基于YOLO的钢铁表面缺陷检测模型训练
上一篇分享了CNN和YOLO的理论基础,接下来的挑战就是如何落地应用。
与自然图像不同,工业图像往往具有重复性、视觉目标小、容错率低等特征。缺陷可能仅占据表面的一小部分,而背景则几乎均匀。纹理的细微变化很容易模糊“正常”与“缺陷”之间的界限。
从模型的角度来说,钢铁表面缺陷检测非常契合目标检测范式:
- 每个缺陷目标都有一个位置
- 缺陷属于某个预定义的类别
- 单个图像中可能出现多个缺陷
这使得YOLO成为理想的候选方案——它能够在一次扫描中定位和分类目标,这与实时检测和自动化质量控制场景非常契合。
使用 Ultralytics YOLO 进行训练
我使用了Ultralytics YOLO框架进行训练,它为训练和部署提供了简洁且易于维护的接口,并抽象出了许多重复性的工程工作,而仍然允许对模型配置和训练行为进行细粒度的控制。
训练在Google Colab中进行,主要是因为它提供了一个开箱即用的环境,预装了 PyTorch 并支持 GPU,这样免去了环境搭建的冗余工作,从而专注于实验本身。
训练数据集来自百度PaddlePaddle竞赛,可在此处下载。数据集包含钢材表面图像以及存储在.xml文件中的标注信息,描述了预定义的缺陷类别及其边界框。可视化后,这些缺陷表现为原本均匀的钢材表面上的局部不规则区域。

Ultralytics YOLO 的一个直接优势在于能够快速启动实验。无需手动连接数据集、模型和训练循环,注意力可以集中在数据和任务本身。
# pip install ultralytics
from ultralytics import YOLO
import os
model = YOLO( 'yolo12m.pt' )预训练权重
预训练权重文件(yolo12m.pt)对应于YOLO v12的中等规模版本,使用大规模数据集训练而成。由于标注数据有限,我选择使用预训练模型,使用m版本是为了在模型能力和训练速度及稳定性之间取得平衡。
数据集配置
数据集的描述.yaml文件中包含以下内容:
- 数据集的根目录
- 训练、验证、测试集的位置
- 缺陷类别及其名称
path: steel_data/ # 训练集根目录
train: train/images # 训练集
val: val/images # 验证集
test: test/images # 测试集
# 目标种类
names:
0: crazing
1: inclusion
2: pitted_surface
3: scratches
4: patches
5: rolled-in_scale模型训练
模型和数据集配置完成后,指定一组超参来进行训练。
results = model.train(
data='./dataset.yaml',
epochs=100,
batch=8,
imgsz=640 ,
patient=50,
save=True,
device='0',
workers=4,
pretrained=True,
optimizer='auto',
verbose=True,
# 数据增强参数
scale=0.5,
mosaic=1.0,
mixup=0.1,
copy_paste=0.1,
) 数据增强超参
在钢材表面缺陷检测实验设计中,我很快意识到一个实际挑战:
- 背景高度重复
- 缺陷样本数量有限,而且贴标签成本高昂
- 实际生产环境会引入不可控的变化
在这种情况下,YOLO 提供了数据增强参数(Data augmentation hyperparameters),用于定义训练中如何将数据呈现给模型。其目标是使模型对无关变化不敏感,同时对定义缺陷的结构模式保持高度敏感。
因此,数据增强参数的选择很重要。我首先尝试了缩放Scale、马赛克Mosaic、混合Mixup和复制粘贴Copy_paste。
Scale:随机缩放图像的大小。没有它,模型只能识别固定尺度的缺陷,从而变得非常脆弱。
Mosaic:将多张图像合并成一张。它可以防止模型记忆背景模式,并将注意力集中在局部异常上。
Mixup:将两幅图像及其标注线性混合。对于边界模糊的缺陷,适度的混合有助于谨慎预测,避免过度自信。
Copy_paste:通过复制缺陷区域并将其插入其他图像中,增加罕见缺陷的出现频率。
初步结果与诊断
经过初始训练后,模型达到了以下目标:
- 验证集 mAP@0.5: 0.7525
- 验证集 mAP@0.5–0.95: 0.4428
- 测试集 mAP50: 0.7510
- 测试集 mAP50–95: 0.4364
mAP@0.5 与 mAP@0.5–0.95
mAP@0.5 用于衡量在固定IoU 阈值 0.5下,预测的边界框与真实边界框的重叠程度是否足够。它相对宽容,主要反映模型能否“找到”目标。而mAP@0.5–0.95 则在更严格的 IoU 阈值下对性能进行平均。它会惩罚不精确的定位,因此能更好地指示box精度。
两项得分之间的明显差距表明,虽然该模型能够检测缺陷,但其定位鲁棒性仍需改进。
结果损失曲线
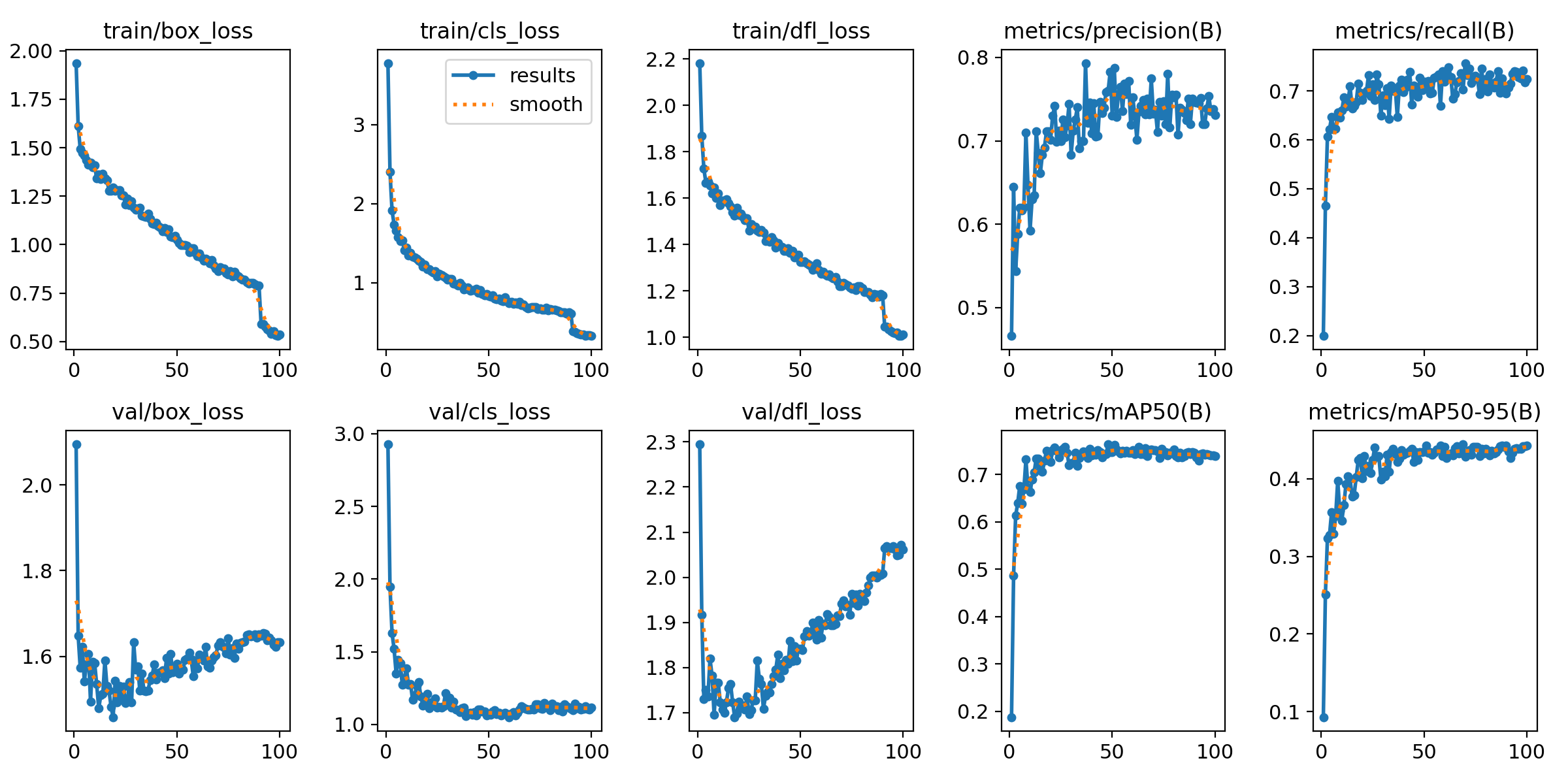
训练曲线显示出稳定的收敛性。损失曲线平滑下降,验证集平均精度(mAP)在大约50个epoch后趋于稳定。验证集相关损失在第40个epoch后略有回升,表明模型在640分辨率下已提前达到饱和,这意味着该模型已提取了该尺度下大部分可用信息。
混淆矩阵
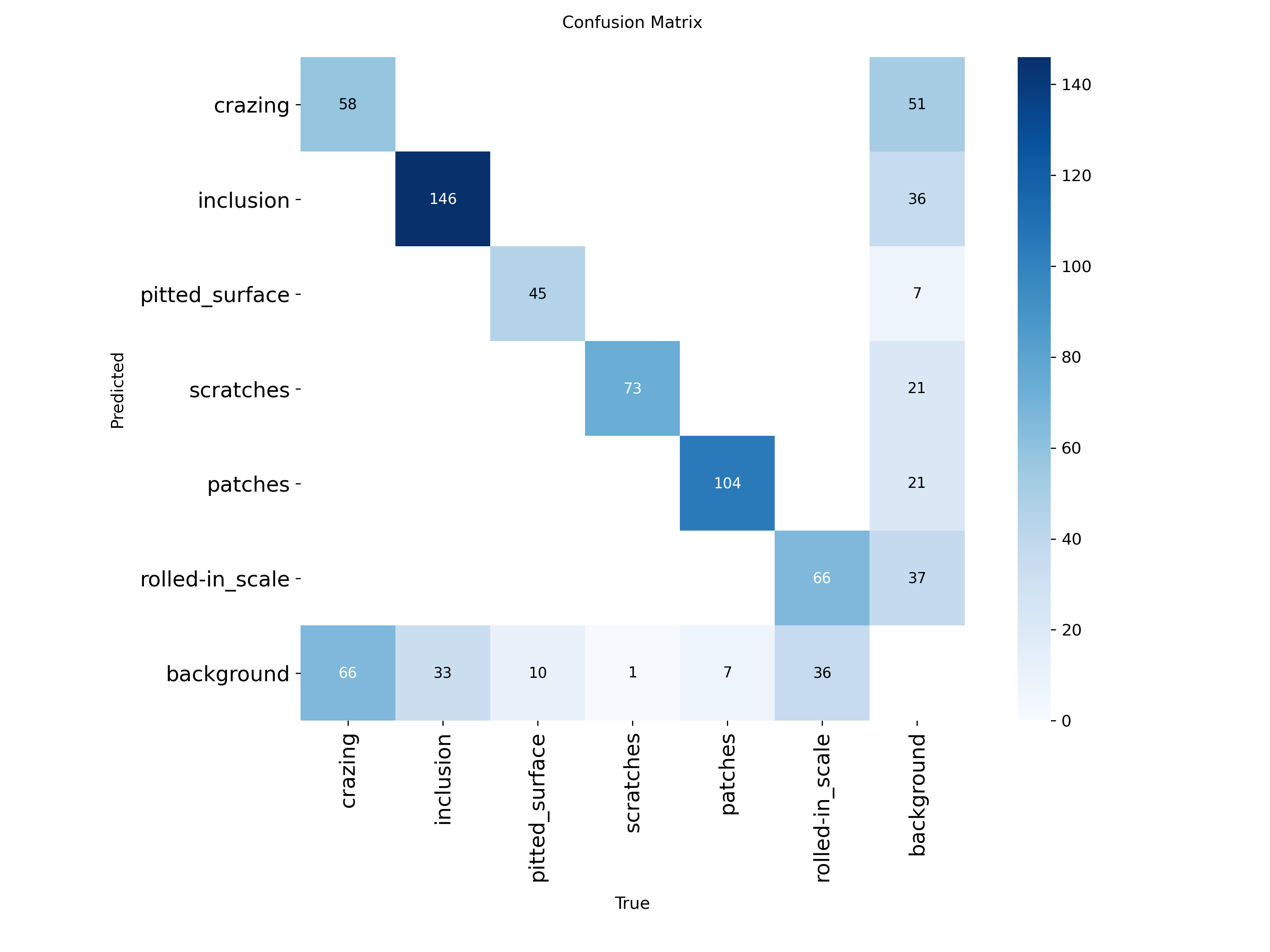
模型对不同类别缺陷的检测性能存在严重的不平衡。
- 能够非常可靠地检测到夹杂和斑点。
- 裂纹漏检和误报严重,氧化皮呈现出类似的模式,但程度比较轻。
- 背景区域多被错误地归类为细微缺陷类型,这凸显了模型在微弱缺陷信号与正常表面纹理之间的混淆。
BoxF1-置信曲线
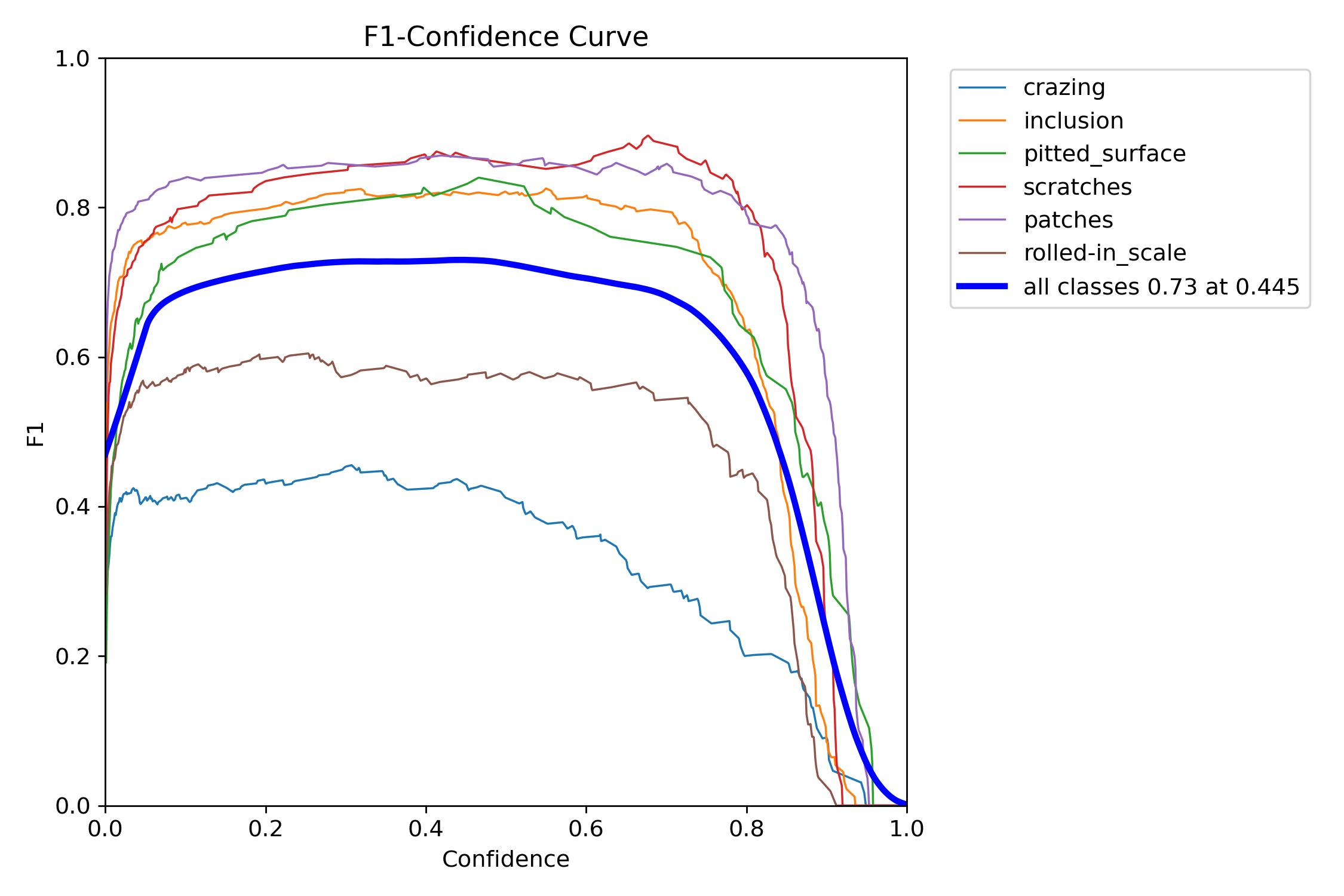
全类峰值在0.45附近——表现优异。然而,裂纹的曲线始终保持较低水平,F1峰值约为0.4。再次说明问题在于细微缺陷特征的识别能力不足。
改进策略
根据上述诊断结果,我调整了训练配置,目标明确:减少误报,稳定分类,提高定位精度。
更高的输入分辨率(imgsz: 640 → 800): 让模型看得更清楚,从而更好地区分真正的缺陷与背景纹理噪声;
更强的分类损失(cls = 1.5): 由于类别混淆是一个主要的错误来源,增加分类损失权重迫使模型优先考虑正确的类别分配。
更多的复制粘贴(copy_paste = 0.3):强化对罕见缺陷类型的学习。
后期马赛克增强关闭(close_mosaic = 20):马赛克增强功能虽然强大,但生成的合成图像与真实的物理分布存在偏差。在最后 20 个训练周期中禁用马赛克增强功能,可以让模型在真实图像上进行微调,从而提高精度。
扩展训练(epochs: 100 → 150):让模型得以充分训练,使改进后的配置生效。
第二次训练结果与改进
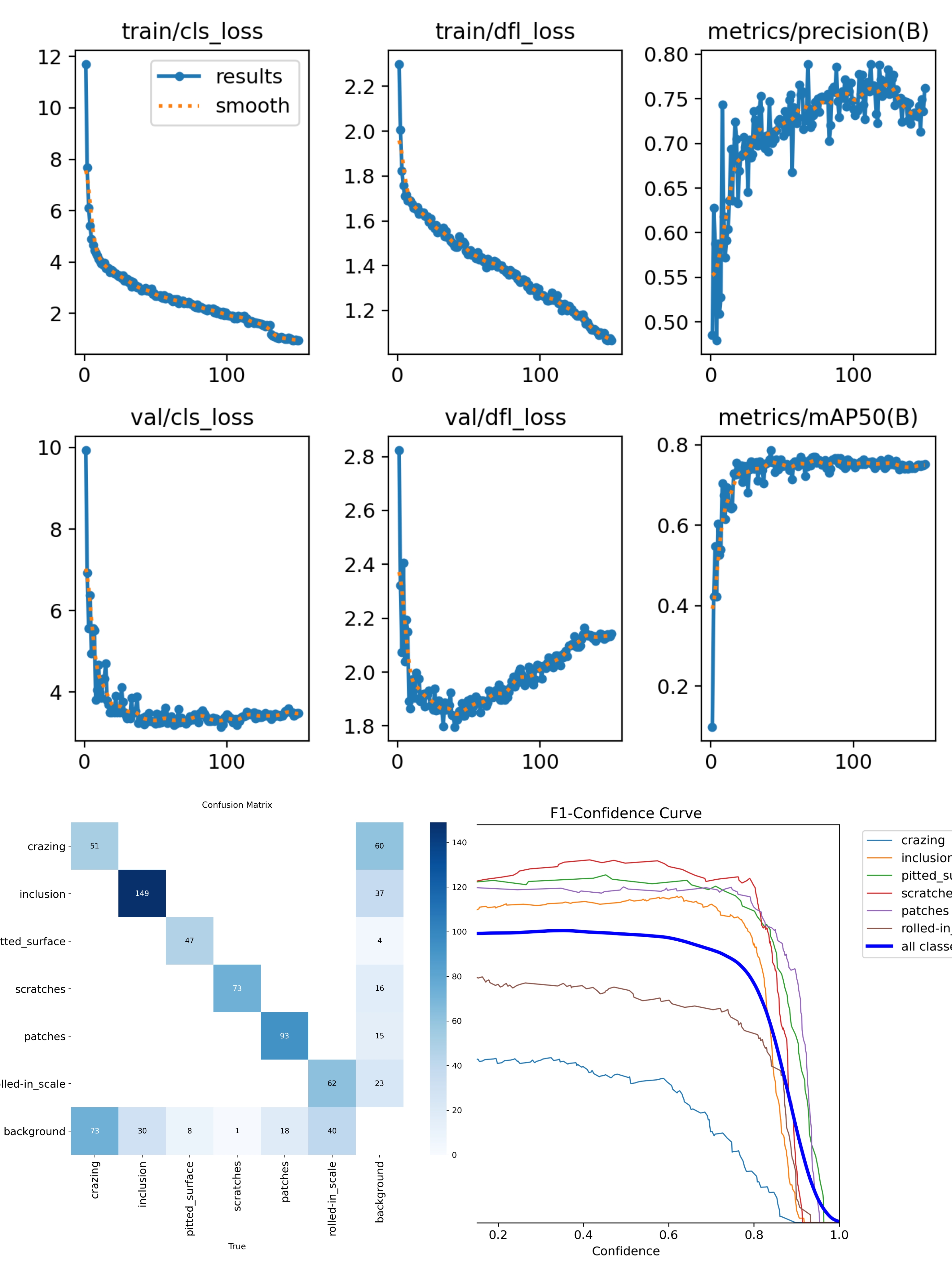
经过优化后,验证集 mAP@0.5 略微提升了 1.45%,达到 0.7634,而mAP@0.5–0.95 的提升更为显著(+3.57%)。这证实了在更高的分辨率下,模型能够更精确地定位缺陷。然而,这种改进并未得以泛化。在测试集上,mAP@0.5 (0.7510 → 0.7269)和mAP@0.5–0.95 (0.4364 → 0.4239)均有所下降,表明该模型的性能开始依赖于验证集特有的噪声。
混淆矩阵揭示了本次参数调整的明显副作用。模型区分裂纹和背景的能力下降了:更多裂纹被误判为背景,而更多背景区域被错误地标记为裂纹。这证实了改进过度强调了边界框的精确度,而牺牲了缺陷分类的鲁棒性。
改进目标转变
在实际的钢铁表面检测中,缺陷检出率和分类可靠性比边界框精度的微小提升更为关键。因此,改进目标从“更精确的边界框”转向更强的缺陷感知能力和更好的泛化能力。
参数调整
提高分类权重(cls = 2.0)以增强对细微缺陷的敏感性,同时label_smoothing = 0.15容忍边界的不确定性;
降低定位边框权重 ( box = 7.0) 以防止进一步的定位驱动过拟合;
适度复制粘贴(copy_paste = 0.1)以避免出现尖锐的合成边缘;
增加 mixup ( mixup = 0.2) 以模拟混合裂纹纹理;
更强的正则化(weight_decay = 0.002)以抑制高频噪声;
禁用颜色增强(hsv_h = 0.0, hsv_s = 0.0),强制模型关注纹理而不是颜色线索。
更多结果及进一步改进
第二次优化使验证集 mAP@0.5 提高了 1.6%,测试集 mAP@0.5 也提高了 1.65% 。这证实了参数调整帮助模型恢复了部分泛化能力。背景的误判率显著降低,但对裂纹缺陷的识别能力仍然有限。基于这一结果,我进一步完善了训练策略:
scale = 0.9 提高对微小缺陷的灵敏度;
mixup = 0.15 略微减少,以避免裂纹状纹理过度模糊;
cos_lr = True 以便实现更平滑、更精确的收敛;
cls = 1.8 略微降低,以避免对分类过度惩罚;
box = 6.5 继续推进从本地化到分类的重点转变;
第四轮训练:稳定性和泛化
第四次训练在验证集和测试集上取得了几乎相同的mAP@0.5值(分别为0.7371和0.7355)。然而,测试集的mAP@0.5–0.95值从0.4237提升至0.4596(+8.48%),与验证集的得分(0.4653)非常接近。这种差距的缩小有力地表明,模型学习到的特征具有很高的可迁移性,而不再局限于验证集的特定模式。
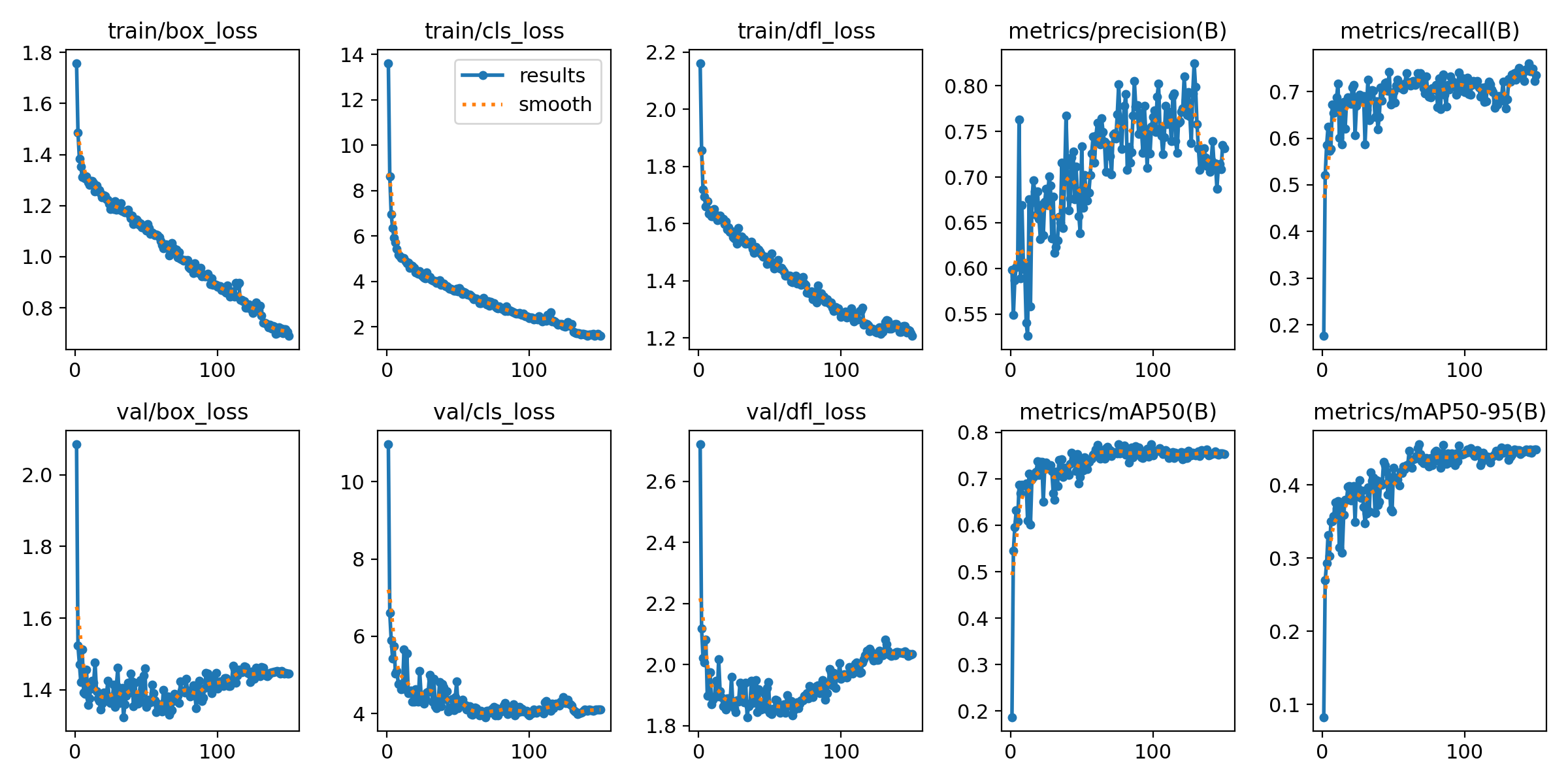
从损失曲线可以看出,val/box_loss和val/cls_loss 的反弹幅度都很小。余弦学习率调度使得模型在最后 20 个 epoch 内能够逐渐稳定到更优状态。
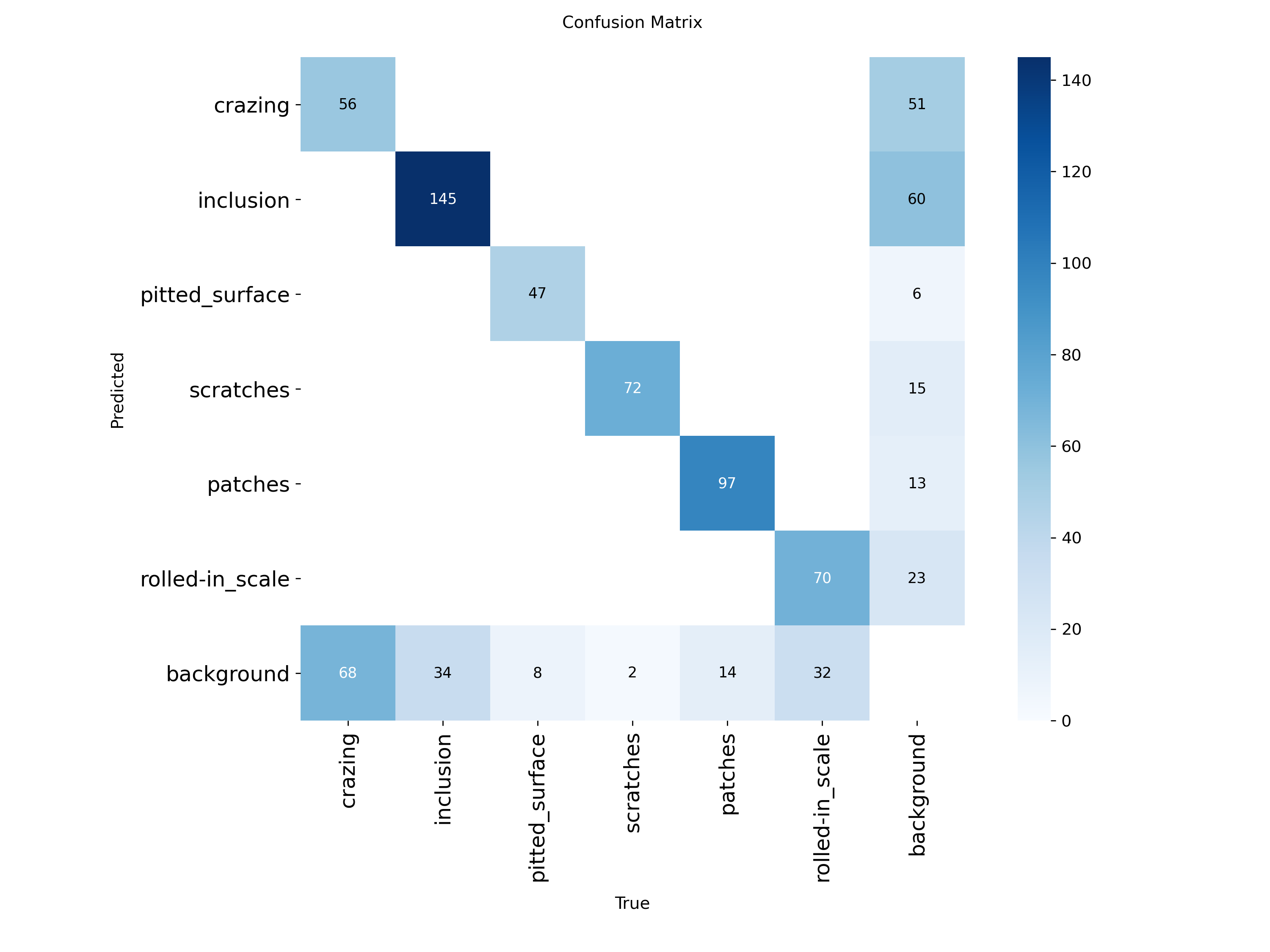
混淆矩阵显示,对裂纹的检测能力有所提升,被错误分类为裂纹的背景数量从 60 个(v2 )下降到 51 个。这证实了cls = 1.8、scale = 0.9和 的组合cos_lr增强了模型捕捉微小、低对比度缺陷的能力。
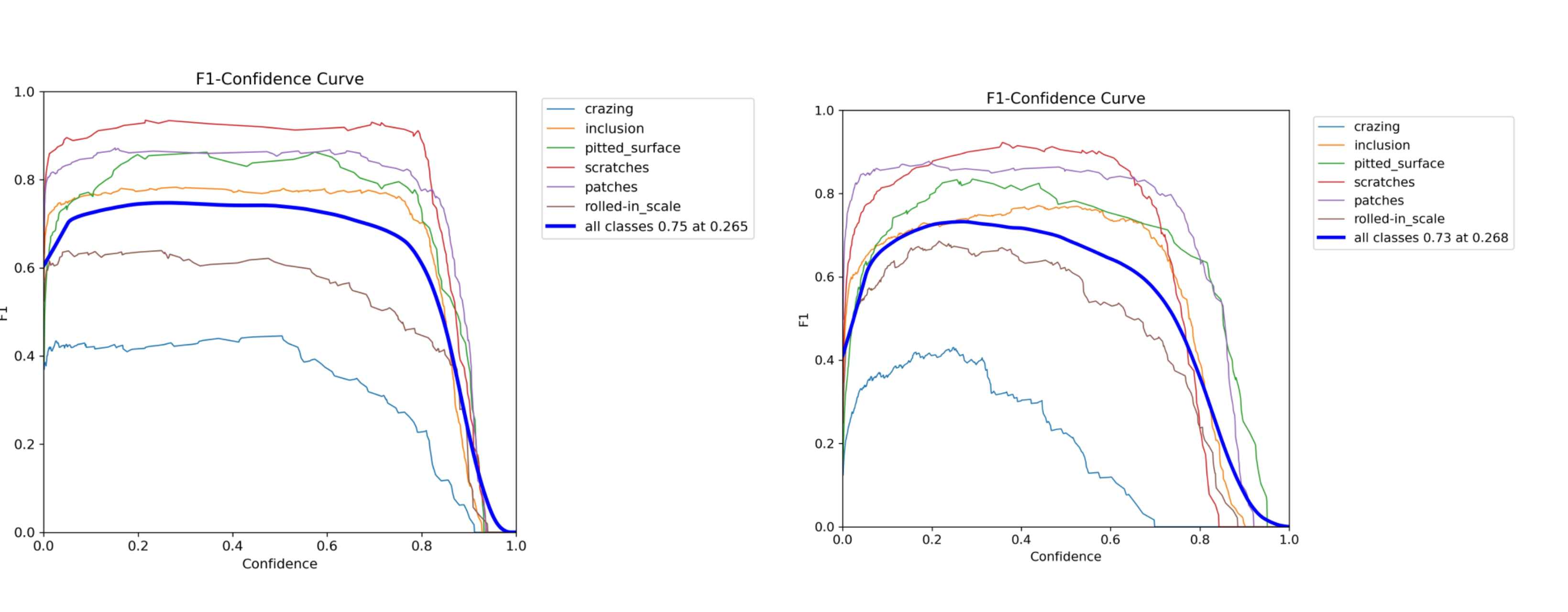
对比v3 v4两次训练结果可以发现,
- v3 版本达到了更高的 F1 峰值分数(置信度 0.265 时为 0.75),并呈现出宽广平坦的平台期。预测结果在较大的置信度范围内保持稳定,表明其具有很强的稳健性。
- v4 峰值 F1 (0.73) 略低,而随着置信度的增加,性能下降得更早,并且在不同类别之间的波动更大。
v3 模型在预测中显得更加果断,可能是由于更强的分类压力(cls = 2.0 ),而产生了更均匀的置信度分布。
融合与微调
由于v3和v4各有优势,我把它们的参数进行融合,又进行一次训练,获得了不错的整体平衡:
- 验证集: mAP@0.5 = 0.7787,mAP@0.5–0.95 = 0.4553
- 测试集: mAP@0.5 = 0.7654,mAP@0.5–0.95 = 0.4438
混淆矩阵证实了整体分类效果有所提升。然而,对裂纹和氧化皮的检测仍然不够理想。为了进一步优化这一点,我又进行了一次微调,降低了学习率(lr0 = 0.0001),并禁用了mixup和copy_paste增强参数,使模型适应真实的图片数据。
经过微调后,验证集的mAP@0.5进一步提升至0.7952,而测试集的性能与v5相比基本保持不变。这表明在当前数据集规模下,模型或许已达到性能上限,并且数据中大部分具有区分性的特征已被充分利用。
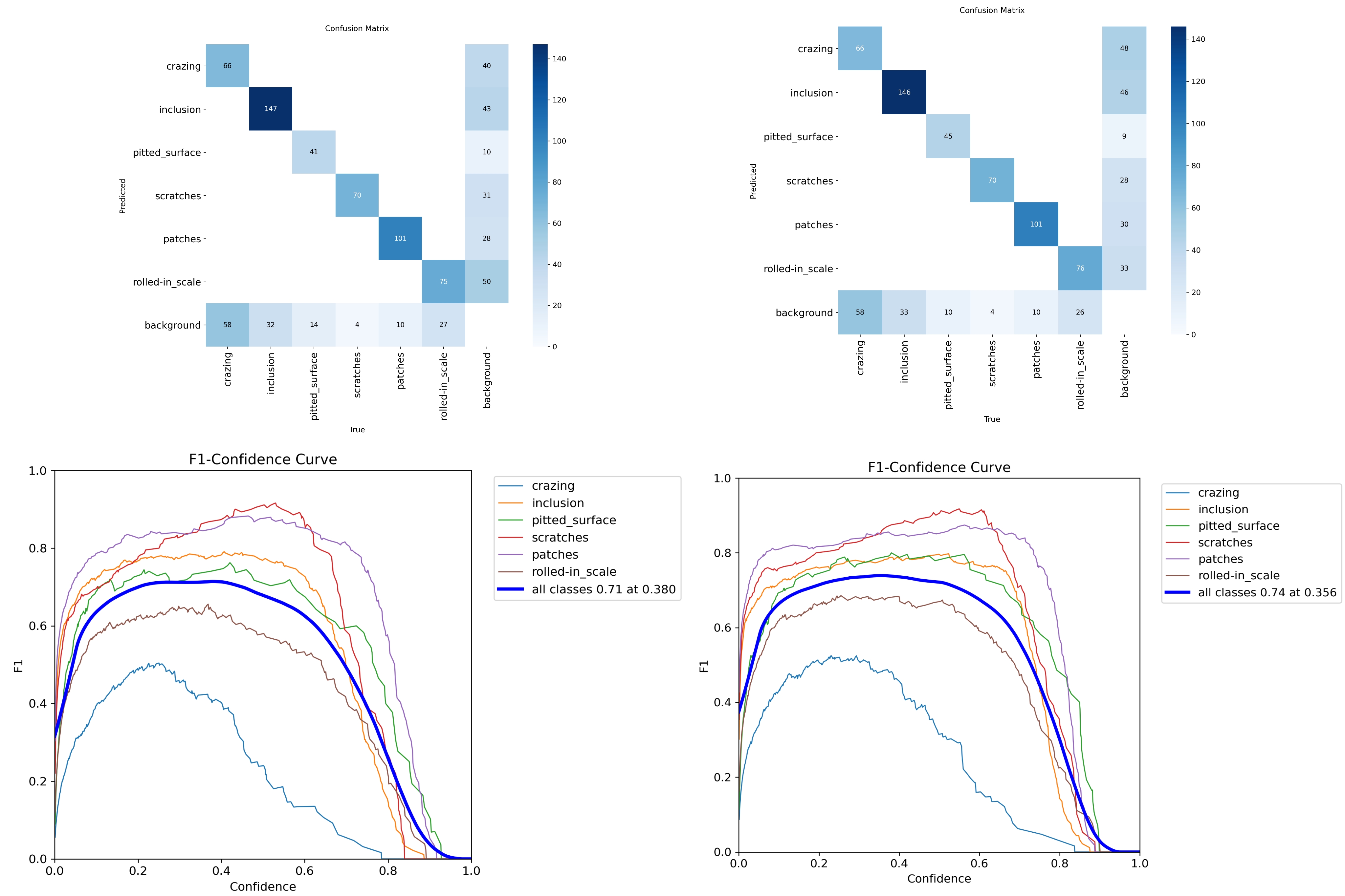
对这两个版本的F1-置信度曲线和混淆矩阵进行比较,可以看出:全局 F1 峰值从置信度为 0.38 时的 0.71提升至置信度为 0.356 时的 0.74 ,这意味着在漏检和误报之间的权衡方面,性能提升了约3% 。与早期版本相比,该模型对背景干扰的鲁棒性显著增强。
混淆矩阵对比结果显示,对氧化皮的检测能力有所提高,背景误报率有所降低。然而,裂纹的识别率仍然没有提升。
其他实验
我也尝试对第一次训练的模型进行微调,因为它是一个稳定的基线模型,初始性能优异(mAP50=0.751)。然而,微调结果并未超越原始基线模型。尽管采用了诸如冻结Backbone层和使用低学习率等保守策略,模型性能仍然略有下降。这表明,v1 的初始参数对于该特定数据集已经达到了最优平衡状态。进一步的修改很可能破坏了特征提取和Head部分之间的微妙平衡。
总结
到目前为止,模型有效地吸收了之前改进的优点:
- 高分类灵敏度
- 泛化保障措施(
weight_decay,cos_lr)
这种组合提高了模型在复杂背景条件下的鲁棒性,并稳定了置信阈值。通过微调,模型区分席位、低对比度缺陷特征的能力得到了进一步增强。经过多阶段改进和针对性微调,v5-Finetune 模型实现了:
- 验证集 mAP@0.5: 0.795
- 测试集 mAP@0.5: 0.765
- F1 峰值: 0.74,置信阈值 0.356
这些结果形成的钢铁表面缺陷检测系统,兼具高抗噪声性和对细微缺陷的可靠检测能力,满足实际需求。
经验和教训
回顾从 v1 到 v5 的迭代优化过程,可以总结出以下几点:
可靠基线的重要性:初始版本(v1)证明,干净的数据集和标准参数可以比复杂的增强方法更有效。高质量的基线为模型的潜力提供了可靠的参考系。
在工业环境中避免“过度增强”: v4 的下降表明,高强度混合和马赛克等激进参数会模糊细微缺陷(比如,裂纹、氧化皮)的边界。在钢铁表面检测中,保持背景的纹理完整性比追求极致的数据多样性更为重要。
战略微调:最终的性能模型(v5-Finetuned)不是通过剧烈的变化实现的,而是通过“外科手术”式的调整:降低学习率,冻结主干网络,并在最后几个 epoch 中禁用 mosaic,让模型“重新聚焦”到真实数据集的图像上。
优化不是为了增加复杂性,而是为了消除阻碍模型看清数据真实面貌的噪声,这体现了以数据为中心的 AI的核心理念,即优化是由数据整洁性而非复杂性定义的。
未来工作
生成式数据增强
本项目的主要局限之一是样本(尤其是裂纹缺陷)规模小且形态多样性低。传统的增强方法(旋转、裁剪)无法创建新的缺陷纹理。未来一个可能的研究方向是使用生成对抗网络(GAN)或Diffusion模型进行生成式增强。例如,可以训练一个缺陷生成对抗网络(Defect-GAN)将普通钢铁表面的图像转换为逼真的含裂纹样本,从而丰富缺陷多样性和空间变异性。
知识蒸馏
当前模型基于相对较大的YOLOv12-m模型训练,接下来可以使用v5-Finetune 模型作为教师模型,蒸馏出一个更小、更快的学生模型,从而在保持大部分检测精度的同时提高推理速度。
参考文献
- Ultralytics, YOLO12 文档,https://github.com/ultralytics/ultralytics/blob/main/docs/en/models/yolo12.md
- Ng, A. 等(2021),以数据为中心的 AI:现实世界的机器学习
- Yun, S. 等(2019),CutMix :使用可局部化特征训练强分类器的正则化策略
- Czimmermann, T. 等(2020),面向工业应用的基于视觉的缺陷检测和分类方法

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)