基于Spark的租房数据分析与交互式可视化系统-基于大数据的城市租赁市场态势感知与可视化平台-基于数据挖掘的住房租赁供需关系可视化分析与预测系统
注意:该项目只展示部分功能,如需了解,文末咨询即可。
1 开发环境
发语言:python
采用技术:Spark、Hadoop、Django、Vue、Echarts等技术框架
数据库:MySQL
开发环境:PyCharm
2 系统设计
随着城市化进程加速和人口流动频繁,住房租赁市场数据呈现爆发式增长,海量租房信息分散在各类平台中难以有效整合利用。传统租房信息管理方式已无法满足用户对精准化、智能化租房服务的需求,亟需借助Spark、Hadoop等大数据技术对多源异构租房数据进行分布式存储、并行计算与深度挖掘,并通过可视化手段实现数据价值的直观呈现。
本系统通过构建基于Python与Spark的大数据处理架构,实现租房信息的多维度分析与动态可视化展示,为租房者提供科学的决策依据,帮助其快速定位高性价比房源;同时为房东和房产中介优化房源配置、制定租金策略提供数据支撑,有效推动租房市场信息透明化,促进住房租赁行业的数字化转型与健康发展。
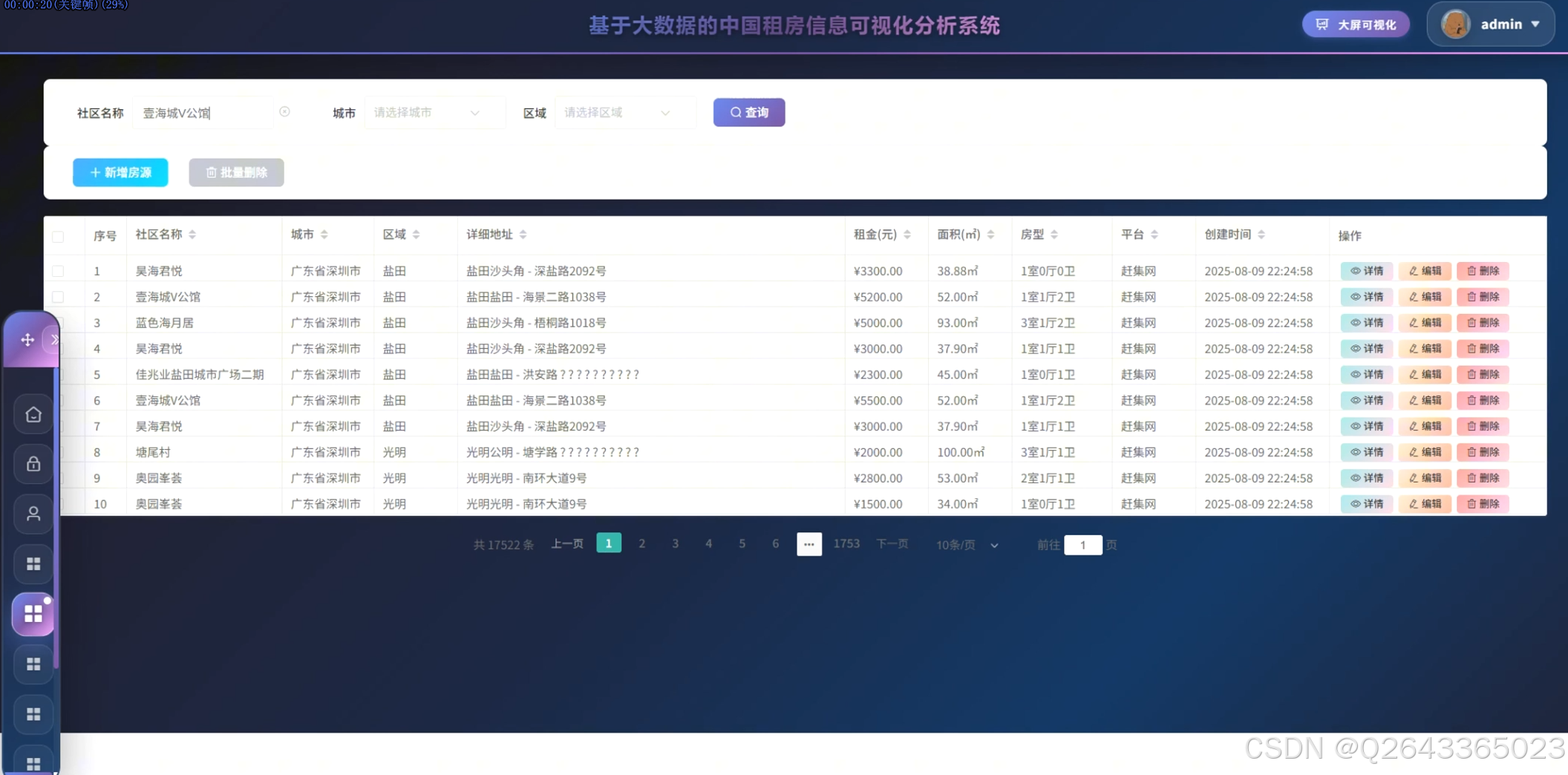
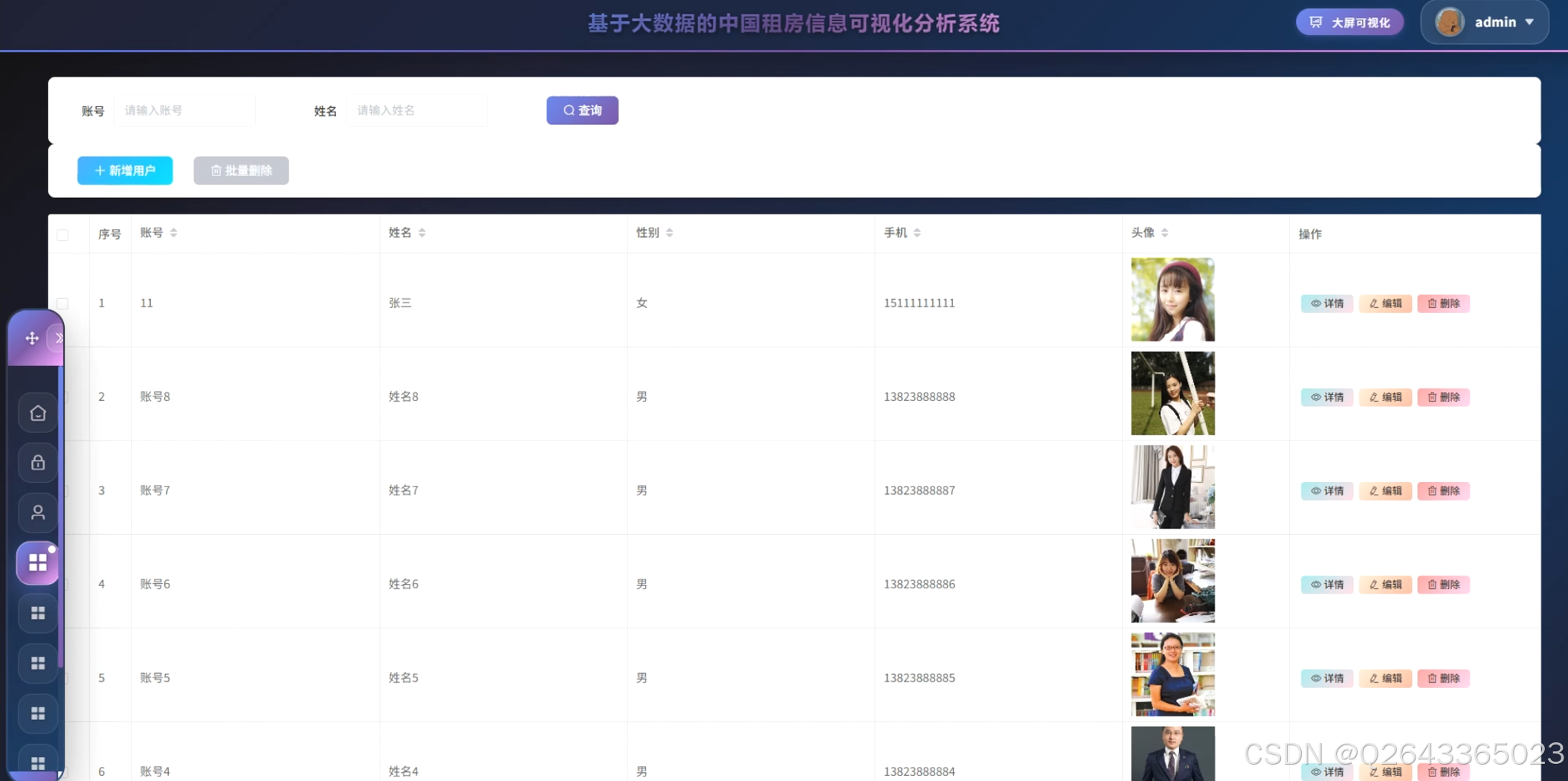
系统主要包含数据采集与存储模块、大数据处理分析模块、可视化展示模块和后台管理模块。数据采集模块负责从多平台爬取租房原始数据并存储至MySQL与HDFS;大数据处理模块基于Spark实现数据清洗、转换与挖掘计算;可视化模块利用Vue结合Echarts构建交互式图表与数据大屏;后台管理模块提供用户与房源信息的增删改查及权限控制功能。
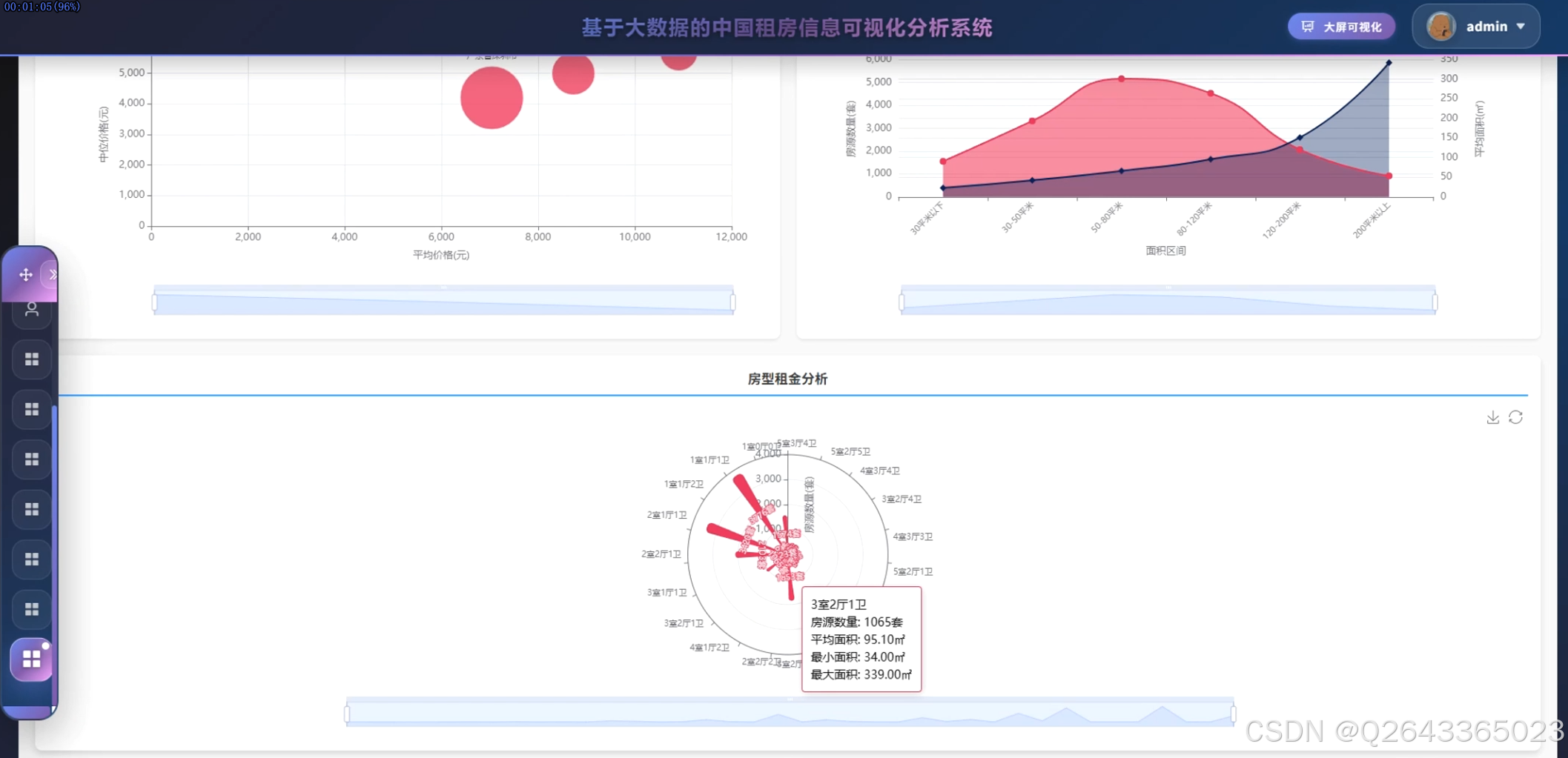
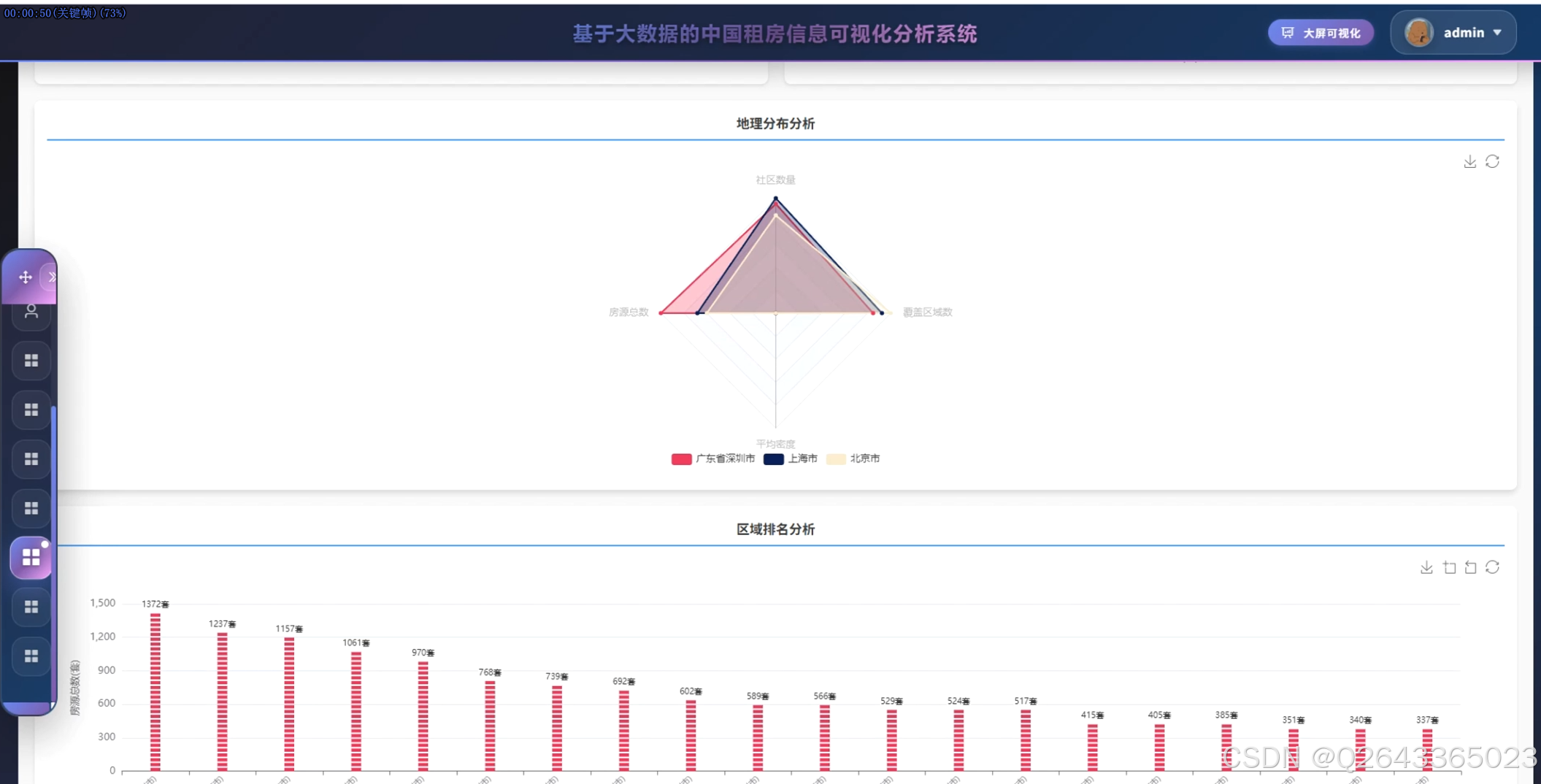
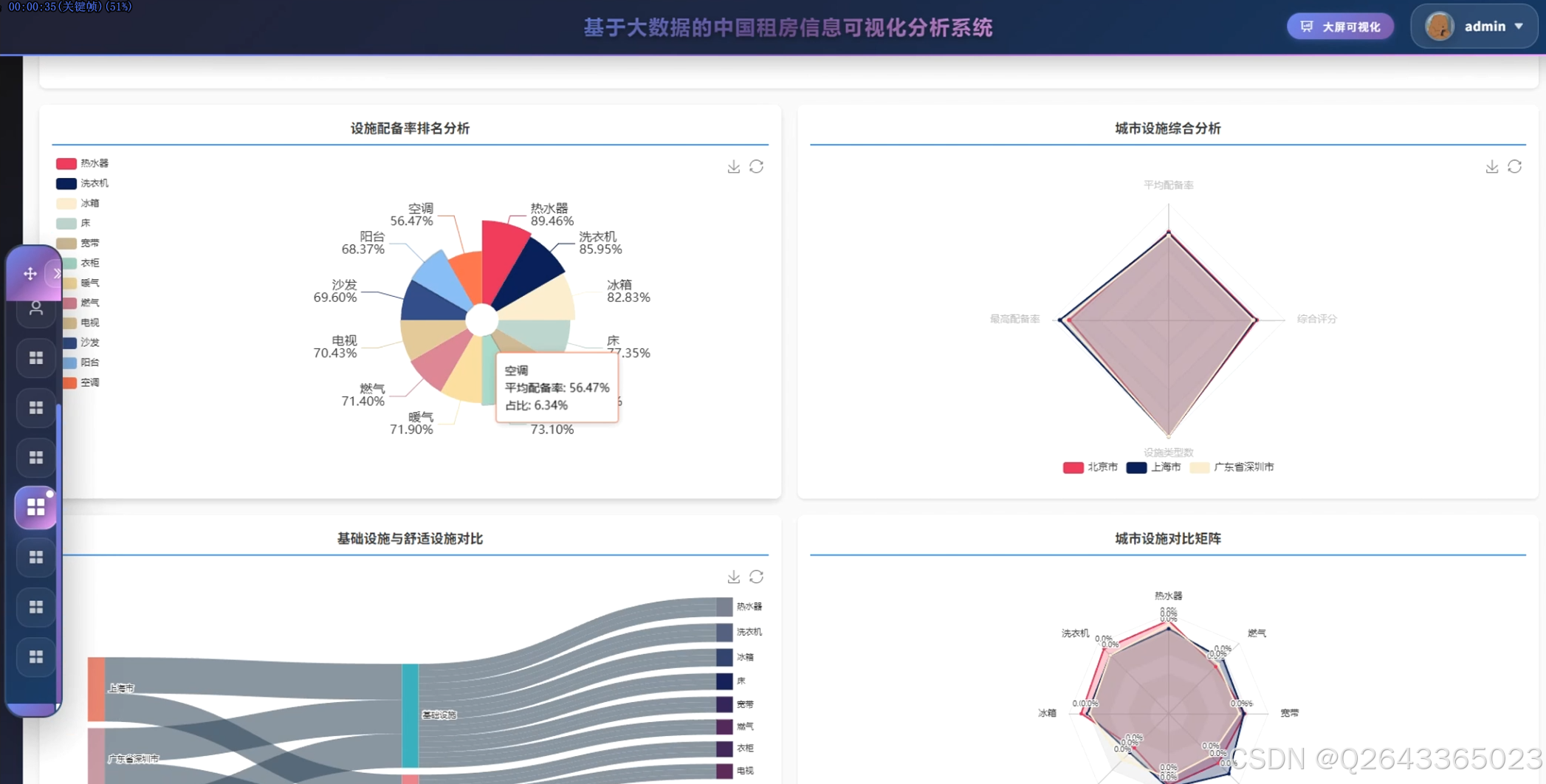
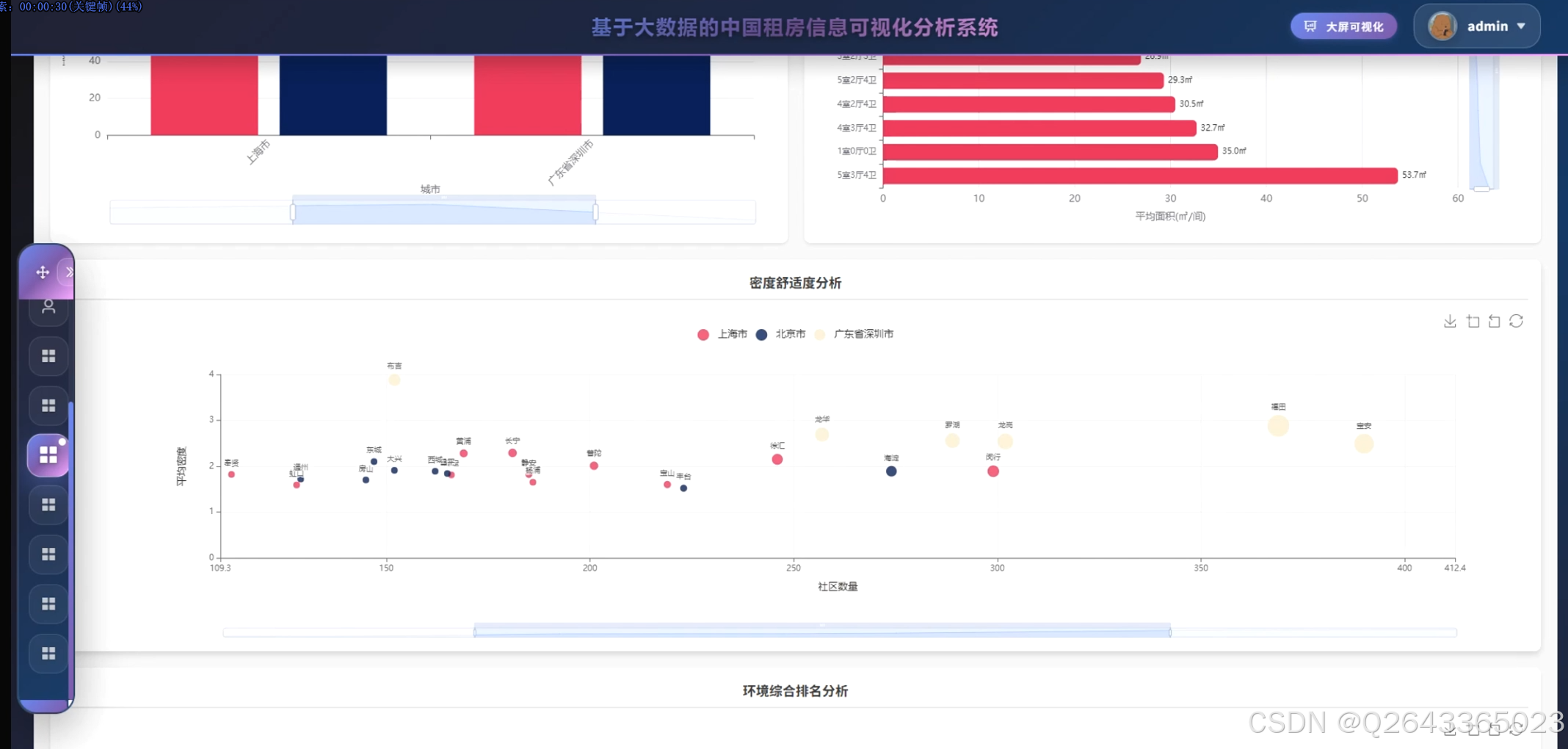
结合系统功能的具体研究内容包括:全国主要城市租房价格对比分析,通过雷达图展示北京、上海、深圳等城市在房源数量、平均价格、中位数价格、最高最低价格等维度的差异特征;租房价格区间分布研究,利用环形图呈现2000元以下至50000元以上各租金区间的房源占比结构;城市房源供应量分析,以柱状图统计各城市房源总量,反映市场供给规模与区域分布差异;房型面积分布研究,通过散点图分析不同房型的面积分布规律与离散程度;热门区域排行分析,横向柱状图展示朝阳、福田、龙岗等区域的房源热度排名;设施配备率研究,通过仪表盘展示总体配备率与高配设施率,量化评估租房生活品质;城市环境质量分析,雷达图多维度对比不同城市的设施评分、气候评分、连通性与生活质量指标;价格偏差极坐标分析,通过极坐标图展示各城市价格偏离度分布,识别价格异常区间;面积区间分布研究,环形图展示30平米以下至200平米以上各面积段的房源占比;密度舒适度分析,散点图展示社区数量与平均密度的关系,评估居住舒适度与房源聚集度;设施配备深度分析,通过饼图展示热水器、洗衣机、空调等设施的配置率排名,利用桑基图分析基础设施与舒适设施流向,结合雷达图对比矩阵展示城市间设施差异;社区房源集中度研究,矩形树图展示各社区房源数量分布,识别高密度社区与热点区域;城市区域分布分析,旭日图层级化展示城市内部各行政区的房源分布结构;地理分布分析,雷达图对比不同城市在房源总数、社区数量、覆盖区域等维度的特征;区域排名分析,柱状图展示各区域房源总量的降序排列;供需平衡分析,气泡图展示供应比例与平均价格的关系,分析市场供需匹配程度;热点社区分析,散点图识别超热门、热门及较热门社区的空间分布;房型租金分析,极坐标柱状图展示不同户型(如3室2厅1卫、1室0厅0卫等)的房源数量与面积特征。
3 系统展示
3.1 功能展示视频
基于hadoop大数据的中国租房信息可视化分析系统毕设源码 !!!请点击这里查看功能演示!!!
3.2 大屏页面
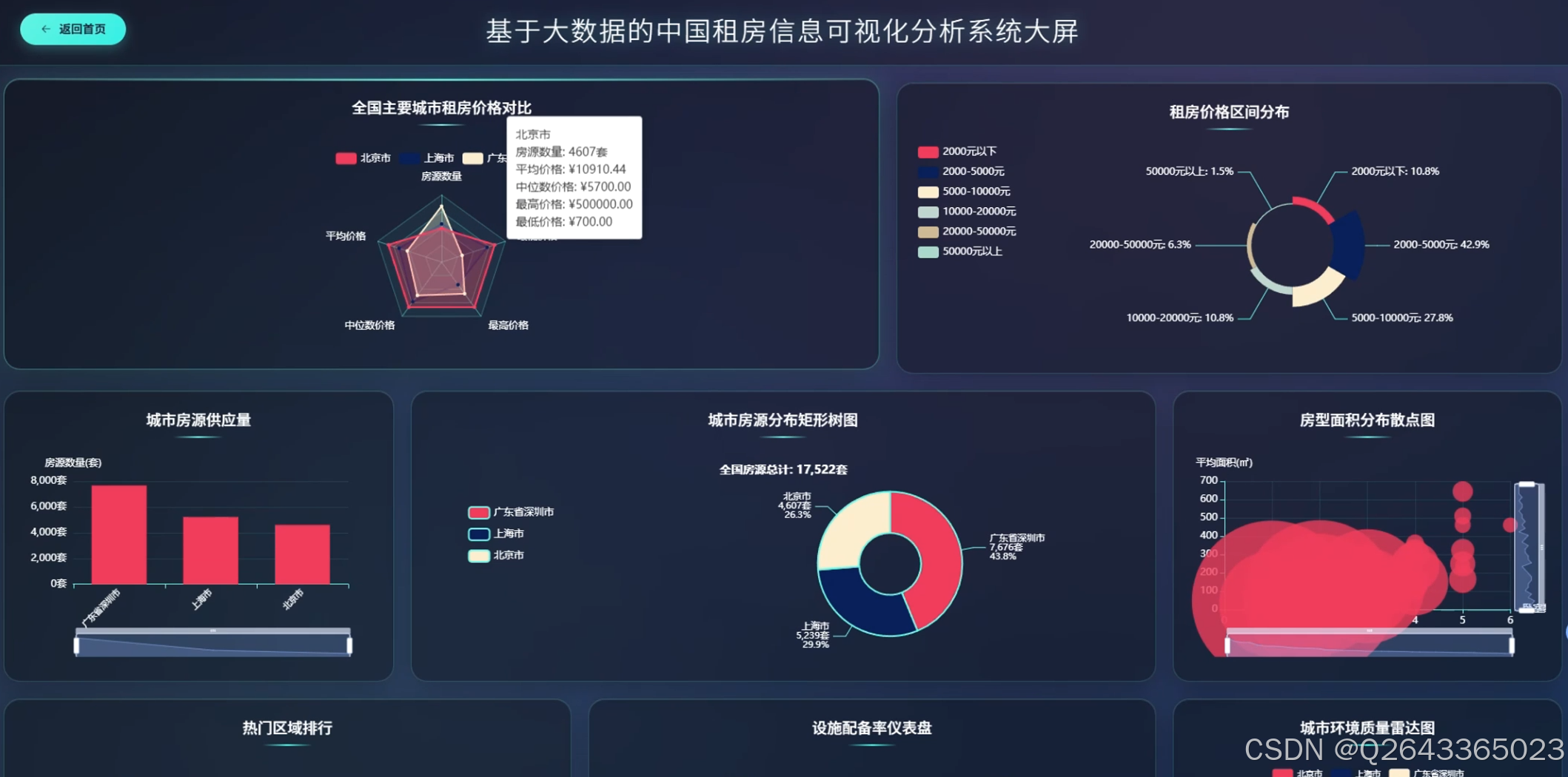
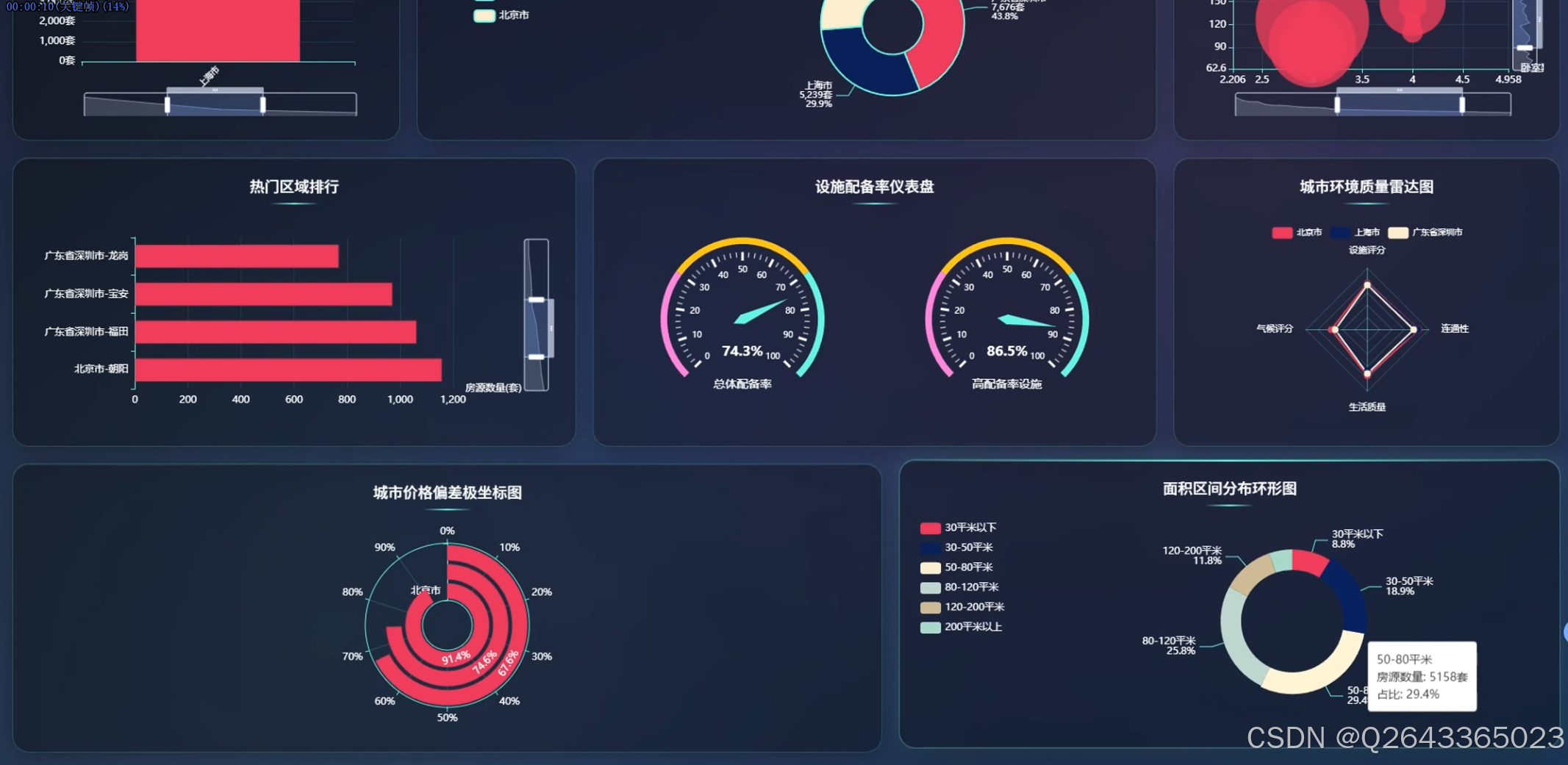
3.3 分析页面
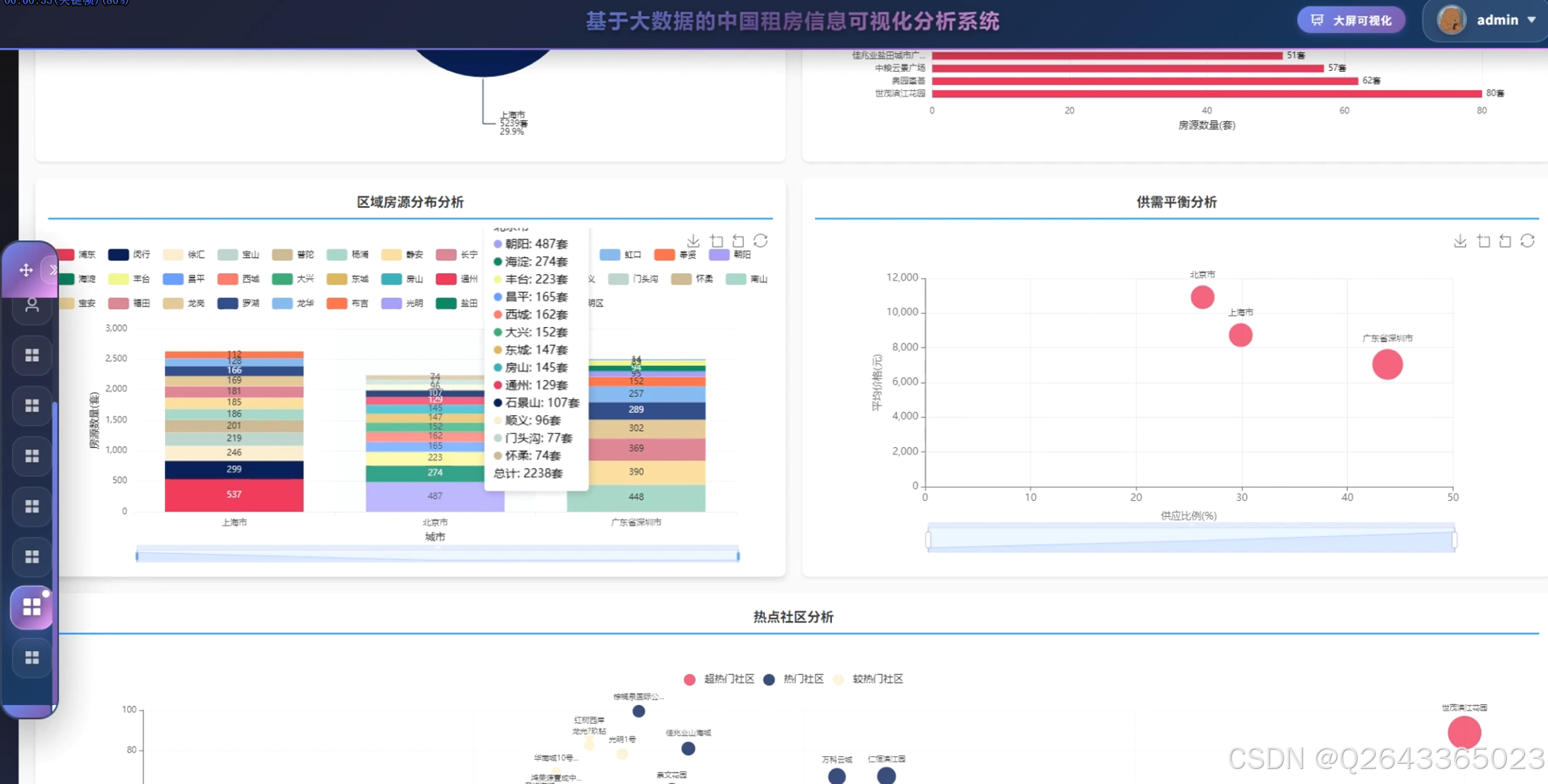
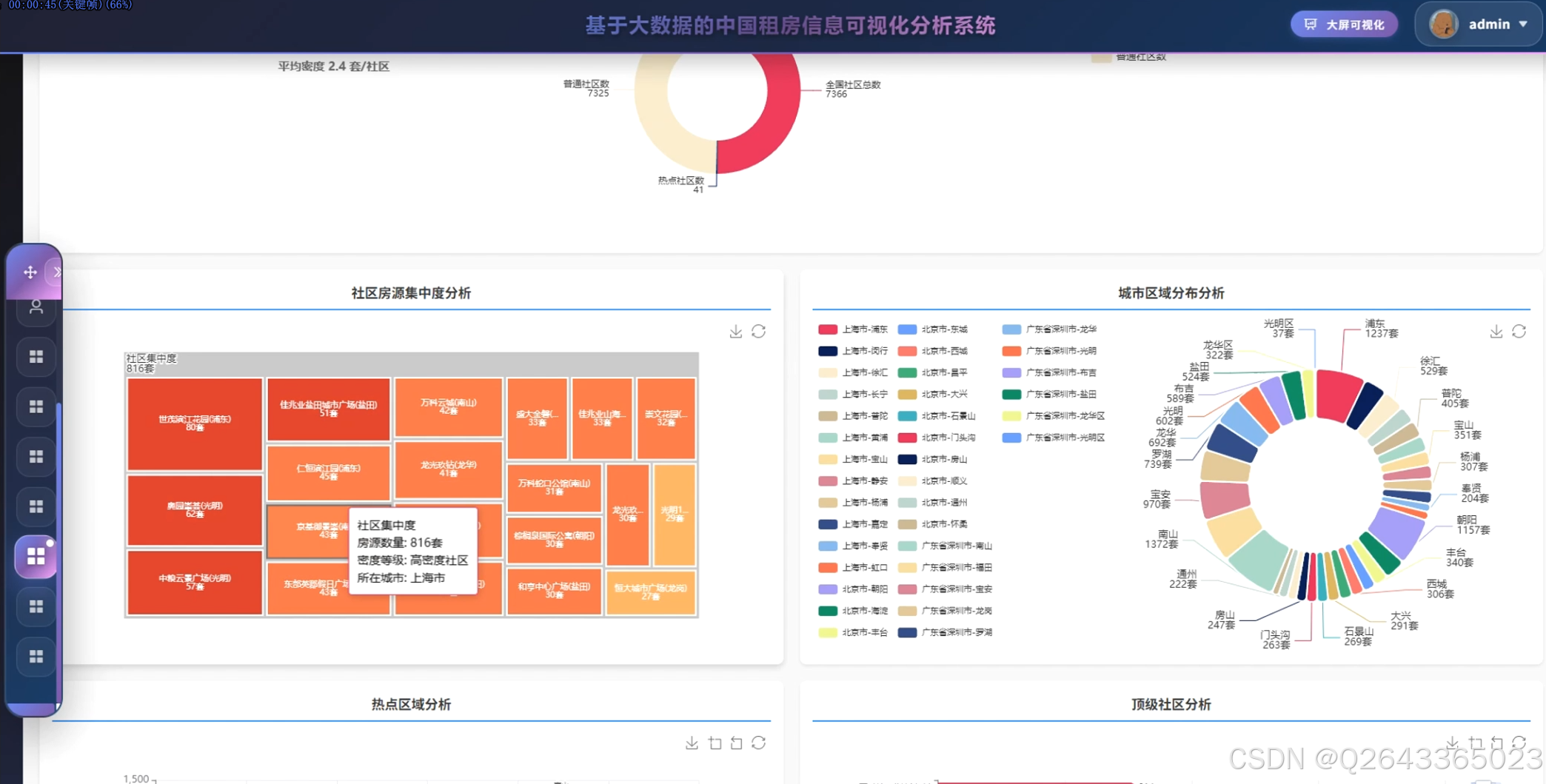
3.4 基础页面
4 更多推荐
计算机专业毕业设计新风向,2026年大数据 + AI前沿60个毕设选题全解析,涵盖Hadoop、Spark、机器学习、AI等类型
计算机专业毕业设计选题深度剖析,掌握这些技巧,让你的选题轻松通过,文章附35个优质选题助你顺利通过开题!
【避坑必看】26届计算机毕业设计选题雷区大全,这些毕设题目千万别选!选题雷区深度解析
紧跟风口!2026计算机毕设新赛道:精选三大热门领域下的创新选题, 拒绝平庸!毕设技术亮点+功能创新,双管齐下
纯分享!2026届计算机毕业设计选题全攻略(选题+技术栈+创新点+避坑),这80个题目覆盖所有方向,计算机毕设选题大全收藏
计算机专业毕业设计选题深度剖析,掌握这些技巧,让你的选题轻松通过,文章附35个优质选题助你顺利通过开题!
5 部分功能代码
# 初始化Spark会话,配置Hadoop连接
spark = SparkSession.builder \
.appName("RentalDataAnalysis") \
.config("spark.hadoop.fs.defaultFS", "hdfs://localhost:9000") \
.getOrCreate()
# 从MySQL读取原始租房数据
df = spark.read.jdbc(
url="jdbc:mysql://localhost:3306/rental_db",
table="rental_house",
properties={"user": "root", "password": "password", "driver": "com.mysql.jdbc.Driver"}
)
# 数据清洗:过滤异常值,转换价格区间字段
clean_df = df.filter((col("price") > 0) & (col("area") > 0)) \
.withColumn("price_range",
when(col("price") <= 2000, "2000元以下")
.when(col("price") <= 5000, "2000-5000元")
.when(col("price") <= 10000, "5000-10000元")
.when(col("price") <= 20000, "10000-20000元")
.otherwise("20000元以上")
)
# 核心分析1:城市维度聚合统计(房源量、均价、极值)
city_analysis = clean_df.groupBy("city").agg(
count("*").alias("房源数量"),
avg("price").alias("平均价格"),
avg("area").alias("平均面积"),
max("price").alias("最高价格"),
min("price").alias("最低价格")
)
# 核心分析2:价格区间分布统计
price_distribution = clean_df.groupBy("price_range").agg(
count("*").alias("房源数量")
).orderBy("price_range")
# 核心分析3:区域热度排行(Top10热门区域)
hot_area = clean_df.groupBy("city", "district").count() \
.withColumnRenamed("count", "房源数量") \
.orderBy(col("房源数量").desc()).limit(10)
# 将分析结果写回MySQL供前端可视化调用
city_analysis.write.jdbc(
url="jdbc:mysql://localhost:3306/rental_db",
table="city_statistics",
mode="overwrite",
properties={"user": "root", "password": "password"}
)
price_distribution.write.jdbc(
url="jdbc:mysql://localhost:3306/rental_db",
table="price_distribution",
mode="overwrite",
properties={"user": "root", "password": "password"}
)
源码项目、定制开发、文档报告、PPT、代码答疑
希望和大家多多交流 ↓↓↓↓↓

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 17
17 0
0- 0



 已为社区贡献72条内容
已为社区贡献72条内容

所有评论(0)