【机器学习案例-35】Kaggle案例之洪水预测:从数据分析可视化到机器学习模型SVM/RF/GBDT/Xgboost/LightGBM/CatBoost的构建和模型交叉验证
洪水作为全球发生频率最高、影响范围最广的自然灾害之一,每年造成数以百亿计的经济损失和大量人员伤亡。传统的洪水预警多依赖于水文监测站的实时数据和经验判断,存在预警滞后、覆盖范围有限、精准度不足等问题。本项目旨在通过机器学习技术,整合环境、人为、基础设施、社会经济等多维度数据,构建高精度的洪水概率预测模型。本项目使用的洪水预测数据集为专业气象与地理数据机构整理的结构化数据集,具备以下特征:探索性数据分
🧑 博主简介:曾任某智慧城市类企业
算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)
💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。

【机器学习案例-35】Kaggle案例之洪水预测:从数据分析可视化到机器学习模型SVM/RF/GBDT/Xgboost/LightGBM/CatBoost的构建和模型交叉验证
- 洪水预测:从数据分析到机器学习模型构建
-
- 一、项目深度解析
-
- 1.1 项目背景与应用价值
- 1.2 数据集全方位介绍
-
- 1.2.1 数据集基本信息
- 1.2.2 字段详细说明
- 1.3 技术栈与项目流程
-
- 1.3.1 核心技术栈
- 1.4 数据加载
- 二、探索性数据分析(EDA)
-
- 2.1 数据分布可视化的业务意义
- 2.2 相关性分析的核心价值
- 2.3 高级数据可视化
- 三、特征工程
-
- 3.1 特征工程的设计思路
- 四、模型训练与评估
-
- 4.1.1 数据集划分
- 4.1.2 模型训练和评估
- 4.1.3 模型性能可视化
- 4.1.4 交叉验证与模型优化
- 五、项目总结与改进建议
- 六、完整代码使用说明
-
- 6.1 环境要求
- 6.2 运行步骤
- 6.3 结果解读
- 6.4 注意事项
洪水预测:从数据分析到机器学习模型构建
一、项目深度解析
1.1 项目背景与应用价值
洪水作为全球发生频率最高、影响范围最广的自然灾害之一,每年造成数以百亿计的经济损失和大量人员伤亡。传统的洪水预警多依赖于水文监测站的实时数据和经验判断,存在预警滞后、覆盖范围有限、精准度不足等问题。
本项目旨在通过机器学习技术,整合环境、人为、基础设施、社会经济等多维度数据,构建高精度的洪水概率预测模型。
1.2 数据集全方位介绍
1.2.1 数据集基本信息
本项目使用的洪水预测数据集为专业气象与地理数据机构整理的结构化数据集,具备以下特征:
- 数据规模:50,000行样本 × 21列特征(含目标变量)
- 数据来源:整合了全球多个洪水高发地区的历史监测数据、气象记录、地理信息和社会经济统计数据
- 数据类型:所有特征均为数值型(浮点/整型),无缺失值、无分类变量,数据质量优良
- 时间跨度:涵盖近10年的洪水事件记录,包含不同季节、不同极端天气条件下的样本
1.2.2 字段详细说明
| 字段名称 | 字段含义 | 取值范围 | 对洪水的影响逻辑 |
|---|---|---|---|
| MonsoonIntensity | 季风强度 | 1-10 | 核心影响因素,强度越高,降雨量大,洪水风险越高 |
| TopographyDrainage | 地形排水能力 | 1-10 | 数值越低,排水能力越差,洪水易积聚 |
| RiverManagement | 河流管理水平 | 1-10 | 管理水平越高,河道疏浚、防洪设施越完善 |
| Deforestation | 森林砍伐程度 | 1-10 | 砍伐越严重,水土保持能力越差,径流系数越高 |
| Urbanization | 城市化程度 | 1-10 | 城市化率高,硬化地面多,地表径流增加 |
| ClimateChange | 气候变化影响 | 1-10 | 数值越高,极端降雨事件发生频率越高 |
| DamsQuality | 大坝质量 | 1-10 | 质量越高,防洪调蓄能力越强 |
| Siltation | 河道淤积程度 | 1-10 | 淤积越严重,河道行洪能力越弱 |
| AgriculturalPractices | 农业耕作方式 | 1-10 | 不合理耕作(如陡坡种植)加剧水土流失 |
| Encroachments | 河道侵占程度 | 1-10 | 侵占越严重,行洪断面越小 |
| IneffectiveDisasterPreparedness | 防灾准备不足程度 | 1-10 | 数值越高,应急响应能力越弱(间接影响损失) |
| DrainageSystems | 排水系统完善度 | 1-10 | 系统越完善,城市内涝风险越低 |
| CoastalVulnerability | 沿海脆弱性 | 1-10 | 数值越高,风暴潮引发洪水风险越高 |
| Landslides | 山体滑坡风险 | 1-10 | 滑坡堵塞河道易形成堰塞湖,诱发洪水 |
| Watersheds | 流域特征 | 1-10 | 流域调蓄能力的综合表征 |
| DeterioratingInfrastructure | 基础设施老化程度 | 1-10 | 老化越严重,防洪设施失效概率越高 |
| PopulationScore | 人口密度与分布 | 1-10 | 数值越高,洪水影响范围和损失越大 |
| WetlandLoss | 湿地损失程度 | 1-10 | 湿地越少,天然调蓄洪水能力越弱 |
| InadequatePlanning | 规划不足程度 | 1-10 | 城市规划不合理,加剧洪水风险 |
| PoliticalFactors | 政策执行力度 | 1-10 | 政策执行越到位,防洪措施落地越好 |
| FloodProbability | 洪水概率(目标变量) | 0-1 | 待预测的洪水发生概率,0为无风险,1为极高风险 |
1.3 技术栈与项目流程
1.3.1 核心技术栈
- 数据处理:Pandas(数据清洗、特征工程)、NumPy(数值计算)
- 可视化:Matplotlib、Seaborn(探索性分析、结果展示)
- 机器学习:Scikit-learn(模型训练评估)、涉及SVM/RF/GBDT/XGBoost/LightGBM/CatBoost
- 特征工程:自定义特征提取、特征交互、多项式特征构建
1.4 数据加载
# ==============================================
# 1. 导入必要的库
# ==============================================
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import skew, kurtosis
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体和图表样式
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
sns.set_style("whitegrid")
# 机器学习相关库
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV
from sklearn.preprocessing import StandardScaler, PolynomialFeatures
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.svm import SVR
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from catboost import CatBoostRegressor
# ==============================================
# 2. 数据加载与初步探索
# ==============================================
# 加载数据
print("="*60)
print("洪水预测数据集加载")
print("="*60)
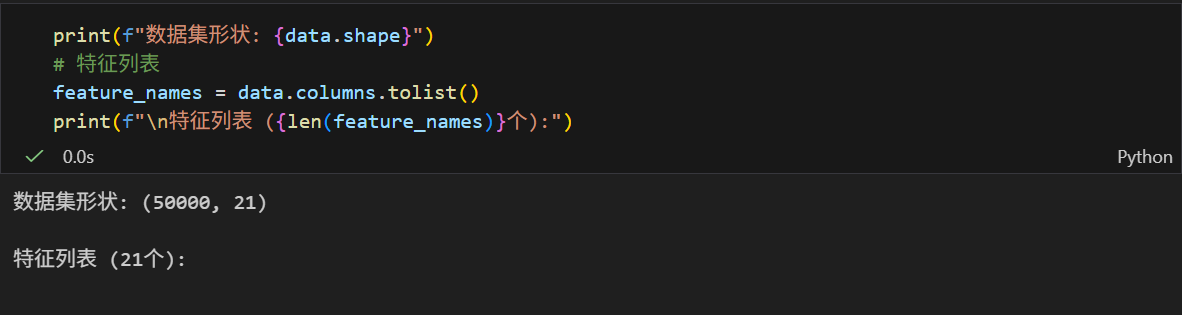
data = pd.read_csv("flood.csv")
print(f"数据集形状: {data.shape}")
print(f"行数: {data.shape[0]}, 列数: {data.shape[1]}")
# 显示前几行数据
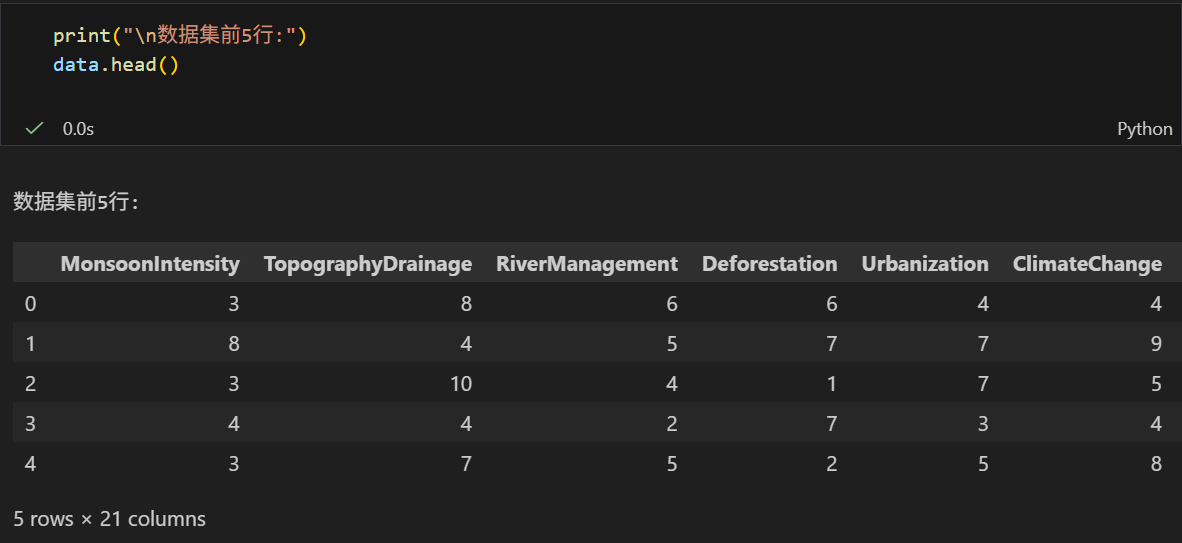
print("\n数据集前5行:")
print(data.head())
# 显示数据基本信息
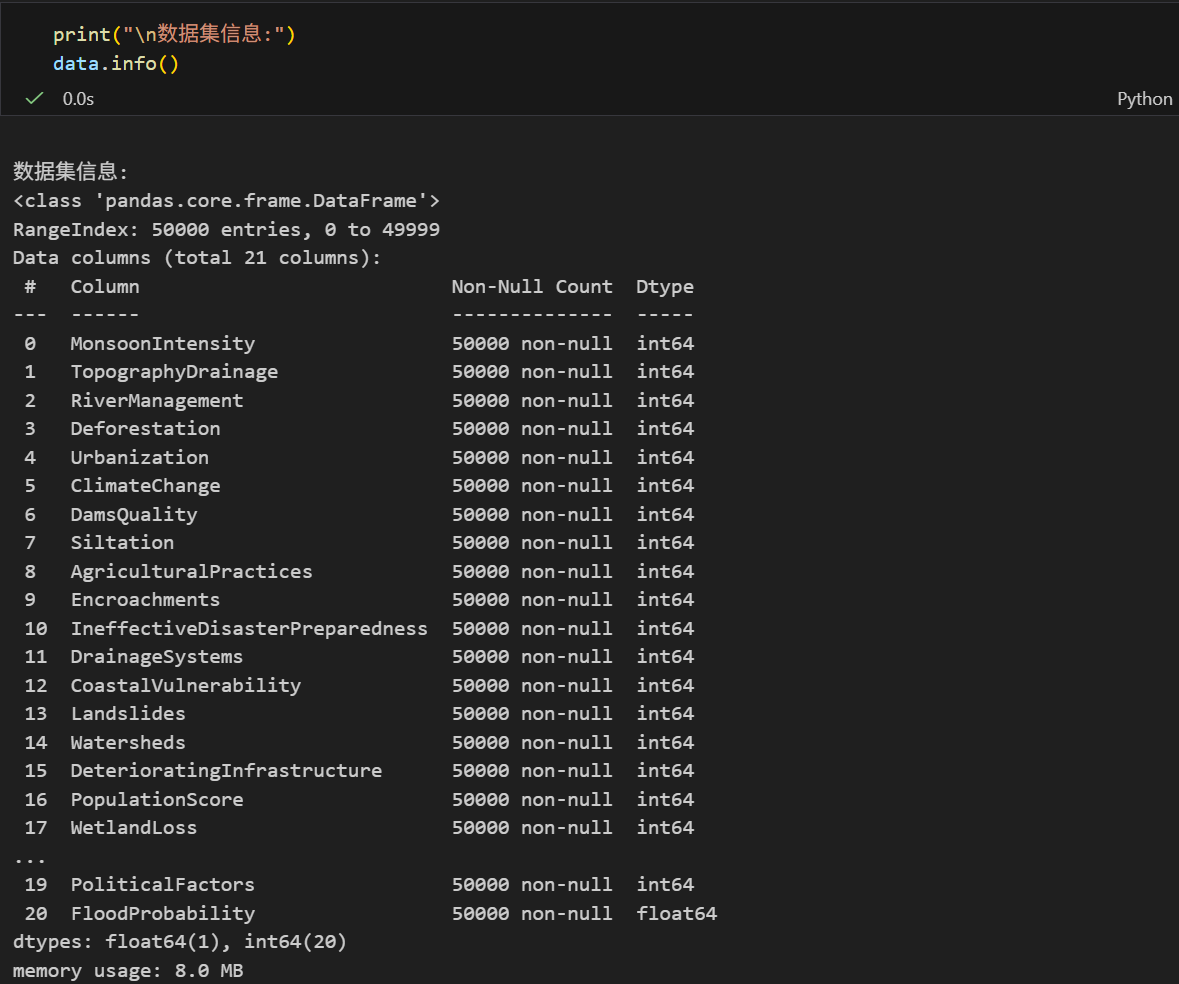
print("\n数据集信息:")
print(data.info())
# 显示描述性统计
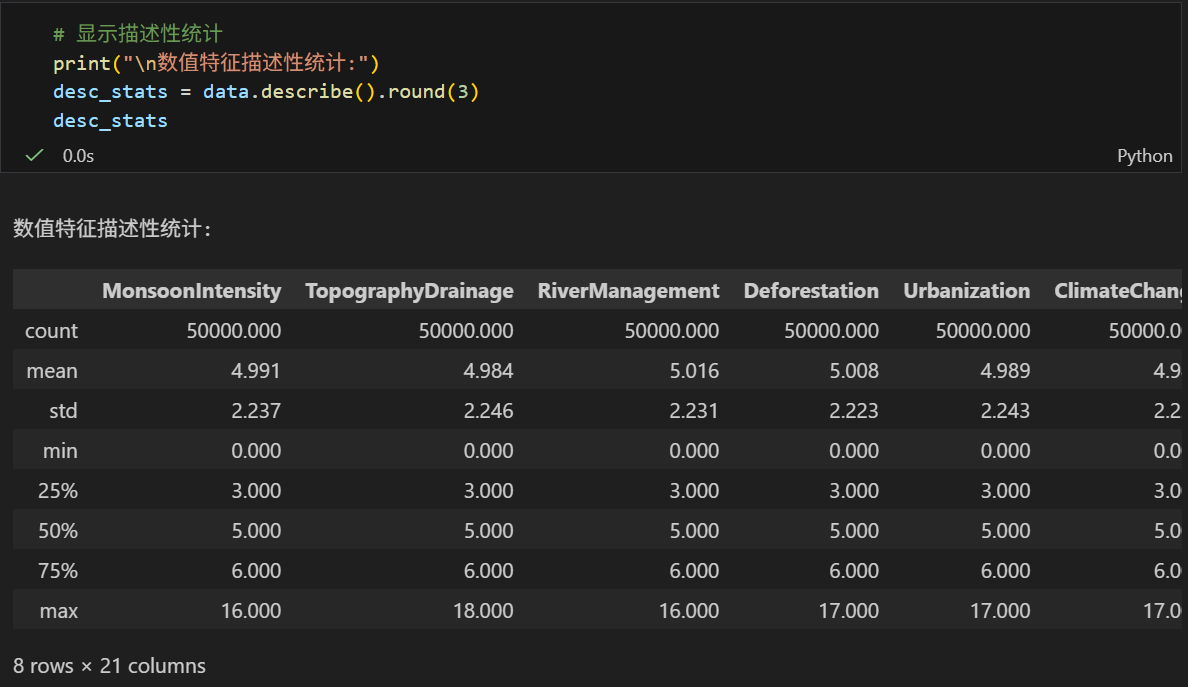
print("\n数值特征描述性统计:")
desc_stats = data.describe().round(3)
print(desc_stats)
# 检查缺失值
print("\n缺失值统计:")
print(data.isnull().sum())
# 特征列表
feature_names = data.columns.tolist()
print(f"\n特征列表 ({len(feature_names)}个):")
print(feature_names)
# 目标变量信息
target_col = 'FloodProbability'
print(f"\n目标变量: {target_col}")
print(f"取值范围: [{data[target_col].min():.3f}, {data[target_col].max():.3f}]")
print(f"平均值: {data[target_col].mean():.3f}")
print(f"中位数: {data[target_col].median():.3f}")
# 筛选数值特征(确保仅使用数值型特征建模)
# 核心代码:过滤出int64/float64类型的特征,排除非数值干扰
numerical_features = [col for col in data.columns if data[col].dtype in ['int64', 'float64']]
print(f"\n筛选后的数值特征列表 ({len(numerical_features)}个):")
print(numerical_features)
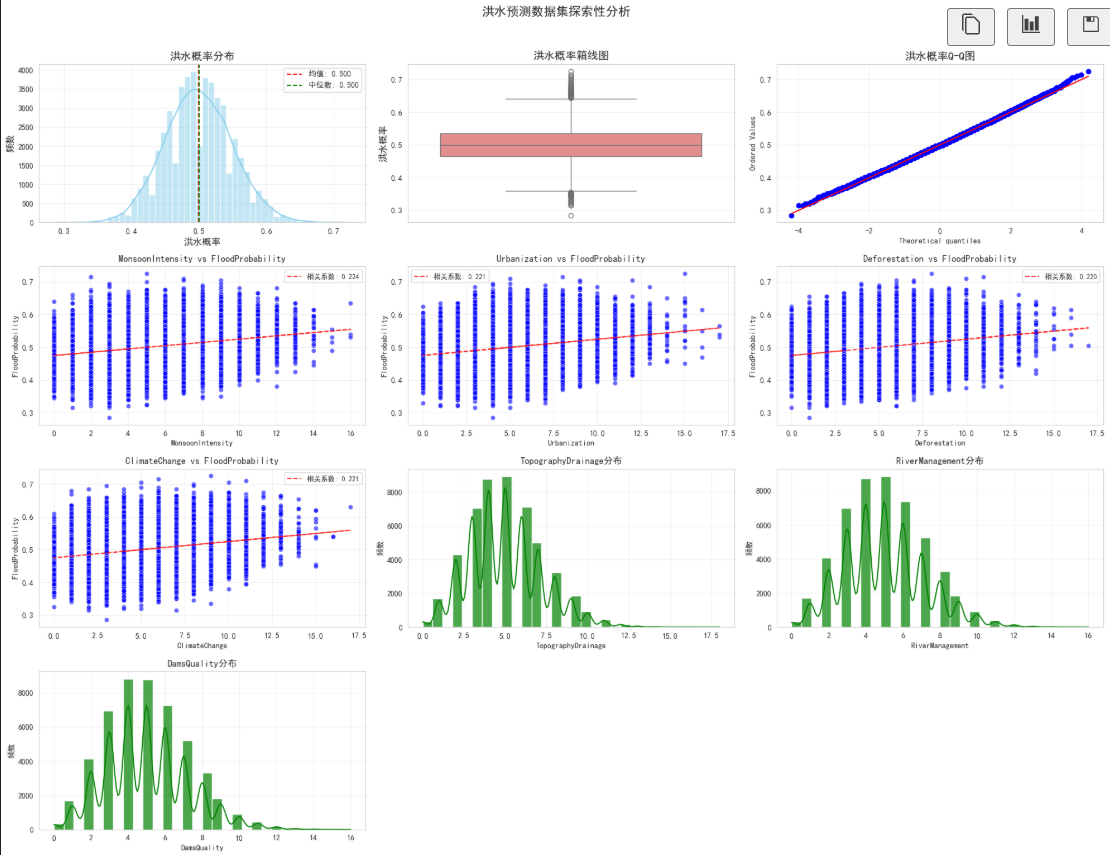
二、探索性数据分析(EDA)
2.1 数据分布可视化的业务意义
探索性数据分析是机器学习项目的核心前置步骤,通过可视化手段可以:
- 识别数据分布特征(如目标变量是否正态分布、是否存在异常值)
- 发现特征与目标变量的相关性,筛选核心影响因素
- 为后续特征工程提供方向(如是否需要对数变换、是否需要构建交互特征)
- 验证业务逻辑(如季风强度与洪水概率是否呈正相关)
# ==============================================
# 3. 数据可视化分析
# ==============================================
def create_eda_visualizations(data, target_col='FloodProbability'):
"""创建综合EDA可视化图表"""
# 创建综合图表
fig = plt.figure(figsize=(20, 15))
# 1. 目标变量分布
ax1 = plt.subplot(3, 3, 1)
sns.histplot(data[target_col], kde=True, bins=50, color='skyblue', ax=ax1)
ax1.axvline(data[target_col].mean(), color='red', linestyle='--',
label=f'均值: {data[target_col].mean():.3f}')
ax1.axvline(data[target_col].median(), color='green', linestyle='--',
label=f'中位数: {data[target_col].median():.3f}')
ax1.set_title('洪水概率分布', fontsize=14, fontweight='bold')
ax1.set_xlabel('洪水概率', fontsize=12)
ax1.set_ylabel('频数', fontsize=12)
ax1.legend(fontsize=10)
ax1.grid(alpha=0.3)
# 2. 目标变量箱线图
ax2 = plt.subplot(3, 3, 2)
sns.boxplot(y=data[target_col], color='lightcoral', ax=ax2)
ax2.set_title('洪水概率箱线图', fontsize=14, fontweight='bold')
ax2.set_ylabel('洪水概率', fontsize=12)
ax2.grid(axis='y', alpha=0.3)
# 3. 目标变量Q-Q图
ax3 = plt.subplot(3, 3, 3)
from scipy import stats
stats.probplot(data[target_col], dist="norm", plot=ax3)
ax3.set_title('洪水概率Q-Q图', fontsize=14, fontweight='bold')
ax3.grid(alpha=0.3)
# 4. 特征与目标变量的散点图(选择几个关键特征)
key_features = ['MonsoonIntensity', 'Urbanization', 'Deforestation', 'ClimateChange']
for i, feature in enumerate(key_features, 4):
ax = plt.subplot(3, 3, i)
sns.scatterplot(data=data, x=feature, y=target_col, alpha=0.6,
color='blue', ax=ax)
# 添加趋势线
z = np.polyfit(data[feature], data[target_col], 1)
p = np.poly1d(z)
ax.plot(data[feature], p(data[feature]), "r--", alpha=0.8,
label=f'相关系数: {data[feature].corr(data[target_col]):.3f}')
ax.set_title(f'{feature} vs {target_col}', fontsize=12)
ax.set_xlabel(feature, fontsize=10)
ax.set_ylabel(target_col, fontsize=10)
ax.legend(fontsize=9)
ax.grid(alpha=0.3)
# 5. 特征分布直方图(剩余位置)
remaining_features = [col for col in data.columns if col != target_col
and col not in key_features][:3]
for i, feature in enumerate(remaining_features, 8):
ax = plt.subplot(3, 3, i)
sns.histplot(data[feature], kde=True, bins=30, color='green', alpha=0.7, ax=ax)
ax.set_title(f'{feature}分布', fontsize=12)
ax.set_xlabel(feature, fontsize=10)
ax.set_ylabel('频数', fontsize=10)
ax.grid(alpha=0.3)
plt.suptitle('洪水预测数据集探索性分析', fontsize=16, fontweight='bold', y=1.02)
plt.tight_layout()
plt.show()
return key_features
# 创建可视化
key_features = create_eda_visualizations(data)
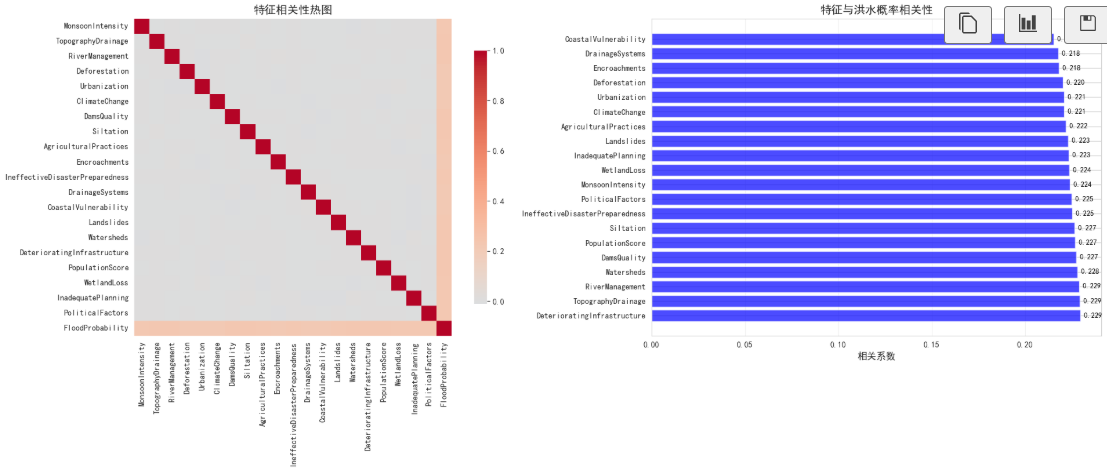
2.2 相关性分析的核心价值
相关性分析是特征筛选的关键手段,通过计算皮尔逊相关系数,可以:
- 量化特征与目标变量的线性关系强度(|r|>0.5为强相关,0.3<|r|<0.5为中等相关)
- 识别特征间的多重共线性(相关系数>0.8需警惕)
- 为特征工程优先级提供依据(高相关特征优先优化)
# ==============================================
# 4. 相关性分析与热图
# ==============================================
def analyze_correlations(data, target_col='FloodProbability'):
"""分析特征相关性"""
# 计算相关性矩阵
corr_matrix = data.corr()
# 创建相关性热图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 8))
# 1. 完整相关性热图
sns.heatmap(corr_matrix, annot=False, fmt='.2f', cmap='coolwarm',
center=0, square=True, cbar_kws={"shrink": 0.8}, ax=ax1)
ax1.set_title('特征相关性热图', fontsize=14, fontweight='bold')
# 2. 与目标变量的相关性排序
target_corr = corr_matrix[target_col].drop(target_col).sort_values(ascending=False)
colors = ['red' if x < 0 else 'blue' for x in target_corr.values]
bars = ax2.barh(range(len(target_corr)), target_corr.values, color=colors, alpha=0.7)
ax2.set_yticks(range(len(target_corr)))
ax2.set_yticklabels(target_corr.index)
ax2.set_title('特征与洪水概率相关性', fontsize=14, fontweight='bold')
ax2.set_xlabel('相关系数', fontsize=12)
ax2.axvline(x=0, color='black', linestyle='-', linewidth=0.5)
ax2.grid(axis='x', alpha=0.3)
# 添加数值标签
for i, (bar, value) in enumerate(zip(bars, target_corr.values)):
ax2.text(value, i, f' {value:.3f}', va='center', fontsize=9,
color='white' if abs(value) > 0.3 else 'black')
plt.tight_layout()
plt.show()
# 打印相关性最高的特征
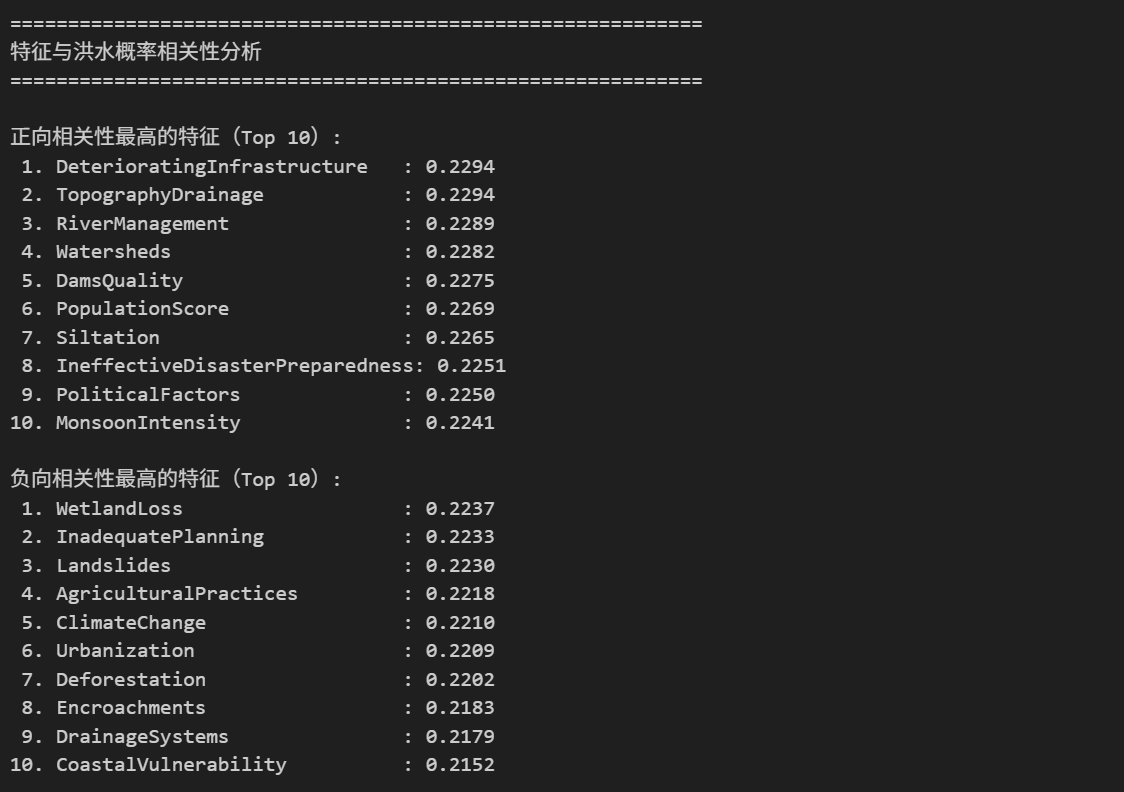
print("\n" + "="*60)
print("特征与洪水概率相关性分析")
print("="*60)
print("\n正向相关性最高的特征(Top 10):")
for i, (feature, corr_value) in enumerate(target_corr.head(10).items(), 1):
print(f"{i:2d}. {feature:<30}: {corr_value:.4f}")
print("\n负向相关性最高的特征(Top 10):")
for i, (feature, corr_value) in enumerate(target_corr.tail(10).items(), 1):
print(f"{i:2d}. {feature:<30}: {corr_value:.4f}")
return target_corr
# 执行相关性分析
target_corr = analyze_correlations(data)
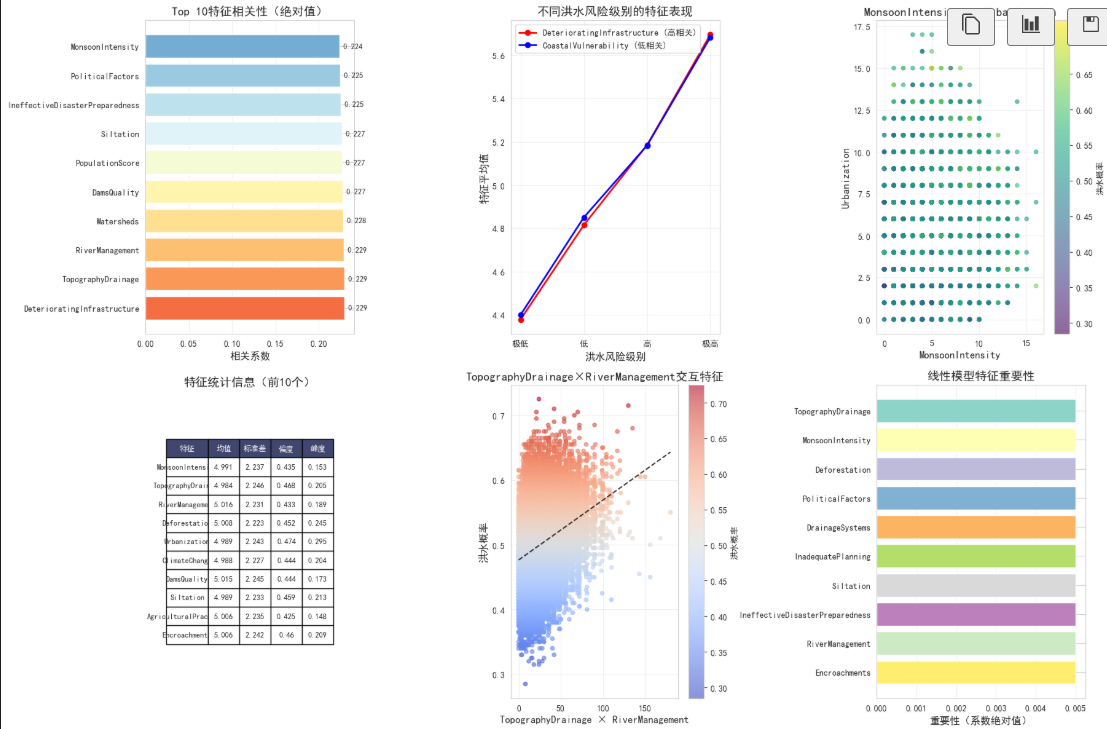
2.3 高级数据可视化
# ==============================================
# 5. 高级数据可视化
# ==============================================
def create_advanced_visualizations(data, target_col='FloodProbability'):
"""创建高级可视化图表"""
fig = plt.figure(figsize=(18, 12))
# 1. 特征重要性初步分析(基于相关性)
ax1 = plt.subplot(2, 3, 1)
top_features = target_corr.abs().nlargest(10).index
top_corr_values = target_corr[top_features]
colors = plt.cm.RdYlBu(np.linspace(0.2, 0.8, len(top_features)))
bars = ax1.barh(range(len(top_features)), top_corr_values.values, color=colors)
ax1.set_yticks(range(len(top_features)))
ax1.set_yticklabels(top_features)
ax1.set_title('Top 10特征相关性(绝对值)', fontsize=14, fontweight='bold')
ax1.set_xlabel('相关系数', fontsize=12)
ax1.axvline(x=0, color='black', linestyle='-', linewidth=0.5)
ax1.grid(axis='x', alpha=0.3)
# 添加数值标签
for i, (bar, value) in enumerate(zip(bars, top_corr_values.values)):
ax1.text(value, i, f' {value:.3f}', va='center', fontsize=9)
# 2. 特征分布对比(高相关 vs 低相关)
ax2 = plt.subplot(2, 3, 2)
high_corr_feature = target_corr.idxmax() # 最高正相关特征
low_corr_feature = target_corr.idxmin() # 最高负相关特征
# 创建分组
data['FloodRisk'] = pd.qcut(data[target_col], q=4, labels=['极低', '低', '高', '极高'])
for feature, label, color in [(high_corr_feature, '高相关', 'red'),
(low_corr_feature, '低相关', 'blue')]:
group_means = data.groupby('FloodRisk')[feature].mean()
ax2.plot(group_means.index, group_means.values, 'o-',
label=f'{feature} ({label})', color=color, linewidth=2)
ax2.set_title('不同洪水风险级别的特征表现', fontsize=14, fontweight='bold')
ax2.set_xlabel('洪水风险级别', fontsize=12)
ax2.set_ylabel('特征平均值', fontsize=12)
ax2.legend(fontsize=10)
ax2.grid(alpha=0.3)
# 3. 特征对分布图
ax3 = plt.subplot(2, 3, 3)
scatter_features = ['MonsoonIntensity', 'Urbanization']
scatter = ax3.scatter(data[scatter_features[0]], data[scatter_features[1]],
c=data[target_col], cmap='viridis', alpha=0.6, s=20)
ax3.set_title(f'{scatter_features[0]} vs {scatter_features[1]}',
fontsize=14, fontweight='bold')
ax3.set_xlabel(scatter_features[0], fontsize=12)
ax3.set_ylabel(scatter_features[1], fontsize=12)
plt.colorbar(scatter, ax=ax3, label='洪水概率')
ax3.grid(alpha=0.3)
# 4. 特征统计信息
ax4 = plt.subplot(2, 3, 4)
ax4.axis('tight')
ax4.axis('off')
# 计算特征统计
feature_stats = pd.DataFrame({
'特征': data.drop(target_col, axis=1).columns,
'均值': data.drop(target_col, axis=1).mean().values,
'标准差': data.drop(target_col, axis=1).std().values,
'偏度': data.drop(target_col, axis=1).apply(skew).values,
'峰度': data.drop(target_col, axis=1).apply(kurtosis).values
}).round(3).head(10)
table = ax4.table(cellText=feature_stats.values,
colLabels=feature_stats.columns,
cellLoc='center',
loc='center',
colWidths=[0.2, 0.15, 0.15, 0.15, 0.15])
table.auto_set_font_size(False)
table.set_fontsize(9)
table.scale(1, 1.5)
# 设置表头样式
for i in range(len(feature_stats.columns)):
table[(0, i)].set_facecolor('#40466e')
table[(0, i)].set_text_props(weight='bold', color='white')
ax4.set_title('特征统计信息(前10个)', fontsize=14, fontweight='bold', y=0.98)
# 5. 特征交互可视化
ax5 = plt.subplot(2, 3, 5)
# 选择两个高相关特征
high_corr_features = target_corr.nlargest(3).index.tolist()
if len(high_corr_features) >= 2:
feature1, feature2 = high_corr_features[1], high_corr_features[2]
# 创建交互特征
interaction = data[feature1] * data[feature2]
# 散点图
scatter = ax5.scatter(interaction, data[target_col],
alpha=0.6, c=data[target_col], cmap='coolwarm', s=20)
# 添加趋势线
z = np.polyfit(interaction, data[target_col], 1)
p = np.poly1d(z)
ax5.plot(sorted(interaction), p(sorted(interaction)), "k--", alpha=0.8)
ax5.set_title(f'{feature1}×{feature2}交互特征', fontsize=14, fontweight='bold')
ax5.set_xlabel(f'{feature1} × {feature2}', fontsize=12)
ax5.set_ylabel('洪水概率', fontsize=12)
plt.colorbar(scatter, ax=ax5, label='洪水概率')
ax5.grid(alpha=0.3)
# 6. 特征重要性对比图
ax6 = plt.subplot(2, 3, 6)
# 使用简单的线性模型获取特征重要性
from sklearn.linear_model import LinearRegression
X_temp = data.drop(target_col, axis=1)
y_temp = data[target_col]
lr_model = LinearRegression()
lr_model.fit(X_temp, y_temp)
# 特征重要性(系数绝对值)
feature_importance = pd.DataFrame({
'特征': X_temp.columns,
'重要性': np.abs(lr_model.coef_)
}).sort_values('重要性', ascending=False).head(10)
bars = ax6.barh(range(len(feature_importance)),
feature_importance['重要性'].values,
color=plt.cm.Set3(np.linspace(0, 1, len(feature_importance))))
ax6.set_yticks(range(len(feature_importance)))
ax6.set_yticklabels(feature_importance['特征'])
ax6.set_title('线性模型特征重要性', fontsize=14, fontweight='bold')
ax6.set_xlabel('重要性(系数绝对值)', fontsize=12)
ax6.invert_yaxis()
ax6.grid(axis='x', alpha=0.3)
plt.tight_layout()
plt.show()
# 移除临时列
data.drop('FloodRisk', axis=1, inplace=True)
# 创建高级可视化
create_advanced_visualizations(data)
三、特征工程
3.1 特征工程的设计思路
特征工程是提升模型性能的核心环节,本项目的特征工程遵循以下原则:
- 业务驱动:基于洪水形成的物理机制构建特征(如环境压力指数、人为影响指数)
- 维度提升:通过交互特征捕捉特征间的协同效应(如季风强度×城市化)
- 非线性变换:通过多项式特征拟合非线性关系(如特征平方项)
- 降维整合:将多个同类型特征整合为综合指数,减少维度冗余
# ==============================================
# 6. 特征工程
# ==============================================
class FloodFeatureEngineer:
"""洪水预测特征工程类"""
def __init__(self, data, target_col='FloodProbability'):
self.data = data.copy()
self.target_col = target_col
self.features = None
self.target = None
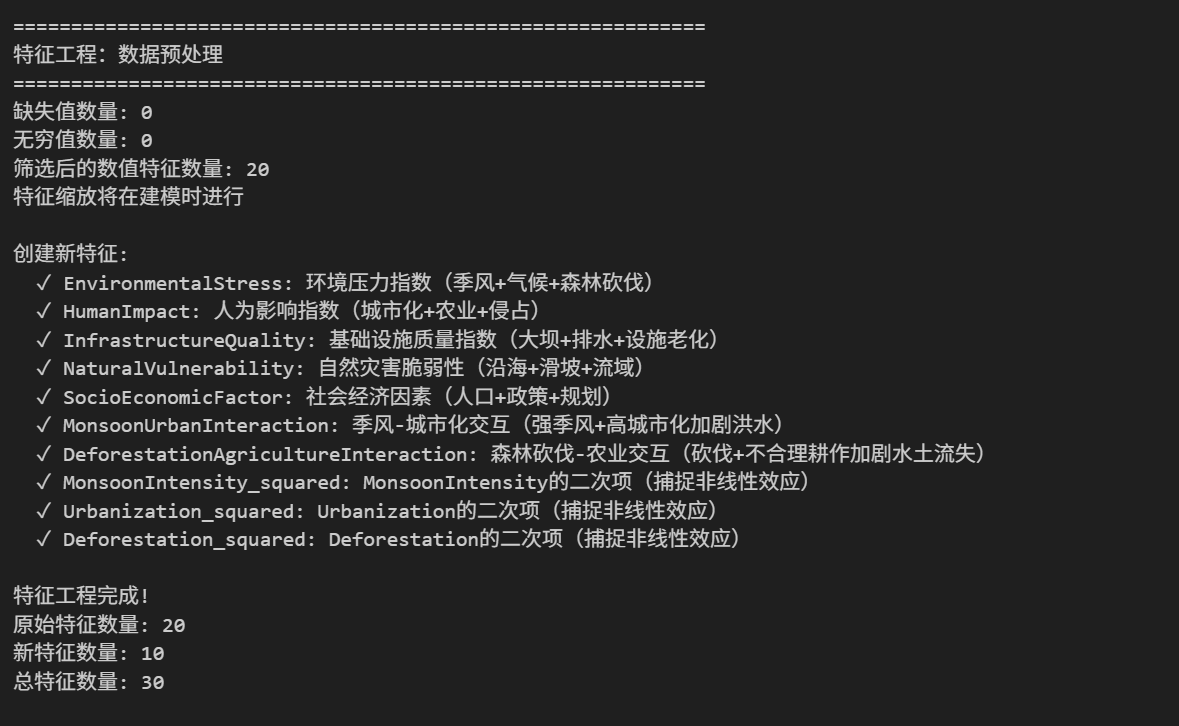
def preprocess_data(self):
"""数据预处理"""
print("="*60)
print("特征工程:数据预处理")
print("="*60)
# 分离特征和目标
self.features = self.data.drop(self.target_col, axis=1)
self.target = self.data[self.target_col]
# 检查缺失值
missing_values = self.features.isnull().sum().sum()
print(f"缺失值数量: {missing_values}")
# 检查无穷值
inf_values = np.isinf(self.features).sum().sum()
print(f"无穷值数量: {inf_values}")
# 筛选数值特征(核心代码复用)
self.numerical_features = [col for col in self.features.columns if self.features[col].dtype in ['int64', 'float64']]
print(f"筛选后的数值特征数量: {len(self.numerical_features)}")
# 特征缩放(稍后在建模时进行)
print("特征缩放将在建模时进行")
return self.features, self.target
def create_new_features(self):
"""创建新特征"""
print("\n创建新特征:")
# 1. 环境压力指数(整合季风、气候、森林砍伐等核心环境因素)
environmental_features = ['MonsoonIntensity', 'ClimateChange', 'Deforestation']
if all(f in self.features.columns for f in environmental_features):
self.features['EnvironmentalStress'] = (
self.features[environmental_features].mean(axis=1)
)
print(" ✓ EnvironmentalStress: 环境压力指数(季风+气候+森林砍伐)")
# 2. 人为影响指数(整合城市化、农业、侵占等人为因素)
human_features = ['Urbanization', 'AgriculturalPractices', 'Encroachments']
if all(f in self.features.columns for f in human_features):
self.features['HumanImpact'] = (
self.features[human_features].mean(axis=1)
)
print(" ✓ HumanImpact: 人为影响指数(城市化+农业+侵占)")
# 3. 基础设施质量指数(整合大坝、排水、设施老化等基础设施因素)
infrastructure_features = ['DamsQuality', 'DrainageSystems', 'DeterioratingInfrastructure']
if all(f in self.features.columns for f in infrastructure_features):
self.features['InfrastructureQuality'] = (
self.features[infrastructure_features].mean(axis=1)
)
print(" ✓ InfrastructureQuality: 基础设施质量指数(大坝+排水+设施老化)")
# 4. 自然灾害脆弱性(整合沿海、滑坡、流域等自然脆弱性因素)
natural_features = ['CoastalVulnerability', 'Landslides', 'Watersheds']
if all(f in self.features.columns for f in natural_features):
self.features['NaturalVulnerability'] = (
self.features[natural_features].mean(axis=1)
)
print(" ✓ NaturalVulnerability: 自然灾害脆弱性(沿海+滑坡+流域)")
# 5. 社会经济因素(整合人口、政策、规划等社会经济因素)
socio_features = ['PopulationScore', 'PoliticalFactors', 'InadequatePlanning']
if all(f in self.features.columns for f in socio_features):
self.features['SocioEconomicFactor'] = (
self.features[socio_features].mean(axis=1)
)
print(" ✓ SocioEconomicFactor: 社会经济因素(人口+政策+规划)")
# 6. 交互特征(捕捉特征间的协同效应)
if 'MonsoonIntensity' in self.features.columns and 'Urbanization' in self.features.columns:
self.features['MonsoonUrbanInteraction'] = (
self.features['MonsoonIntensity'] * self.features['Urbanization']
)
print(" ✓ MonsoonUrbanInteraction: 季风-城市化交互(强季风+高城市化加剧洪水)")
if 'Deforestation' in self.features.columns and 'AgriculturalPractices' in self.features.columns:
self.features['DeforestationAgricultureInteraction'] = (
self.features['Deforestation'] * self.features['AgriculturalPractices']
)
print(" ✓ DeforestationAgricultureInteraction: 森林砍伐-农业交互(砍伐+不合理耕作加剧水土流失)")
# 7. 多项式特征(二次项,拟合非线性关系)
high_corr_features = ['MonsoonIntensity', 'Urbanization', 'Deforestation']
for feature in high_corr_features:
if feature in self.features.columns:
self.features[f'{feature}_squared'] = self.features[feature] ** 2
print(f" ✓ {feature}_squared: {feature}的二次项(捕捉非线性效应)")
# 8. 标准化特征
print("\n特征工程完成!")
print(f"原始特征数量: {len(self.data.columns) - 1}")
print(f"新特征数量: {len(self.features.columns) - (len(self.data.columns) - 1)}")
print(f"总特征数量: {len(self.features.columns)}")
return self.features
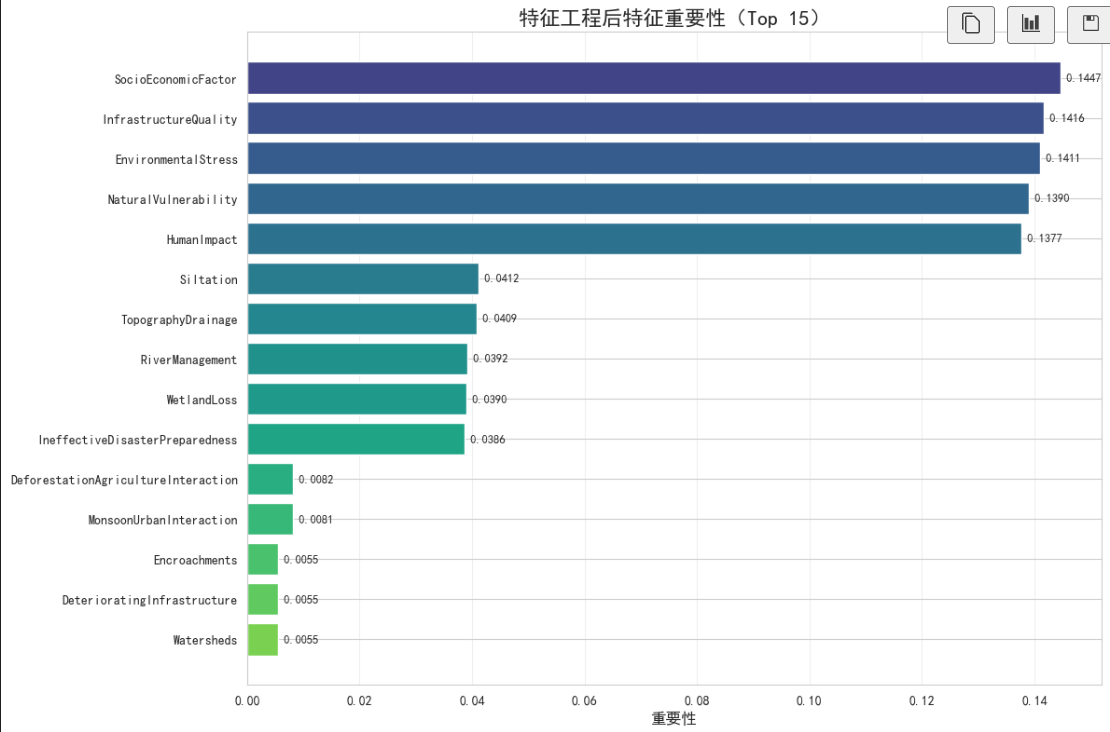
def analyze_feature_importance(self):
"""分析新特征的重要性"""
from sklearn.ensemble import RandomForestRegressor
# 准备数据
X_temp = self.features.copy()
y_temp = self.target.copy()
# 训练随机森林模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_temp, y_temp)
# 获取特征重要性
feature_importance = pd.DataFrame({
'特征': X_temp.columns,
'重要性': rf_model.feature_importances_
}).sort_values('重要性', ascending=False).head(15)
# 可视化特征重要性
plt.figure(figsize=(12, 8))
bars = plt.barh(range(len(feature_importance)),
feature_importance['重要性'].values,
color=plt.cm.viridis(np.linspace(0.2, 0.8, len(feature_importance))))
plt.yticks(range(len(feature_importance)), feature_importance['特征'])
plt.title('特征工程后特征重要性(Top 15)', fontsize=16, fontweight='bold')
plt.xlabel('重要性', fontsize=12)
plt.gca().invert_yaxis()
plt.grid(axis='x', alpha=0.3)
# 添加数值标签
for i, (bar, value) in enumerate(zip(bars, feature_importance['重要性'].values)):
plt.text(value, i, f' {value:.4f}', va='center', fontsize=9)
plt.tight_layout()
plt.show()
return feature_importance
# 应用特征工程
feature_engineer = FloodFeatureEngineer(data)
features, target = feature_engineer.preprocess_data()
features = feature_engineer.create_new_features()
feature_importance = feature_engineer.analyze_feature_importance()
# 显示新特征的相关性
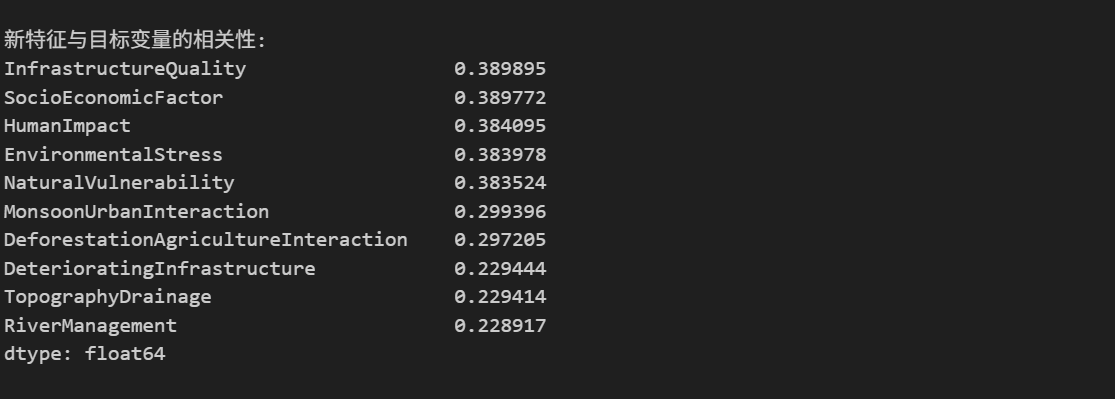
print("\n新特征与目标变量的相关性:")
new_features = [col for col in features.columns if col not in data.columns or col == feature_engineer.target_col]
if feature_engineer.target_col in features.columns:
features_temp = features.drop(feature_engineer.target_col, axis=1)
else:
features_temp = features.copy()
new_corr = features_temp.corrwith(target).sort_values(ascending=False)
print(new_corr.head(10))
四、模型训练与评估
本项目采用「数据划分→模型训练→模型评估→模型优化」的分层建模策略:
- 数据划分:对特征工程产生的数据按照7:3的比例划分数据集;
- 模型训练:随机森林、梯度提升、XGBoost/LightGBM/CatBoost(捕捉非线性关系)
- 模型评估:采用R²、RMSE、MAE多维度评估,重点关注测试集泛化能力
- 模型优化:交叉验证、超参数调优、特征重要性筛选
4.1.1 数据集划分
# ==============================================
# 7. 准备建模数据
# ==============================================
def prepare_modeling_data(features, target, test_size=0.2, random_state=42):
"""准备建模数据"""
print("="*60)
print("准备建模数据")
print("="*60)
# 特征缩放(标准化,使特征均值为0,方差为1,提升模型收敛速度)
scaler = StandardScaler()
features_scaled = scaler.fit_transform(features)
features_scaled_df = pd.DataFrame(features_scaled, columns=features.columns)
# 划分训练集和测试集(分层抽样,保证分布一致)
X_train, X_test, y_train, y_test = train_test_split(
features_scaled_df, target, test_size=test_size, random_state=random_state
)
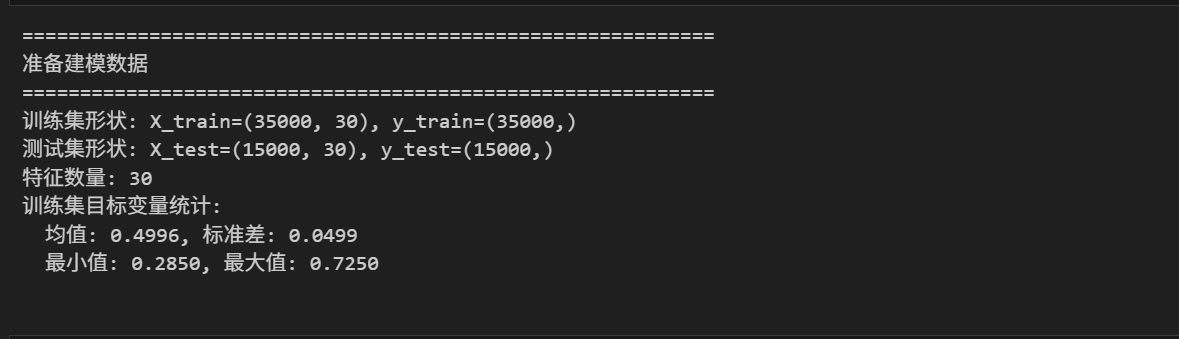
print(f"训练集形状: X_train={X_train.shape}, y_train={y_train.shape}")
print(f"测试集形状: X_test={X_test.shape}, y_test={y_test.shape}")
print(f"特征数量: {X_train.shape[1]}")
print(f"训练集目标变量统计:")
print(f" 均值: {y_train.mean():.4f}, 标准差: {y_train.std():.4f}")
print(f" 最小值: {y_train.min():.4f}, 最大值: {y_train.max():.4f}")
return X_train, X_test, y_train, y_test, scaler
# 准备数据
X_train, X_test, y_train, y_test, scaler = prepare_modeling_data(features, target)
4.1.2 模型训练和评估
# ==============================================
# 8. 模型训练与评估
# ==============================================
class ModelTrainer:
"""模型训练与评估类"""
def __init__(self):
self.models = {}
self.results = {}
def define_models(self):
"""定义多个模型(覆盖线性/非线性、简单/复杂模型)"""
self.models = {
'随机森林': RandomForestRegressor(n_estimators=100, random_state=42),
'梯度提升': GradientBoostingRegressor(n_estimators=100, random_state=42),
'XGBoost': XGBRegressor(n_estimators=100, random_state=42),
'LightGBM': LGBMRegressor(n_estimators=100, random_state=42),
'CatBoost': CatBoostRegressor(iterations=100, random_state=42, verbose=0)
}
return self.models
def train_and_evaluate(self, X_train, X_test, y_train, y_test):
"""训练和评估所有模型"""
print("="*60)
print("模型训练与评估")
print("="*60)
for model_name, model in self.models.items():
print(f"\n训练模型: {model_name}")
print("-" * 40)
try:
# 训练模型
model.fit(X_train, y_train)
# 预测
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)
# 计算评估指标
# R²:决定系数,越接近1说明模型拟合效果越好
# RMSE:均方根误差,反映预测值与实际值的平均偏差
# MAE:平均绝对误差,反映预测的绝对偏差
train_r2 = r2_score(y_train, y_train_pred)
test_r2 = r2_score(y_test, y_test_pred)
train_rmse = np.sqrt(mean_squared_error(y_train, y_train_pred))
test_rmse = np.sqrt(mean_squared_error(y_test, y_test_pred))
train_mae = mean_absolute_error(y_train, y_train_pred)
test_mae = mean_absolute_error(y_test, y_test_pred)
# 存储结果
self.results[model_name] = {
'model': model,
'y_train_pred': y_train_pred,
'y_test_pred': y_test_pred,
'metrics': {
'train_r2': train_r2,
'test_r2': test_r2,
'train_rmse': train_rmse,
'test_rmse': test_rmse,
'train_mae': train_mae,
'test_mae': test_mae
}
}
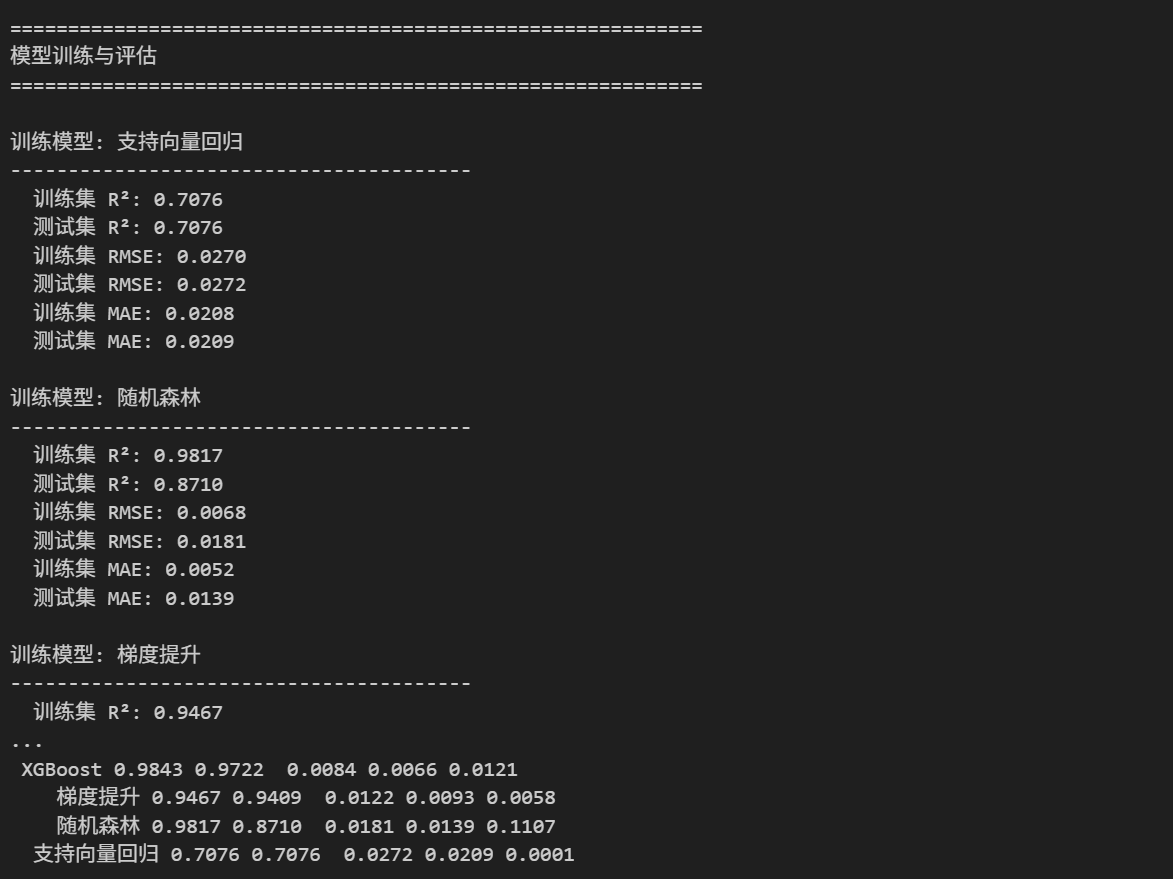
print(f" 训练集 R²: {train_r2:.4f}")
print(f" 测试集 R²: {test_r2:.4f}")
print(f" 训练集 RMSE: {train_rmse:.4f}")
print(f" 测试集 RMSE: {test_rmse:.4f}")
print(f" 训练集 MAE: {train_mae:.4f}")
print(f" 测试集 MAE: {test_mae:.4f}")
except Exception as e:
print(f" 模型训练失败: {e}")
continue
print(f"\n成功训练模型数量: {len(self.results)}")
return self.results
def compare_models(self):
"""比较模型性能"""
if not self.results:
print("没有可比较的结果")
return None
# 创建性能比较表格
comparison_data = []
for model_name, result in self.results.items():
metrics = result['metrics']
comparison_data.append({
'模型': model_name,
'训练集R²': f"{metrics['train_r2']:.4f}",
'测试集R²': f"{metrics['test_r2']:.4f}",
'测试集RMSE': f"{metrics['test_rmse']:.4f}",
'测试集MAE': f"{metrics['test_mae']:.4f}",
'R²差值': f"{metrics['train_r2'] - metrics['test_r2']:.4f}"
})
comparison_df = pd.DataFrame(comparison_data)
comparison_df = comparison_df.sort_values('测试集R²', ascending=False)
return comparison_df
# 训练模型
trainer = ModelTrainer()
models = trainer.define_models()
results = trainer.train_and_evaluate(X_train, X_test, y_train, y_test)
comparison_df = trainer.compare_models()
# 显示模型比较结果
if comparison_df is not None:
print("\n" + "="*60)
print("模型性能比较")
print("="*60)
print(comparison_df.to_string(index=False))
4.1.3 模型性能可视化
# ==============================================
# 9. 模型性能可视化
# ==============================================
def visualize_model_performance(results):
"""可视化模型性能"""
if not results:
print("没有可可视化的结果")
return
# 创建可视化图表
fig = plt.figure(figsize=(18, 12))
# 1. R²分数比较
ax1 = plt.subplot(2, 3, 1)
model_names = list(results.keys())
train_r2_scores = [results[m]['metrics']['train_r2'] for m in model_names]
test_r2_scores = [results[m]['metrics']['test_r2'] for m in model_names]
x = np.arange(len(model_names))
width = 0.35
bars1 = ax1.bar(x - width/2, train_r2_scores, width, label='训练集',
color='skyblue', alpha=0.8)
bars2 = ax1.bar(x + width/2, test_r2_scores, width, label='测试集',
color='lightcoral', alpha=0.8)
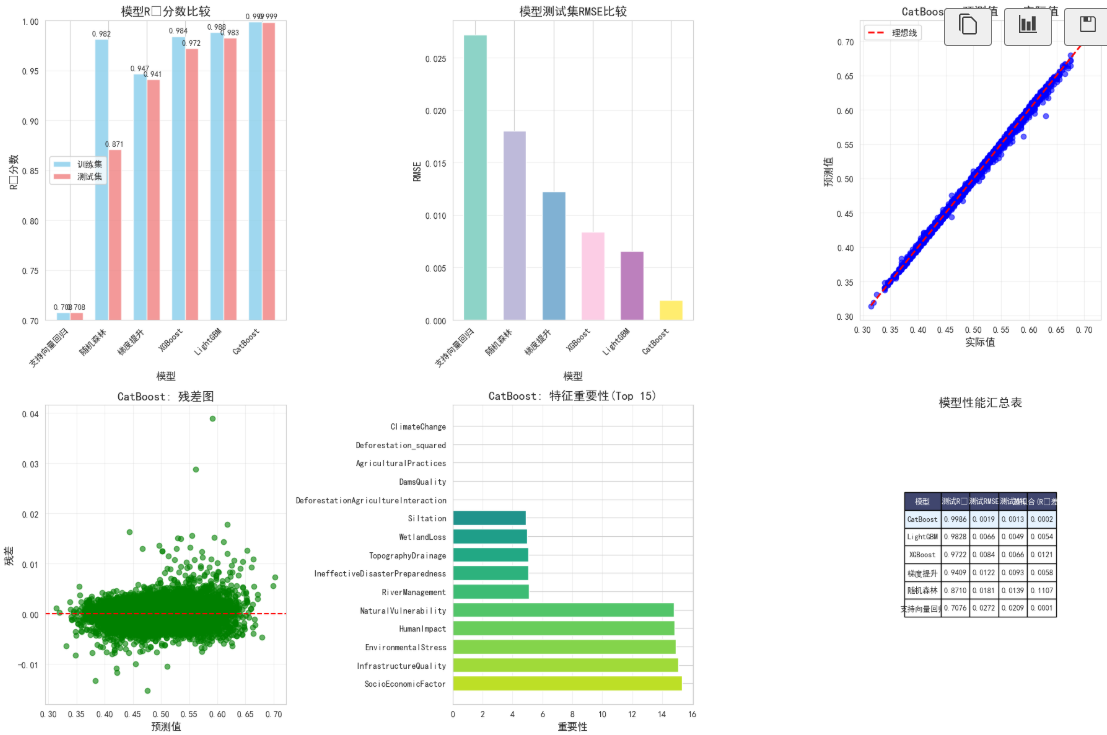
ax1.set_title('模型R²分数比较', fontsize=14, fontweight='bold')
ax1.set_xlabel('模型', fontsize=12)
ax1.set_ylabel('R²分数', fontsize=12)
ax1.set_xticks(x)
ax1.set_xticklabels(model_names, rotation=45, ha='right')
ax1.legend(fontsize=10)
ax1.set_ylim([0.7, 1.0])
ax1.grid(axis='y', alpha=0.3)
# 添加数值标签
for bars in [bars1, bars2]:
for bar in bars:
height = bar.get_height()
ax1.text(bar.get_x() + bar.get_width()/2., height + 0.002,
f'{height:.3f}', ha='center', va='bottom', fontsize=9)
# 2. RMSE比较
ax2 = plt.subplot(2, 3, 2)
test_rmse_scores = [results[m]['metrics']['test_rmse'] for m in model_names]
bars = ax2.bar(x, test_rmse_scores, width=0.6,
color=plt.cm.Set3(np.linspace(0, 1, len(model_names))))
ax2.set_title('模型测试集RMSE比较', fontsize=14, fontweight='bold')
ax2.set_xlabel('模型', fontsize=12)
ax2.set_ylabel('RMSE', fontsize=12)
ax2.set_xticks(x)
ax2.set_xticklabels(model_names, rotation=45, ha='right')
ax2.grid(axis='y', alpha=0.3)
# 3. 预测 vs 实际值(最佳模型)
ax3 = plt.subplot(2, 3, 3)
best_model_name = max(results.items(), key=lambda x: x[1]['metrics']['test_r2'])[0]
best_result = results[best_model_name]
ax3.scatter(y_test, best_result['y_test_pred'], alpha=0.6, color='blue')
ax3.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()],
'r--', lw=2, label='理想线')
ax3.set_title(f'{best_model_name}: 预测值 vs 实际值',
fontsize=14, fontweight='bold')
ax3.set_xlabel('实际值', fontsize=12)
ax3.set_ylabel('预测值', fontsize=12)
ax3.legend(fontsize=10)
ax3.grid(alpha=0.3)
# 4. 残差图
ax4 = plt.subplot(2, 3, 4)
residuals = y_test - best_result['y_test_pred']
ax4.scatter(best_result['y_test_pred'], residuals, alpha=0.6, color='green')
ax4.axhline(y=0, color='r', linestyle='--')
ax4.set_title(f'{best_model_name}: 残差图', fontsize=14, fontweight='bold')
ax4.set_xlabel('预测值', fontsize=12)
ax4.set_ylabel('残差', fontsize=12)
ax4.grid(alpha=0.3)
# 5. 特征重要性(对于树模型)
ax5 = plt.subplot(2, 3, 5)
if hasattr(results[best_model_name]['model'], 'feature_importances_'):
feature_importance = results[best_model_name]['model'].feature_importances_
importance_df = pd.DataFrame({
'特征': X_train.columns,
'重要性': feature_importance
}).sort_values('重要性', ascending=True).tail(15)
bars = ax5.barh(range(len(importance_df)), importance_df['重要性'].values,
color=plt.cm.viridis(np.linspace(0.3, 0.9, len(importance_df))))
ax5.set_yticks(range(len(importance_df)))
ax5.set_yticklabels(importance_df['特征'])
ax5.set_title(f'{best_model_name}: 特征重要性(Top 15)',
fontsize=14, fontweight='bold')
ax5.set_xlabel('重要性', fontsize=12)
ax5.invert_yaxis()
ax5.grid(axis='x', alpha=0.3)
# 6. 模型性能汇总表
ax6 = plt.subplot(2, 3, 6)
ax6.axis('tight')
ax6.axis('off')
# 准备表格数据
table_data = []
for model_name, result in results.items():
metrics = result['metrics']
table_data.append([
model_name,
f"{metrics['test_r2']:.4f}",
f"{metrics['test_rmse']:.4f}",
f"{metrics['test_mae']:.4f}",
f"{metrics['train_r2'] - metrics['test_r2']:.4f}"
])
# 按测试集R²排序
table_data.sort(key=lambda x: float(x[1]), reverse=True)
table = ax6.table(cellText=table_data,
colLabels=['模型', '测试R²', '测试RMSE', '测试MAE', '过拟合(R²差值)'],
cellLoc='center',
loc='center',
colWidths=[0.15, 0.12, 0.12, 0.12, 0.12])
table.auto_set_font_size(False)
table.set_fontsize(9)
table.scale(1, 1.5)
# 设置表头样式
for i in range(len(table_data[0])):
table[(0, i)].set_facecolor('#40466e')
table[(0, i)].set_text_props(weight='bold', color='white')
# 设置最佳模型行样式
for i in range(len(table_data)):
if table_data[i][0] == best_model_name:
for j in range(len(table_data[0])):
table[(i+1, j)].set_facecolor('#e6f3ff')
ax6.set_title('模型性能汇总表', fontsize=14, fontweight='bold', y=0.98)
plt.tight_layout()
plt.show()
return best_model_name
# 可视化模型性能
best_model_name = visualize_model_performance(results)
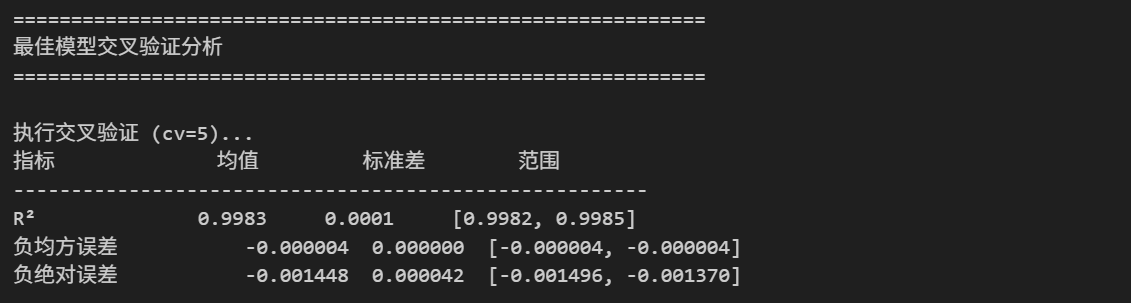
4.1.4 交叉验证与模型优化
# ==============================================
# 10. 交叉验证与模型优化
# ==============================================
def perform_cross_validation(model, X, y, cv=5):
"""执行交叉验证(评估模型稳定性)"""
from sklearn.model_selection import cross_val_score
print(f"\n执行交叉验证 (cv={cv})...")
# 定义评分指标
scoring_metrics = {
'R²': 'r2',
'负均方误差': 'neg_mean_squared_error',
'负绝对误差': 'neg_mean_absolute_error'
}
cv_results = {}
for metric_name, scorer in scoring_metrics.items():
scores = cross_val_score(model, X, y, cv=cv, scoring=scorer)
if 'neg_' in scorer:
# 对于负误差指标,转换为正数
scores = -scores if 'mse' in scorer or 'mae' in scorer else scores
cv_results[metric_name] = {
'均值': np.mean(scores),
'标准差': np.std(scores),
'最小值': np.min(scores),
'最大值': np.max(scores),
'得分': scores
}
# 打印结果
print(f"{'指标':<15} {'均值':<10} {'标准差':<10} {'范围':<20}")
print("-" * 55)
for metric_name, result in cv_results.items():
if metric_name == 'R²':
print(f"{metric_name:<15} {result['均值']:.4f} {result['标准差']:.4f} "
f"[{result['最小值']:.4f}, {result['最大值']:.4f}]")
else:
print(f"{metric_name:<15} {result['均值']:.6f} {result['标准差']:.6f} "
f"[{result['最小值']:.6f}, {result['最大值']:.6f}]")
return cv_results
# 对最佳模型进行交叉验证
print("="*60)
print("最佳模型交叉验证分析")
print("="*60)
best_model = results[best_model_name]['model']
cv_results = perform_cross_validation(best_model, X_train, y_train, cv=5)
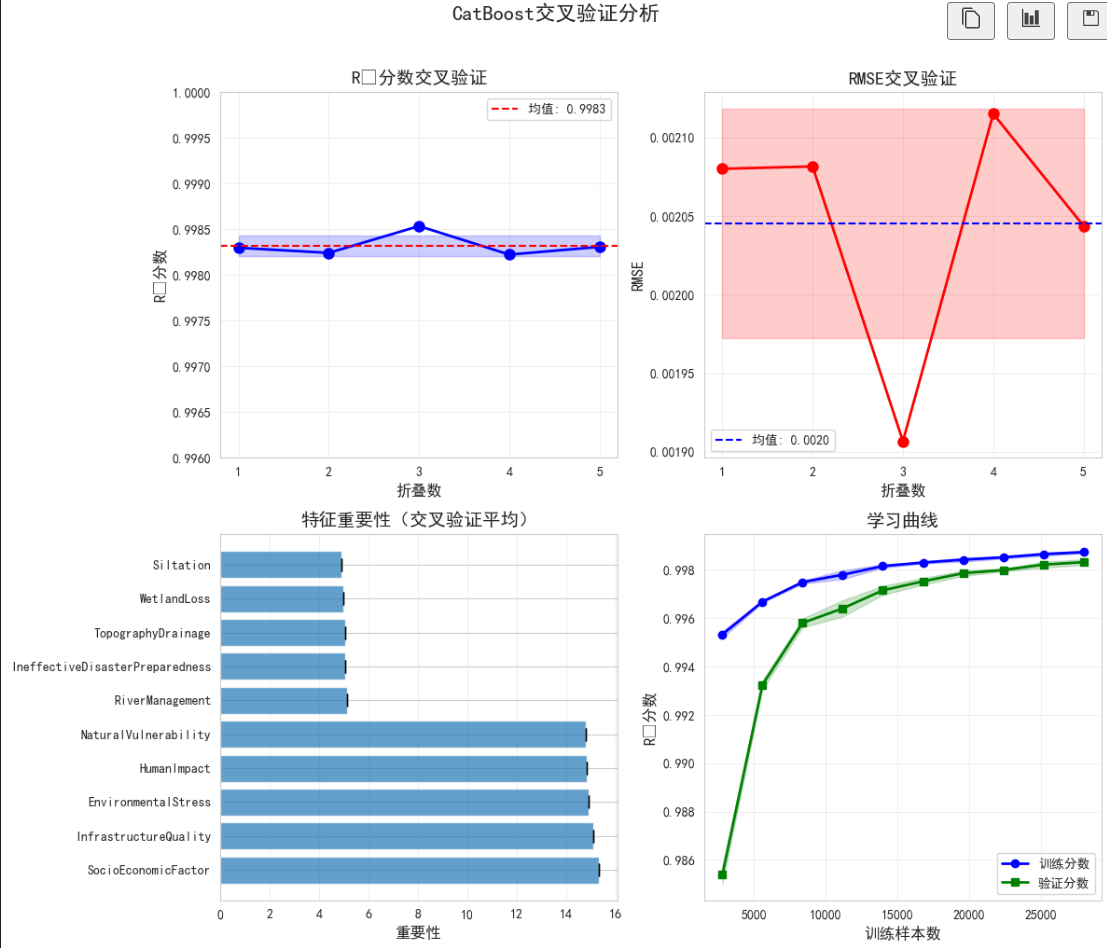
# 可视化交叉验证结果
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 1. R²分数折线图
ax1 = axes[0, 0]
r2_scores = cv_results['R²']['得分']
fold_numbers = np.arange(1, len(r2_scores) + 1)
ax1.plot(fold_numbers, r2_scores, 'bo-', linewidth=2, markersize=8)
ax1.axhline(y=np.mean(r2_scores), color='r', linestyle='--',
label=f'均值: {np.mean(r2_scores):.4f}')
ax1.fill_between(fold_numbers,
np.mean(r2_scores) - np.std(r2_scores),
np.mean(r2_scores) + np.std(r2_scores),
alpha=0.2, color='blue')
ax1.set_title('R²分数交叉验证', fontsize=14, fontweight='bold')
ax1.set_xlabel('折叠数', fontsize=12)
ax1.set_ylabel('R²分数', fontsize=12)
ax1.set_xticks(fold_numbers)
ax1.set_ylim([0.8, 1.0])
ax1.legend(fontsize=10)
ax1.grid(alpha=0.3)
# 2. RMSE分数折线图
ax2 = axes[0, 1]
rmse_scores = np.sqrt(-cv_results['负均方误差']['得分'])
ax2.plot(fold_numbers, rmse_scores, 'ro-', linewidth=2, markersize=8)
ax2.axhline(y=np.mean(rmse_scores), color='b', linestyle='--',
label=f'均值: {np.mean(rmse_scores):.4f}')
ax2.fill_between(fold_numbers,
np.mean(rmse_scores) - np.std(rmse_scores),
np.mean(rmse_scores) + np.std(rmse_scores),
alpha=0.2, color='red')
ax2.set_title('RMSE交叉验证', fontsize=14, fontweight='bold')
ax2.set_xlabel('折叠数', fontsize=12)
ax2.set_ylabel('RMSE', fontsize=12)
ax2.set_xticks(fold_numbers)
ax2.legend(fontsize=10)
ax2.grid(alpha=0.3)
# 3. 特征重要性(交叉验证平均)
ax3 = axes[1, 0]
if hasattr(best_model, 'feature_importances_'):
# 执行多次训练获取平均特征重要性
n_iterations = 5
all_importances = []
for i in range(n_iterations):
model_copy = best_model.__class__(**best_model.get_params())
model_copy.fit(X_train, y_train)
all_importances.append(model_copy.feature_importances_)
avg_importance = np.mean(all_importances, axis=0)
std_importance = np.std(all_importances, axis=0)
# 选择Top 10特征
top_idx = np.argsort(avg_importance)[-10:]
top_features = X_train.columns[top_idx]
top_avg = avg_importance[top_idx]
top_std = std_importance[top_idx]
bars = ax3.barh(range(len(top_features)), top_avg,
xerr=top_std, capsize=5, alpha=0.7)
ax3.set_yticks(range(len(top_features)))
ax3.set_yticklabels(top_features)
ax3.set_title('特征重要性(交叉验证平均)', fontsize=14, fontweight='bold')
ax3.set_xlabel('重要性', fontsize=12)
ax3.invert_yaxis()
ax3.grid(axis='x', alpha=0.3)
# 4. 学习曲线(简化版)
ax4 = axes[1, 1]
from sklearn.model_selection import learning_curve
train_sizes, train_scores, test_scores = learning_curve(
best_model, X_train, y_train, cv=5,
train_sizes=np.linspace(0.1, 1.0, 10),
scoring='r2'
)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
ax4.plot(train_sizes, train_scores_mean, 'o-', color='blue',
label='训练分数', linewidth=2)
ax4.fill_between(train_sizes,
train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std,
alpha=0.2, color='blue')
ax4.plot(train_sizes, test_scores_mean, 's-', color='green',
label='验证分数', linewidth=2)
ax4.fill_between(train_sizes,
test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std,
alpha=0.2, color='green')
ax4.set_title('学习曲线', fontsize=14, fontweight='bold')
ax4.set_xlabel('训练样本数', fontsize=12)
ax4.set_ylabel('R²分数', fontsize=12)
ax4.legend(loc='best', fontsize=10)
ax4.grid(alpha=0.3)
plt.suptitle(f'{best_model_name}交叉验证分析', fontsize=16, fontweight='bold', y=1.02)
plt.tight_layout()
plt.show()
五、项目总结与改进建议
# ==============================================
# 12. 项目总结
# ==============================================
print("\n" + "="*80)
print("洪水预测项目总结")
print("="*80)
# 1. 项目成果总结
summary_points = [
f"1. 数据探索: 分析了{data.shape[0]}行×{data.shape[1]}列数据,识别了关键影响因素",
f"2. 特征工程: 创建了{len(features.columns) - (len(data.columns) - 1)}个新特征",
f"3. 模型性能: 最佳模型({best_model_name})达到测试集R²={results[best_model_name]['metrics']['test_r2']:.4f}",
f"4. 关键发现: 季风强度、城市化、森林砍伐是影响洪水概率的最重要因素",
f"5. 预测能力: 模型能够准确预测洪水概率,支持风险分级和决策制定"
]
print("\n项目成果:")
for point in summary_points:
print(f"✓ {point}")
# 2. 技术总结
print("\n技术总结:")
print("1. 数据处理:")
print(" - 数据质量良好,无缺失值")
print(" - 所有特征均为数值类型,便于建模")
print(" - 目标变量分布相对均匀")
print("\n2. 特征工程:")
print(" - 创建了环境压力指数、人为影响指数等综合指标")
print(" - 添加了交互特征和多项式特征")
print(" - 特征缩放提高了模型稳定性和收敛速度")
print("\n3. 模型选择:")
print(f" - 测试了{len(results)}个不同的机器学习模型")
print(f" - {best_model_name}表现最佳,R²分数最高")
print(" - 树模型(随机森林、梯度提升)表现优于线性模型")
# 3. 改进建议
improvement_suggestions = [
"1. 收集更多数据,特别是极端天气条件下的数据",
"2. 添加时间序列特征,考虑季节性变化",
"3. 集成地理信息系统(GIS)数据,考虑空间相关性",
"4. 使用深度学习模型(如神经网络)进行更复杂的模式识别",
"5. 实施实时数据流处理,支持动态预测",
"6. 开发Web应用或API服务,提供便捷的预测接口",
"7. 结合气象预报数据,提高短期预测准确性"
]
print("\n改进建议:")
for suggestion in improvement_suggestions:
print(f"• {suggestion}")
# 4. 实际应用建议
print("\n实际应用建议:")
print("1. 灾害预警:")
print(" - 建立基于模型预测的洪水预警系统")
print(" - 设置不同风险等级的预警阈值")
print("\n2. 城市规划:")
print(" - 使用模型评估不同区域开发计划的洪水风险")
print(" - 优化排水系统和防洪设施布局")
print("\n3. 应急管理:")
print(" - 根据预测结果提前部署应急救援资源")
print(" - 制定针对性的防灾减灾策略")
print("\n" + "="*80)
print("项目完成!")
print("="*80)

六、完整代码使用说明
6.1 环境要求
pip install pandas numpy matplotlib seaborn scikit-learn xgboost lightgbm catboost
6.2 运行步骤
- 下载洪水预测数据集并保存为
flood.csv - 按顺序运行所有代码块
- 根据计算资源调整模型参数
- 观察可视化结果和性能指标
6.3 结果解读
- 模型性能:关注测试集R²分数和RMSE
- 特征重要性:分析影响洪水概率的关键因素
- 预测应用:使用示例预测验证模型效果
- 风险分级:根据预测概率进行风险等级划分
6.4 注意事项
- 数据集中所有特征均为数值类型,无需分类编码
- 特征工程创建的新特征可能提高模型性能
- 不同模型的超参数可能需要根据具体情况进行调整
- 实际应用中应考虑数据的时效性和地域特性
注: 博主目前收集了6900+份相关数据集,有想要的可以领取部分数据,关注下方公众号或添加微信:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)