window java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$POSIX
·
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan;
import org.apache.spark.sql.execution.SparkPlan;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.Arrays;
import java.util.List;
public class SparkTask {
public static void main(String[] args) {
System.setProperty("HADOOP_HOME", "D:\\hadoop-3.0.3");
System.setProperty("HIVE_HOME", "D:\\apache-hive-3.1.0-bin");
System.setProperty("HIVE_CONF_DIR", "D:\\apache-hive-3.1.0-bin\\conf");
SparkSession sparkSession = SparkSession
.builder()
.master("local[*]")
// .config("spark.sql.queryExecutionListeners", "com.crock.listener.FieldLineageListener") // 注册监听器
.enableHiveSupport()
.getOrCreate();
// 创建示例数据
List<Row> data = Arrays.asList(
RowFactory.create(100, "Alice", 34),
RowFactory.create(10, "Bob", 45),
RowFactory.create(1,"Cathy", 29)
);
// 定义 schema
StructType schema = new StructType(new StructField[]{
new StructField("id", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("name", DataTypes.StringType, false, Metadata.empty()),
new StructField("age", DataTypes.IntegerType, false, Metadata.empty())
});
// 创建 DataFrame
Dataset<Row> dfA = sparkSession.createDataFrame(data, schema);
// 创建示例数据
List<Row> datab = Arrays.asList(
RowFactory.create(100, "Alice", 34),
RowFactory.create(10, "Bob", 45),
RowFactory.create(1,"Cathy", 29)
);
// 定义 schema
StructType schemab = new StructType(new StructField[]{
new StructField("id", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("name", DataTypes.StringType, false, Metadata.empty()),
new StructField("age", DataTypes.IntegerType, false, Metadata.empty())
});
// 创建 DataFrame
Dataset<Row> dfB = sparkSession.createDataFrame(datab, schemab);
sparkSession.sql("create table if not exists table_c (id int, name string)");
// 创建临时视图(只在当前 session 有效)
dfA.createOrReplaceTempView("table_a");
dfB.createOrReplaceTempView("table_b");
Dataset<Row> sql = sparkSession.sql("insert into table_c SELECT a.id, b.name FROM table_a a JOIN table_b b ON a.id = b.id");
// Dataset<Row> sql = sparkSession.sql("with abc as (select 1 as id , 'abc' as name) SELECT a.id, b.name FROM table_a a JOIN table_b b ON a.id = b.id join abc on a.id=abc.id");
// sql.explain(true);
// sql.logicalPlan();
System.out.println("---------------------------analyzer--------------------------------------");
LogicalPlan analyzed = sql.queryExecution().analyzed();
System.out.println(analyzed);
System.out.println("---------------------------analyzer--------------------------------------");
LogicalPlan optimizedPlan = sql.queryExecution().optimizedPlan();
System.out.println(optimizedPlan);
System.out.println("---------------------------物理执行计划--------------------------------------");
SparkPlan sparkPlan = sql.queryExecution().sparkPlan();
System.out.println(sparkPlan);
System.out.println("---------------------------执行计划--------------------------------------");
SparkPlan executedPlan = sql.queryExecution().executedPlan();
System.out.println(executedPlan);
// System.out.println(sql.queryExecution().logical());
}
}
问题:
java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$POSIX.stat(Ljava/lang/String;)

下载 hadoop 配置 HADOOP_HOME 环境变量
通过 https://github.com/Zer0r3/winutils ,下载 winutils.exe、hadoop.dll 注意版本对应,winutils.exe 放到 %HADOOP_HOME%/bin 目录下,hadoop.dll 放到 c:/Windows/System32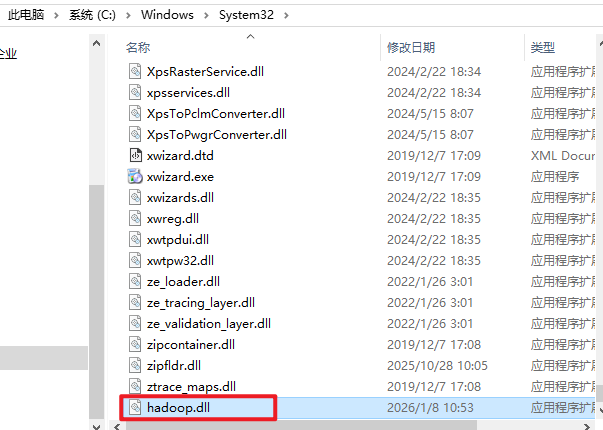
----------------------------- 以下没用到 -----------------------------
下载 hadoop 源码
复制 org.apache.hadoop.io.nativeio.NativeIO 源码并新建 NativeIO.java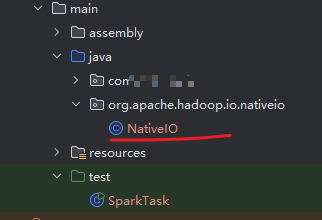

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)