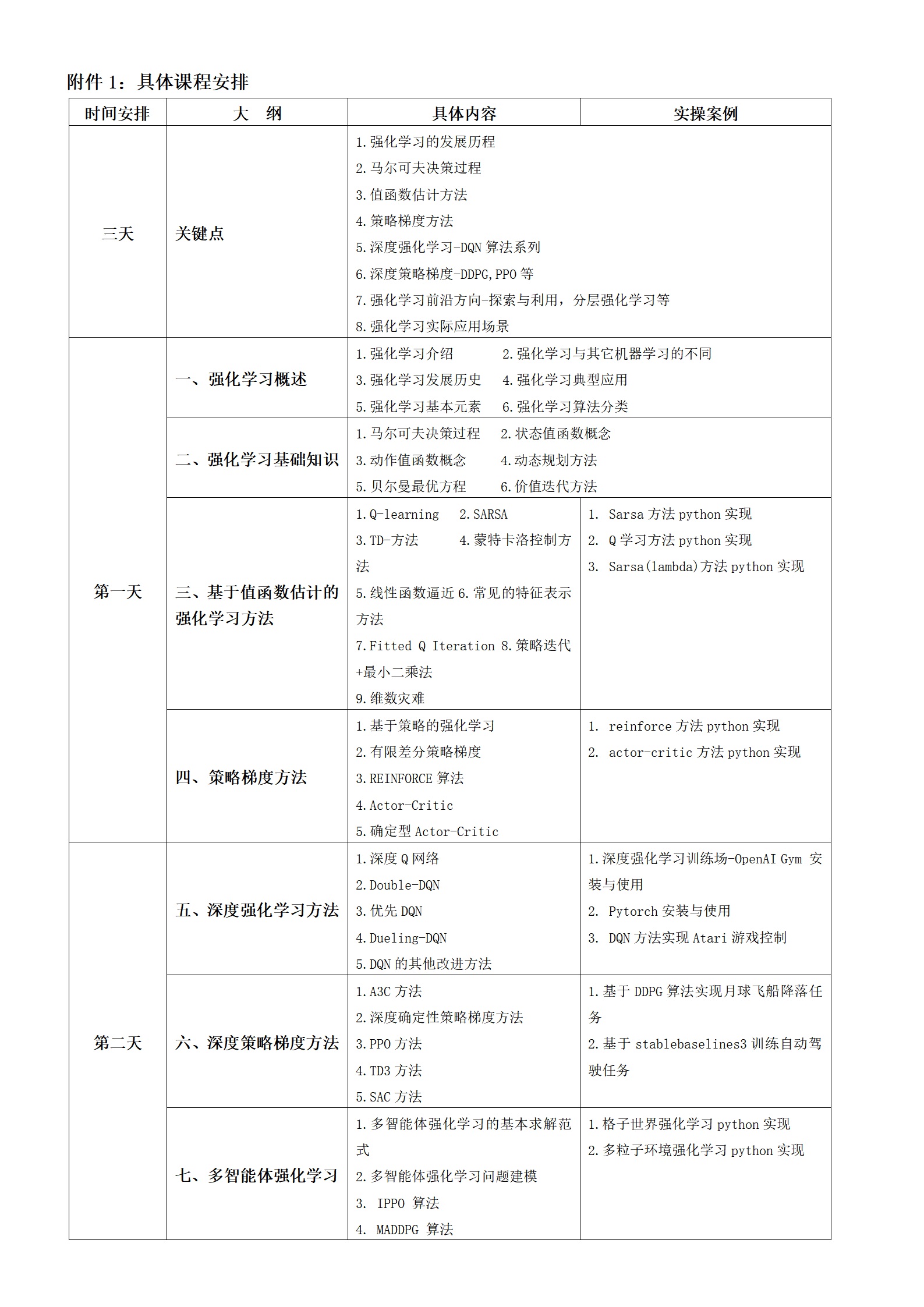
强化学习赋能路径规划:技术演进与应用实践
在机器人导航领域,强化学习赋予机器人自主探索未知环境的能力,通过不断试错调整移动策略,实现复杂地形下的精准定位与路径规划,广泛应用于仓储机器人、巡检机器人等场景。与传统方法相比,强化学习的核心优势在于其强大的动态适应能力——无需预先构建完整的环境模型,就能通过实时交互应对环境中的突发变化,例如自动驾驶中的临时交通管制、机器人导航中的动态障碍物避让等场景。尽管当前仍面临样本效率、奖励函数设计等挑战,
路径规划是智能系统实现自主决策的核心环节,广泛应用于自动驾驶、机器人导航、物流调度等领域。传统路径规划方法如Dijkstra算法、A*算法虽能解决简单场景下的最优路径求解问题,但在动态环境、多约束条件等复杂场景中,往往存在适应性差、决策滞后等不足。强化学习作为一种基于“试错”的机器学习方法,通过智能体与环境的持续交互优化决策策略,为复杂场景下的路径规划提供了全新解决方案。本文将从技术逻辑、核心优势、应用场景及发展趋势四个维度,探讨强化学习在路径规划领域的应用价值与实践路径。
强化学习路径规划的核心逻辑是构建“智能体-环境-奖励”的交互闭环。在这一框架中,智能体作为路径规划的执行主体,通过传感器感知环境状态(如障碍物位置、交通流量、地形信息等);环境根据智能体的行动(如转向、加速、避让等)产生新的状态反馈;奖励函数则作为优化导向,对智能体的“优行动”(如路径最短、耗时最少、能耗最低)给予正向奖励,对“劣行动”(如碰撞、偏离目标、路径冗余)给予负向惩罚。智能体通过不断迭代更新策略,最终学习到适配特定场景的最优路径规划方案。与传统方法相比,强化学习的核心优势在于其强大的动态适应能力——无需预先构建完整的环境模型,就能通过实时交互应对环境中的突发变化,例如自动驾驶中的临时交通管制、机器人导航中的动态障碍物避让等场景。
在实际应用中,强化学习已成为解决复杂路径规划问题的关键技术。在自动驾驶领域,基于深度强化学习的路径规划系统能够融合摄像头、激光雷达等多传感器数据,实时感知道路环境,动态规划避障路径与行驶轨迹,同时兼顾行驶安全性与舒适性。例如,特斯拉Autopilot系统通过强化学习优化路径决策,可在拥堵路段实现自适应跟车与高效变道。在机器人导航领域,强化学习赋予机器人自主探索未知环境的能力,通过不断试错调整移动策略,实现复杂地形下的精准定位与路径规划,广泛应用于仓储机器人、巡检机器人等场景。在物流调度领域,强化学习能够统筹考虑货物数量、运输成本、时效要求等多约束条件,优化车辆行驶路径与配送顺序,有效提升物流配送效率,降低运输成本。此外,在无人机航拍、星际探测等特殊场景中,强化学习也能应对复杂环境下的路径规划挑战,保障任务的顺利执行。
尽管强化学习在路径规划领域已取得显著进展,但仍面临诸多挑战。一是样本效率问题,强化学习需要大量交互样本才能优化出稳定的策略,在实际场景中可能存在训练成本高、周期长的问题;二是奖励函数设计难题,复杂场景下多目标优化(如安全与效率、成本与时效)的奖励权重难以平衡,易导致策略偏向性;三是安全性保障不足,训练过程中的“试错”行为可能导致实际应用中的安全风险,如自动驾驶中的碰撞隐患。针对这些问题,业界正在通过融合迁移学习、模仿学习等技术提升样本效率,借助多目标优化算法优化奖励函数设计,同时通过仿真训练与真实场景逐步适配的方式降低安全风险。
未来,强化学习路径规划将朝着“多智能体协同”“跨场景泛化”“与其他技术深度融合”的方向发展。多智能体强化学习将实现多个智能体(如多辆自动驾驶车辆、多个机器人)的协同路径规划,提升群体任务的执行效率;跨场景泛化能力的提升将使强化学习模型能够快速适配不同环境,降低场景迁移成本;而与深度学习、大数据、物联网等技术的深度融合,将进一步增强环境感知的精准度与决策的智能化水平。随着技术的不断迭代,强化学习有望在更多复杂场景中替代传统路径规划方法,为智能系统的自主决策提供更可靠、更高效的技术支撑。
综上所述,强化学习以其独特的动态适应能力,为复杂场景下的路径规划提供了创新解决方案,在自动驾驶、机器人导航等领域展现出广阔的应用前景。尽管当前仍面临样本效率、奖励函数设计等挑战,但随着技术的持续突破,强化学习必将推动路径规划技术向更智能、更高效、更安全的方向发展,为智能产业的升级赋能。
相关学习推荐:强化学习核心技术理论与应用课程



腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 31
31 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)