多层神经网络概述
上篇文章提到,一个神经元只能画出直线,无法直接“画圈”圈出三角形。
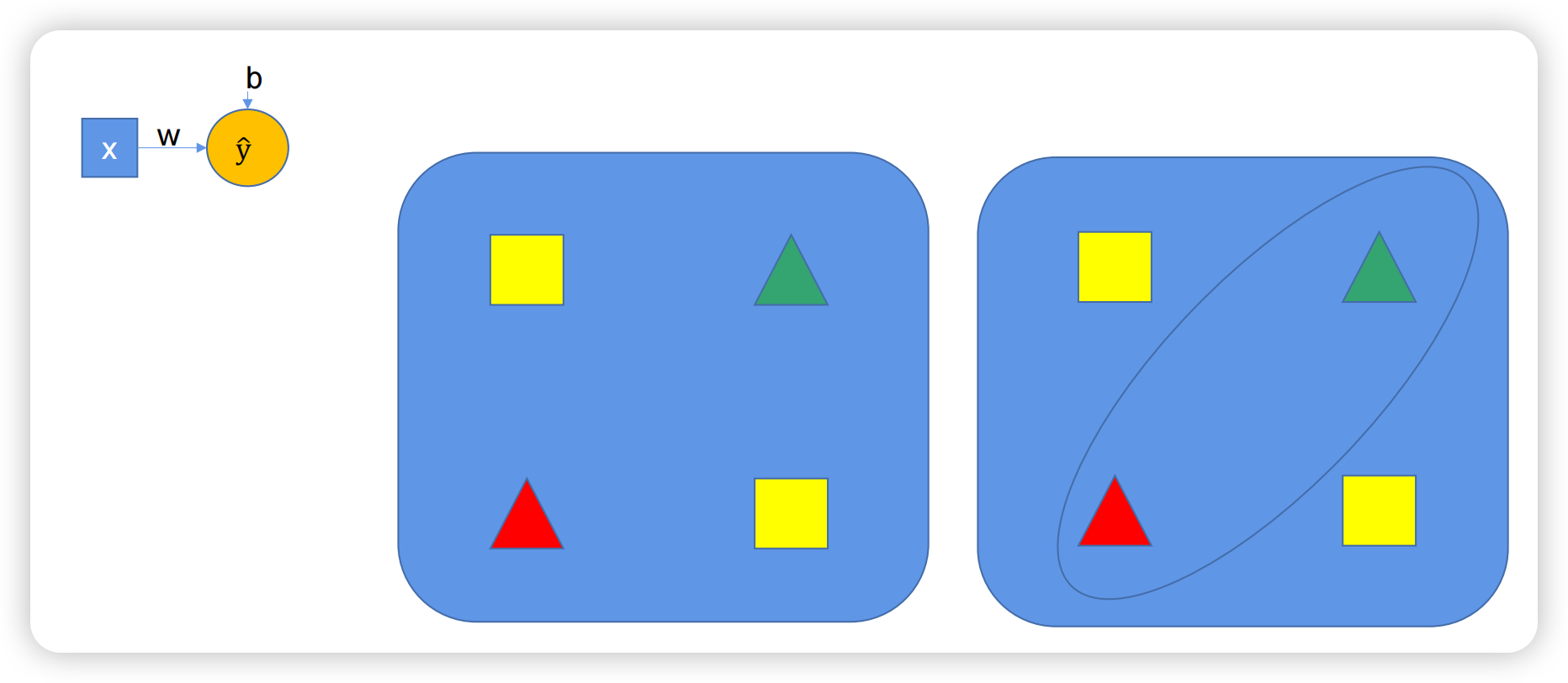
完成该任务需要更复杂的神经网络,叠加更多神经元。
引言:人类大脑神经与神经元
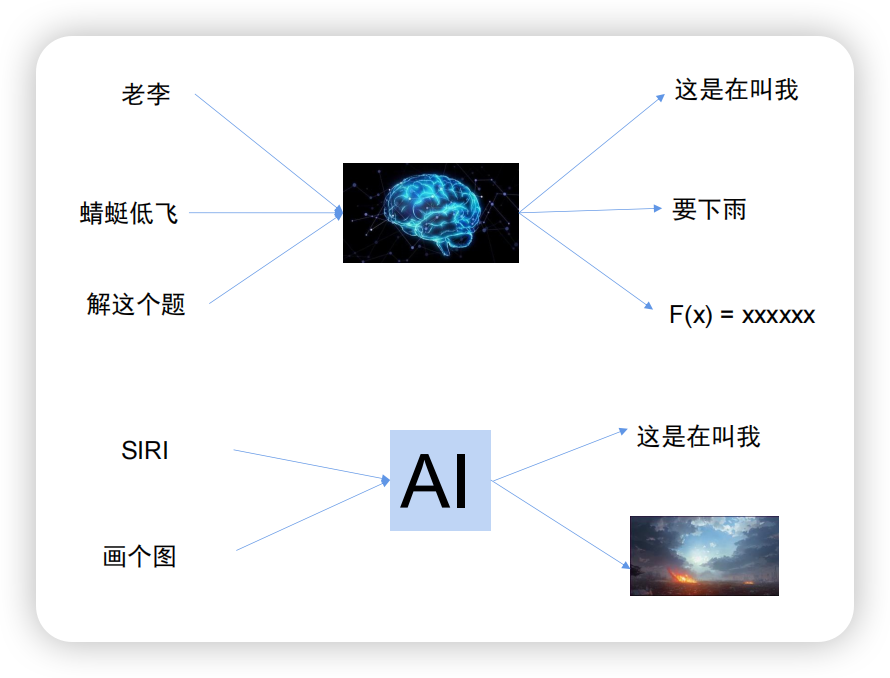
深度学习一开始时又称为人工神经网络,模仿的是人类的大脑。喊一声“老李”,老李的大脑就知道这是在叫他;而喊一声“Siri”,AI就知道你是在叫她,如下图所示,一层神经网络。
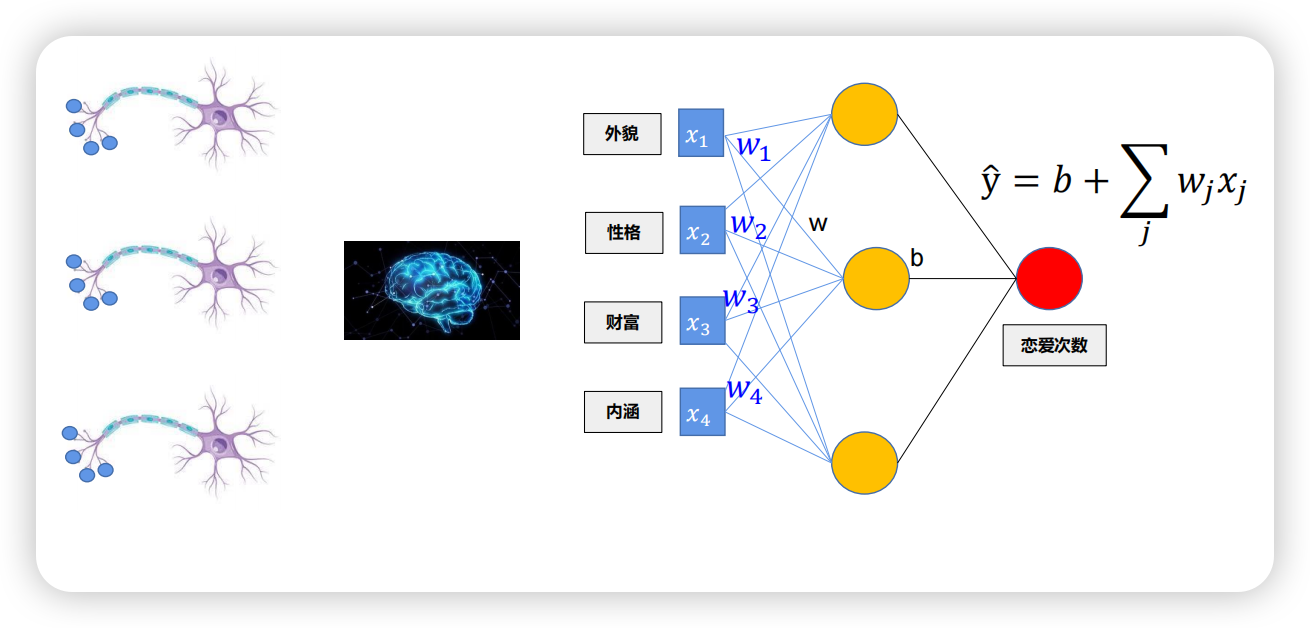
下面举一个人工神经元的例子:根据“外貌”、“性格”、“财富”、“内涵”四项判断一个大学生在校期间能谈多少次恋爱,叠加的四个神经元共同作出判断,神经网络加宽又加深(一个神经元变为三个、一层神经元变为两层)。
神经元与矩阵
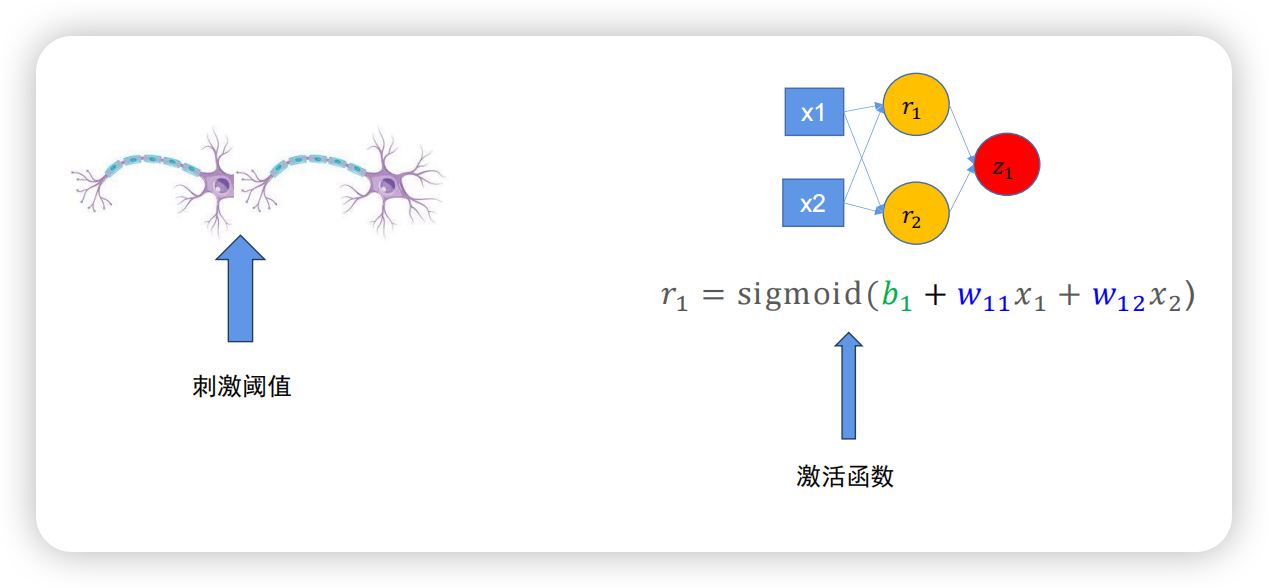
实际上,叠加的神经元能够用矩阵的方式来表示,如下图所示,表示r1的公式能够被线性表示。
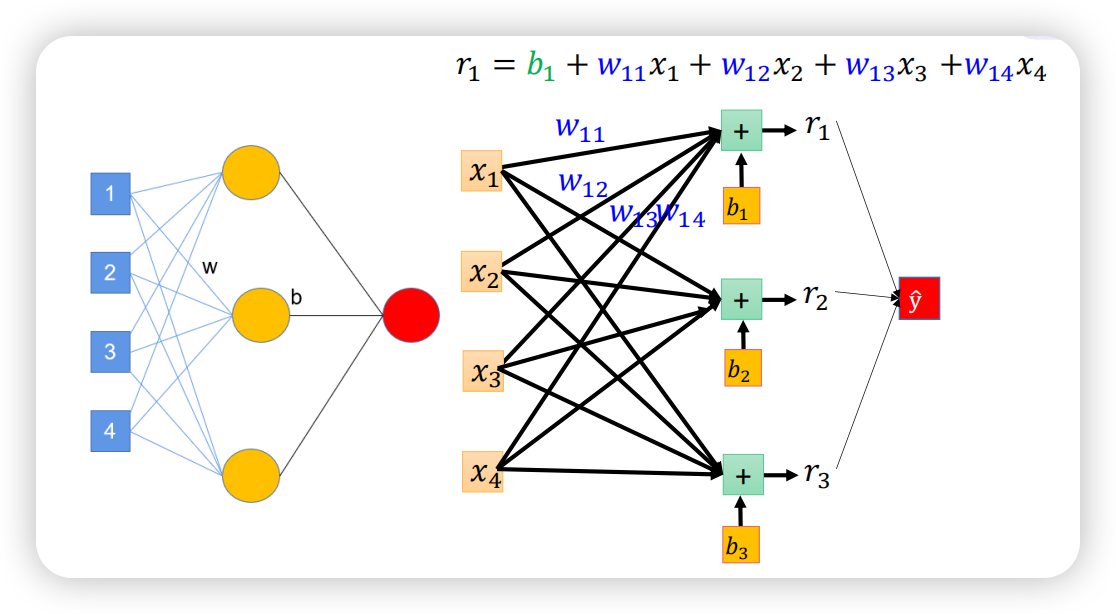
同理得到r2、r3的公式;三组公式可以写成矩阵形式,下图右侧复杂的神经元连接其实就是一个矩阵运算,如下图左下方所示。
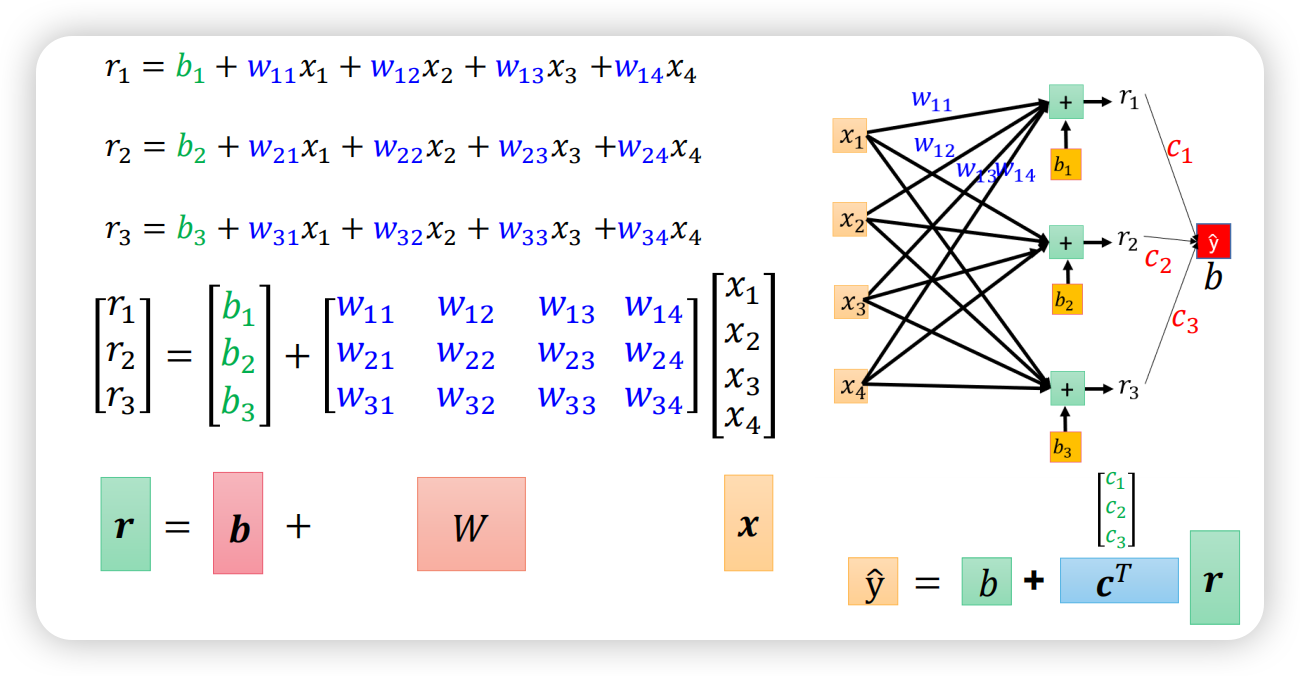 神经元的串联
神经元的串联
人的神经元可以不止一条地串在一起加深链路长度,人工神经元也可以这样加深。
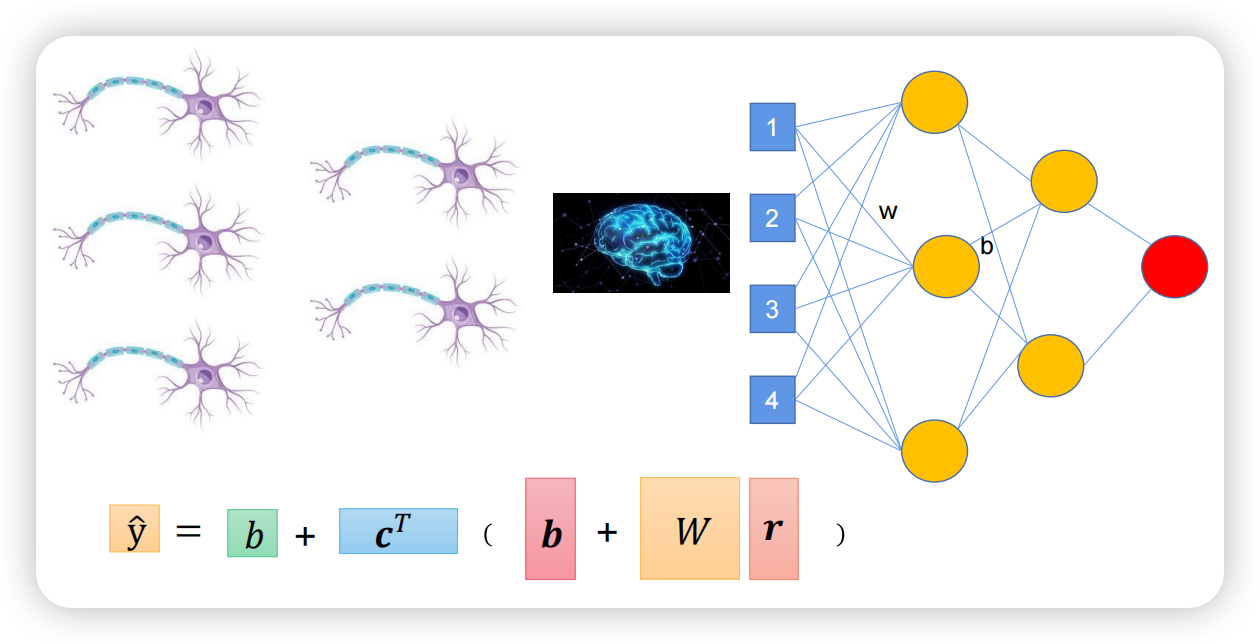
刚刚提到的复杂的两层神经网络就是这样加深的,但串联的神经元如果只有传递的作用,那么一根或者多根似乎没有区别。简单的数学证明如下所示:
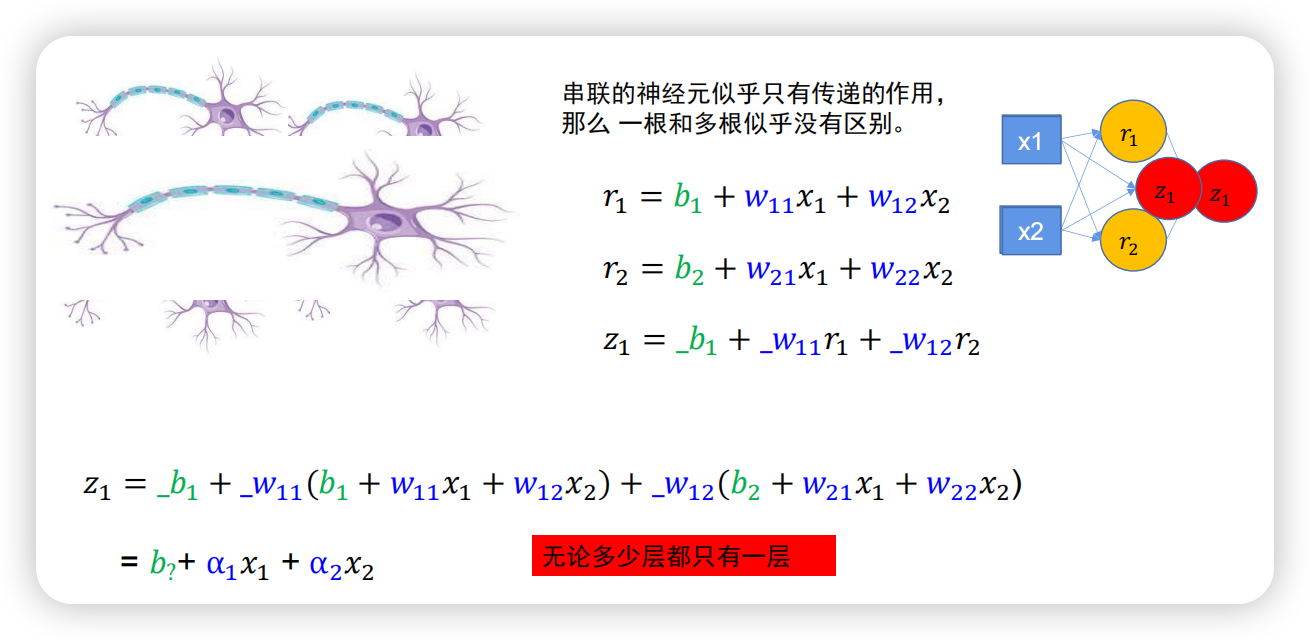
可以看到,串联的神经元最终表示为一个单层神经元的公式,而因为其中的参数可以学习变化,这与一层的神经网络没有什么区别, 加深层数并不能“画圈”(仍为线性函数)。
再次联系人的大脑特征可以解决这个问题:人的大脑的神经元有自己的决定权,受到的刺激超过“阈值”才会产生神经冲动:人来到有榴莲的环境会觉得臭,因为受到了“刺激”;待了一会不认为臭,因为神经元调整了这种“刺激”。
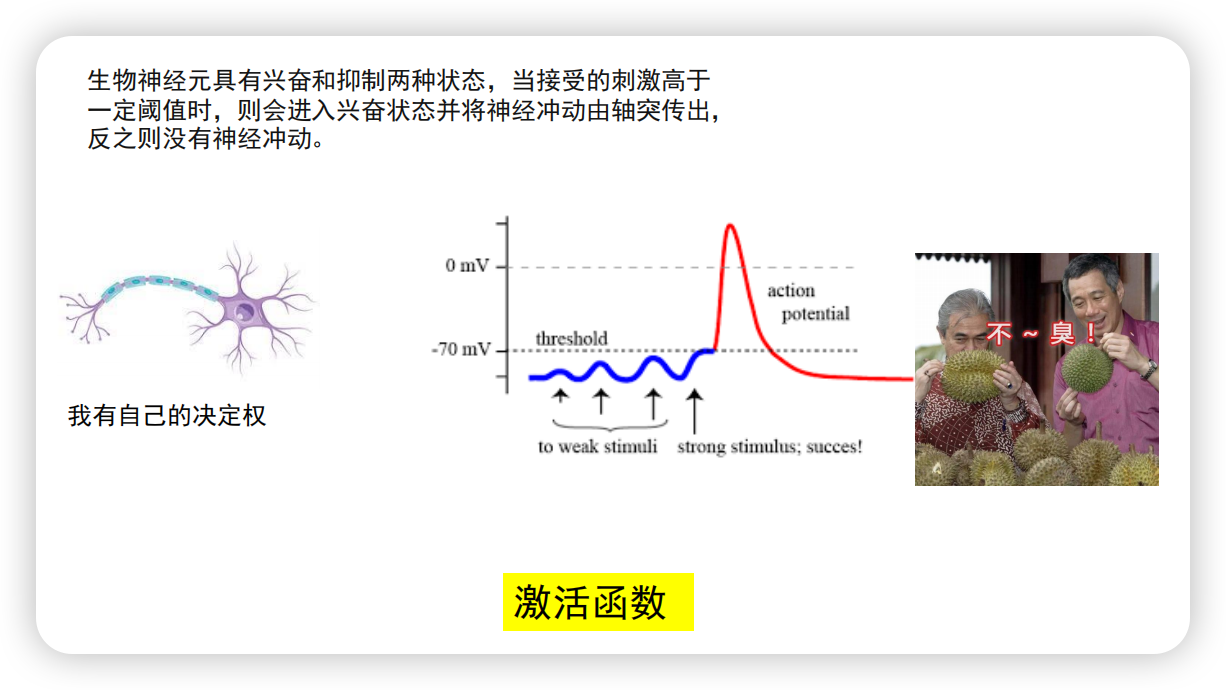
而对于人工神经网络来说,这个刺激“阈值”便是激活函数(例如sigmoid函数)。
神经网络中的激活函数
激活函数和非线性因素
激活函数让神经元引入了非线性特质,使得神经网络可以逼近任何非线性函数,此时线性组合的神经元能够完成非线性任务(如“画圈任务”),能够应用到更多非线性模型中。
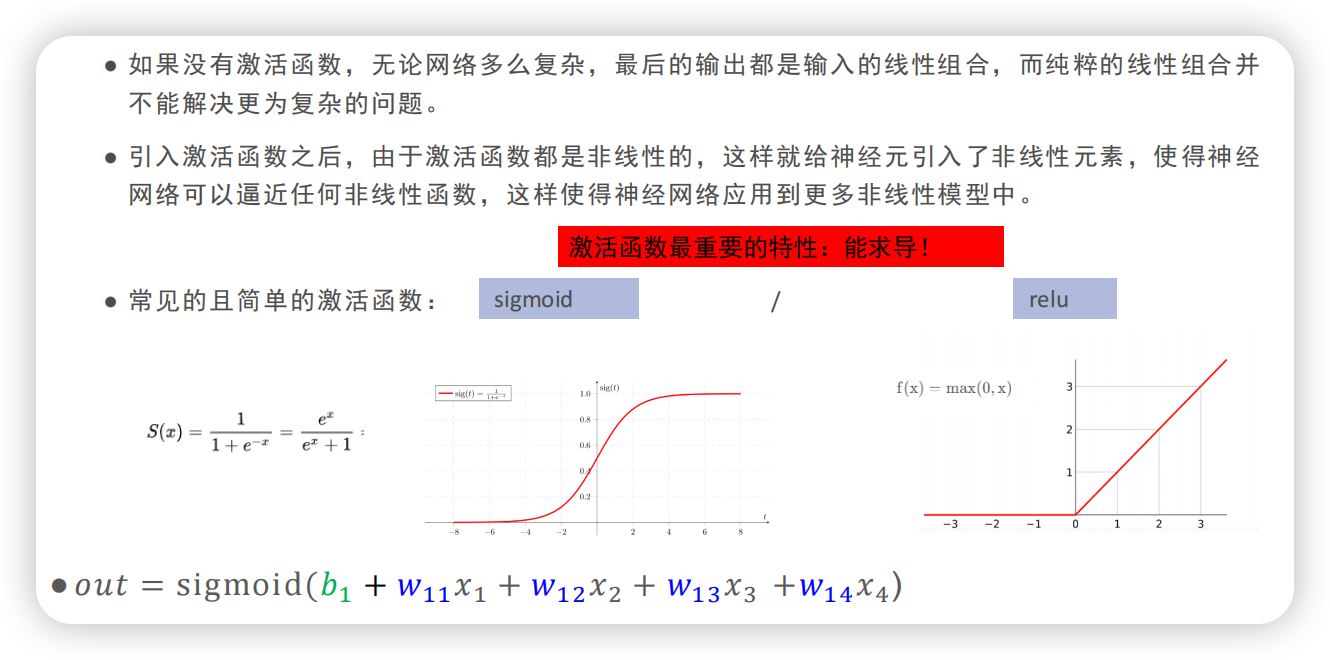
sigmoid和relu是常见的两个简单激活函数。relu是分段函数,但也能实现“画圈”,因为大于0的部分是那个部分本身,只要有一点点微小的变化就会转向,无数个转向最终成圆。激活函数最重要的特性是能够求导,原因后面会解释。
激活函数的位置
那么激活函数到底加在哪里?加在每一层的节点上,如下图所示。
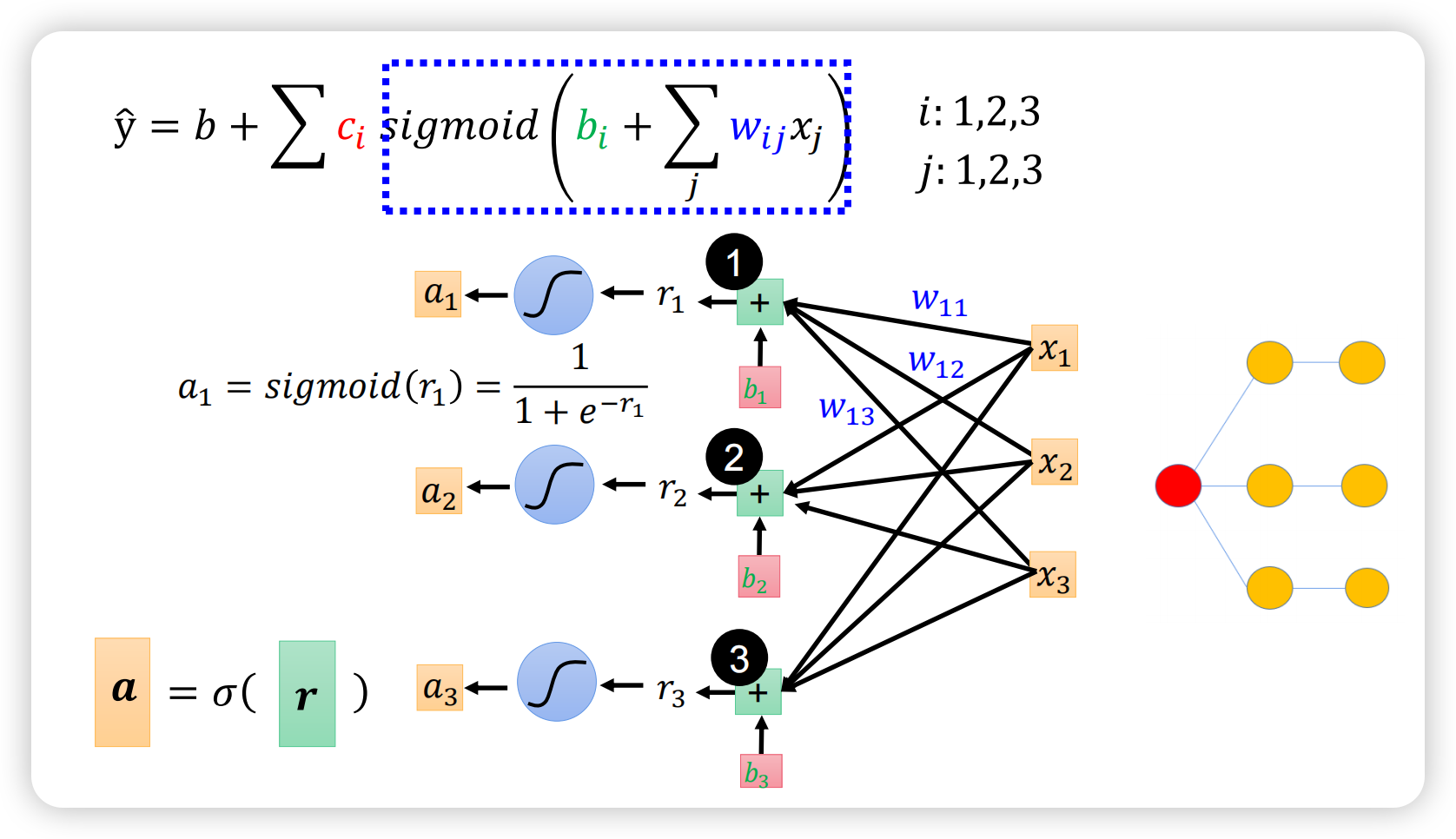
左下角为矩阵表示,σ是激活函数。
激活函数的效果:神经网络模拟函数
不管神经网络有多少神经元多少层,没有激活函数只能画出直线。但加入一个激活函数sigmoid后变得稍微贴合,加入两个sigmoid激活函数后已经十分贴合:
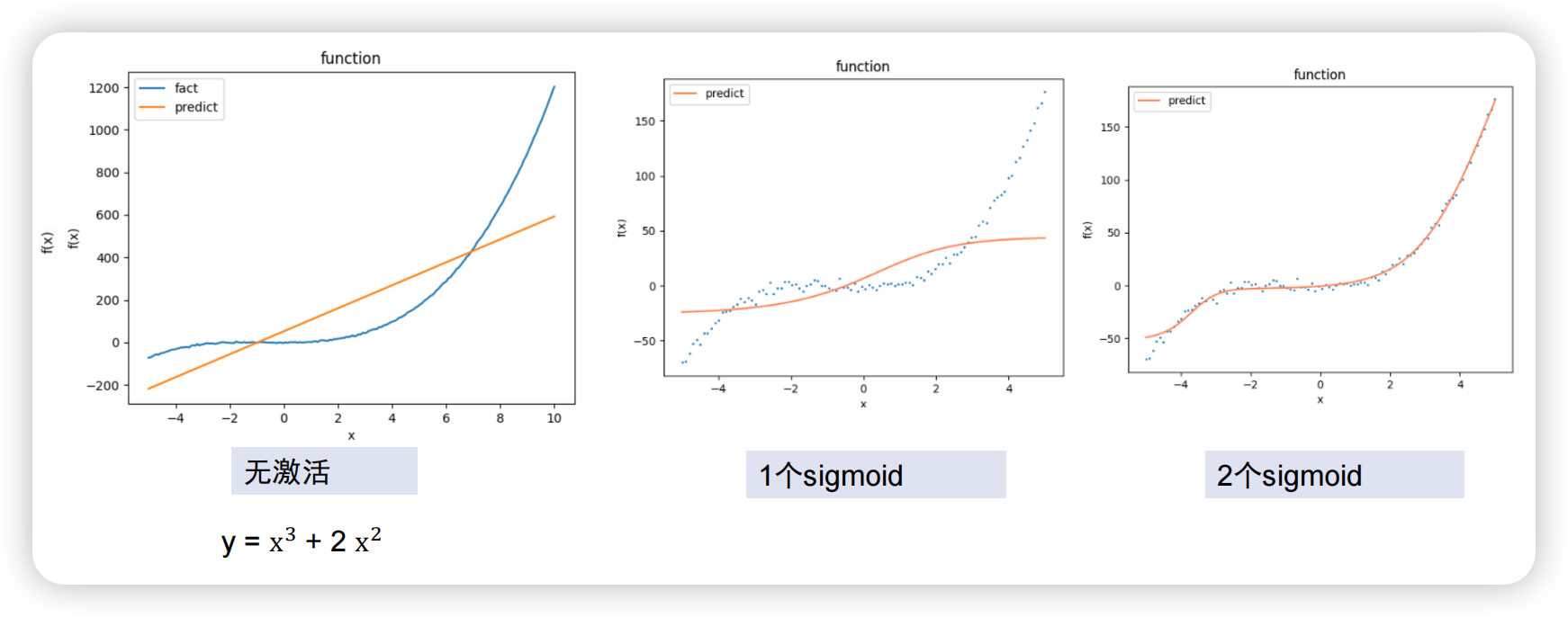
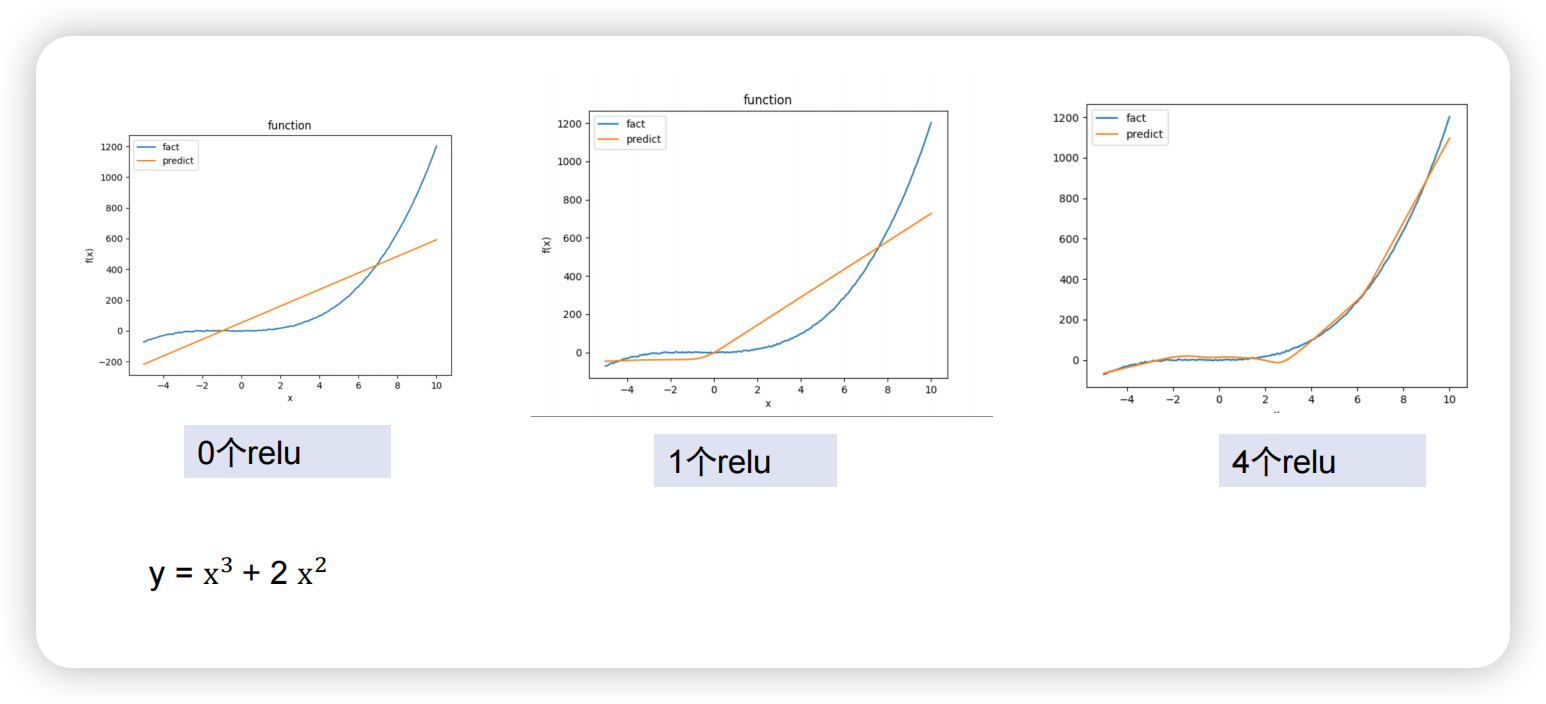
relu同理,加入后模拟效果更好:
另一个角度理解拟合和激活函数
两个线性函数无法模拟分段函数,因为是两条直线,但加入激活函数relu后直线能够拐弯,如图左侧蓝色曲线所示,两条蓝色曲线叠加正好是红色曲线,模拟出了分段函数。
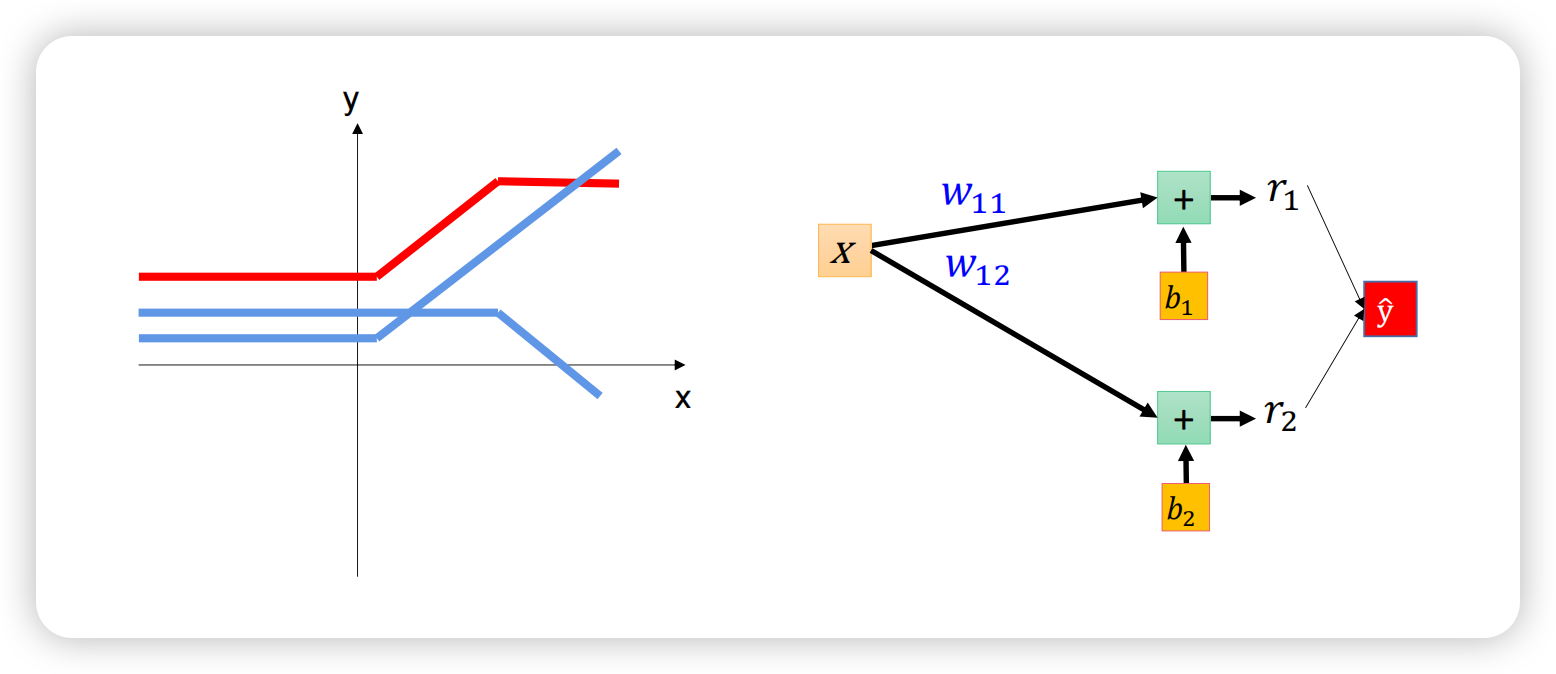
模型整体结构
加入激活函数后模型的整体结构如下所示。
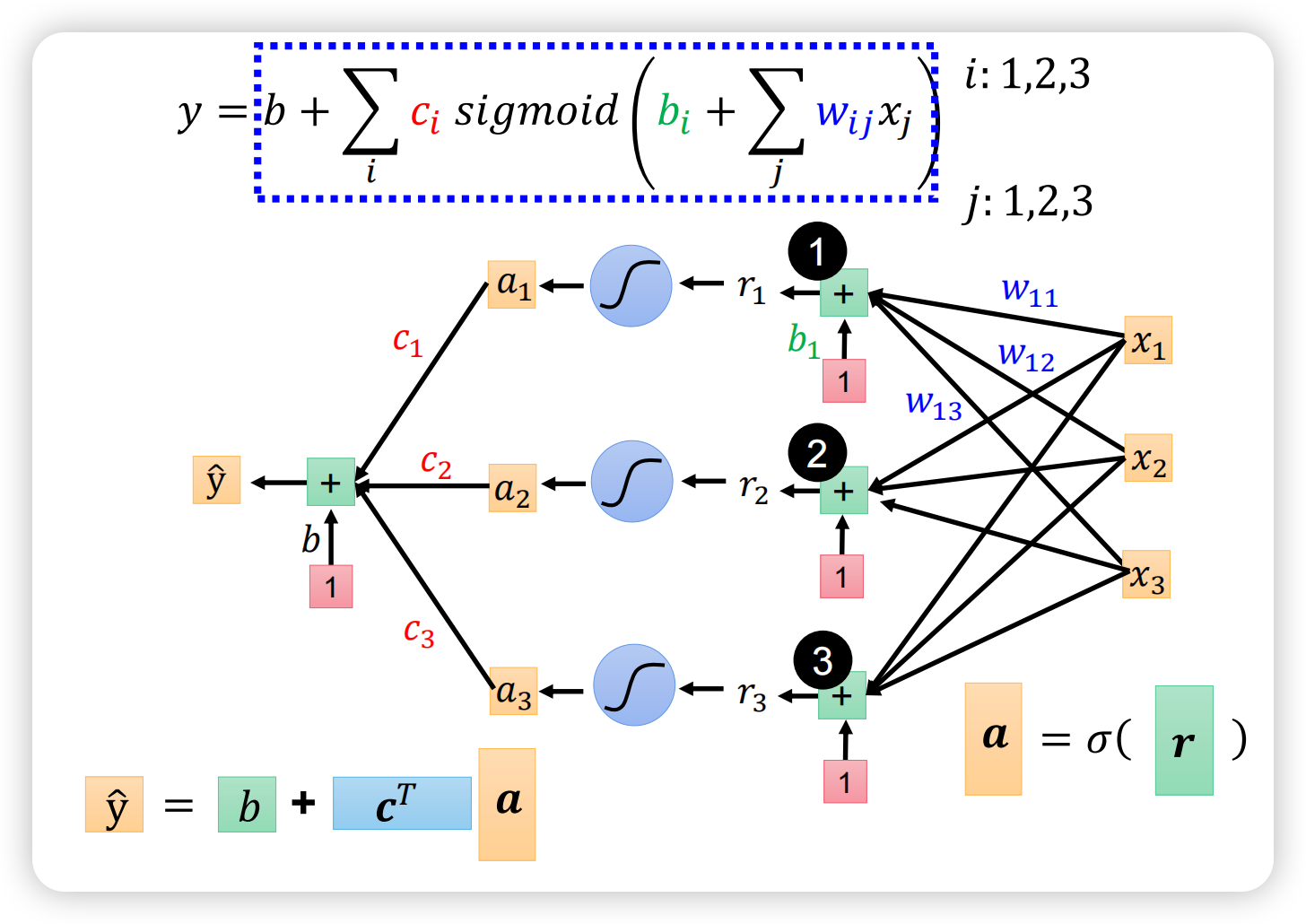
实际上,下图中的三个部分表示的是同一个东西,互相对应,背后就是矩阵运算;图中右侧的部分一共有16个参数:3*3+3+3+1,学会计算参数量十分重要。
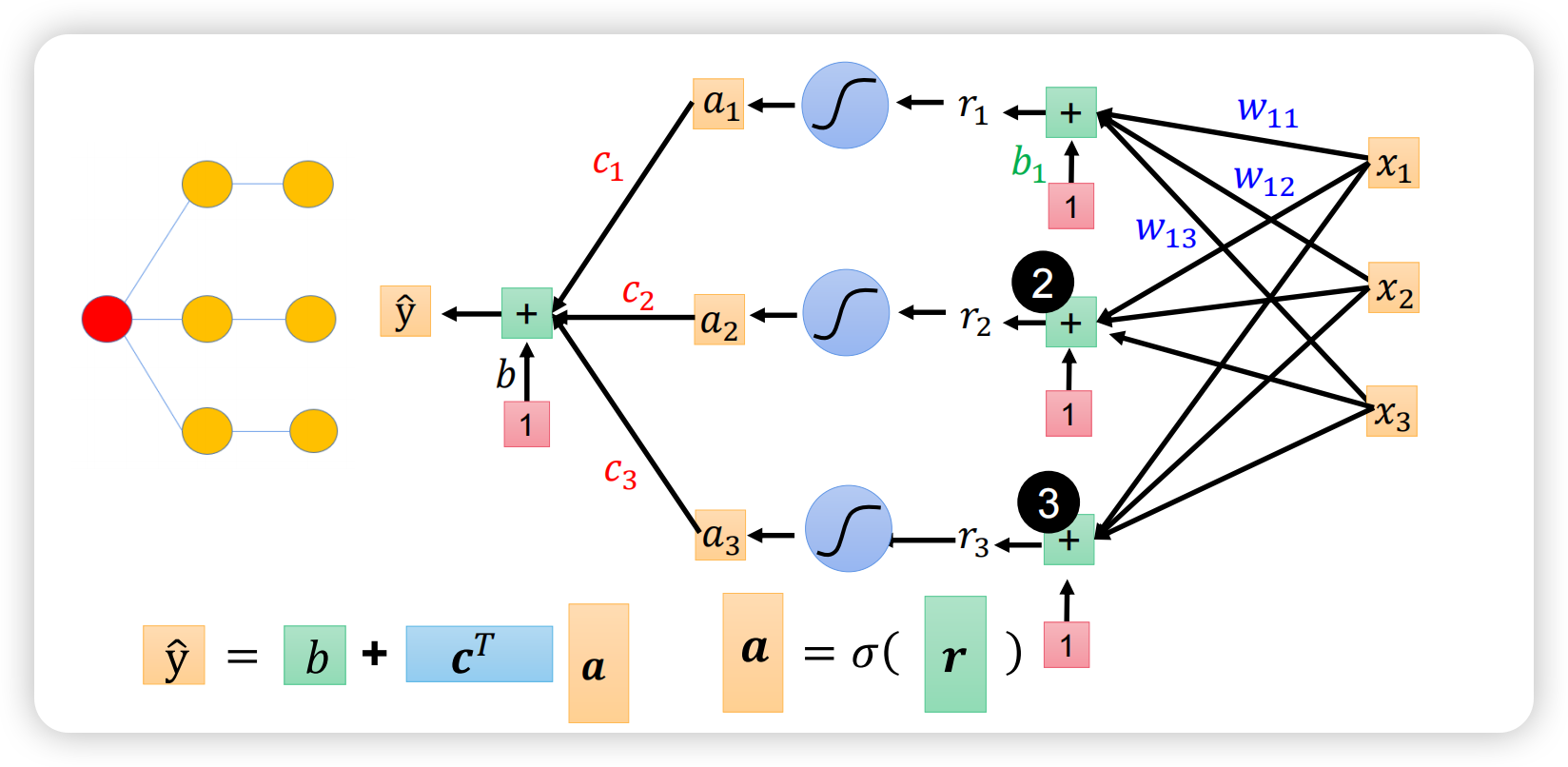
通过这样一个矩阵运算就实现了从 X 到 Y 的映射,x是feature,其他乱七八糟的W、b等是需要训练的未知参数,统称为θ,可用矩阵表示。所谓万亿参数大模型中的“参数”就是指θ。
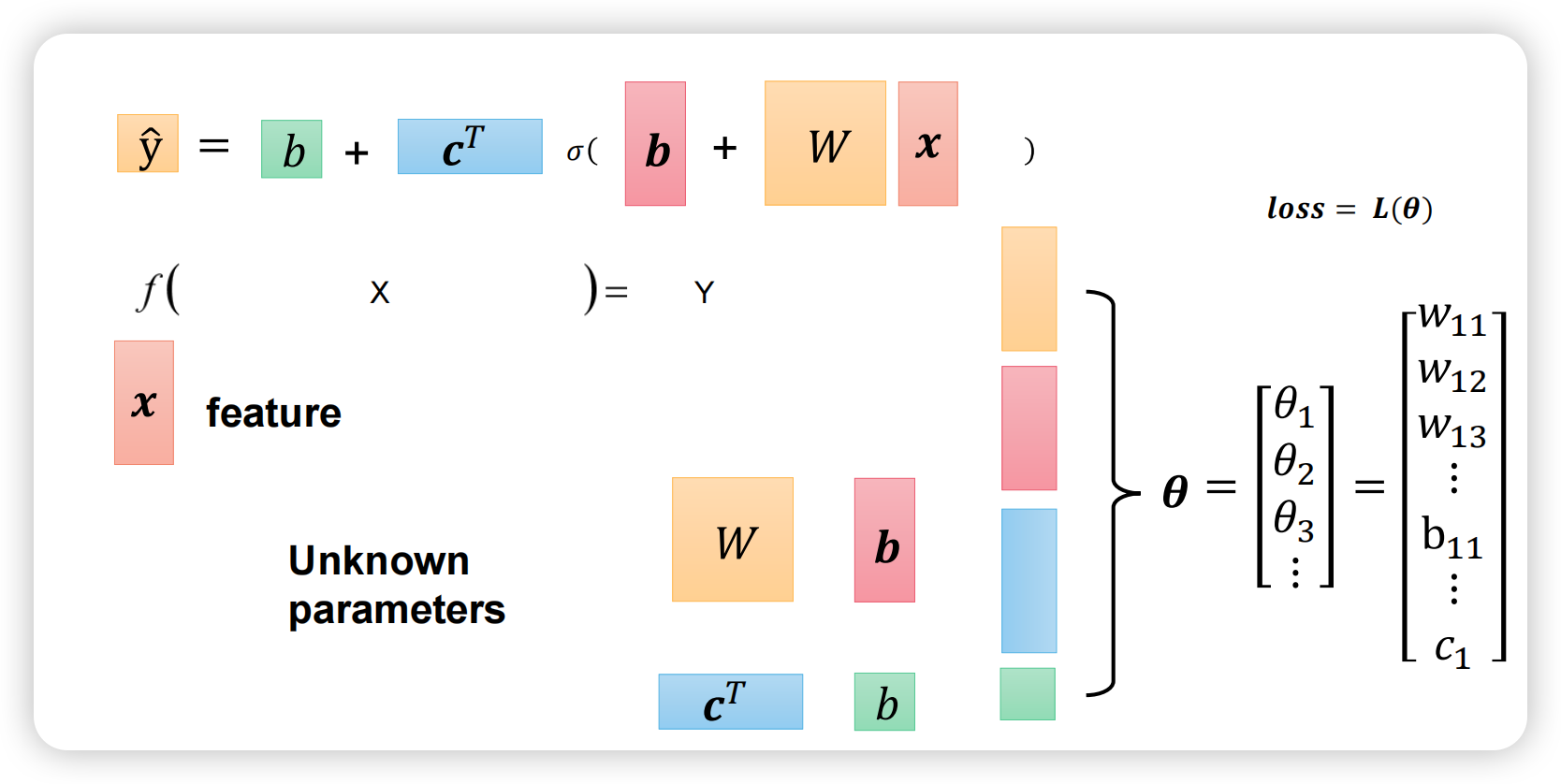
神经网络的参数
如何优化神经网络的参数?与上一篇文章提到的一样:先用X1、X2、X3、X4运算得到输出Y,即:前向过程;再与真实值(Label)求loss;求出loss后求偏导:往回求导,称为梯度回传。
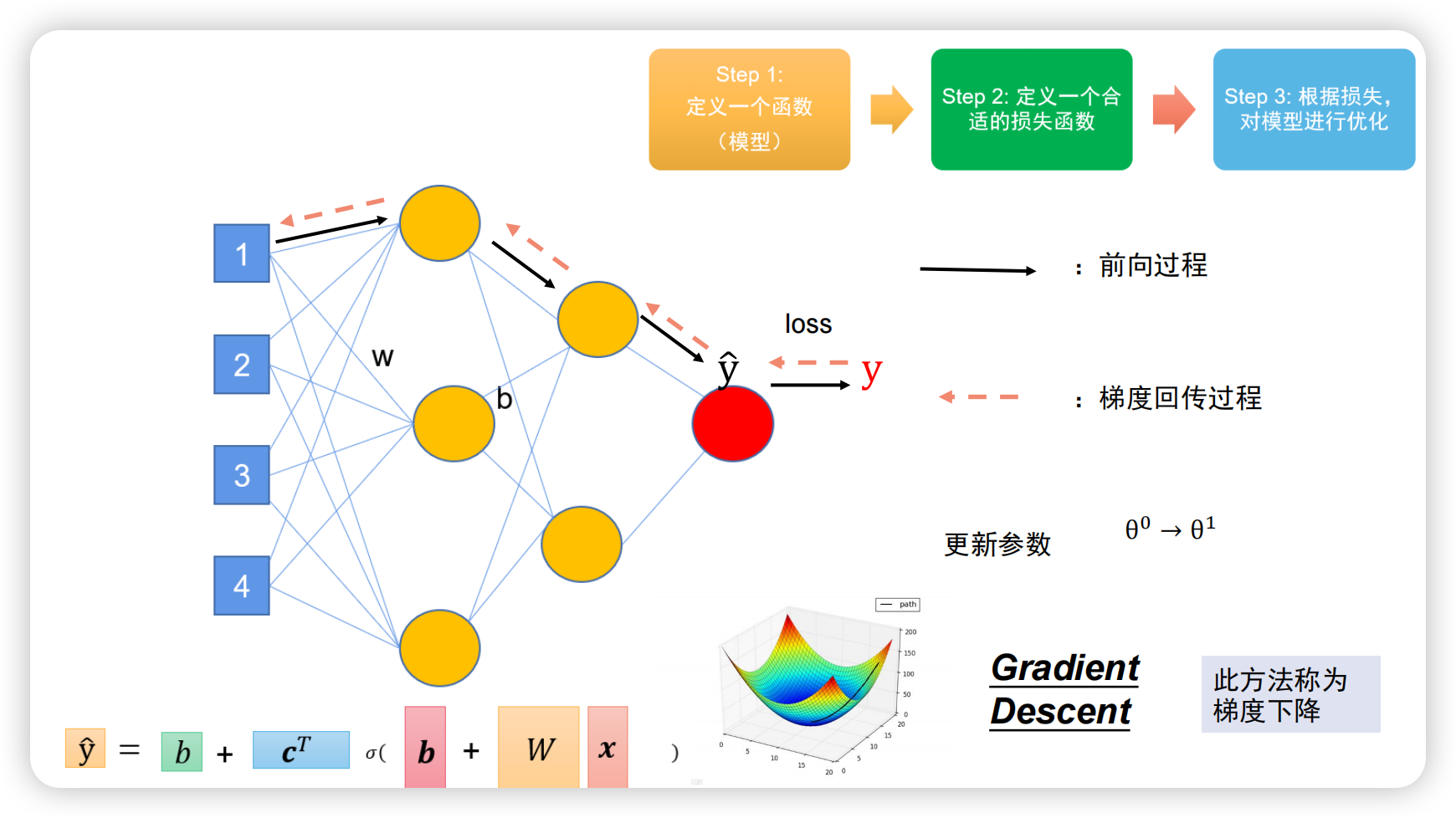
有了每个参数的导数后就可以用上一篇文章提到的“梯度下降”方法优化参数。
之前提到激活函数最重要的特性是能够求导,原因是梯度回传时要保证能往回求导;激活函数relu在 x = 0 处不可导,因此有各种改进版本,大家感兴趣可以去了解,但其本身已经十分好用。
事情不会那么简单
下图是上一篇文章提到的“梯度下降”优化方法,看上去十分简单。
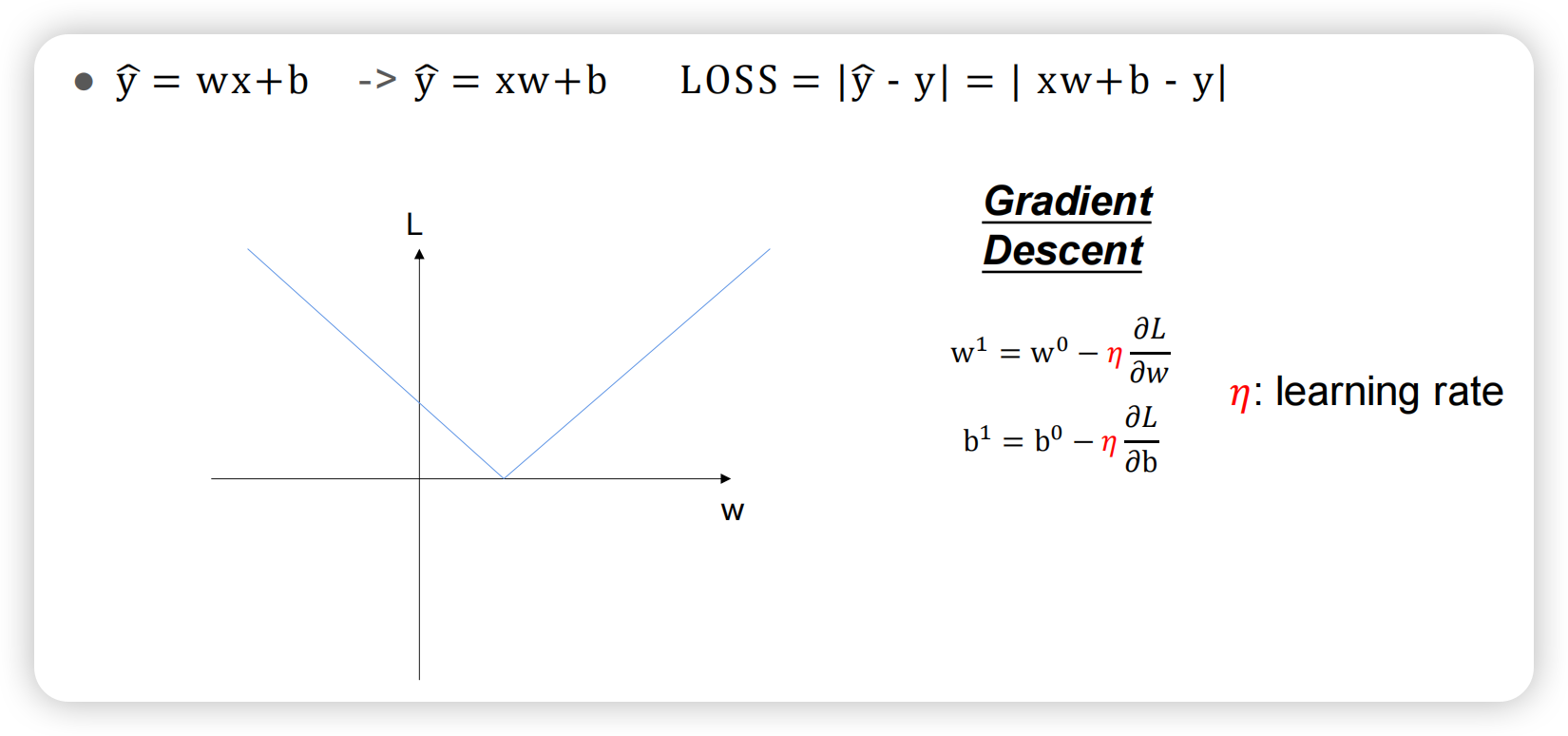
但一旦神经元的数量变多、神经网络变宽变深,loss函数就变得复杂,基本无法通过解析解得到最小值,如下图所示;只能一步步试探最优解。
此时模型如何优化呢?一样的方法,还是对loss求偏导。用链式法则求loss对w的偏导,得到导数后直接更新模型。
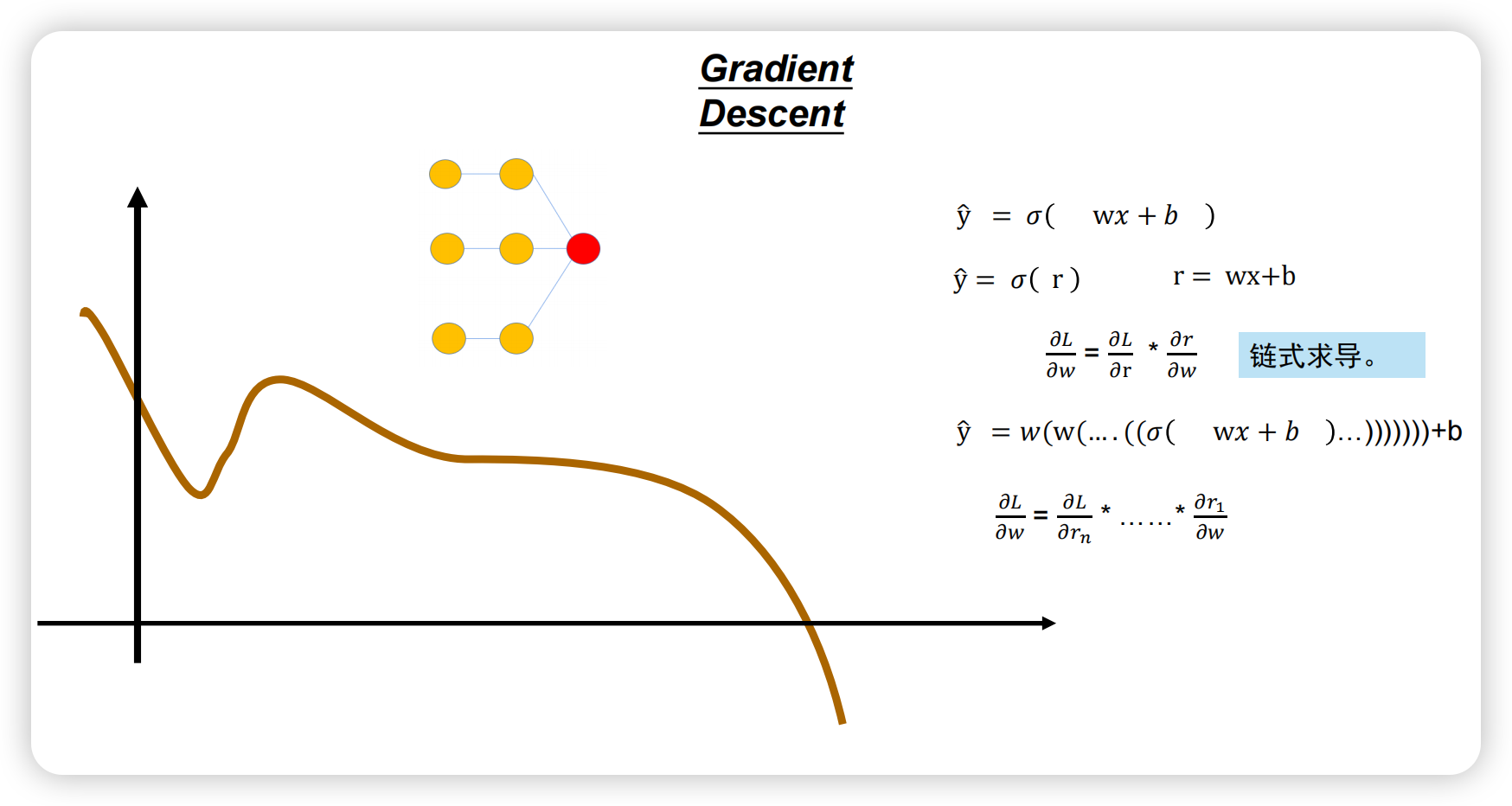
如果模型非常复杂非常深, 一样通过链式法则在初始点求偏导,得到偏导后用梯度下降更新模型参数即可。
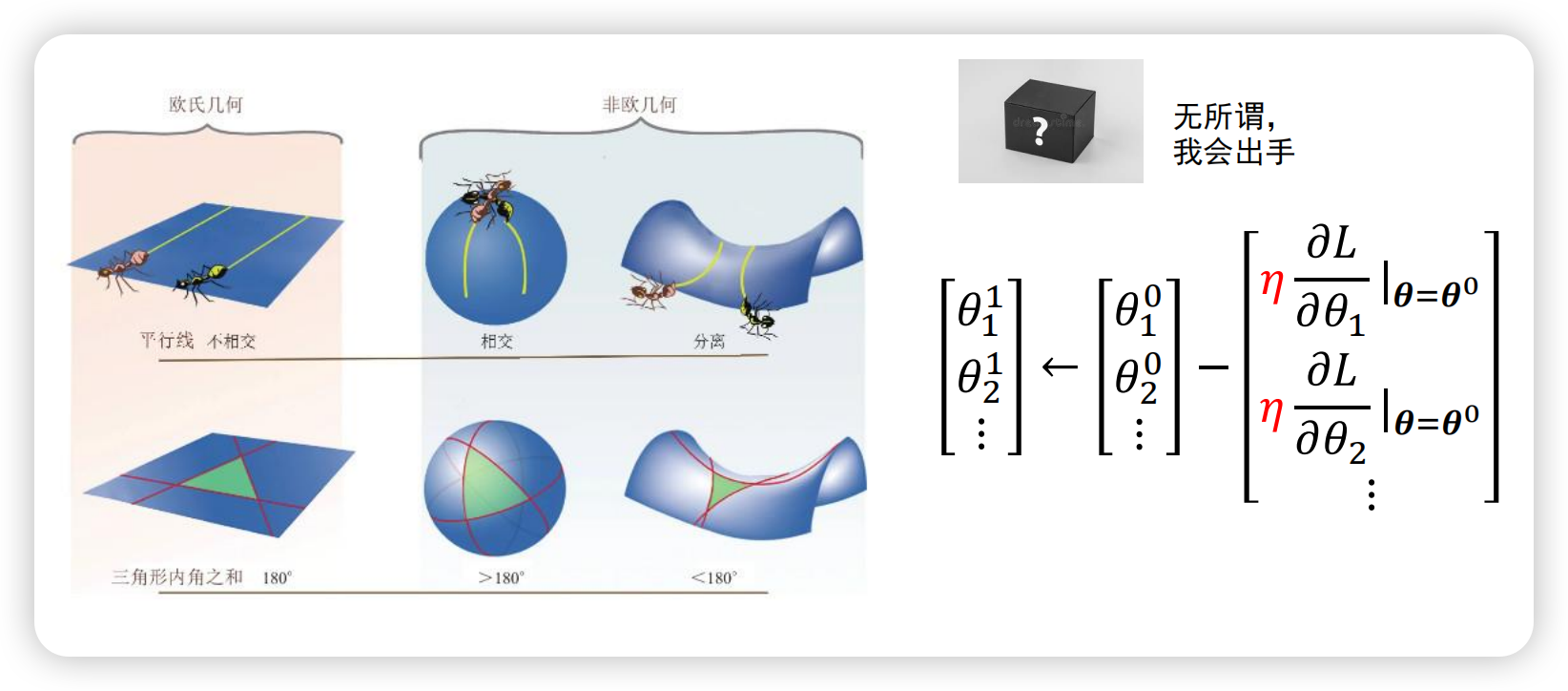
即使是非欧氏几何空间的loss曲线也没关系,求偏导即可,得到导数更新模型即可。
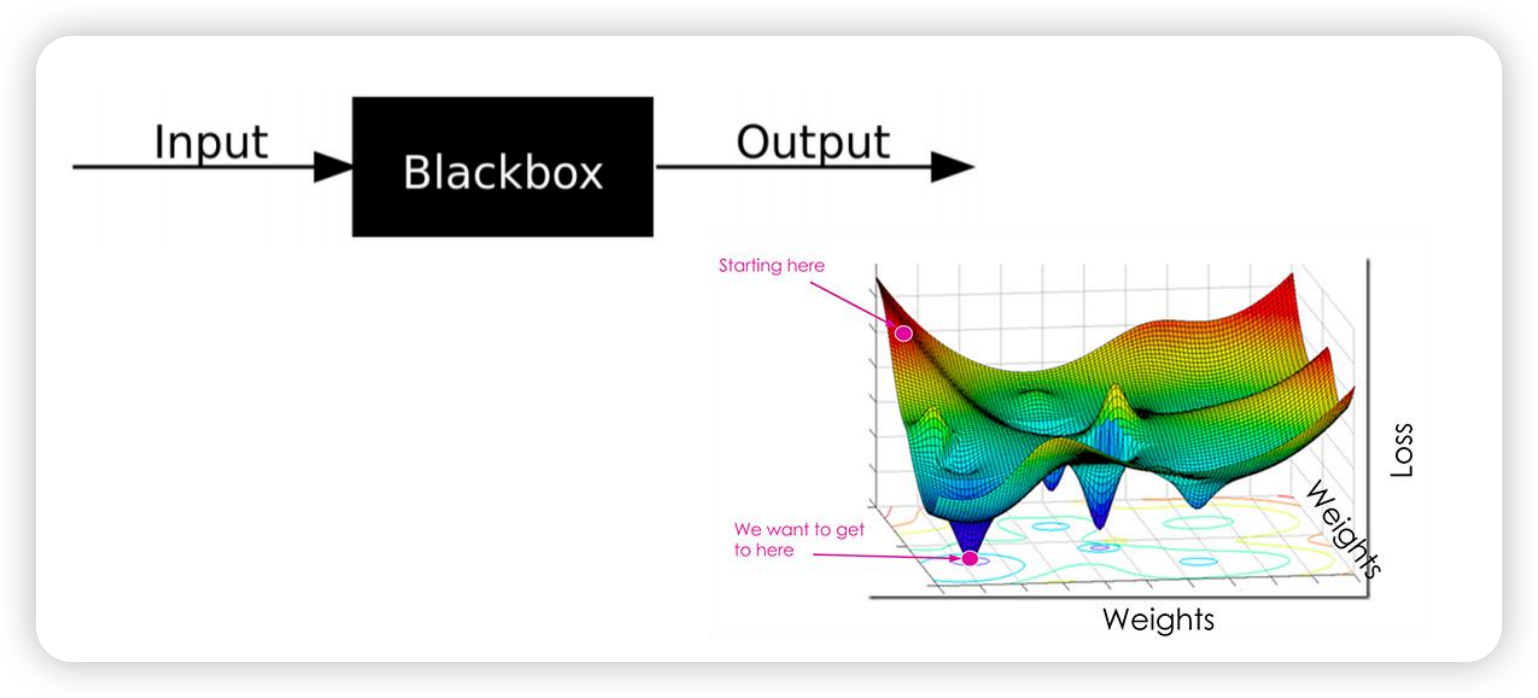
只需要从输入得到输出,中间的过程没有人知道,是一个“黑匣子”,但这没有关系,结果好即可。
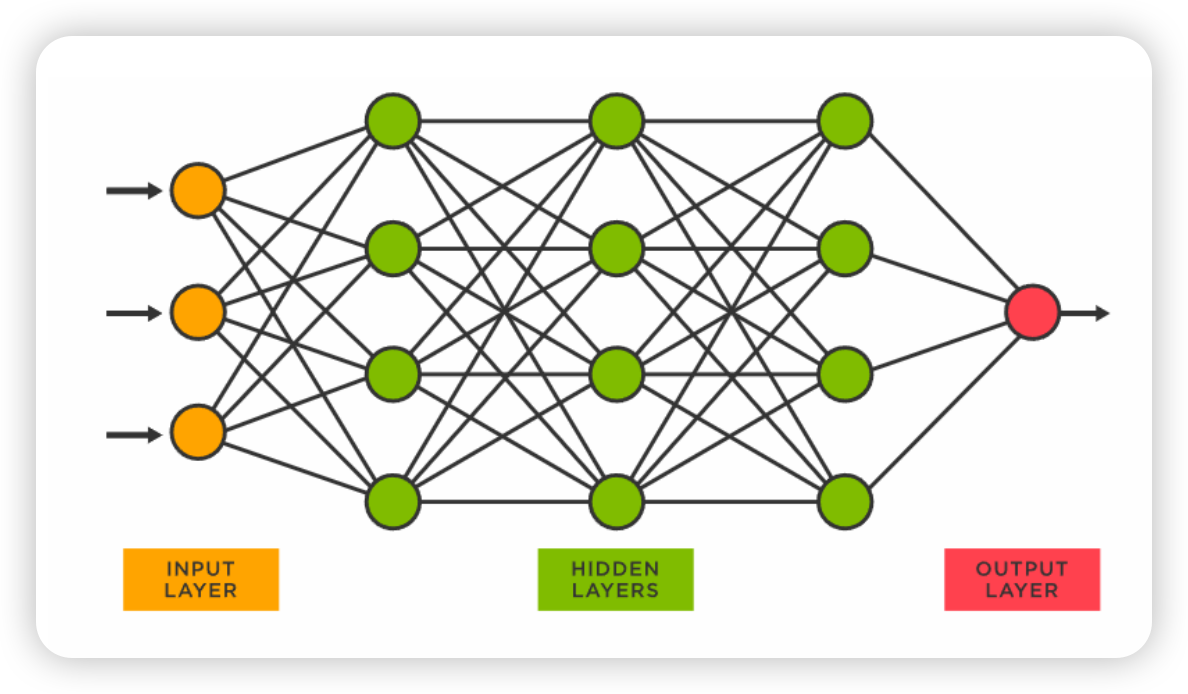
Fully Connected Network
讲一下名词,刚刚我们讲的神经网络叫“全连接神经网络”,如下图所示,每个部分和下一层都有连接。
黄色圈圈为神经元(Neuron),用来连接的线上的权重称为weight,神经元上的的偏置称为bias。
图中的网络称为“人工神经网络”,这个名字上世纪七八十年代已经出现,也称为“多层感知机”,就是今天的“深度学习”。
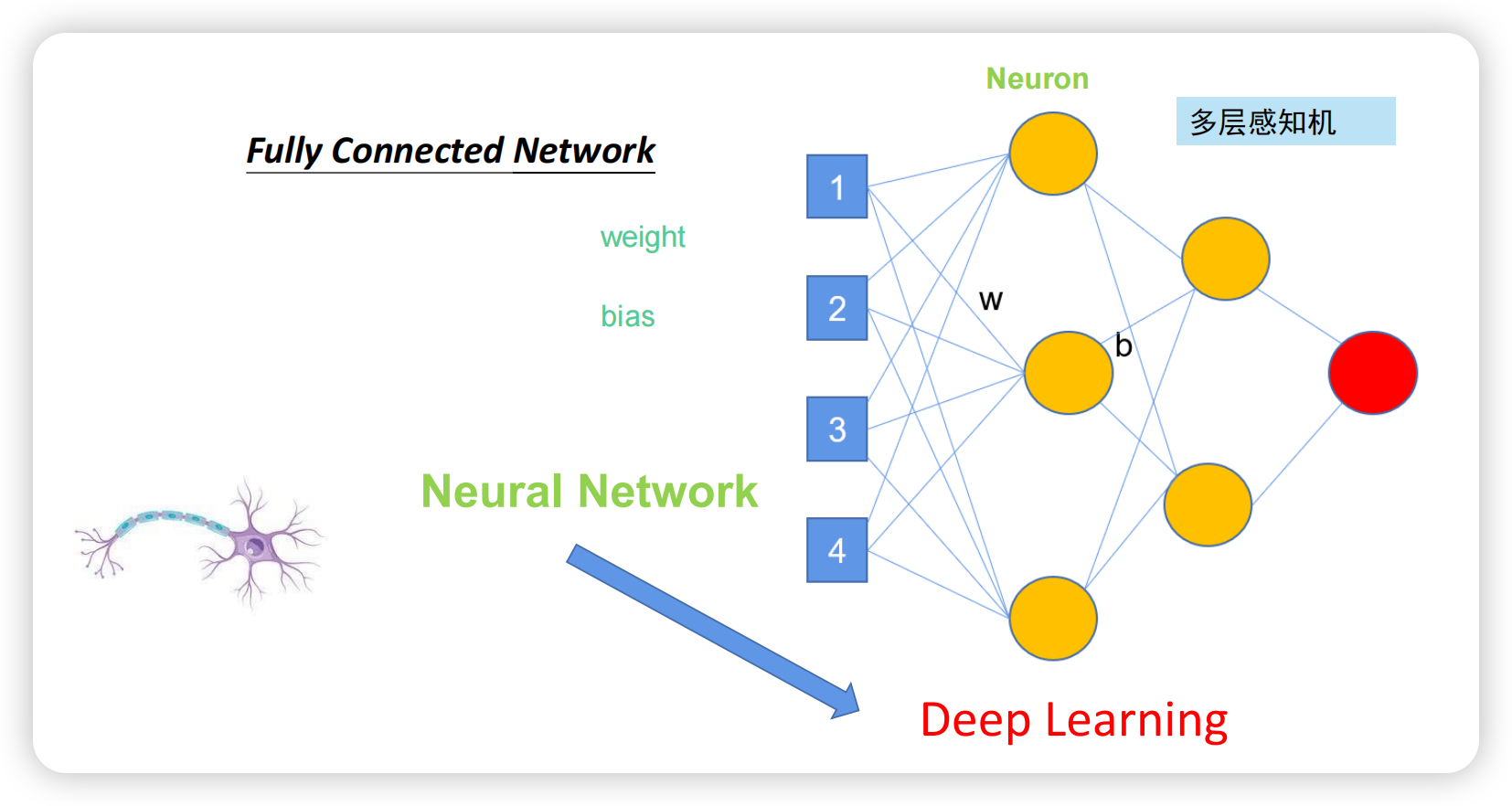
深度学习有多深?
从2012的AlexNet出现,深度学习开始火起来,该模型8层,错误率16.4%。到了2014年的VGG,深度为19层,7.3%的错误率;谷歌的GoogleNet有22层,错误率6.7%。
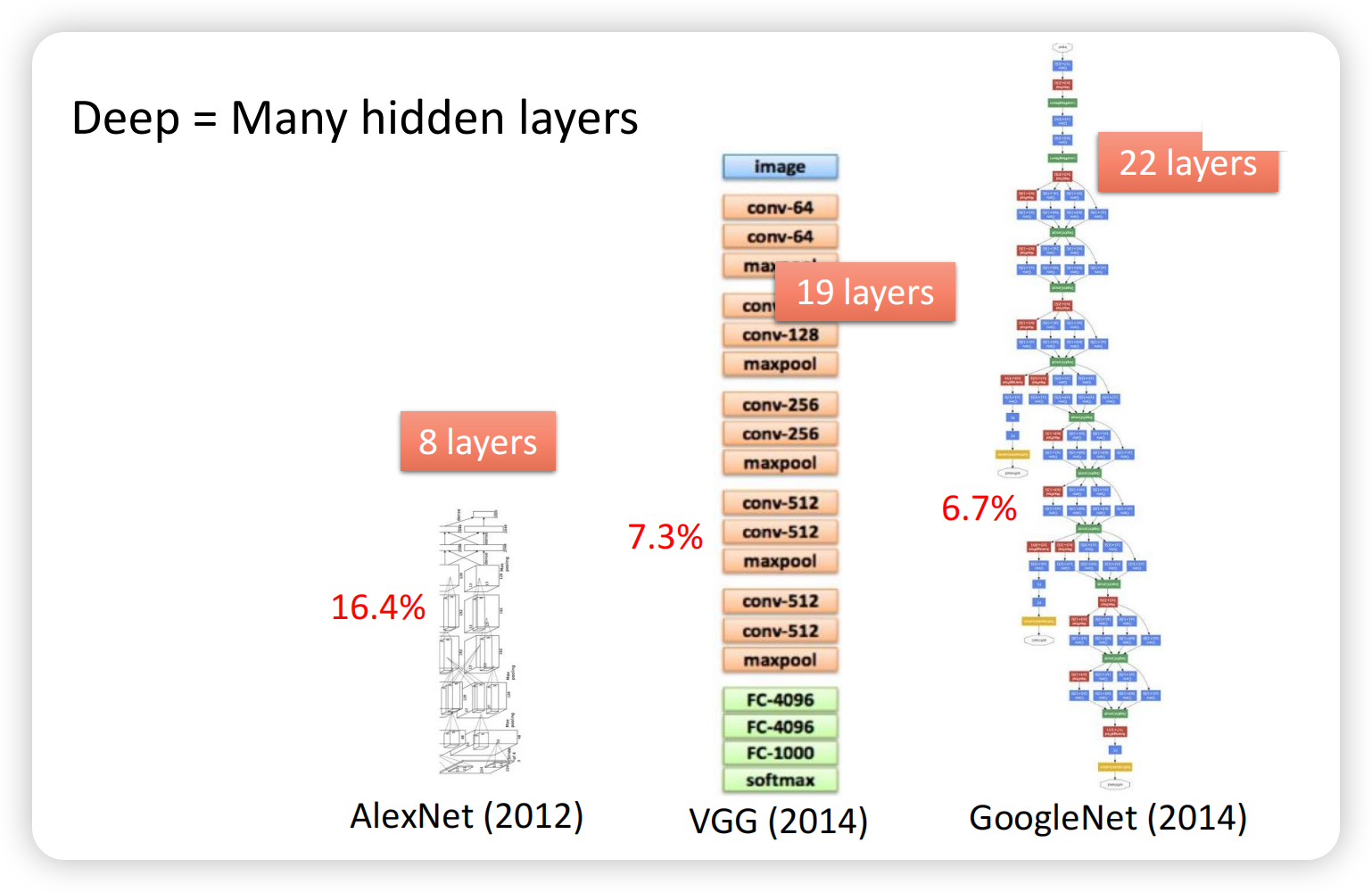
到了2015年的Residual Net,能够达到152层甚至上千层,秘诀是“残差连接”;Residual Net比成都绿地中心还要高,哈哈哈。
联系python代码
举一个数学公式的例子:用python拟合函数,对比无激活函数relu和有激活函数relu的情况。
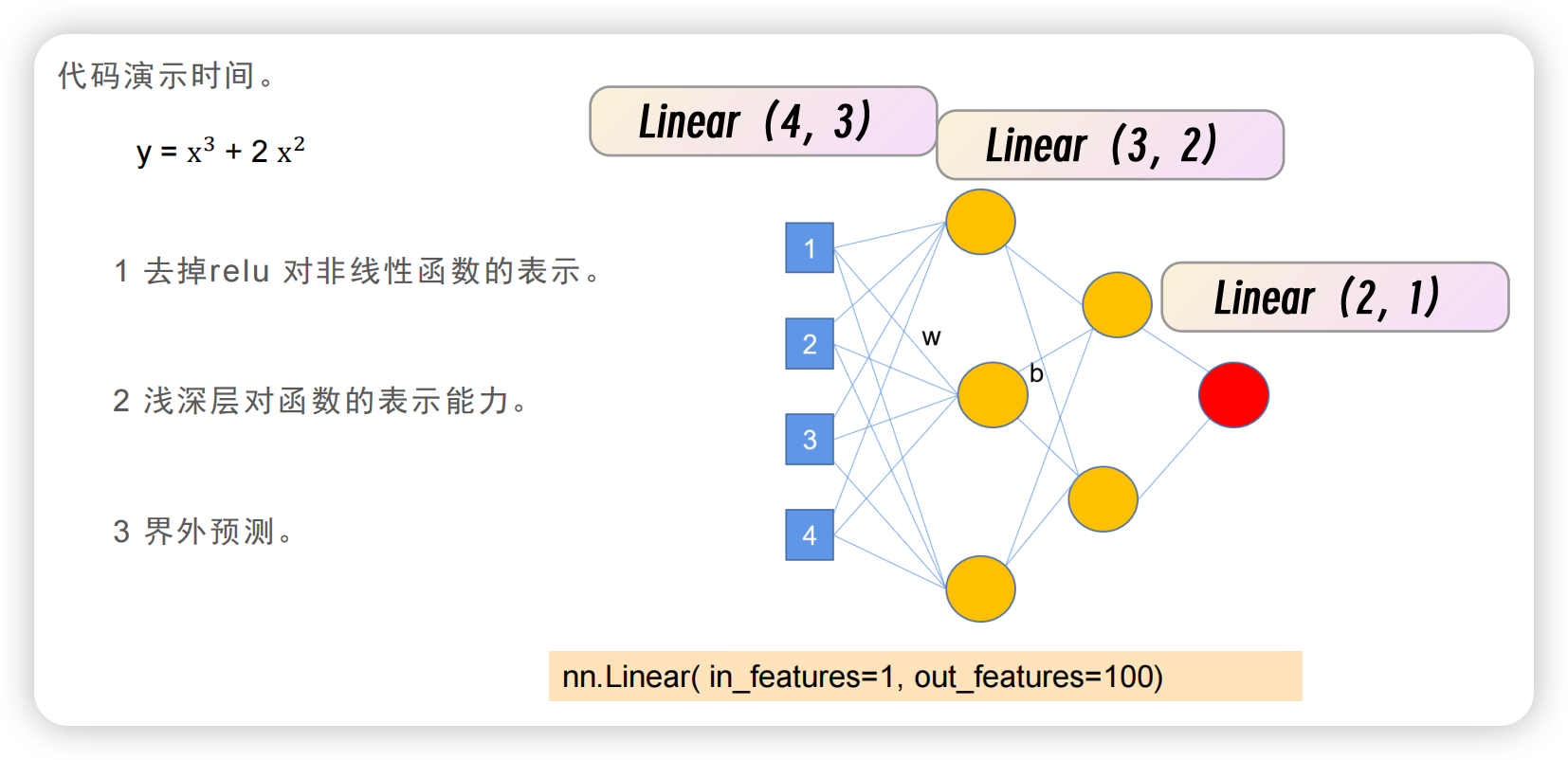
去掉relu对非线性函数的表示
无激活函数relu时:
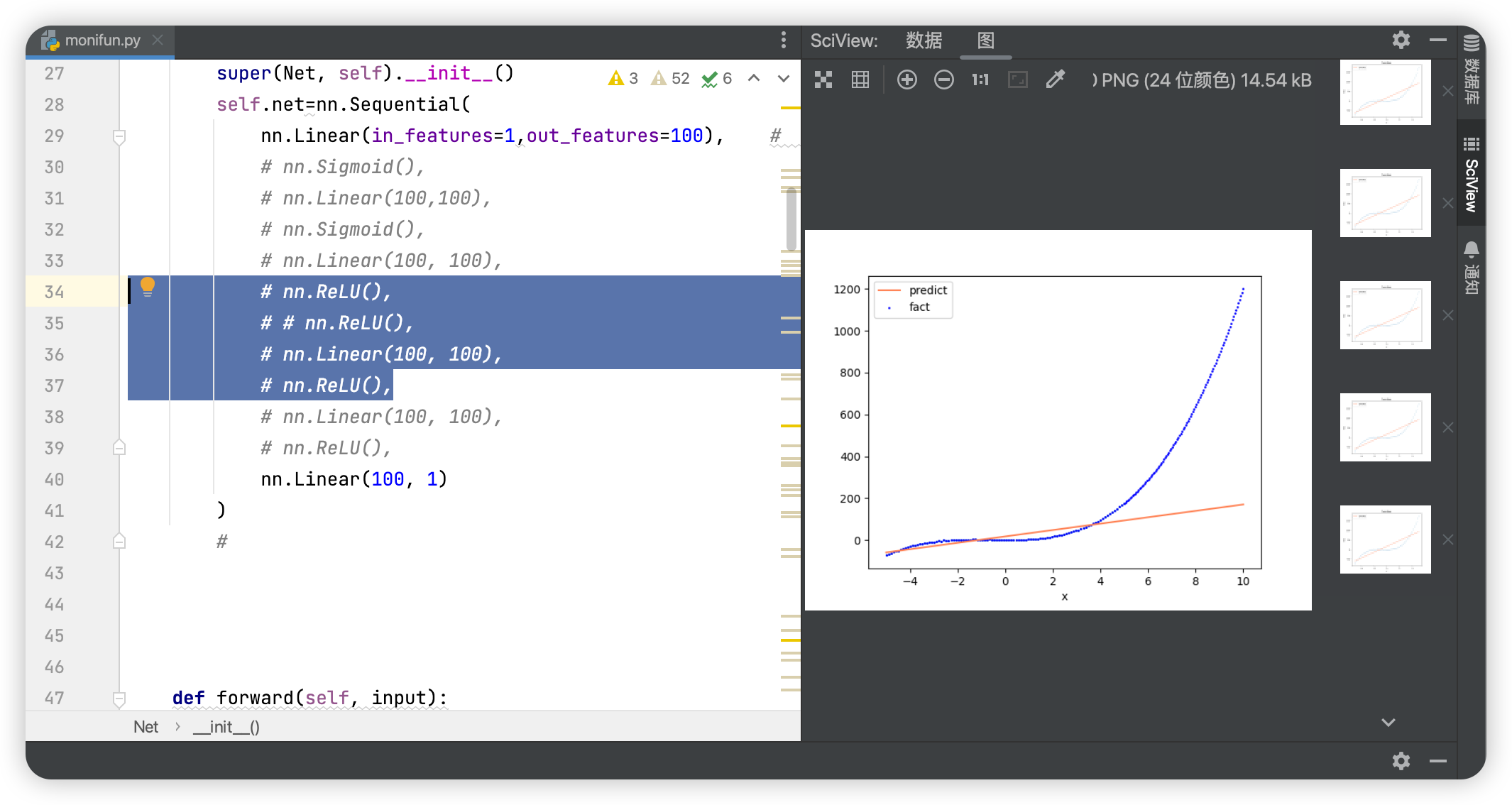
(完整代码在文章末尾的链接)
加上激活函数后:
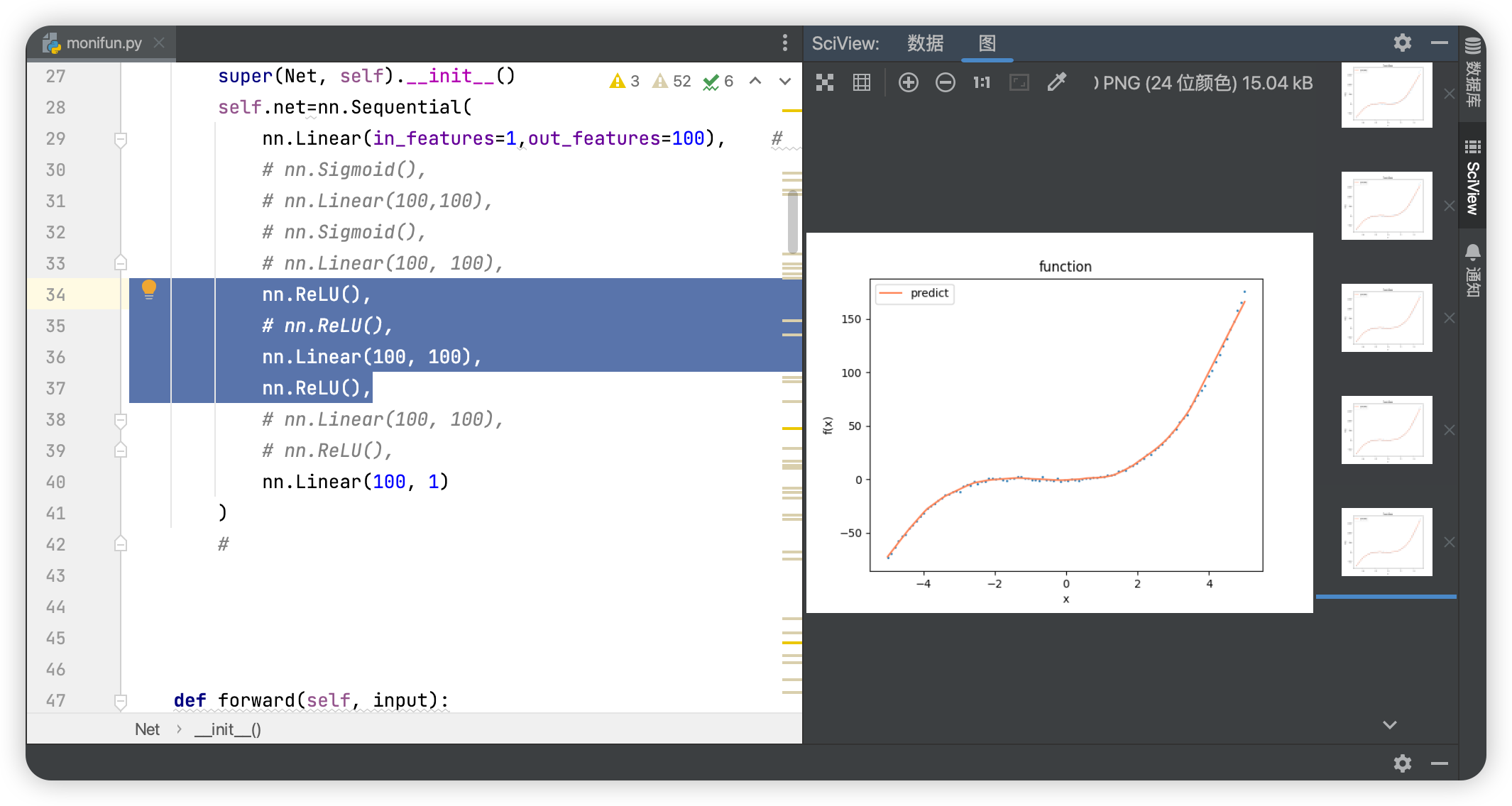
(完整代码在文章末尾的链接)
深浅层对函数的表示能力
简单提一下,是一个关于层数的特点:层数浅的时候可能不够拟合,与数据不太贴合;层数深时可能很多褶皱,不够光滑。
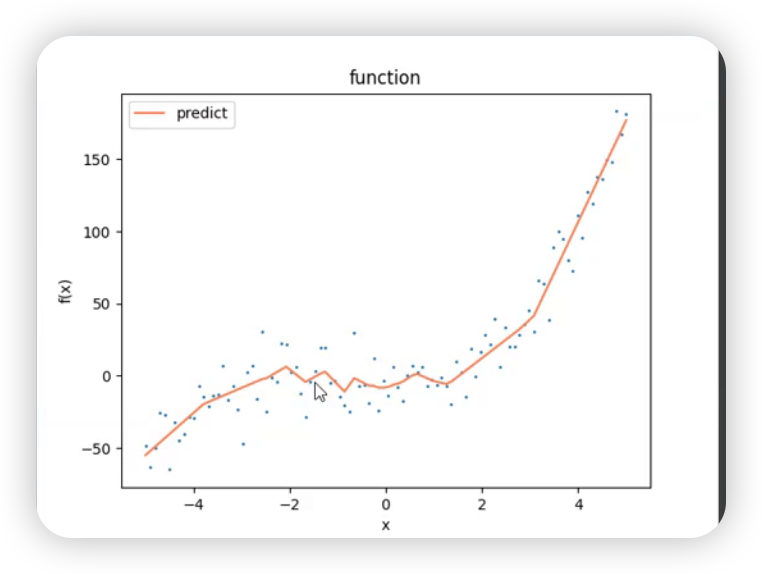
界外预测
根据数据拟合函数曲线并预测数据范围外的结果:
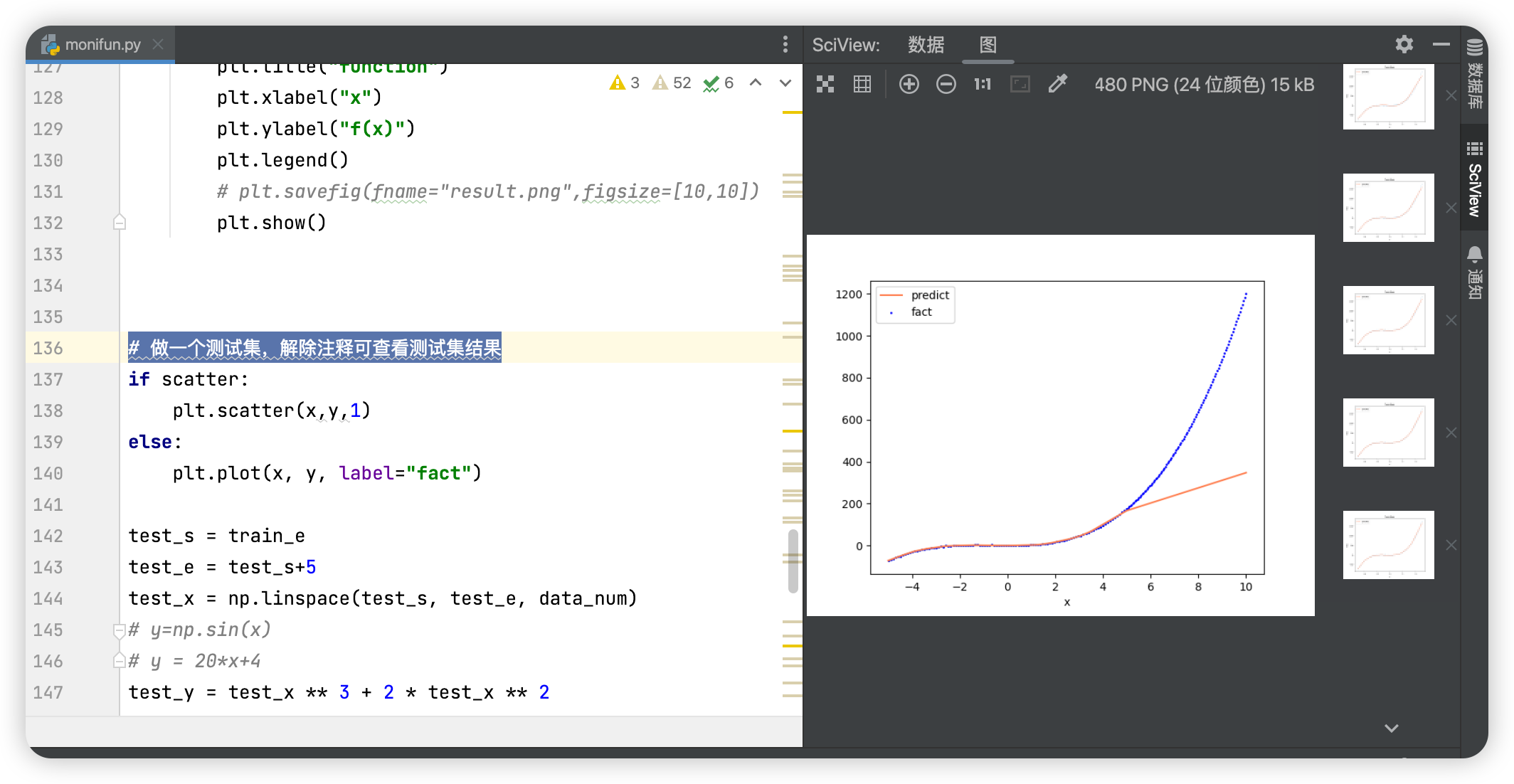
这暴露了一个问题:无法预测没见过的数据。
过拟合与欠拟合
在拟合下面叫欠拟合(Underfit),在拟合上面叫过拟合(Overfit)。为什么会这样,其实就是刚刚提到的深浅层对函数的表示能力。当神经网络模型很深效果特别好时,参数越多能力越强,就会想要把每个点都连接起来,即:连偏离的“噪声”也被连接起来了,此时出现过拟合;欠拟合同理。
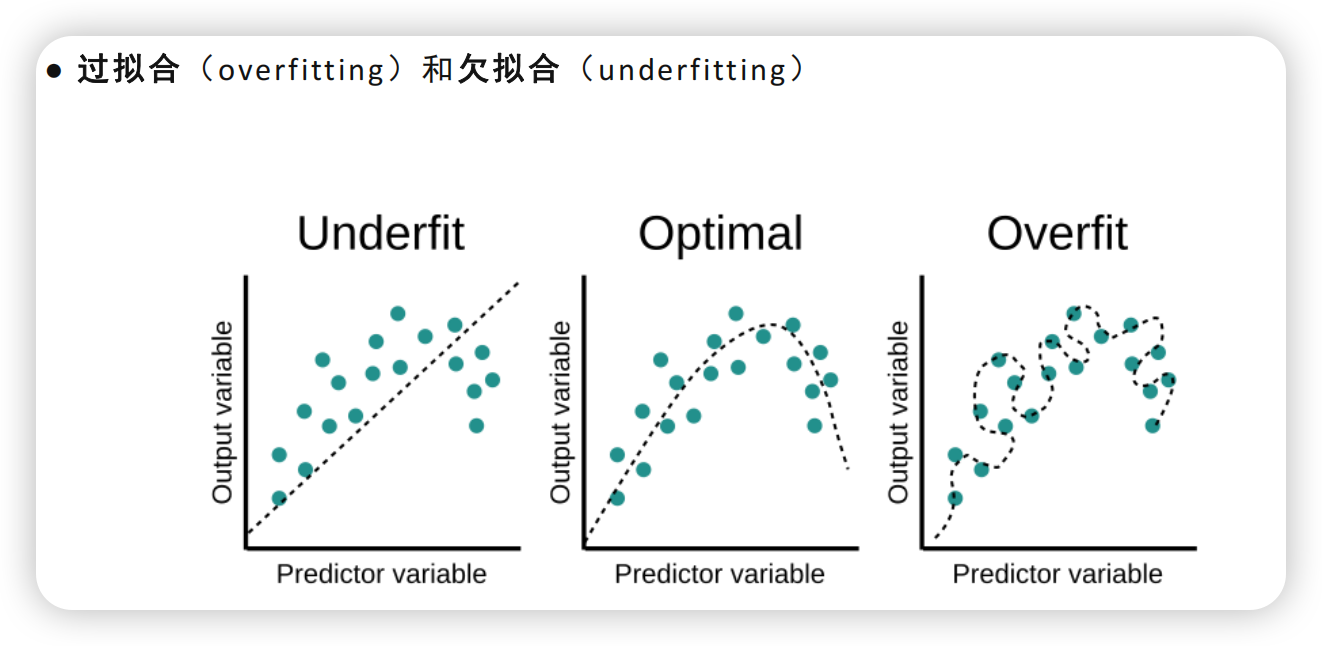
解决欠拟合问题:加深神经网络层数、加参数量;而过拟合的解决过程非常复杂,后续有机会再提及。
神经网络透析
架构设计
架构不同实际上就是函数结果不同,架构设计需要根据个人经验,通过实验得出,因为神经网络模型是一个黑盒子。
应用场景
神经网络可以完成超级复杂的任务,诸如图片生成, 人脸识别等等;但回归到一些原始纯粹的简单问题上, 它表现得可能没那么好。如: 刚才的模拟函数、判断一个数字是否为偶数、发现数字规律等。为什么呢,因为神经网络模型和新生儿比较相似,缺少了“先验知识”。
而大模型对刚刚提到的图片生成等任务完成得很好,因为大模型吃掉了互联网上的所有知识,因此具备“先验知识”,能够很好地完成任务。

代码链接,自取:
链接: https://pan.baidu.com/s/1gTG6vW8E19k1NVSG92mppw?pwd=bhx1 提取码: bhx1
--来自百度网盘超级会员v4的分享

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)