[深度学习网络从入门到入土] 残差网络ResNet
[深度学习网络从入门到入土] 残差网络ResNet
个人导航
知乎:https://www.zhihu.com/people/byzh_rc
CSDN:https://blog.csdn.net/qq_54636039
注:本文仅对所述内容做了框架性引导,具体细节可查询其余相关资料or源码
参考文章:各方资料
文章目录
参考资料
Deep Residual Learning for Image Recognition.
背景
在 2014–2015 年,深度 CNN 进入“越深越好”的阶段:
- AlexNet:8 层
- VGG:16–19 层
- GoogLeNet:22 层
问题来了:当网络超过 20 层后,训练误差反而上升
这不是过拟合,而是优化困难(degradation problem)
resnet横空出世: 让网络学习“残差”,而不是直接学习映射
传统网络:
H ( x ) = F ( x ) H(x)=F(x) H(x)=F(x)
ResNet:
H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x
架构(公式)
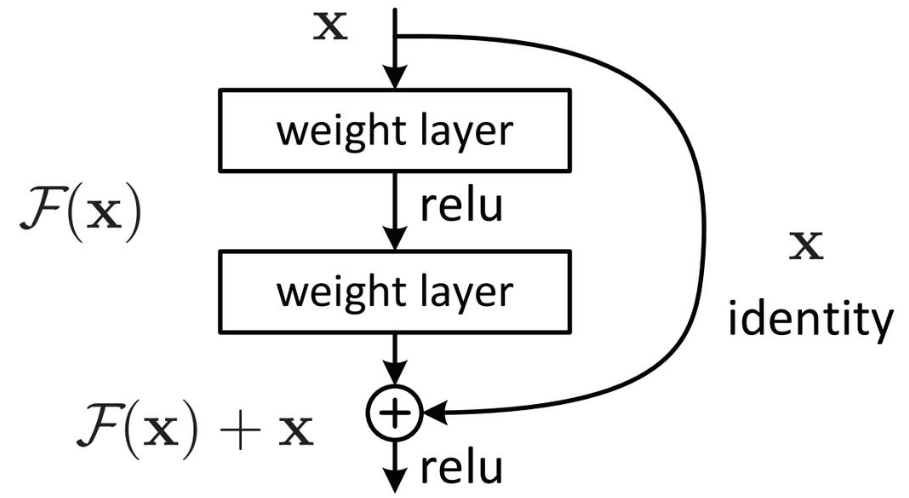
1. BasicBlock(ResNet18/34)
Conv → BN → ReLU
Conv → BN
+
Shortcut
→ ReLU
y = ReLU ( F ( x ) + x ) F ( x ) = W 2 σ ( W 1 x ) y = \text{ReLU}(F(x) + x) \\ F(x) = W_2 \sigma(W_1 x) y=ReLU(F(x)+x)F(x)=W2σ(W1x)
2. Bottleneck(ResNet50/101/152)
当网络变得非常深时,使用瓶颈结构:
1×1(降维) → 3×3(提取特征) → 1×1(升维)
F ( x ) = W 3 σ ( W 2 σ ( W 1 x ) ) F(x) = W_3 \sigma(W_2 \sigma(W_1 x)) F(x)=W3σ(W2σ(W1x))
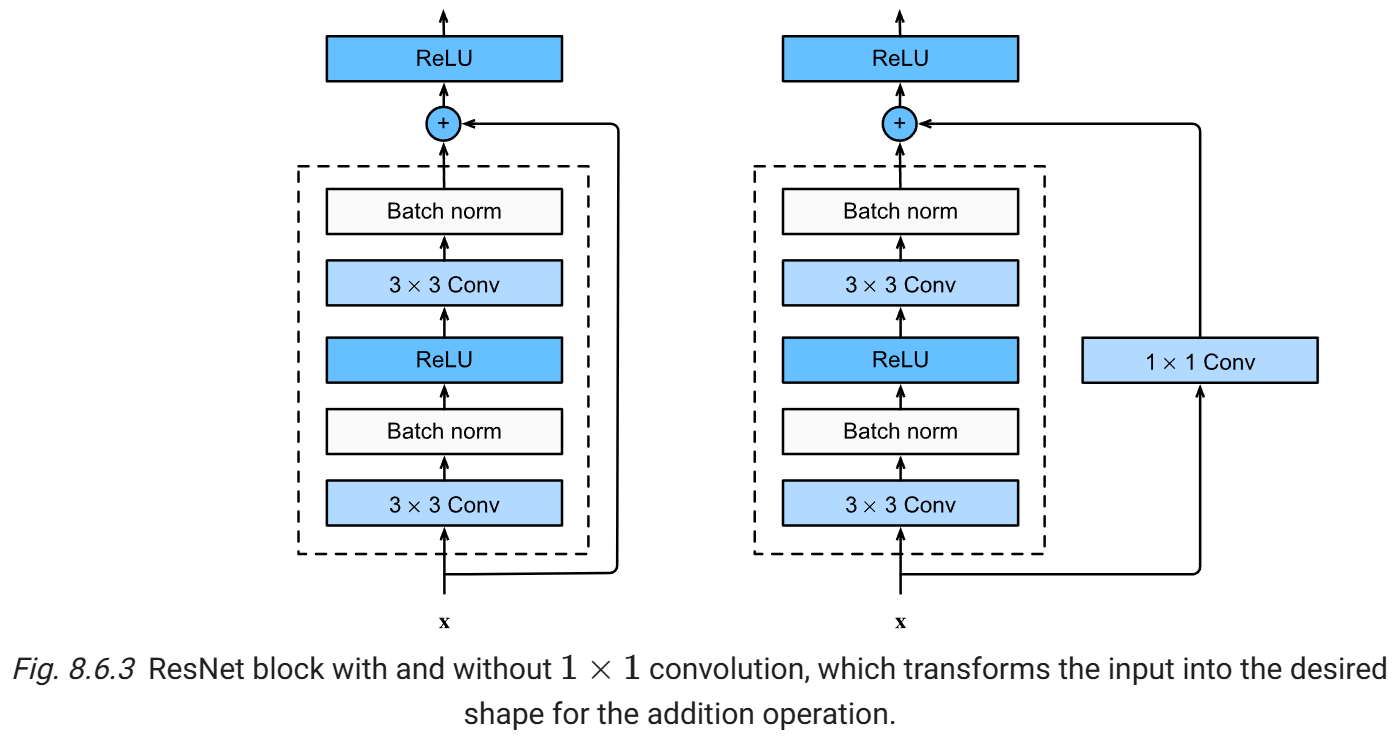
3. Shortcut 类型
情况1:尺寸相同
y = F ( x ) + x y = F(x) + x y=F(x)+x
情况2:尺寸不同(下采样)
y = F ( x ) + W s x W s = 1 × 1 Conv y = F(x) + W_s x \\ \color{purple}{W_s = 1\times1 \text{ Conv}} y=F(x)+WsxWs=1×1 Conv
创新点
1. 残差连接(Skip Connection)
允许梯度直接传播
2. 可训练超深网络
152 层首次成功训练
3. 结构简洁但极强
成为后续几乎所有视觉网络的基础(DenseNet, U-Net)
为什么 ResNet 能训练 152 层
残差网络的理论基础:
∂ y ∂ x = ∂ F ( x ) ∂ x + 1 \frac{\partial y}{\partial x} = \frac{\partial F(x)}{\partial x} + 1 ∂x∂y=∂x∂F(x)+1
即梯度中始终存在 “+1” 项:
- 梯度不会消失
- 网络可以直接传递恒等映射
残差块
有 BasicBlock 和 Bottleneck 两种残差块
-> 解决 深层网络退化问题(degradation problem)
深层网络退化问题: 网络变深之后, 训练误差反而升高(不是过拟合,而是优化困难)
让网络学习“残差”,而不是完整映射:
- 更容易优化
- 梯度可以直接走 shortcut
- 深度可以无限堆叠
1. BasicBlock
3×3 → 3×3
(没有通道扩张)
- 两个 3×3 代替一个 5×5 (继承自 VGG 的设计思想)
- 适用于中等深度网络
2. Bottleneck
1×1 → 3×3 → 1×1
- 先降维(1×1) -> 缩小计算量
- 在低维空间做 3×3 -> 非常省计算
- 再升维(1×1) -> 恢复表达能力
本质: 在低维空间做重计算
3. 对比
| 对比点 | BasicBlock | Bottleneck |
|---|---|---|
| 使用模型 | ResNet18/34 | ResNet50+ |
| 结构 | 3×3 → 3×3 | 1×1 → 3×3 → 1×1 |
| 是否扩张通道 | 否 | 是(×4) |
| 参数量 | 大 | 小(更高效) |
| 适合深度 | 中等深度 | 超深网络 |
| 计算效率 | 一般 | 高效 |
BasicBlock:简单粗暴,适合不太深的网络
Bottleneck:用“降维 → 计算 → 升维”节省算力,让网络可以变得极深
4. 举例
假设通道 256 -> BasicBlock 大约是 Bottleneck 的 17 倍参数量
BasicBlock 用“全维计算”
Bottleneck 用“低维计算 + 高维表达”
BasicBlock:
第一层 3×3: 3 × 3 × 256 × 256 = 589 , 824 第二层 3×3: 3 × 3 × 256 × 256 = 589 , 824 总共: 589 , 824 × 2 = 1 , 179 , 648 \begin{align} \text{第一层 3×3:}\quad& 3×3×256×256=589,824 \\ \text{第二层 3×3:}\quad& 3×3×256×256=589,824 \\ \text{总共:}\quad& 589,824×2=1,179,648 \end{align} 第一层 3×3:第二层 3×3:总共:3×3×256×256=589,8243×3×256×256=589,824589,824×2=1,179,648
Bottleneck:
第一层 1×1: 1 × 1 × 256 × 64 = 16 , 384 第二层 3×3: 3 × 3 × 64 × 64 = 36 , 864 第三层 1×1: 1 × 1 × 64 × 256 = 16 , 384 总共: 16 , 384 + 36 , 864 + 16 , 384 = 69 , 632 \begin{align} \text{第一层 1×1:}\quad& 1×1×256×64=16,384 \\ \text{第二层 3×3:}\quad& 3×3×64×64=36,864 \\ \text{第三层 1×1:}\quad& 1×1×64×256=16,384 \\ \text{总共:}\quad& 16,384+36,864+16,384=69,632 \end{align} 第一层 1×1:第二层 3×3:第三层 1×1:总共:1×1×256×64=16,3843×3×64×64=36,8641×1×64×256=16,38416,384+36,864+16,384=69,632
代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
from byzh.ai.Butils import b_get_params
class BasicBlock(nn.Module):
"""
ResNet-18/34 使用的基础残差块(BasicBlock)。
主分支(main path):
conv3x3(stride) -> BN -> ReLU -> conv3x3(stride=1) -> BN
(第二个卷积后不立刻 ReLU,先与残差分支相加)
残差分支(shortcut / identity path):
- 当 stride=1 且 in_ch==out_ch 时:恒等映射(x 直接相加)
- 当 stride!=1 或 in_ch!=out_ch 时:使用 1x1 conv + BN
用于下采样(stride)或通道对齐
输出:
ReLU(main + shortcut)
"""
expansion = 1 # BasicBlock 不扩张通道:输出通道数 = out_ch * expansion = out_ch
def __init__(self, in_ch: int, out_ch: int, stride: int = 1):
"""
Args:
in_ch : 输入特征图通道数 C_in
out_ch : 主分支两层 3x3 卷积的输出通道数(基础通道数)
stride : 第一层 3x3 卷积的步长
- stride=1:不下采样,空间尺寸不变
- stride=2:下采样,H/W 减半(典型 stage 切换)
"""
super().__init__()
# =========================
# 主分支 main path
# =========================
# conv1:3x3 卷积(可能下采样)
# padding=1 让 stride=1 时保持 H/W 不变
self.conv1 = nn.Conv2d(
in_ch, out_ch, kernel_size=3, stride=stride, padding=1, bias=False
)
self.bn1 = nn.BatchNorm2d(out_ch)
# conv2:3x3 卷积(不下采样,stride=1)
# 第二层卷积后不立刻 ReLU:符合 ResNet v1 的 “post-activation after add”
self.conv2 = nn.Conv2d(
out_ch, out_ch, kernel_size=3, stride=1, padding=1, bias=False
)
self.bn2 = nn.BatchNorm2d(out_ch)
# =========================
# 残差分支 shortcut
# =========================
# 默认恒等映射:当尺寸和通道都一致时,不做任何参数化变换
self.shortcut = nn.Sequential()
# 若 stride!=1(空间尺寸变化)或 in_ch!=out_ch(通道不一致)
# 需要通过 1x1 conv 对齐:既可以下采样也可以通道匹配
if stride != 1 or in_ch != out_ch:
self.shortcut = nn.Sequential(
nn.Conv2d(in_ch, out_ch, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_ch),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Args:
x: 输入特征图,形状 (N, C_in, H, W)
Returns:
输出特征图,形状 (N, C_out, H', W')
"""
# -------- main path --------
out = self.conv1(x)
out = self.bn1(out)
out = torch.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# -------- residual add --------
# shortcut(x) 要与 main 的 out 在 (N, C, H, W) 上完全同形状,才能逐元素相加
out = out + self.shortcut(x)
# -------- activation after add --------
out = torch.relu(out)
return out
class Bottleneck(nn.Module):
"""
ResNet-50/101/152 使用的瓶颈残差块(Bottleneck)。
主分支(main path):
1) 1x1 conv: 降维(C_in -> out_ch)
2) 3x3 conv: 特征提取(stride 控制是否下采样)
3) 1x1 conv: 升维(out_ch -> out_ch * expansion)
每个卷积后接 BN;ReLU 放在前两层后;
第三层 1x1 卷积后不立即 ReLU,先与 shortcut 相加,再 ReLU。
残差分支(shortcut):
- 当 stride=1 且 in_ch==out_ch*expansion:恒等映射
- 否则:1x1 conv(stride) + BN 做尺寸/通道对齐
注:
expansion=4 是经典 ResNet bottleneck 设计:
最终输出通道 C_out = out_ch * 4
"""
expansion = 4 # 瓶颈块最终输出通道扩大 4 倍
def __init__(self, in_ch: int, out_ch: int, stride: int = 1):
"""
Args:
in_ch : 输入通道数 C_in
out_ch : 瓶颈内部通道数(中间维度),最终输出通道为 out_ch*4
stride : 3x3 卷积的步长(通常在 stage 切换时为 2)
"""
super().__init__()
# =========================
# 主分支 main path
# =========================
# conv1:1x1 降维,不改变空间尺寸
self.conv1 = nn.Conv2d(in_ch, out_ch, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_ch)
# conv2:3x3 特征提取,可下采样(stride)
# padding=1 让 stride=1 时保持 H/W 不变
self.conv2 = nn.Conv2d(
out_ch, out_ch, kernel_size=3, stride=stride, padding=1, bias=False
)
self.bn2 = nn.BatchNorm2d(out_ch)
# conv3:1x1 升维,输出通道 out_ch*expansion
self.conv3 = nn.Conv2d(out_ch, out_ch * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_ch * self.expansion)
# =========================
# 残差分支 shortcut
# =========================
self.shortcut = nn.Sequential()
# 若 stride!=1(空间尺寸变化)或通道数不匹配(in_ch != out_ch*expansion)
# 需要对齐后才能相加
if stride != 1 or in_ch != out_ch * self.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_ch, out_ch * self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_ch * self.expansion),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Args:
x: 输入特征图,形状 (N, C_in, H, W)
Returns:
输出特征图,形状 (N, out_ch*4, H', W')
- H'/W' 由 stride 决定(stride=2 时通常减半)
"""
# -------- 1) reduce --------
out = self.conv1(x)
out = self.bn1(out)
out = torch.relu(out)
# -------- 2) transform --------
out = self.conv2(out)
out = self.bn2(out)
out = torch.relu(out)
# -------- 3) expand (no ReLU here) --------
out = self.conv3(out)
out = self.bn3(out)
# -------- residual add --------
out = out + self.shortcut(x)
# -------- activation after add --------
out = torch.relu(out)
return out
class ResNet(nn.Module):
"""
input shape: (N, 3, 224, 224)
"""
def __init__(self, block, layers, num_classes=1000):
super().__init__()
self.in_ch = 64
self.conv1 = nn.Conv2d(3, 64, 7, 2, 3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(3, 2, 1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_ch, blocks, stride=1):
layers = []
layers.append(block(self.in_ch, out_ch, stride))
self.in_ch = out_ch * block.expansion
for _ in range(1, blocks):
layers.append(block(self.in_ch, out_ch))
return nn.Sequential(*layers)
def forward(self, x):
x = torch.relu(self.bn1(self.conv1(x)))
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
class B_ResNet18_Paper(ResNet):
"""
input shape: (N, 3, 224, 224)
"""
def __init__(self, num_classes=1000):
block = BasicBlock
layers = [2, 2, 2, 2]
super().__init__(block=block, layers=layers, num_classes=num_classes)
class B_ResNet34_Paper(ResNet):
"""
input shape: (N, 3, 224, 224)
"""
def __init__(self, num_classes=1000):
block = BasicBlock
layers = [3, 4, 6, 3]
super().__init__(block=block, layers=layers, num_classes=num_classes)
class B_ResNet50_Paper(ResNet):
"""
input shape: (N, 3, 224, 224)
"""
def __init__(self, num_classes=1000):
block = Bottleneck
layers = [3, 4, 6, 3]
super().__init__(block=block, layers=layers, num_classes=num_classes)
class B_ResNet101_Paper(ResNet):
"""
input shape: (N, 3, 224, 224)
"""
def __init__(self, num_classes=1000):
block = Bottleneck
layers = [3, 4, 23, 3]
super().__init__(block=block, layers=layers, num_classes=num_classes)
class B_ResNet152_Paper(ResNet):
"""
input shape: (N, 3, 224, 224)
"""
def __init__(self, num_classes=1000):
block = Bottleneck
layers = [3, 8, 36, 3]
super().__init__(block=block, layers=layers, num_classes=num_classes)
if __name__ == '__main__':
# ResNet18
net = B_ResNet18_Paper(num_classes=1000)
a = torch.randn(50, 3, 224, 224)
result = net(a)
print(result.shape)
print(f"参数量: {b_get_params(net)}") # 11_689_512
# ResNet34
net = B_ResNet34_Paper(num_classes=1000)
a = torch.randn(50, 3, 224, 224)
result = net(a)
print(result.shape)
print(f"参数量: {b_get_params(net)}") # 21_797_672
# ResNet50
net = B_ResNet50_Paper(num_classes=1000)
a = torch.randn(50, 3, 224, 224)
result = net(a)
print(result.shape)
print(f"参数量: {b_get_params(net)}") # 25_557_032
# ResNet101
net = B_ResNet101_Paper(num_classes=1000)
a = torch.randn(50, 3, 224, 224)
result = net(a)
print(result.shape)
print(f"参数量: {b_get_params(net)}") # 44_549_160
# ResNet152
net = B_ResNet152_Paper(num_classes=1000)
a = torch.randn(50, 3, 224, 224)
result = net(a)
print(result.shape)
print(f"参数量: {b_get_params(net)}") # 60_192_808
项目实例
库环境:
numpy==1.26.4
torch==2.2.2cu121
byzh-core==0.0.9.21
byzh-ai==0.0.9.56
byzh-extra==0.0.9.12
...
ResNet18训练MNIST数据集:
# copy all the codes from here to run
import torch
import torch.nn.functional as F
from byzh.ai.Btrainer import B_Classification_Trainer
from byzh.ai.Bdata import B_Download_MNIST, b_get_dataloader_from_tensor, b_stratified_indices
# from uploadToPypi_ai.byzh.ai.Bmodel.study_cnn import B_ResNet18_Paper
from byzh.ai.Bmodel.study_cnn import B_ResNet18_Paper
from byzh.ai.Butils import b_get_device
##### hyper params #####
epochs = 10
lr = 1e-3
batch_size = 32
device = b_get_device(use_idle_gpu=True)
##### data #####
downloader = B_Download_MNIST(save_dir='D:/study_cnn/datasets/MNIST')
data_dict = downloader.get_data()
X_train = data_dict['X_train_standard']
y_train = data_dict['y_train']
X_test = data_dict['X_test_standard']
y_test = data_dict['y_test']
num_classes = data_dict['num_classes']
num_samples = data_dict['num_samples']
indices = b_stratified_indices(y_train, num_samples//5)
X_train = X_train[indices]
X_train = F.interpolate(X_train, size=(224, 224), mode='bilinear')
X_train = X_train.repeat(1, 3, 1, 1)
y_train = y_train[indices]
indices = b_stratified_indices(y_test, num_samples//5)
X_test = X_test[indices]
X_test = F.interpolate(X_test, size=(224, 224), mode='bilinear')
X_test = X_test.repeat(1, 3, 1, 1)
y_test = y_test[indices]
train_dataloader, val_dataloader = b_get_dataloader_from_tensor(
X_train, y_train, X_test, y_test,
batch_size=batch_size
)
##### model #####
model = B_ResNet18_Paper(num_classes=num_classes)
##### else #####
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
criterion = torch.nn.CrossEntropyLoss()
##### trainer #####
trainer = B_Classification_Trainer(
model=model,
optimizer=optimizer,
criterion=criterion,
train_loader=train_dataloader,
val_loader=val_dataloader,
device=device
)
trainer.set_writer1('./runs/resnet18/log.txt')
##### run #####
trainer.train_eval_s(epochs=epochs)
##### calculate #####
trainer.draw_loss_acc('./runs/resnet18/loss_acc.png', y_lim=False)
trainer.save_best_checkpoint('./runs/resnet18/best_checkpoint.pth')
trainer.calculate_model()

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)