DataFlow 教程|Text-to-SQL Pipeline 为大模型训练输送高质量 SQL
很多人在第一次听到 Text2SQL 时,都会有一个直觉判断:
模型已经能理解自然语言,也能生成代码,那么把一句话翻译成一段 SQL,应该就只是两种“结构化语言”之间的转换。
然后就会很自然地期待,只要模型足够强、提示词足够好,Text2SQL 的效果就会水到渠成。但在真正落到实践中时,情况往往并不理想:
-
模型可能能写出“看起来正确”的 SQL,却在真实数据库上无法执行;
-
也可能在简单查询上表现不错,一旦涉及多表、聚合或嵌套逻辑,效果就迅速崩塌;
-
更常见的是,在测试集上指标尚可,一接入真实业务数据库,问题就集中暴露出来。
这些问题表面上看是模型能力不足,但如果把视角从模型移开,回到数据本身,会发现一个更核心的事实:
Text2SQL 的难点,从来不是“会不会写 SQL”,而是“有没有被教会在真实数据库上写 SQL”。
而“教会”这件事,本质上是一个数据问题。
现有的 Text2SQL 数据往往存在三个结构性缺陷:
一是 SQL 表达空间有限,模型学到的是少量固定模式;
二是数据缺乏可执行验证,语义是否正确无法保证;
三是问题、SQL 与数据库结构之间的对应关系并不稳定。
如果没有一套系统化的数据构建方式为大模型训练提供高质量的 Text2SQL 数据,那么模型能力越强,这些问题反而越容易被放大。那该如何解决呢?
什么是 Text2SQL Pipeline
Text2SQL Pipeline 是 DataFlow 数据准备系统中一个开箱即用的流水线,它关注的核心问题只有一个:**如何稳定地产出高质量、可验证、可用于模型训练的 Text2SQL 数据。**展开来说,Text2SQL Pipeline 就是用于清洗和扩充现有的 Text2SQL 数据,为每个样本生成包含训练提示词和思维链的高质量问答数据用于模型训练,从而帮助提升模型进行 Text2SQL 的能力和水平。
在使用方式上,Text2SQL Pipeline 支持两种模式。
第一种模式是,已经存在一定规模的 Text2SQL 数据,但质量不稳定、覆盖不足。这时可以通过数据优化模式,对已有的数据进行筛选、扩充和增强 ,让数据真正为模型训练“可用”。
第二种模式是,几乎没有任何现成数据,只有数据库本身。这时就可以通过数据合成模式,直接从数据库出发,合成自然语言问题和对应的 SQL,构建完整的训练样本。
需要强调的是,这两种方式并不对应两套不同逻辑。它们的区别只存在于数据从哪里来,而不是数据如何被处理。
Text2SQL Pipeline 的数据处理流程
了解了 Text2SQL Pipeline 的核心理念之后,我们来详细看看它的数据处理流程,主要分为以下三个阶段:
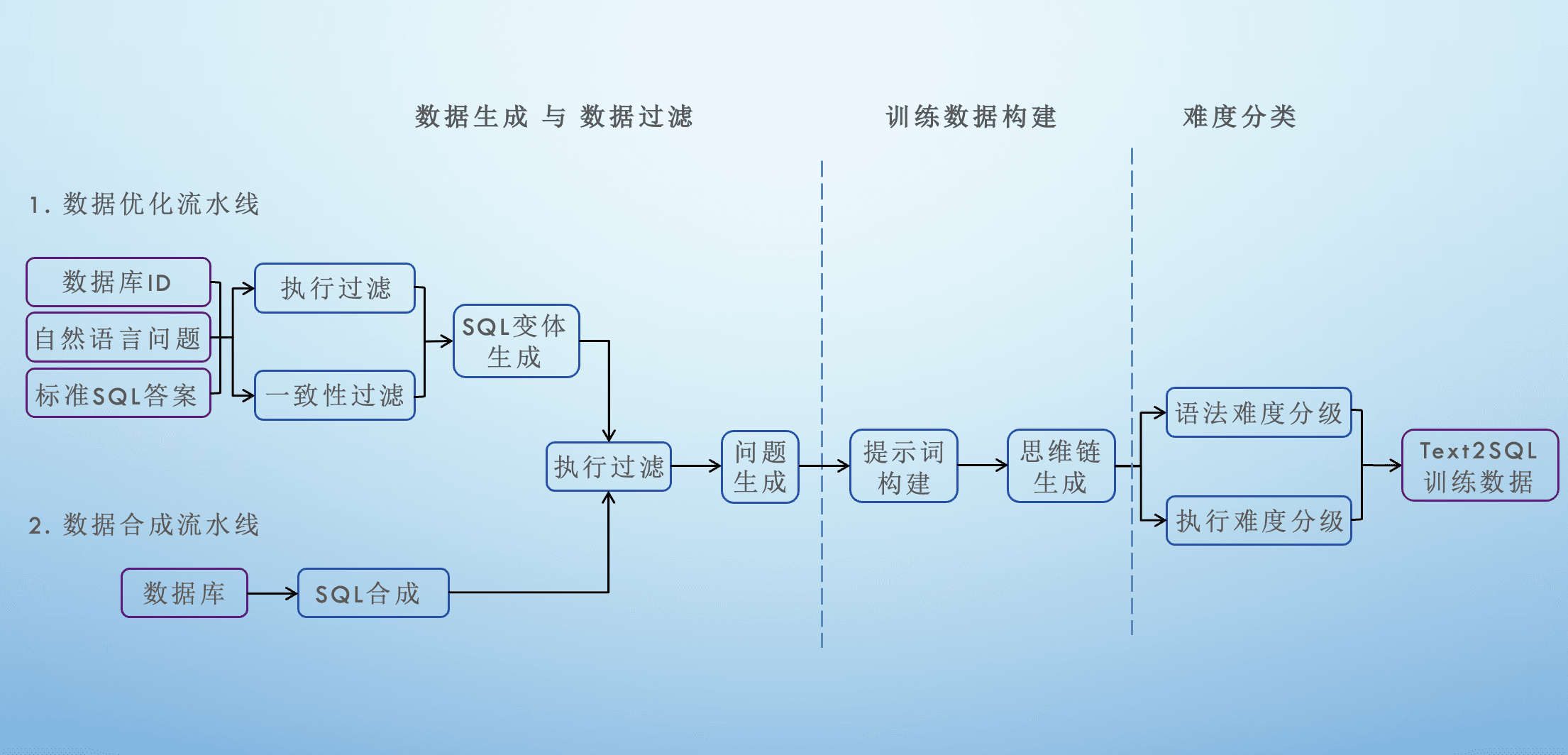
第一阶段:数据生成与过滤
前面提到,Text2SQL Pipeline 支持两种模式的处理方式,它们将分别通过数据优化流水线和数据合成流水线来输出所需的数据。
在数据优化流水线中,Pipeline 的输入需要包含数据库 ID、自然语言问题和标准的 SQL 答案。接下来对这些输入进行两步过滤:首先是执行过滤,检查 SQL 是否是可以在数据库中执行的 SQL;然后是一致性过滤,检查自然语言问题和 SQL 所描述的内容是否一致。之后,就可以通过筛选后的数据进行 SQL 变体的生成,扩增更多数据。
而在数据合成流水线中,Pipeline 的起点只有数据库本身。系统直接基于数据库合成 SQL。这种方式更接近真实使用场景,也常被用于从零构建面向特定数据库的 Text2SQL 数据。
通过两条流水线输出的变体 SQL 和合成 SQL 都会再次被进行执行过滤,以筛选并检查它们是否有效,是否可以在数据库中执行。然后,被检验为有效的 SQL 就会用于生成自然语言问题。
通过这种方式,Pipeline 在流程的最前端就引入了一个强约束:只有数据库认可的 SQL,才可以进入后续步骤。
第二阶段:训练数据构建
在通过执行过滤之后,Pipeline 才开始面向模型训练构建数据。
这一阶段的重点,是将“数据库可以执行的 SQL”,转化为“模型可以学习的训练样本”。Pipeline 会围绕每一条 SQL 构建清晰的提示词,并生成相应的思维链,使模型能够理解从自然语言到 SQL 的完整推导路径。
到这里,数据的角色发生了一次转变:它不再只是查询语句,而是承载了问题理解、结构选择和逻辑组合的信息。
第三阶段:难度分类
最后,对于不同的场景,SQL 的难度也存在一定的变化,因此需要对 SQL 和自然语言问题进行分类。分类的方法从两个维度出发,即语法难度的分级和执行难度的分级。这种划分并不是为了展示,而是为了服务于后续训练和评估。
难度分类之后,结合以上生成的数据类别,就输出了完整的 Text2SQL 训练数据。
回顾整个流程可以看到,Text2SQL Pipeline 的数据处理流程可简化为:生成 → 执行验证 → 构建 → 分级。
下面我们通过实战来看看如何执行这一流程。
Text2SQL Pipeline 实战教程
本章将从工程实践角度,按照 Text2SQL Pipeline 的实际运行顺序,介绍如何完成一次完整的 Pipeline 执行,包括环境准备、参数配置、流水线运行以及结果查看。
所有步骤都围绕一个目标展开:稳定地产出可用于训练的 Text2SQL 数据。
1. 环境准备
这一部分在之前的文章有详细的解释,这里我们就不再赘述了。大家可以直接参考下面的步骤代码完成环境准备。
配置环境
conda create -n dataflow python=3.10
conda activate dataflow
git clone https://github.com/OpenDCAI/DataFlow.git
cd DataFlow
pip install -e .
初始化工作空间
mkdir test
cd test
dataflow init
初始化后将生成两个流水线文件:
-
api_pipelines/text2sql_pipeline_gen.py -
api_pipelines/text2sql_pipeline_refine.py
配置 API
API key需要用户在命令行中填写,名称为DF_API_KEY:
export DF_API_KEY="YOUR PERSONAL API KEY"
之后需要配置API url:

2. 数据库配置
在整个前期准备阶段,最关键的步骤就是要准备好数据库
使用示例数据库
为了方便大家初步了解,我们提供了示例数据库。当 db_root_path 参数为空字符串时,系统会自动从 Hugging Face 下载示例数据库文件。
首先配置 HF_TOKEN,可在 Hugging Face 官网获取:
export HF_TOKEN="hf_xxxxx"
配置完成后,保持 db_root_path 参数为空字符串即可。
使用自定义数据库
当然,Pipeline 还支持用户使用自己的数据库。当使用自定义数据库时,将 db_root_path 参数设置为数据库文件夹路径即可。下面,我们主要以 SQLite 数据库和 MySQL 为例来演示如何运行 pipeline。
SQLite 数据库配置
SQLite 是基于文件的数据库系统,使用时需指定数据库文件存储路径。
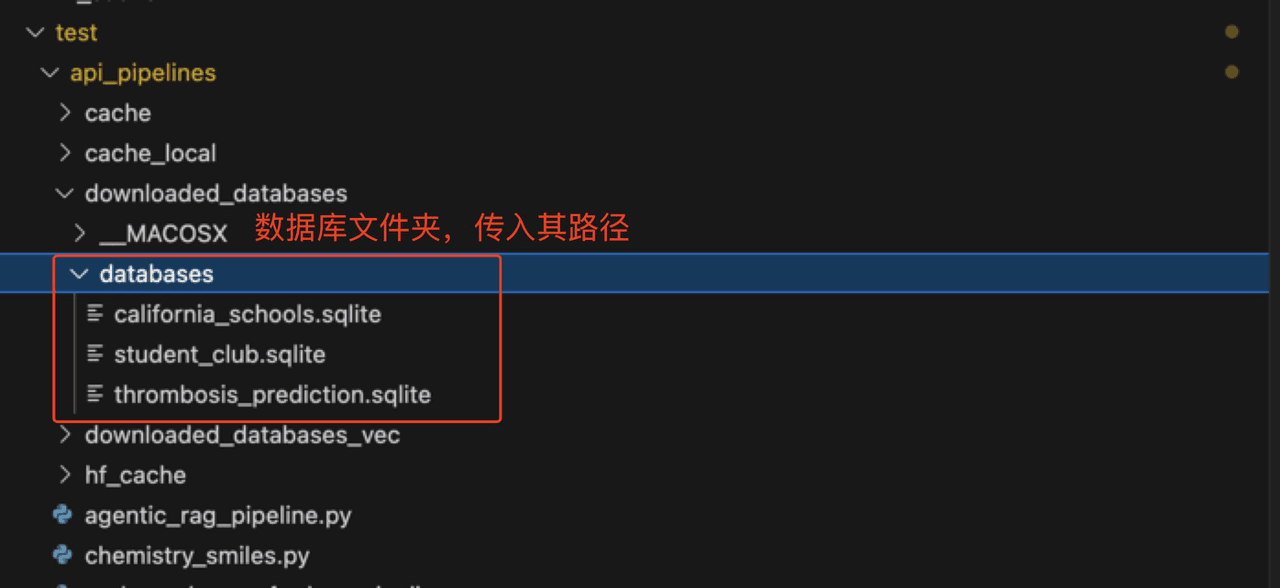
之后配置db_root_path为路径:
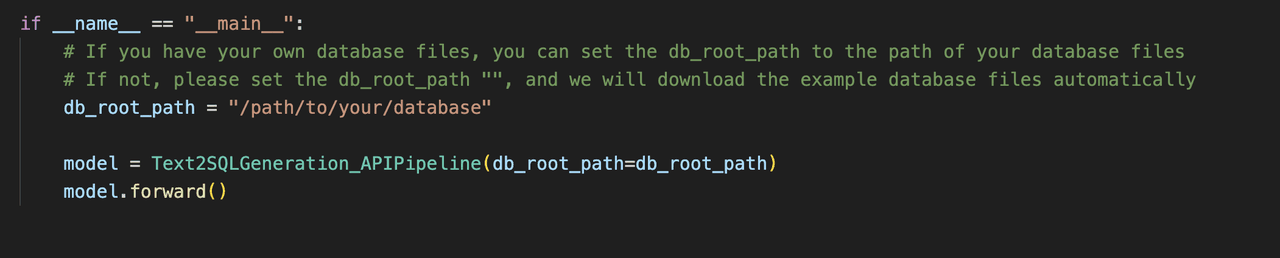
代码中database_manager的配置如下,db_type必须设置为 sqlite。

MySQL 数据库配置
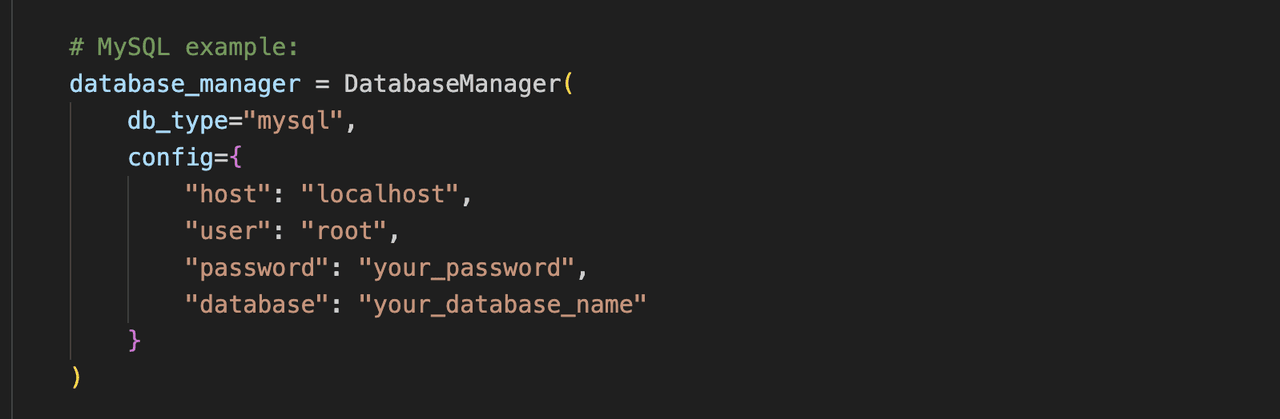
MySQL 数据库以服务器形式存在,需要配置连接信息。请确保 MySQL 服务已启动,且具有相应数据库的访问权限。然后在代码的 database_manager 中配置 mysql 参数即可:
配置 SQL 源文件
根据需求选择不同的流水线:
数据优化流水线(text2sql_pipeline_refine)
输入数据需包含以下字段:
{
"db_id": "california_schools",
"question": "What is the highest eligible free rate for K-12 students in the schools in Alameda County?",
"SQL": "SELECT `Free Meal Count (K-12)` / `Enrollment (K-12)` FROM frpm WHERE `County Name` = 'Alameda' ORDER BY (CAST(`Free Meal Count (K-12)` AS REAL) / `Enrollment (K-12)`) DESC LIMIT 1"
}
需要将 json 文件的路径配置到first_entry_file_name中:

数据合成流水线(text2sql_pipeline_gen)
该模式无需现有数据,直接从数据库合成数据。配置数据库后,将 first_entry_file_name 设置为空字符串:

3. 运行流水线
运行数据优化流水线:
python pipelines/api_pipelines/text2sql_pipeline_refine.py
运行数据合成流水线:
python pipelines/api_pipelines/text2sql_pipeline_gen.py
4. 结果示例
在cache_local文件夹中,会看到最后的执行结果,其中最后一个文件是最后的结果:
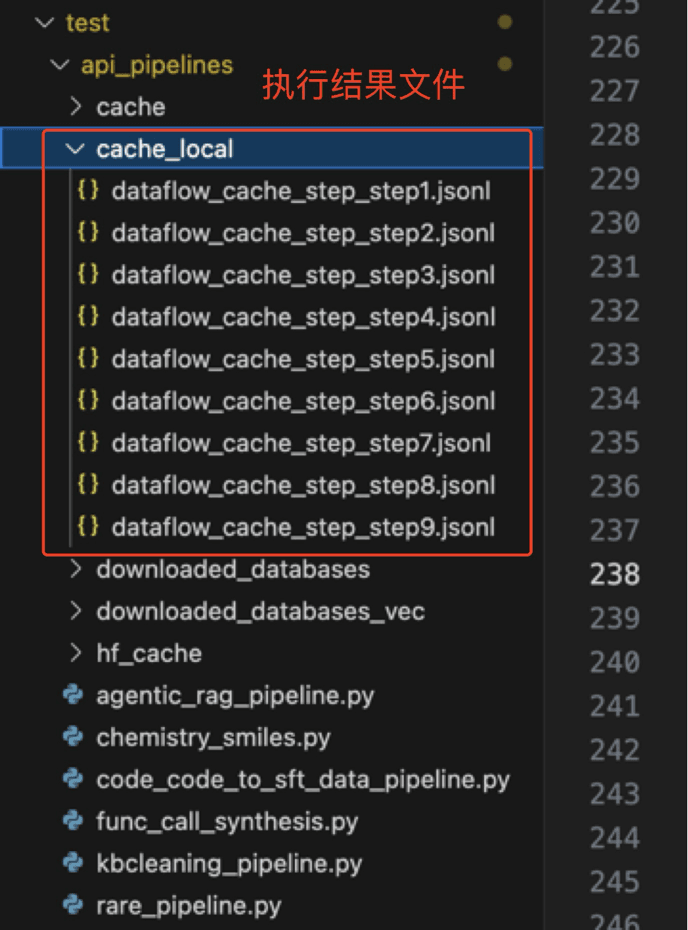
-
db_id: 数据库id -
question: 自然语言问题 -
SQL: 标准SQL答案 -
prompt: 用于训练的提示词,包含自然语言问题、数据库Schema和提示信息 -
cot_reasoning: 长链推理数据,包含推理过程和最终答案,用于模型训练 -
sql_component_difficulty: SQL组件复杂度评估 -
sql_execution_difficulty: SQL执行复杂度评估
示例数据如下:
{
"db_id":"california_schools",
"SQL":"SELECT AVG(s.AvgScrRead) AS average_reading_score\nFROM satscores s\nINNER JOIN frpm f ON s.cds = f.CDSCode\nINNER JOIN schools sc ON f.CDSCode = sc.CDSCode\nWHERE s.cname = 'Alameda'\n AND f.\"Charter School (Y\/N)\" = 1\n AND f.\"Charter Funding Type\" = 'Directly funded'\n AND sc.County = 'Alameda';",
"question":"What is the average reading score for directly funded charter schools in Alameda County?",
"prompt":"Task Overview: /* Given the following database schema: ... /* Answer the following: What is the average reading score for directly funded charter schools in Alameda County? * Let's think step by step",
"cot_reasoning":"To translate the natural language question into an executable SQLite query, we will follow these steps. ... we can construct the full SQLite query based on these steps:\n\n```sql\nSELECT AVG(s.AvgScrRead) AS average_reading_score\nFROM satscores s\nINNER JOIN frpm f ON s.cds = f.CDSCode\nINNER JOIN schools sc ON f.CDSCode = sc.CDSCode\nWHERE s.cname = 'Alameda'\n AND f.\"Charter School (Y\/N)\" = 1\n AND f.\"Charter Funding Type\" = 'Directly funded'\n AND sc.County = 'Alameda';\n```\n\nThis query follows the logic outlined above and ensures alignment with the reference solution.",
"sql_component_difficulty":"medium",
"sql_execution_difficulty":"medium"
}
结语
Text2SQL 的问题,表面看是模型是否足够聪明,实际上却反复暴露在同一个地方:模型生成的 SQL,是否真的能在真实数据库中成立。
本文围绕 Text2SQL Pipeline 展开,从数据的来源、约束方式到最终的训练样本构建,展示了一条以数据库执行结果为核心的数据路径。无论是优化已有数据,还是从数据库直接合成数据,所有 SQL 都必须经过同一套验证与筛选流程,才能进入模型训练。
这条 Pipeline 的价值不在于“生成更多 SQL”,而在于让每一条被模型学习的 SQL 都是可信的。当 Text2SQL 被放回到这样一条可验证的数据流水线中,它才真正具备走向真实系统的基础。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)