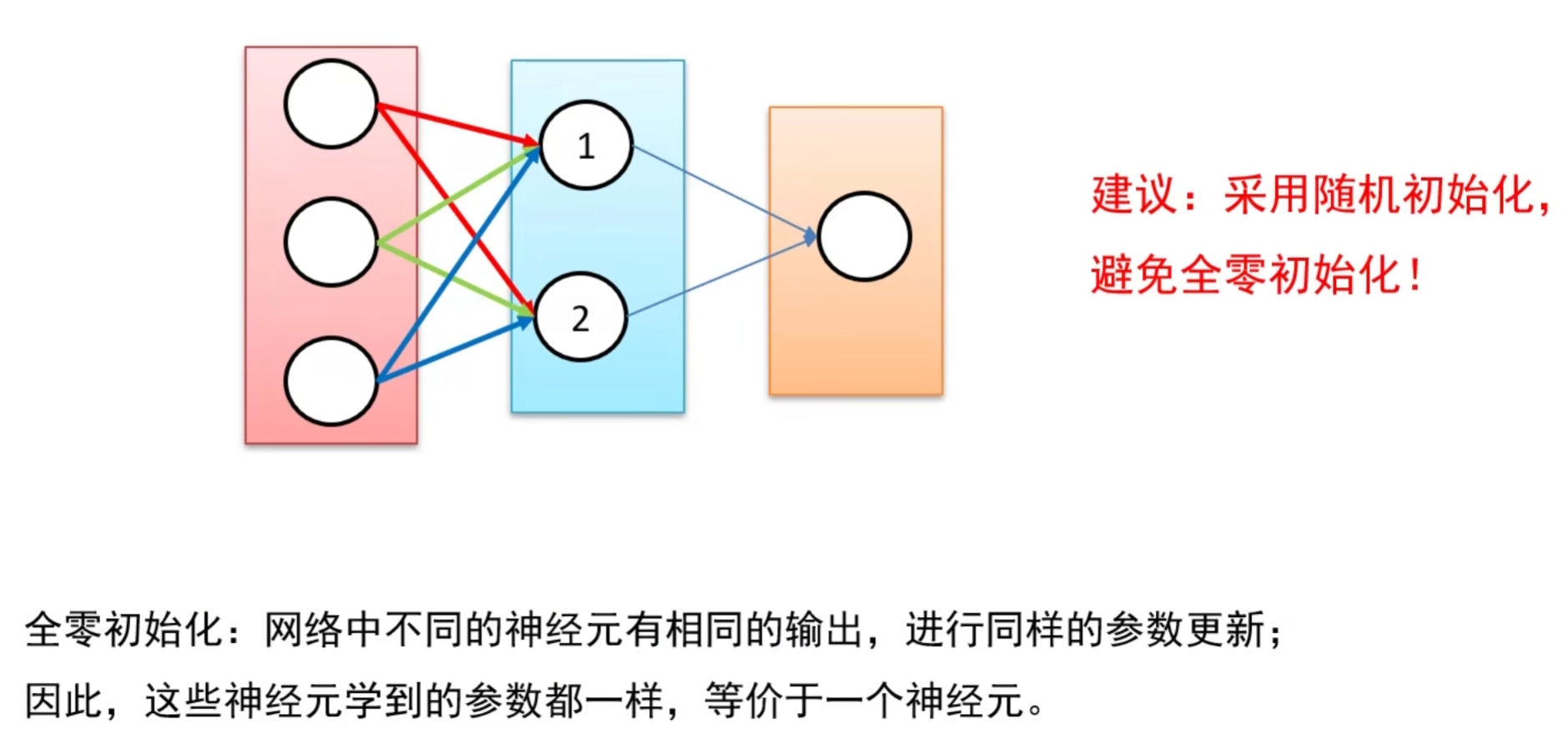
- 错误逻辑:认为 “初始化为 0,公平对待所有参数”。
- 问题:若所有权重 W 和偏置 b 都初始化为 0,那么每一层的输出都相同(因为输入 ×0+0=0),导致所有神经元的梯度也相同 —— 参数更新后仍保持一致,网络无法学习到差异化特征。
- 结论:全零初始化完全不可用。
(2)随机初始化( naive ):“权重过大 / 过小,梯度异常”
- 错误逻辑:认为 “随机给个小值就行”(如 W~N (0, 0.01))。
- 问题:
- 权重过小:输入经过多层线性变换后,输出会趋近于 0,ReLU 激活后大量神经元死亡(梯度 = 0);
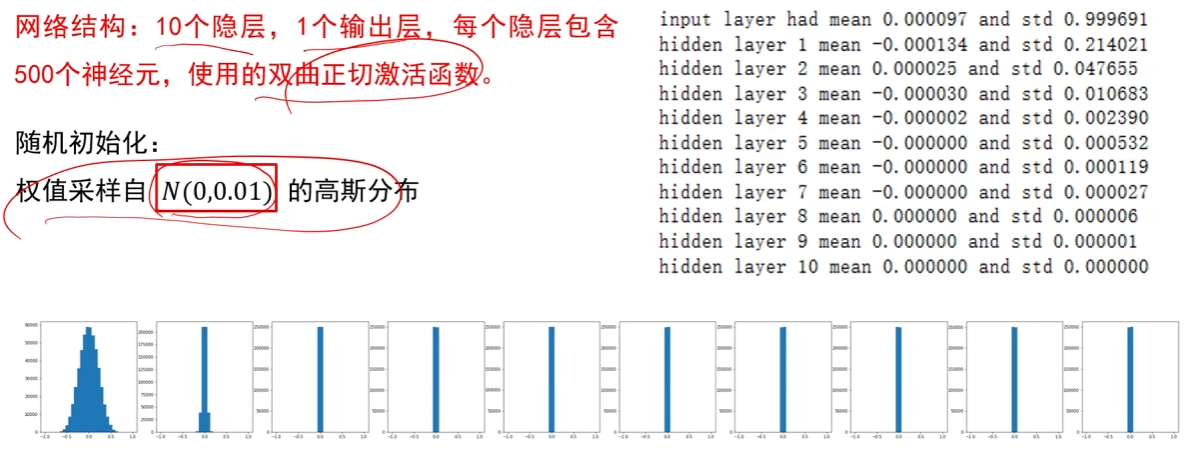
- 权重过大:输入经过多层线性变换后,输出会趋近于 ±∞,Sigmoid/Tanh 进入饱和区(梯度≈0),导致梯度消失。
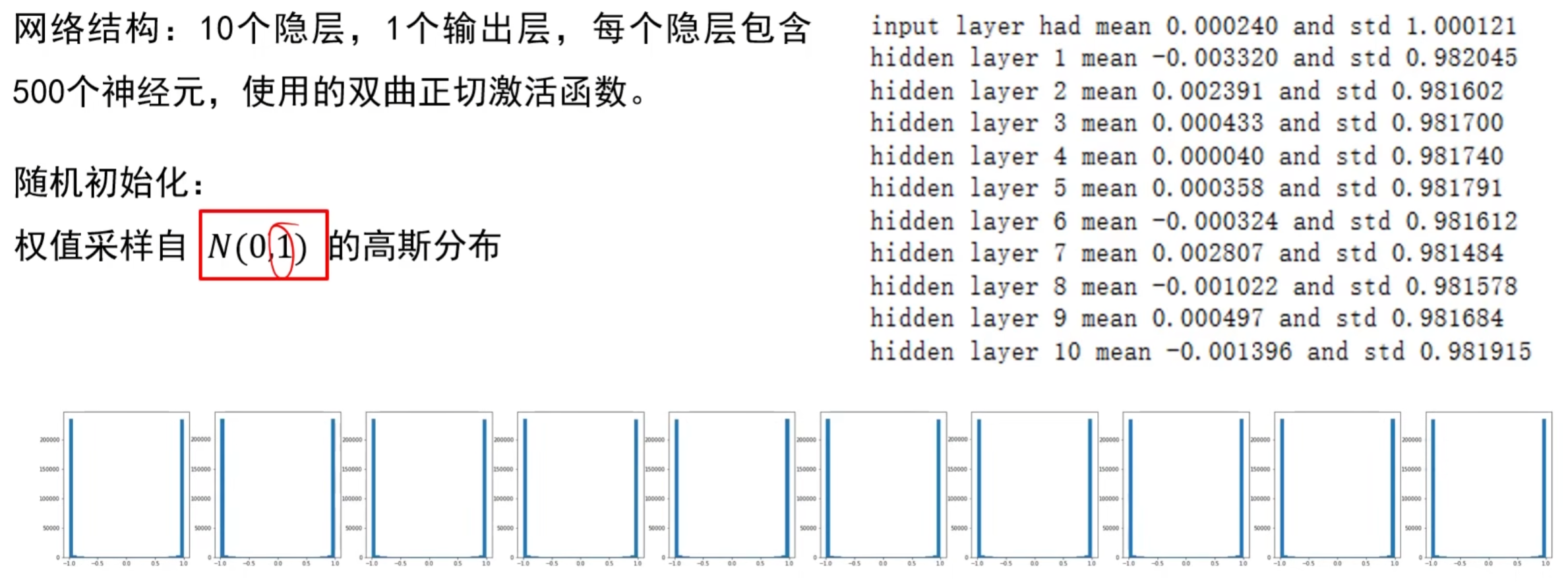
- 权重过小:输入经过多层线性变换后,输出会趋近于 0,ReLU 激活后大量神经元死亡(梯度 = 0);
- 结论:仅让初始化时的权值不相等,无法保证网络能够正常被训练。
所以,有效初始化方法:要让网络各层的激活值、局部梯度的方差在传播过程中尽量保持一致,以此维持网络正向与反向的数据流动。
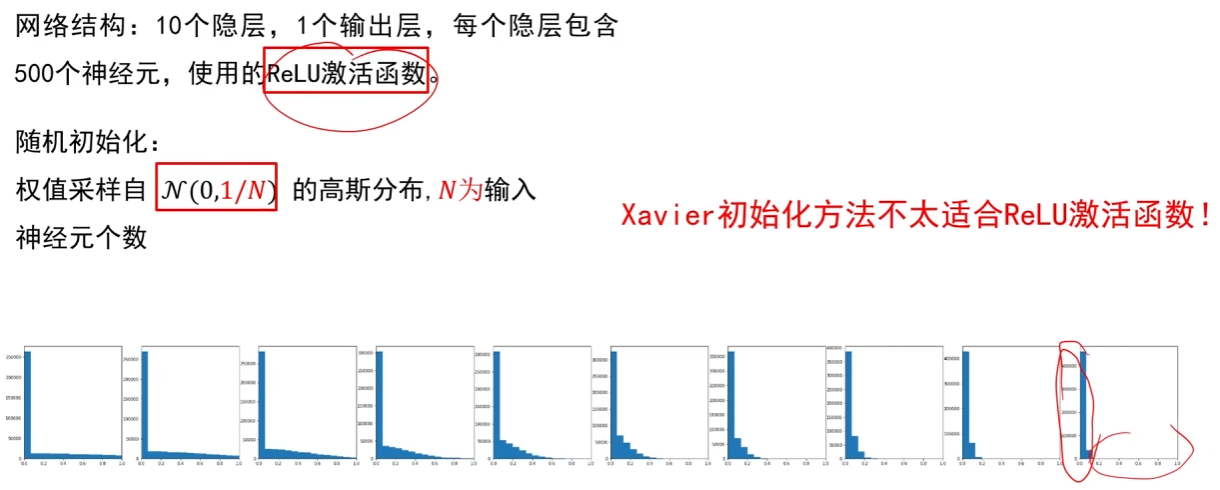
2. Xavier 初始化:适配 Sigmoid/Tanh 的 “方差匹配” 策略

Xavier 初始化的核心思想:让 “前一层输出的方差” 等于 “当前层输入的方差”,避免输出值因多层叠加而趋近于 0 或 ±∞。

这张图是神经网络权值初始化的关键推导 —— 单个神经元的输出,由输入与对应权值的加权和经过激活函数得到。假设输入和权值的均值均为 0,可推导出输出方差等于 “输入数量 × 权值方差 × 输入方差”;只要将权值方差设为 “1 除以输入数量”,就能让输出与输入的方差保持一致,避免数据在网络传播中出现方差爆炸或消失,这也是后续经典初始化方法的核心理论依据。
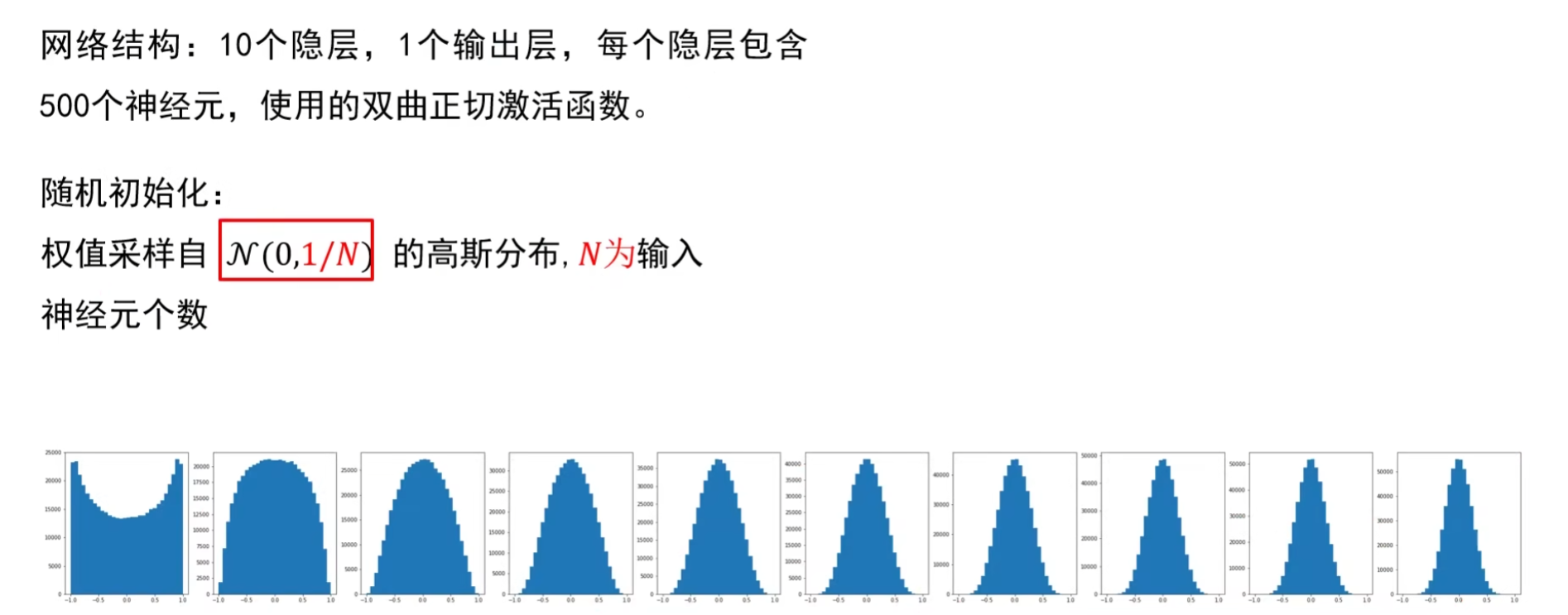
首先明确网络配置:这是一个包含 10 个隐层(每层 500 个神经元)+1 个输出层的网络,隐层激活函数采用双曲正切函数。
其权值初始化方式,正是对应之前推导的理论结论 —— 权值从均值为 0、方差为 1/N 的高斯分布(N(0,1/N))中采样,其中N是当前层的输入神经元个数。
图下方的一系列直方图,是网络各层激活值的分布情况:能看到从第 1 层到后续层,激活值的分布形状始终保持稳定,没有出现 “方差急剧放大 / 缩小” 的情况。这也验证了该初始化方法的有效性 —— 通过约束权值方差,让网络各层的激活值波动维持在合理范围,避免了方差爆炸或消失的问题。
小结:
Xavier 初始化是适配 Sigmoid/Tanh 激活函数的 “方差匹配” 策略,其完整逻辑形成了从理论推导到实践验证的闭环:
从单个神经元的输出方差推导出发,通过假设输入、权值的均值为 0,得出 “将权值方差设为 1/N(N 为输入神经元数),可让输出与输入方差一致” 的核心结论;
在实际网络中,按 “均值 0、方差 1/N 的高斯分布” 采样权值后,各层激活值的分布始终保持稳定,成功避免了数据传播中的方差爆炸 / 消失问题,最终实现了 “前层输出方差与后层输入方差匹配” 的初始化目标。
3. He 初始化:专为 ReLU 设计的 “梯度友好” 方案
He 初始化(由何凯明提出)针对 ReLU 的特性优化:ReLU 会 “丢弃” 输入≤0 的神经元(约 50% 的输入),因此需要将方差扩大一倍,补偿被丢弃的信息。
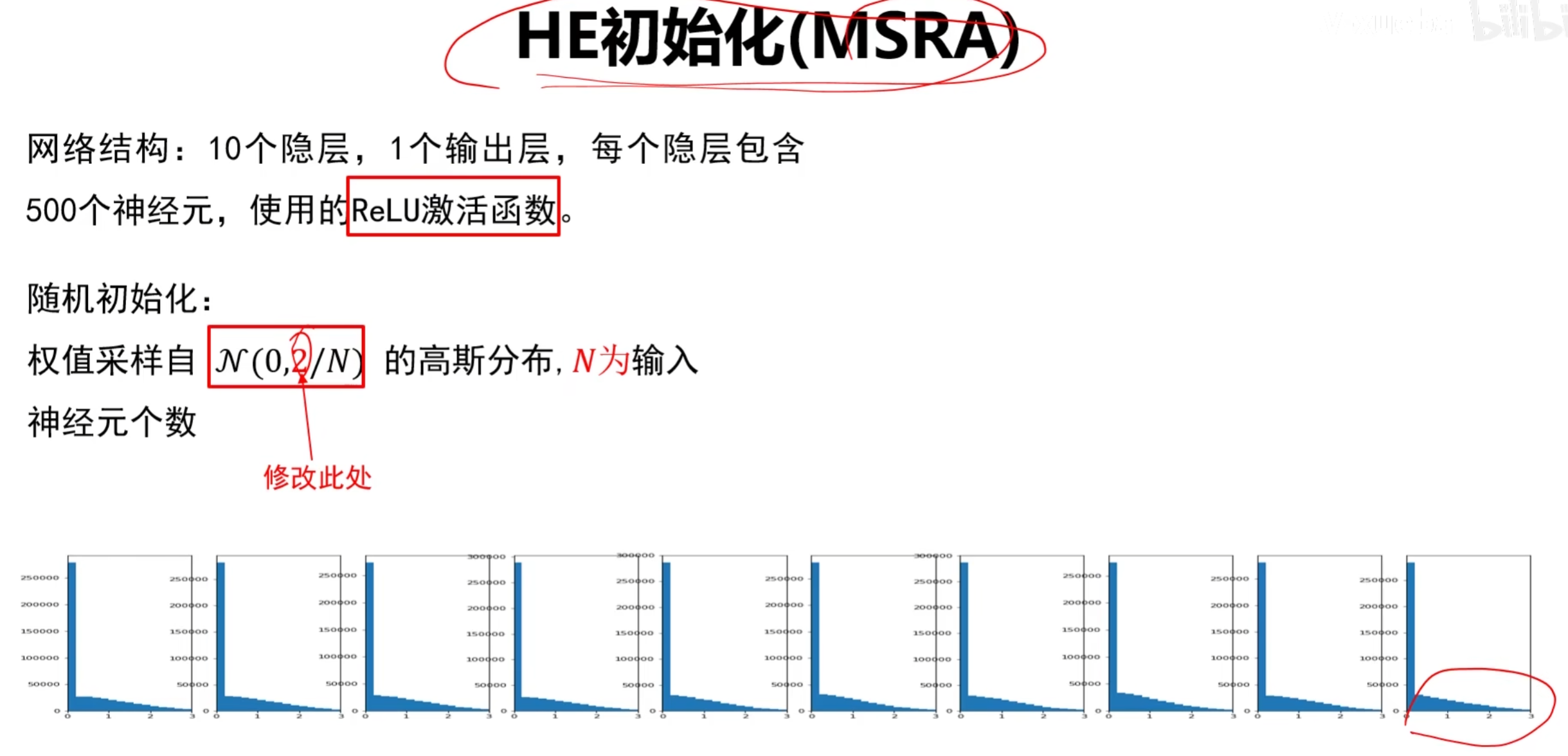
适用场景:
仅用于 ReLU 及其变体(如 Leaky ReLU)—— 课程中验证:用 He 初始化的 ReLU 网络,前层输出的方差能保持稳定,梯度回传更顺畅,收敛速度比 Xavier 初始化快 30% 以上。
权值初始化总结:

| 初始化方法 | 适配激活函数 | 核心逻辑 |
|---|---|---|
| 全零初始化 | 无(不可用) | 神经元输出 / 梯度一致,无法训练 |
| 随机初始化 | 无(不推荐) | 方差失控,易导致梯度异常 |
| Xavier 初始化 | Sigmoid/Tanh | 匹配输入输出方差,避免饱和 |
| He 初始化 | ReLU/Leaky ReLU | 扩大方差,补偿 ReLU 丢弃的神经元 |
思考感悟:
教授i想传递的核心认知是:模型初始化从来不是 “随便选个方法就行” 的细节,而是决定模型 “能否正常学习、如何高效学习” 的底层前提。
全零初始化看似 “统一公平”,却让所有神经元输出、梯度完全同质化,直接掐断了模型学习的可能性 —— 这是 “用简单统一替代合理设计” 的反面教材;无约束的随机初始化看似 “灵活”,但方差失控带来的梯度爆炸 / 消失,会让模型还没开始学习就陷入 “数据传着传着就‘变味’” 的困境;而 Xavier 与 He 初始化的差异,则更清晰地体现了 “适配性” 的重要性:Sigmoid/Tanh 容易饱和,所以 Xavier 用 “方差匹配” 避免数据落到饱和区;ReLU 会丢弃负半轴神经元,He 初始化就通过扩大方差来补偿信息损失 ——不同的组件(激活函数)特性,需要对应的初始化逻辑来适配,“匹配组件特性” 才是让模型稳定、高效学习的关键。
说到底,模型设计是个 “系统适配工程”:每个环节的选择(哪怕是初始化这种 “开头步骤”),都得贴合其他组件的特性,脱离了适配性的 “方法选择”,要么让模型 “学不了”,要么让模型 “学不好”。
四、批归一化(BN):让每一层 “平稳训练” 的关键技术
即使选对了激活函数、优化器和初始化,深层网络仍会遇到 “内部协变量偏移”(Internal Covariate Shift)问题 —— 随着训练推进,前层参数更新会导致后层输入的分布持续变化,后层需要不断 “适应” 新分布,导致训练缓慢且不稳定。批归一化(Batch Normalization,BN)正是为解决这一问题而生。
1. 批归一化的核心目的:解决 “内部协变量偏移”
用 “工厂流水线” 比喻:
- 若前工序(前层)的产品(输入)规格持续变化,后工序(后层)就需要不断调整设备(参数),效率低下;
- BN 相当于在每道工序间加一个 “标准化环节”,将产品规格固定在统一标准,后工序只需按标准生产,效率大幅提升。
数学上:BN 将每一层的输入 “归一化” 到均值 = 0、方差 = 1 的分布,让后层的输入分布稳定,避免因前层参数更新导致的分布波动。
2. 批归一化的四步流程:从 “批统计” 到 “缩放平移”
BN 通常应用于 “线性变换后、激活函数前”(即对 z=Wx+b 进行归一化),具体步骤如下(针对某一层的小批量样本,批量大小为 m):

问:“输出的 0 均值 1 方差正态分布是最有利于网络分类的分布吗?”
答:不一定。这正是 γ 和 β 存在的核心价值 —— 它们并非人工预设的超参数,而是神经网络能自主学习的参数:既让网络借助归一化获得更稳定的训练节奏,又能让网络根据分类任务的实际需求,灵活调整数据分布的均值与方差,避免强制归一化造成的特征信息失真。
问:“当使用单张样本进行模型测试时,批归一化所需的均值和方差应如何设置?”
解决方案:测试阶段的均值和方差来自模型训练过程 —— 训练时会持续记录每个训练批次的均值与方差,最终通过计算这些批次统计量的平均值(实际工程中常用 “指数移动平均” 来更稳定地积累统计量),将该结果作为测试阶段的均值和方差。
4. 批归一化的工程价值
课程总结了 批归一化(BN) 的三大核心作用:
- 加速收敛:解决内部协变量偏移,后层无需频繁适应前层分布变化,收敛速度可提升 2~3 倍;
- 缓解梯度消失:归一化后的输入更接近激活函数的 “线性区”(如 ReLU 的输入 > 0、Sigmoid 的输入∈[-1,1]),梯度更顺畅;
- 降低初始化敏感度:即使初始化稍差,BN 也能通过归一化调整输入分布,让模型仍能启动训练。
“批归一化(BN) 是深层网络的‘标配技术’—— 几乎所有超过 10 层的全连接网络或 CNN 都会用到 批归一化(BN),它让深层模型的训练变得更稳定、更高效。”
五、学习感悟:从 “理论建模” 到 “工程优化” 的思维转变
这一讲的内容让我深刻意识到:“深度学习不是‘公式堆砌’,而是‘工程问题的针对性解决’”—— 全连接网络的训练优化,每一个策略都对应一个具体的工程痛点,没有 “万能方法”,只有 “适配场景的方案”。我的核心收获有三点:
1. 对 “梯度” 的认知升级:从 “数学工具” 到 “训练命脉”
最初我认为梯度只是 “求导的结果”,但课程中梯度消失 / 爆炸的例子让我明白:梯度是 “参数更新的指令”,一旦梯度传递中断,整个训练就会停滞。激活函数的选择、权重初始化、BN 的引入,本质上都是为了 “保证梯度顺畅传递”—— 这是训练所有深度学习模型的核心前提。
2. 工程优化的核心逻辑:“针对性解决痛点” 而非 “盲目堆砌方法”
例如,动量法解决 “震荡”,RMSprop 解决 “步长自适应”,Adam 融合两者;Xavier 适配 Sigmoid,He 适配 ReLU;BN 解决内部协变量偏移 —— 每一个优化策略都有明确的 “解决目标”,而非 “为了复杂而复杂”。工程实践中,应先定位问题(如损失不下降→查梯度是否消失;损失震荡→试动量法),再选择对应方案。
3. 超参数调优的启示:“没有万能参数,只有适配任务的参数”
课程中提到:Adam 的默认参数在大多数任务中有效,但并非所有场景 —— 若任务数据噪声大,可减小学习率;若任务收敛慢,可适当调大 β₁(增强动量)。这让我明白:超参数调优不是 “试错”,而是 “基于问题的推理”—— 理解每个参数的物理意义(如 β₁控制动量惯性),才能更高效地找到适配参数。
结语
鲁鹏教授的 “全连接神经网络(中)”,完整搭建了全连接网络的 “训练优化体系”—— 从激活函数的梯度特性,到梯度下降的工程改进,再到权重初始化和 BN 的应用,这些内容不仅是全连接网络的训练关键,更是后续 CNN、Transformer 等复杂模型的 “通用优化框架”。
下一篇笔记中,我将继续梳理课程的 “全连接神经网络(下)”,重点学习 “过拟合的解决方法”(如正则化、Dropout)和 “全连接网络的实践案例”(如 CIFAR-10 分类)。如果有同方向的学习者对 “Adam 的参数调优”“BN 的实现细节” 有疑问,欢迎在评论区交流 —— 深度学习的学习之路,需要在 “理论理解” 与 “工程实践” 中不断迭代,才能真正掌握其核心逻辑。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)