英伟达GDPO多奖励强化学习算法在多项任务上超越GRPO
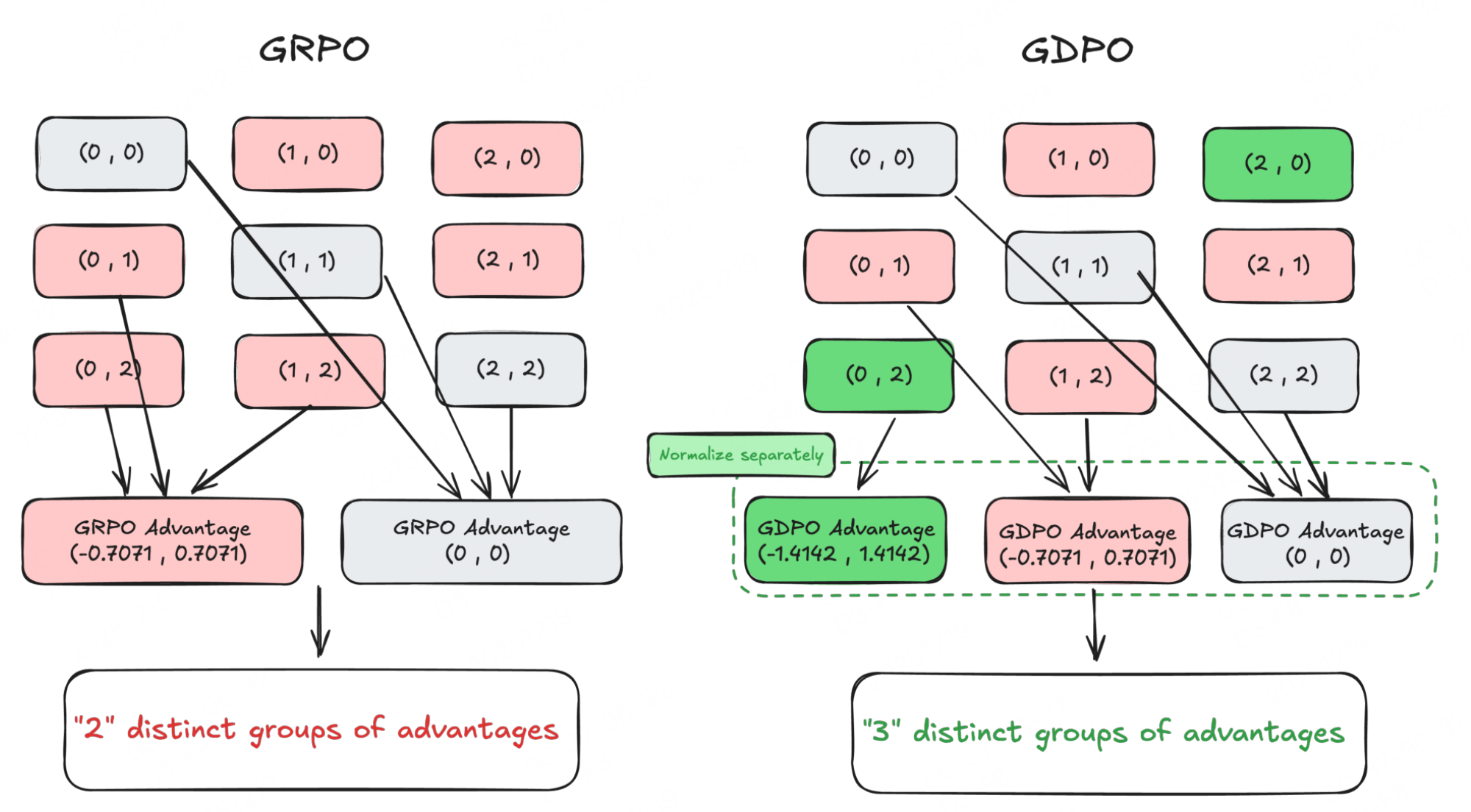
正如上期文章介绍的《》:GRPO的奖励信号坍缩(Reward Collapse)当GRPO应用于多奖励场景时,会导致:如下图左边例子,例如两个二元奖励(0/1)的场景中,GRPO会将(0,1)、(0,2)、(1,2)等不同奖励组合,统一映射为(-0.7071, 0.7071)的优势值,无法区分“满足1个奖励”和“满足2个奖励”的差异。:降低训练信号的分辨率,导致策略更新不准确、收敛次优,甚至早期训
GRPO的RL方法存在缺陷:
- GRPO将多个奖励求和后,通过组内相对优势估计进行策略更新。
- GRPO原本为单奖励优化设计,直接迁移到多奖励场景时未被验证合理性。
正如上期文章介绍的《强化学习中的熵坍缩》:

GRPO的奖励信号坍缩(Reward Collapse)当GRPO应用于多奖励场景时,会导致不同奖励组合映射为相同优势值,丢失关键信息,表现如下:
-
信息丢失:如下图左边例子,例如两个二元奖励(0/1)的场景中,GRPO会将(0,1)、(0,2)、(1,2)等不同奖励组合,统一映射为(-0.7071, 0.7071)的优势值,无法区分“满足1个奖励”和“满足2个奖励”的差异。
-
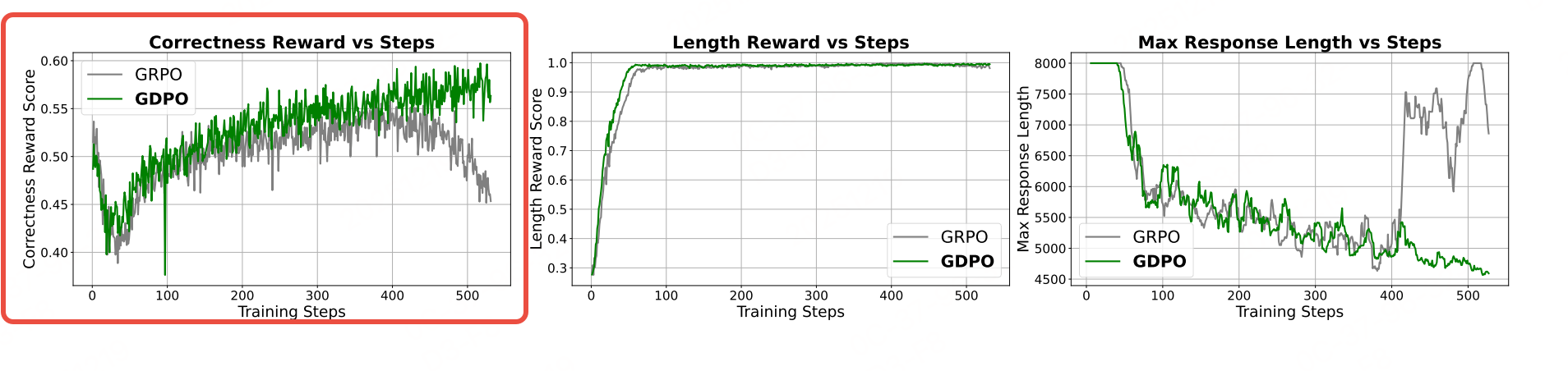
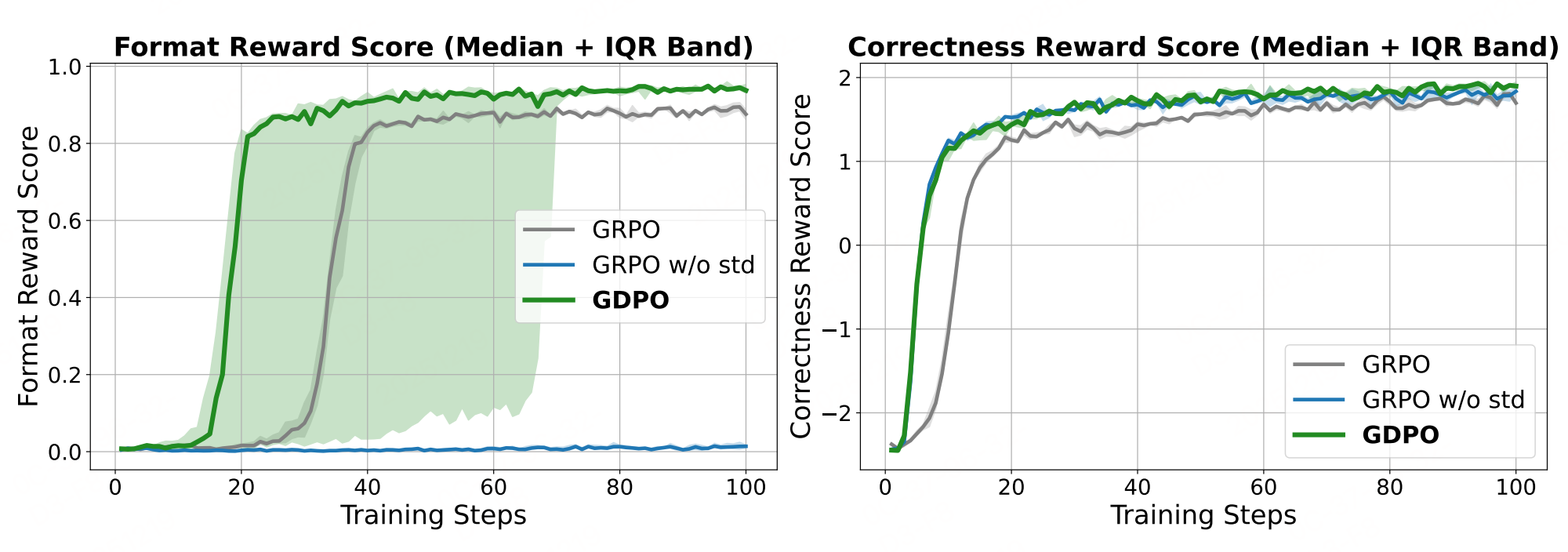
训练缺陷:降低训练信号的分辨率,导致策略更新不准确、收敛次优,甚至早期训练失败(如GRPO在数学推理任务中400步后正确性奖励下降)。
关于GRPO:《DeepSeek采用的GRPO算法数学原理及算法过程浅析》
GDPO
其核心思想是解耦每个奖励的归一化过程:避免先求和再归一化导致的信息坍缩,通过“单独归一化→求和→批次稳定”的流程,保留不同奖励组合的相对差异。
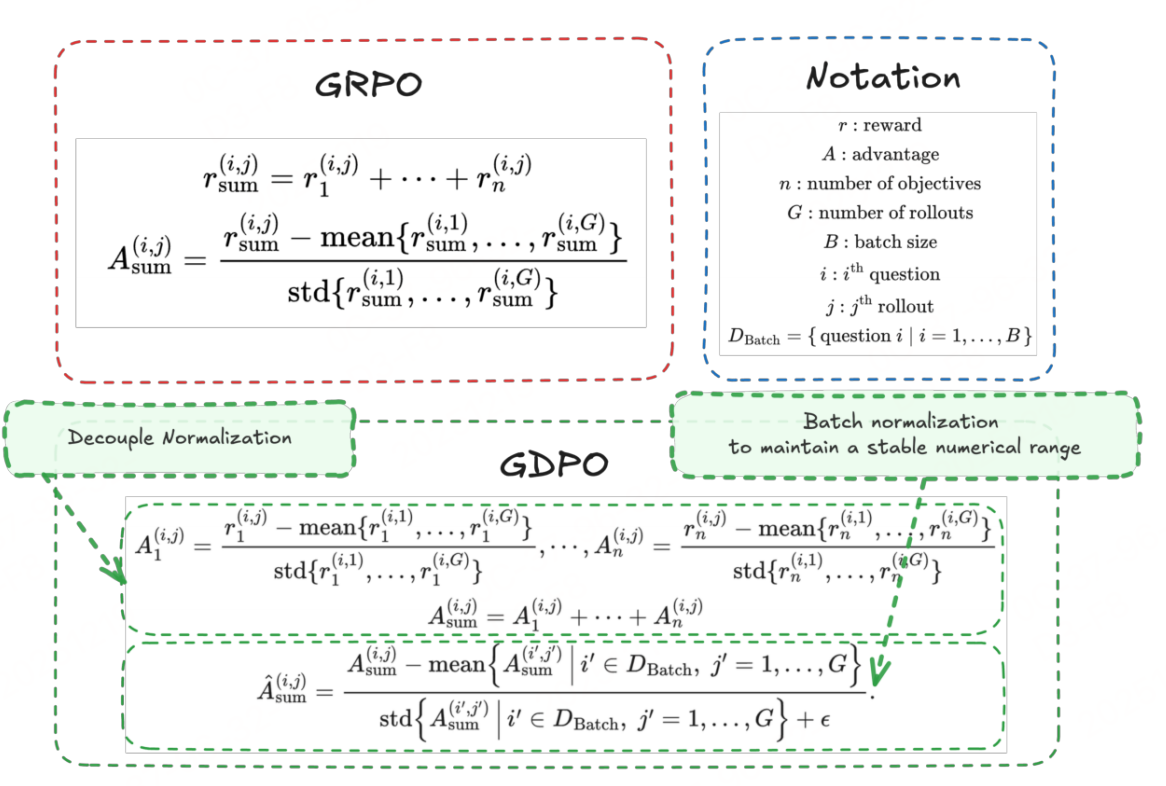
如图图,假设任务有 $ n $ 个奖励目标,每个问题生成 $ G $ 个rollout,GDPO的优势计算分3步:
步骤1-解耦:单奖励组内归一化
对每个奖励 $ r_k ( ( ( k=1…n $)单独进行组内归一化,消除不同奖励的量纲差异,同时保留组内相对优劣:
A n ( i , j ) = r n ( i , j ) − mean { r n ( i , 1 ) , . . . , r n ( i , G ) } std { r n ( i , 1 ) , . . . , r n ( i , G ) } A_n^{(i,j)} = \frac{r_n^{(i,j)} - \text{mean}\{r_n^{(i,1)}, ..., r_n^{(i,G)}\}}{\text{std}\{r_n^{(i,1)}, ..., r_n^{(i,G)}\}} An(i,j)=std{rn(i,1),...,rn(i,G)}rn(i,j)−mean{rn(i,1),...,rn(i,G)}
- $ (i,j) $:第 $ i $ 个问题的第 $ j $ 个rollout;
- 作用:每个奖励的“好坏”独立评估,避免某一奖励主导求和结果。
步骤2:多奖励优势求和
将所有归一化后的单奖励优势相加,得到总优势:
A sum ( i , j ) = A 1 ( i , j ) + ⋯ + A n ( i , j ) A_{\text{sum}}^{(i,j)} = A_1^{(i,j)} + \cdots + A_n^{(i,j)} Asum(i,j)=A1(i,j)+⋯+An(i,j)
- 作用:融合多个目标的优化信号,且每个目标的贡献已通过步骤1归一化。
步骤3-保障稳定性:批次级优势归一化
对批次内所有rollout的总优势进行归一化,确保数值范围稳定,不随奖励数量增加而膨胀:
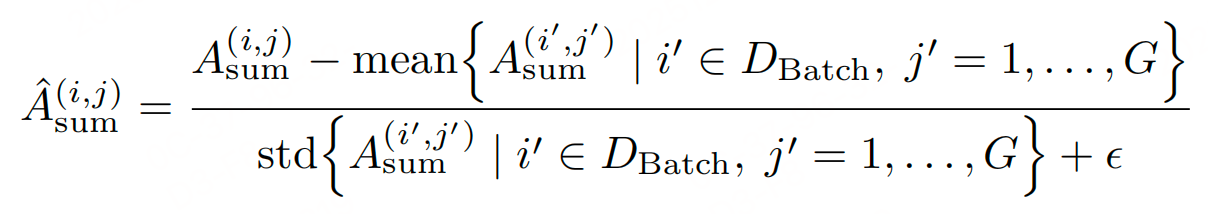
$ \epsilon $:避免分母为0的微小值;
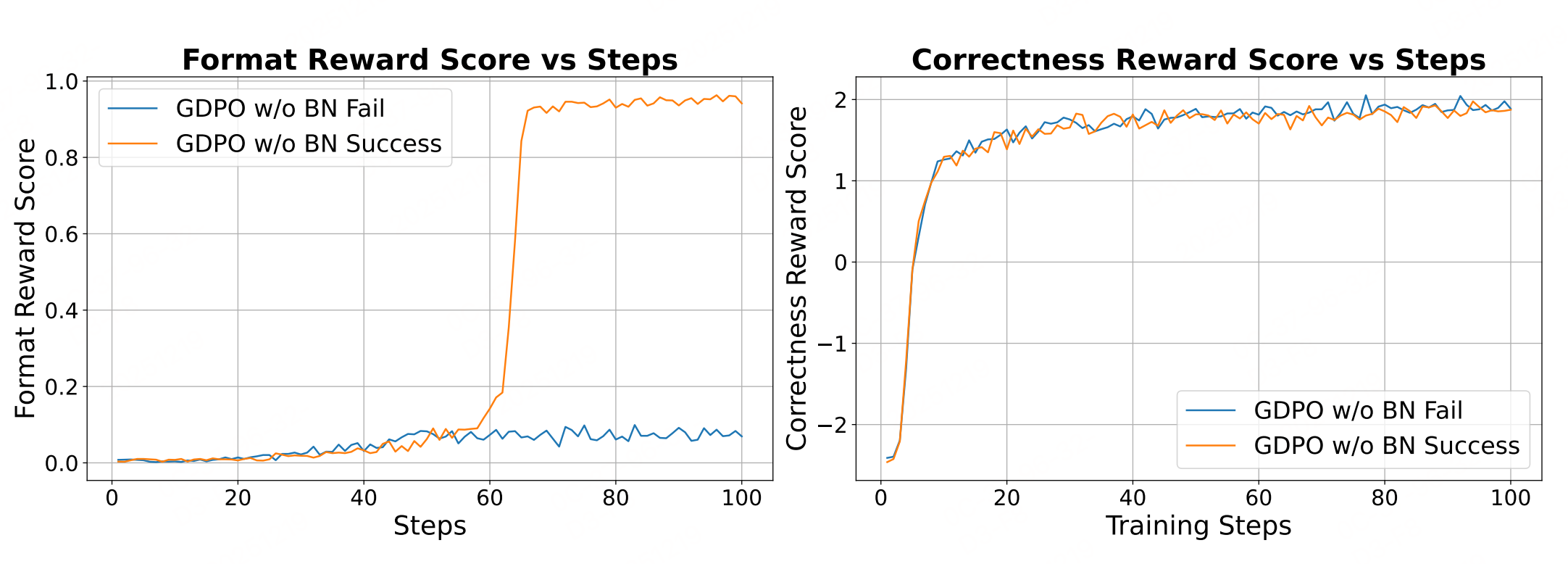
上述实验证明去掉这一步会导致偶尔收敛失败。
GRPO vs GDPO代码上的差异
https://github.com/NVlabs/GDPO/blob/main/trl-GDPO/trl-0.18.0-gdpo/trl/trainer/grpo_trainer.py
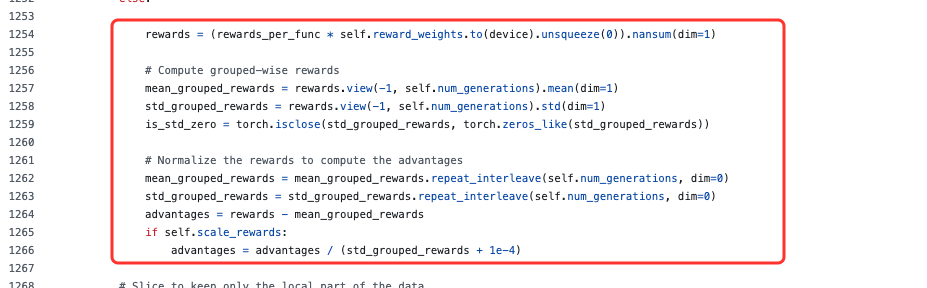
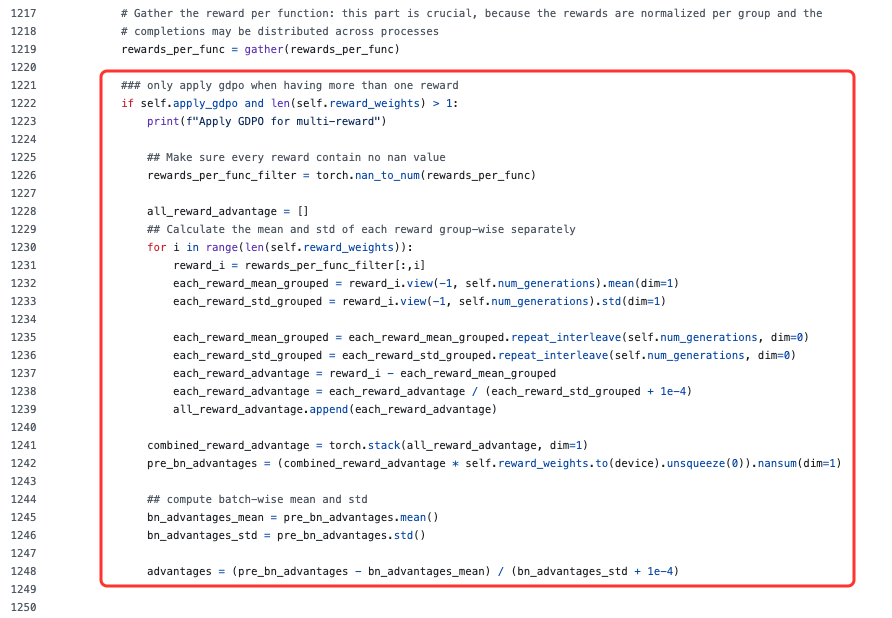
从上述代码可以看出,其差异较小,两者的本质区别在于多奖励的处理顺序:
- GRPO:先将多奖励加权合并为单一总奖励,再对总奖励进行组内一次归一化。
- GDPO:先对每个奖励独立进行组内归一化(解耦核心),再加权求和,最后进行批次级二次归一化(稳定性保障)。
GDPO奖励优先级优化(扩展设计)
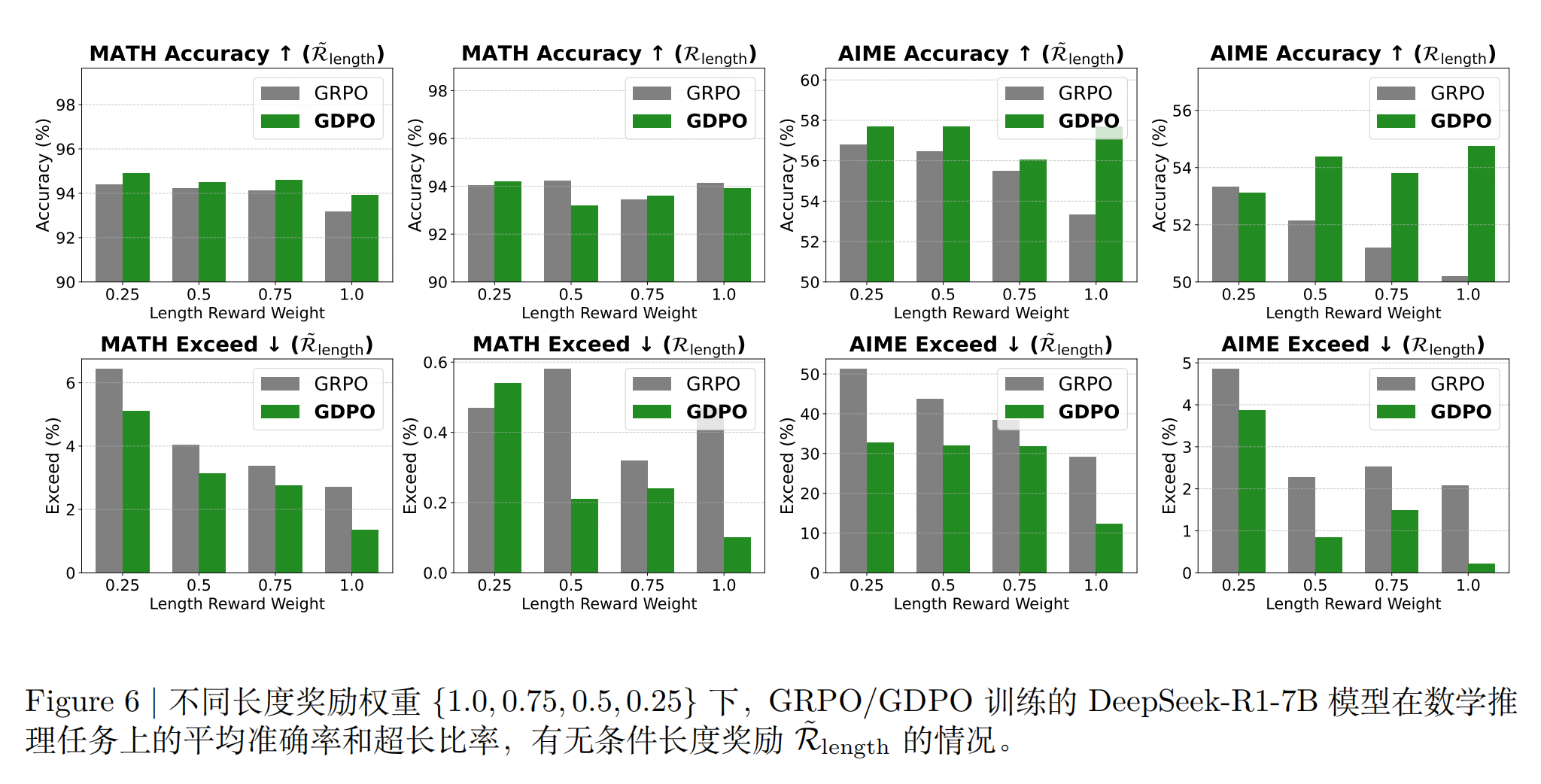
这个挺实用的,针对“不同奖励难度差异大”的场景(如长度约束易优化,准确性难优化),提出两种优先级调整策略:
-
策略1:奖励权重调整:为高优先级奖励分配更大权重 $ w_k $,但需注意:难度差异过大时,需极大权重才能抵消难度偏差,效果有限。
-
策略2:条件奖励设计:让易优化奖励依赖于难优化奖励(如长度奖励仅在准确性达标时生效,强制模型优先满足高优先级(难)目标。):
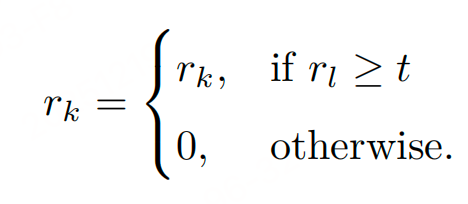
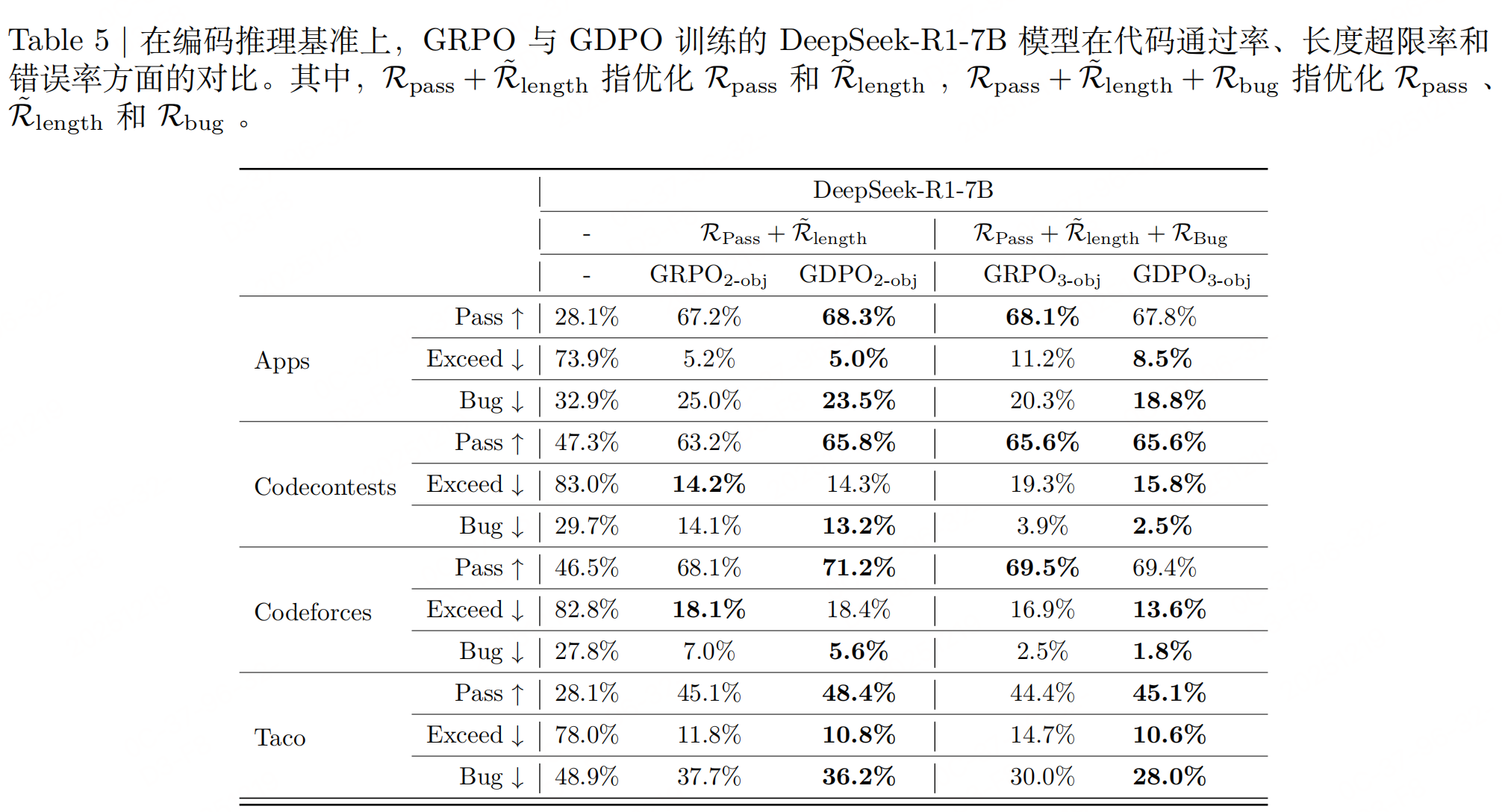
实验
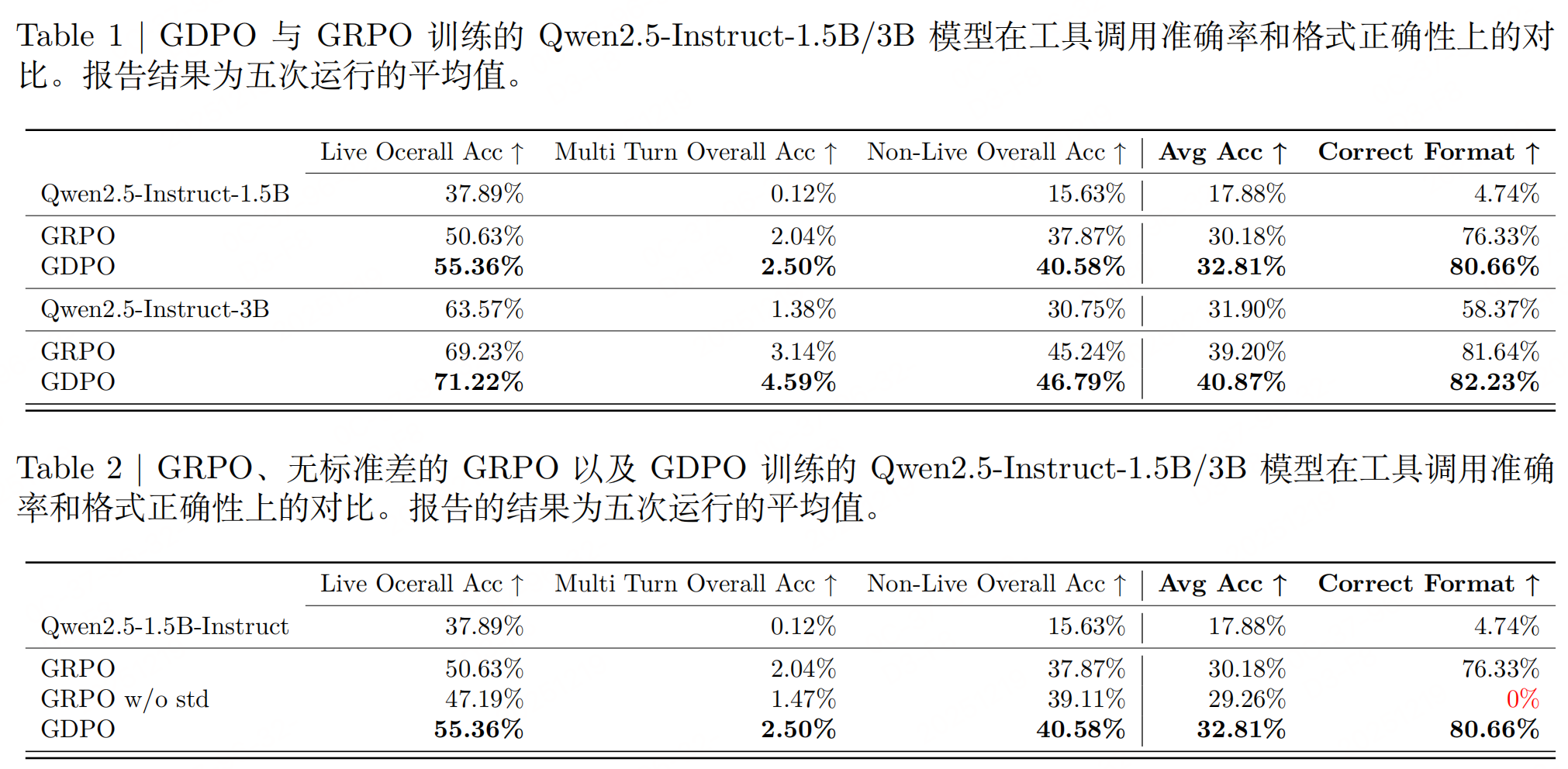
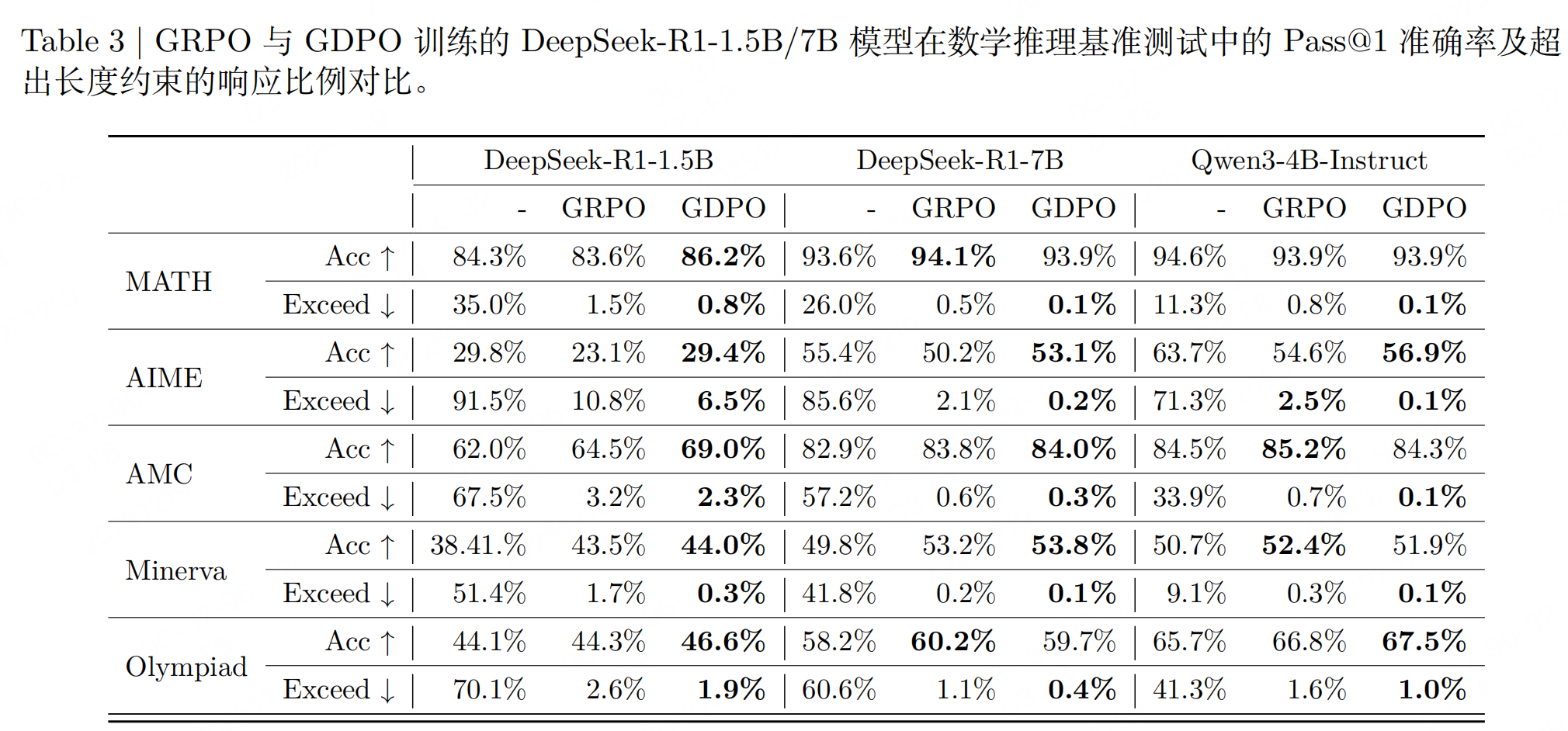
结论:与 GRPO 相比,GDPO 在多奖励强化学习中是一种更稳定、更准确且偏好对齐的最优化方法。
参考文献
- https://github.com/NVlabs/GDPO/tree/main
- GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization,https://arxiv.org/pdf/2601.05242

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 37
37 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)