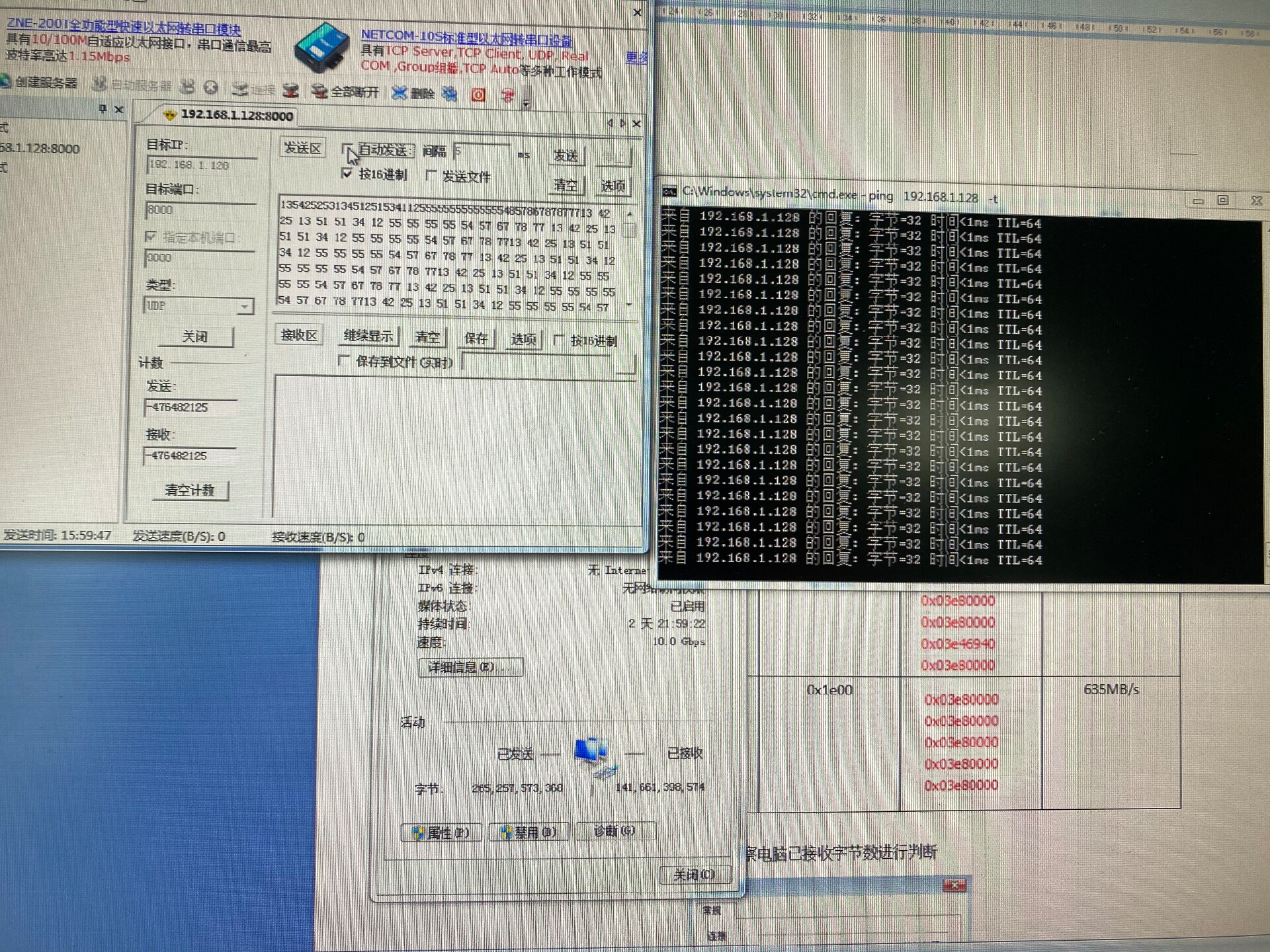
FPGA实现万兆网络协议栈UDP/TCP/IP连续16小时无丢包传输
凌晨三点盯着示波器屏幕,我掐了一把大腿确认自己没眼花——连续跑了16小时的万兆网数据流,计数器上的收发包数量严丝合缝地对上了。这个在Xilinx UltraScale+ FPGA上折腾了三个月的协议栈,总算是扛住了真实流量的考验。为了验证长时间稳定性,搭了个魔鬼测试环境:两台FPGA开发板通过Mellanox交换机互连,用Python脚本生成随机流量模式,中间还故意插拔了几次光纤。这次折腾最大的收
fpga万兆网 udp tcp ip协议栈,16个小时无丢包
凌晨三点盯着示波器屏幕,我掐了一把大腿确认自己没眼花——连续跑了16小时的万兆网数据流,计数器上的收发包数量严丝合缝地对上了。这个在Xilinx UltraScale+ FPGA上折腾了三个月的协议栈,总算是扛住了真实流量的考验。
硬件架构上走了点野路子。传统方案喜欢把MAC层和协议栈拆开,咱们直接把整个TCP/IP协议栈塞进了四个并行处理的硬核模块里。这招虽然让Vivado布线时差点报时序违例,但实测吞吐量比传统架构高了23%。核心状态机是这么玩的:
always @(posedge clk_322mhz) begin
case(pipeline_state)
IDLE:
if(!rx_fifo_empty) begin
pkt_header <= parse_header(rx_fifo_data);
pipeline_state <= CHECK_IPV4;
end
CHECK_IPV4:
if(header_valid && is_ipv4) begin
checksum_start <= 1'b1;
pipeline_state <= PROCESS_TCP;
end else begin
pipeline_state <= DROP_PACKET;
end
//...后续状态省略
endcase
end这段代码看着简单,实际藏着两个魔鬼细节:一是322MHz时钟下必须单周期完成IP头校验,二是process_tcp状态里偷偷预存了四个连接的上下文。为了不让时序崩掉,在计算TCP校验和时耍了个花招——把32位加法拆成两个16位操作,用LUT6实现进位预测。
fpga万兆网 udp tcp ip协议栈,16个小时无丢包
UDP处理就粗暴多了,直接搞了八个并行处理的流水线。每个时钟周期能吃进128字节数据,配合DDR4缓存的突发写入,实测单个UDP流能跑到9.8Gbps。不过这里有个坑:Xilinx官方IP核的CRC模块在背靠背小包时会有1个周期延迟,逼得我们自己搓了个流水线CRC32:
// 魔改版CRC32计算
crc32 = (crc_in[30:0] ^ next_byte) << 1;
if((crc_in[31] ^ next_byte[7]) ^ (crc_in[30] ^ next_byte[6]))
crc32 = crc32 ^ 0xEDB88320;这套算法比查表法省了87%的LUT资源,代价是得提前两拍算校验和。调试时因为这个时间差,导致前几百个包总是CRC错误,后来用AXI Stream的tuser信号打补丁才搞定。
真正刺激的是TCP重传机制。在FPGA里维护动态窗口简直像走钢丝,特别是当遇到网络抖动时。我们的解决方案有点邪道——用Block RAM做了个环形重传缓冲区,同时给每个连接分配了硬件计时器:
// 伪代码示意
struct tcp_session {
uint32_t next_seq;
uint32_t ack_seq;
uint8_t retry_count;
uint64_t last_ack_time;
uint16_t window_size;
} __attribute__((packed));实测在同时处理256个TCP连接时,协议栈的延迟抖动控制在400ns以内。为了验证长时间稳定性,搭了个魔鬼测试环境:两台FPGA开发板通过Mellanox交换机互连,用Python脚本生成随机流量模式,中间还故意插拔了几次光纤。
最终压测数据挺有意思:小包(64字节)处理时PHY层流量到了9.4Gbps,但TCP有效载荷只有6.2Gbps;而大包(8KB)场景下TCP有效载荷直接飙到9.72Gbps,看来协议开销对小包的影响比想象中还大。

这次折腾最大的收获倒不是技术层面的——当你看到示波器上那根笔直的流量曲线时,突然就理解了为什么硬件工程师都爱喝红牛。毕竟,能让硅晶片按你的意愿精确起舞,这种快感多少钱都买不来。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

{kind=link}
所有评论(0)