LightRAG应用二-[文档Postgres数据库存储]
前言
LightRAG 将上传的文档进行 向量存储,数据库采用Postgres
一、安装、配置
-
安装PostgreSQL 16.9 (忽略 Apache age 图形扩展插件的安装)
-
.env 文件 配置,如下:
### PostgreSQL
LIGHTRAG_KV_STORAGE=PGKVStorage
LIGHTRAG_DOC_STATUS_STORAGE=PGDocStatusStorage
###注意修改PGGraphStorage为NetworkXStorage,防止未安装Postgres / Apache age图形扩展的安装报错
LIGHTRAG_GRAPH_STORAGE=NetworkXStorage
LIGHTRAG_VECTOR_STORAGE=PGVectorStorage
### PostgreSQL Configuration
POSTGRES_HOST=localhost
POSTGRES_PORT=5432
POSTGRES_USER=postgres
POSTGRES_PASSWORD='postgres'
POSTGRES_DATABASE=postgres
POSTGRES_MAX_CONNECTIONS=12
### DB specific workspace should not be set, keep for compatible only
### POSTGRES_WORKSPACE=forced_workspace_name
### PostgreSQL Vector Storage Configuration
### Vector storage type: HNSW, IVFFlat, VCHORDRQ
POSTGRES_VECTOR_INDEX_TYPE=HNSW
POSTGRES_HNSW_M=16
POSTGRES_HNSW_EF=200
POSTGRES_IVFFLAT_LISTS=100
POSTGRES_VCHORDRQ_BUILD_OPTIONS=
POSTGRES_VCHORDRQ_PROBES=
POSTGRES_VCHORDRQ_EPSILON=1.9
说明:
LightRAG 使用 4 种类型的存储来满足不同用途:
- KV_STORAGE:LLM 响应缓存、文本块、文档信息 -> 配置为:PGKVStorage,存储在
lightrag_doc_chunks、lightrag_doc_full、lightrag_entity_chunks、lightrag_full_entities、lightrag_full_relations、lightrag_llm_cache、lightrag_relation_chunks 等表中 - VECTOR_STORAGE:实体向量、关系向量、文本块向量 -> 配置为:PGVectorStorage ,存储在
lightrag_vdb_chunks_text_embedding_v1_1536d、lightrag_vdb_entity_text_embedding_v1_1536d、lightrag_vdb_relation_text_embedding_v1_1536d表中 - GRAPH_STORAGE:实体关系图 -> 配置为:NetworkXStorage,存储在 graph_chunk_entity_relation.graphml文件中
- DOC_STATUS_STORAGE:文档索引状态 -> 配置为:PGDocStatusStorage,信息存储在 lightrag_doc_status表
提示: PostgreSQL需要安装 AGE 插件,才能在PostgreSQL库中存储图形数据, 故GRAPH_STORAGE参数值由:PGGraphStorage 修改为 默认的 NetworkXStorage,即 存在在内存中的图,否则报错:DETAIL: Could not open extension control file "~PostgreSQL/share/extension/age.control": No such file or directory
实体关系图最终以文件的形式存储在:%LightRAG%\rag_storage\graph_chunk_entity_relation.graphml
- 终端启动
lightrag-server
二、文档(管理) & 检索
1.上传文件、文件切分、加强embedding 与存储
文件【 智慧城市.xlsx】

2.检索
用户输入【智慧城市客服服务人数是多少?】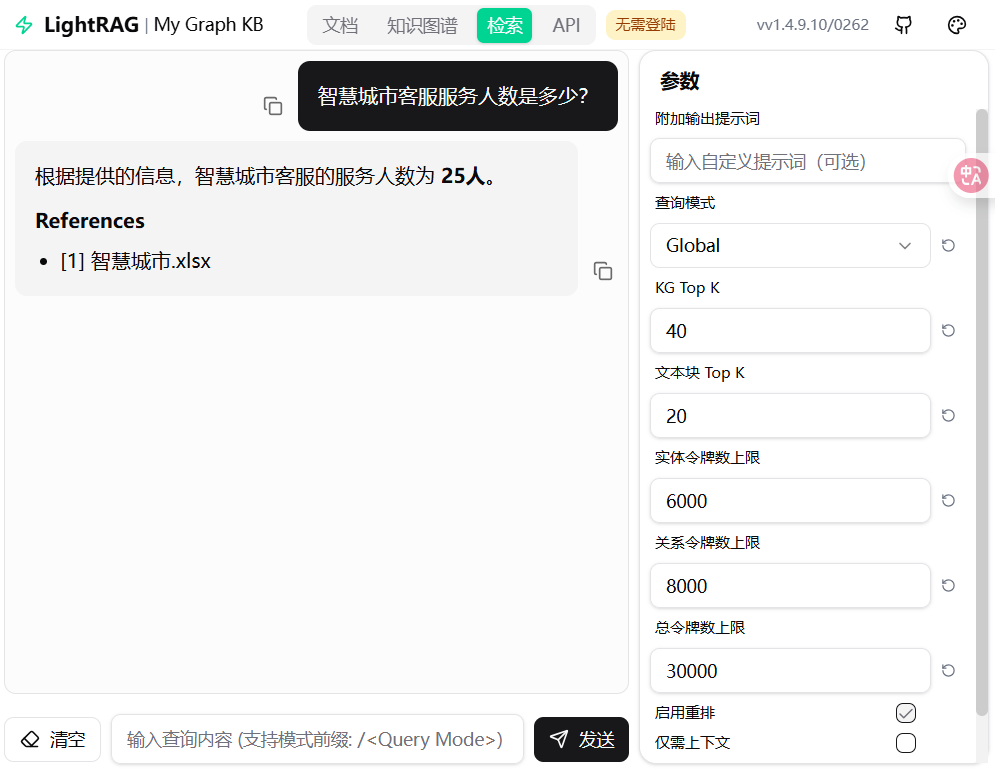
PostgreSQL 存储 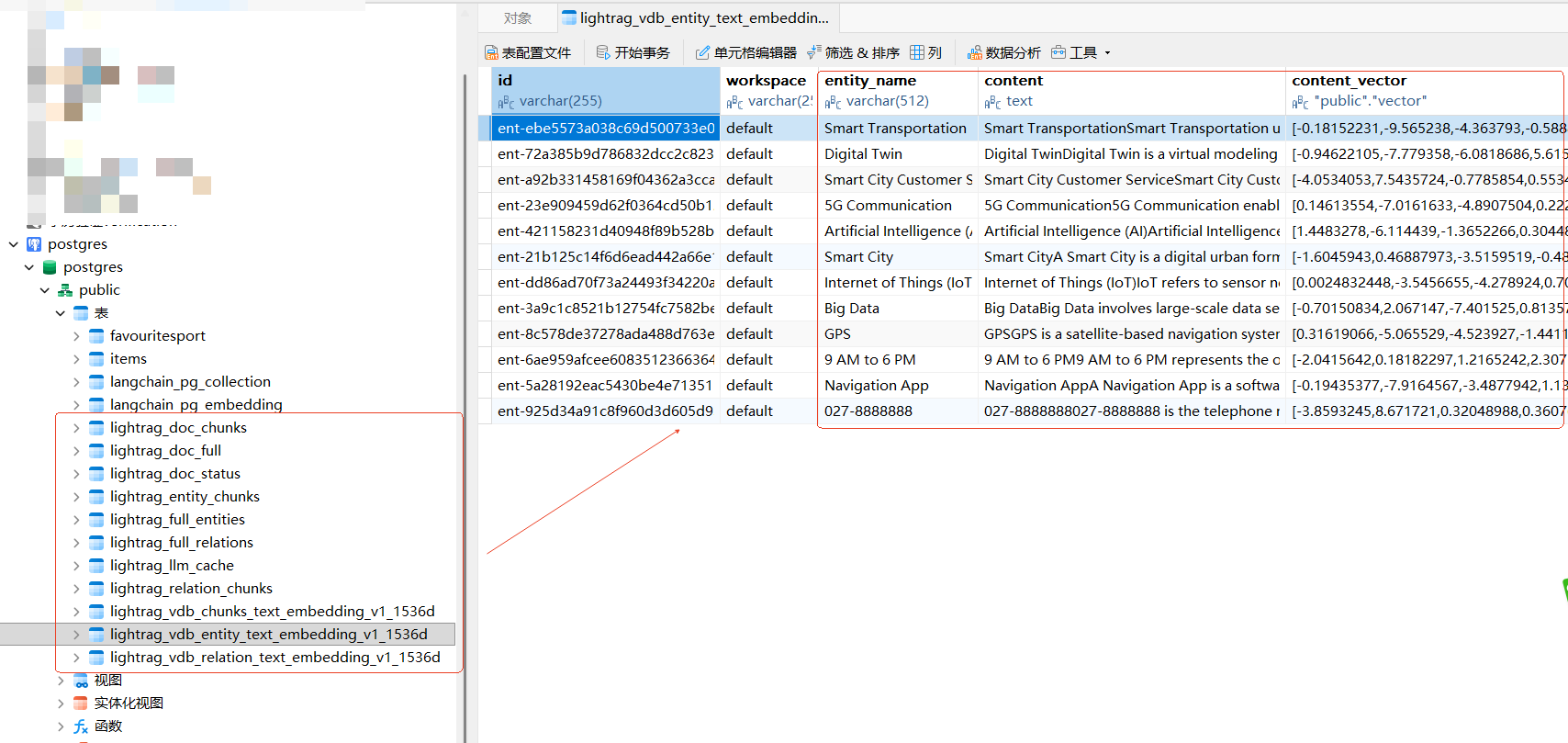
提示: 上传中文文档,vdb_entity_text_embedding、vdb_relation_text_embedding 存储的 entity_text、relation_text 为英文 ,原因见 【三、大模型对于存在英文抽取的解释】
三、大模型对于存在英文抽取的解释
本地解决办法
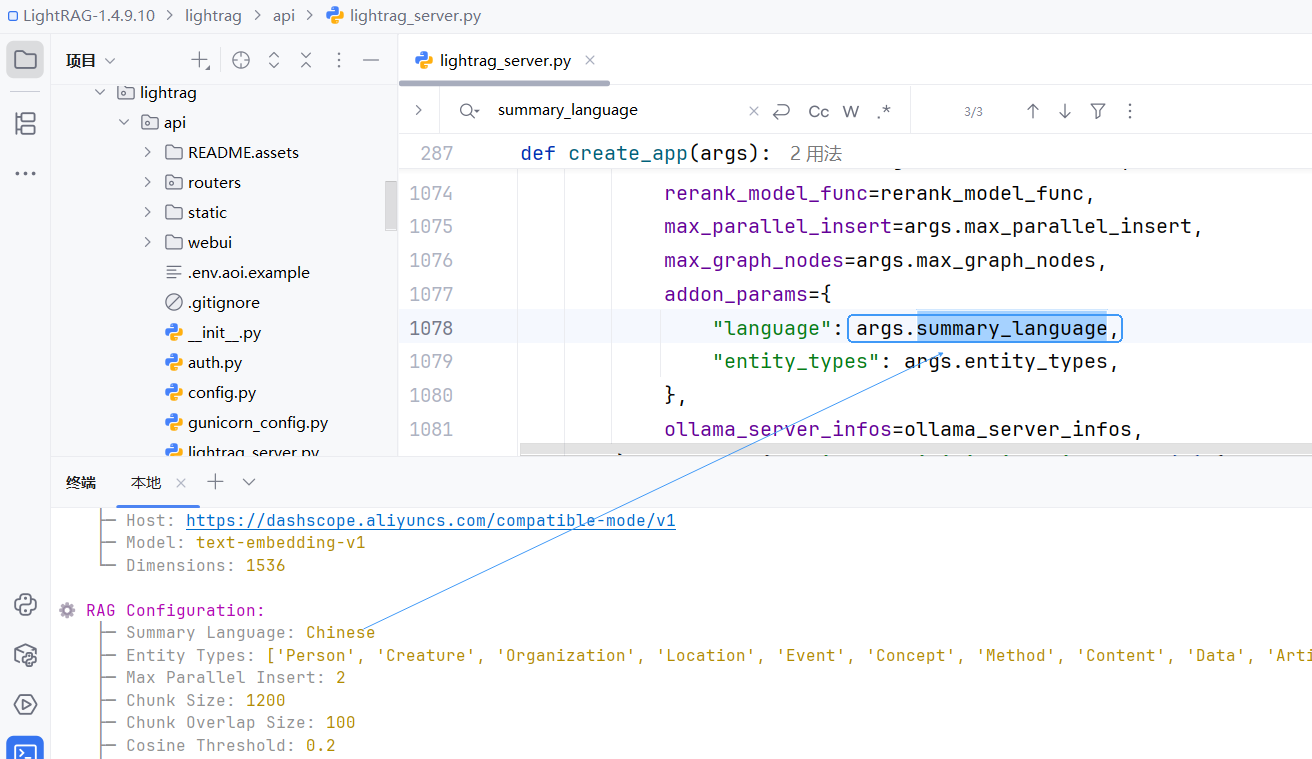
.env文件: 修改 SUMMARY_LANGUAGE = Chinese
### Document processing output language: English, Chinese, French, German ...
SUMMARY_LANGUAGE=Chinese
lightrag_server.py文件(lightrag/api/)
try:
rag = LightRAG(
working_dir=args.working_dir,
workspace=args.workspace,
llm_model_func=create_llm_model_func(args.llm_binding),
llm_model_name=args.llm_model,
llm_model_max_async=args.max_async,
summary_max_tokens=args.summary_max_tokens,
summary_context_size=args.summary_context_size,
chunk_token_size=int(args.chunk_size),
chunk_overlap_token_size=int(args.chunk_overlap_size),
llm_model_kwargs=create_llm_model_kwargs(
args.llm_binding, args, llm_timeout
),
embedding_func=embedding_func,
......
addon_params={
###env参数SUMMARY_LANGUAGE设置language
"language": args.summary_language,
"entity_types": args.entity_types,
},
ollama_server_infos=ollama_server_infos,
)
except Exception as e:
logger.error(f"Failed to initialize LightRAG: {e}")
raise
观察启动日志
知识图谱效果图: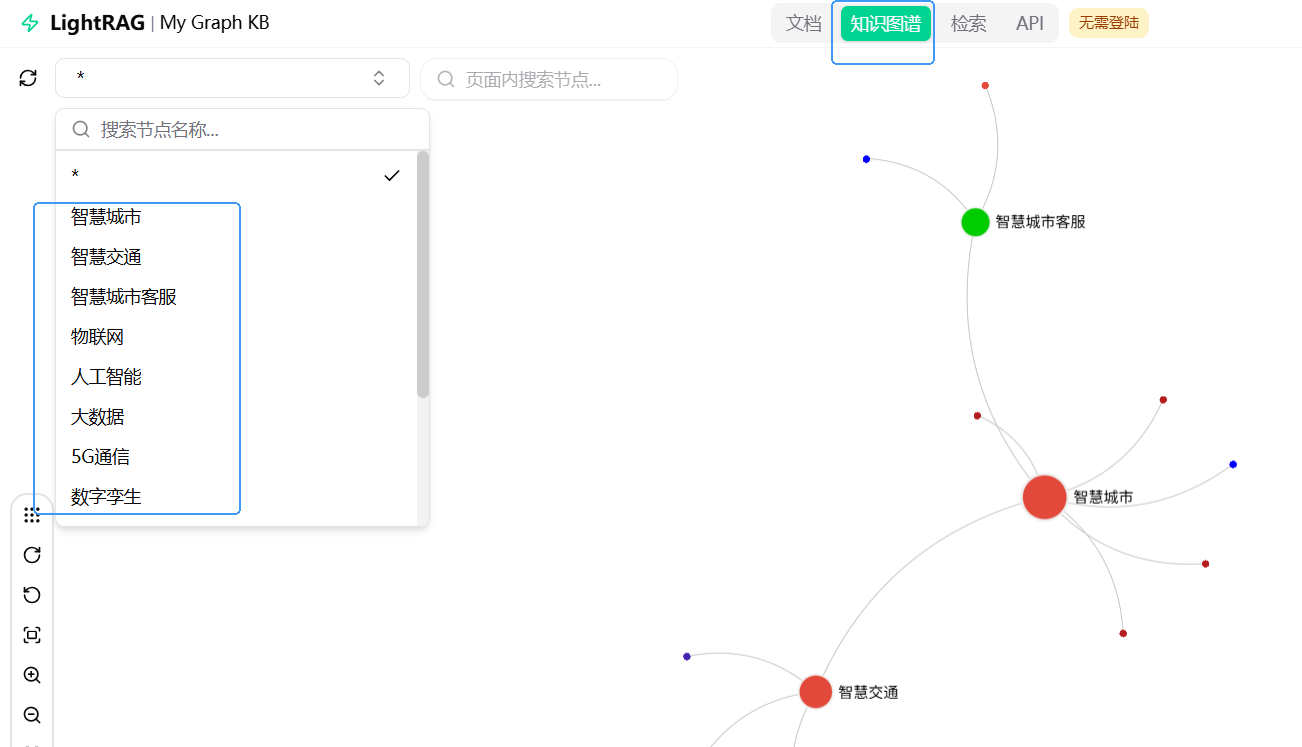
四、数据隔离
LightRAG 使用工作空间来确保不同实例之间的向量数据在逻辑上是分离的。这对于多租户应用程序或在同一存储基础设施上管理多个不同项目至关重要,可以防止一个实例的数据干扰另一个实例。
引用 【LightRAG 数据隔离】

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)