LabelStudio+YOLO实战:从数据标注到模型训练完整指南
1 前言
最近在尝试做图像目标检测相关的模型训练工作,但是如果想要实现一个模型的训练,数据集是至关重要,而目标检测数据集的制作相对于图像分类要复杂一些,因此需要一个简单易用的标注工具。
2 关于YOLO和Label-studio
2.1 YOLO
目前YOLO系列应用最广泛、生态最成熟的是YOLOv8。YOLOv8 由 Ultralytics 于 2023 年 1 月 10 日发布,在准确性和速度方面提供了尖端性能。与旧版本相比,YOLOv8 采用最先进的骨干和颈部架构,从而改进了特征提取和目标检测性能。不仅如此,YOLOv8还专注于在准确性和速度之间保持最佳平衡,适用于各种应用领域中的实时对象检测任务。
YOLO26是 YOLO 系列实时对象检测器的最新演进,从头开始专为边缘和低功耗设备而设计。它引入了简化的设计,消除了不必要的复杂性,同时集成了有针对性的创新,以实现更快、更轻、更易于访问的部署。
2.1.1 任务
YOLOv8 系列提供各种各样的模型,每个模型都专门用于计算机视觉中的特定任务。这些模型旨在满足各种需求,从目标检测到更复杂的任务,如实例分割、姿势/关键点检测、旋转框检测和分类。
| 模型 | 文件名 | 任务 |
|---|---|---|
| 无后缀的模型/det | yolov8n.pt | 检测 |
| seg | yolov8n-seg.pt | 实例分割 |
| pose | yolov8n-pose.pt | 关键的 |
| obb | yolov8n-obb.pt | 姿势 |
| cls | yolov8n-cls.pt | 分类 |
- 目标检测是一项涉及识别图像或视频流中目标的位置和类别的任务。目标检测器的输出是一组边界框,这些边界框包围了图像中的目标,以及每个框的类别标签和置信度分数。当需要在场景中识别感兴趣的目标,但不需要确切知道目标在哪里或其确切形状时,目标检测是一个不错的选择。
- 实例分割比对象检测更进一步,包括识别图像中的各个对象并将它们与图像的其余部分分割开来。实例分割模型的输出是一组掩码或轮廓,它们勾勒出图像中每个对象,以及每个对象的类别标签和置信度分数。 当不仅需要知道对象在图像中的位置,还需要知道它们的精确形状时,实例分割非常有用。
- 图像分类是三个任务中最简单的,它涉及将整个图像分类到一组预定义的类别中。图像分类器的输出是单个类别标签和一个置信度分数。当只需要知道图像属于哪个类别,而不需要知道该类别的对象位于何处或其确切形状时,图像分类非常有用。
- 姿势估计是一项涉及识别图像中特定点的位置的任务,这些点通常称为关键点。关键点可以代表对象的各个部分,例如关节、地标或其他独特特征。姿势估计模型的输出是一组点,这些点代表图像中对象上的关键点,通常还包括每个点的置信度分数。当需要识别场景中对象的特定部分及其彼此之间的位置时,姿势估计是一个不错的选择。
- 定向对象检测通过引入一个额外的角度来更准确地定位图像中的对象。定向目标检测器的输出是一组旋转的边界框,这些边界框精确地包围了图像中的目标,以及每个框的类别标签和置信度分数。当目标以各种角度出现时,定向边界框特别有用。
2.1.2 变体
YOLOv8提供了不同精度和性能的模型变体:
- YOLOv8n:nano(最小、最快)
- YOLOv8s:small(小型)
- YOLOv8m:mediem(中型)
- YOLOv8l:large(大型)
- YOLOv8x:extra large(最大、最慢)
其中n变体最轻量但精度和准确度低,x变体精度最高但所需计算资源多且推理速度慢。
2.1.3 模式
yolo提供了五种模式来满足不同的工作流程,每种模式旨在为模型开发和部署的不同阶段提供全面的功能:
- 训练(train):在自定义或预加载的数据集上微调您的模型。
- 验证(val):训练后的检查点,用于验证模型性能。
- 预测(predict):释放模型在真实世界数据中的预测能力。
- 导出(export):以各种格式使模型部署准备就绪。
- 跟踪(track):将对象检测模型扩展到实时跟踪应用程序。
- 基准测试(benchmark):分析模型在不同部署环境中的速度和准确性。
YOLOv8系列的每个变体都与各种操作模式兼容,包括推理、验证、训练和导出,从而方便了它们在部署和开发的不同阶段中使用。但是其他系列的不一定都能兼容,具体兼容情况见官方文档。
2.1.4 调用
可以使用 Python API、命令行界面 (CLI) 或配置文件来自定义每个参数。
- python api方式
from ultralytics import YOLO
model = YOLO("yolo26n.pt")
model.train(cfg="train_custom.yaml")
- CLI
直接从终端运行各种任务。
yolo train data=coco8.yaml model=yolo26n.pt epochs=10 lr0=0.01
- 配置文件
在 YAML 配置文件中定义所有训练参数,包括增强。
data: coco8.yaml
model: yolov8n.pt
epochs: 100
hsv_h: 0.03
hsv_s: 0.6
hsv_v: 0.5
2.1.5 参数配置
不同的阶段的配置参数也不一样。以下仅介绍常用的配置,详细的配置见官方文档。
● 训练设置
包括影响模型性能、速度和准确性的超参数和配置。 关键设置包括批量大小、学习率、动量和权重衰减。 优化器、损失函数和数据集组成的选定也会影响训练。 调整和实验对于获得最佳性能至关重要。
参数 描述
model 指定用于训练的模型文件,接受.pt预训练模型或.yaml配置文件路径。
data 数据集配置文件的路径(例如coco8.yaml),文件包含数据集特定的参数,包括训练集和验证集的路径、类别名称和类别数量
epochs 训练轮数
batch 批次大小,默认为16,与模型的泛化能力有关。
imgsz 用于训练的目标图像大小,默认为640。大目标检测需增大该值,但相应地计算复杂度和耗时也会增大。
save 启用保存训练检查点和最终模型权重。可用于恢复训练
save_period 保存模型检查点的频率,用于保存中间模型
device 指定训练设备
amp 启动自动混合精度训练,减少内存使用
lr0 初始学习率,影响模型权重的更新速度
weight_decay L2正则化项,惩罚大权重防止过拟合
val 在训练期间启用验证,定期评估模型在验证集的性能
● 验证设置
预测设置包括影响推理过程中性能、速度和准确性的超参数和配置。
参数 描述
source 指定推理的数据源
conf 设置检测的最小置信度阈值,将忽略置信度低于此值的对象
iou 较低的值会通过消除重叠狂来减少检测数量
half 启用半精度推理,能加快gpu上的推理速度
show 可视化参数
save 标注的图像或视频是否保存
save_txt 以txt文件格式保存检测结果
show_label 显示每个检测的标签
line_width 指定边界框的线条宽度
● 验证设置
验证设置涉及超参数和配置,以评估 验证数据集 上的性能。这些设置会影响性能、速度和准确性。常用设置包括批量大小、验证频率和性能指标。验证数据集的大小和组成以及特定任务也会影响该过程。
参数 描述
data 指定数据集配置文件(coco8.yml),该文件应包含验证集数据集路径
save_json 将结果保存至json文件
device 指定验证的设备
● 导出设置
导出设置包括用于保存或导出模型以在不同环境中使用的配置。这些设置会影响性能、大小和兼容性。
参数 描述
format 导出模型的格式,不同的格式支持不同的部署环境。支持’onnx’、'torchscript’等
workspace 设置最大工作区大小,单位为GB,用于TensorRT优化,平衡内存使用和性能
● 数据增强设置
数据增强技术对于提高YOLO模型鲁棒性和性能至关重要,它通过向训练数据引入变异性,帮助模型更好地泛化到未见过的数据。
参数 描述
hsv_h 通过色轮的一小部分调整图像的色调,从而引入颜色变化。取值范围[0, 1]
hsv_s 通过色轮的一小部分调整图像的饱和度,从而引入颜色强度。取值范围[0, 1]
degrees 在指定的角度范围内随机旋转图像,取值范围[0, 180]
mosaic 将四个训练图像组合成一个,模拟不同场景组成和物体交互。对于复杂的场景理解非常有效。取值范围[0, 1]
mixup 混合两个图像及其标签,创建一个合成的画像。通过引入标签噪声和视觉变化增强模型的泛化能力。取值范围[0, 1]
erasing 训练期间随机擦除图像区域,以鼓励模型关注不太明显的区域。取值范围[0, 0.9]
bgr 以指定的概率将图像通道从RGB翻转至BGR,取值范围[0, 1]
flipud 以指定的概率将图像上下翻转,取值范围[0, 1]
fliplr 以指定的概率将图像左右翻转,取值范围[0, 1]
perspective 对图像应用随机透视变换,增强模型理解3D空间中物体的能力。取值范围[0, 0.001]
2.1.6 评估指标
| 名称 | 含义 |
|---|---|
| 混淆矩阵 | 显示中识别精准度显示是一条对角线,方块颜色越深代表对应的类别识别的精准度越高。 |
| IoU | 交并比,量化模型预测的框与真实标注框中间的匹配精度。IoU=交集面积/并集面积 |
| 平均精度(mAP) | 衡量模型准确找到物体的能力,反映模型在不同置信度下的精确率和召回率水平 |
| mAP@0.5 | 常用的评估指标,表示在IoU阈值为0.5时的mAP。只有当预测框与真实框的重叠面积IoU≥50%时,才认为检测结果正确 |
| mAP@0.5:0.95 | IoU阈值从0.5到0.95、步长为0.05的10个阈值下mAP的平均值。对于定位十分严格的场景更应关注此指标 |
| 精确率(Precision) | 衡量模型预测为正样本的结果中实际也是正样本的比例 |
| 召回率(recall) | 衡量实际所有正样本中被模型正确预测为正样本的比例 |
| F1分数(f1-score) | 精确率和召回率的调和平均 |
| 边界框损失(box_loss) | 预测框与标注框的位置误差,越小越准 |
| 分类损失(cls_loss) | 预测类别与实际类别的误差,cls_loss高有可能是类别混淆 |
| 目标存在损失(obj_loss) | 该位置是否有目标的误差,obj_loss高可能是背景干扰多 |
| FPS | 每秒能处理的图片数量,实时检测需要有较大的FPS |
| inference time | 单张图片的推理时间 |
| train time | 单轮训练时间 |
| 一般来说常用的就是精度指标和f1-score,其他的根据实际场景选择。面对一堆指标,不用面面俱到,按这个优先级分析即可: |
- 先看 mAP@0.5:判断模型整体精度是否达标;
- 再看 F1 分数,是否符合场景需求;
- 然后看损失曲线:判断训练是否收敛,是否有过拟合;
- 最后看 FPS:判断模型是否能落地使用。
2.2 label-studio
对比了网上的一堆工具之后,最后选择了label studio,主要是以下原因:
- 数据安全性:期望标注的数据可以只在内网使用,不希望暴露在外网
- 便捷性:无需下载只要打开网页就能实现标注,多人协作
- 自动/半自动标注:可以结合训练的模型来辅助标注实现自动/半自动标注,也可以可视化和验证训练模型的目标检测效果。
label-studio共享8080端口,启动前需检查该端口是否被占用。
3 项目架构
3.1 代码架构
暂无。
3.2 流程

4 环境准备
本项目支持Python3.8+。
4.1 环境搭建
安装python,并添加路径至系统变量,只有添加了环境变量才能在cmd或powershell启动启动图片标注应用。
4.2 虚拟环境
- 创建虚拟环境并激活
- 安装依赖
pip install label-studio
pip install ultralytics
5 数据集制作
5.1 LabelStudio启动
- 终端执行以下指令,等待一会会弹出网页。
label-studio start
-
第一次进入会弹出登录页面,自行注册登录即可。
-
点击右上角的create新建项目,根据需求填写信息即可。注意图片数量是由上限的。
-
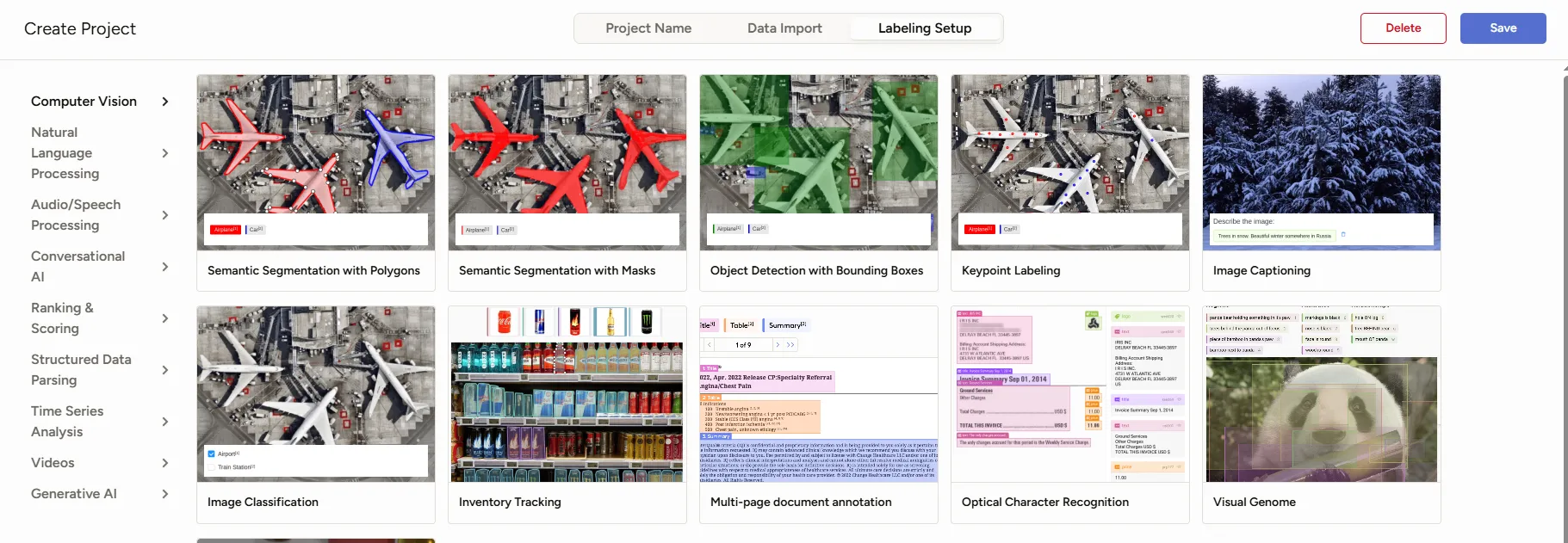
选择标注类型后,需要配置标签模板。可以用 xml 方式直接配置,也可以使用现有的模版。详细介绍见官方文档。选择的标注类型根据实际情况调整即可。
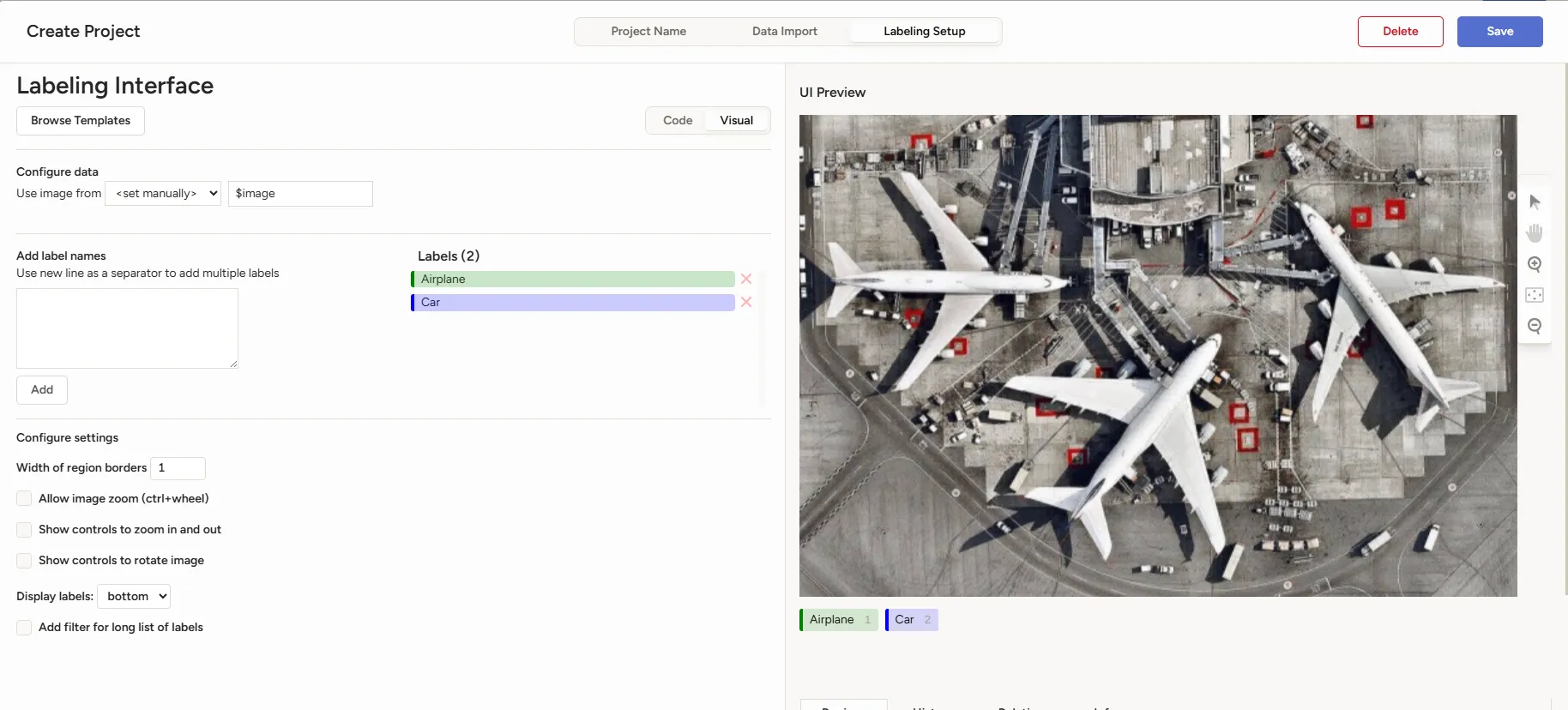
-
开始标注.。。
-
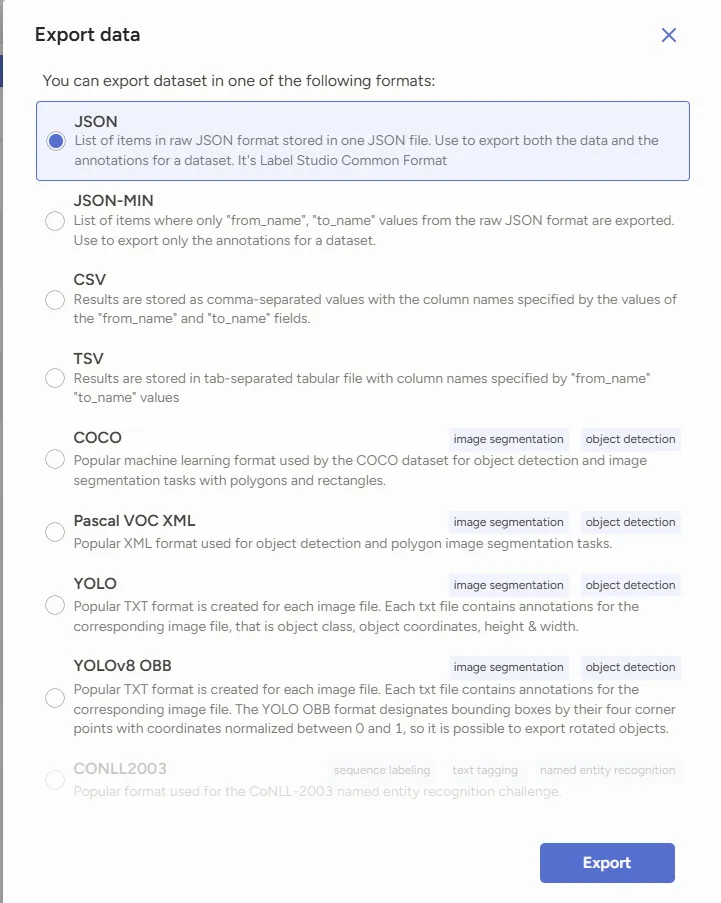
点击export,导出标注的数据。根据所需的格式导出。
5.2 数据集划分
通过以下脚本将数据集划分为训练集验证集和测试集,比例默认为7:2:1。
import os
import shutil
import random
from pathlib import Path
def split_yolo_dataset(src_dir="output_yolo", ratios=(0.7, 0.2, 0.1)):
"""
参数说明:
src_dir: 原始数据集目录(需要包含images和labels子目录)
ratios: 训练/验证/测试集比例
"""
# 创建备份目录
dst_dir = f"{src_dir}_split"
if os.path.exists(dst_dir):
shutil.rmtree(dst_dir)
# 创建标准目录结构
base_path = Path(dst_dir)
(base_path / "images").mkdir(parents=True)
(base_path / "labels").mkdir(parents=True)
# 复制原始文件
shutil.copytree(Path(src_dir) / "images", base_path / "images" / "original")
shutil.copytree(Path(src_dir) / "labels", base_path / "labels" / "original")
shutil.copy(Path(src_dir) / "classes.txt", base_path)
if (Path(src_dir) / "notes.json").exists():
shutil.copy(Path(src_dir) / "notes.json", base_path)
# 获取所有图像文件名
all_images = [f.stem for f in (base_path / "images/original").glob("*.*")
if f.suffix.lower() in ['.jpg', '.png', '.jpeg']]
random.shuffle(all_images) # 随机打乱顺序
# 计算分割点
total = len(all_images)
train_end = int(ratios[0] * total)
val_end = train_end + int(ratios[1] * total)
# 划分数据集
splits = {
"train": all_images[:train_end],
"val": all_images[train_end:val_end],
"test": all_images[val_end:]
}
# 创建目标目录结构
for split in splits:
(base_path / "images" / split).mkdir()
(base_path / "labels" / split).mkdir()
# 移动文件到对应目录
for split, files in splits.items():
for fname in files:
# 处理图像文件
src_img = next((base_path / "images/original").glob(f"{fname}.*"))
dst_img = base_path / "images" / split / src_img.name
shutil.move(str(src_img), str(dst_img))
# 处理标注文件
src_label = base_path / "labels/original" / f"{fname}.txt"
dst_label = base_path / "labels" / split / src_label.name
if src_label.exists():
shutil.move(str(src_label), str(dst_label))
else:
print(f"警告:缺失标注文件 {src_label}")
# 清理原始目录
shutil.rmtree(base_path / "images/original")
shutil.rmtree(base_path / "labels/original")
print(f"数据集已分割到 {dst_dir}")
print(f"最终目录结构:")
print(f"images/")
print(f"├── train/ : {len(splits['train'])} 图像")
print(f"├── val/ : {len(splits['val'])} 图像")
print(f"└── test/ : {len(splits['test'])} 图像")
print(f"labels/")
print(f"├── train/ : {len(splits['train'])} 标注")
print(f"├── val/ : {len(splits['val'])} 标注")
print(f"└── test/ : {len(splits['test'])} 标注")
if __name__ == "__main__":
split_yolo_dataset()
处理后的数据集目录结构如下:
output_yolo
├──images
│ ├──train
│ | ├──train1.jpg
│ | ├──train2.jpg
│ | ├──train3.jpg
...
│ ├──test
│ | ├──test1.jpg
│ | ├──test2.jpg
│ | ├──test3.jpg
...
│ ├──val
│ | ├──val1.jpg
│ | ├──val2.jpg
│ | ├──val3.jpg
...
├──labels
│ | ├──train1.txt
│ | ├──train2.txt
│ | ├──train3.txt
...
│ ├──test
│ | ├──test1.txt
│ | ├──test2.txt
│ | ├──test3.txt
...
│ ├──val
│ | ├──val1.txt
│ | ├──val2.txt
│ | ├──val3.txt
...
├──classes.txt
└──notes.json
其中,classes.txt和notes.json都是记录类别的文件。
5.3 配置文件
创建配置文件:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: dataset/ebike_test_split # 数据集路径
train: images/train # 训练集路径(相对路径)
val: images/val # 验证集路径(相对路径)
test: # 测试集路径(可选)
# 类别(按照notes.json文件的顺序填写)
names:
0: class0
1: class1
2: class2
...
5 模型训练
5.1 预训练模型获取
直接在官网下载或训练时再默认下载。
5.2 训练
5.2.1 训练代码
from ultralytics import YOLO
import torch
def main():
# 训练设备检测
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 选择模型
model = YOLO("yolov8m.pt")
# 开始训练
results = model.train(
data='dataset.yaml',
epochs=100
)
# 验证集评估
metrics = model.val(data='dataset.yaml', split='val')
print("\n验证集结果:")
print(f" mAP@0.5: {metrics.box.map50}")
print(f" Precision: {metrics.box.mp}")
print(f" Recall: {metrics.box.mr}")
if __name__ == '__main__':
main()
6.2.2 预测
使用训练好的模型预测。
from ultralytics import YOLO
model = YOLO("path/to/best.pt") # 替换模型路径
results = model("path/to/photo.png", save=True) # 替换图片路径,图片结果保存
# 导出结果框位置
for result in results:
xywh = result.boxes.xywh
xywhn = result.boxes.xywhn
xyxy = result.boxes.xyxy
xyxyn = result.boxes.xyxyn
names = [result.names[cls.item()] for cls in result.boxes.cls.int()]
confs = result.boxes.conf
6.2.3 模型导出
from ultralytics import YOLO
model = YOLO("path/to/best.pt")
model.export(format="onnx") # 转换为onnx格式
要导出其他格式的请见官方文档。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)