Python数据分析:机器学习基础(附完整代码)
本文介绍了机器学习的基础概念和实践应用。首先通过购物推荐、照片分类等生活场景引出机器学习技术,阐述其从数据中学习模式的核心特点。接着详细讲解了监督学习和无监督学习的区别,以及分类与回归任务的不同。文章重点展示了两个实战案例:使用线性回归预测波士顿房价(回归问题)和决策树分类鸢尾花品种(分类问题),完整呈现了数据探索、特征工程、模型训练与评估的全流程。最后提供了学习资源推荐和常见问题解答,建议学习者
一、机器学习:从生活场景谈起
想象一下这样的场景:
• 你打开购物APP,系统总能精准推荐你感兴趣的商品
• 手机相册自动将同一人的照片归类到一起
• 银行风控系统能识别出可疑的交易行为
这些神奇功能的背后,都有一个共同的引擎——机器学习。机器学习通过从数据中学习规律,让计算机具备"预测"和"决策"的能力。
机器学习解决的核心问题
机器学习本质上解决的是"从数据中学习模式"的问题。不同于传统编程中我们明确告诉计算机"怎么做",机器学习是让计算机通过大量数据自己学会"怎么做"。
二、机器学习基础概念
2.1 学习范式分类
根据数据是否有标签,机器学习主要分为两大类:
|
学习类型 |
定义 |
典型应用 |
算法示例 |
|
监督学习 |
数据包含特征和对应的标签 |
房价预测、垃圾邮件识别 |
线性回归、决策树、SVM |
|
无监督学习 |
数据只有特征,无标签 |
客户分群、异常检测 |
K-means聚类、PCA降维 |
2.2 任务类型区分
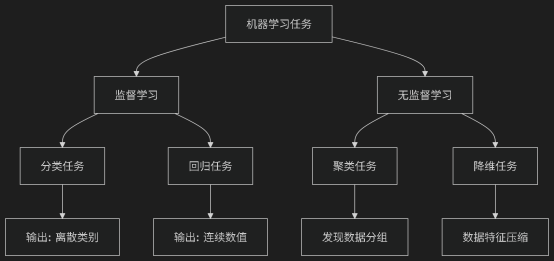
分类 vs 回归的关键区别:
• 分类:预测结果是离散的类别(如:是/否、猫/狗/鸟)
• 回归:预测结果是连续的数值(如:房价、温度、销量)
三、机器学习完整工作流程
一个完整的机器学习项目通常包含以下步骤:

3.1 环境准备
首先导入必要的库:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_boston, load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import mean_squared_error, r2_score, accuracy_score, classification_report
from sklearn.cluster import KMeans
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置绘图风格
sns.set_style("whitegrid")四、实战案例一:线性回归预测房价
4.1 问题定义
使用波士顿房价数据集,通过房屋特征预测房价。这是一个典型的回归任务。
4.2 数据加载与探索
# 加载波士顿房价数据集
boston = load_boston()
df_boston = pd.DataFrame(boston.data, columns=boston.feature_names)
df_boston['PRICE'] = boston.target
# 查看数据基本信息
print("数据集形状:", df_boston.shape)
print("\n数据前5行:")
print(df_boston.head())
# 基本统计信息
print("\n数据统计描述:")
print(df_boston.describe())数据分布可视化:
# 房价分布图
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
sns.histplot(df_boston['PRICE'], bins=30, kde=True)
plt.title('房价分布直方图')
plt.xlabel('房价($1000)')
plt.ylabel('频数')
# 特征相关性热力图
plt.subplot(1, 2, 2)
correlation = df_boston.corr()
sns.heatmap(correlation[['PRICE']].sort_values(by='PRICE', ascending=False),
annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('各特征与房价的相关性')
plt.tight_layout()
plt.show()图表解读:
• 左图显示房价近似正态分布,主要集中在20-25之间
• 右图展示了各特征与房价的相关性,RM(房间数)与房价正相关最高,LSTAT (低收入人群比例)与房价负相关
4.3 特征工程
# 选择与房价相关性较高的特征
selected_features = ['RM', 'LSTAT', 'PTRATIO']
X = df_boston[selected_features]
y = df_boston['PRICE']
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, test_size=0.2, random_state=42
)
print(f"训练集大小: {X_train.shape}")
print(f"测试集大小: {X_test.shape}")4.4 模型训练
# 创建并训练线性回归模型
lr_model = LinearRegression()
lr_model.fit(X_train, y_train)
# 查看模型系数
print("模型系数:")
for feature, coef in zip(selected_features, lr_model.coef_):
print(f"{feature}: {coef:.4f}")
print(f"截距: {lr_model.intercept_:.4f}")4.5 模型评估与可视化
# 预测
y_train_pred = lr_model.predict(X_train)
y_test_pred = lr_model.predict(X_test)
# 计算评估指标
train_mse = mean_squared_error(y_train, y_train_pred)
test_mse = mean_squared_error(y_test, y_test_pred)
train_r2 = r2_score(y_train, y_train_pred)
test_r2 = r2_score(y_test, y_test_pred)
print(f"训练集 MSE: {train_mse:.4f}, R²: {train_r2:.4f}")
print(f"测试集 MSE: {test_mse:.4f}, R²: {test_r2:.4f}")
# 预测结果可视化
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.scatter(y_test, y_test_pred, alpha=0.6)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', lw=2)
plt.xlabel('实际房价')
plt.ylabel('预测房价')
plt.title('实际值 vs 预测值')
plt.grid(True, alpha=0.3)
plt.subplot(1, 2, 2)
residuals = y_test - y_test_pred
plt.scatter(y_test_pred, residuals, alpha=0.6)
plt.axhline(y=0, color='r', linestyle='--', lw=2)
plt.xlabel('预测房价')
plt.ylabel('残差')
plt.title('残差图')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()图表解读:
• 实际值vs预测值图:点越接近红色对角线,预测越准确
• 残差图:残差应随机分布在0线周围,若出现明显模式说明模型存在问题
五、实战案例二:决策树分类鸢尾花
5.1 问题定义
使用鸢尾花数据集,根据花萼和花瓣的尺寸预测花的品种。这是一个典型的多分类任务。
5.2 数据加载与探索
# 加载鸢尾花数据集
iris = load_iris()
df_iris = pd.DataFrame(iris.data, columns=iris.feature_names)
df_iris['species'] = iris.target
df_iris['species'] = df_iris['species'].map({
0: 'setosa', 1: 'versicolor', 2: 'virginica'
})
print("鸢尾花数据集信息:")
print(df_iris.head())
print(f"\n各类别数量:\n{df_iris['species'].value_counts()}")特征分布可视化:
# 特征分布箱线图
plt.figure(figsize=(12, 8))
features = iris.feature_names
for i, feature in enumerate(features, 1):
plt.subplot(2, 2, i)
sns.boxplot(data=df_iris, x='species', y=feature)
plt.title(f'{feature} 分布')
plt.tight_layout()
plt.show()
# 特征散点图矩阵
sns.pairplot(df_iris, hue='species', markers=['o', 's', 'D'])
plt.suptitle('鸢尾花特征散点图矩阵', y=1.02)
plt.show()图表解读:
• 箱线图显示了不同品种鸢尾花在各特征上的分布差异
• 散点图矩阵展示了特征两两之间的关系,setosa品种与其他品种有明显区分
5.3 数据准备
# 特征和标签
X_iris = iris.data
y_iris = iris.target
# 划分训练集和测试集
X_train_iris, X_test_iris, y_train_iris, y_test_iris = train_test_split(
X_iris, y_iris, test_size=0.3, random_state=42, stratify=y_iris
)
print(f"训练集: {X_train_iris.shape}, 测试集: {X_test_iris.shape}")5.4 模型训练
# 创建并训练决策树模型
dt_model = DecisionTreeClassifier(random_state=42, max_depth=3)
dt_model.fit(X_train_iris, y_train_iris)
# 查看特征重要性
feature_importance = pd.DataFrame({
'feature': iris.feature_names,
'importance': dt_model.feature_importances_
}).sort_values('importance', ascending=False)
print("特征重要性排序:")
print(feature_importance)5.5 模型评估
# 预测
y_train_pred_iris = dt_model.predict(X_train_iris)
y_test_pred_iris = dt_model.predict(X_test_iris)
# 计算准确率
train_acc = accuracy_score(y_train_iris, y_train_pred_iris)
test_acc = accuracy_score(y_test_iris, y_test_pred_iris)
print(f"训练集准确率: {train_acc:.4f}")
print(f"测试集准确率: {test_acc:.4f}")
# 详细分类报告
print("\n测试集分类报告:")
print(classification_report(y_test_iris, y_test_pred_iris,
target_names=iris.target_names))5.6 模型性能对比可视化
# 不同深度决策树性能对比
depths = range(1, 10)
train_scores = []
test_scores = []
for depth in depths:
dt = DecisionTreeClassifier(random_state=42, max_depth=depth)
dt.fit(X_train_iris, y_train_iris)
train_scores.append(dt.score(X_train_iris, y_train_iris))
test_scores.append(dt.score(X_test_iris, y_test_iris))
plt.figure(figsize=(10, 6))
plt.plot(depths, train_scores, 'o-', label='训练集准确率')
plt.plot(depths, test_scores, 's-', label='测试集准确率')
plt.xlabel('决策树最大深度')
plt.ylabel('准确率')
plt.title('不同深度决策树的性能对比')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()图表解读:
• 深度1-3时,测试集准确率随深度增加而提升
• 深度超过3后,训练集准确率继续提升但测试集准确率下降,出现过拟合现 象
• 最优深度为3,此时模型泛化能力最好
六、学习资源推荐
6.1 经典书籍
|
书名 |
作者 |
难度 |
特点 |
|
《机器学习》 |
周志华 |
中等 |
国人经典,理论扎实 |
|
《Python机器学习》 |
Sebastian Raschka |
入门 |
实战导向,代码详细 |
|
《统计学习方法》 |
李航 |
较高 |
数学基础要求高 |
6.2 在线课程
• Coursera: Andrew Ng《Machine Learning》- 经典入门课程
• Kaggle Learn: 免费互动式机器学习教程
• Scikit-learn官方文档: 权威的API文档和示例
七、常见问题解答(FAQ)
Q1: 机器学习和深度学习有什么区别?
A: 机器学习是广义概念,包含传统算法(如决策树、SVM)和深度学习。深度学习使用多层神经网络,适合处理图像、语音等非结构化数据,但需要更多数据和计算资源。
Q2: 如何判断模型是否过拟合?
A: 观察训练集和测试集的性能差异。如果训练集准确率很高但测试集明显较低,很可能过拟合。解决方法包括:增加数据量、使用正则化、简化模型复杂度等。
Q3: 特征工程有多重要?
A: 特征工程往往是决定模型性能的关键环节。"数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。"
Q4: 如何选择合适的机器学习算法?
A: 没有万能算法,需要根据数据类型、任务类型、数据规模等因素综合考虑。建议从简单算法开始(如线性回归、决策树),再尝试复杂算法。
八、总结与进阶建议
本文通过两个完整案例,介绍了机器学习的核心概念和完整工作流程。掌握机器学习需要:
1. 理论基础:理解基本概念和算法原理
2. 实践能力:通过项目经验积累技能
3. 持续学习:关注最新技术和最佳实践
下一步学习建议:
• 尝试更多算法(随机森林、XGBoost、神经网络)
• 学习模型调优技术(网格搜索、交叉验证)
• 探索真实业务场景的数据项目
机器学习是一个广阔而精彩的领域,希望这篇博客能为你的学习之旅提供一个良好的起点!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)