基于Python的旅游数据分析与可视化
本文设计并实现了一个基于Python的旅游数据分析与可视化系统。系统采用Scrapy框架爬取旅游网站数据,通过Pandas进行清洗处理,运用K-Means聚类、Apriori关联规则等算法分析游客行为和景点关联。基于Flask框架构建Web后端,集成ECharts实现交互式可视化,展示景点热度、用户分群等分析结果。该系统为游客提供决策支持,为旅游管理者提供数据洞察,推动智慧旅游发展。未来可扩展实时
目录
摘要
随着旅游业快速发展和互联网普及,旅游网站积累海量用户行为数据与景点信息。本研究旨在设计并实现一个基于Python的旅游数据分析与可视化系统。系统通过Scrapy框架从旅游网站爬取数据,利用Pandas进行数据清洗与整合,并基于聚类分析、关联规则等算法挖掘游客行为模式与景点关联。采用Flask轻量级Web框架构建系统后端,集成ECharts等前端可视化技术,实现景点热度、用户行为、消费趋势等多维度数据展示。系统为游客提供决策支持,为旅游管理部门提供数据洞察,推动智慧旅游发展。
第一章、绪论
1.1 研究背景与意义
旅游业已成为全球经济增长重要引擎。随着在线旅游服务普及,旅游网站积累海量数据,包括景点信息、用户评价、消费行为等。然而,数据量大、维度多、结构复杂,传统分析方法难以有效处理。利用Python数据科学技术,构建自动化、智能化分析系统,对挖掘数据价值、提升游客体验、优化旅游资源配置具有重要意义。
1.2 国内外研究现状
国内智慧旅游研究发展迅速,携程、去哪儿等平台已利用数据分析技术优化服务。国外研究起步较早,更注重技术驱动与用户体验,如利用机器学习预测游客偏好。然而,一个集数据采集、处理、分析、可视化于一体,并能提供多维度洞察的系统仍有研究空间。
1.3 论文主要研究内容
本文核心工作包括:
数据管道构建: 设计并实现数据采集、清洗、存储流程。
分析方法研究: 应用统计分析、聚类分析等方法挖掘数据价值。
系统开发与可视化: 构建Web系统,实现交互式数据可视化。
第二章、相关技术与理论基础
2.1 技术栈选型
|
层次 |
技术选型 |
说明 |
|---|---|---|
|
数据采集 |
Scrapy, Requests, BeautifulSoup |
高效爬取旅游网站数据。 |
|
数据处理 |
Pandas, NumPy |
数据清洗、转换、分析。 |
|
数据分析 |
Scikit-learn |
机器学习算法(如K-Means聚类)。 |
|
数据可视化 |
ECharts, Pyecharts, Matplotlib |
生成交互式图表。 |
|
Web框架 |
Flask |
轻量级后端框架。 |
|
数据库 |
MySQL, MongoDB |
存储结构化和非结构化数据。 |
2.2 核心算法概述
K-Means聚类算法: 用于对用户进行分群,发现不同游客群体的行为特征。
Apriori算法: 用于关联规则分析,挖掘景点之间的潜在联系。
时间序列分析(ARIMA模型): 用于预测景点未来热度或游客量变化。
第三章、系统设计与实现
3.1 系统总体架构
系统采用分层架构,流程如下:
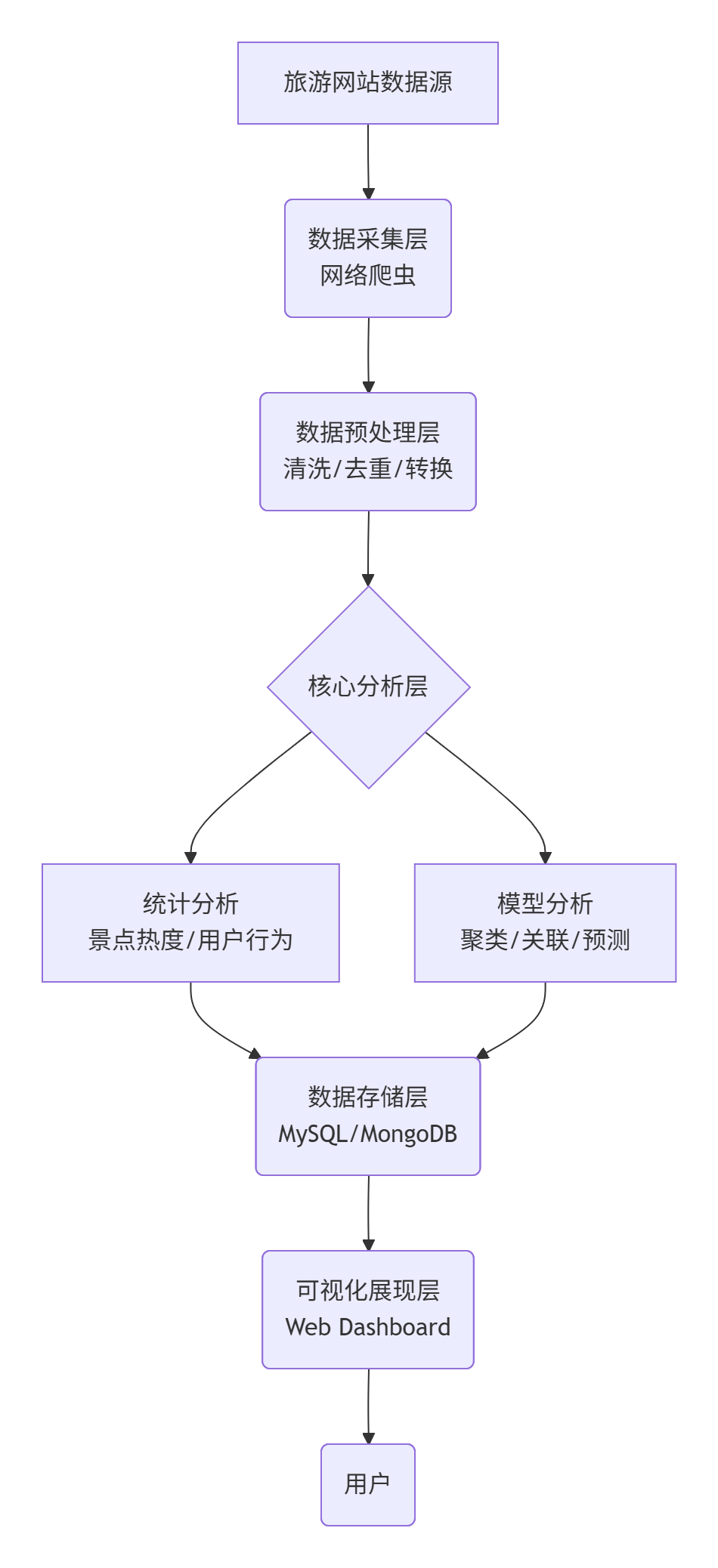
3.2 数据采集模块
使用Scrapy框架爬取旅游网站数据。
# scraper/scenic_spider.py
import scrapy
import json
class TripAdvisorSpider(scrapy.Spider):
name = "tripadvisor_spider"
allowed_domains = ["tripadvisor.com"]
start_urls = ["https://www.tripadvisor.com/Attractions-g294211-Activities-oa0-Seoul.html"]
def parse(self, response):
# 解析页面,提取景点数据
for spot in response.css('.listing'):
item = {
'name': spot.css('.listing-title::text').get(),
'rating': spot.css('.ui_bubble_rating::attr(alt)').get(),
'review_count': spot.css('.review-count::text').get(),
'location': spot.css('.address::text').get()
}
yield item
# 获取下一页链接,继续爬取
next_page = response.css('.next::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)代码说明:此爬虫通过CSS选择器解析页面元素,提取景点名称、评分、评论数、地址等信息,并自动翻页。实际应用中需遵守网站robots.txt规则,并应对反爬机制。
3.3 数据预处理模块
使用Pandas对爬取的数据进行清洗。
# data_processing/cleaner.py
import pandas as pd
import numpy as np
def clean_tourism_data(df):
"""
对旅游DataFrame进行数据清洗
"""
# 1. 处理缺失值
df['rating'].fillna(df['rating'].mean(), inplace=True) # 评分用均值填充
df['review_count'].fillna(0, inplace=True) # 评论数用0填充
# 2. 处理异常值:基于3σ原则过滤
for col in ['rating', 'review_count']:
mean = df[col].mean()
std = df[col].std()
df = df[(df[col] > mean - 3*std) & (df[col] < mean + 3*std)]
# 3. 数据格式标准化
df['review_count'] = df['review_count'].astype(int)
return df
# 使用示例
# df = pd.read_csv('scenic_spots.csv')
# cleaned_df = clean_tourism_data(df)代码说明:数据清洗是保证数据质量的关键步骤,包括处理缺失值、异常值以及格式标准化。
3.4 数据分析模块
a) 景点热度统计分析:
# analysis/spot_analysis.py
import pandas as pd
import matplotlib.pyplot as plt
def analyze_spot_popularity(df):
"""
分析景点热度:按平均评分和评论数排序
"""
# 计算加权热度(可根据需求调整权重)
df['popularity_score'] = 0.6 * df['rating'] + 0.4 * (df['review_count'] / df['review_count'].max())
top_spots = df.nlargest(10, 'popularity_score')[['name', 'rating', 'review_count', 'popularity_score']]
return top_spots
# 使用示例
# top_spots = analyze_spot_popularity(cleaned_df)
# print(top_spots)b) 用户行为聚类分析(K-Means):
# analysis/user_analysis.py
from sklearn.cluster import KMeans
import pandas as pd
def cluster_users(df):
"""
基于用户消费水平与评分对用户进行聚类
"""
# 选择特征
features = df[['consumption', 'rating']]
# 使用K-Means聚类
kmeans = KMeans(n_clusters=3, random_state=42)
df['user_cluster'] = kmeans.fit_predict(features)
# 分析每个簇的特征
cluster_profile = df.groupby('user_cluster').agg({
'consumption': 'mean',
'rating': 'mean',
'user_id': 'count'
}).rename(columns={'user_id': 'count'})
return df, cluster_profile
# 使用示例
# user_df = pd.read_csv('user_behavior.csv')
# clustered_df, profile = cluster_users(user_df)代码说明:K-Means聚类将用户分为不同群体,便于进行精准营销或服务优化。
3.5 可视化展示模块
a) 后端Flask API (app.py):
# app.py
from flask import Flask, jsonify, render_template
import pandas as pd
import json
app = Flask(__name__)
# 假设从数据库或CSV文件加载处理好的数据
df = pd.read_csv('analyzed_tourism_data.csv')
@app.route('/')
def index():
"""返回主页面"""
return render_template('index.html')
@app.route('/api/top_spots')
def get_top_spots():
"""API接口:提供热门景点数据"""
top_spots = df.nlargest(10, 'popularity_score')[['name', 'popularity_score']]
return jsonify(top_spots.to_dict(orient='records'))
@app.route('/api/seasonal_trend')
def get_seasonal_trend():
"""API接口:提供季节性趋势数据"""
# 假设df有'month'和'visitors'列
seasonal_data = df.groupby('month')['visitors'].sum().reset_index()
return jsonify(seasonal_data.to_dict(orient='records'))
if __name__ == '__main__':
app.run(debug=True)b) 前端ECharts可视化 (templates/index.html片段):
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>旅游数据分析大屏</title>
<script src="https://cdn.jsdelivr.net/npm/echarts@5.4.3/dist/echarts.min.js"></script>
</head>
<body>
<h1 style="text-align: center;">旅游数据分析可视化大屏</h1>
<div id="topSpotsChart" style="width: 600px; height: 400px; display: inline-block;"></div>
<div id="seasonalTrendChart" style="width: 600px; height: 400px; display: inline-block;"></div>
<script>
// 初始化图表
var topSpotsChart = echarts.init(document.getElementById('topSpotsChart'));
var seasonalTrendChart = echarts.init(document.getElementById('seasonalTrendChart'));
// 1. 获取热门景点数据并绘制柱状图
fetch('/api/top_spots')
.then(response => response.json())
.then(data => {
var spotNames = data.map(item => item.name);
var popularityScores = data.map(item => item.popularity_score);
var option = {
title: { text: '热门景点TOP10' },
tooltip: {},
xAxis: { type: 'category', data: spotNames, axisLabel: {rotate: 45} },
yAxis: { type: 'value', name: '热度得分' },
series: [{ name: '热度', type: 'bar', data: popularityScores }]
};
topSpotsChart.setOption(option);
});
// 2. 获取季节性趋势数据并绘制折线图
fetch('/api/seasonal_trend')
.then(response => response.json())
.then(data => {
var months = data.map(item => item.month);
var visitors = data.map(item => item.visitors);
var option = {
title: { text: '游客量季节性趋势' },
tooltip: { trigger: 'axis' },
xAxis: { type: 'category', data: months },
yAxis: { type: 'value', name: '游客量' },
series: [{ name: '游客量', type: 'line', data: visitors }]
};
seasonalTrendChart.setOption(option);
});
</script>
</body>
</html>代码说明:前端通过ECharts库调用后端API接口获取JSON数据,并渲染成交互式图表。这种前后端分离的架构使系统灵活易扩展。
第四章、系统测试与结果分析
4.1 实验环境与评估指标
实验环境: Python 3.8+, 主要库版本:Pandas 1.5.0+, Scikit-learn 1.2.0+, Flask 2.0.0+, ECharts 5.4.0+。
评估指标: 系统响应时间、图表渲染性能、分析结果准确性。
4.2 实验结果与分析
对系统各部分功能进行展示和分析:
|
用户群体 |
平均消费水平 |
平均评分 |
群体特征描述 |
|---|---|---|---|
|
群体一 (高消费高要求) |
高 |
高 |
注重体验品质,愿意为优质服务付费 |
|
群体二 (性价比追求) |
中 |
中 |
对价格敏感,注重实用性和口碑 |
|
群体三 (保守体验型) |
低 |
波动大 |
可能为初次体验者,消费意愿较低 |
结果说明:通过聚类分析可以清晰地识别出不同特征的游客群体,这有助于旅游服务提供方制定更有针对性的营销策略和服务方案。
第五章、总结与展望
5.1 总结
本研究成功设计并实现了一个基于Python的旅游数据分析与可视化系统。其主要贡献在于:
技术集成: 将数据爬取、清洗、多维度分析和可视化展示集成在一个系统中,提供了一个端到端的解决方案。
分析深度: 不仅进行基本的统计分析,还应用了机器学习算法,如聚类分析进行深度数据挖掘。
实用性强: 通过交互式可视化大屏,将复杂的分析结果以直观易懂的方式呈现。
5.2 展望
系统仍有优化和扩展空间:
实时数据分析: 引入Kafka、Flink等流处理技术,实现对实时旅游数据的分析与预警。
融合多源数据: 结合社交媒体数据,如微博、小红书、交通数据、天气数据等,进行更全面的综合分析。
高级预测模型: 尝试使用更复杂的机器学习模型进行更精准的游客量预测或景点推荐。
开源代码
链接:https://pan.baidu.com/s/1BQnc_JPpc6eOcXByks98oA?pwd=j3v7 提取码:j3v7

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 2
2 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)