实验五 Python 数据可视化
一、实验基本原理
运用 Anaconda 搭建的 Jupyter notebook 平台编写实例 Python 程序。
二、实验目的
1、学习使用 jieba、wordcloud 等类库生成词云图。
2、学习使用 Matplotlib 库进行数据可视化。
三、具体要求
1、掌握 jieba、wordcloud 等类库生成词云图的方法。
2、掌握使用 Matplotlib 库进行数据可视化的方法。
四、实验环境
1、Windows 10 电脑一台。
2、Anaconda、Python、Jupyter notebook 平台。
五、 实验内容
实例 1:简历信息词云图
用 Python 编程实现,设定一张背景图片(图片可以自己另找),将个人信息填充至该图片中,生成简历信息词云图。每个同学用自己的姓名、爱好、家乡名等相关的简历信息作为词云(文本里可以用查找替换)。
要求:
(1)利用 imageio 读取背景图片并解析。
(2)利用 jieba 库进行简历信息分词处理。
(3)利用 wordcloud 库中的 WordCloud 生成词云。
(4)利用 matplotlib 输出生成的词云图。
import jieba #分词模块import matplotlib.pyplot as plt #画图模块from wordcloud import WordCloud #文字云模块import imageio #这是一个处理图像的函数,读取背景图片wf = 'per_info.txt'word_content = open(wf,'r', encoding='utf-8').read().replace('\n','') #读取文件内容img_file = 'china.jpg' #设置背景图片mask_img = imageio.imread(img_file) #解析背景图片word_cut = jieba.cut(word_content) #进行分词word_cut_join = " ".join(word_cut) #把分词用空格连起来wc = WordCloud( )#设置字体,允许最大词汇量,最大号字体,使用的背景图片,输出的图片背景色wc.generate(word_cut_join) #生成词云plt.imshow(wc) #用于显示图片,需配合 plt.show()一起使用plt.axis('off') #去掉坐标轴,否则外围有一个带坐标的框plt.savefig('09-YangZhongBao.jpg') #将图片保存到本地plt.show()
示例:

输入:
#实例1:简历信息词云图
import jieba # 分词模块
import matplotlib.pyplot as plt # 画图模块
from wordcloud import WordCloud # 文字云模块
import imageio.v2 as imageio # 处理图像并读取背景图片
# 定义指定地址路径
txt_path = r"E:\大三上\人工智能与大数据\实验\shiyan3\实验五 Python 数据可视化\实验5-实例1-生成简历信息词云图\per_info.txt"
img_path = r"E:\大三上\人工智能与大数据\实验\shiyan3\实验五 Python 数据可视化\实验5-实例1-生成简历信息词云图\china.jpg"
font_path = r"E:\大三上\人工智能与大数据\实验\shiyan3\实验五 Python 数据可视化\实验5-实例1-生成简历信息词云图\STXINGKA.ttf"
# 读取简历信息内容
# 建议指定 encoding='utf-8' 以防止中文乱码
word_content = open(txt_path, 'r', encoding='utf-8').read().replace('\n', '')
# 解析背景图片
mask_img = imageio.imread(img_path)
# 利用 jieba 进行分词处理
word_cut = jieba.cut(word_content)
word_cut_join = " ".join(word_cut) # 把分词用空格连接起来
# 设置词云参数并生成词云
wc = WordCloud(
font_path = font_path, # 使用指定的字体文件地址
max_words = 300, # 允许最大词汇量
max_font_size = 100, # 设置最大号字体
mask = mask_img, # 设置使用的背景图片
background_color = 'white' # 设置输出图片的背景色
)
wc.generate(word_cut_join) # 生成词云
# 利用 matplotlib 输出生成的词云图
plt.imshow(wc) # 用于显示图片
plt.axis('off') # 去掉坐标轴
# 修改保存地址为指定路径,保留文件名WT.png
plt.savefig(r"E:\大三上\人工智能与大数据\实验\shiyan3\实验五 Python 数据可视化\实验5-实例1-生成简历信息词云图\xx.png")
plt.show() # 配合 plt.imshow() 一起使用显示图像修改文本文档内容:
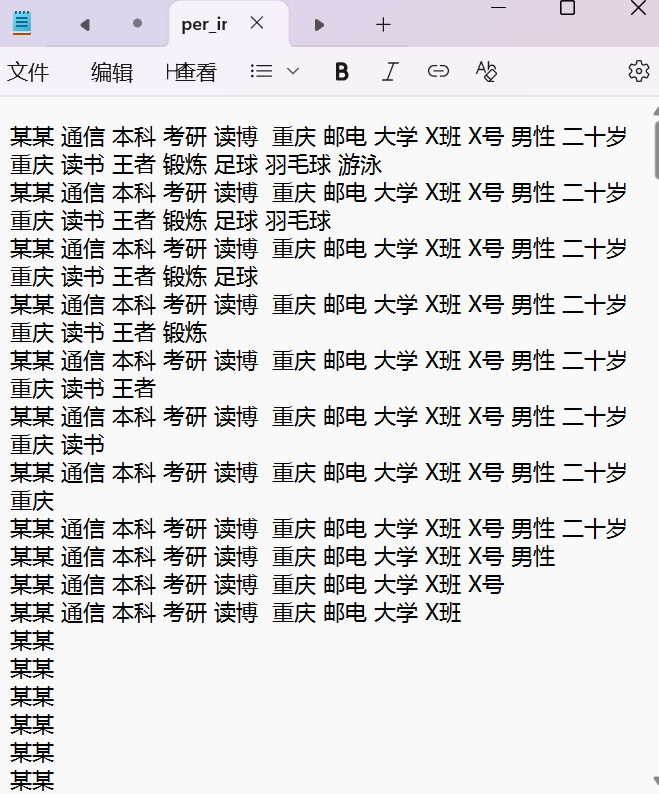
实例 2:疫情病例数发展趋势可视化
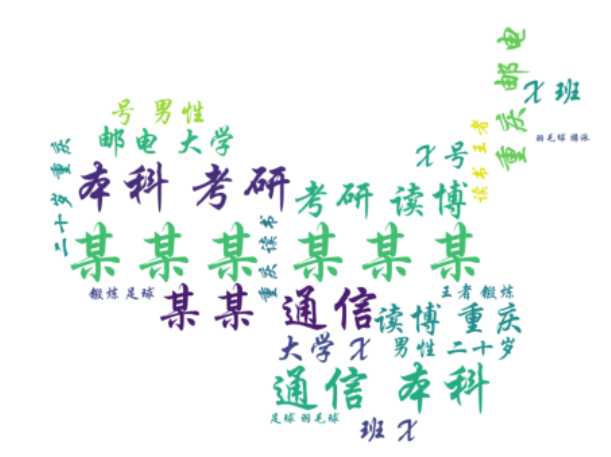
对重庆本次疫情每天的感染人数(确诊+无症状)进行可视化,生成折线图,展现整个疫
情发展趋势。
要求:
(1)使用 pandas 库读取文件 cq_COVID-19.xlsx 中的日期和感染人数数据,并将其保存
至两个 list 中。
(2)利用 matplotlib 输出重庆十一月份感染人数走势折线图。
注意:
如果运行后提示错误 Missing optional dependency 'xlrd'. Install xlrd >= 1.1.0 for Excel
support Use pip or conda to install xlrd.
如果直接安装 pip install xlrd,安装的为 xlrd2.0.1 版本,已满足 xlrd >= 1.1.0 的需求,但
xlrd 大于等于 2.0 时,仅支持 xls 格式,不支持 xlsx,所以,直接用命令安装 xlrd==1.1.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlrd==1.1.0
输入:
#实例2:疫情病例数发展趋势可视化
import pandas as pd
import matplotlib.pyplot as plt
import os
# 设置文件路径与保存路径
file_path = r"E:\大三上\人工智能与大数据\实验\shiyan3\实验五 Python 数据可视化\实验5-实例2-疫情病例数发展趋势可视化\cq_COVID-19.xlsx"
save_dir = r"E:\大三上\人工智能与大数据\实验\shiyan3\实验五 Python 数据可视化\实验5-实例2-疫情病例数发展趋势可视化"
save_path = os.path.join(save_dir, "cq_trend_chart.png")
# 设置中文字体以防止图表乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 使用 pandas 读取 Excel 数据
# 注意:如果环境提示缺少 xlrd,请在终端执行: pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlrd==1.1.0
df = pd.read_excel(file_path)
# 将日期和感染人数数据提取到两个列表中
date_list = df['日期'].tolist()
count_list = df['感染人数'].tolist()
# 利用 matplotlib 绘制折线图
plt.figure(figsize=(12, 6))
plt.plot(date_list, count_list, marker='o', markersize=4, color='red', linestyle='-', linewidth=1)
# 设置图表标题、坐标轴标签及样式
plt.title('重庆十一月份感染人数走势——绘制人:XX')
plt.xlabel('日期')
plt.ylabel('感染人数')
plt.xticks(rotation=45)
plt.grid(True, linestyle='--', alpha=0.6)
plt.tight_layout()
# 保存图片到指定地址并显示
plt.savefig(save_path)
print(f"图表已成功保存至: {save_path}")
plt.show()输出:
六、思考题
思考题:政府工作报告高频词可视化
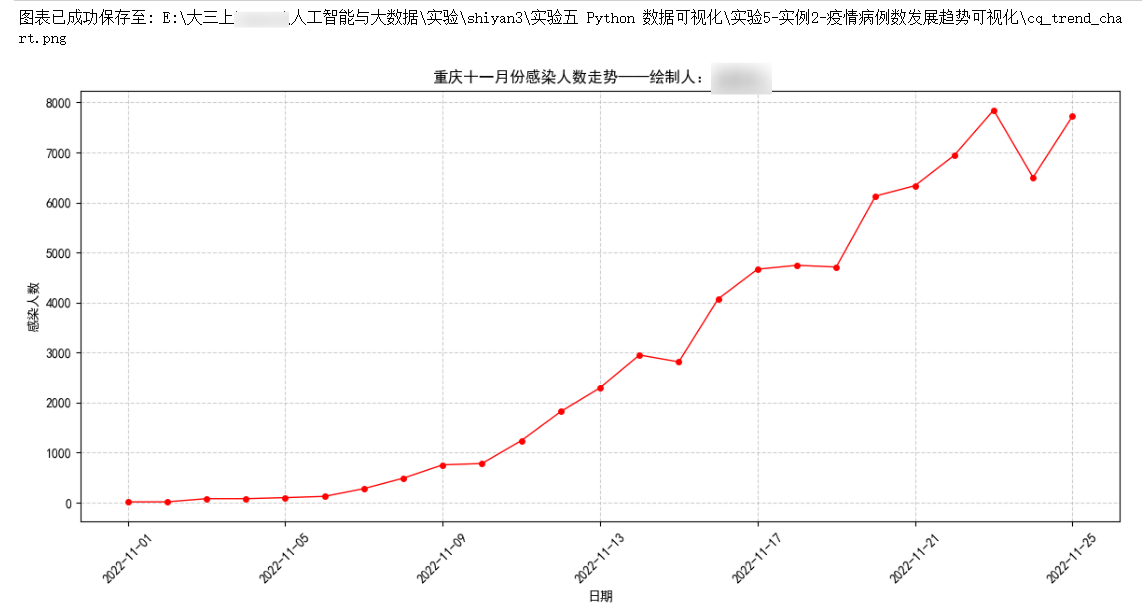
将 2022 年的政府工作报告:govreport-2022.txt 中出现频率最高的 5 个词语进行可视化,生成柱状图。
要求:
(1) 读取 govreport-2022.txt 文件中的内容进行分词处理。
(2) 利用 jieba 库对读取的文字信息进行分词处理。
(3) 对分词后的数据解析为字典,获取每个词语在文中出现的次数,并将字典转换为list,根据词语出现次数降序排序,得到出现频率出现最高的 5 个词语。
(4) 构建两个 list,将 5 个词语及其对应出现的次数分别存储,并使用 matplotlib 库绘制柱状图(X 轴为词语名称,Y 轴为词语对应出现的次数)。
1、导入文件内容wf = 'govreport-2022.txt' #词源的文本文件word_content = open(wf,'r', encoding='utf-8').read().replace('\n','')2、使用 jieba 进行分词处理word_cut = jieba.cut(word_content) #进行分词输出3、解析分词后的数据:counts={}for word in word_cut :word = word.replace(",", "").replace("!", "").replace("“", "") \.replace("”", "").replace("。", "").replace("?", "").replace(":", "") \.replace("...", "").replace("、", "").strip(' ').strip('\r\n')if len(word) == 1 or word == "":continueelse:counts[word]=counts.get(word,0)+1 #单词计数
输入:
#思考题:政府工作报告高频词可视化
import jieba
import matplotlib.pyplot as plt
import os
# 设置文件地址与保存地址
file_path = r"E:\大三上\人工智能与大数据\实验\shiyan3\实验五 Python 数据可视化\实验5-思考题-政府工作报告高频词可视化\govreport-2022.txt"
save_dir = r"E:\大三上\人工智能与大数据\实验\shiyan3\实验五 Python 数据可视化\实验5-思考题-政府工作报告高频词可视化"
save_file = os.path.join(save_dir, '词频.png')
# 读取文件内容并分词
# 按照实验要求读取 govreport-2022.txt 内容
word_content = open(file_path, 'r', encoding='utf-8').read().replace('\n', '')
word_cut = jieba.cut(word_content)
# 解析分词数据并进行词频统计
counts = {}
for word in word_cut:
# 按照实验提示清洗标点符号
word = word.replace(",","").replace("!","").replace("“","")\
.replace("”","").replace("。","").replace("?","")\
.replace(":","").replace("...","").replace("、","").strip()\
.strip('\r\n')
# 过滤掉单字和空白字符
if len(word) == 1 or word == "":
continue
else:
counts[word] = counts.get(word, 0) + 1
# 将统计结果转换为列表并按词频降序排序
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
# 获取出现频率最高的 5 个词语
w = []
c = []
for i in range(5):
word1, count = items[i]
w.append(word1)
c.append(count)
# 使用 matplotlib 绘制柱状图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示问题
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.figure(figsize=(10, 6))
plt.bar(w, c, color='steelblue')
# 设置图表标签和标题
plt.xlabel("单词名称")
plt.ylabel("出现次数")
plt.title("WordCount(词频统计)——绘制人:XX")
# 保存图片并显示
plt.savefig(save_file, dpi=300, bbox_inches='tight')
print(f"图表已保存至: {save_file}")
plt.show()

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)